►
Description
Speaker: Al Tobey, Open Source Mechanic at DataStax
Slides: http://www.slideshare.net/planetcassandra/practice-makes-perfect-extreme-cassandra-optimization
Ooyala has been using Apache Cassandra since version 0.4. Our data ingest volume has exploded since 0.4 and Cassandra has scaled along with us. Al will cover many topics from an operational perspective on how to manage, tune, and scale Cassandra in a production environment.
A
So
this
is
practice
makes
perfect
extreme
cassandra
optimization.
I
originally
had
a
more
boring
title
for
this
talk
and
before
I
came
today
stacks
they
gave
me
this
title
for
it.
I
I
kind
of
like
it
now
there's
a
bit
of
a
discrepancy
on
the
slides,
you'll
see
down
in
the
corner.
It
says
and
up
there
it
says
data
stacks.
About
two
weeks
ago
I
left
uyla
and
joined
datastax
and
my
title.
A
A
So
what
I'm
going
to
talk
about
is
mostly
things
that
I
learned.
It
were
pretty
much
entirely
things
I
learned
at
yala
I
spent
about
two
years
administering
crescendo
for
them.
We
broke
it
in
every
possible
imaginal
way
that
we
could
come
up
with,
and
there
was
a
lot.
So
we
will
tell
you
how
not
to
manage
cassandra
clusters
and
how
we
made
it
better,
how
we
got
it
better
and
then
how
what
a
jurisdiction
or
what
I
call
a
jurisdiction
and
it's
basically
an
approach
to
performance,
tuning
and
optimization
and
troubleshooting.
A
That
is
different
from
being
scientific
about
it
and
you're
all
intelligent
people
and
want
to
be
scientists
and
want
to
be
rigorous
and
be
able
to
approach
things
and
be
able
to
be
really
confident.
You
did
it
right,
but
sometimes
when
you're
under
the
under
the
gun,
you're
you're
in
the
heat
of
the
battle
trying
to
fix
things.
A
So
my
role
there
was,
I
was
tech
lead
of
a
team
called
data
services.
They
built
were
basically
rebuilding
uyala's
big
data
platform
to
be
a
platform
as
a
service.
Internally,
it
was
a
devops
team.
We
had
two
systems,
administrators,
a
dba
myself
as
tech
lead
and
I'm
kind
of
more
ops
background.
Although
I
do
a
lot
of
coding
and
two
engineers.
A
A
A
little
about
yellow.
I
won't
spend
a
lot
of
time
on
this
stuff.
I
promise
they
were
found
in
2007.
They
have
230
employees.
This
is
all
the
boring
stuff.
200
million
unique
users
in
110
countries,
100
1
billion
videos
played
per
month,
2
billion
analytics
events
per
day,
what's
important
about
that
is
when
I
talk
about
these
systems
that
we
maintain
there
that,
basically
all
of
those
are
wrapped
around
cassandra.
All
of
those
analytic
events
ended
up
in
cassandra
in
one
form
or
another.
Sometimes
they
end
up
as
aggregates
in
the
new
systems.
A
It's
all
going
in
real
time
all
the
events
raw
forever
or
until
they
run
out
of
disk
and
so
they've
been
using
cassandra
since
0.4
when
I
joined
it
with
0.6
and
we
went
through
the
transition
from
0.6
to
0.7
and
0.8
and
I'll
get
to
that
in
just
a
minute.
They
in
that
their
clusters
that
they
had
when
I
started
there,
they
stored
analytics
data
duh.
That's
what
about
half
of
the
cassandra
use
cases
we
also
started
using
as
a
highly
available
key
store.
A
You
might
be
watching
a
video
on
your
phone
on
the
tube
and
when
you
get
halfway
through
it,
your
your
trip
is
over.
You
close
your
phone,
you
go
home,
and
maybe
you
watch
start
watching
on
your
tv
and
it
should
pick
up
in
the
same
place,
and
so
we
use
cassandra
for
that
and
there's
a
large
machine
learning
system
that
they
have
that
basically
stores
all
of
its
intermediate
data.
A
A
This
is
a
pretty
byzantine
architecture
and
or
complicated
architecture,
so
that's
being
replaced.
So
this
was
an
18-note
cassandra
cluster,
it's
about
an
80-note
hadoop
cluster,
every
20
minutes,
or
so
the
hadoop
cluster
would
beat
the
beat
on
that
cassandra.
Cluster
push
a
whole
bunch
of
data
into
it.
Oh
move
on!
Oh
no!
That's
right!
Sorry!
So
so
the
problem
that
we
had
here
was
the
read,
modify
right.
A
It
gets
to
be
pretty
slow
and
really
hammers
on
the
database.
You
have
to
do
a
few
things
to
make
that
work.
So
at
the
time
we're
doing
we're.
Reading
at
read,
repair
100,
I
think
they're
still
doing
that,
and
it
has
some
problems
in
the
storage
engine
now,
like
I
said
with
the
with
cassandra
2.0,
you
have
the
compare
and
set
which
would
make
this
a
lot
cleaner,
and
they
should
definitely
be
looking
at
moving
to
that.
