►
Description
Speaker | Brian O'Neill (Lead Architect, Health Market Science)
Date | Thursday December 13
Want to gift a cool Java application to Grandma this holiday season? Don't miss this webinar where we'll create a couple from scratch to go along with that potholder you got her. We'll use a couple of the most popular APIs, Hector and Astyanax, to demonstrate how quickly you can get up and running on Cassandra. We'll also delve into a bit of data modeling; specifically, we'll take a look at composite columns and how to get at them in Java.
A
Welcome
everybody
to
this
edition
of
college
credit
webinar
series
creating
your
first
java
application
with
Apache
Cassandra
I
am
very
excited
to
have
a
patchy,
Cassandra
MBP
Brian
O'neill
with
us.
Today
you
can
follow
brian
@b
o'neill
42
on
twitter,
and
I
strongly
recommend
reading
his
blog
as
well
just
a
couple
of
housekeeping
items.
A
This
is
going
to
be
a
very
hands-on
presentation.
Today,
brian
is
actually
going
to
walk
us
through
how
to
create
our
first
java
application.
So
there's
a
lot
of
screen
sharing
going
on.
We
will
hold
our
questions
until
the
end
of
the
presentation,
but
brian
is
reserving
a
lot
of
time
to
answer
your
questions
today.
So
please
use
the
WebEx
Q&A
panel
to
ask
your
questions
and
I
will
pose
them
to
Brian
at
the
end
of
today's
webinar.
So
without
further
ado,
I
would
like
to
welcome
Brian
area
well,.
B
B
So
today
our
challenge
is
going
to
be
to
help
Santa
Claus,
so
keeping
with
the
spirit
of
the
holidays,
we're
going
to
build
a
nice
and
naughty
list,
form
that
is
globally
scalable
and
then
we're
also
going
to
keep
track
of
which
children
want
what
toys-
and
this
came
from
just
a
little
background.
I'm
lead
architect
at
health
market
science,
where
we
are
in
the
master
data
management
space
for
the
healthcare
industry.
So
we
bring
in
you
know
over
2000
feeds
of
data
on
all
with
different
schemas.
We
put
them
together
and
we
track.
B
B
To
write
prescriptions,
and
then
you
know,
we
help
the
pharmacies
with
that,
so
without
further
ado,
so
that
translates
almost
identically
to
what
we
want
to
do
today,
which
is
build
this
scaleable
naughty
list,
so
we'll
get
deeper
into
the
data
modeling
aspect
of
it.
But
the
irony
here
is
I.
Looked
it
up
and
there
are
1.9
billion
children
in
the
world
and
with
Cassandra
that
will
actually
fit
in
a
single
row.
Beverley
little
tip
there.
B
So
what
we
want
to
do
is
build
an
application
that
can
allow
children
to
log
in
and
check
their
standing
of
Santa
Claus
and
also
as
Santa's
flying
around
the
world,
he'll
be
able
to
query
by
country,
state
and
zip
code
which
children
on
the
nice
list
of
which
children
are
on
my
list
and
he'll
do
that
with
some
speed.
So
this
should
be
fun.
Let's
get
set
up,
though,
so,
to
install.
Consider
one
of
the
one
of
the
great
things
about
Cassandra
is
the
ease
of
administration
to
get
set
up?
B
Really
all
you
need
to
do
is
uncompress.
The
archive
that
you
can
get
from
here
today
we'll
be
using
the
1
to
beta
version,
which
is
a
sort
of
cutting
edge,
but
is
going
to
be
released,
released
candidate
ready
soon,
so
I
wanted
to
keep
the
content
fresh
and
actually
show
everybody.
Some
of
the
new
features
that
are
available
so
I
decided
to
go
with
one
too.
So
if
we
take
jump
over
to
the
terminal,
real
quick
see
off
shot
it
down.
Just
so
I
can
show
you
guys.
B
So
you
know
you
know
I
usually
keep
a
bunch
of
the
Cassandra
versions
available
here,
so
I,
actually
one
one
one,
two
one
one
one
two
one
one
five
one
two
zero
and
really
all
I
did
is
take
the
tarball
into
this
directory
and
type
on
zip
for
time
reasons,
I'm
going
to
not
download
it
right,
while
you're
watching
but
and
I
just
create
a
symlink
and
then
start
her
up.
All
you
do
is
type
in
Cassandra.
D
B
B
Yamo
itself
and
you'll
see
start
native
transport.
True,
so
this
that
will
start
the
new
transport
that
is
not
dependent
on
unthrift
on
1942
in
this
case
out
of
the
box,
and
then
you'll
be
ready
to
do
this.
Do
this
at
home.
So
if
you're,
following
along
at
home,
go
ahead
and
download
unzip
change
that
value,
and
then
you
can
do
bin
Cassandra
app
and
usually
what
I'm
in
development
mode
I
just
leave
it
in
the
foreground.
Just
in
case
so,
and
you
can
see
it
fired
up,
pretty
quick
right
there
so
moving
along.
B
Next,
we
want
to
talk
about
the
data
model
and
I'm
not
going
to
go
too
deep
into
data.
Modeling
I
have
a
link
here
when
we
share
the
slides
that
Aaron
Morton
did
a
great
demonstration
on
data
modeling.
So
you
know
I
recommend
everybody
go
take
a
look
at
that
it
is.
