►
Description
Apache Cassandra Project Chair, Jonathan Ellis, looks at all the great improvements in Cassandra 1.2, including Vnodes, Parallel Leveled Compaction, Collections, Atomic Batches and CQL3.
A
Wanted
to
talk
about
feature
that
little
bit
of
a
makeup
for
1
dot
1
wherein
contender
one
got
one.
We
added
support
or
concurrent
schema
changes,
but
arguably
the
most
important
one
of
all
we
didn't
address,
which
is
that
in
one
dot
one
you
can
concurrently,
you
can
have
multiple
clients
altering
your
schema
across
your
cluster,
except
that
you
can't
create
column,
families
or
cables
safely.
Concurrently,
so
you
can
alter
them,
you
could
add
columns,
you
could
add
indexes
and
so
forth.
A
You
can
do
that
in
parallel
in
one
dot
one,
but
not
the
actual
creation
of
the
table.
Definition
itself
so
in
one
got
to
wee-wee
address
that.
Finally,
and
so
you
can
programmatically
I've
gave
and
drop
table
for
temporary
page
or,
if
you're,
using
a
table
per
customer
kind
of
model
that
was
totally
okay
because
I
programmatically.
A
Now
the
next
big
thing
in
one
got
to
that
that
doesn't
tie
into
the
bat
mood
support
that
is
useful
to
everyone,
not
just
people
running
on
large
servers,
it's
virtual
nodes,
so
historically,
we've
had
a
one
token
/,
commander
server
model
in
our
in
our
consistent
hashing
partitioning.
So
in
this
example,
I
have
the
note
F
colored
red
here
has
one
token
assign
to
it
and
virtual
nodes.
What
we're
going
to
do
is
they're
going
to
split
that.
A
You
can
increase
that,
if
you
need
to,
you
can
even
have
different
nodes
in
the
cluster
have
different
amount
of
virtual
nodes
which
can
help
you.
If
you
have
a
heterogeneous
hardware
in
your
cluster,
so
you
can
give
newer
more
powerful,
no
more
powerful
machines.
You
can
give
them
more
virtual
mode.
They'll
take
more
of
the
load
from
your
Buster.
That
way
about
in
this
is
glad
I've,
just
colored
in
three
virtual
nodes
to
give
you
the
idea.
So
the
problem
that
is
solved
is
that
it
allows.
A
Even
allows
operations
to
be
distributed
across
the
cluster
in
a
more
fine-grained
kind
of
wave,
so
in
particular,
there's
a
couple
places
that
isn't
particularly
important,
which
are
adding
mission
to
the
cluster
or
replacing
them.
If
you
have
a
failure.
So
let's
look
at
the
state
of
your
case
where
I
have
a
cluster
and
then
one
of
my
machines
dies
and
it's
not
just
a
bad
power
supply
or
something
that
that
I
can
replace
in
English.
A
I've
actually
catastrophic,
we
lost
all
the
data
is
on
that
machine
and
I
need
to
rebuild
it.
So
in
the
Canary,
oh,
where
you
have
one
token
for
machine
in
contender,
one
dot
one
and
earlier
you
can
rebuild
that
den
machine
from
it
appears
in
the
cluster
that
that
is
replicated
to
so,
and
it
is
commonly
the
case.
In
this
example,
we
have
each
range
of
data
is
replicated
to
me.
A
Machines
in
the
cluster
so
notify,
which
is
our
dead
machine,
had
ranges
C,
D
and
E,
and
you
can
see
which
those
share-
those
two
choices
for
each
range
that
it's
replicated
to.
So
what
that
means
is
you
for
each
of
those
ranges
we
can
stream
it
from.
It
appears
in
the
cluster
concurrently,
meaning
that
and
a
weekend
can
rebuild
range
fee
and
rinse
Jian
Ren
GE
in
parallel,
but
we
don't
get
the
benefit
of
the
entire
cluster.
A
In
other
words,
in
this
example,
I
I
have
fifty
percent
of
my
cluster
participating
in
the
rebuild,
because
I
have
three
ranges
to
screen
and
six
nodes
in
the
cluster,
but
as
the
cluster
size
grows.
If
I
have
a
no,
the
cluster
and
I
am
only
using
three
percent
of
that
cluster
capacity
to
do
the
rebuild
so
if
I
can
spread
it
out
and
right
across
the
entire
cluster
that
my
rebuild
is
going
to
happen,
that
much
faster
and
we'll
get
it
over
with
now
much
better.
