►
From YouTube: Cassandra Community Webinar | What and Why NoSQL?
Description
Speakers | Aaron Morton (Apache Cassandra Committer), Robin Schumacher (VP of Products, DataStax)
Date | Wednesday, September 12 @ 11AM PST
In the first of our bi-weekly C*ollege Credit series Aaron Morton, DataStax MVP for Apache Cassandra and Apache Cassandra committer and Robin Schumacher, VP of product management at DataStax, will take a look back at the history of NoSQL databases and provide a foundation of knowledge for people looking to get started with NoSQL, or just wanting to learn more about this growing trend. You will learn how to know that NoSQL is right for your application, and how to pick a NoSQL database. This webinar is 101 level.
A
A
So
in
the
second
half
of
the
19th,
these
ideas
are
advanced
in
the
sort
of
commodity
databases
that
people
were
juice,
not,
but
not.
The
maintain
things
that
IBM
when
creating,
but
in
the
commodity,
databases
and
probably
the
most
famous
one
of
those
in
the
open
source
world
has
been
my
sequel.
We
look
at
the
history.
There
had
the
first
public
release
in
96,
so
by
then
be
tree
was
already
an
established
product.
A
So
we
had
this
time
when,
if
you
were
doing
small
to
medium
enterprise
development,
you
are
using
something
you
approved,
maybe
using
company
that
didn't
support
SQL
at
all.
In
99
they
had
the
I
fam
engine
and
we
still
don't
have
my
items
and
we
still
don't
have
transaction
support
and
2001
nodb
becomes
the
default
and
we
get
acid
transactions
from
from
aunty
people,
and
we
get
foreign
key
constraints
for
a
referential
integrity
jump
over
to
the
Microsoft
SQL
Server
world
in
Nice
lies.
A
They
had
their
first
big
release,
which
was
version
sticks
and
they
were
working
with
slide
basin.
They
came
with
priorities
and
foreign
keys
and
in
many
version
6.5
they
enhance
the
joint
ematic.
So
we
got
both
inner
and
outer
joins
in
98.
They
added
some
replication
and
support
for
Unicode
and
then
in
two
thousand
we
got
the
full
set
of
retro
referential
integrity
controls.
A
So
these
allow
you
to
do
things
like
say
when
you
delete
a
record
and
there's
foreign
key
somewhere
delete
the
record
that
has
befallen
ki
cascading
delete,
set
null
or
set
default
on
when
referential
integrity
is
going
to
be
broken
and
finally
postgres.
Another
well-known
open
source
relational
database
had
an
initial
and
released
late
in
the
80s,
went
through
some
issues
and
came
out
again
in
the
public
open
source
project.
A
We
knew
that
those
three
platforms
concede
that
around
2000
2001
they
started
to
look
like
we
think
relational
databases
should
look.
They
had
support
for
the
trend
for
transactions,
referential
integrity
and
the
enhanced
join
semantics,
and
there
was
a
time
there
where
they
didn't
end
exactly
that.
Those
features
were
added
to
to
get
anti-people
components.
A
So
we
move
into
the
needs
into
the
new
millennium,
people
that
were
creating
applications
and
creating
websites
started
to
run
into
issues
of
scale
for
capacity
and
throughput
and
availability
and
the
tools
that
they
used
to
solve
these
problems,
often
lived
outside
of
the
database,
were
added
on
to
the
database
platform
later
on.
So
we
look
at
the
first
one
teaching
many
key
steam
came
out
in
learning
2001
and
the
idea
is
you
put
the
date
that
you
use
frequently
outside
of
the
database
and
pull
it
from
memory?
A
A
This
problem
is
under
in
herds
where,
if
your
case
goes
down,
you've
got
a
lot
more
request:
code
access
database
that
we
had
previously
or
if
your
patients
warming
up
it's
going
to
get
a
lot
of
cash
message
and
as
I
say
there
are
there
only
two
hard
problems
in
computer
science
station
naming
and
off
by
one
errors
and
problem.
The
patient
is
that
you
has
to
invalidate
the
case
at
some
point,
and
so
you
have
a
consistency
problem
here
between
the
case
and
the
database.
A
Early
in
the
nerve,
the
3000
and
then
some
clever
person
came
up
with
the
idea
of
Chardon
and
the
idea
was:
let's
take
half
a
million
users
and
put
them
on
one
commodity
database
server:
ok,
next,
half
a
million
users
and
put
them
on
a
different
commodity
database
server
with
all
of
their
data.
So
it's
a
horizontal
partition
through
your
schema
and
we'll
keep
on
going
and
we'll
keep
adding
servers.
A
A
A
So
you
can
get
some
availability,
we
have
replication,
we
saw
the
microsoft
SQL
habit
and
mine
still
has
it
and
typical
master-slave
replication
occurs
outside
of
the
transaction,
and
the
market
does
don't
think
any
gets
federated
out
to
the
slaves
to
failure.
The
scenario
there
can
add
application
complexity,
it
might
be
managed
by
infrastructure,
arrives,
managing
the
application.
You've
got
an
unknown
asynchronous
delay
between
the
master
and
the
slave.
When
the
game
you've
got
two
assistants
e
problems.