It
is
really
important
to
understand
the
data
model
that
cassandra
has
underneath
bit,
though,
and
as
we'll
see
today,
you're
really
going
to
get
there
two
views
into
the
Cassandra
world.
B
When
you
start
to
look
at
cql,
one
is
from
the
cql
perspective,
which
looks
a
lot
like
regular
tables
in
a
relational
database,
and
then
another
is
from
the
persistence
perspective
where
how
laid
out
in
both
rows
and
columns
for
Cassandra
underneath
and
the
reason
that's
important,
is
in
from
the
Java
API
perspectives.
You
actually
get
to
see
and
interact
with
the
storage
model
tightly.
So
when
you
ask
for
rows
and
columns,
that's
what
you're
going
to
get
it's
going
to
be
two
standard
versions
of
rows
and
columns.
So
what's
all
that
mean
so?
B
The
at
the
top
of
the
Sanders
data
model
is
the
schema
and
that
used
to
be
called
key
space.
So
in
a
lot
of
the
Java
API
you're
still
going
to
hear
key
space,
and
you
see
those
kinds
of
classes
there
within
a
key
space.
That's
also
where
Cassandra
has
its
security,
so
you
can
authenticate
against
the
key
space.
So
a
lot
like
you
know
my
sequel
or
any
relational
database
is
how
you
can
create
your
own
schema
within
a
schema.
You.
B
They
used
to
be
called
column
families.
So
again,
a
lot
of
java
api
is
you're,
going
to
see
the
terminology
column
family
over
in
the
cql
world,
they're
going
to
use
the
terminal
table
terminology,
okay,
so
that
all
fairly
standard
now
the
fun
part.
So
within
the
table
you
can
have
rows,
that's
normal,
but
rows
can
have
any
arbitrary
number
of
columns
and
the
number
of
columns
can
differ
between
rows.
So
that's
pretty
different
and
pretty
powerful.
B
So
we're
going
to
see
how
we
can
leverage
that
to
on
sort
of
indexing
as
we
go
through
our
schema
here
and
then
so
and
then
you
can
look
in
the
details
of
this
a
little
deeper
afterwards,
but
Cassandra
treats
data
fairly
opaque.
It
doesn't
look
into
data,
so
the
really
the
only
two
mechanisms
it
has
is
it
valid
eggs
validates
the.
C
B
That
you're
giving
it
that
they're
they're
compatible
with
your
table.
So
in
the
case
of
rows,
it's
really
going
to
only
validate
your
row
keys
on,
so
we
don't
make
sure
that
it's
utf-8.
For
example,
there
are
other
data
types
but
again
refer
to
back
to
Aaron's
presentation
for
more
on
that
information.
So
then,
within
robes
you
have
columns,
and
the
key
piece
here
is
that
columns
are
are
sorted,
so
you
have
to
specify
a
comparator
for
your
columns.
The
reason
for
that
is
that
columns
are
stored,
sorted
on
disk,
which
is
pretty
important.
B
Okay,
so
let's
take
that
data
model
and
now
apply
apply.
It
exchanges,
distributive
architecture
and
again
I'm
not
going
to
go
into
detail
too
much
here,
but
it's
important
when
considering
how
to
layout
your
schema,
so
in
Cassandra
nodes
form
a
ring,
and
what
happens
is
that
each
of
those
instances
starts
up
with
an
initial
token
which
gives
it
its
location
on
the
ring
row
keys.
B
A
B
C
B
To
get
converted
into
the
token
range
right,
so
here,
I'm
just
ending
the
night,
a
range
of
$0.99
Alex
will
pretend
at
50
Bob
the
three
need
to
15
they're,
actually
going
to
be
distributed
unevenly
right
along
this
ring
and
in
no
particular
order.
So
that's
that's
really
important
on
that
range.
Searching
across
a
set
of
rows
is
difficult
in
Cassandra
because
it
could
span
all
of
your
notes
right
so
traversing
a
keys
base
in
Cassandra
will
actually
touch
all
of
your
different
other
nodes.
B
There's
some
caveats
to
that
for
replication
and
such
but
again
we're
going
to
gloss
over
those
a
bit.
So
what
I
like
to
keep
in
mind
from
a
Java
from
a
Java
heads
perspective,
is
that
the
Cassandra
data
model
always
maps
to
this
in
my
bike
right.
So
it's
a
hash
map
where
the
row
Keys
the
different
segments
of
the
hash
different
rows
in
the
hash
are
distributed
across
machines.
B
Then
each
row
right
is
actually
a
sorted
map
of
columns.
Okay,
so
again,
M
says
there's
enough
as
trips
of
some
people
up,
but
if
you
boil
it
down
to
this
is
I.
Think
things
are
pretty
clear,
so
the
implications
here
that
a
direct
row
fetch
is
fast
searching.
A
range
of
rows
can
be
costly
as
I
explained
and
then
searching
a
range
of
columns
is
cheap
because
they're
all
sorted
on
disk.
So
that's
the
background.
I
think
we
need
to
start
on
our
first
app.
B
Ok,
so
let's
take
a
look
at
our
schema
for
this
application.
I'm
suggesting-
and
let
me
let
me
also
say
that
the
defining
a
schema
for
Cassandra
is
an
art
and
I
think
there's
lots
of
good,
great
blog
post
out
there
on
recommendations
on
how
you
do
it,
but
often
you
work
backwards
from
the
queries
you
want
to
support.
