►
Description
Speaker: Jon Haddad, Technical Evangelist
Company: DataStax
This sessions covers diagnosing and solving common problems encountered in production, using performance profiling tools. We’ll also give a crash course to basic JVM garbage collection tuning. Attendees will leave with a better understanding of what they should look for when they encounter problems with their in-production Cassandra cluster. This talk is intended for people with a general understanding of Cassandra, but it not required to have experience running it in production.
A
All
right,
so
I'm
going
to
be
talking
about
diagnosing
problems
of
production.
I
we've
talked
a
lot
today
about
new
data
modeling,
how
cassandra's
different,
how
amazing
it
is
and
how
everything
is
perfect
when
you're
using
it
you're
going
to
put
this
in
production,
and
you
are
going
to
need
to
understand
your
system.
That's
just
the
confidence
work.
A
A
The
first
thing
is
to
monitor
your
system
right
for
that
you're
going
to
want
to
go
to
data
stacks
off
center.
This
is
going
to
do
about
90
of
what
you
need
as
far
as
monitoring.
What's
going
on
inside
the
sandro,
what's
happening
with
compaction
things
like
that,
we
can
get
visual
histograms
into
everything.
That's
going
on
inside
of
our
cluster
you're,
probably
going
to
want
to
integrate
with
some
other
tools.
That's
cool!
That's
available!
You
can
access
any
of
this
information
over
jnx
or
using
metrics,
which
I'm
going
to
talk
about
today.
A
There
is
a
community
version
of
data
stacks
off
center
and
it's
free
and
there's
also
the
enterprise,
one
that
comes
with
dse,
and
that
gives
you
some
additional
features
you
can
use.
You
can
use
this
to
launch
servers
on
amazon,
there's
a
whole
bunch
of
other
functionalities,
provided
here
I
will
go
into
two
deeper
details.
A
You're
gonna
have
general
purpose
monarch.
This
is
cassandra
running
on
this
box
alerts.
This
is
from
those
of
us
that
have
been
in
australia.
A
lot
of
this
is
very,
very
basic,
but
it's
also
easy
to
kind
of
forget
about
or
skip
I'm
absolutely
guilty
of
putting
stuff
in
progression
without
monitoring.
I
have
regretted
it,
which
is
why
it
is
now.
In
my
slide,
I
consider
myself
pretty
thorough
and
yeah.
I
definitely
just
caught
with
it
so
you're
going
to.
B
A
A
To
want
to
know
about
it,
cassandra
a
disk
based
database
does
not
perform
well
on
full
disks
unless
rights
don't
work
anymore.
Unless
you
don't
do
that,
there's
like
various
tools
that
are
along
the
lines
of
an
audience
messing
up,
I
think
there's
several
others
that
are
forces
might
give
us
that
they're
pretty
popular.
You
can
use
third-party
services.
A
If
you
don't
want
to
run
your
own
infrastructure,
and
I
definitely
recommend
that
if
you're,
a
smaller
company
and
you're
looking
to
not
have
to
worry
about
the
headache
of
all
this
monitoring,
just
make
sure
you
get
something
in
place.
Let
you
know
it
works
test
it
out
right,
stuff,
it's
okay,
you're
gonna,
want
to
collect
application
methods
who
here.
A
Okay,
how
long
not
a
lot
of
people
are
using
this
right
now
in
the
room?
I
strongly
recommend
that
you
integrate
this.
If
you
build
out
an
application,
you
can
do
things
like
monitor,
very,
very
small
blocks
of
code.
You
can
put
micro
timers
around
it.
You
can
graph
those
micro
timers
over
time.
You
can
understand
how
many
times
a
section
of
code
has
been
called
and
you
can
put
counters
around
them.
So
you
can
understand
how
often
how
many
user
logins
are
happening
per
hour
right
now.
Did
that
just
drop
off?