But
that's
not
my
problem
anymore.
A
So,
but
here's
the
problem
with
it-
and
this
is
a
really
simplified
version
and
don't
take
this
as
canonical
for
how
the
the
cassandra
engine
works,
but
it's
a
high-level
view
of
how
it
works.
So
what
you
might
do
is
say
we're
going
to
go
drinking,
so
this
is
my
old
team
and
after
the
after
the
conference
or
the
workshops,
and
so
we've
created
a
table-
and
these
are
our
partition
keys
right
here
and
then
these
are
just
column
values
for
for
each.
So
for
each
day
how
many
drinks
people
are
going
to
have.
A
So
this
would
be
the
column
key,
the
value
of
key
value
and
so
we're
all
good
there
right.
We
can
write
that
in
it's
perfectly
safe.
We
come
along
a
few
minutes
later
or
a
day
has
passed
and
then
we
decide
we're
going
to
write
into
update
these
values.
I
say:
well,
I
don't
think
I'm
really
going
to
drink
that.
Much
because
I
got
to
talk-
and
you
know
I
find
out
that
phil
is
gonna-
is
quit
drinking
for
some
reason
and
he's
not
going
to
that
night.
So
we
have
to
update
it.
A
So
we
write
that
in
it
goes
in
the
mem
table.
This
guy
has
already
been
flushed
out
to
disc
this.
This
one
has
so
now
we
have
some
data
in
memory,
some
data
on
disk
and
they're
different.
So
when
you
do
a
read,
it's
going
to
go
through
the
mem
table
first
and
then,
if
it
hits
in
the
mem
table,
you're
good
it's
going
to
return
immediately
and
if
it
misses,
then
it's
going
to
go
to
ss
table
or
go
to
disk.
A
A
A
And
what
this
is
doing
is
creating
a
compaction
problem.
Is
that
you're
going
to
have
a
lot
of
data
that
needs
to
be
merged
and
so,
at
the
time
of
size,
tiered
compaction?
It
was
a.
It
was
a
big
performance
problem
and
when
you
hear
people
talk
about
look
watching
for
your
compactions
backing
up,
this
is
kind
of
what's
happening.
A
All
right,
so
we
had
that
we
had
that
cluster
up
and
running
for
a
long
time
and
we
got
it
all
tuned
up
and
it's
running
just
fine.
I
went
off
to
work
on
another
project
hand
it
off
to
some
other
people.
They
were.
They
were
working
busy
with
a
whole
bunch
of
stuff
and
the
cassandra
cluster
kind
of
got
forgotten
about
it.
Just
sat
there
running,
it
was
doing
great
for
about
six
months.
I
think
it
was
and
what
happened
is
they
forgot
to
run
repairs
for
about
that?
A
Long
and
all
the
tombstones
had
expired,
the
past
gc
grace
and
when
we
got
to
the
end
we
had
this
problem.
We
have
all
this
data
sitting
on
disk.
It
was
about
25
terabytes
worth
that
was
no
longer
valid.
We
could
be
reading
back
invalid
values
because
the
tombstones
were
all
expired,
so
we
decided
to
do
is
this
is
pretty
crazy.
I
don't
recommend
it.
A
A
We
moved
up
to
cassandra.0.8
at
the
time
we
were
already
at
a
24
gig
heat,
because
the
bloom
filters
were
so
large
and
at
the
time
I
don't
think
it
was
tunable,
then
so
that's
definitely
not
recommended.
I
used
to
recommend
that
people
ran
larger
than
eight
gigabyte.
Now
you
want
to
stick
with
eight
gigabyte
heaps
whenever
you
can
and
only
go
larger.
If
you
really
have
a
good
need
for
it,
and
you
don't
you're,
not
worried
about
gc
latency
problems,.
A
The
the
other
one
was
is
just
a
simple
sun
java
update
moved
to
linux
2636,
so
we
were
on
ubuntu
lucid
at
the
time,
and
I
believe
that
was
on
2632
and
there
were
some
features
in
2636
we
wanted
to
play
with
and
it
turned
out
to
be
very
stable.
We
were
running
that
same
kernel
on
other
clusters
in
the
in
the
environment
and
decided
to
merge
it
all
to
that.
We
moved
to
xfs
and
md
raid5
and
there's
a
note
about
that
which
is
you
can
run
jbod
or
raid
0.
A
If
you
want
to
get
maximum
storage
space,
you
can
run
raid
0..
If
you
like,
sleeping
at
night,
you
can
run
raid
5
or
raid
10.
and
that
that's
kind
of
important,
because
the
the
the
most
important
I'm
sorry
the
most
likely
component
in
a
computer
to
fail
is
the
hard
drive
it
has
the
most
moving
parts
in
it
and
I've
replaced
so
many
hard
drives
and
servers.