B
Is
what
I'm
suggesting
in
this
in
this
approach
and
again,
you
could
debate
a
bit
because
it
is
a
bit
of
an
art
what
the
best
approach
is.
But
let's
go
along
this
path
a
little
bit
here.
So
let's
get
down
into
the
details
of
the
naughty
or
nice
list,
specifically
because
I
think
the
the
children
table
is
pretty
straightforward,
but
the
naughty
or
nice
list
again
is
the
one
that's
a
little
creative.
B
So
because
we
do
one
row
per
standing,
:
country
right
so
nice
or
naughty,
and
then
USA
or
Ireland
the
shores,
all
children
in
a
country
or
group
together
on
desk
right.
So
that's
basically
what
we're
saying
and
then,
if
we
could
one
column
per
child
using
a
compound
key
and
I'll
explain
more
about
what
that
is.
B
If
it
would
ensure
that
all
the
children
are
grouped
with
each
other
if
they
are
geographically
close
to
one
another,
which
is
pretty
neat,
so
you're
actually
dictating
what
the
storage
is
on
disk
so
that
you
can
get
to
BD
queries
I'm
by
designing
your
schema.
So
you
know
so.
I'll
actually
show
this
right
here.
So
so,
let's
just
mean
visually
for
the
naughty
or
nice
list.
B
This
is
my
row
key
and
then
list
it
down
on
my
columns
and
each
you
can
see
if
these
are
in
sorted
order,
and
it
would
be
fast
for
me
to
go
graph
all
the
rows
that
are
of
a
certain
zip
because
they
would
all
be
stored
together
right
so
couple
things
here,
though,
as
we've
done,
some
very
large
wide
rows
in
our
production
environments
is
for
hot
spotting.
So
let's
say
that
you
know
we
are
actually
only
going
to
have
one
row
that
has
all
the
nice
children
in
America
in
it.
B
C
C
B
B
Centers
all
I
need
to
specify
for
my
key
space
is
the
replication
strategy
and
how
many
replicas
I
want
so
again
since
I'm
local
one
replicas,
fine
and
a
simple
strategy,
because
I
don't
have
multiple
data
centers
again
I
forgot
and
some
of
the
other
information
online
for
more
information
on
that.
So
then,
just
like
relational
world,
you
say
which
database
you
want
to
use
and
then
I'm
going
to
create
my
two
tables-
and
this
looks
awfully
familiar
right.
B
When
is
you
this
statement?
The
sequel,
SH
prompt
cql
creates
the
schema
forming,
but
it
has
a
lot
of
extra
capabilities
that
it
will
adjust.
My
schema
slightly
and
in
this
first
example
since
we're
going
to
be
using
one
of
the
Java
API
s,
I'm,
going
to
say
with
compact
storage,
that
makes
it
the
schema
that
I
have
here
map
better
to
the
Java
API
s.
I
will
go
into
that
more
in
a
little
bit,
so
let's
keep
going
and
then
I'm
going
to
create
my
naughty
or
nice
list.
B
C
B
All
I
really
do
is
cap,
that
into
sequel,
SH,
so
c,
plus
h
is
the
new
sequel
prompt
on
c
ql
prompt
that
is,
the
SE
recommended
way
to
create
and
interact
with
schemas
make
sort
of
database
administration
a
little
easier
in
the
old
days.
We
Cassandra,
CLI
and
I
actually
still
use
that
you're
going
to
see
why
in
a
second?
So
let's
just
issue
that
command
and
you're
going
to
see
Cassandra
started
working
in
the
background
and
so
I
went
purple.
B
B
B
B
What's
interesting,
is
that
if
I
go
over
to
the
naughty
list
check
this
out?
So
it's
what
we
wanted!
One
row
key
per
standing
and
country,
so
you
can
see
I've
got
Bart,
Simpson,
Dennis
and
Michael
Myers
all
naughty
in
the
USA,
then
over
an
island
I
got
Colin,
O'neill
and
Eoghan
O'neill,
so
but
you're
going
to
see
that
all
of
that
for
the
entity
was
squished
into
a
single
column.
Name,
there's
actually
no
values
here,
which
is
interesting.
So
we
flip
back
to
the
PowerPoint
and
describe
that
real,
quick.
So.
C
B
Sequel
data
modeling
rules,
everything
it
here's
the
key
part
comes
down
to
how
you
declare
this
primary
key
all
right,
so
the
first
primary
key
becomes
the
row
key,
so
you
can
see
we
did
standing
by
country
there,
then
subsequent
component
for
the
primary
key
from
a
composite
column
name.
So
basically,
what
cql
did
for
me
is
to
put
these
things
together
and
stuff
them
in
the
column
name
now.
In
this
example,
I
didn't
have
any
non
primary
key
columns,
but
had
I
done
that,
but
also
for
each
one
of
those
columns
create
a
new.
C
B
So
for
each
data
column
right,
they
have
that
is
not
related
to
the
key
it
will.
When
you
I
do
a
single
write.
It
will
write
multiple
columns,
one
for
each
of
those
types
of
data
that
I'm
storing
to
I'll.