A
So
when
we
parallel
eyes
this
with
virtual
nodes-
and
you
can
see
even
in
this
simple
example
of
only
three
virtual
nodes
per
machine-
I'm
already
able
to
parallel
eyes
that
rebuild
across
the
entire
cluster,
because
those
ranges
that
I'm
assigning
to
the
different
replicas
are
so
much
smaller
and
more
fine-grain.
That
I
can
have
everyone
participate
in
it.
So
then
that's
the
the
main
idea
I'll
be
no!
It's
not
about
extra
performance
really
in
terms
of
what
your
clients
are
doing
of,
reading
and
writing
data
to
your
tables
and
Cassandra.
A
A
I've
configured
it
across
the
cluster
so
in
having
to
continue
raid
on
each
machine
to
replicate
that
locally
as
well.
Now,
that's
wasting
fifty
percent
of
my
business
days.
So,
if
I
just
want
to
be
a
larger
scale,
we're
close
where
I've
got
a
large
amount
of
relatively
cold
data
for
machine
and
I
want
to
make
the
most
cost
effective
use
of
my
hardware.
What
I
really
want
to
do
is
they
want
to?
A
A
When,
when
I
do
have
this
face,
it
failed
in
prior
releases
pretend
to
really
didn't
know
how
to
detect
that,
and
it
would
keep
on
trying
to
write
new
data
to
a
failed
disk,
and
it
would
just
cause
problems
in
your
cluster
until
we
disabled
that
machine
and
took
it
out
and
fix
it
assuming
you
didn't,
have
raised
going
on
to
it
to
hide
that
finger
from
it.
So
what
we
did
and
went
on
to
is
we
added
this
failure,
policies
and
the
ability
to
recognize
this
face
to
Cassandra.
A
But
if
you
have,
if
you
care
more
about
availability
than
inconsistency
and
that
option
is
there
for
you
to
go
ahead
and
black
with
it
keep
running
when
the
next
feature
that
we
worked
on
for
the
at
node
support
is
to
move
a
bunch
of
our
storage
engine
internals
off
of
the
Java
heat.
So
what
that's
about
is
the
amount
of
memory
we
have
available
on.
The
servers
has
by
and
large
kept
pace
with
the
amount
of
disk
space
that
we're
trying
to
address.
So
it's
not
really
a
problem
per
se
that
we
have.
A
The
internal
structures
of
the
storage
engine
that
require
memory
proportional
to
the
bit
of
space
use.
That's
not
that's,
not
really
a
problem
by
itself.
The
problem
is
that
we've
had
all
those
structures
on
the
Java
heat
and
the
Java
sheep,
or,
more
specifically,
the
job
of
garbage
collector,
has
not
kept
pace
with
the
growth
of
memory
in
which
is
to
say
that
Java
heaps
are
basically
stuck
at
about
eight
gigabytes.
A
To
maybe
up
to
16
is
the
largest
you
can
make
the
Java
heat
before
the
garbage
collector
pause
times
start
getting
large
enough
to
affect
your
application
in
a
bad
way.
So
what
we
want
to
do
is
we
want
to
take
those
structures
that
we
have
and
move
them
into
native
memory
off
of
the
heap
where
we
can
clean
them
up
using
manual
reference
counting
instead
of
relying
on
the
Java
a
garbage
collector
to
do
it
so
that.
B
A
B
A
So
this
is
the
main
feature
related
to
application
development
that
isn't
cql
specific.
So
what
we're
doing
is
we're
taking
the
concept
of
Katanga
batches
that
we've
had
for
forever
and
were
we're
making
them
on
another
level
more
robust
by
by
adding
support
for
atomic
batches.
So
as
a
review,
a
contender
batches
are
sort
of
the
analog
to
a
transaction
in
Japan
er
the
differences
that
the
transaction.
A
You
have
a
bunch
of
steps
that
happen
sequentially
and
at
any
point
you
have
the
option
to
will
that
that
transaction
and
say
nevermind,
you
know
I
ran
into
a
deadlock
or
I
all
right.
Someone
else
modify
this
data
out
from
under
me,
so
I
had
to
abort.
If
you
have
that
ability
to
roll
back
that
transaction
Cassandra
ventures
are
always
they
only
go
in
one
direction.
You
give
it
the
entire
batch
of
one
and
customer
says
okay
I'm
going
to
make
this
happen.
A
So
in
this
there's
no
concept
of
rollback,
there's
just
the
concept
up,
there's
a
bunch
of
updates
that
I
need
you
to
make
happen
all
all
together.