A
There,
like
we
saw
with
patients
in
front
of
the
database
and
potentially
you're,
wasting
resources
on
those
slave
servers.
If
they're
just
there
as
a
passive
failover,
you've
got
CPU
and
memory
and
disk
that
you
could
be
getting
more
valuable
and
finally,
the
reliability
of
that
slave
server
is
unknown.
I
might
go
from
here.
Well,
we
failed.
A
So
you
might
decide
to
do
some
things
with
that
flame,
so
you
might
have
a
bright
master
in
the
reeds
lake
and
again
adding
to
the
application
complexity.
It
has
to
say
the
application
hashim.
Oh
well.
This
is
the
right
and
right
to
go
to
this
machine
and
read:
go
to
those
machines
still
managing
this
asynchronous
delaying
replication,
so
you've
got
consistency.
Problems
between
the
two
and
you've
still
got
a
single
point
of
failure
for
the
right.
Maybe
you've
got
to
failover
to
Mario,
where
you
can
pick
a
new
master.
A
So
if
we
keep
going
down
this
path,
we
have
multiple
machines.
We
have
caching,
multiple
machines
with
shards
and
master
slave
replication.
We
have
to
deal
with
our
database
schema
in
the
relational
database.
The
schema
is
a
really
useful
thing
and
it
helps
the
query.
Engine
understand
how
to
run
your
complicated
SQL
query
and
starts
as
possible.
A
The
ante
start
an
admission
you
and
you
want
to
make
changes.
You
have
to
run
altered,
evil
and
alter
table
locks
the
table
and
blocks
out
readers
and
writers
and
let
the
problem
if
you're
owning
a
24-7
operation,
you've
got
lots
of
machines.
You
have
to
apply
that
to
individual
servants
and
also,
as
you
go
and
include
a
fast-changing
problem
domain,
you
often
tend
towards
the
situation
where
you
have
a
lot
of
columns
that
just
my
sins
default
null.
So
a
tight,
well-defined
schema
starts
to
become
a
problem.
A
The
second
half
of
that
decade.
We
had
some
really
interesting
papers
published.
We
start
with
the
Google
BigTable
paper.
It
came
out
in
2006
and
talked
about
a
data
distributed
fault,
tolerant
database
platform
that
they
build
one
of
the
interesting
things
in
it
was
the
data
model,
so
they've,
broken
away
from
the
idea
of
a
row
orientated
database
model
that
you
have
in
relational
database
and
use
these
things.
A
Next
year,
amazon
publish
their
dynamo
paper
again
about
an
internal
across
the
databases
they
created
and
the
interesting
thing
the
dynamo
talked
about
was
this
idea
of
eventual
consistency
is
a
way
for
a
cluster
of
machines
to
return
consistent
data
to
quite
request.
Even
if
some
of
the
machines
have
been
down
and
missed
some
of
the
right
activity,
they
might
have
different
physical
data,
a
different
data
on
their
bit,
but
you
can
still
have
the
cost
to
give
you
a
consistent
result
and
you
can
deal
with
nodes
failing
after
a
while.
A
They
released
it
shortly
after
onto
google
code
and
it
became
an
Apache
Incubator
project,
and
then
we
ended
up
having
web
web
chats
like
they
are
today
because
of
these
three
papers
that
came
out
and
pointed
the
direction
that
we
could
going
in
the
second
half
of
that
decade.
We
had
a
lot
of
new
ideas
in
beta
based
platforms.
A
We
sort
of
fall
into
four
broad
categories.
We
have
key
value
stores.
There's
a
platform
called
Tokyo
cabinet
read.
It
is
a
very
popular
key
value.
Store
Voldemort
from
LinkedIn
is
a
key
values,
platform
and
riot
member
shows
in
the
key
value
systems
that,
just
as
they
say
on
the
PM
is
key
and
a
value.
Maybe
those
values
have
some
structure
to
them
like
in
readers,
or
maybe
they
are
just
blobs
of
paper,
and
we
have
document
orientated
stores,
Apache,
CouchDB
and
mongodb,
and
these
ideas
that
client
sends
a
document
of
key
value
pairs.
A
The
service
stores
that
maybe
an
index
of
some
it
goes
very
flexible,
subjective,
schema
grass
databases
allow
you
to
lay
out
things
and
we
look
at
the
internet
movie
grass
everywhere,
so
they
become
quite
popular
as
well
and
Khan.
Family
stores,
those
sorts
of
things
that
Cassandra
the
category
that
Cassandra
falls
into.
A
A
Google
then
took
their
big
table
infrastructure
and
made
that
available
to
the
public
via
google
app
engine
and
put
two
days
there,
because,
typically
in
typical
Google
fashions,
it
was
released
in
two
thousand
eight
and
taken
out
of
preview
or
better.
In
2011,
we
had
a
patchy
Cassandra,
which
entered
the
incubator
and
apache
in
2009,
became
a
popular
project
in
2010,
and
recently
amazon
has
made
their
dynamo
database
available
to
the
public
through
the
Amazon
Web
Services
system.
A
So
they
can
support
fasta
durations
on
platforms
and
support,
anemia
or
mon
structured
data
and
the
built
around
the
ideas
that
nodes
fail.