Give
that
a
second
to
process
so
comes
because
that's
that's
pretty
important
and
pretty
powerful
I
mean
we'll
see
how
that
translates
over
to
the
java
api
world.
B
Okay,
so
I
sort
of
ran
through
the
two
different
views
that
we
had
one
can
the
CLI
view
1
from
the
Siebel
vo,
just
captured
in
the
slides
here
now,
one
last
thing
really
to
the
scheme.
Up
before
we
start
hacking.
Some
code
is
the
data
model
implications
and
what
I
can
and
cannot
do
with
respect
to
cql
here.
So
if
we
go
here,
hopefully
I
got
this
right.
B
B
Okay,
so
this
error
right
there
so
coming
from
relational
world,
you
would
have
expected
to
be
able
to
do
this,
but
when
you
think
about
how
it
is
laid
out
on
disk,
you
got
a
guide
Cassandra
through
getting
to
your
data.
So
first
you
want
to
specify.
First,
you
need
to
specify
the
row
key.
So
it's
good
ending
country
equal
to
nice
USA
right.
So
this
will
actually
work
because
I'm
just
I'm
telling
you
what
the
first
place
to
go
is
right.
B
B
Yelled
at
me,
because
I
haven't
told
it
where
to
go
next
in
the
sorted
columns
on
storage
right,
so
you
actually,
you
have
to
progress
through
and
go
from
your
outer
granularity
down
into.
So
that's
good
and
said:
equals
nine
four,
three,
three
three
so
that'll
be
happy
and
IP
equals
richie-rich
there.
B
So
you
can
see
it's
happy,
but
you
can't
skip
any
of
the
intermediate
components
of
the
column
name,
because
it's
literally
searching
down
into
the
storage
on
the
disk,
which
is
all
sorted
by
column,
and
it's
and
basically
what
it's
doing
is
refusing
to
do
table
scans
for
you
so
which
I
actually
think
is
good.
So,
okay,
so
can
I
move
on
here.
Let's
get
over
to
code
alright,
so
this
is
the
fun
part.
So
let
me
let
me
I
even
hesitated
to
put
numbers
on
this
slide.
B
Let
me
just
say
this
slide
is
all
in
my
humble
opinion.
Okay,
so
your
mileage
may
vary
and
whom
you
talk
to.
They
may
give
you
different
different
answers.
One
of
the
great
parts
about
the
Cassandra
community
is
that
it
is
incredibly
active.
It
is
well
that
you
know
hats
off
to
Jonathan
and
crew.
They
they
do
a
great
job
of
wrangling,
the
community
hurting
the
cats
and
we
as
Java
developers.
You
know
the
ramifications
that
are
that
we
have
tons
of
options
for
client
development.
B
So
let
me
just
raise
down
three
years:
I
want
to
keep
going,
make
sure
you
type
of
questions
so
for
people
that
know
threats
are
heard
that
term
thrift
that
the
old
RPC
layer
that
goes
to
Cassandra.
So
you
know
thrift
is
used
by
a
bunch
of
different
projects
to
get
really
efficient,
RPC
and
Cassandra.
Has
that
and
I'd
say
I
can't,
let
me
see
all
except
for
maybe
the
bottom.
One
of
these
Java
API
is
built
on
thrift
so
and
yeah
I.
B
It's
a
tight
coupling
to
Cassandra
I
mean
at
the
same
it
basically
just
mimics
the
objects
that
our
server-side
client-side
and
allows
you
to
call
all
those
methods
on
those
objects
client-side.
But
it
isn't
tightly
coupled
to
the
server
which
makes
it
fairly
difficult
to
interact,
but
so,
if
you're
trying
to
choose
a
Java,
API
I
would
just
bypass
the
rift
and
it's
still
supported,
but
in
the
future
we
may
we
may
see
thrift
go
away.
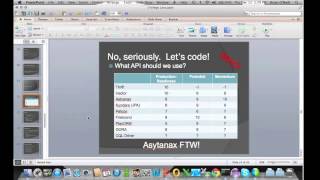
So
a
Hector
is
probably
the
most
production
ready
here
at
help.
B
Market
science,
I'd,
say
95%
of
all
our
heavy-duty
code
is
written
on
Hector.
So
I've
got
three
columns
about
the
top
here.
You
know
crusher
readiness
potential,
which
means,
like
you
know,
there's
some
good
stuff
here
that
people
might
latch
on
for
this
and
it
might
become
something
great
amen,
momentum.
So
just.
B
People
are
using
it
how
many
people
are
flocking
to
it
that
kind
of
thing
so
Hector,
absolutely
production-ready.
You
know
if
you've
got
mission-critical
apps
I'd
go
with
Hector
potential.
A
lot
of
people
are
gravitating
more
towards
a
C
Anik
these
days,
so
you
might
want
to
go
with
Afghan
--ax
if
you're
looking
for
what
the
API
might
become
so
Afghan
acts
is
a
little
more
momentum
than
Hector
I'd
say,
and
it's
tiny
bit
more
potential,
Kundera
I
love
what
what
those
guys
are
doing.
It
is
a
Cassandra
implementation
for
JPA.
B
B
So
that
might
be
another
contender,
there's
actually
built
on
P,
laughs,
I,
think
so,
but
I,
don't
we
don't
use
fuel
ops
at
all
in
our
in
our
house
and
I
think
most
people
if
you're
looking
for
a
straight
up,
Java
API,
gravitate
more
towards
Hector
and
SP
onyx
firebrand
is
a
is
a
newcomer
and
doing
honest
I
haven't
played
around
with
it.