A
Do
we
want
to
put
alerts
around,
so
we
can
tell
based
on
what's
happening
in
these
graphs
if
my
system
is
behaving
abnormally,
so
this
is
a
pretty
useful
thing.
I
strongly
recommend
you
get
this.
This
also
works
very
well
with
the
sander
itself.
There's
this
metrics
library
from
a
guiding
code
of
ale
and
cassandra
metrics
integration
effectively
lets
you
spit
out
the
internal
metrics
of
descender
into
these
graphs.
A
So
you
can
take
your
application
level
graphs
like
those
user
logins
and
answers,
let's
say
a
timer
from
a
user
table
like
how
long
the
query
is
taken.
So
you
can
actually
correlate
things
like.
Is
there
a
problem
on
user
logins?
Maybe
it's
correlated
to
a
performance
problem
I
have
login
out
is
one
of
those
other
things
that
I
try
to
not
use,
and
I
have
realized
that
it's
insane
not
to
there's
a
whole
bunch
of
other
solutions
here,
splunk
boggling,
you
can
do
it
yourself,
you
can
use.
I
love
logsdash.
A
I've
also
used
greylog
before
there's
a
logging
tool
that
I
just
found
out
about
that.
I
managed
to
make
it
into
these
slides,
but
it's
a
dse
based
logsdash,
so
it
uses
solar
instead
of
elasticsearch.
So
if
you've
already
got
vsd,
then
you
may
want
to
consider
using
that,
but
basically
this
this
just
lets
you
take
all
your
logs
put
them
in
one
place.
Have
it
be
searchable,
so
you
can
easily
digest
the
information
and
you
can
go
back
and
you
can
like
look
at
error
rates
over
time.
A
The
important
thing
here
is
to
make
sure
that
you're
not
spitting
out
a
lot
of
noise.
My
last
company,
someone
decided
to
throw
an
error
for
no
reason,
which
is
the
future
in
here
in
the
log.
Just
so
they
could
tell
if
a
block
of
code
was
being
hit.
They
never
removed
it.
So
we
were
seeing
millions
of
errors
per
minute
and
we
realized
the
information.
Wasn't
pointless.
You
couldn't
couldn't
get
anything
out,
so
log
errors,
don't
block
hot
errors
and
you'll
be
okay,
so
there
are
some
gotchas.
A
We
talked
a
little
bit
before
about
what
happens.
If
you
have
incorrect
server
times,
why
do
you
need
to
run
atpd?
This
is
a
an
attempt
at
visualizing.
What
can
happen
with
your
server
time
as
well?
So,
let's,
let's
say
that
we
have
our
first
server
and
at
real,
let's
say,
clock
time:
20,
our
server
is
eight
seconds
ahead,
so
it's
just
wrong
and
a
mutation
comes
in
and
as
an
insert.
Well,
it's
going
to
get
a
time
stamp
of
20.
A
A
Is
actually
behind
it's
five
seconds
behind
and
now
clock
caught
time
15?
So
three
seconds
later
in
the
future,
we
issue
a
delete
to
delete
that
data
that
delete,
because
it's
been
issued
to
the
second
server
carries
a
timestamp
of
10
because
it's
behind
so
that
data
won't
get
deleted.
Now
this
example
may
seem
a
little
ridiculous,
but
I
have
personally
run
into
this
in
production
and
I've
seen
other
people
run
into
this.
A
B
A
A
A
A
This
happens
when
we
have
a
ton
of
tombstones
in
a
partition,
and
the
anti-pattern
here
is
trying
to
use
cassandra.
As
the
cube
I'll
tell
you
up
front
cassandra
is
the
worst
team
on
the
planet.
Do
not
use
it
as
a
cube.
I
would
rather
use
anything
else,
including
a
human
and
pieces
of
paper,
then
use
cassandra
as
a
cube,
because
that
would
be
better
business.
A
So
what
happens
here?
