►
Description
Speaker: Luke Tillman
Company: DataStax
Relational systems have always been built on the premise of modeling relationships. As you will see, static schema, one-to-one, many-to-many still have a place in Cassandra. From the familiar, we’ll go into the specific differences in Cassandra and tricks to make your application fast and resilient.
A
I'm
running
a
little
bit
behind
so
so
I'm
going
to
go
ahead
and
get
started
and
they
asked
me
to
tell
everyone
if,
if
you
have
an
empty
seat
next
to
you
like,
if
you
guys,
I
don't
know,
if
there's
still
people
at
the
back,
that
don't
have
table
space.
But
if
you're
like
raise
your
hand
if
you've
got
another
seat
next.
A
So
come
check
that
out,
if
you
would
like,
so
I
got
them
wanted
after
lunch
speaking
slot
when
everyone
wants
to
be
in
a
food
coma.
So
I'm
pretty
excited
about
this.
This
is
also
the
first
time
that
I've
ever
given
the
internet
modeling
talk.
Normally
my
boss,
patrick
mcdaddy,
used
their
chief
evangelist
for
cassandra
at
datastax.
A
Is
relational
data
modeling
so
earlier
it
seemed
like
everybody,
or
almost
everybody
probably
had
a
background
in
relational
databases.
They've,
you
know,
maybe
use
them.
So
I
want
to
just
talk
at
a
basic
level
like
what
are
some
of
the
differences
between
between
cassandra
and
relational
database.
What
are
some
things
you
can
do
now
we'll
talk
about
just
basic
data
modeling
with
cassandra
a
couple
of
common
sort
of
techniques
that
we
see
people
use
or
patterns.
A
You
know
that
people
use
when
they're
data
modeling
cassandra,
we'll
talk
about
cql
collections
a
little
bit
because
that's
kind
of
a
cool
feature
of
cassandra
that
you
know
that
you
don't
have
in
the
relational
database
world
so
kind
of
an
interesting
thing
to
talk
about
I'll.
Show
you
some
syntax.
That
kind
of
thing
then
we'll
talk
about
modeling
relationships.
So
you
know
just
because
you're
using
cassandra,
which
is
not
a
relational
database,
doesn't
mean
that
your
data
is
not
still
going
to
have
relationships,
so
you're,
probably
wondering
okay.
A
How
do
I
model
stuff
like
that?
So
we'll
take
a
look
at
that
a
little
bit
and
then,
lastly,
we'll
finish
up
with
the
time
series
data
use
time.
Series
data
model
use
case
so
consider
is
very,
very
popular
with
people
that
have
time
series
problems.
So,
if
you
think,
like
internet
of
things
type,
you
know
like
I've
got
lots
of
sensors,
giving
me
readings
or
lots
of
readings
coming
in
from
all
these
different
places.
A
A
At
this
point
right,
so
we
mentioned
third
normal
form
or
higher.
You
know.
Everybody
kind
of
that's
working
relational
database
knows
this.
Also,
this
idea
of
acid
guarantees
right
so
atomicity
consistency,
isolation,
durability.
It
makes
it
really
easy
for
developers
to
kind
of
reason
about.
What's
going
on,
you
know
what
data
and
what
kind
of
guarantee
do
I
have
and
get
data
out
and
what
kind
of
guarantees
and.
A
A
All
these
kind
of
things
are
available
in
vu
with
sql,
so
I
just
wanted
to
give
you
an
example
of
a
relational
data
model.
So
so
this
is
a
pretty
simple
one
right:
we've
got
employees
and
we've
got
departments
and
as
employees
join
the
company
right.
This
is
some
data
tax
employees,
they're
gonna
join
the
company
as
a
member
of
the
department,
and
so
we've
got
two
different
tables,
and
so
you
know
john
and
myself
were
department
id
201,
which
actually
points
at
the
evangelists
row
in
the
department's
table.
A
A
This
example
that
I
have
down
the
bottom
left
corner
just
an
example
of
an
sql
join
right,
so
you
think
about
kind
of
like
the
thought
process
that
you
go
through
when
you're
when
you're
doing
a
relational
data
model,
and
you
tend
to
kind
of
start
with
the
data.
What
are
the
things
that
I
have
in
the
system
right,
so
I've
got
employees
and
I've
got
departments
right
and
then
you
kind
of
have
this
prescribed
way
of
modeling
right.
I've
got
data,
I've
got
you
know
this
third
normal
form
or
higher.
A
So
how
do
I
take
this
data
that
I
have
in
my
system
and
how
do
I
divide
it
out
so
that
I
get
it
in
the
third
normal
form
or
higher?
So
I
don't
duplicate
data.
You
know,
I
don't
make
everything
very
normalized
and
then
lastly,
kind
of
the
last
thing
that
you
think
about
when
you're
in
your
data
mining
is
really
okay
and
now
it's
time
to
build
an
application.
A
What
kind
of
queries
am
I
going
to
run?
You
know
like
you
know
what
are
the?
What
are
the
actual
queries
that
I'm
going
to
do?