Oh
my
that
stuff
and
I
love
what
I
see
so
I
think
it's
got
a
lot
of
potential,
but
again
Hector
nasty.
B
An
axis
are
sort
of
more
more
widely
used
play
ORM.
Another
great
contender
Dean's
got
some
good
stuff
going
on
over
there
and
what
he
he's,
bridging
the
gap.
So
you
don't
get
joined
in
Cassandra
either
right.
So
if
you
go
to
some
data
model,
so
he's
building
his
framework
to
allow
a
lot
of
the
capability
that
you
had
in
relational
world
and
a
massively
scalable
way
so
again,
good
stuff
coming
for
another
one
of
those.
B
These
guys
is
the
one
just
sort
of
like
Kundera,
they're
kind
of
build
a
API
spans,
the
no
sequel
databases.
So
it's
it's
getting
there
so
I'd
say
I.
Don't
notice
for
sure
but
Gorry
if
you
look
at
RIT's,
tutorials
are
mostly
focused
on
HBase,
but
they
also
have
a
Cassandra.
So
you
sort
of
get
that
feel
when
you
go
to
use
it
and
then
cql
driver
I'm
going
to
come
back
to
at
the
end
of
the
presentation.
Hopefully
all.
B
Now
we're
gonna
get
to
the
go
all
right.
So
what's
the
first
thing,
we
need
to
do
so.
I'm,
going
to
flip
over
here
and
I.
Have
all
this
code
up
on
github
I'll
give
you
the
lead
at
the
end.
So
let's
go
so
what's
the
first
thing
you
need
to
do
when
you're
going
to
write
an
application.
Well,
you
need
to
get
connected
to
the
database.
So
in
this
case,
I've
got
a
little
ASCII
annex
Dao
class.
B
Here
it
takes
a
host,
which
is
just
you
know,
a
host
name
and
the
key
space
I
want
to
connect
to
and
for
asking
annex
you've
got
to
give
it
a
cluster
name.
That's
really
just
for
you
what
you
want
to
identify
this
cluster.
As
for
the
for
your
application
code,
then
the
key
space
that
should
be
fairly
self-evident
and
then
what
asking
X
Afghan
exceed
the
covers
is
discover
all
the
nodes
that
are
part
of
that
cluster.
B
So
you
can
tell
it
what
to
use
to
do
that
discovery
since
we're
locally
so
ring
describe
again.
You'll
know
some
of
these
from
other
presentations.
But
again,
since
we're
load,
bombs
can
look
at
none
and
then
there's
also
connection
pooling
in
here,
so
max
connects
per
hosts
seed
host
connection
pool
monitor.
So
this
is
a
great
facility
to
have
again
so
in.
If
you
were
interacting
that
at
a
lower
level,
you
would
have
to
build
a
lot
of
this
connection,
bullying
and
fault
tolerance
on
your
own.
B
So
here
you
can
just
configure
it
with
the
fluent
style
here.
So
these
are
the
key
lines
right
so
once
I've
identified
where
I
want
to
connect,
how
I
want
to
connect
them
by
connection
pool
I
start
off
the
Afghan,
ex-con
techs
and
I
grab
a
key
space
from
it
and
then
what
I
typically
do
is
throw
a
line
in
here
just
to
invoke
a
command
in
the
key
space
which
will
immediately
validate
that
I'm
good
with
the
caption
before
I
go
on.
B
B
The
other
API
is
in
that
the
way
the
API
was
designed
is
pretty
readable
when
you
go
and
interact
with
anything
so
to
change
things
in
Cassandra,
it's
done
through
a
mutation
and
you
can
put
a
batch
of
changes
into
a
single
mutation.
So
that's
what
you
see
have
to
keep
happening
here
so
anytime.
You
want
to
change
something,
go
ahead
and
grab
your
key
space,
but
which
is
just
the
object
from
up
here,
not
to
guess
all
that
access
Iran
it
down
here
key
space
right.
B
So
like
a
key
phase-
and
you
say:
prepare
mutation
batch
now
here,
I
designed
the
signature
of
this
method
to
be
incredibly
flexible
right,
so
I'm,
not
even
taking
a
child
object
at
all.
I
just
take
a
string
and
map
of
string,
strings
and
all
I
need
to
do
is
say:
mutation
wit
row
right
where
you
specify
your
column,
family,
gosh,
state.
B
Sorry
say
this:
I've
got
the
table
name
up
here,
declared
as
a
static
final
strength
that
children
table
that
we
saw
earlier
and
what
I
need
to
tell
Afghan
--ax
is
what
kinds
of
things
are
in
this
table
column
for
the
columns
right.
So
we've
string
serializers
here,
which
basically
just
says
what
the
rows
and
columns
are
in
that
table
and.
D
B
Syria
lies
before
me,
we'll
see
more
about
it,
we'll
see
more
detail
on
that
when
we
get
to
the
composites
okay,
so
this
is
should
be
dead
simple
when
you
look
at
it
right,
it's
just
adding
the
map
of
string
strings
in
as
columns
on
this
row
so
row
and
columns
right
exactly
like
the
way
I
think
about
that
de
tomate
from
the
childhood
perspective.