This
example
is
if
we
have
100
000
rows
on
a
partition
and
we've
decided
to
have
999
tombstones
in
the
front.
Well,
when
we
go
to
read
this
data,
all
we
want
is
one
thing:
it's
going
to
have
to
read
all
these
tombstones
out
of
the
front
this
takes
forever,
even
if
we're
on
solid
state
drives.
This
is
a
ridiculous
problem,
so
you
don't
ever
want
to
do
this.
A
I
have
a
slide
in
there
that
actually
shows
you
how
bad
the
framework
is.
There's
something
called
snitch
snitch
is
pretty
convenient.
It
lets
us
distribute
our
data
and
fault
on
our
way.
I
talked
a
little
bit
about
how
we
can
use
multiple
racks
before
one
of
the
things
that
the
stitch
allows
us
to
do.
Is
we
say
I
have
three
racks,
let's
put
only
one
copy
of
my
data
in
each
rack.
A
A
A
The
streaming
protocol,
which
is
what
gets
used
to
introduce
a
new
nerve,
will
change
between
major
versions
and
when
you
try
and
string
a
new
note
in
it
will
just
sit
there
and
it
will
fail.
Repairs
will
also
break
decommissioning,
will
also
open.
The
proper
way
to
upgrade
is
to
shut
a
note
down,
upgrade
it
to
place,
bring
it
back
up
if
you've
got
multiple
racks
and
you
should
then
the
proper
way
to
do
it
is
to
shut
down.
One
rack
upgrade
the
entire
back
at
a
time,
bring
the
entire
back
back
up.
A
A
A
Of
those
things,
that's
a
pain
to
change
after
you've
already
put
this
into
production.
So
all
my
gotchas
are
things
like.
Oh
you
know.
I
didn't
think
this
before
I
watched
my
cluster
and
now
it's
it's
like
a
several
day
process
to
fix
or
hey.
I
have
data
loss
or
hey.
I
can't
delete
stuff
like
what's
going
on
and
you'll
spend
days
like,
I
did
trying
to
figure
out
what
was
going
on.
It's
like,
oh
for
some
reason,
the
server
doesn't
have
a
tpd.
So
why
don't
do
that?
A
So
that's
kind
of
like
this
right.
If
you
do
this-
and
you
upgrade
one
rack
at
a
time
as
long
as
you're
using
the
right,
snitch,
you're,
totally
fine
and
then
the
bigger
your
cluster,
the
more
reliable
it
is
that
you'll
be
fine
with
one
half
at
a
time
because
you
have
ten
racks
like
you
could
lose
100,
clustered
repairs.
B
A
So
when
you
add
a
new
node
into
your
cluster,
it
is
streamed
automatically.
You
don't
have
to
really
worry
about.
Maybe
just
saying
hey,
I
turn
you
on
and
it
goes
hey
give
me
some
data
and
it
gets
together
for
everybody
else
and
it
joins
the
party
and
starts
certain
queries
and
it
tells
the
application
about
it
and
you
don't
need
to
restart
your
app.
A
A
All
right,
shared
storage-
I
don't
know
if
this
has
come
up
at
all.
You
do
not
want
to
run
this
handler
on
a
nas
on
a
sand
on
floppy
drives
over
at
s
on,
like
you,
you
name
it
like
you,
you
want,
you
want
to
use
local
storage.
The
best
thing
you
can
do
is
just
get
solid.
State
drives,
run
locally,
they're
cheap,
well
they're
cheaper
than
they
used
to
be.
A
Option
than
putting
everything
on
snap
putting
up
using
the
sanders
is
ridiculous.
You
would
you
could
have
100
cassandra
nodes
and
have
a
single
point
of
failure
on
your
sound,
like
I,
people
will
have
argued
with
me
that
their
samples
go
down
and,
like
the
next
day,
they're
saying
we're
going
to
have
and
there's
like
a
300
servers.