How
do
I
need
to
access
this
data
in
my
application
and
that's
when
the
flexible
query
language
stuff
like
joins,
and
things
like
that
really
are
kind
of
nice
right,
because
it's
kind
of
the
last
thing
you
think
about
it,
so
you
can
take
these
normalized
data
models
and
kind
of
join
the
disparate
data
together
to
get
it
out
the
way
that
your
application
needs.
A
What
you'll
find
with
cassandra
data
modeling
when
you
go
down
down
this
path,
is
that
it's
actually
almost
the
opposite
right
so
with
cassandra
data
modeling
is
very
query
driven,
so
a
lot
of
times
you're
going
to
start
with
the
application.
You
can
start
thinking.
Okay.
What
is
this
application
that
I'm
building?
What's
it
going
to
do?
How
is
it
going
to
access
the
data?
A
What
queries
am
I
going
to
need
to
run
and
from
that
those
the
answer
to
those
questions?
That's
when
you
go
when
you
build
models,
you
build
tables
to
actually
answer
those
queries
and
then,
lastly,
you
kind
of
worry
about.
Okay,
what
data
like?
How
am
I
going
to
get
the
data
into
these
models
that
I
just
built
to
be
able
to
answer
my
queries,
so
it's
very.
A
A
In
cql,
because
there
are
certain
things
that
just
don't
scale
across
a
big
distributed
database,
the
way
that
they
can
work
on
a
single
machine
right.
So
a
good
example
is
joints.
You
don't
have
joins
in
cql
and
you
don't
have
aggregations.
You
can't
do
sub
selects
that
kind
of
some
of
that
flexibility
that
you
use
like
whether
you
that
you
have
in
sql
and
query
time
you
don't
have
in
cql,
because
they
just
honestly
just
don't
scale
right
across
the
distributed
system.
A
A
So
what
we
would
do
with
with
this
example
here
is.
We
would
have
a
single
table
right,
so
we're
going
to
write
the
data
into
a
single
table.
The
way
that
we
need
to
read
it
out.
So,
instead
of
having
two
different
tables,
employees
and
departments
we're
going
to
have
a
single
employees
table
with
the
id
by
id
there,
and
it's
got
the
first
and
last
name
of
the
employees
and
it's
got
their
department
in
it
right.
So
now
there's
no.
B
A
A
Little
bit
earlier
in
our
introduction
talk
is
this
idea
of
sequences
and
audio
incrementing
ideas.
Anybody
going
to
use
a
sequence
or
an
auto
implementing
id
in
a
relational
database
for
a
single
sequence
is
a
pretty
popular
way,
so
so
these
are
great
for
letting
the
blending
of
database
sort
of
handle
auto-generating
ids
right.
So
hey
give
me
so
this
is
definitely
here
we're
inserting
into
the
employees
table
and
we're
saying
give
me
the
next
unique
value
that
you
know
that
hasn't
been
used
for
this
new
employee,
patrick
mcfadden
and
they're
guaranteed
to
be
unique.
A
A
The
other
thing
you
do
is
you
want
to
use
certain
keys.
Instead,
you
would
use
uuids
instead
of
integers,
so
uuids
you've
never
seen
these.
This
is
a
guide
for
dot-net
folks,
if
you're
like
being
a
diamond
guy,
I
don't
know
why
we
needed
universally
unique
identifier
versus
globally
unique
identifier,
but
we
have.
A
Number,
it
looks
something
like
this:
it's
represented
in
the
character
form
and
these
can
be
generated
on
the
client
side.
So
just
about
every
programming
language
I
mean,
I
don't
know
everyone
that
I'm
aware
of
has
some
sort
of
library
or
something
built
into
their
base
class
libraries
for
generating
uu
ids.
So.
A
Okay,
so
so,
let's
talk
a
little
bit
about
sort
of
the
basics
of
some
of
the
basic
techniques
and
things
that
we
see
in
that
standard.
So
again,
just
to
reinforce
this,
you
know
kind
of
flip
it
on
its
head
from
from
relational
databases,
you
want
to
start
with
the
application.
You
want
to
start
with
your
queries.
A
B
A
Table
and
I'm
going
to
be
looking
users
up
by
id
pretty
common
thing
so
anytime,
I've
got
this.
This
idea,
where
I
need
to
look
something
up
by
id.
You'll,
probably
see
a
see
a
padding
like
this,
so
we're
using
uuids
you'll
notice
as
the
primary
key
here.
It's
a
simple
primary
key.
It's
just
got
one
column,
it's
the
it's
the
first
and
only
part
of
the
of
the
primary
key,
and
you
can.
A
Looks
like
right!
So
if
I
want
to
select
the
first
name
and
last
name
for
a
given
user,
pretty
simple
right,
exactly
what
you
do,
what
you
expect
and
just
a
reminder,
kind
of
going
back
to
our
talk
this
morning.
Remember
that
the
first
and
and
in
this
case
only
part
of
the
primary
key
is
the
partition
right,
and
this
is
responsible
for
distributing
data
around
the
cluster.
A
So
let's
talk
about
more
complicated
scenarios,
so
we
kind
of
showed
a
similar
example
to
this.
You
know
in
our
demonstration
during
our
first
talk
this
morning.
