►
Description
Speaker: Eric Evans, Apache Cassandra Committer and Chief Architect at OpenNMS
Slides: http://www.slideshare.net/planetcassandra/4-eric-evans
A discussion of the recent work to transition Cassandra from its naive 1-partition-per-node distribution, to a proper virtual nodes implementation.
A
My
name
is
eric
evans,
I'm
on
the
apache
cassandra
pmc
have
been
since
pretty
much
the
time
it
entered
the
incubator
working
on
it
originally
for
rackspace,
then
for
a
kunu,
and
I
worked
for
a
company
called
the
open
nms
group
now,
and
this
talk
is
on
virtual
nodes,
a
new
feature
in
cassandra.
One
two
before
I
can
explain
virtual
nodes.
A
I
need
to
kind
of
get
a
little
introductory
background
at
the
risk
of
telling
you
something
you
may
have
already
heard
in
another
talk
today
or
another
cassandra
event,
kind
of
basic
material
call
it
dht101
dht
is
this.
Probably
I
probably
should
have
resisted
the
urge
to
put
that
down.
The
original
research
that
led
to
this
kind
of
distribution
was
called
a
distributed
hash
table.
Fundamentally,
cassandra
is
still
a
distributed
hash
table
into
the
covers,
even
though
our
data
model
is
much
more
richer
than
a
simple
hash
table.
A
So
how
we
typically
visualize
this
is
you
take
a
ring
or
a
clock
face
if
you
will
and
you
map
the
the
entire
name
space
for
these
keys
in
sorted
ascending
order
such
that
when
you
reach
the
highest
possible
key
you
roll
over
to
the
lowest
and
having
done
this.
If
you
divide
this
ring
up
or
partition
it,
if
you
will,
then
you
can
give
each
of
these
partitions
to
a
node
in
the
cluster
and
then
finding
out
where
to
go,
write
or
read.
A
From
this
point
out,
it
doesn't
matter
which
copy
is,
which
there's
no
special
distinction.
This
is
just
how
the
algorithm
for
placement
works,
oops.
Okay,
so
once
we
have
multiple
copies
of
data
on
the
cluster,
we
have.
We
have
a
different
kind
of
problem,
which
is
that
these
contention,
these
contentious
properties
between
you,
know,
consistency
and
availability,
that
we
usually
use
the
cap
theorem
as
a
device
for
explaining
this.
But
it's
pretty
simple.
If
you
imagine,
we
had
a
replication
factor
of
three
and
we
just
want
to
copy
data
onto
it.
A
Synchronously
we
we
rely
on
the
fact
that
a
successful
operation
is
the
you
know
is
writing
on
all
three
nodes
successfully.
Then
we
can
reason
about
the
consistency
of
the
data
on
the
system,
but
we've
given
up
availability
because
we
can
no
longer
meet
those
requirements
if,
if
we're
down
a
node,
if
a
node
has
failed.
A
Conversely,
if
we,
if
we
choose
asynchronous
replication
instead
for
all
or
part
of
those
three
copies,
we
can
get
availability
because
we
can
survive
a
node
failure,
but
we
can't
reason
about
about
the
consistency
and
that's
what
the
cap
theorem
is
really
speaking
to
is
that
these
properties
are
are
contentious
in
a
distributed
storage
system.
This
is
the
reality
we
have
to
live
with.
So
in
cassandra.
We
deal
with
this
with
something
called
tunable
consistency.
A
So
if
you
imagine
again
a
replication
factor
of
three,
if
we
chose
a
consistency
level,
one
for
a
write,
then
we're
going
to
block
we're
going
to
wait
until
we've
successfully
written
it
to
one
node
and
then
we
consider
that
considered
a
success
after
we
hang
up
and
go
away.
We're
expecting.
You
know
really
within
milliseconds
for
asynchronous
replication
to
update
these
remaining
two
copies,
but
we
have
no
guarantees
at
that
time.
A
We
have
a
way
of
dealing
with
in
a
very
flexible
way
these
with
these,
these
contentious
properties,
consistency
and
availability.