A
B
A
A
The
other
thing
that
you
have
to
take
into
account
is
that
you're
still
accessing
a
drive
over
the
network,
so
that
latency
is
you
just
have
more
latency
than
you're
ever
going
to
have
whatever
you
talk
to
when
it's
available,
you
always
want
to
do
local
and
thermal
storage.
If
you're
going
to
be
using
the
center
in
arizona
and
even
on
gce
there's
there's
a
local
businesses
with
local,
solid
state
drive
spending
is
a
basic
kill.
A
So
this
is
a
really
useful
thing
to
have
if
you're
using
solids
and
drops,
which
I
can't
recommend
enough-
you
can
kind
of
uncap
this
and
just
let
it
go
nuts,
especially
if
you're
using
level
of
compaction
you
use
a
lot
higher.
But
as
a
result,
your
reads
are
just
crazy.
Fast,
you've
got
a
whole
bunch
of
compaction
options
levels
I
just
mentioned
great
on
solid
state.
Sized
here
is
the
one
that's
been
around
forever
dave
tier
is
the
best
compaction
option
if
you've
got
ttl
time
series
data.
A
A
So
let's
talk
a
little
bit
about
some
diagnostic
tools.
This
will
help
you.
If
something
does
go
wrong.
These
are
tools
that
everybody,
even
non-host
people
should
be
aware
of,
because
they're
just
amazing
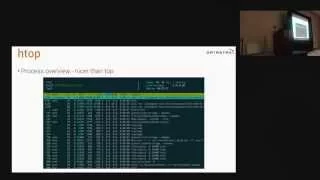
h-top
is
kind
of
like
a
general
purpose
tool.
If
you
know
top,
the
shop
is
a
little
bit
better.
I
know
staff
I
was
thinking
about
actually
taking
this
slide
out
of
here,
because
I
have
staff
can
be
replaced
by
my
two
slides
for
now.
A
A
A
Dstat
is
the
tool
I
just
mentioned.
That
is
the
successor
to
iostat.
I
find
it's
better
in
every
way
imaginable.
You
can
get
a
ton
of
information
about
everything
going
on
in
your
system.
I
recommend,
if
you
are
running
linux,
then
you
should
have
this
installed
on
every
machine
because
you
will
be
able
to
diagnose
so
many
problems
very
quickly.
It
includes
network
memory,
cpu
disk,
it's
just
everything.
It's
fantastic.
A
A
A
Why
is
this
pausing
for
five
seconds?
Like
you
know,
it's
a
problem.
That's
hard
to
solve,
if
you
don't
have
any
insight,
unless
you
annotate
every
single
line,
you
have
a
print
statement
which
is
impactful,
so
you
can
filter
with
the
dash
e
flag,
which
is
really
useful.
If
you
just
want
to
take
a
look
at
I
o
or
network,
and,
like
I
said
you
can
attach
to
a
running
process
or
you
can
start
the
process
with
estrogen
so
in
this
example,
this
is.
A
A
Jstack
is
extremely
useful
if
you
are
looking
at
a
jvm
process
and
you
want
to
know
what
all
the
threads
are
inside
of
it,
where
they
are
and
the
state
the
state
that
they're
in
you
can
use
jstac.
If
you
use
this
on
cassandra,
you'll
get
an
output
of
every
single
thread
that
exists
and
what
it's
doing
so,
if
something
hangs,
you
can
run
jstack
a
couple
times,
take
a
look
at
the
traces
and
understand
where
the
source
code.
This
is.
A
This
is
one
of
those
tools
that,
if
you
want
to
be
on
the
open
source
side
of
things-
and
you
want
to
act
under
sandra,
you
can
take
these
lines
and
match
them
up
to
the
source
that
you're
looking
at
and
figure
out.
If
there's
a
problem,
if
you
want
to
take
a
look
at
your
network
traffic,
let's
say
I'm,
you
know
I
want
to
know
what
packets
pretending,
tcp
jump
is
a
really
useful
tool
you
can
monitor
and
import.