A
You
don't
need
to
go
raid
6
generally,
because
you
can
always
use
cassandra's
replication
to
rebuild
the
node,
but
if
you're
running
really
deep
nodes,
a
node
rebuild
can
cost
you
an
awful
lot
of
time,
an
awful
lot
of
network
I
o
in
in
latency,
because
the
impact
on
your
cluster.
So
I
I
highly
recommend
that
as
a
tuning
for
operations,
happiness
setting
and
the
other
thing
is,
if,
if
you've
seen
me
talking
at
other
events,
here,
always
turn
swap
off.
If
you
possibly
can,
if
you've
got
more
than
16
gigs
around
turn
swap
off.
A
What
linux
will
do
by
default,
if
you
have
swap
enabled,
is
if
it's
doing
a
whole
bunch
of
io
across
the
file
system,
it'll
actually
start
to
evict
applications
to
swap
to
make
space
for
vfs
cache
and
that's
great
on
desktop
systems,
sometimes
like.
If
you're
running,
google
chrome,
that,
then
you
kind
of
want
it
to
do
that,
because
chrome
will
eat
up
all
your
memory
and
you
want
to
swap
it
out,
get
it
out
of
the
way
so
that
you
can
have
faster
disk
access,
but
generally
linux's,
swap
as
default.
A
A
It
was
just
a
human
error,
kind
of
just
comedy
of
people
not
talking
to
each
other
anyway,
so
we
already
had
the
code
to
do
this,
so
we
did
the
same
thing
and
one
of
the
tricks
we
played
it's
actually
a
really
handy
trick
to
keep
around
is
clusterfest
is
kind
of
a
interesting
piece
of
technology.
People
either
love
it
or
they
hate
it.
The
people
who
hate
it
have
used
it
in
production
in
large,
distributed
setups
and
they
run
into
these
replication
problems
and
they
swear
it
off
forever.
A
And
if
you
talk
to
them
especially
operations
people,
they
will
cuss
and
swear
at
you,
but
it
has
one
mode
where
you
can
use
it,
and
everybody
agrees
that
this
is
pretty
cool
is
when
you
just
do
point-to-point
mounts.
So
what
we
did
is
when
we
were
processing
all
these
ss
tables,
the
mapreduce
job
is
we
exported
all
the
file
systems
from
cassandra,
the
where
the
ss
tables
were
to
all
the
nodes
in
the
hadoop
cluster.
So
it
was
this
big
crisscross
mount
job
from
all
across
all
the
nodes
so
80
to
18..
A
In
the
first
version.
In
this
version
we
actually
used
dse
mapreduce,
so
it
was.
It
was
18
to
18,
so
the
cluster
fs
mounts.
Then
we
ran
this
mapreduce
job
that
read
it
out
of
the
database
on
the
old
cluster
over
cluster
fs
and
then
wrote
back
into
the
cassandra
on
the
same
nodes
that
dse
was
running
on
and
got
us
back
out
of
that.
We
also
made
some
other
changes
at
the
time
we
moved
to
leveled
compaction.
A
We
moved
to
dsc
3.,
oh
obviously,
the
heap
stayed
really
huge
that
that
I
think
that
we
actually
fixed
right
before
I
left
the
the
big
mistake
we
made,
though,
was
moving
to
md
raid
0.,
so
we
said
well,
we
don't
want
to
run
into
these
storage
problems
again
where
we
run
out
of
space.
So
we're
going
to
go
md
raid
0
get
the
maximum
amount
of
space.
A
A
The
other
one
is
running
on
ubuntu
lucid
and
that's
not
something
against
ubuntu.
It's
just
that.
Ubuntu,
lucid
is
older
than
debian
6
and
the
dsc
packages
are
the
c
components
are
compiled
on
debian
6
and
it
doesn't
compatible
with
the
libsy
and
ubuntu
lucid
that
probably
doesn't
matter
to
anybody
today.
But
it's
something
to
watch
out
for
in
the
future.
Just
when
you're
loading
up
cassandra
watch
the
logs
and
you'll,
sometimes
you'll
see
that
the
native
components
don't
load
and
very
often
that's
a
lipsy
linking
error
and
ubuntu
precise
works
just
fine.
A
A
Yep,
as
I
mentioned,
we
went
to
lcs.
The
other
big
change
is
the
bloom
filter
fp
chance.
I
think
that's
changed
a
little
bit
recently.
I'm
still
getting
caught
up
on
all
this
stuff,
but
the
the
big
change
there
is
the
default
was
zero
point.
I
think
zero
zero
seven
and
that's
why
we
were
using
almost
20,
gigs
or
16
gigs
worth
of
heap
for
our
bloom
filters.
After
moving
up
to
0.1
that
dropped
down
to
where
we
could
go
into
an
eight
gig
heap,
so
we
stayed.
A
We
stayed
with
the
really
large
heap
for
a
while
just
to
be
safe
on
the
safe
side,
and
then
we
later
moved
to
the
the
the
smaller
heap
this
this
middle
one.
Here
the
ss
table
size
megabytes
used
to
be
a
problem.