And
if
you
want
to
create
a
highly
available,
always
up
application,
you
have
to
have
a
platform
with
us
that
accepts
that
and
and
can
continue
to
operate
in
the
face
of
individual
service
failures.
C
Okay,
great
thanks
very
much
Aaron,
so
let
me
go
ahead
and
I'm
going
to
be
covering
for
you
today.
Errands
done
a
great
job
in
terms
of
telling
us
what
no
SQL
is
and
has
identified
many
of
the
common
players.
So
one
of
the
things
that
I
want
to
do
now
is
take
you
through
why
you
should
be
using
a
no
SQL
database.
Okay,
when
is
the
relational
database?
C
Okay,
when
should
you
be
looking
at
a
no
sequel
database
and
so
I'm
going
to
provide
a
number
of
different
reasons
why
you
want
to
go
to
know
SQL
and
then
I'm
going
to
show
you
how
catchy
Cassandra
meets
those
particular
use
cases
so
before
I?
Do
that,
though,
I
want
to
draw
your
attention
to
the
fact
that
they're
simply
big
claims
right
now
being
made
about
no
SQL.
For
example,
here's
a
smoke
quote
from
an
article
and
infoworld
but
says
no
SQL
is
the
stuff
of
the
Internet
age.
C
It's
pretty
big
claim
and
really
what
did
that
even
mean,
and
so,
if
we
start
to
dive
down
into
that
a
little
bit,
what
really
characterizes
a
modern
database
in
this
internet
age?
Well,
there's
a
number
of
different
factors.
You
could
look
at,
but
I've
listed
three
for
you
here
on
the
screen
number
one
big
data,
and
this
is
not
just
hype.
This
is
real.
I'll
cover
this
more
in
a
few
moments
here,
but
here
you're
dealing
with
being
able
to
scale
how
fast
data
is
coming
in
the
variety
of
data
to
volume.
C
So
that's
one
of
the
things
that
really
characterizes
I
think
today's
data
age,
second,
would
be
the
clouds.
So
a
lot
of
people
looking
to
cloud
trying
to
move
their
databases
to
the
cloud
for
a
variety
of
reasons
may
be
operational.
Efficiency,
maybe
cause
something
like
that
cloud
makes
a
lot
of
promises.
It
promises
that
you're
going
to
get
transparent,
elasticity
scalability
all
these
types
of
things
is
it
legit
is
it
true.
C
B
C
Big
data
use
cases
right
and
what
characterizes
big
data
is
the
3ds
the
volume
brought
in
and
volume.
So
you
have
should
just
a
little
air
on
the
slide
should
be
velocity
there.
So
data
velocity
it's
coming
in
very,
very
quickly
and
perhaps
from
different
locations.
You've
got
a
variety
of
data,
may
be
structured,
semi-structured,
unstructured
data
and
then
the
volume
of
data
oftentimes
people
here
big
dating
they
think
well.
That
just
naturally
means
terabytes
and
petabytes
not.
C
We
have
a
number
of
customers
here
at
datastax
who
have
very
big
data
use
cases,
but
they
don't
have
petabytes
that
they're
managing,
so
volume
is
not
the
only
characteristic.
That
really
constitutes
a
big
data
use
case.
Something
else
is
the
complexity
of
data
distribution,
because
you've
got
all
this
data.
That's
coming
in
may
be
high
speed,
different
types,
lots
of
it
and
you've
got
a
distributed
around
different
locations.
C
Maybe
they
couldn't
add
new
online
subscribers
as
fast
as
they
needed
to,
and
they
never
want
that
to
happen
again
and
so
they're
looking
for
something
to
ensure
their
success
in
the
future-
and
this
is
where
again,
Big
Data
technologies
come
into
play,
and
one
thing
that
analysts
tend
to
agree
on
is
that
you
need
something
other
than
a
relational
database.
So
I
have
a
quote
here
on
the
screen
from
ITC.
That
says
really
big
data
technologies.
It's
not
relational,
it's
really
something
else,
and
this
is
where
no
SQL
comes
into
play
and
specifically
cassandra.
C
Cassandra
is
a
massively
scalable,
no
SQL
database
that
what
it
was
architected
from
the
ground
up
to
do
to
handle
big
data
workloads.
This
means
that
it's
going
to
give
you
very
strong
right
performance
for
data
velocity.
It's
going
to
support
the
various
data
types
that
you
need,
unstructured
semi-structured.
All
of
that,
and
it's
going
to
offer
you
linear,
scalability,
for
your
data
volumes
and
or
handling
your
concurrent
users.
C
You
can
see
the
quote.
They
said
you
know:
we've
seen
basically
a
seven
hundred
percent
performance
improvement
while
at
the
same
time
our
database
grew
over
five
hundred
percent
and
we've
cut
costs.
Forty
percent,
so
not
bad.
So
the
first
reason
you
want
to
go
to
know
SQL,
you
have
a
big
data
use
case
when
big
data
is
talked
about.
Quite
a
bit
in
performance
comes
up.
You
know
how
really
fast
will
the
database
run?
