►
From YouTube: Antrea Community Meeting 01/18/2022
Description
Antrea Community Meeting, January 18th 2022
A
So
good
morning,
good
afternoon
or
good
evening,
I
think
we
can
consider
this
the
first
distance
of
the
anterior
community
meeting
for
year
2022.
As
you
probably
know,
we
had
a
very
short
meeting
on
january
4th.
But
as
there
was
no
topic
on
the
agenda,
the
meeting
was
cut
kind
of
short
immediately
and
therefore
this
is
our
first
real
meeting
of
the
year.
Today
is
january
wednesday,
the
19th,
of
course,
if
you
are
in
the
united
states,
you're
still
in
the
past,
it's
still
tuesday
january
18th.
B
C
B
B
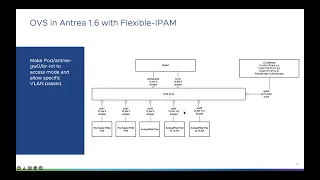
And
for
entry
1.6,
we
need
to
add
the
multiple
vlan
support,
so
we,
firstly,
we
need
to
set
the
existing
port
as
the
access
mode
and
with
vlan
0,
but
we
can
also
keep
keep
it
in
trunk
mode
this
if
we
keep
it
in
in
trunk
mode.
It
is
friendly
for
the
upgrade
scenario,
because
we
don't
need
to
change
the
existing
part
mode.
B
B
B
Next
is
os
flow
tables
enhancement
because
entrance
uses
os
table
10110
as
the
output
table
to
output
packet
to
os
ports
and
if
we
want
to
add
the
multiple
vlan
support
since
obs
won't
process
vlan
tag
automatically.
If
we
specify
the
output
port,
we
need
to
add
a
new
table
to
process
this
network
before
the
output
table.
B
B
B
We
need
to
set
the
go
to
table
action
from
the
output
to
the
vlan
table
and
we
add
some
flows
in
vlan
tables
to
process
it
such
as
this.
If
the
import
is
uplink
and
we
we
can,
we
can
believe
the
output
part
is
not
uplink,
so
it
is
a
access
part,
so
we
can
just
pop
vlan
and
if
the
import
is
a
ipam,
vlan
port
and
the
register,
one
is
which,
which
stores
the
the
output
part
number
and
the
three
means
the
output
is
uplink.
B
B
And
also,
we
still
have
some
open
items
open
items
for
this.
For
this
change
first
is
frederick's
name.
We
we
already
have
the
and
trap
ham
fresher
gate,
but
if
we
need
to,
if
we
want
to
add
another
con
config
config
to
switch
on
or
off
the
multiple
vlan
support,
we
we
need
to
cut
decide
a
new,
a
new
configuration,
and
the
second
item
is
I
mentioned
about.
B
D
D
D
B
B
D
A
Hello
ron,
there
is
something
that
I
did
not
understand
about
the
flaws.
Can
you
go
back
to
slide?
Eight,
the
one
with
the
flows,
the
second
floor,
the
one
that
applies,
the
the
tag
you
see
that
it
captures
a
it
says
import
and
that's
you
know,
that's
the
por,
the
pod
port,
which
is
supposed
to
be
target
and
then
registry,
one
zero
extreme
means
uplink.
B
A
A
No,
I
understand
this,
I'm
trying
to
figure
out
what
is
the
expected
behavior
for
vlan
traffic
between
two
pods
that
have
are
supposed
to
be
on
the
same
vlan,
which
are
on
the
same
on
the
same
host.
Do
we
send
it
to
the
physical
network
in
any
case,
or
in
that
case,
do
will
we
forward
the
traffic
locally
on
open
switch.
A
I
understand
I
understand
now,
I'm
just
asking
this.
You
know
to
sorry
if
this
is
a
stupid
question,
so
this
means
that
we
are
not
able
to
tag
the
traffic
if
the
traffic
is
supposed
to
be
local
in
the
same
in
the
same
open
with
which
instance.
So
if
you
have
two
pods
on
the
same
vlan
on
same
open
with
which
distance
the
traffic
will
be
forwarded,
let's
say
using
normal
forwarding
rules,
but
it
will
not
be.
It
will
not
have
a
vlan
tag.
Is
that
correct.