The
the
old
default
was
10
megabytes
and
what
happened
when
we
loaded
all
this
data
in
really
fast
through
the
mapreduce
job,
was
that
we
created
something
like
a
hundred
and
fifty
thousand
files
on
a
single
file
system,
and
linux
gets
really
really
cranky.
A
So
just
setting
that
at
256
megabytes
it's
a
pretty
good
size
for
linux,
the
new
default's
160
megabytes,
that's
also
a
really
good
size
with
read
ahead,
enabled
on
the
drives
and
the
way
modern
drives
are
designed.
You
should
be
able
to
do
really
fast
io
reading
doing
streaming,
I
on
256,
megs
reading
and
writing.
A
We
enabled
snappy
compression,
that's
now
enabled
by
default
and
I
think
2-0
and
enabling
it
on
even
one
or
one
one
was
definitely
a
big
win
and
then
the
this
last
one
isn't
generally
recommended.
But
if
you
are
running
into
compaction
problems
where
your
compaction
is
constantly
getting
behind,
but
you
find
that
your
discs
just
aren't
really
that
that
loaded
I've.
I
tried
things
like
putting
that
up
to
500
megabytes
and
I'm
pretty
sure.
I
think
that
was
a
bug
that
was
fixed.
A
But
what
would
happen
is
I
put
it
500
megabytes
and
I'm
still
only
doing
like
10
percent
of
what
my
disk
array
can
do
and
by
setting
that
to
zero.
It
actually
turns
off
that
whole
code
path
entirely
and
you
can.
Your
compactions
will
run
at
the
full
speed
of
your
disks
and
they
generally
keep
up
and
if
you're
on
ssds,
it's
definitely
worth
considering
just
to
make
sure
that
you
don't
get
into
a
corner.
A
So
in
so
this
year
the
decision
was
made
to
rebuild
this
entire
architecture
and
we
bought
a
whole
new
cage
in
the
data
center
and
built
out
all
new
hardware.
It
was
hp
servers,
eight
drives
128
gigs
of
ram
10
gig
ethernet
out
the
back,
really
cool
ospf
networking
setups
that
had
fill
over
20
gig.
It's
pretty
neat
the
lesson
there
is
there
isn't
one
sorry.
A
This
is
starting
to
get
old
for
me
already,
so
things
that
are
coming
soon.
Is
this
new
cluster?
The
reason
why
we
originally
built
it
was
what
we
wanted
to
do
is
change
from
this
process.
This
batch
process,
where
all
these
logs
went
into
s3
and
then
eventually
made
their
way
into
hdfs
and
they
were
processed
by
hadoop.
It's
a
very
high
latency
process.
A
At
best
we
were
doing
an
hour,
maybe
two
hours
between
when
an
event
happened
on
somebody's
device
and
when
a
customer
could
see
the
impact
on
their
their
streams,
it
was
the
turnaround
was
far
too
long.
So
we
wanted
to
do
is
make
those
those
events
right,
because
center
can
do
this.
We
want
to
write
them
directly
into
cassandra
and
full-time.
It's
a
project,
we
call
the
event
store
and
the
idea
was,
is
we'd,
get
all
the
data
into
cassandra
and
then
start
building
the
roll-ups.
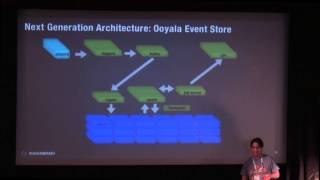
A
Let's
do
this
the
so
the
new
architecture
truncates
that
process
the
loggers
are
pretty
much
the
same,
except
they
write
into
a
kafka
queue
which
gives
us
just
a
little
bit
of
a
buffer
and
then
all
that
gets
ingested
directly
into
cassandra.
The
ingest
system
is
written
in
scala,
it's
using
acca
cluster,
it's
distributed
out.
I
think
it's
a
dozen
nodes
today.
A
Eventually,
it's
going
to
run
on
meso,
so
it'll
be
distributed
across
the
whole
cluster
and
that's
all
running
today
and
then
the
really
cool
neat
thing
that
they
had
on
top
is
they
started
using
spark
and
if
you
look
online,
there's
evan
chan
did
a
talk
at
cassandra
summit
in
san
francisco
and
the
recording
is
online
talking
a
lot
of
sparks.
So
I
won't
talk
about
spark
very
much.
A
We
wrote
a
job
server
in
front
of
it,
which
is
this
really
neat
pattern
that
I
I
think,
most
hadoop
and
even
sometimes
in
front
of
cassandra
and
a
lot
of
the
big
data
services
is
a
really
good
idea,
which
was
sparks
interface,
is
a
lot
like
hadoop's.
In
that
you
got
to
know
these
environment
variables.
You
got
to
know
what
port
it's
running
on.
A
You
got
to
know
which
servers
it's
running
on,
it's
kind
of
a
real
pain
for
the
developers
to
iterate,
because
they've
got
to
have
either
a
replication
of
the
config
and
vagrant
or
on
their
laptop
or
their
own
little
mini
cluster.