So,
let's
run
over
and
give
this
a
test
all.
B
C
B
B
C
B
You
go
that's
a
read,
pretty
easy
all
right,
so
let's
go
ahead
and
write,
so
just
for
fun
figure
would
be
fun
to
throw
the
devil
on
the
naughty
list,
but
check
it
out.
This
doesn't
even
conform
to
our
schema.
So
let's
see
what's
going
to
come
on
here,
so
for
the
devil,
if
you
had
known
country,
state
or
zip,
so
I
decided
to
throw
in
plane
of
existence
on
there.
So
let's
run
over
run
that
to
you
into
alright.
So
this
called
the
DAO
that
we
were
just
looking
at.
A
B
B
Look
at
that
it
had
no
problem
in
30
met.
So
what's
crazy,
though
it
look,
plane
of
existence
did
not
get
appended
on
here.
Alright,
so
again,
there's
two
different
views
into
the
system.
Right
now,
one
is
the
cql
view,
which
has
some
metadata
about
what
I
should
be
putting
into
my
table
and
what
it
should
look
like
and
then,
let's
quick
flip
over
to
Sandra,
CLI
again
and
I
still
love
looking
over
here.
Then
this
gives
you
the
real
view
into
how
the
day
is
laid
out
with
these
sports.
B
B
C
B
Know
you're
getting
to
the
future,
so
we
did
not.
You
know
it's
kind
of
interesting
for
me.
Even
you
know,
we've
been
using
the
Cassandra
for
a
couple
years
now
and
within
the
advent
of
cql,
you
get
a
very
scheme
Ashfield
to
Cassandra,
but
it
you
haven't
lost
any
of
you
know:
sequel,
no
schema
power,
especially
from
the
Java
API
perspective.
So
that's
something
to
keep
in
mind.
Okay,
so
just
for
completeness,
let
me
see.
I
have
a
delete
here
so.
C
B
C
C
B
I
won't
get
into
it,
so
you
still
see
the
row
there,
but
it
is.
It
has
no
columns
so
there's
some
behind
the
scenes
up
the
coast
and
and
needs
to
communicate
the
actual
deletion
across
the
clusters.
That's
why
sometimes
it
is
there
okay,
so
that's
the
child
table
now
we're
going
to
get
sort
of
level
up
here,
alright,
so
the
child
table
look
at
that
is
incredibly
straightforward.
B
You
can
see
how
you
could
build
an
app
off
of
that
pretty
easily
now
we're
going
to
get
into
the
fun
stuff,
and
you
saw
that
I
didn't
even
create
a
child
object
to
map
there.
I
don't
need
to,
but
with
the
list
on
the
nicer
naughty
list
table
I'm
going
to
use
a
list,
entry
object
that
maps
to
the
components
in
the
columns
right,
so
that
is
it
the
or
the
columns
in
the
table
right
and
this.
B
B
So
so,
let's
try
and
forget
to
read
in
here
and
get
flipped
over.
So
let's
just
read
all
the
values
in
Nice
USA.
So,
as
you
can
read
the
one
row
see
if
that
works.
Okay,
that's
good!
So
that's
the
read!
So
you
can
see
if
the
exact
same
as
before,
to
Center
to
do
so.
The
read
that's
residual
at
the
back
and
in
the
list.
Entry
Gao
test,
I.
B
Just
have
a
log
again
statement,
but
you
can
see
here
that,
because
it's
typed
and
I
sort
of
like
this
with
SD
on
X
right
I
get
my
actual
object
back.
So
it
does
the
sterilization
into
the
exact
object
that
I
was
going
to
use.
So
it's
pretty
convenient
so
I'm
actually
using
the
object
here
and
topping
the
object.
Now.
This
is
the
fun
part
as
well.
So
here
we're
going
to
do
a
write,
so
we're
going
to
put
Hank
down
into
our
database
and
I
want
to
show
you
an
interesting
effect.
B
And
I'm
doing
tab
completion
here,
it's
nice!
Look
at
that!
That's
terrible!
So
what
happened
there
and
this
descript
me
up.
So
if
we
go
over
to
the
Cassandra
logs
X
having
a
right
index
out
of
bounds
exception
over
in
Cassandra-
and
this
is
the
actual
server
right
and
then
that
manifests
itself
as
a
T
socket
read
zero
bytes
and
it
took
me
except
being
a
wild
first
x,
there's
a
blog
post
on
this!
So
I.
B
If
you
look
here,
there's
no
colon
on
the
end
of
Hank,
the
way
that's
eql
and
then
there's
a
great
but
I
actually
have
the
blog
link
from
there's
a
blog
by
Jonathan
and
another
one
Africa
who
wrote
a
lot
about
the
difference
between
thrift
and
cql,
but
weighted
cql
constructed
this.
Is
it's
ready
to
put
a
data
column
on
the
end
of
here,
so
we
happen
to
construct
the
schema
that
has
no
data
columns,
so
what
we
actually
need
to
go
do
further.
Oh.
B
Yeah,
so
let
me
remove
Hank
real
quick
and
show
you
this
so
now.
Hanks
going
back
over
here,
pull
select
and
I
can
now
select
again,
that's
good,
so
my
tables
back
to
normal
and
what
you
have
to
do
over
on
the
Afghan
excite
is
create
another
ordinal
value
to
support
that
extra
spot
in
the
column
name.