You
can
do
tcp
udp
in
this
mode.
A
A
So
I
was
just
watching
the
queries
that
are
coming
across.
I
don't
like
this
for
not
just
for
december,
but
for
any
application
server
or
just
web
servers
in
general
or
any
database
server.
This
is
this
is
really
nice
whenever
you're
having
connection
problems
and
you're
wondering
like
am,
I
am
I
even
able
to
hit
this
machine
like
you'll,
be
able
to
figure
out?
A
So
if
you
run
nodetool
tv
stats,
tp
stands
for
correctly
and
it
will
show
you
all
the
things
that
are
going
on
with
different
threads
and
it
will
show
you
how
many
of
them
are
blocked.
That's
the
thing
that
you
really
want
to
take
a
look
at,
for
instance,
if
you
have
a
med
table
flush
rider
blocked.
That
means
that
you
either
have
not
enough
clusters
configured
or
your
disks
are
too
slow.
A
If
that
happens,
there's
a
good
chance
that
you're
going
to
hit
garbage
collection
problems,
because
this
is
memory
that
we
need
to
free
by
flushing
data
onto
this.
So
we
have
all
these
flush
drivers
piled
up.
We've
got
all
these
bent
tables
sitting
in
memory
and
garbage
collection
is
going
to
cause
them
to
be
promoted,
and
that
ends
up
resulting
in
more
interesting
problems.
A
If
you
see
drop
mutations,
that
means
you've
got
some
networking
problems
along
the
way
and
then
you're
going
to
need
to
prepare
histogram
is
really
useful.
So
there's
two
on
the
left.
We
see
proxy
histograms.
This
is
the
cumulative
time
that
it
takes
to
serve
a
request,
including
on
any
network
round
trips,
that
you
need.
So,
if
you're
doing
a
consistency,
level
form
this
takes
into
account
the
amount
of
time
that
it
takes
to
get
a
response
from
another
note
as
well,
so
you
can
just
get
your
high
level
reading
times.
A
Cf
histograms
is
a
little
bit
more
useful
if
you've
narrowed
panel
using
proxy
histograms
a
performance
problem
with
a
particular
server,
it's
useful.
Sometimes
you
see
histograms
and
cf.
Histograms
works
on
single
key
space
on
a
single
node
and
it
will
do
is
give
you
a
histogram
of
your
read
write
times
so
you
can
say,
like
you,
can
just
look
at
the
scene
as
little
bump
and
you
go
well.
This
is
where
my
time
spent
and
you
can
narrow
down
400
problems
to
an
individual
key
space
table.
A
A
A
It's
fairly
reasonable
until
you
hit
the
zero
live
and
a
hundred
thousand
tombstones,
and
that's
where
the
time
just
jumps
up
like
crazy.
So
this
is
on.
This
was
on
my
laptop
and
this
was
under
no
real
load.
It
was
just
that's
how
long
it
takes
to
read.
100
000,
so
you
can
guess
how
bad
this
would
be
in
production.
If
I
let
you
do
that,
so
don't
use
cassandra's
cube,
just
show
of
hands
who
here
still
wants
to
use
as
a
kid
success
awesome
all
right.
This
is
the
most
intense
part
of
the
talk.
A
This
is
jvm
garbage
collection,
so,
unlike
a
language
like
c
java
will
perform
automatic
management
forms
and
it's
very
convenient,
but
it
does
cost,
and
that
cost
is
that
every
so
often
frequently
the
jvm
needs
to
scan
all
the
memory.
That's
currently
in
use
and
build
an
object
map
and
determine
if
that
memory
is
still
reachable
what
can
be
freed
and
what
can
be
promoted.
A
A
So
the
two
meat,
the
meat
in
space
once
the
eating
space
is
full.