What
we
wanted
to
do
is
get
it
to
where
they
could
write,
write
code
for
spark,
compile
it
into
a
monolithic
jar
and
just
use
an
http
service
to
upload
it
and
just
get
it
running
without
having
to
touch
any
of
that
any
of
the
configuration
gu,
and
so
that's
what
the
job
server
is.
A
Oh
yeah,
that
was
it
sorry,
so
the
other
thing
we're
doing
is
the
this
block
here.
So
previously
this
was
kind
of
they
wanted
to
be
secret.
How
many
nodes
it's
120
nodes
and
what's
running
on
there
is
it's
not
just
cassandra
we're
running
cassandra.
We're
running
spark
is
running
on
the
same
nodes,
we're
running
apache,
mesos,
they're,
running
kvm
on
those,
so
there's
one
kvm
on
every
node.
A
Has
this
facility
called
c
groups
which
is
becoming
a
lot
more
well
known
these
days,
because
there's
a
project
called
docker?
That's
getting
really
popular,
but
what
that
does.
Is
it's
a
little
bit
like
the
resource
controls
you
used
to
find
in
solaris
or
some
of
the
other
more
advanced
units
unixes,
where
you
can
assign
deterministic
resource
allocations
to
a
specific
process
or
set
of
processes,
and
you
can
do
network
or
disk
or
memory
cpu,
and
you
can
do
very
fine-grained
control
of
how
many
shares
each
container
gets.
A
So
you
can
group
processes
together
in
the
same
c
groups
or
you
can
put
every
process
into
its
own,
but
the
point
is:
is
the
linux
scheduler
isn't
as
stupid
as
it
used
to
be?
It
used
to
be
used
to
be
that
every
process
was
in
the
same
pool,
and
it
would
use
these
these
heuristics
to
figure
out
what
what
the
prioritization
was
and
inevitably
especially
from
a
systems
administrator's
perspective,
got
it
wrong,
so
c
groups,
definitely
something
worth
looking
at.
If
you're
managing
large
clusters.
A
And
then
moving
on
to
just
kind
of
the
the
art
of
performance
tuning,
the
just
to
lead
into
that
is:
there's
a
there's,
a
there's
a
whole
lot
more
to
tuning
than
just
making
things
really
fast,
and
I've
worked
with
a
lot
of
different
people
who
who
are
into
this
and
talk
to
a
lot
of
people
that
are
in
performance
tuning
and
if
your
only
goal
is
to
make
it
fast.
You
end
up
having
to
leave
a
lot
of
things
on
the
floor.
A
A
Excuse
me
and
you
don't
have
to
deal
with
encryption
overhead,
but
you
do
definitely
need
to
think
about
it.
Even
if
you're
going
to
turn
it
off,
you
need
to
consider
what
are
the
ramifications
of
doing
so.
What
what
is
going
to
be
the
impact
of
my
business
of
disabling
security?
You
have
really
strong
perimeter
defense
around
your
databases.
It's
probably
not
a
big
deal
if
you're
sitting
in
ec2
and
you
have
all
your
security
groups
wide
open.
That's
probably
not
a
good
idea,
so
definitely
make
sure
that
you
think
about
that.
A
It
should
always
be
first
and
foremost
the
cost
of
goods
sold.
Or
what
is
the
impact
on
my
business's
bottom
line?
I
can
make
anything
fast.
If
you
give
me
enough
money,
I
can
go
and
give
our
sponsors
fusionio.
I
can
go
and
give
them
a
million
dollars
for
all
the
best
hardware
that
they
have
to
offer,
and
I
don't
have
to
think
about
this
problem,
because
it's
just
I
don't
have
to
think
about
how
to
tune
spindles
and
make
them
line
up
and
do
block
alignment
and
all
that
bs.
A
A
How
many
are
in
management
all
right
so
for
the
ops
people?
So
if
you're,
if
you're
an
engineer-
and
mostly
you
are
just
think
about
the
fact
that
the
operations
guys
they're
at
the
bottom
of
the
hill
and
bad
things-
roll
downhill
right
and
they
catch
all
of
it
at
the
end
of
the
day,
they
they
carry
the
pagers
that
when
you
don't
answer
yours
theirs
goes
off
and
they
have
to
get
up
and
fix
it.
I
did
that
job
for
a
decade.
A
A
You
know
these
things
make
the
operations
life
a
lot
easier,
actually
at
the
end
of
the
day,
because
it
makes
managing
the
system
when
failures
happen,
you
can
look
at
the
pager
will
still
go
off,
but
I
used
to
do
this
all
the
time
where
a
cassandra
node
would
throw
me
a
page
I'd
roll
over
in
bed
and
I'd.
Look
at
my
phone.
A
Oh
that's
a
cassandra
node
right
because
I
I
just
didn't
have
to
get
up
it
wasn't
an
emergency.
I've
got
three
replicas,
so
that's
that's
a
big
reason,
big
thing
to
think
about
obviously
developer
happiness
for
yourselves,
but
I
also
encourage
operations.