So
let's
say:
we've
got
comments
by
video,
so
let's
say
we're
building
a
site
like
youtube
and
I'm
actually
going
to
talk
later
this
afternoon,
I'm
going
to
show
you
sort
of
a
youtube-like
site
that
we
built
that
you
can
kind
of
check
out
as
an
example
project
and
see
as
a
schema.
So
that's
where
these
these
examples
actually
come
from.
But
let's.
C
A
We're
building
youtube,
and
so
we've
got
this
site
and
people
can
upload
videos
and
then,
when
they
upload
videos,
other
users
can
comment
on
them.
Like
I'm
sure,
everybody's
probably
spent
some
time
on
youtube
right
at
this
point
in
their
internet
lives.
So
you're
going
to
find
the
comments
for
a
given
video
right
so
on
the
ui,
where
you're,
showing
the
video
you're
probably
going
to
want
to
show,
like
maybe
the
10
latest
comments
posted
by
by
users
right
so.
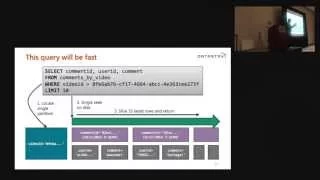
A
That
table
might
look
like,
so
you
can
see,
we've
got
kind
of
a
more
complicated
primary
key
and
you
can
see
what
the
query
would
look
like
to
actually
select.
Maybe
the
10
latest
comments,
so
I
kind
of
want
to
break
this
down.
This
create
tables
taken
down
kind
of
point
out
a
few
different
things
like
what's
going
on
here,
to
illustrate
a
little
bit
about
computer
data.
A
So
first,
let's
talk
about
this
common
type
column
here
in
the
comments
by
video
table.
So
it's
a
tiny
uid
if
you've
never
seen
this
before.
I
know
it
was
new
to
me
when
I
first
started
using
cassandra
because
in
you
know
I
was
a
backup
programmer
for
a
really
long
time.
We
don't
have
a
base.
We
don't
have
a
base
class
library
type
like
this
in
java,
I'm
pretty
sure
they
have
a
time
to
uid
class,
but
so.
A
It's
a
valid
uuid
or
good
for
microsoft,
people,
but
it's
generated
with
a
timestamp
component.
So
when
I
generate
a
tiny
uuid,
what
actually
comes
out
is
a
totally
valid
uuid
that
looks
like
they're
in
the
operating
corner
there,
but
I
generated
I
provide
a
time
stamp
or
if
you
don't,
a
lot
of
a
lot
of
libraries
will
actually
generate
one
using
the
current
system.
A
Time
and
the
cool
thing
about
the
tiny
uib
is
that,
even
though
it's
a
valid
uuid,
it
has
this
time
stamp
sort
of
embedded
in
it,
and
then
I
can
do
stuff
like
order
on
it,
and
it's
basically
like
ordering
on
the
timestamp
that
was
used
to
generate
it.
So
I
can
actually
order
by
a
time
uuid
and
have
things
ordered
temporarily
from
say
you
know,
newest
oldest
or
vice
versa,
right.
A
So
a
tiny
new
idea
to
kind
of
point
out
what
that
data
type
means.
We've
got
the
primary
keys,
so
we
decided
that
video
id
combined
with
the
comment
id
those
two
things
together
are
going
to
uniquely
identify
a
comment
on
a
video.
Then
the
first
part
of
this
primary
key
is
the
partition.
Key,
so
that
means
that
for
a
given
video
id
we're
going
to
store
all
the
comments
for
that
video
together
in
partition.
So
on
one.
C
A
Going
to
be
talking
to
a
single
node,
and
thus
the
query
will
be
fast
right,
because
we're
only
talking
a
single
node
instead
of
multiple
nodes
and
then
the
second
part
of
the
primary
key.
In
this
case,
we
only
have
a
single
clustering
column,
but
you
could
have
more
than
one,
but
the
second
part
of
the
primary
key
in
this
example
is
comment.
Id
and
so
inside
of
the
partition,
we've
decided
comments.
For
again,
a
video
will
be
ordered
by
the
comment
type
either
to
be
clustered
by
the
comment.
A
Id
and
remember,
because
comment
id
was
a
tiny
uid,
basically
we're
ordering
by
time
ordering
by
timestamp.
So
this
is
where
the
hey
give
me.
The
the
ten
latest
comments
you
know
of
our
query
comes
up
so
then
the
last
thing
to
point
out
is
this:
with
clustering
order
by
clause,
so,
basically,
with
clustering
order
by
is
just
providing
a
default
ordering
to
cassandra
we're
telling
sandra
hey
when
you
store
these
records,
store
them
in
common
id
descending
order
right
so
store
the
newest
ones.
A
Because
we
decided
in
our
query,
we
said
hey
when
we
show
these
on
the
screen
we
actually
want
to.
Have
you
show
you
the
10
latest
ones?
First
and
then
maybe
we'll
have
some
sort
of
ui
or
they
can
kind
of
page
back
into
time
and
see
older
comments,
but
since
we're
always
going
to
be
querying
them
in
that
order,
sort
of
descending
order.
Why
don't
we
just
take
advantage
of
this
and
have
it
stored
in
that
order
as
well,
because
that'll
be
faster?
A
So
if
you
want
to
kind
of
think
about
this,
conceptually,
like
you
know,
what's
what
it
kind
of
looks
like,
maybe
on
disk
a
little
bit
inside
the
single
partition.