So
it
sounds
pretty
elegant
sounds
pretty
pretty
nice
and
on
paper
you
know
it
does,
but
in
reality,
after
years
of
experience
using
this,
we
found
it's
not
quite
as
perfect
as
it
seems
it's
not
as
as
pretty
as
it
initially
looks.
A
So
one
problem
relates
to
the
distribution
of
of
requests
or
or
operations.
So,
going
back
to
that
first
diagram,
I
said
that
keys
that
belong
on
partition,
a
are
replicated
on
on.
You
know
in
this.
In
the
simplest
case
on
the
next
successive
nodes
working
clockwise
around
the
ring,
so
we
have
data
from
partition,
a
node,
a
being
replicated
to
nodes
b
and
c,
but
this
is
true
for
all
of
the
nodes
in
the
cluster,
so
node
z
replicates
its
data
onto
a
and
b
and
node
y
replicates
its
data
onto
z
and
a
so.
A
A
So
it's
localized
to
the
neighboring
nodes,
topologically
speaking
in
a
perfect
world,
you'd
like
to
see
this
distributed
throughout
the
nodes
in
the
cluster,
but
it's
it's
localized.
So
we
could
fix
this.
You
know
we
bring
the
node
back
up
or
let's
say
in
the
case
of
a
catastrophic
failure.
We
bootstrap
a
new
node
in
in
place
either
way
we
have
data
that
should
be
on
the
node
that
we
missed
and
we
need
to
get
it
copied
in.
So
where
does
that
data
come
from?
A
A
Another
problem
is
how
we
manage
placement
of
data
within
the
cluster.
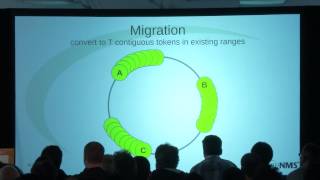
So
imagine
we
have
a
nice,
well-balanced,
four
node
cluster.
Traditionally
this
has
meant
that
you
know
the
the
operator
divides
the
key
space
four
ways
and
creates
corresponding
tokens
and
assigns
them
to
nodes,
and
then
we
have
this
nice
balance
where
each
node
has
the
same
amount
of
data.
A
But
at
some
point
you
know,
hopefully
we're
scaling
up
in
throughput
we're
scaling
up
in
in
data
and
we
need
to.
We
need
to
grow
the
cluster,
and
this
is
something
cassandra
is
supposed
to
be
good
at
it's
linearly
scalable,
you
just
bootstrap
a
new
node
in
right,
except
for
where
do
you
put
it
in?
The
very
best
you
can
do
is
to
bootstrap
one
of
these
existing
or
bootstrap
into
one
of
these
existing
partitions
to
bisect
it,
but
that
creates
a
pretty
severe
imbalance.
A
One
you'd
like
to
have
one
one
you'd
like
to
correct.
So
one
option
is
to
just
move
the
remaining
nodes.
Such
that
you,
you
position
them
where
you
have
balance
again,
but
for
every
every
one
of
these
moves
there
is
an
in
an
interval
of
data
which
has
to
be
moved
off
of
the
node
onto
another
one
and
on
to
it
from
from
another
node
in
in
all
cases.
So
it's
a
lot
of
unnecessary
movement
of
data.
A
We
would
like
to
avoid
that,
if
possible,
so
this
isn't
a
really
good,
really
good
solution,
which
is
why
we
usually
tell
people
just
double
the
size
of
the
cluster.
You
have
four
double
it
to
eight.
You
have
three
double
it
to
six
and
this
works
simply
because
now
we're
bisecting
all
of
the
partitions,
but
frankly
I
think
we
got
a
little
bit
too
comfortable
telling
people
to
just
double
the
size
of
their
cluster.
That's
it's
almost
absurd.
If
you
think
about
it,
I
mean
this
could
literally
equate
to
doubling
your
hosting
costs.
A
A
You
know
many
partitions,
so
we
just
we
just
divide
the
ring
up
into
into
many
more
partitions
than
we
have
nodes
and
then
randomly
allocate
them
to
to
the
nodes
we
have,
and
this
has
a
number
of
benefits
it's
it's
operationally
simpler
because
you
no
longer
need
to
manage
tokens.