People
when
I
talk
to
them
to
do
the
same
thing
and
think
about
well
sure
you
could
make
this
the
most
secure,
awesome
fast
system
ever,
but
your
engineers
are
going
to
have
to
write
all
this
extra
code
and
deal
with
all
this
extra
deployment
and
they
don't
want
to
do
it.
A
A
So,
as
I
mentioned
about
the
jurisdiction
thing
or
heuristics,
as
I've
described,
we
had
all
these
emergencies
going
on
at
uyella
when,
where
things
things
were
on
fire
and
the
business
is
running
at
full
speed,
we
don't
have
time
to
sit
down
and
go
well.
I
could
take
this
new
cluster
and
go
and
run.
You
know,
lay
out
all
my
tests
in
a
spreadsheet,
I'm
going
to
do.
A
8,
gig,
heaps
and
12
gig
keeps
and
24
gig
heaps
and
run
a
test
for
24
hours
on
each
one
and
I'll
run
cassandra
stress
and
ysdb
or
whatever
that
one's
called
and
and
really
just
kind
of
make
sure
I
got
all
the
data
and
go
and
just
put
together
nice
graphs
and
display
it.
You
can
do
that
stuff
right.
You
can
write
a
nice
paper
about
performance
tuning,
but
that
takes
a
lot
of
time
and
a
lot
of
resources,
and
very
often
you
just
don't
have
access
to
it.
A
A
So
that's
what
I
mean
about.
I
would
really
love
to
be
scientific
about
these
things.
I
hope
I
someday
will
have
the
time
to
sit
down
and
actually
do
the
rigorous
kind
of
study
and
and
make
sure
that
my
data
is
clean,
but
that's
probably
not
going
to
happen.
So
the
the
thing
is
is
the
human
brain
is
really
awesome
at
heuristics.
It's
what
we
do
it
better
than
pretty
much
any
other
creature,
literally.
Actually
maybe
dolphins
right,
they
seem
a
lot
happier
than
us.
A
So
so
the
idea
is
that
you
need
to
lean
into
that
ability.
You
need
to
trust
yourself,
trust
your
judgment
and
there's
a
book
by
malcolm
gladwell
who's.
This
guy
right
here
called
blink
and
I'm
pretty
sure
it's
translated
into
a
lot
of
different
languages.
I
tried
to
check
and
I
couldn't
find
a
good
reference
for
it,
but
it's
a
it's.
A
A
You
make
these
changes
in
production,
you
observe
them,
and
if
it's
really
dangerous,
you
try
to
test
it
somewhere
else.
But
at
the
end
of
the
day,
you've
got
to
do
the
same
thing
in
production
and
my
contention
or
my
what
I'm
proposing
is
that
cassandra
is
a
really
great
place
to
kind
of
practice
this,
because
you've
got
replicas.
You've
got
a
large
ring.
You've
got
some
slack
to
make
mistakes
and
correct
them.
A
You
know
I've
got
vms
on
this
laptop
that
are
running
crazy
stuff.
So
you
know
I
really
love
running
the
latest
linux
kernel.
There's
always
some
new
feature.
That's
really
interesting.
You
know
huge
pages,
transparent,
huge
pages
which
are
actually
a
boon
for
things
like
cassandra
and
any
java
application
zfs
on
linux.
I've
been
playing
with
that
for
a
few
years
now
it's
finally
made
it
to
the
where
it's
stable,
where
people
can
start
testing
it
in
production.
A
Btrfs
is
kind
of
the
little
brother
or
wannabe
of
zfs.
It's
a
nice
little
file
system.
It's
got
a
lot
of
similar
features,
copy
on
right,
snapshots
and
really
that's
the
transparent
compression
that
was
really
interesting
for
us,
with
cassandra
pri
prior
to
snappy
and
even
after
snappy,
because
it's
lzl
compression
and
it
compresses
everything.
Instead
of
just
the
data,
that's
pushed
pushed
through
snappy
and
cassandra.
A
We
played
around
with
a
lot
of
different
jvm
parameters
and
almost
all
of
the
stuff
was
tested
in
production
on
production
machines.
What
what
I
do
is-
or
some
of
my
colleagues
would
do-
we'd
just
pick
a
node
or
two
distributed
throughout
the
ring,
and
we
would
test
on
those.
So
if
I
was
saying
I
want
to
do
a
kernel
upgrade,
I
want
to
go
from
2
6
36
and
I
want
to
go
up.
The
new
linux,
3.0
kernel
is
really
awesome.
Looking
right,
it's
got
that
shiny,
big
three
at
the
front.
A
I
want
to
do
that
I'll
pick
this
part
of
the
ring,
or
this
node
and
I'll
test
it
there,
and
if
I
want
to
test
it
on
two
nodes,
I'm
not
going
to
put
it
on
this
one
right.
So
this
is
it's
really
simple
with
cassandra,
because
you
have
the
ring
there.
It's
really
easy
to
visualize,
put
your
your
kernel
upgrade
here
and
put
it
over
there.