So
those
of
those
updates
that
you
did
contender
in
the
batch
or
still
individual
grows
changes
that
you
want
to
make
to
those,
but
I've
represented
those
on
this
slide
as
three
different
colors
of
red,
yellow
and
blue,
and
so
those
different
rows
in
the
back
are
ultimately
going
to
live
on
different
replica.
So
the
coordinators
will
know
that
the
Cassandra
client
is
talking
to.
A
You
is
responsible
for
keeping
those
out
to
the
appropriate
replica,
and
the
problem
is
with
these
classic
matches
is
if
I
am
a
batch
like
this,
and
then
the
coordinator
itself
failed
before
it
completes
sending
out
that
back
then
I
have
I
basically
created
another
inconsistent
scenario
in
my
cluster.
What
we
said
in
the
past
is
that
the
climate
is
now
responsible
for
reconnecting
to
a
different
coordinator
and
retrack
that
back
to
deal
with
that
coordinated
failure,
but
that's
the
wrong
solution.
A
A
If
you
want
a
non-atomic
batch,
if
you
want
the
old
behavior,
you
actually
have
to
say
he
can
unlock
back
and-
and
that
will
be
the
OPA
here,
which
is
there's
about
a
spirited
recent
performance
overhead
to
the
atomic
bachelor.
So
if
you're
a
one
hundred
percent
certain
that
it's
okay,
if
you
get
partial,
match
completion
or
for
whatever
reason,
you're
okay
with
that,
then
yeah,
you
do
have
the
option
to
fall
back
to
the
old
behavior
and
get
that
slight
performance
edge.
A
But
in
the
general
case
you
think
that
it's
more
important
to
do
the
surviving
by
default
the
spacing
by
default.
So
we
made
atomic
behaviour
of
people
in
CTL.
Now
we
didn't
really
have
that
option
for
the
thrift
API.
So
what
we
did
was
we
added
a
separate
switch
next
method,
so
you
have
a
vacuum.
You
take
method
for
the
old
behavior
and
we
added
a
new
atomic
batch
mutate
for
the
new
baby
here.
A
So
those
of
you
using
a
rift,
client
or
script
based
clients
will
want
to
be
aware
of
that
and
how
those
different
clients
to
decide
to
expose
that
delivering
this
to
the
c
ql
updates
that
we've
done
in
19
2-
and
this
is
this-
is
where
we've
really
gotten
a
handle.
I
think,
on
the
common
pain
points
that
people
have
was
doing.
A
Data
modeling
with
we
basically
been
exposing
the
contenders,
storage
engine
more
or
less
directly
to
people
and
saying
here,
make
sense
of
this
and
write
your
ass
so
that
it
makes
sense,
pretender,
storage
engine,
and
you
know
that
we've
been
reasonably
successful
with
that
approach,
but
I
think
long
term
that
we
don't
want
to
do
that.
We
want.
A
So
to
do
this,
we've
done
a
couple
things
we
fleshed
out
the
support
we
had
for
compound
primary
key
and
mapping,
user-facing
tables
to
storage
engine
column,
families
under
the
hood
with
that,
and
then
we've
also
added
new
features
like
collections
to
allow
you
to
more
easily
handle
common
scenarios
of
the
normalization
in
your
application.
Growth.
A
A
Need
you
to
partition
alee
I,
don't
need
particularly
to
partition
in
any
particular
order.
So
this
is
a
really
simple
example
that
we've
been
able
to
do
for
a
while,
and
what
I'm
going
to
do
now
is
talk
about
how
Linda
to
you
know
we're
not
fundamentally
changing
what
Cassandra
does
I'm
not
trying
to
make
it
more
of
an
SQL
we're
not
going
into
joins
or
anything
like
that,
what
we
are
making
it
able
to
exposed
Cassandra's
strength
in
a
way
that
makes
more
sense
so
to
talk
about
that.
A
I
want
to
give
an
example
of
a
song
and
playlist
manager
and
show
how
we
go
from
the
thrift
and
command
line
based
schema
to
c
ql.
Three
base
schema
into
fender
one
dot
too.
So
there
was
the
first
column
family
or
table
that
we're
going
to
talk
about
is
just
a
song
data
itself.
So
this
is
what
the
definition
looks
like
if
you're
defining
it
with
the
script
based
command
line.
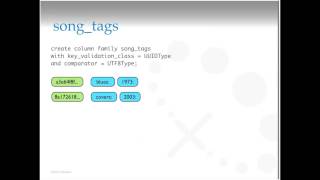
A
So
if
they
create
called
family
song,
I
give
it
a
key
validation,
class
I
colored
the
keys
light
green
on
this
lighted
show
them
that
distinct
from
the
column,
data
and
then
I,
give
it
a
comparator
and
then
for
each
column,
I
give
it
a
column,
meta
data
entry
with
the
name
and
a
validation
class.