So
you
can
see
on
the
left
and
bottom
left
here.
We've
got
a
single
video
id,
a
single
partition
key
and
then
we've
got
the
rows
laid
out
next
to
each
other.
A
So
we've
got
the
comment,
id
kind
of
grouping
there
in
the
comment
data
and
you
can
see-
I
pulled
the-
I
pulled
the
timestamp
out
of
the
time
uid,
just
to
kind
of
show
that
hey
we're
ordering
things
from
newest
comment
back
in
time.
To
oldest
comments
as
we
go
down
the
partition,
and
so
why
is
this
query
fast
like
so
we
go
back
to
our
query
again,
so
we've
got
where
video
id
equals,
which
is
going
to
give
us
locality,
so
we're
only
talking
to
a
single
partition.
A
So
that's
going
to
be
that's
going
to
be
fast,
then
we're
going
to
be
doing
a
single
sequin
disc,
to
find
you
know
the
first
row
in
the
partition
and
then
cassandra
could
just
slice
the
10
rows,
the
10
lightest
rows
or
if
there's
less
than
10,
maybe
give
us.
You
know
five
rows
if
there's
only
five
commas
and
return
that
data
back
to
us.
So
that's
going
to
be
a
fast
query
inside
of
cassandra.
A
So
how
do
I
get
you
know?
You
know
what
what
are
some
guidelines?
I
guess
for
for
getting
the
most
out
of
your
queries
or
getting
you
know,
making
sure
that
your
queries
are
fast.
So
you
can
remember
that
partitioning
keys
queries
on
the
partition
key.
Those
are
always
going
to
be
fast,
so
that
example,
I
just
showed
you
where
video
id
equals
I'm
providing
a
value
for
the
partition.
A
Key,
that's
always
going
to
be
fast
and
the
fewer
partitions
we
have
to
talk
to
the
fewer
nodes
are
potentially
involved
in
the
query,
and
so
you
know
fewer
nodes,
less
latency
going
to
be
faster,
so
your
goal
should
always
be
to
you
know,
be
doing
a
query
in
as
few
partitions,
particularly
one
partition.
If
you
can,
if
queries
on
the
partition
key
and
then
optionally,
one
or
more
clustering
columns,
those
will
also
be
fast.
A
For
that
video
between-
I
don't
know
december
1st
and
january
31st,
or
something
like
that,
we
could
have
done
a
range
query
right
on
that
clustering
column,
because
common
id
is
actually
a
time
stamp
and
that
would
have
been
quick
as
well.
So
we
could
have
done.
We
could
do
kind
of
slice
queries
so
again
inside
a
single
partition.
A
If
possible,
you
should
always
try
and
restrict
to
a
single
partition
in
an
optional
clustering
columns,
and
if
you
try
to
stray
from
this,
so
if
you
try
to
use
you
know
a
select
statement
and
you
try
to
include
some
other
column-
that's
not
a
partition,
key
or
a
clustering
column.
In
your
where
clause,
for
example,
cassandra
will.
B
A
Errors
back
so
it
tries
to
push
you
towards
things
that
will
scale.
That's
you
know,
kind
of
why
we
data
model
in
this
particular
fashion,
and
so,
if
you're
like,
if
you've
got
dev
center,
open
or
something
or
you've,
got
cqlsh
open
and
you're
kind
of
running
queries,
you're,
creating
tables
just
trying
things
out,
seeing
what
works
and
what
doesn't
work
and
you
start
getting
errors
back.
Sometimes
it
can
be
helpful
to
think.
Okay,
what's
really
going
on,
you
know
you
can
you
know
think
of
things
like
this,
like.
A
What's
going
on
really
with
the
you
know,
with
this
table
that
I'm
building,
how
is
the
data
being
distributed
around?
How
is
how
are
things
being
you
know
being
organized
inside
a
partition?
Why
would
you
know
why
would
cassandra
not
be
allowing
me
to
run
this
query?
Why
would
this
query
not
be
fast?
A
So
the
last
thing
I
want
to
talk
about
before
we
take
a
few
questions.
Is
this
idea
of
more
than
one
way
to
query
data
right
so
a
lot
of
times
you'll
have
you'll
be
in
the
scenario
where
hey
I've
got
two
different
ways
of
looking
at
the
same
data,
so
we
just
showed
you
the
example
of
the
example
of
showing
comments
by
videos,
so
location
in
the
10
latest
comments
for
a
given
video
on
our
site.
A
What
if
we
also
had
a
screen,
like
maybe
a
user
profile
screen,
or
something
like
that,
where
we
showed
the
10
latest
comments
posted
by
a
given
user?
So
it's
the
same
comment
data
just
looked
at
from
the
user
perspective,
as
opposed
to
looking
at
it
from
my
video
perspective,
and
so
you
might
end
up
with
a
table
like
this.
A
If
you're
doing
a
query
where
you
find
the
latest
comments
for
a
user
and
you'll
notice
that
these
look
like
very
similar,
so
if
you
put
them
next
to
each
other,
actually
you
take
the
two
tables
and
put
it
next
to
each
other.