So
so
I'm
going
to
drop
that
in
there
and
then
we're
going
to
write
again.
B
Let's
and
let's
be
ambitious
and
see
if
Hank
comes
up
here,
he
does
so.
You
can
see
I
had
to
actually
support
and
match
the
up
sort.
The
schema
that
I
went
and
creative
with
seat
duo
so
and
I
send
you
to
my
blog
code
to
see
how
that
maps
actually
to
the
data
columns,
specifically
alright,
so
that
was
all
fun.
So
if
we
flip
back
to
the
PowerPoint,
we
now
have.
Oh,
let
me
let
me
finish
that
up
here.
B
If
I
go
back
to
source
test,
Java
list
entry,
I
didn't
do
the
fine
right.
So
this
is
the
actual
important
one.
So
I
want
to
leverage
my
date
at
my
schema
I
date,
a
model
to
perform
a
find
right.
So,
as
I
said
to
you
know,
we
want
to
be
able
to
search
Santa
Claus
once
we
had
a
search
at
varying
levels
of
granularity.
So
what
I
did
is
I
created?
B
This
method
here
called
fine
which
can
take
Roky,
which
just
says
you
know
nice,
kids
in
the
USA,
a
state
and
an
optional,
zip
right,
and
what
I
do
is
I
use
that
serializer
to
use
what's
called
a
range
builder,
to
specify
the
query
I
want.
So,
if
zip
is
null
I,
don't
care
what
the
dip
is.
So
I've
got
a
wide
range
for
zip
and
I'm
just
going
to
specify
state,
but
they
specify
if
they
specify
the
state
and
the
zip,
then
I
want
equal
to
the
zip.
So
you
created.
C
B
Equals
and
less
than
equals
so
going
exactly
so
let's
go
test
this
out
so
other
than
that.
It's
exactly
the
same.
So
you
know
I
do
prepare
query
cat
key
with
column
range
and
I
specify
the
range
that
I
constructed
here.
So
we
flip
over
and
we
do
it
fine
and
you
can
to
first
find
for
all
kids
in
PA.
Then
all
kids
in
the
nine
for
one
on
one
zip.
B
We
look
at
our
data.
We
actually
had
two
in
California,
so
one
in
Pennsylvania,
two
in
California.
Second
query
only
returned
the
one
that
was
relevant
cool,
so
I
think
we
just
fulfilled
both
of
our
our
use
cases
on
trying
to
speed
up
here
a
little
bit
just
to
show
okay
I'm
going
to
do
this.
One
really
quick.
We
have
time
for
questions
I'm,
just
I'm
pretty
excited
about
some
of
this
capability.
B
So
what
if
we
wanted
to
add
on
a
toy
list
for
Santa
right
in
a
relational
world
yeah
that
would
mean
create
another
table,
create
a
joint
able
to
it
for
the
one
to
n.
But
one
of
the
exciting
features
about
cql
three
in
Cassandra
1.2
is
now
we
have
collection,
support
which
is
awesome,
so
you've
got
sets
lists
and
maps
that
you
can
store
in
your
in
your
in
your
tables,
so
I'm
gonna
skip
over
this
bit
and
let's
just
go
dive
right
in
sorry
to
start
going
so
fast.
B
So
what
I
have
here?
What
I
created
is
the
North
Pole
plus
plus
schema
and
check
this
out
so
right
here,
I
changed
just
my
child.
Children
table
to
include
a
attribute
toys
which
is
a
set
of
text,
and
then
you
can
check
to
see
this
down
here.
You're
allowed
to
make
statements
like
update
children,
set
toys,
equal
toys
plus
Legos,
where
child
equals
old
on
you
so
but
some
quickly
blast
that
in
so
I'm
going
to
blow
away
the
schema
and
recreate
it
right.
B
C
B
B
B
The
cql
Java
driver
uses
the
cql
language
to
to
perform
mutations
against
Cassandra,
so
it
has
this
nice
little
syntax
here
that
allows
you
to
build
the
query.
I
think
this
is
called
query
builder.
So
it
looks
you
know
very
similar.
You
know
the
flu
kind
of
style.
Add
toys,
a
toy
where
child
ID
was
the
child
idea
that
I
passing
so
I
could
have
just
issued
the
text
as
well.
B
But
this
is
a
nice
way
to
make
sure
that
you're
building
a
syntactically,
correct
statement,
so
the
actual
method
just
passes
those
two
in
I
log,
both
the
query
and
the
query
builder
those
plans
to
see
that
what
they
look
like
and
how
they're
different
and
to
get
connected
via
cql
driver
you
just
do
a
cluster
builder,
a
cluster
builder.
Add
your
host
call
connect
here,
I'm,
issuing
a
statement
that
says,
use
the
key
space
that
I
want
and
show
this
working.
B
So
in
my
palm
file
down
here,
you'll
see
I
had
to
I
had
to
build
the
Java
driver
locally
and
then
I
included,
I,
don't
know,
I,
don't
know
if
it's
been
released,
so
maybe
repository
or
yet
yeah
or
not.
So,
let
me
say,
add
to
a
Chromebook:
oh
no
Neil
run
as
a
unit
test
boom
and
over
here,
Chromebook
pass.
Look
at
that.