If
you
want
to
be
conservative,
do
the
same
thing
with
your
operating
system
upgrades
I
mean
start
doing
your
operating
system
upgrades
if
you're
not
doing
them.
A
You
know
within
minor
releases,
if
you're
running
an
lts,
rel,
six
or
ubuntu
precise.
You
know
you
need
to
be
doing
those
upgrades
for
the
security
patches.
There
are
very
often
performance
fixes
and
it's
a
lot
of
people
don't
do
them,
because
it's
dangerous
right.
A
lot
you've
been
everybody's,
been
bitten
by
it.
The
systems
administrator
went
in
and
did
an
apt-get
upgrade,
and
then
you
come
in
the
next
day
and
none
of
your
crap
works
because
something
changed
in
the
lip
scene.
A
So
with
cassandra,
you
just
change
it
in
on
two
notes:
let
it
run
for
a
week
two
weeks
a
month,
whatever
you
like,
and
then
you
come
back
to
it
and
you
do
it
on
the
rest
of
the
nodes.
Or
maybe
you
just
do
one
note
a
week,
but
that's
up
to
you.
But
what
I'm
saying
is
you
can
run
these
experiments
and
this
is
exactly
what
we
did.
A
Moving
on
to
tools
this
this
chart,
I
did
not
make
brendan
gregg-
is
an
engineer
at
joint.
He
came
from
sun.
Is,
I
think,
the
author
of
d
trace?
If
he's
not
the
author,
I
he's
definitely.
The
expert
he's
got
a
lot
of
really
cool
slides
out
there.
A
lot
of
he
does
a
lot
of
talking
at
conferences,
but
this
is
one
of
my
favorites.
The
links
here.
The
slides
will
be
up
and
they're
older
copies
of
this
talk
out
online.
A
A
A
So
it's
got
all
the
stuff
that
vmstat
has
in
and
more
and
it's
color
coded
too.
So
if,
if
you're
not
colorblind,
you
can
watch
this
flow
by
and
you'll
see
things
turn
red
and
yellow
when
things
are
going
wrong,
and
very
often
when
you
have
a
node,
that's
say
under
compaction
problems
right,
it's
backed
up
you'll,
see
the
disk
I'll
you'll
instantly
see
it.
The
disk
io
will
be
red
and
it'll
be
going
at
300
megabytes
a
second
or
whatever,
and
the
pro
you'll
have
one
processor
peg.
A
A
Checking
things
out
this
one
is
a
tool
I
wrote
a
long
time
ago
and
I
just
kind
of
drag
it
around
with
me,
because
it's
really
handy
it's
out
on
github.
I
haven't
seen
any
other
tools
like
this.
What
it
does
is
ssh
is
in
all
the
boxes
in
your
cluster,
so
you'd
have
you
know
you
have
a
25,
node
sender,
cluster
it'll,
connect
to
all
of
them
and
keep
a
persistent
connection
open,
and
then
it
reads
the
stat
files
from
proc
on
linux
and
calculates
these
values
every
two
seconds.
A
So
this
whole
thing
will
update
and
what
you
can
do
is
watch
the
state
of
the
whole
cluster
and
you'll
see
disk.
I
o
moving
around
the
cluster.
This
is
this
guy.
Oh
here
this
is
network
io.
So
you
can
see
the
behavior
of
the
cluster
in
a
holistic
view
just
right
in
your
terminal.
There's
no
web
browser,
fancy
stuff
and
then
they're
aggregate.
These
are
just
aggregates
down
at
the
bottom.
A
Iostat,
I
hardly
ever
use
iostat,
but
I
use
this
one
version,
this
one's
command
of
it,
which
is
iostat
minus
x1,
and
what
this
is
really
handy
for
is,
if
you
have
an
md-raid
device
or
any
kind
of
disk
aggregation
system,
so
it'll
work
with
zfs
or
md
raid
or
device
mapper.
What
you're
looking
for
here
are
these
these
columns
here
and
you're
looking
for
disks
for
outliers.
A
What
so,
what
usually
happens
with
the
raid
array?
Is
you
have
one
disk
that
starts
going
bad
and
starts
dragging
down,
and
so,
when
you
have
stripes
going
across
a
raid
set
you're
just
going
to
hit
that
disk
and
it's
going
to
spike
its
spike
latency
and
slow
the
whole.
I
o
down
for
the
application
and
a
lot
of
times
when
you
have
when
you're
looking
at
the
database
and
you're
scratching
your
head
and
what
the
hell
is
wrong
with
this
database.
Everything
looks
fine.
A
A
H-Top
is
one
that
I'm
I'm
surprised
that
more
people
don't
use
it's
a
improved
top,
so
everybody
uses
top
to
figure
out
which
processes
are
in
cpu.
The
nice
thing
with
h
top
is
it
shows
you
all
the
threads
by
default.
The
the
normal
top
can
do
that.
If
you
hit
capital
h,
but
this
one's
really
nice,
you
can
turn
on
color
coding.