They
look
really
really
similar
the
difference
being
here
that
the
primary
key
is
different
right.
So
I've
got
one
one.
That's
the
primary
key
of
user
id.
A
A
This
is
where
batches
come
into
play,
so
we
talk
about
log
batches
and
when
I
do
an
insert,
when
somebody
adds
a
comment
to
the
site,
then
I'm
going
to
probably
use
a
batch
of
cassandra
to
insert
into
both
tables
at
the
same
time,
so
that
I
get
that
that
guarantee
that
either
both
of
the
rights
will
succeed
or
neither
of
the
rights
will
also
see
that's
what
batches
are
foreign
normalization
or
duplication
of
your
data
and
you're
going
to
normalize
at
the
right
time.
So
that
then
come
every
time.
A
B
D
Is
that
the
the
use
cases
are
not
completely
fleshed
out
in
the
application
that
we
are
building
with
the
software
networking
space
for
some
layer,
two
layers
on
their
zero
based
applications?
So
we
do
have
the
streaming
layer
and
we
do
have
some
use
cases
to
work
with.
However,
since
this
is
such
a
new
field,
we
don't
have
the
use
cases
coming
up
in
the
example
that
you
just
showed
which
so
now
we
have
one
view
today.
It's
conceivable
that
we
have
a
slightly
different
view,
maybe
six
months
online
or
yeah
sure.
A
So
if
you're
asking
so,
you
can
absolutely
add
new
tables
as
you
go
along,
I
mean
it's
best
to
do
as
much
analysis
upfront
as
you
can,
but
the
reality
of
the
situation
is
yeah.
You're
gonna,
you
know
at
some
point
in
your
application,
you're
gonna
say:
oh
yeah
there's
some
new
way.
We
need
to
look
at
that
data.
You
know,
so
what
I
usually
tell
people
is,
if
they're
trying
to
sort
of
migrate
their
existing
data
and
they
need
to
take
a
look
at
it
in
a
different
way.
A
This
is
something
where
spark
is
really
really
good
at
doing
so,
you
write
it
down.
You
can
do
a
smart
job.
Take
the
pull
the
data
out
of
the
existing
table,
dump
it
into
your
new
table
that
we
just
created
right,
there's
a
ticket
right
now
for,
if
you're
used
to
having
in
in
the
relational
database
world.
A
We
have
this
create
table
as
select
capability
where
it's
like,
create
a
table
based
on
this
select
statement,
so
basically,
it'll
select
made
out
of
the
you
know
out
of
an
existing
table
and
dump
it
into
this
new
table
that
you're
creating
kind
of
thing
and
kind
of
having
the
database
migrate.
The
data
for
us
there
is
a
ticket
for
casino,
that's
open
for
one
of
the
3.0
or
3.1
versions,
where
we
might
actually
get
that
capability
sandra.
A
A
A
A
It's
all
the
exact
same
columns,
so
it's
basically
building
tables
making
duplicates
of
your
data,
the
different
ways
that
you
need
to
view
with
the
different
ways
that
you
need
to
query
it
now,
if
you're,
in
a
scenario
where
you're
kind
of
like
who
knows,
I'm
gonna
have
to
query
this,
or
I
may
like
need
to
have
search
like
people
may
need
to
search
on
a
bunch
of
different
ways.
You
know
to
query
that.
That's
where
stuff
like
solar
can
come
in,
you
know
having
something
that
actually
does
search
on
top
of
that.
A
A
F
C
F
If
someone
was
to
use
the
universal
identifier
for
partitioning
it
almost
seems
like
you
have
to
have
the
burden
of
also
knowing,
at
the
time
of
the
data
model,
how
that
universal
identifier
will
actually
be
created
and
what
it
looks
like
in
order
to
truly
be
as
efficient
as
possible.
When
choosing
the
right
partitioning
key
well
selected.
A
The
uuid,
you
know,
I
mean
you're,
going
to
choose
a
partition
key
you're,
trying
to
I
mean
you're,
going
to
have
partitions
of
different
sizes.
That's
a
certain
reality,
but
like
the
goal,
is
to
try
and
get
your
partition
to
the
same
size
like
so.
The
goal
is
to
try
and
make
the
you
know
to
try
to
be
efficient
and
put
it
as
efficient
as
possible,
so
kind
of
try
to
spread
the
data
around
as
easily
as
you
possibly
can,
with
a
uuid
being
random.
A
D
A
A
F
A
I
mean,
I
would
think
that
I
think
conceptually
you
need
to
know
like
you
know,
so
what
are
the
things
that
are
going
to
be
in
the
system?
So,
like
you
know
an
example
of
our
video
sharing,
it's
like
we're
going
to
have
users
we're
going
to
have
videos
and
we're
going
to
have
comments
and
the
user
is
going
to
have
a
first
name.
A
A
Collections,
this
is
a.
This
is
a
feature
that
you
don't
actually
have
in
relational
databases.
This
idea
of
a
collection
as
a
column
type,
so
cpl
collections,
we've
you've
seen
some
of
the
common.
In
fact,
I
think
john
included
those
collections
of
data
types
on
the
data
type
slide
in
the
intro
this
morning.
So
you've
seen
things
like
you
can
have
an
integer.