You
no
longer
have
to
calculate
the
the
splits
in
the
ring
and
and
assign
tokens
you
no
longer
have
to
move
them.
A
So
we
share
replica
sets
with
with
a
with
with
a
high
enough
rep
token
per
node
count
with
a
high
high
degree
of
statistical
probability.
We
share
partitions
with
every
other
node
in
the
cluster,
and
this
this
streaming
from
from
from
multiple
hosts
gives
us
concurrency.
You
know
we
get
to
transfer
that
data
from
from
many
nodes
to
the
one,
as
opposed
to
just
those
neighboring
nodes
which
makes
that
faster
and
by
creating
more
tokens
by
creating
more
partitions
there.
It
follows
that
they're,
smaller
and
smaller
partitions
equate
to
a
more
reliable
cluster.
A
There's
a
lot
of
bipartition
operations,
things
that
happen
on
a
partition
that
can
be.
You
know
very
intensive
from
a
disk
network
io
perspective,
or
you
know,
computationally
intensive
and
by
by
making
those
smaller
there's
less
to
redo.
If
there's
an
error
or
failure
or
some
side,
you
know
things
progress
more
incrementally
and
finally,
it's
it's
a
it's
a
better
excuse
me,
it's
a
better.
A
So
there
are
a
number
of
strategies
that
can
be
taken
when,
when
implementing
virtual
nodes-
and
these
names
are
sort
of
possibly
made
up,
they
may
not
directly
equate
to
things
you
see
in
literature,
but
these
these
seem
to
represent
what
you
find
in
existing
systems
out
there.
So
you
know
these
are
things
that
we
can
draw
experience
from
as
opposed
to
just
you
know.
Maybe
academic
research.
A
A
This
is
how
bigtable
the
the
the
big
table
paper
describes
things.
So
it's
how
the
the
clones
like
hbase
and
hypertable
work-
and
I-
and
I
think
this
is
this-
is
pretty
much.
How
long
goes
auto
sharding
works,
although
I
understand
so
little
about
how
works,
then
you
have
fixed
partition
assignment.
This
is
this
is
what's
described
in
the
the
dynamo
paper
is
strategy
number
three.
This
is
the
one
that
they
they
finally
settled
on
and
the
way
this
one
works.
A
Is
you
divide
the
the
ring,
the
the
key
space
into
q
evenly
sized
partitions?
You
just
you
just
give
it
a
constant
number
of
partitions,
so
each
node
has
q
over
n.
It
has
an
equal
number
of
of
partitions
and,
when
you
add
a
new
node
to
the
cluster,
you
just
recalculate
q
over
n
and
copy
that
many
partitions
from
the
existing
nodes
to
the
new
one.
A
A
More
partitions
is
better,
but
only
to
a
point.
These
partitions
are
metadata
that
has
to
be
exchanged
between
nodes.
More
of
them
equals
greater
computational
complexity.
When
making
routing
decisions
taken
to
the
extreme,
you
can
imagine
a
partition
being
so
small
that
it
could
only
hold
one
key
and
that's
not
where
we
want
to
be
and
the
same
with
partition
size.
We
would
like
to
keep
these
things.
You
know
to
us
to
a
reasonable
size
that
we
could.
A
A
A
We
have
a
constant
partition
size
that
being
the
constant
without
with
automatic
sharding
and
that's
good.
We
can
reason
about
the
size
of
a
partition
really
well
and
that's
useful,
but
because
the
partition
size
is
a
constant,
it
means
that
the
the
number
of
partitions
scales
linearly,
as
we
add
more
data
and
for
a
system
that
you
know
we're
ostensibly
trying
to
make
infinitely
scalable.
That's
that's
not
very
good
for
the
fixed
partition
assignment.
This
is
the
one
where
we
assign
q
evenly
sized
partitions
to
the
to
the
cluster
up
front.