What
happens
is
we
have
what's
called
a
binary
pc
and
the
mineral
gc
causes
all
the
objects?
First
of
all,
let's
stop
the
world,
so
all
the
threads.
Even
if
you
had
a
million
cores
and
100
million
threads,
they
all
had
to
stop
and
all
the
objects
from
youtube
are
looked
at
and
some
of
them
are
going
to
be
promoted
out
of
the
survivor
generations
and
then
a
bunch
of
them
are
going
to
be
prohibited
from
eating
into
survival.
A
If
there's
not
enough
space
in
a
survivor,
then
all
the
extra
spillover
gets
moved
into
the
vulture.
One
thing:
that's
really
important
to
keep
in
mind
here
is
that
copying
objects
in
the
jvm
is
very
slow.
If
you
have,
let's
say
you
create
a
ton
of
temporary
objects
and
none
of
them
need
to
be
promoted.
It's
actually
very
fast,
you'll
see
like
an
l-sided
pause,
but
if
you
have
a
huge
new
jam,
then-
and
all
that
needs
to
be
promoted,
that's
not
going
to
be
fast,
it'll
be
pretty
slow.
A
A
So
then
we
have
our
old
gem
objects
that
have
been
promoted
from
new
gen
sit,
the
old
gen
and
there's
a
process
called
major
gc
and
major
gc
is
a
mostly
concurrent
process
and
it's
just
constantly
scanning
through
and
it's
doing,
two
short
pauses
called
mark
and
remark.
What
they
are
is
one
takes
a
look
at
all
the
objects
that
even
determines,
if
they
point
and
maybe
not
just
the
old
gen-
that's
that's
it.
It
unpauses
draws
the
object.
A
Graph
pauses
determines
if
those
objects
are
still
reachable
and
then
cleans
up
anything
that
we
don't
need,
and
so
this
isn't
so
bad.
These
are
constantly
happening
and
they
shouldn't
really
impact
performance
on
your
system
too
much
now,
the
big
problem
comes
when
you
fill
up
your
whole
chat
and
you
get
a
full
gc,
so
full
of
gc
is
pretty
much
the
worst
thing
to
have
in
your
application.
It
might
as
well
not
be
on
anymore,
because
it's
going
to
pause
for
like
30
seconds
that
we
can
effectively
call
the
system
again
at
this
point.
A
If
the
new
gen
is
completely
filled
up
or
objects
can't
be
promoted.
What
we'll
do
is
it
will
do
a
couple
of
things.
One
will
collect
all
generations,
and
that
means
like,
if
you
had
an
akt,
has
to
look
through
everything
in
the
stop
the
world,
and
it's
actually
also
going
to
be
it's
going
to
defragment
the
memory
as
well,
and
that
is
really
ridiculous.
So
it's
going
to
just
copy
your
tongue
here,
you
don't
want
to
hit
these.
A
So
if
you
have
a
right,
heavy
workload,
objects
that
are
going
to
be
promoted
in
the
most
event
tables
and
the
problem
that
you
can
run
into
is
if
your
new
gen
is
too
big
you're
going
to
have
these
tables
that
are
sitting
there
and
you're
going
to
have
a
pause,
and
it's
going
to
promote
all
this
stuff
and
remember,
copying
is
slow
in
fact
it's
ridiculously
slow.
So
what
happens?
A
Is
you
promote
all
this
stuff
and
you
have
a
really
long
stoppage
like
I've
seen
400
milliseconds,
that's
400,
milliseconds
that
if
you
started
a
query
and
you
expected
it
to
be
two
milliseconds
and
you
just
happen
to
catch
it
right
in
the
middle
you're,
going
to
take
four
through
two
milliseconds
to
cancel
this
query.
It's
very
very
frustrating
to
get
these
long
pauses.
A
The
second
workload
that
I
want
to
talk
about
is
our
weekend
and
the
read
heavy
workload
is
the
complete
positive.