C
So
at
the
top
of
the
screen
here,
I've
got
a
quote
from
a
recent
academic
benchmark
that
was
done
presented
at
a
very
large
database
conference
here
this
year
and
they
tested
a
number
of
different,
no
SQL
contenders
and
in
the
end
they
said,
look
in
terms
of
scalability
there's
a
clear
winner:
Cassandra
achieves
the
highest
throughput,
the
maximum
nodes
and
all
experience
experiments
with
linear
increasing
throughput.
So
it
doesn't
matter
whether
it's
in
the
cloud
and
you
can
see
a
benchmark
they're
done
by
Netflix,
whether
it's
in
web
apps.
C
You
can
see
a
an
external
benchmark,
they're
done
against
one
of
Cassandras,
no
SQL
rivals.
Cassandra
really
doesn't
disappoint
where
performance
is
concerned
and
what
it's
big
data
were
closed
or
not,
okay.
Secondly,
why
no
ask
you:
why
do
you
want
to
go
to
a
no
SQL
database?
Number
two?
You
need
continuous
availability,
and
this
is
different
than
high
availability.
What
we're
talking
about
here
or
applications
that
simply
can't
go
down,
so
that
means
whether
you're
doing
maintenance.
That
means
whether
there
is
a
particular
disaster.
C
Hardware
failures,
those
type
of
things
know
your
application
cannot
go
down
and
it
may
involve
one
or
more
locations.
So
maybe
you
have
multiple
data
centers
that
are
serving
up
different
clients
all
over
the
globe.
So
you
need
that
continuous
availability
and
you
need
it
everywhere.
Well,
here
again,
Cassandra
really
shines.
It
is
a
continuously
available,
no
sequel
database.
So
it
was
again
architected
to
overcome
the
fact
that
hardware
failures
can
and
do
occur
so
built
into
Cassandra.
C
What
you're
going
to
find
is
no
single
point
of
failure
in,
however,
it
manages
data
and
function,
so
you
get
out
of
the
box.
Redundancy
a
function
and
data
with
its
built-in
replication,
with
its
architecture,
where
Evernote
is
the
same
you're
not
going
to
have
an
issue
in
terms
of
availability
when
it
comes
to
Cassandra.
C
Here
we
have
a
quote
on
the
screen
from
one
of
our
customers
right
scale
and
the
primary
reason
they
say
that
they
chose
Cassandra
was
because
they
needed
that
continuous
availability,
their
app
can't
go
down
and
they
have
multi
data
center
support
so
that
when
they
write
data
there
is
no
worry
that
it's
going
to
be
written.
So
that's
not
point
number
two.
Why
no
SQL?
You
need
a
continuously
available
database
number
three.
You
need
true
location
independence.
C
This
may
sound
like
a
funny
term,
but
what
it
basically
means
is
you
need
to
be
able
to
read
and
write
your
data
anywhere
now.
Theron
was
talking
about
earlier,
there's
number
of
different
architectures
that
can
perhaps
get
you
reads
if
you
can
get
you
rights
as
well,
and
that
is
a
problem
that
the
no
SQL
databases
like
Cassandra
overcomes.
So
if
you
need
to
read
and
write
data
anywhere
in
multiple
locations,
you
have
one
logical
database.
That,
perhaps,
is
made
up
of
many
different
physical
locations.
C
This
we're
a
no
SQL
database
like
the
standard
comes
in
and
how
it
handled
the
various
operations.
The
data
itself
is
going
to
be
eventually
synchronized
in
all
locations,
and
you
want
to
keep
data
local,
perhaps
for
very
fast
access.
So
if
I'm
here
in
the
United,
States
and
I
need
doing
some
queries
or
looking
up
some
data
doing,
search
or
whatever
I
don't
want
to
have
to
wait
for
a
query
to
be
satisfied
in
a
server.
That's
tens
of
thousands
of
miles
away
or
I
keep
my
data
very
local
for
fast
access
and
again.
C
This
is
where
Cassandra
can
help
out,
because
with
Cassandra
you
get
out
of
the
box.
Multi
data
center
support,
really
that
is
the
standard
in
the
no
SQL
database
industry,
really
the
standard
for
multi
data
center
support,
multi-directional
capable,
and
it
allows
you
to
create
clusters
that
are
hybrid
in
nature.
Perhaps
you
need
some
data
on
premise:
some
data
in
the
cloud,
those
type
of
things
you
can
do
that
with
Cassandra
very
easily.
C
Another
reason
point
number
four:
why
you
want
a
no
SQL
database.
You
need
real-time
transactional
capabilities.
Now.
Some
of
you
may
think
now
wait
a
minute.
I
thought
no
SQL
didn't
do
transactions.
Let
me
clarify
this
a
little
bit
so
with
transactions.
You
have
something
an
acronym
called
acid
that
is
typically
applied
to
relational
databases,
and
if
you
need
true
acid
level,
compliance
you
can
get
by
with
a
relational
database.
Typically
now
there
are
some
no
SQL
databases
that
will
try
to
give
you
acid
and
what
have
you?
C
But
by
and
large
no
skill
databases
don't
look
to
really
support
acid
in
the
sense
that
it's
defined
in
the
sensitives
defined
in
the
relational
world.