A
A
Also,
the
the
one
problem
with
fixed
partition
assignment
is
the
there's
greater
operational
overhead,
because
it's
on
the
operator
to
to
know
or
to
think
about
ahead
of
time
how
much
data
is
going
to
be
in
the
system
and
how
many
nodes
it
will
take
to
accommodate
that,
so
that
they
can
assign
the
correct
number
of
partitions
up
front.
And
it's
rare
that
people
have
have
things
that
well
in
hand.
You
know
started
off.
Is
I'm
never
that
well
prepared?
A
And
finally,
we
have
a
random
token
assignment
so
random
a
token
assignment
again?
Is
we
assign
t
random
tokens
for
every
joining
node,
the
constant
here
being
the
number
of
tokens
per
node,
and
so
the
total
number
of
partitions
for
the
cluster
scales
linearly
with
hosts,
which
is
okay,
it's
certainly
better
than
scaling
with
the
amount
of
data
and
the
partitions
size
scales
based
on
the
amount
of
data
and
the
number
of
nodes.
A
A
So
that's
pretty
much
like
all
of
the
you
know
the
the
theory,
I
guess
the
rest
of
it
just
pertains
to.
You
know
like
practical
details
of
the
implementation
of
cassandra
which
isn't
much
because
this
actually
makes
things
a
lot
simpler,
there's
not
a
whole
lot
to
this,
so
the
only
the
only
real
configuration
aspects
are
found
in
the
cassandra.yaml
file.
A
There's
two
things
that
affect
virtual
nodes:
one
is
the
initial
token
parameter
which
will
allow
you
to
specify
a
comma
separated
list
of
tokens.
We
don't
recommend
doing
this.
It
was
kind
of
added
for
sake
of
completeness
initial
token.
Does
something
and
there's
an
expectation
there,
so
it
was
more
or
less
conforming
to
the
elements
of
least
surprise.
A
It's
worth
mentioning
that
num
tokens
is
similar
to
initial
token,
in
the
sense
that
it's
kind
of
a
one-shot
deal.
You
cannot
change
the
num
tokens
parameter
later
and
and
and
have
that
affect
the
number
of
tokens
on
that
node.
It's
it's
set
the
first
time.
It's
it's
run
at
some
point,
we'll
probably
add
the
ability
to
to
add
or
remove
tokens
to
scale
up
the
number
of
tokens
scale
them
down,
but
that
that
capability
doesn't
exist.
Now
and
frankly,
it's
it's.
There
hasn't
been
a
lot
of
impetus
for
it.
A
It's
not
something
you'd
want
to
change
lightly.
Anyway,
if
you're
familiar
with
any
of
the
the
operational
tools.
Some
of
these
things
changed
for
reasons
which
may
or
may
not
be
obvious.
No
tool
info
is,
is
something
that
operators
run
commonly
just
to
sort
of
get
a
summary
view
of
of
one
node.
But
one
field
in
that
output
was
the
token
and
obviously
this
is
much
less
useful
if
it
blows
up
by
255
lines,
because
you
have
255
more
tokens
than
you
did.
A
So
we
just
suppress
that
output
and
ask
you
to
pass
a
switch.
If
you
want
it,
the
other
one
that
changed
is
no
tool
ring.
No
tool
ring
started
off
as
a
way
of
not
very
intuitively,
but
as
a
way
of
sort
of
diagramming
that
ring
that
we're
so
used
to
looking
at
in
a
linear.
You
know
ascii
fashion,
it's
meant
to
just
describe
the
the
content
topology
of
the
system,
but
what
it's
kind
of
grown
into
is
this
sort
of
like
one
shot,
high
level
status?
A
You
know
like
a
way
of
looking
at
the
cluster
from
a
high
level
overview
and
again
having
having
that
output
blow
up
by
you
know.
255
lines
per
host
means
it's
much
less
useful
for
that,
so
it's
still
there
and
it
still
does
what
you
expect.
But
it's
you
know
if
you're,
if
you
use
cassandra
and
you
you
switch
to
virtual
nodes,
you'll
find
it's
not
useful
as
that
sort
of
summary
view
anymore.