So
when
I
read
a
bunch
of
data
out
of
this
handler,
I'm
expecting
that.
Maybe
I
have
a
few
milliseconds
and
I
read
a
bunch
of
stuff
off
disk.
I
send
it
out
over
the
network
and
then
I
don't
even
think
about
it
right.
These
are
these
objects
to
be
collected.
A
So
if
we
have
a
really
really
small
new
gen,
what
happens
is
we've
got
this
really
heavy
workload.
That's
creating
tons
of
temporary
objects
in
memory,
but
this
is
getting
filled
up
so
quickly.
It
goes
up
nope.
We
have
to
stop.
Let's
promote
everything,
so
you've
got
these
objects
that
are
constantly
being
promoted
into
your
old
gym
that
don't
belong
to
them
and
then
they're
also
being
promoted
so
frequently
out
of
new
generator
old
jam
fills
up
and
you
end
up
with
full
gc's.
A
So
this
this
re-heavy
workload
will
result
in
lots
of
full
gc's,
which
has
become
are
terrible
so
to
understand
what
is
happening
from
a
garbage
collection
point
of
view.
I
recommend
a
tool
called
jstab
jstaff,
combined
with
a
flag
called
gc
tilt,
pass
in
the
process
id
the
number
of
milliseconds
to
interval
and
then
account
we'll
show
you
at
that
interval
what
the
state
is
of
garbage
electronic
mission.
So
you
can
look
here
and
you'll
see
the
different
survivor
generations,
eaton
old,
gym.
A
A
So
this
is
what
happened
when
we
tuned
garbage
collection,
or
we
moved
to
the
jvm.
In
my
last
company,
we
saw
an
almost
tenfold
increase
in
performance
on
our
cassandra
cluster,
so
this
was
a
screenshot
that
we
took.
I
mean
the
number
of
top
like
at
the
top
of
the
graph
was
ridiculous,
like
we're
talking
almost
30
milliseconds
for
operation,
because
we
were
seeing
so
much
pause
and
then
they
already
know.
I
mean
we're
on
solid
state
drives
whereby
why
is
it
taking
20
milliseconds?
A
A
A
Without
a
doubt,
it's
a
oh,
like
really
because
you're
doing
some
api
calling
here's
some
like
a
random
website
that
happens
to
be
out,
like
that's
pretty
sure,
it's
not
standard,
so
you
want
to
go
and
monitor
this
stuff
right.
You
need
to
put
those
metrics
in
place,
so
so
you
can
graph
everything
and
look
at
the
rate
of
failures
that
are
happening
in
your
system.
A
If
you
do
think
it's
top
centering
or
if
you
do
think
it's
cassandra,
you
should
check
awesome
off
center
is
going
to
give
you
information
immediately.
How
many
nodes
are
down?
What
is
the
jvm
profile?
Look
like
you'll
have
very,
very
good
information
as
to
whether
or
not
something
has
changed
in
the
last
day
or
whatever,
and
that
should
lead
you
down
towards
the
path
of.
A
Maybe
maybe
I
have
to
fix
this.
Do
we
have
slow
queries,
it's
possible
that
your
data
model
is
incorrect.
It's
possible
you're
using
the
wrong
compaction
strategy.
You
need
to
look
at
your
system
stats,
it's
possible
that
you're
just
seeing
lots
of
jvm
pauses
and
that
there's
nothing
wrong
with
all.
It
just
happens
that
you
only
bigger
bigger
new
chain
size.
A
So
you
take
a
look
at
the
histograms
query
tracing
and
you
should
be
able
to
pinpoint
if
it's
an
individual
query,
it's
an
individual
table
or
if
it's
a
garbage
collection
or
just
a
misconfigured
server
or
a
dead
disk.
All
this
stuff
should
be.
You
should
be
able
to
diagnose
this
stuff
very
quickly.
If
you
put
the
right
metrics
in
place.