So
okay,
so
this
is
still
fairly
straightforward.
A
It's
kind
of
verbose
and
a
little
bit
clunky
to
remember
this
intact,
but
it's
very
straightforward
and
mapping
bad
to
c
ql
is
also
straightforward,
so
this
become
create
table
song.
I
have
a
uuid
primary
key
and
then
I
have
some
columns
to
find
and
I
flips
data
off,
because
that's
just
a
binary
blob
I
don't
want
to
put
three
megabytes
of
data
on
the
fly,
but
but
the
other
three
columns
will
represented
here.
A
You
know
the
Phils
are,
are
defined,
sparsely
so
with
each
so
I
have
to
repeat
I,
have
title
and
and
for
each
title
fill
and
then
I
specify
artist
for
each
article
and
I
have
repeat
that
in
my
in
my
storage
engine
self.
So
when
we,
when
we
move
to
the
the
CTL
representation
now
does
this
looks
a
lot
more
familiar
because
we
have
the
night.
A
Where
is
where
things
start
to
get
more
interesting
when
I
start
talking
about
how,
in
c
ql,
you
define
your
columns
up
front
and
people
who
are
familiar
with
with
earlier
versions
of
Cassandra,
you
know
we
starting
to
get
worried,
isn't
any
well,
you
are
you
going
to
take
my
dynamic
columns
away
from
me?
No,
but
we're
not
doing
that
we're
just
helping
you
represent
them
in
a
more
straightforward
fashion.
A
Class
and
a
comparator,
so
this
is
an
example
of
what
we
used
to
call
dynamic
column.
Family
I,
don't
have
any
column
metadata
specified
because
each
of
my
fellow
peer
is
going
to
have.
You
know
a
name,
the
determinant
runtime
that
whatever
the
application
decides
to
insert
so
my
still
name
and
my
column
name
and
at
a
user
level,
are
not
going
to
chorus
on
121
anymore.
So
here's
an
example
of
some
data
there
where,
for.
A
B
A
So
this
is
this
is
the
part
where,
where
your
brain
explodes
a
little
bit,
and
so,
if
then
you're
in
really
good
shape.
So
what
how
we
mapped
is
to
a
table
in
c
ql.
Three
looks
something
like
this:
where,
where
we're
going
to
go
ahead
and
they
create
tables
on
tags
and
we're
going
to
give
it
the
ID
for
the
key
and
the
tag
name,
is
it's
going
to
be
our
under
column?.
A
So
you
can
see
that
that
the
a36
of
uuid,
we
had
a
single
storage
engine
row
that
becomes
multiple
rows
that
are
exposed
in
the
c
ql
results
back.
In
fact,
we
have
one
row
per
storage,
engine
self
and
the
storage
engine
cell
name
become
the
tag
name
value
in
the
particular
result,
set
representation,
and
so
note
that
I
color
I
put
an
orange
box
around
the
part
that
that
correspond
here,
fixed
X
of
parts
to
go
together.
So
basically
what
the
teachable
partition
that
we're
going
to
guarantee
all
goes
to
the
same
server.
A
So
you
can.
You
can
fetch
it
efficiently
all
that
colored
morning,
so
we've
taken
that
one
orange
storage
engine
row
and
we
split
it
up
into
those
two
rows
and
the
PQ
result
back
and
and
I
still
blocked
them
in
in
orange
suppose
to
show
the
password
those
are
coming
from
it's
coming
from
the
same
same
storage
partition
now.
One
thing
that
does
come
up
is:
can
I
again
have
a
partition
key?
That
is
itself
composed
of
multiple
columns,
and
the
answer
is
yes,
you
can
do
you
use
parentheses
to
denote
that
this?
A
The
take
home
message
from
that
is
that,
in
moving
to
this
representation
in
CTL,
free
and
we've
been
very
careful
to
make
sure
that
we're
not
actually
losing
any
functionality.
So
if,
at
any
point
in
this,
you
get
the
impression
that
is
hey,
it
looks
like
I
can't
do
something
that
I
used
to
be
able
to
do
from
thrift.
Then
it's
probably
my
fault
for
explaining
it
poorly
because
that's
that's
been
our
goal.
The
whole
way
through
to
make
sure
we're
not
losing
any
functionality.