A
A
It
used
to
be
the
case.
It
was
an
assumption
throughout
the
code
base,
documentation,
best
practices.
We
referred
to
a
node
by
its
token,
because
there
was
only
ever
one
token.
It
was
the
only
thing
that
was
globally
unique
about
a
node.
An
ip
address
could
change,
but
you
know
the
token
is
what
really
represented
that
node
with
256
of
them,
for
example,
if
that's,
if
you
stick
with
the
default,
even
with
five,
it
just
doesn't
make
as
much
sense.
So
we
replaced
this
with
a
uuid
and
you'll
probably
see
this
start
to.
A
A
A
A
A
It
will
essentially
split
that
token
that
partition
num
tokens
ways
so
256
by
default.
You
end
up
with
256
partitions
that
are
all
within
the
same
interval
of
the
one
that
you
had
before.
So
there's
no
placement
change
all
of
the
data
that
was
there
before
still
belongs
there
and
all
the
routing
decisions
still
still
send
everything
for
that
that
partition
to
the
same
place
and
there's
some
value
in
doing
just
this,
because
you
know
if
you
went
no
no
further.
This
is
really
safe.
You
could
do
this
on
a
running
system.
A
Of
course
you
know
rolling
restart
on
the
nodes,
because
it's
just
a
metadata
change,
there's
no
movement
and
data,
nothing
drastic
happening,
and
you
know
you
still
get
this
smaller
partitions.
So
things
you
know
the
the
general
reliability
increases,
and
you
know
over
time.
We
would
expect
those
to
you
know
to
to
fail
and
be
replaced
at
which
point
the
the
placement
of
the
partitions,
the
mapping
of
the
partitions
to
nodes,
would
randomize
over
time.
A
A
The
way
that
works
is
the
mapping
is
created
and
each
node
transfers
the
ranges
that
are
that
are
destined
for
it
to
itself.
So
you
know
for
each
range
transfer,
there's
a
source
and
a
destination.
We're
queuing
these
entries
up
on
the
destination
of
those
of
those
range
transfers,
and
then
each
one
works
through
their
queue
in
order
sequentially
one
at
a
time,
with
a
break
to
sort
of
help
prevent
one
node
from
you
know:
outrunning
the
others
and
copying
all
the
all
the
partitions
to
itself.
A
And
to
the
best
of
my
knowledge,
this
works,
but
this
is
definitely
something
you
should
probably
test
in
your
own
environment
first
and
get
your
own
sense
of
comfort
for
it.
It
is
in
many
ways
you
know
much
more
complicated
than
things
like
decommission
and
bootstrap,
but
it
will
never
really
be
as
thoroughly
tested
as
those
things,
because
it's
the
sort
of
thing
you
would
do
at
most
once
and
not
every
cluster
is
going
to
have
it.
A
A
Doing
a
shuffle
is
pretty
straightforward.
If
you
run
create
it'll,
create
those
mappings
write,
the
the
the
moves
on
to
the
the
queues
of
each
node,
but
it
won't
start
it.
You
can
use
ls
to
view
what's
going
to
happen
clear
if
you
don't
want
that
to
to
happen.
If
you
change
your
mind
and
then
enable
and
disable
to
to
toggle
that
on
and
off,
maybe
you
want
to
run
it
during
off-peak
hours
and
stop
it
when
peak
hours
come
around.
A
The
only
other
switch
of
interest
is
the
the
the
dc
or
only
dc
switch,
which
would
limit
the
the
remapping
to
within
a
single
data
center.
So
if
you
have
a
multi-data
center
cluster-
and
you
don't
want
range
transfers
to
be
happening
over
the
lan
link,
you
can
localize
these.
These
moves
to
a
data
center
and
finally
I'll
finish
up
with
a
little
bit
of
performance,
because
I
don't
know
why
it's
like
a
cultural
thing.
A
We
want
to
quantify
all
you
know
everything
we
do
and
how
else
do
you
quantify
it
other
than
you
know
how
much
faster
it
made
and
it
did
make
it
faster.
So
this
is
a
benchmark.