Okay
and
what
I
mean
by
that
is
that
the
see
an
acid
does
not
apply
to
really
the
no
steel
database
on
those
field.
Data
is
like
a
sandra.
It
refers
to
referential
integrity,
form,
key
constraints
and
with
databases
like
the
central,
you
don't
have
those
types
of
mechanisms
you
don't
have
joins
and
what-have-you,
where
you're
going
to
need
to
support
that
see
in
the
relational
database.
C
Acid
definition,
in
fact,
some
people
don't
think
you
really
need
acid
style
transactions
for
many
of
today's
modern
applications.
I
have
a
quote
here
from
Dan
McCreary
on
the
screen,
where
he
asserts
ninety
percent
of
the
apps
that
he
sees
right
now
they
don't
need
acid
transactions.
Now
that
doesn't
mean
that
Noah
ql
can't
support
transactions
for
you
indeed,
Cassandra.
Can
it
excels
in
real
time
in
those
sequel
transactions?
It
supports
the
eid
portion
of
the
transactional
definition,
so
you're
going
to
get
an
atomic,
isolated
and
durable
transaction.
C
What
it
does
a
little
differently
is
again
dealing
that
see
part
of
the
acid
definition
so
again,
you're
not
going
to
have
foreign
key
constraints
and
referential
integrity
to
deal
with
instead
you're
dealing
with
consistency
and
how
data
is
made
consistent
across
many
different
machines.
Many
different
database
clusters
that
perhaps
are
in
multiple
locations
and
again
as
I
mentioned
earlier.
This
is
where
cassandra
offers
something
that's
kind
of
unique
tunable
data
consistency.
C
What
this
means
is
you
have
the
flexibility
to
choose
on
a
per
operation
basis,
how
consistent
a
particular
operation
that
you're
performing
is
going
to
be
in
the
database.
So,
for
example,
if
you
want
a
right
to
be
propagated
across
all
nodes
across
all
different
location
and
all
must
respond
back
before
that
transaction
is
complete.
You
can
do
that.
You
can
specify
that
on
a
single
insert,
a
single
update,
perhaps
other
rights,
though
other
inserts
and
updates.
You
don't
need
that
type
of
assurance
that
it
made
to
all
notes.
C
Maybe
you
could
maybe
you
just
want
a
majority
of
the
nodes
to
respond,
or
maybe
you
just
want
one
node
to
respond.
The
whole
thing,
though,
is
you
get
to
choose
you're
in
charge
on
a
per
operation
basis?
You
have
a
lot
of
flexibility
from
a
development
perspective
to
make
this
happen.
Okay,
so
yeah.
Why.
A
C
C
Another
reason
why
you
want
a
no
sequel
database,
you
heard
Aaron
talk
about
this
a
little
earlier.
You
need
a
more
flexible
data
model.
All
right,
relational
data
model
is
the
cob
date.
Data
model
very
good
serves
its
purpose
that
it
is
rigid
all
right,
perhaps
particular
applications
you're
developing
need
to
be
a
little
bit
more
flexibility,
a
little
bit
more
agility.
You
don't
what
I
have
to
worry.
If
you
have
what
are
called
wide
rows
of
data,
maybe
data
that's
made
up
of
hundreds
or
thousands
or
even
tens
of
thousands
of
columns.
C
Well
again,
a
database
like
Cassandra
handles
this
very
very
well
now.
The
good
news
if
you're
coming
from
the
relational
world
like
I
was,
is
that
you're
going
to
see
some
things
that
we
are
familiar
in
Cassandra,
so
Cassandra
uses
the
data
model
big
table
to
row,
oriented
column
structure
very
similar
to
relational
table,
but
it's
going
to
give
you
more
flexibility
and
agility.
So,
for
example,
I
could
insert
a
row
into
a
Cassandra,
what's
called
a
column
family
and
maybe
contain
metadata
about
myself,
and
it
only
contains
a
couple
of
columns.
C
Maybe
ten
columns,
then
I
need
to
insert
a
second
row
into
that
same
column,
family
about
you,
and
maybe
you
have
a
thousand
different
attributes
that
I
have
to
track
well,
the
good
news
is
I
can
do
that.
I
can
insert
that
that
particular
data
about
yourself
keep
the
one
about
me
all
on
the
same
data
with
no
storage
impact.
No,
no
storage,
overhead
issues,
no
query
issues
that
you
need
to
deal
with.
It's
all
handled
by
Cassandra,
very,
very
well,
there's
other
things
that
are
very
familiar
to
you.
C
So,
for
example,
you
have
primary
keys.
You
have
secondary
indexes
that
you
can
create
for
faster
access.
So
you
have
some
very
nice
things
that
that
don't
get
in
the
relational
world
but
at
the
same
time
the
learning
curve
is
not
very
high.
All
in
terms
of
understanding
the
data
model
and
understanding
how
things
work,
one
of
our
customers
here
NASA
they
went
to
a
no
SQL
solution
from
relational
database.
They
had
and
we're
very
pleased
to
see
that
they
were
able
to
do
things
much
more.
C
Naturally,
they
said,
then
the
relational
database
was
forcing
them,
and
the
data
model
also
delivered
much
faster
performance
than
they
were
getting
from
the
relational
database.