You
can
have
a
uuid,
you
can
have
a
text
column.
You
know
these
these
kind
of
basic
data
types
that
you're
used
to
from
relational
databases.
A
A
Syntax
is
very
different
from
the
insert
syntax
a
lot
of
times,
so
I'm
going
to
show
you
the
I'm
going
to
show
you
examples
of
all
of
the
collection
types
and
the
syntaxes
for
kind
of
inserting
and
modifying
and
whatnot,
and
then
reads
when
you
do
reads
of
cql
collections.
This
requires
the
entire
collection
to
be
read
into
memory,
cassandra,
which
is
always
the
most
efficient
thing.
So
even
if
you
just
need
to
get
say
one
value
out
of
a
you
know,
one
value
out
of
a
collection
alexander.
A
It
has
to
read
the
entire
collection
into
memory
before
it
can
get
that
one
value
for
you.
So
so
that's
something
to
keep
in
mind
as
well,
when
you,
when
you
go
down
the
path
of
collections,
so
here's
we're
gonna
start
with
cql
sets.
So
this
is
just
like
a
asap.
That's
in
your
programming,
language
of
choice,
your
favorite
programming
language.
A
So
this
up
top
here
is
the
example
of
what
the
syntax
looks
like
in
your
in
your
create
table
statement
to
actually
define
one
of
these.
So
we've
got
a
set
underscore
example:
column.
It's
got
a
collection
type
of
set
and
then
you
can
see
we're
using
angle
brackets.
So
this
looks
a
lot
like
generics
and
java,
where
we've
actually
got
the
type
of
item
in
our
set
inside
of
the
angle
brackets.
A
So
here
we're
storing
a
set
of
text,
so
I've
got
an
insert
example
here
and
just
for
all
these
all
these
collections
examples
that
I'm
gonna
give
I've
got.
This
collections
example
table
and
it's
got
an
id
of
integer
in
real
life.
Of
course
you
wouldn't
use
integers.
You
would
probably
use
a
uuid
or
something
as
your
as
your
primary
key,
but.
A
C
A
And
cassandra
uses
a
sorted
set
internally,
so
it's
sorted
based
on
the
cql
type
of
the
item.
So,
for
example,
if
I
insert
patrick
john
and
luke,
what's
actually
going
to
happen,
is
cassandra's
going
to
store
them
alphabetically
because
I
use
text
as
my
c2l
type.
So
it's
really
going
to
come
out
as
john
luke
and
patrick.
If
I
were
to
select
the
back
out
of
cassandra,
here's
what
it
looks
like
to
modify
a
set
so
adding
an
element
and
removing
an
element
from
a
set.
A
You
can
see
we're
setting
the
set
example
column
equal
to
itself,
plus
some
new
item,
we're
adding
rebecca's
to
the
set
or
removing
an
element.
If
I
wanted
to
remove
my
name
from
the
set,
I
would
do
the
set
setting
or
score
example
equal
to
itself
minus
some,
some
value
notice
that
we're
using
curly
braces
for
for
sets
as
well
lists.
A
C
A
Are
just
like
sets:
they've
got
a
single
kind
of
values
stored
in
them.
They
are
sorted
by
insertion
order,
though,
and
they
also
allow
duplicates.
So
this
is
just
like
lists,
so
you're
also
used
to
from
you
know,
programming
language
of
choice
with
caution,
so
we
generally
tell
people
to
stay
away
from
lists
if
they,
if
they
can.
C
A
Sets
and
maps
which
I'll
show
you
maps
last.
Those
are
okay.
The
problem
with
lists
is
because
they
allow
duplicates
like
you
could
have
two
writers.
You
can
run
into
concurrency
issues.
Basically,
you
can
have
two
writers
like
inserting
a
value
like
both
trying
to
insert
some
value
into
a
list,
and
they
could
both
succeed
right.
You
could
have
end
up
with
two
copies
of
the
same
data,
whereas
with
sets
and
maps,
if
I
try
to
do
an
insert
at
the
same
time,
you
know
with
the
same
amount
of
data.
A
A
The
difference
in
syntax
is
square
packets
instead
of
curly
braces.
So
when
you're,
inserting
you'll
use
square
brackets-
and
the
other
thing
to
know
about
this
is
that
it's
since
it's
sorted
by
insertion
order,
my
my
entries
are
just
going
to
be
they're
going
to
come
out
exactly
the
way
I
just
inserted
them.
C
A
A
A
Name
and
then
we
use
brackets
along
with
the
key
in
it,
so
we're
setting
set
or
mechanic
equal
to
29..
I
don't
know
if
she's
actually
trying
to
she
is
for
this
example.
If
you
want
to
update
an
example
same
syntax,
so
so
update
that
example,
we're
saying
john
had
a
birthday
sent
him
to
34
instead
of
33
and
then
removing
an
element.
This
is
this.
A
One
is
a
little
funky,
so
it's
using
the
delete
statement
in
cql,
as
opposed
to
an
update,
like
you
saw
with
the
other
ones,
so
delete
map
example
following
and
I'm
deleting
myself
from
this,
so
sequel
collections,
I'm
going
to
talk
about
them
again
in
my
last
talk
of
the
day,
but
keep
those
in
mind.