A
A
A
I
I
recommend,
if
you're
administering
clusters
that
you
just
flip
through
the
tree
every
once
in
a
while
and
look
at
the
value,
especially
during
version
upgrades
and
look
at
what
those
some
of
those
values
are,
because
there
are
some
of
the
hidden
things
in
there
like
there's
the
assassinate
node
or
whatever.
It's
called
for
getting
rid
of
stale
nodes,
a
lot
of
the
the
kind
of
real
nuts
and
bolts
stuff
that
the
you
know.
A
My
colleagues
at
datastax
will
come
in
and
help
with
are
kind
of
hidden
in
there,
they're,
not
hidden
they're,
just
they're
not
easily
found.
So
I
mean
make
sure
you
know
how
to
connect
with
j
console,
make
sure
that
your
firewall
rules
are
set
up,
because
what
I
found
is
a
lot
of
times.
People
have
these
java
applications
running
in
ec2
or
whatever.
None
of
the
ports
are
up
for
jmx
a
lot
of
times.
It's
not
even
enabled
so
just
make
sure
that
it's
on
any
java
app
and.
A
A
A
Obviously
no
tool
ring
can
show
you
some
everybody
knows
that
one
cf
stats
and
there
are
a
whole
bunch
of
neat
other
commands
under
node
tool.
You
should
familiarize
familiarize
yourself
with
the
big
ones
to
watch
here.
Are
the
the
esses
table
count,
which
is
the
one
I
ran
into
if
that
gets
up
into
the
hundreds
of
thousands
you're
going
to
have
bad
day
and
the
bloom
filter
false
positive
ratio?
A
Obviously,
when
you
spin
up
a
new
cluster,
the
first
thing
you
should
do
is
try
to
put
some
stress
on
it:
they're
not
just
to
benchmark
it,
but
also
to
make
sure
that
the
hardware
is
burned
in
because,
like,
as
I
mentioned
before,
hard
drives
like
to
fail
when
they're
new
they
fail
when
they're
new
and
they
fail
when
they're,
really
old,
so
making
sure
you
do
a
whole
bunch
of
io
on
new
drives.
You
can
shake
that
up
before
you
go
to
production.
A
Cassandra
stress.
Obviously,
there's
been
a
lot
of
work
being
done
on
that
these
days,
to
make
it
a
little
easier
to
use.
Why
csb
is
a
lot
of
people
use
that
test
in
production
watch
your
production
traffic?
That's
why
I
spend
a
lot
of
time
on
system
stats
is
because
in
production
you
can
always
log
into
systems
and
without
causing
problems,
be
watching
system
stats
and
be
able
to
look,
and
if
you
get
good
at
watching
the
systems
you
can
see
traffic.
A
No,
I
have
two
more
minutes,
so
these
will
be
available
in
slides.
This
is
the
assist
control
comp
that
I
mentioned
earlier.
The
first
one
is
is
totally
unnecessary,
but
I
love
it
especially
on
map
reduce
systems
that
burn
through
pids
like
crazy.
It
sets
the
the
pit
max
to
a
million,
so
instead
of
the
pid
rolling
over
at
32
000,
it
will
actually
go
all
the
way
up
to
a
million
which
means
that
you
don't
it
doesn't
cycle
all
the
time.
A
So
when
you
type
psef,
you
don't
see,
your
processes
aren't
constantly
mixed
all
over
the
place.
You
actually
get
a
nice
period
of
time
where
they're,
nice
and
linear
it's
nice
for
observing
systems.
The
rest
of
these
I'm
gonna,
sorry,
I'm
gonna
have
to
skip
over
the
bottom
two.
I
don't
really
recommend
as
much
anymore,
but
they
can
be
pretty
important
for
I
o
systems,
and
definitely
these
network
settings
on
every
cassandra
box
should
have
these
basically
make
sure
that
you
open
up
the
throttle
on
network
I'll
skip
that.
A
If
you
have
dual
socket
intel
systems
or
amd
systems,
modern
ones,
actually
I'm
out
of
time-
I'm
sorry
I
can
talk
about
these
later,
but
make
sure
that
you
consider
numa
issues
when
you're
having
problems
with
memory
bandwidth,
it
happens.
I've
seen
it
in
production
java
has
support
for
pneuma
or
the
pneuma
control.
Inner
leaf
will
actually
make
sure
that
just
flatten
it
all
out
and
it
treats
all
memories
equal
and
will
spread
the
load
across
all
the
nodes
automatically.
A
So
sorry,
I
didn't
get
to
cover
those
slides,
but
conclusions
tuning
is
a
multi-dimensional
effort.
You
need
to
look
at
a
whole
bunch
of
different
considerations.
You
look
at
security,
look
at
systems,
metrics,
look
at
database,
metrics,
look
at
application
metrics
and
talk
to
your
operations.
People
talk
to
your
engineers
work
together
to
find
the
right
balance
of
things,
because
just
tuning
for
pure
speed
is
is
almost
never
the
right
answer
and
production
is
your
most
important
benchmark.
Thank
you
very
much.