So
the
very
last
reason
why
you
might
want
to
choose
a
no
sequel
a
base.
Did
you
just
need
a
better
architecture?
Now
we've
talked
about
some
of
these
things
already,
but
I
really
wanted
to
bring
it
out
explicitly
so
again
earlier,
you
heard
Aaron
talk
about
the
different
types
of
architectures
that
you
might
be
using
with
relational
we're
non-relational
and
such
so.
C
You
have
master
slave
and,
if
you're
like
me
with
a
background
in
databases,
I'm
sure
you've
done
all
of
these
so
master
slave.
It
has.
There
is
issues
that
you
have
to
deal
with,
most
notably
a
right
bottleneck,
there's
latency,
replication
issues
between
the
slaves
and
the
master.
Then,
if
the
master
fails,
the
failover
has
to
occur,
then
what
else
you
don't
hear
talking
about
its
failing
back
to
the
master
webkinz
brought
back
online?
C
That's
usually
very
tough
to
do,
but
you
have
those
things
to
take
care
of
manual,
sharding,
very
difficult,
oftentimes
done
in
an
application
and
requires
quite
a
bit
of
elbow
grease
on
a
part
of
the
developer.
To
make
it
happen,
then
you
have
shared
storage
model
architectures
that
have
availability
concern,
since
that
storage
area
could
be
a
single
point
of
failure
for
you
well
again,
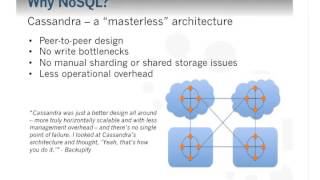
a
database
like
Cassandra
overcome
these
limitations
overcome
these
issues,
because
it's
a
masterless
architecture
to
peer-to-peer
design.
Where
every
note
is
the
same.
C
Cassandra
had
all
this
built
and
we
thought
yeah,
that's
how
you
do
it
so
again.
Just
to
summarize,
why
might
you
come
to
a
no
SQL
database
like
Cassandra?
Well,
you
need
to
handle
big
data,
use
cases,
ET
continuous
availability.
You
need
a
real
location,
independent
database.
You
want
a
real
time,
modern,
transactional
database.
You
need
more
flexibility
and
agility
in
your
data
model
and
east
just
need
a
plane,
better
architecture
to
take
care
of
things.
C
So
what
are
some
of
the
types
of
use?
Cases
grill,
world
practical
use
cases
that
a
database
like
Cassandra
can
tackle
list
a
number
of
them
here?
It's
certainly
not
exhaust.
Is
that
real
time,
Big
Data
workload
Cassandra
excels
at
time
series
data
management.
So
if
you
have
financial
data,
you
have
web
clip
string
data,
you
have
data,
that's
coming
off
various
devices,
oftentimes
called
data
exhaust.
It
really
does
a
wonderful
job
of
these
types
of
systems,
social
media,
real-time
data,
analytics
online
portals
and
right
intent.
Systems
are
on
and
on.
C
These
are
the
types
of
use
cases
that
Cassandra
really
excels
at,
so
that
I,
a
quick
screen
pic
here
of
the
COS
guide
to
no
sequel,
which
I
thought
was
pretty
good
study.
I
would
definitely
recommend
you.
You
take
a
look
at
that.
Mccreary
says
you
when
you
really
get
down
to
it.
What
is
sort
of
benefit
you're
going
to
derive
you
outside
of
the
technical
benefits
that
I
outline
and
some
of
the
technical
reasons
why
you
want
to
choose?
C
No
sequel,
you
search
that
you
can
really
build
systems
much
faster
because
you
really
don't
need
a
logical
data.
Modeling
or
any
entity
relationship
diagram
I
would
caution
there.
You
certainly
need
to
put
fought
your
data
model,
so
I
might
disagree
with
him
a
little
bit
on
that,
but
I
certainly
agree
that
you
can
definitely
scale
more
automatically
you're
going
to
have
much
lower
failure
rates
without
continuous
availabilities
featured
characteristics
that
are
built
into
cassandra,
and
it's
definitely
more
extensible.
B
Thank
you
very
much
indeed,
Robin
and
Aaron.
We
have
a
couple
of
questions
so
far
and
I
will
go
ahead
and
ask
those
if
you
do
have
a
question:
please
feel
free
to
either
use
the
Q&A
with
in
WebEx
and
we
will
monitor
that
and
read
them
out
or
use
the
hashtag
Cassandra
QA,
and
we
will
monitor
that
and
read
them
out
so
Robin
I'm
going
to
direct
the
first
question
to
you.
C
There's
a
couple
different
routes
you
can
take
if
you,
if
you
just
want
to
use
the
open
source
version
of
Cassandra,
it
does
have
manual
integration
with
the
tube
that
is
offered
with
it,
and
it
would
require
some
manual
development
efforts
to
go
ahead
and
construct
an
integration
path
between
Cassandra
and
Hadoop,
but
you
can
certainly
do
it.
What
I
would
recommend,
though,
is
if
you
go
to
davis
XCOM.
We
have
our
day
sex,
Enterprise
Edition,
which
integrates
Apache,
Cassandra,
Hadoop
and
apache
solr,
all
together
in
the
same
set
of
software.