I
forget
the
specifics.
I
think
we're
like
13
m1,
extra-large
ec2
instances,
and
you
know
something
like
500
million
rows.
It's
not
really
important.
What
was
kind
of
we're
kind
of
looking
for
here
is
you
know
the
relative
difference
between
cassandra,
one
one.
You
know
without
virtual
nodes,
one
two
with
virtual
nodes:
this
is
the
remove
node
operation.
A
A
If
you
had
a
node
failure,
you
have
a
node,
it's
completely
unresponsive.
You
can't
gracefully
exit
from
the
cluster.
You
need
to
get
another
one
back
in.
This
is
kind
of
your
worst
case
scenario
between
these
two
things:
it's
about
three
and
a
half
times
faster,
which
is
really
important
if
you
think
about
it,
not
just
because
it's
faster
and
we
all
like
to
see
things
happen
faster,
but
because,
in
this
case
this
is
this
is
how
long
it's
going
to
take
for
us
to
get
back
up
to
full
capacity.
A
A
B
B
A
By
a
machine
yeah
there's
no
dc
or
rack
awareness,
taking
into
account
on
where
to
where
to
place
partitions
on
machines,
the
only
the
only
the
only
difference
there
is
that,
obviously
we
wouldn't
want
to
put
you
know
we're
going
to
skip
over
the
same
machine.
If
you
know
typically
the
way
the
the
the
network
topologies
would
work
is
you
would
look
for
the
next?
A
C
A
Yes,
that's
true,
that's
that's
actually
a
good
question,
so
it
is.
It
is
true
that,
with
you
know,
classic
cassandra
with
one
token
per
node
that
if
you
lost
irretrievably
lost
the
right
three
nodes
where
replication
count
is
three,
you
would
lose
your
data
and
the
probability
that
you
would
lose
the
right
three
nodes
with
virtual
nodes
is
is
much
much
higher,
in
fact,
probably
one
because
again
we
said
that
they
all
share
I'll
share
data.
A
So
the
answer
to
that
is
the
same
as
it
is
with
one
token
per
node.
Is
you
know?
Don't
let
that
many
nodes
fail?
But
but
you
know
it's
it's
actually,
richard
lowe
with
the
cooney
who
worked
out
the
he
did,
the
math
I'll
have
to
trust.
Him
was
right
because
it
was
beyond
me,
but
that
that,
with
the
faster
rebuild
time
that
that
provided
there
was
no
one
to
sleep
at
the
wheel
that
you
were
statistically
less
likely
to
lose
data
because
you
could
recover
faster.
A
I
don't
know
if
you
buy
that
argument
or
not
what
you're
I
haven't,
I'm
not
sure
what
the
technical
terminology
for
that
is.
I
heard
someone
call
it
distribution
factor
or
whatever
what
you'd
like
is
somewhere
in
between.
You
know,
you'd
like
something
that
was,
you
know
less
than
perfectly
localized
like
cassandra
with
one
token
is
and
something
better
than
you
know
completely,
but
that
is
that
is
a
fair
point.
Now.
D
A
F
E
A
A
A
I
mean
extremely
skewed
distribution
among
your.
You
know
your
data
in
terms
of
you
know,
hot
hot
keys.
I
mean
extremely
skewed
in
order,
for
you
know
a
three
node
cluster,
for
example,
with
768
tokens
to
have
one
or
two,
and
you
know
that,
with
the
I
mean,
that's
that's
kind
of
your
hot
spot
scenario.
You
literally
have
to
have
one
or
two
that
was
a
problem,
one
or
two
of
those
partitions
and
that
seems
less
likely
much
less
likely.
E
A
F
A
No,
it's
just
a
partitioning
partition,
still
one
jvm
per
node,
that's
probably
an
unfortunate
naming
virtual
nodes.
We
continue
to
call
it
that
because
that's
what
the
dynamo
paper
called
it-
and
you
know
it
is
the
same
thing-
that's
described
in
the
dynamo
paper
so
rather
than
confuse
things
by
giving
it
a
different
name.
It's
unfortunate
aiming.