A
If
the
storage
engine
layer
and
not
having
to
be
right
any
existing
data,
which
is
what
you
had
to
do,
if
you
were
taking
the
JSON
blob
approach
in
prior
releases,
so
the
last
example
I
wanted
to
talk
about
here
was
the
playlist
themselves.
So
the
way
we
do
that
in
the
thrift
world
is
we're
going
to
say
them
each
song
in
a
playlist.
It's
going
to
be
this
composite
column,
where
the
cult,
though
the
cell
name,
is
composed
of
the
different
pieces
of
data
that
we
want
to
track
for
that
song.
A
So
that's
what
we
that's!
What
we've
got
here
where
of
the
comparator,
is
a
composite
type
of
three
utf-8
components,
and
so
were
11
of
those
components
is
the
title:
one
is
the
artist
and
one
is
the
album,
so
that
doesn't.
How
does
that
tell
those
map
to
that
to
that
storage
engine
row
so
the
way
we
we
map
this
to
the
situa
world
is
similar
to
how
we
did
it
with
the
song
tag.
We're
going
to
have
a
compound
primary
key.
A
A
A
Alright,
so
moving
along,
if
you
do
have
questions
about
it,
then
we
can
still
take
them
at
the
end,
with
with
everything
else,
there's
one
more
B's
about
the
cql
mapping
of
table
to
storage
engine
column
family
that's
worth
discussing,
and
that
is
that
how
the
healthy
jewelz
I
exposes
the
comparator.
So
the
comparator
is
what
we
use
to
with
these
dynamic
column
family.
To
make
sure
we
give
the
results
back
in
the
orders
in
the
application
monster
math.
So.
B
A
So
CG
well
is
a
query
language
that
kind
of
transport
agnostic.
So
you
can
query,
you
can
perform
sequel
queries
over
thrift
know,
there's
an
execute
cql.
Three,
a
query
method
is
rip
that
most
of
the
existing
and
use
to
access
each
well,
we've
also
added
4
1
dot
to
native
cql
protocol,
but
you
know
part
of
the
upgrade
path
that
we
want
to
provide.
A
Yet
we
don't
want
you
to
have
to
rewrite
your
entire
application
on
top
of
a
new-
protocol
clients
to
access
any
of
this,
so
there's
definitely
the
potential
for
a
gentle
upgrade
path
by
continuing
to
use
the
thrift
API
in
your
clients
that
you
that
your
application
is
built
on
and
then
adding
new
features
didn't
teach
well.
If
that
makes
sense
and
clamps
like
Hector
on
the
Java
side,
picasa
on
the
python
side
are
taking
that
approach
of
exposing
methods
to
perform.
Tql
queries
from
basically
a
great
debate.
A
Now
it's
also
worth
pointing
out
that
the
ability
to
access
data
that
was
created
in
one
way
or
the
other
is
bi-directional
so
I've
been
talking
about
here.
How
each
will
is
basically
able
to
access
data
that
was
created
from
thrift,
so
in
any
of
these
examples,
I,
for
instance,
this
one
I-
can
actually
pull
data
out
of
this
column
family
with
from
a
tql
query
without
having
to
go
through
and
do
this
create
table.
A
So
if
I
already
have
this
column,
family
defined
I
can
go
and
pick
you
Ellen,
please
select
start
from
playlist
and
what
catendra
will
do
is
it
will
assign
column
names
to
the
different
composite
component?
So
you'll
get
it
back
with
column,
one
column
two
and
calm
3
instead
of
artist
title
and
album,
and
then
you
can
go
ahead
in
and
say,
alter
table,
playlist,
rename
column
one
to
Tyler
and
rename
column,
two
artist
and
and
yeah.
A
You
can
give
cql
that
extra
metadata
without
having
to
do
any
rewriting
of
of
your
data
on
disk
and
you
can
you
can
access
things
the
other
way
as
well.
If
I
create
this
playlist
table,
I
can
still
access
that
data
from
Frick.
If
I
understand
how
that's
mapped
to
the
storage
engine
under
the
hood
and
playing
around
with
the
command
line
interface
can
help.
A
Alright,
so
the
last
piece
of
this
bubble
is
how
does
have
a
cql
handle
of
exposing
the
comparator
and
orderly
rows
to
the
c
ql
world
ordering
rows
within
that
partition?
So
in
the
playlist
example-
and
we
didn't
particularly
care
about
what
order
are
songs
are
stored
in
and
not
sure
that
maybe
we
could
store
them
in
chronological
order
or
something
but
I.
Think
of
that
an
example
that
makes
a
little
more
sense
intuitively
is
to
talk
about.