B
A
A
B
A
A
Okay,
I
mean
I
I
understand-
I
understand
where
you're
coming
from
it's
just
that
probably
and
yes,
if
the
other
network
policies
they
will
achieve
the
same
result
is
just
probably
that
this
is
something
that
probably
at
least
we
want
to
document,
as
it
might
not
be
obvious
to
users.
They
may
think
that
hey,
I
just
configured
vlan
and
I'm
done.
E
E
E
A
Inside
of
yes,
we
need
to
couple
that,
with
with
the
network
policies
now,
yes,
we
can
discuss
from
a
requirement
perspective
whether
we
want
to
give
let's
say
the
same
behavior,
that
user
will
normally
expect
with
the
vlans
or
whether,
instead
you
know,
we
think
that
it
is
okay
to
have
this
sort
of
peculiar
behavior,
and
then
it's
just
documented,
and
so
users
know
that
they
have
to
define
a
namespace
with
a
vlan
tag
and
additionally
also
configure
the
network
policy
for
isolation
yeah.
I
think
that
that
might
be
acceptable.
A
A
A
Okay.
So
thanks
a
lot
for
the
clarification,
so
my
other
question
is
on
slide
4
on
the
specification
and
it's
a
very
simple
question:
do
you
think
that
we
need
to
add
the
validation
or
admission
controllers
for
making
sure
that
vlans
are
unique,
that
you
know
no
two?
We
don't
have
two
name
species
using
the
same
villain.
B
E
B
D
D
D
B
B
B
A
D
D
B
D
F
Yes,
I
am,
but
can
I
actually
share
my
screen
to
to
demonstrate
this
sure
sure
go
ahead?
Okay,
okay,
I'll
try
to
make
this
as
quick
as
possible.
So
essentially,
you
know
with
the
upstream
cluster
network
policy
discussions
we're
the
background.
Is
that
we're
trying
to
you
know
design
the
new
cluster
network
policy
api
for
the
upstream
kubernetes
and
in
terms
of
design
choices?
We
were
we're
in
current
encountering.
F
F
So,
for
example,
in
ingress
rules,
one
of
the
ways
to
select
workloads
is
using
namespace
vector,
which
you
know,
selects
all
the
workloads
and
namespaces
matching
one
label
and
the
other
way
is
paw
selector,
which
means
that,
regardless
of
namespace,
as
long
as
the
pod
matches
certain
labels,
those
parts
will
be
selected
now.
The
interesting
part
is
that
those
two
selectors
can
be
used
in
conjunction,
which
means
that
some
the
parts
needs
to
satisfy
both
conditions,
both
the
name,
space,
vector
condition
and
the
positive
vector
conditions
for
it
to
be
actually
selected
by
this.
F
You
know,
conjunctive
selection
mechanism,
so
though
this
was
working
in
network
policy
implementation,
but
there's
an
interesting
problem
brought
up
because
some
people
are
are
actually
trying
to
add
news
vectors
to
the
network
policy
peers,
for
example,
service
account
selector
right
so
consider
this
like.
I
wanted
to
select
service
account
possible
service,
certain
service
accounts
and
matching
namespace
selectors
blah
blah
blah,
and
people
are
saying
that
I
okay.
We
wanted
to
add
this
to
the
current
network
policy.
F
Why
can't?
We,
just
you
know,
throw
this
in
right,
because
it's
just
another
selector
and
we
can
do
some
sort
of
like
api
validation,
to
make
sure
that
you
know.
In
a
certain
period,
the
service
account
can
only
be
standalone
or
to
be
used
with
namespace
selector,
but
you
cannot
say
something
like
service
accounts,
vector
and
post
vector.
That's
just
not
about
it.
Why
can't
we
do
that
now?
F
F
F
So
entry
will
process
this
the
same
way
as
this,
because
entry
doesn't
actually
know
to
look
for
service
accounts
vector
that
just
doesn't
exist
for
as
far
as
the
cni,
though,
because
it's
an
upgraded
cni
and
that
creates
a
problem
because
in
the
actual
implementation
or
realization
of
obvious
flows
and
sure
will
just
push
down
the
addresses
matching
the
namespace
vector
but
disregard
this,
and
you
know
there
won't
be
any
errors
thrown
out,
because
entrad
doesn't
know
that
this
is
a
problem.