You
have
them
available
to
you.
If
you
have
a
collection
of
related
things
and
you
want
to
store
them
in
a
column
on
your
on
your
table,
you
have
this
tool
available
to
you.
A
So
let's
go
back
to
relationships,
so
we
showed
this
example
at
the
beginning
of
the
talk
where
we
had
departments
and
employees-
and
this
was
a
good
example
actually
of
a
one-to-many
relationship.
So
a
lot
of
people
get
into
cassandra
and
they're
like
hey.
This
isn't
a
relational
database
but
yeah.
My
data
still
has
relationships
so.
C
D
A
A
A
What
about
if
we
wanted
to
look
at
it
from
the
other
side?
So
we
didn't.
You
know
we
looked
at
it
from
the
employee's
perspective.
What
about
department
has
many
employees?
What
if
we
wanted
to
say,
hey
get
all
the
employees
for
a
given
department
for
this
department.
Tell
me
all
the
employees
that
are
part
of
this
department.
A
So
this
is
what
that
table
might
look
like.
So
we've
got
employees
by
department
table.
You
can
see.
It's
got
a
primary
key
of
department,
id
and
employee
id,
and
this
is
what
the
select
statement
that
same
select
statement,
michael
colette
from
that
table,
and
so
with
the
primary
key
of
department,
id
and
employee
id.
A
What
we
actually
have
is
for
any
given
so
department
id
is
our
partition
key.
So
we're
saying
for
any
given
department
store
all
the
employees
for
that
department
together
in
a
partition
and
then,
when
I
do
my
query
I'll,
be
able
to
say
where
department
id
equals
blah
and
be
able
to
go
to
onenote
talk
to
one
node.
That
query
will
be
efficient.
A
So
if
you
want
to
go
back
to
sort
of
like
our
logical
view
of
the
storage
and
kind
of
what's
what's
going
on
conceptually
or
the
storage
layer,
you
can
see,
we've
got
our
department
id
over
the
left.
We've
got
our
employee,
ids
kind
of
clustering
things
ordering
order
things,
and
then
we've
got
the
actual
employee
information.
There.
A
Now
one
thing
you
might
notice
about
this
is
that
there's
some
information,
that's
actually
going
to
be
the
same
across
all
rows
in
our
partition.
So
for
a
given
department
id
the
actual
department
name
is
going
to
be
the
same.
So
john
and
I
are
both
evangelists
and
if
we
were
to
like
go
update,
you
know
say
we
went
from
being
evangelists
to
being
community
or
something
like
that.
Our
team,
your
department
name,
changed,
or
something
like
that.
It
should
probably
affect
all
of
the
rows
in
that
partition.
A
That
data
should
probably
be
the
same
across
all
the
rows
in
the
partition
and
you'll
get
that
you'll
get
into
this,
especially
when
you're
doing
the
other
side
of
a
many
to
one
relationship.
You'll
get
this
thing
where
you've
got
a
partition
and
then
you've
got
some
data.
That's
not
part
of
the
partition
key,
but
it's
going
to
be
the
same
for
all
the
rows
across
the
partition,
and
so
this
is
a
scenario
when
you
want
to
use
something
called
a
static
column
in
cassandra.
So
what's
it
look
like
to
do
it?
A
A
Made
to
it
or
anything
like
that,
it's
going
to
affect
all
the
rows
in
the
partition.
There's,
basically
one
copy
kind
of
stored
there
right
next
to
the
department
id
and
then
we've
got
our
our
rows
next
to
it
so
think
left,
especially
if
you're
doing
sort
of
the
other
side
of
the
many
one
relationship
think
about
using
static
columns
or
think
about
whether
you
might
have
some
static
columns.
A
So
the
last
thing
to
talk
about
is
talk
through
a
little
bit
of
a
use
case.
So
let's
talk
through
a
time
series
use
case
and
then
later
today
I
think
I'm
doing
the
last
topic
today.
I'm
going
to
be
doing
building
your
first
application
on
cassandra
and
that's
we're
going
to
walk
through
that
actual
video
sharing
site.
That's
like
youtube,
so
it's
called
killer
video
I'll
kind
of
walk
you
through
the
thought
process
that
I
went
through.
A
A
So
first
thing
we're
going
to
do
we're
going
to
start
with
our
queries
right.
So
what
a?
How
do?
I
need
to
query
this
data
for
this?
For
this
example,
so
things
we're
probably
going
to
want
to
do
we're
probably
going
to
want
to
get
all
the
data
for
a
given
weather
station
so
for
a
given
location
like
for
atlanta,
georgia,
where
we
have
a
weather
station,
give
me
all
the
data,
all
the
data.
Historically,
we're
probably
going
to
want
to
get
data
for
a
single
date
and
time
so
say
hey.
A
You
know
december
1st
2005
at
7,
00
am
what
was
the
temperature?
Then
we're
also
probably
going
to
want
to
do
getting
a
range
of
data,
so
we're
also
probably
going
to
say
hey
between
7
a.m
and
10
a.m.
On
december
1st
2005
give
me
the
the
trend
temperatures.
How
did
what
was
the
temperature
change
over
time
so.