A
You
know
something
like
Twitter
or
something
like
Facebook,
where
I'm
following
my
friends
and
I,
want
to
see
their
updates
on
in
some
kind
of
chronological
order.
So
there's
an
example
of
a
way:
I
could
store
a
Twitter
timeline,
meaning
the
tweets
that
my
friends
have
made
in
Cassandra.
So
I'll
have
a
table
timeline
I'll
have
user
ID!
That's
me:
that's
the
person
whose
whose
friends
tweets
were
tracking
here
and
then
we'll
have
tea,
tidy
and
tweet
author
and
three
body
for
each
tweet.
A
So
the
tweet
author
is
the
person
the
tweet
and
then
user
ID
is
the
person
who's
following
him
here.
So
what
I
wanted
to
do
is
I
want
to
get
a
list
of
all
the
tweets
of
people
that
drift
X
is
following
and
I
want
to
give
those
in
chronological
order.
So
what
I
do
is
in
my
compound
primary
key
definition:
the
user
ID.
That's
my
partition
key,
that's
the
first
entry,
but
then
any
other
component.
It
needs
of
different
components
of
the
primary
key.
A
Those
are
going
to
get
turned
into
the
comparator,
so
I'm
by
having
this
user
any
combat
creed,
IV
primary
key
definition,
I'm,
saying
that
within
the
user
ID
partition
tweets
should
be
sorted
by
Pete
ID
and
since
I've
been
fine
tweet.
I
need
to
get
time
basic
UI
the
aversion
one
user
ID.
Then
I'm
going
to
get
those
in
chronological
order.
So
when
I
say
the
leg
start
from
timeline
where
user
ID
is
with
sex,
I
get
that
back
in
chronological
order,
don't
have
to
do
any
work.
A
A
A
Alright,
so
switching
gears
just
a
little
bit,
but
still
in
the
realm
of
what
we've
done,
will
teach
you
well
we're
moving
towards
exposing
more
of
the
information
cassandra
has
about
itself
through,
seek
you
out
so
there's
a
couple
categories
of
information
that
we
have.
The
first
one
is
about
the
schema
and
the
table,
definitions
that
we
have
and
then
the
other
is
more
about.
You
know
what
other
nodes
are
in
the
cluster
and
look
like
know
about
them
so
for
the
fritter
on.
A
So
all
of
these,
by
the
way
all
of
these
are
going
to
be
in
the
system
key
space.
So
that
is
that's
where
I'm
doing
these
queer
example.
So
for
the
schema,
we
have
three
tables
in
the
schema
cubase
that
deal
with
the
schema
information.
So
the
first
is
scheme
on
this
quirky
basis,
and
that
looks
like
it's
very,
very
simple,
a
number
of
pieces
of
data
about
each
key
stage
that
we
have
defined.
A
We
also
have
schema,
underscore
column,
families
and
schema
underscore
columns.
I
won't
show
example,
data
for
those
because
there's
a
lot
more
columns
in
each
of
them,
but
that's
where
that
data
about
about
the
tables
you
define
this
store
now.
One
other
thing
that's
worth
pointing
out
here
about
that
strategy,
options
and
other
places
where
we
have
kind
of
a
set
of
options
in
the
schema,
for
instance,
with
compression
options
for
compaction
options,
all
of
which
are
per
column
families.
A
We
change
those
to
be
max
now
that
we
have
this
native
mac
data
type
to
do
that
written
contender,
so
the
syntax
has
changed
a
little
bit.
So
is
the
way
you
would
define
that
now
is
with
the
mass
syntax
of
curly
braces
and
calling.
But
when
you
see
in
defying
the
restate
coming
back
in
this
query
here,
rather
than
with
the
old
kind
of
ad
hoc
colon
delimited
option
impact
from
one
that
one
and
earlier.
A
Then
the
information
that
we
have
about
the
cluster
itself,
we
have
two
tables
for
that.
We
have
the
local
table,
which
is
about
the
the
notice.
Are
the
machine
itself
says
that
we're
talking
to
and
then
with
a
slightly
of
dinner
table
is
the
peers
table,
which
is
everyone
in
the
cluster?
What
do
I
know
about
them?
Do
you
consume
the
period
table?
We
know
what
their
network
address
is
what
schema
version
based.
They
know
about
what
data
center
and
rach
they're
in
and
out
and
their
token,
but
you'll
know
because
of
the
virtual
nodes.