C
That
allows
you
to
build
a
database
cluster
that
automatically
integrates
Cassandra
with
the
Duke
with
solar
and
it's
automatically
built
in
there's,
nothing
special.
You
have
to
do
you
basically
just
install
the
software
startup,
the
different
nodes
in
the
mode
that
you
wish
them
to
be
in
so
you
might
start.
Let's
say
you
wanted
to
attend.
Node,
cluster
and
half
Mike,
because
Sandra
nodes
half
might
be
Hadoop
nodes.
You
could
certainly
do
that.
C
You
would
just
start
that
nodes
up
in
their
respective
order
and
their
respective
quote-unquote
personality,
whether
it's
real
time
with
Cassandra
or
analytics
with
Hadoop.
Then,
when
you
insert
data
into
those
various
nodes,
it's
automatically
going
to
be
replicated
to
to
the
different
subsystems.
So
it's
when
you
insert
data
on
the
Hadoop
side,
it's
going
to
be
replicated
Cassandra
when
you
insert
data
Cassandra's
automatically
going
to
be
replicated
with
Hadoop.
C
So
if
you
just
go
to
the
downloads
page
on
Davis
XCOM,
you
can
download
data
sex,
Enterprise,
Edition,
completely
free
download
there
and
and
completely
free
to
use
for
development
purposes.
So
if
you
feel
free
to
download
and
develop
to
your
heart's
content
with
enterprise,
that's
what
I
would
really
recommend
in
terms
of
getting
started
with
a
a
bundled
or
integrated
Cassandra
in
Hadoop
distribution.
B
A
Yeah
one
of
the
things
that
I
think
we
have
to
deal
with
now
sorry
is
fast.
Changing
life,
changing
problem
spaces
and
different
sorts
of
data
in
the
90s
database
books
talked
mostly
about
slowly
changing
problems,
accounting
systems
and
banking
systems
and
the
modern
sorts
of
data
that
we
deal
with
from
information
from
sensors
and
health
either
end
things
doesn't
fit
too
well
into
a
chiton
structured
row
based
relational
model.
B
A
So
the
story
of
schema
changes
and
cassandra
is
one
of
it
been
a
little
bit
painful,
and
now
we
being
essentially
angels
and
essentially
the
same
as
you
would,
with
a
single
relational
database
coming
up
in
version
1.2.
We
have
support
for
concurrent
online
schema
changes.
Nowadays,
you
can
make
online
schema
changes.
A
Just
the
same,
though,
in
a
relational
database
where
you
add
more
tables
and
your
database
has
to
do
a
bit
more
work
in
cassander,
if
you
add
lots
of
column
family,
so
it's
all
three
in
the
hundreds,
then
your
then
the
Cassandra
server
has
to
do
a
bit
more
work.
So
if
you're
a
10,
you
can
just
throw
a
query,
throw
a
query
on
Cassandra
and
we'll
get
to
work
and
create
that
content.
As
for
you,.
B
A
Good
question
replication
fact
areas
depending
on
two
factors:
I
guess
number
one
is
your
aversion
to
risk
and
number
two?
Is
your
expectation
I
think
about
how
about
the
data
that
you're
going
to
get
back?
So
emergence
of
risk
means
different
when
you're
sending
a
query-
and
we
talked
about
this
consistency
idea.
A
If
you
we
have
Cassandra
generally
works
as
a
quorum
based
system,
and
if
you
have
a
replication
factor
of
three,
then
the
quorum
is
too
because
the
quorum
is
half
the
modes
plus
one
and
and
at
that
level
we
will
always
give
you
consistent
results
back.
If
you
use
Coram's
for
reads
and
writes,
oh
I
would
normally
suggest
that
you
start
with
a
replication
factor
of
three.
A
If
you
let
and
use
corn
consistency,
and
that
will
mean
that
your
database,
you
have
these
consistent
reads
and
writes,
and
it
really
looks
the
same
as
when
you're
in
a
single
relational
database
server.
When
you
get
into
things
a
bit
more
and
you're
scaling,
you
might
add
replication
factor,
because
you
need
to
scale
because
you
want
to
spread
your
data.
Further.
A
B
Thanks
a
lot
Aaron
Robin,
so
you
don't
feel
left
out.
Here's
one
for
you,
but
but
feel
free
to.
You
know
flip
it.
If
you
need
to
this
one
from
Mike,
c-can
Cassandra,
efficiently
support
data
with
thousands
of
columns
with
secondary
indexes
on
hundreds
of
columns
for
searching
across
a
wide
variety
of
data
attributes.
If
not,
what
is
the
practical
upper
limit
to
secondary
indexes,
supported.
C
C
So
I
I
think
you're
really
are
there's
nothing
for
Mike
to
worry
about
again.
Cassandra
really
is
is
architected
to
support
again
thousands
or
more
columns
and
secondary
indexes
at
least
are
there
and
outside
of
perhaps
maybe
a
little
storage
or
something
like
that.
There's
really
no
limit
that
I'm.
Aware
of
that.
He
had
to
worry
about.
B
Thank
you
and
last
question
right
now
and
then
we'll
wrap
up.