A
It's
we're
probably
going
to
store
data
per
weather
station
right
so
because
we're
always
going
to
be
looking
up
hey
for
a
different
weather
station
for
a
given
location.
Give
me
this
data
we're
going
to
store
data
for
weather
station
and
we're
probably
also
going
to
store
it
in
time
serious
order.
So,
first
to
last
so
this.
A
Isn't
too
small
for
people
in
the
back,
but
these
slides
will
be
available
later
as
well.
So
this
is
what
the
table
might
look
like.
So
we've
got
a
temperatures
table
this
temperatures
table
you
can
see.
It's
got
a
primary
key
of
weather
station
as
the
partition
key.
So
that's
because
we're
always
going
to
be
giving
it
a
weather
station
id
of
some
kind,
we're
going
to
say
for
this
location,
give
us
the
data.
So
that's
our
partition
key
and
then
you
can
see.
A
We've
got
the
time
component
of
it
and
we
got
it
kind
of
broken
down
into
year
month,
day
and
hour
and
I'll
show
you
kind
of
why
that
might
make
sense
a
little
bit.
Why,
when
we
get
to
some
of
the
other
queries
that
we
need
to
do,
but
this
is
this
is
what
it
will
look
like
to
insert
data
into
that
table.
So
you
can
see
we're
inserting
some
data
for
a
single
weather
station.
A
Here
we've
got
four
insert
statements:
we're
inserting
four
records
for
this
one:
zero,
zero,
one,
zero
weather
station
and
we're
inserting,
looks
like
we're
getting
readings
every
hour.
So
we've
got
2005
december
1st
hour
7
and
we've
got
2005
december
1st
hour
8..
So
basically,
our
weather
station
is
taking
readings
every
hour
and
sending
it
back
to
us,
along
with
the
temperature.
A
C
A
To
in
a
data
model
like
this,
so
this
is
what
it
would
look
like
when
we
go
to
do
our
query,
where
we're
saying
hey,
give
me
all
the
data
for
for
a
given
weather
station.
It
would
probably
look
something
like
this
and
if
we
think
about
the
results
that
come
back,
we
kind
of
get
a
nice
view
of
this.
Where
we've
got
the
weather
station
in
one
column,
we've
got
an
hour
here
and
another
column,
and
then
we've
got
the
actual
temperature
reading
in
the
last
column.
A
You
can
see
up
top
so
for
2005
december
first
hour,
seven,
so
on
so
forth,
down
down
the
line,
we've
got
our
actual
temperature
readings,
so
this
is
merged,
sorted
and
stored
in
sequential,
which
is
which
is
kind
of
nice.
That's
going
to
do
things!
It's
going
to
make
our
queries
very
efficient
because.
A
A
New
things,
to
the
end,
very,
very
simple,
to
kind
of
add
things
to
this
partition
as
new
records
come
out
so
then
we
can
do.
Then
we
can
take
the
example
of
that
range.
Query
right,
so
we
said
we
wanted
to
be
able
to
do
hey
for
some
day
give
us
the
temperature
ranges
between
7
a.m
and
10
a.m,
or
between
noon
and
3
o'clock,
or
something
like
that,
and
so
you
can
see
that
what
that
query
might
look
like.
A
You
can
see
the
select
statement,
we're
always
providing
the
value
for
weather
station,
which
so
we're
saying
for
a
given
weather
station.
Give
me
the
give
me
the
range
of
temperatures
and
that
partition
key
value
again
is
for
locality.
So
I'm
going
to
be
able
to
go
talk
to
a
single
partition.
Talk
to
a
single
node,
that's
going
to
be
fast,
then
we'll
do
a
single
second
disk
to
find
the
beginning
of
the
range
so
we're
saying
where
hour
is
greater
than
or
equal
to
seven
and
less
than
or
equal
to
ten.
A
So
when
we
actually
go
to
that
query,
we
get
something
that
looks
like
this
logically,
and
this
is
nice,
because
it's
sorted
in
time
time
order-
and
this
is
easy
for
developers
to
reason
about
right.
So
we've
been
doing
you
know,
we've
been
doing
queries
that
come
back.
That
look
like
this
for
a
really
long
time
against
relational
databases.
A
A
A
good
primary
key,
so
choosing
a
good
partition
key
in
particular,
is
important
and
I'll.
Show
you
an
example
of
my
later
talk
actually
about
like
a
example
of
one
where
maybe
I
chose
the
partition
key
a
little
wrong
or
it
could
be,
there
could
be
a
potential
problem
sort
of
thing,
so
maybe
something
to
watch
out,
for
you
should
definitely
minimize
the
number
of
partitions
that
you
read
for
any
given
query.
So
remember.
A
A
Normal
form
from
my
cold
dead
hands
and
so
minimizing
the
number
of
rights
not
don't
worry
about
it
right.
The
center
is
right.
Optimized,
you
know.
Events
in
the
center
are
passed
to
take
advantage
of
that
also
minimizing
data
duplication.
So
this
is
not
a
paranormal
form
that
you're
used
to
from
relational
databases
and
disk
is
cheap.
These
days
right
so
so
store
multiple
copies
of
my
data
where
it
might
have
been
expensive
in
the
past,
like
disc,
is
typically
the
cheapest
part
of
your
system.
In
this
day
and
age.