A
B
A
The
other
thing
I
wanted
to
point
out
here
is
that
this
gives
you
everything
you
need
to
know
about
how
Cassandra
route
your
data,
the
different
replicas
in
the
cluster,
so
in
the
local
table,
I
store
what
partitioner
I
have
in
the
key
phases
table
I
store
what
replication
strategy
on
using
and
then
in
the
pier
table.
I
also
have
the
data
center
in
rack
for
each
machine
in
the
cluster.
A
So,
given
those
pieces
of
information,
a
client
can
actually
determine
for
a
row
that
it
wants
to
queries
where
that
role
lives
in
the
cluster
and
use
a
connection
pool
to
connect
to
a
node
directly
that
has
that
data
locally,
rather
than
going
over
an
extra
hawk
through
a
coordinator
that
doesn't
have
a
data
locally.
So
a
hectare
of
existing
class
SD
annex
plans
like
that
I'll
like
to
do
this
already
and
so
again,
our
goal
with
cql
is
to
give
you
all
the
functionality
that
you
have
exposed,
no
more
happy.
A
So
the
train
starts
off
in
blue,
that's
the
coordinator
and
talking
to
from
the
secure
shell,
it's
the
127
00
that
one
and
then
it's
going
to
the
coordinators,
send
that
request
to
a
replica
node
in
the
cluster
that
dot
to
and
that's
colored
in
red,
and
then
the
replica
machine
ascends
the
replied
back
to
the
coordinator
back
in
blue,
which
will
then
give
it
back
to
jook
eul
shell,
that's
kind
of
the
life
cycle
of
the
request
of
a
very
simple
request
here.
Now.
A
If
I
wanted
to
do
this
from
thrift,
what
I
need
to
do
is
is
I
need
to
call
the
trace
next
query
method:
that
and
then
the
sender
will
collect
the
treating
data
into
the
system,
underscore
traces
TP,
and
then
you
can
pull
it
back
from
that
programmatically
if
you're
not
doing
this
from
situation,
but
I
wanted
to
give
an
example
of
how
this
can
be
useful.
One
kind
of
common
anti-pattern
that
people
come
up
with
when
they're
first
exposed
to
the
sender
is
hey.
I've,
got
a
data
partitioning
and
ordering
within
that
partition.
A
A
Rather
than
having
that
that
mission,
the
mists
of
the
week
replay
the
original
data
backed
up
and
have
it
reappear,
which
we
don't
want,
so
what
I've
represented
that
on
this
slide
as
striking
out
the
deleted
entries
so
they're
still
there
in
the
sense
that
we
have
a
tombstone
saying
that
this
entry
doesn't
exist
is
more.
But
if
I
do
a
select
query
from
it,
then
they
won't
be
included
in
the
results
because
they
can
delete
it.
A
So
if
I
go
ahead
and
insert
a
hundred
thousand
entries
into
this
cube
and
and
then
delete
all
of
them
and
then
I
go
ahead
and
run
my
select
next
entry
from
the
head
of
the
cube,
which
is
which
is
this
query,
the
top
here
then
yeah,
you
know
what
you
will
see
it
and
the
number
of
injuries
in
your
cube
that
you
injure
them
to
leave
it.
As
that
number
increases,
your
query,
slows
down
and
requests
rating.
Show
you
what
the
what
the
problem
is.
A
B
Has
thank
you
very
much,
so
we
have
about
10
minutes
and
we've
got
some
questions
coming
in.
If
you
would
like
to
ask
jonathan
a
question,
please
go
to
the
Q&A
tab
in
WebEx
and
type
your
question
there.
I'll
read
them
out
to
Jonathan
and
we'll
try
to
get
through
as
many
as
we
can
in
10
minutes.
So
let's
get
cracking
the
first
one
that
from
Jerry
this
one
is
regarding
vinodh
with
vino
support.
Can
we
reboot
n
is
greater
than
our
F
number
of
nodes
at
the
same
time
safely?
A
That's
a
good
question
and
you
know,
is
basically
separate
from
your
replication
factors,
so
you're
still
going
to
have
the
same
number
of
replicas
across
the
cluster.
The
difference
is
that,
instead
of
having,
instead
of
having
the
same
three
or
so
node
replicating
all
of
your
data,
as
you
respond
to
all
of
a
given
range
of
data,
we're
splitting
that
range
up
into
much
smaller
pieces
and
scattering
those
across
the
cluster.
A
So
instead
of
having,
instead
of
sharing
data
with
Reno's
you're
sharing
data
with
the
entire
cluster,
but
each
each
other
member
has
a
much
smaller
piece
that
it
shares
with
you.