So
again
it
you
know
this
is
partially
style,
so
the
cql
drivers
supposed
to
be
pretty
fast,
I
personally
haven't
done
any
metrics
for
it
yet,
but
going
forward.
B
It
is
going
to
be
the
way
that
you
can
take
advantage
of.
Some
of
these
newer
features
like
operations
on
collections.
To
do
the
same
thing,
I
just
demonstrated
with
the
cql
driver
against
in
one
of
the
other
api's.
I
think
it
is
possible,
but
basically
you
have
to
go
through
the
thrift,
cql
layer
in
hectare
or
a
ski
annex
and
basically
specify
teague
all
through
there.
So
you
know
so
this
is
this
sort
of
wherever
you
are
on
your
development.
You
want
to.
You
know
your
development
timeline.
You
want
to
start
paying
attention.
B
The
cql
Java
driver,
because
I
think
that's
that's
where
things
are
going
eventually,
the
Java
API
is,
will
probably
move
off
a
thrift,
but
probably
not
for
a
long
time.
But
if
you
want
some
of
the
cutting-edge
capability
CQL
way
to
go
right,
okay,
I
think.
Let
me
just
summarize
here
real
quick
Oh,
some
shameless
shoutouts
I
think
I
mentioned
so
we've
contributed
here
at
health
market
times.
We
do
a
lot
of
open
source
stuff,
so
we've
done
a
a
Cassandra
rest
interface
for
Cassandra.
That
also
originally
included
some
MapReduce
capabilities.
B
If
anyone
wants
to
get
involved,
I
love,
we'd,
love
some
help
on
on
Virgil.
You
can
see
it
out
there.
We
also
we
use
storm
here
on
top
of
Cassandra,
we
use
digital,
so
we
used
to
have
MapReduce
capability.
Who's
actually
switched
entirely
over
to
storm
almond,
I'll
be
doing
a
webinar
on
storm
and
Cassandra
in
January.
So
you
can
see
our
storm.
Cassandra
bolt
is
out
there
as
well,
so
I
think.
That's
it
for
me.
B
C
A
Great,
we
do
have
some
questions.
We've
got
about
eight
minutes
left,
so
let's
see
how
many
we
can
get
through
Oh.
The
question
is:
all
arms
are
by
where
I
like
softball
questions.
When
will
the
recording
be
available
and
other
slides
available
from
today's
presentation,
as
you
saw
that
one
too
many
slides,
but
we
will
have
this
presentation
available
within
24
hours
and
you
will
have
an
email
notifying
you
of
that?
B
Yeah,
it's
a
great
question.
So,
to
be
honest,
the
suit
I
know
super
column
should
I
do
okay.
The
funny
thing
is
one
of
the
reasons
that
we
chose.
Cassandra
is
because
super
columns
were
there
way
back
when,
but
I
think
composites
eliminates
the
need
for
super
columns,
and
the
recommendation
is
typically
do
not
use
super
columns.
D
B
A
B
So
I
I
have
not
used
it.
So
oh
yeah
I
have
not
used
that
stuff,
I
believe
it's
there,
so
we've
always
gone.
We
go
one
of
two
ways
right
so
with
Hector.
We
do
not
have
objects
so
or
do
any
object.
Mapping
so,
but
I
know
there
is
a
hibernate
object,
mapping
out
there
and
then
with
asti
annex
we
use
the
fluid
style
with
mapped
objects.
So
I'm
not
exactly
sure
what
kind
of
templating
capabilities.
A
B
That's
a
great
question:
let
me
think
about
that.
I
I,
don't
think
so.
To
be
honest,
so
now
with
that
said,
the
you
know
the
thrift
API
that
is
out
there
is
Java
and
that's
what
a
lot
of
people
build
on,
but
so
so
with
Virgil
our
rest
interface.
We
actually
have
some
Ruby
apps
out
there.
They
come
Virgil
and
they're
there.
You
know
just
as
good
so
I
can't
think
of
I.
Don't
think
the
performance
would
be
a
reason,
so
I
can't
think
of
any
advantage.
A
Yeah
and
actually
I'm
going
to
give
a
little
plug
right.
Now,
it's
not
available
as
of
this
moment,
but
on
Monday
we
are
pushing
lives,
the
new
planet,
Cassandra,
dot,
org
community
site
and
what
we're
trying
to
do
that
is
centralize
all
of
these
great
resources
around
Cassandra
in
one
spot.
So
there
is
actually
pretty
nice
and
expensive
Client
driver
library
on
that
we're
trying
to
keep
track
of
know
all
the
new
stuff.
That's
coming
as
well.
Yep,
perfect,
okay!
Well,
we
are
right
at
the
top
of
the
out,
I
mean.
A
Let
me
take
a
quick
look
down
so
upcoming
webinars
there's,
actually
one
that
we're
having
on
this
before
Brian's
next
webinar,
which
he
talks
about,
which
is,
you
know,
a
streaming
topic
CEP
distributed
processing
on
Cassandra
with
storm
we
so
the
Apache
foundation.
The
vote
is
underway
right
now
on
when
Cassandra
1.2
will
be
available
to
the
community
and
its
its
launches
imminent,
we're
expecting
by
the
end
of
the
year.
So
Jonathan
Ellis,
who
is
the
chair
of
the
cassandra
project,
will
be
doing
a
webinar.