In
fact,
it
might
doesn't
even
know
at
all
that.
F
There's
a
field
called
service
consecutive
existing
in
the
in
the
new
now
policy
spec,
because
it
doesn't
know
to
look
for
it
so
to
to
to
summarize,
the
problem
is
that
oc
and
nice
may
enforce
the
new
api
network
policy
api
instances
wrong
without
any
warnings
or
errors
wrong,
and
this
is
what
we're
trying
to
avoid
in
the
upstream.
That's
why
you
know
in
the
in
the
upstream
discussions
when
people
are
trying
to
bring
service
account,
selectors
or
or
something
similar
into
current
network
policies.
F
F
So,
as
you
can
see,
there
is
a
lot
of
redundant
information,
because
here
you
will
say:
okay,
the
entire
struct
is
a
namespace
and
pass
vector
and
underneath
you
have
namespace
vector
empires
pause
vector.
So
this
feels
redundant.
But
what
what's
good
about
it
is
that
now
you
can
mandate
the
network
policy
peer
to
be
one
of
a
couple
of
kinds,
so
the
only
valid
kind
will
be
namespace
vector
all
paw
selector
or
this
namespace
and
pass
vector
or
whatever
the
other
combinations
that
we
support
in
the
future.
F
Now,
when
c-
and
I
look
at
this,
cni
should
look
for
a
specific
type.
For
example,
I
the
the
specific
type
being
like
enum,
that
it
is
already
supporting
it.
It's
either
namespace
vector
pod,
selector
or
namespace
and
pod
selector.
Now,
when
user
created
something
like
namespace
and
service
accounts,
vector
cnis
will
immediately
know
that
this
is
a
problem,
because
this
is
a
new
type
that
it
doesn't
really
know
about.
F
In
that
case,
it
can
draw
the
mirror
saying
that
hey,
I
don't
know
how
to
implement
this,
or
I
don't
know
how
to
realize
this
on
in
obs,
because
you're
using
a
new
ingress
period,
type
that
I
haven't
been
supporting
yet
so
so
this
is
the
sort
of
like
a
result
of
the
discussions
we
had
and
I
actually
was
talking
to
grayson
on.
You
know
his
pr
that
we
probably
wanted
to
incorporate
this
comment
into
some
of
the
new
designs.
F
We're
making
specifically
about
service
accounts,
so
right
now
in
the
service
account
api
design.
You
know
we're
a
lot
of
places
where
using
the
old
way
where,
when
we're
selecting
service
accounts,
we're
using
a
mixture
of
selectors,
for
example,
the
labels
vector
namespace
vector
ended
together
or
conjuncted
together
and
namespace
name,
which
is
another
way
of
selecting
this.
Now.
Instead
of
doing
something
like
this,
we
might
consider
doing
something
really
explicit
and
verbals
so
that
you
know
under
service
accounts.
F
We
strongly
type
the
the
kind
of
service
account
selection
mechanism
that
we
support
it's
either
a
namespace
name
or
a
namespace
label
and
service
account
label,
selector
or,
let's
say
namespace
label
and
service
account,
name
selector.
So
any
kind
of
like
valid
combination
that
we
wanted
to
support
support.
We
laid
it
out
explicitly
so
that
you
know
people
know
that
which
kind
of
selection
mechanism
we're
using
and
by
doing
this
it
we
are
basically
future
proof
in
ourselves
and
any
new
selection
mechanism.
We
wanted
to
add
in
the
future.
F
For
example,
paw
selector
with
ended
with
service
account
selector
doesn't
really
make
sense,
so
this
would
not
be
a
combination
that
we
support,
and
so
that's
why
we
won't
have
you
know
that
combination
as
a
type
here,
but
the
idea
is
that
you
know
any
combination
that
we
support.
We
sort
of
like
laid
it
out
so
that
when
we
define
the
open
api
validation
for
the
service
accounts,
we
can
say
the
the
service
account.
F
F
You
know
a
real
headache
because
of
the
acn
piece
back
that
we
all
have
already
rolled
out
so
that,
if
we,
you
know,
don't
support
this
anymore,
then
it
would
be
a
huge
backward
compatibility
issues.
And
you
know
if
we
support
both
this.