But
the
number
of
replicas
you
have
total
is
the
same,
and
so
the
guidance
on
you
can't
lose
more
than
one
machine
and
still
be
able
to
do.
Coronaries
with
replicas
is
unchanged.
B
Great
I
can
take
the
next
question:
I
love
it.
When
I
can
answer
a
question,
this
is
from
Kevin.
Is
this
webinar
available
for
viewing
later?
Yes,
it
is
all
of
our
webinars
are
available
for
viewing
both
from
the
base
tax
com
website
and
also
from
the
new
community
website,
planet
Cassandra
org.
We
try
to
get
the
archives
up
and
posted
within
24
hours
and
we
will
email
you
when
the
archive
is
available.
B
A
So
them
we've
actually
explored
that
we've
actually
explored
moving
them
tables
occup
as
well.
The
problem
is
that
the
reference
counting
we
need
to
do
for
that
gets
really
really
hairy,
because
what
we,
what
we
want
to
be
able
to
do
is
we
want
to
be
able
to
free
that
memory
up
as
soon
as
it's
flushed,
but
if
we
have
a
client
requests
that
is
using
that
memory,
because
it
was,
it
was
accessing
that
name
table.
A
B
A
Just
because
of
the
way
the
cocodes
organized
and
how
that
works
out,
excuse
me
that's
a
pretty
hairy
thing
to
tackle,
and
so
what
we've
done
instead
is,
when
you
add
data
to
a
compounding,
it
goes
into
the
mem
table.
We
actually
copy
that
into
a
large
byte
buffer
that
are
allocate
one
megabyte
size,
byte
buffers
and
then
copy
your
your
data
into
those.
A
So
we're
basically
doing
arena
allocation
within
the
data
Yale
and
what
happens
is
those
of
the
arena
that
we've
created
the
mega
byte
size
buffers
those
gay
tenured
fairly
quickly,
so
they
don't
interfere
with
your
car.
Do
many
more
after
a
few
minutes
of
being
up
and
active.
So,
ideally,
I
would
like
to
cut
the
cheese
book
for
it
even
further
by
moving
those
of
you
that
I
think
will
we
is
what
we're
doing
is
a
good
compromise
between
complexity
of
implementation.
Ok,.
A
So,
let's
feel
are
basically
the
only
hint
you
need
to
know
is
that
you
need.
You
want
to
be
on
the
most
recent
minor
release
of
your
series
before
upgrading
and
if
you
news
text
file,
it
will
have
details
on
when
exactly
this
is
necessary,
but
as
a
rule
of
thumb,
it's
best.
If
you're
on
10
and
update
to
10
10
or
whatever
the
most
trees
tomorrow
releases,
and
then
you
can
jump
straight
to
one,
not
two
from
there.
You
don't
you
don't
so
far.
Let
me
put
it
this
way.
A
So
far,
we've
never
made
you
stop
or
we
never
made.
You
do
intermediate
upgrades
or
still
fully
backwards,
compatible
activist
layer,
all
the
way
back
to
0
dot,
six
I
think,
but
you
do
want
to
be
on
that
most
recent
minor
release,
because
sometimes
there's
network
protocol
issues
where
it's
not
it's
not
compatible
with
doing
a
live,
rolling,
upgrade
a
part
of
your
quest
at
a
time
unless
you're
on
that
most
recent
minorly.
B
A
I
can
give
you
a
historical
perspective
on
that.
We're
with
that
affect
enterprise
to
when
we
first
released
that
on
one
dot,
10,
sorry
10,
and
then
we
get
a
minor
release
of
the
sp2
and
it
was
two
dot
one
where
we
released
is
based
on
when
de
cassandra
one
down
one
row,
so
we're
going
to
we're
going
to
see
the
same
thing.
A
I
expect
with
the
satisfaction
of
fries
three,
then
first
it
will
be
released
on
and
I'm
a
tender
one
down
one
and
then
we'll
do
a
minor
upgrade
or
a
minor
will
be
that
incorporates
Cassandra
12
as
to
how
long
that
that
will
take
all
I
can
say
is
our
goal
is
to
be
faster
than
it
was
with
still
one
dot,
0
to
1
dot.
One
migration.
A
If
you
really
want
to
do
that,
pretty
I,
don't
think
it
does
anything
particularly
special
around
connection
pooling
it
may
not
even
min
even
push
the
connection
pulling
off
and
say
you're
responsible
for
doing
it
yourself
or
with
some
other
library.
You
really
need
to
ask
the
native
ECG
project
about
that.
I'm,
not
super
familiar
with
it.
At
this.