Unless
anyone
ask
anything
additional
this
one
from
alvin
kind
of
guy,
an
again
apologies
for
pronunciation
there
is
there
any
way
to
fine-tune
the
hash
algorithm
that
Cassandra
employees
or
is
it
fixed
in
terms
of
how
it
distributes
data.
C
Look
I
can
start,
maybe
Eric
and
finish,
maybe,
if
he's
getting
to
the
various
modes
that
you
can
operate
in
in
terms
of
the
data
distribution,
random,
is
the
default
and
recommended
in
terms
of
a
randomized
method
of
Cassandra
distributing
the
data
across
the
nodes
in
the
cluster.
There
is
an
ordered
petitioner
that
is
also
available.
However,
it's
typically
not
recommended
for
a
variety
of
different
reasons
and
I'll.
Let
Aaron
the
expand
on
that.
If
you'd,
like
yeah.
A
So
we
have
when
it
comes
to
distributing
data.
This
there's
two
features
in
Cassandra
that
we
use.
There's
the
partitioner
when
the
random
petitioner
and
the
ordered,
partitioner
and
random
gives
you
a
good
fan
point:
a
random
sampling
of
data
across
all
the
modes
which
allows
you
to
partition
capacity
and
throughput.
But
then,
on
top
of
that
is
the
idea
of
the
replication
strategy,
which
determines
how
data
is
just
through
videos
as
well
and
nowadays
the
default
replication
strategy.
A
Cassandra
is
called
the
network
topology
strategy,
that's
the
one
that
allows
you
to
say,
use
a
replication
factor
of
three
in
my
East
Coast
data
center,
a
replication
factor
of
three
in
my
West
Coast,
a
temper
and
in
in
the
middle
of
the
country.
I've
got
my
own
premises.
Cluster
and
I
want
a
replication
factor
one
in
there,
because
I
just
want
the
data
in
there
so
that
my
developers
can
come
along
and
touch
that
and
hit.
Therefore,
it's
just
for
backup
purposes.
B
B
A
So
there's
a
utility
Cassandra
called
no
tool
and
it
can
do
snapshots
and
when
we
do
a
snapshot,
we
flush
everything
from
memory
onto
disk
and
then
use
disk
level
hardlex
in
Linux
to
do
a
snapshot
of
that
they
nordisk
did.
We
use
that
to
them
run
their
backup
systems,
it
might
be
when
you're
doing
an
upgrade,
either
a
snapshot
so
that
you've
got
your
data
from
before
you
upgraded
your
upgrade
check
the
box
and
everyone's
happy
and
delete
those
snapshots.
A
You
can
also
use
those
as
part
of
your
disaster
recovery
planning
to
move
data
off
snowed
on
to
something
like
Amazon,
s3
and
Netflix.
Do
this
and
using
their
open
source
platform
called
prior,
which
they
used
to
manage
that
Cassandra
clusters
and
they'd
also
involve,
but
it
also
lets
them
take
their
off
those
backups
and
spin
up
our
own
a
clones
cluster.
A
So
they
use
this
when
they
move
into
a
new
region.
They
move
this
when
use
this
when
they
launch
their
European
service
and
they
needed
to
take.
Essentially
they
contain
the
cluster
and
stamp
it
a
new
datacenter
out
over
in
England,
and
so
they
snapshot.
It
went
into
x3
and
they
got
it
over
there,
so
you
can
do
snapshots
for
various
reasons.
Wherever
you
want
to
start
off
your
data,
you
can
take
those
snapshots
and
use
those
to
bootstrap
new
clusters
or
new
baby
comes
in
the
cluster.
A
C
One
thing
that
I'll
add
about
that
is:
there
is
a
web-based
management
tool
from
data
second
off
center,
which
you
can
go
to
the
downloads
page
and
download
off
center,
and
it
supports
doing
visual
snapshots.
So
you
can
actually
point
and
click
your
way
through
creating
snapshot,
scheduling
a
snapshot
to
run
on
a
repetitive
basis.
Things
like
that,
so
that
has
available
for
you.
B
Thank
you
both
very
much
and
I
love
it.
When
I
can
answer
a
question
this
one
from
Mike
see,
will
these
presentation
slides
be
available
for
download?
Yes,
they
will
from
dates
tanks,
comm.
We
will
put
the
archive
of
this
webcast,
so
you
can
go
through
and
hone
in
on
areas
you
want
to
and
then
also
make
the
slides
available.
Alongside
that,
we
will
aim
to
have
those
up
by
this
time
tomorrow
and
we
will
send
out
a
link
to
all
the
registrants
and
attendees
when
they're
available.
B
That
is
it
for
today's
webcast.
Please
join
us
in
two
weeks
time
when
Billy
Bosworth,
the
CEO
of
dates
tax,
is
going
to
talk
about
transitioning
from
relational
databases,
to
no
sequel
and
then
two
weeks
after
that,
we
welcome
back
Aaron
Morton
again,
who
will
give
a
deeper
dive
into
Apache
Cassandra
as
an
introduction
and
some
of
these
questions
that
we've
had
today
Aaron,
it
would
be
great
actually
if
we
can
incorporate
those
into
your
introduction,
presentation.