This
kind
of
writing
and
the
other
writing.
It
will
also
be
really
confusing
to
people
so,
but
but
the
bottom
line
is
that
for
the
new
api
designs,
we're
trying
to
stuck
with
this
pattern
instead
of
the
the
old
ones.
D
Should
be
specified
ex
expensive
early,
but
my
question
is
whether
it
could
lead
to
too
many
strikes
similar
strikes
that
how
similar
fields,
for
example,
this
namespace
label
and
the
service
encounter
label
selector
and
the
namespace
and
the
port
they
will
say.
Could
we
use
some
unified
structure
to
represent
multiple
types?
For
example,
we
could
just
have
two
basic
types:
namespace
the
object,
selector
and
just
object
selector
and
for
the
formal
one
we
just
have
two
fields.
One
is
called
select
a
one
object,
selector
and
another
one
is
the
type
of
the
object.
F
So
it
will
be
a
little
bit
of
a
mind
twisting
for
people
to
you
know
when,
when
you
write
acmps,
you
select
workloads
in
in
one
sort
like
fashion,
and
when
you
write
about
service
accounts
in
a
cnp's,
then
you
need
to
write
it
in
entirely.
You
know
different
ways,
but
I
don't
know
it's
a.
It
might
not
be
a
problem,
but
yes,
I
think
that's
that's
a
good
proposal
that
we
can.
We
should
definitely
consider
as
well
we'll,
let's
see
I,
I
guess
I'll
I'll-
actually
point
it
to
grayson.
F
G
Yeah
from
my
understanding,
I
guess
maybe
for
service
account,
we
can
use
the
like
you
proposed
in
the
on
screen
in
the
comments
and
when
we,
if
we
want
to
like
use
this
kind
of
api
design
or
acnp
like
between
namespace
selector
and
the
pod
selector,
we
can
try
to
do
like
add
a
field
called
type.
It's
a
pod
or
it's
a
service
account
and
change.
The
service
account
api
design.
At
the
same
time,
you
know
if,
if,
if
that's,
if
that
kind
of
design
will
like
use
less
struct.
F
F
F
A
So
since
we
are
almost
top
of
the
hour,
perhaps
this
is
something
that
we
can
keep
discussing
in
the
next
community
meeting
and
it
might
help
providing
some
more
yaml
examples
and
also,
I
believe,
the
other
important
aspect
to
keeping
to
keep
in
check
is
potential
backward
compatibility
implications
and
figure
out
how
to
handle
those.
But
this
is
something
that
I
believe
we
can
address
in
the
next
community
meetings
meeting
in
two
weeks
time,
and
is
there
any
other
question
or
comment
regarding
what
has
just
discussed?
It's
been
discussed
regarding
selectors.
A
D
Maybe
I
could
give
a
quick
update
about
the
release,
progress
or
for
1.5
sure.
Currently,
a
major
code
change
have
been
made
merged,
except
the
except
pr
for
merging
the
multi
cluster
branch
to
main
branch.
So
I
would
appreciate
that
the
reviewers
or
for
the
that
branch
could
review
the
mod
pr
so
that
we
could
process
proceed.
D
The
release,
progress,
yeah
and
some
other
minor
appears,
as
as
they
are
pending
on
reviewing,
for
example,
the
talk
and
the
antenna
test
patches
for
new
features,
yeah,
that's
what
we
need
kindly
and
I
will
write
a
release
note.
Maybe
today,
and
hopefully
you
could
review
that
pr
tomorrow,
then
we
can
ensure
that
the
risk
can
go
out
this
week.
D
E
C
E
D
E
D
A
Cool,
so
I
think
that
that
might
be
all
for
today's
meeting
and
I
would
like
to
thank
everyone
for
joining
this
call.
Most
importantly,
thanks
to
ron
for
presenting
the
new
design
for
multivitamin
and
many
thanks
for
yank
for
bringing
up
these
this
problem
with
the
syntax
network
policy,
api,
syntax
and
then
semantics-
and
I
guess
that's
all
for
today.
So
thanks
again
for
joining-
and
I
will
talk
to
you-
we
will
talk
again
in
two
weeks
time.
So
I
wish
everyone
a
good
morning
good
afternoon
good
evening
and
goodbye.