►
Description
Speaker: Roy Bailey, Director of Neo Platform Services at UBS Securities
In this talk, Roy will discuss how their large scale client-facing application initiatives at UBS Securities utilize Apache Cassandra. This talk dives into their search for a scalable solution which allows them to serve their investment bank's equity time series data across the globe.
A
Good
afternoon
everybody,
my
name
is
Roy
Bailey
and
I
work
for
the
UBS
investment
bank,
not
a
bad
crowd.
Considering
the
competition
I've
got
on
this
particular
slot,
I
would
say:
I
was
expecting
a
few
less,
but
this
this
presentation
is
a
presentation
that
I
gave
earlier
in
the
year
on
a
meet-up
to
explain
to
people
the
the
story.
A
If
you
will
the
people's
story
in
the
database
choice
story
that
UBS
made
some
years
ago
on
cassandra
and
it's
quite
a
high-level
story,
could
I
just
ask
how
many
people
in
the
audience
have
got
Cassandra
live
in
production,
okay
and
then
the
rest
of
you
perhaps
investigating
and
thinking
about
it.
I'd
say
this
is
maybe
useful
to
those
thinking
of
adopting
cassandra
and
those
of
you
already
in
production
is
probably
not
much.
That's
very
new
here,
UBS
neo
I
work.
A
It
falls
under
the
e-commerce
department,
but
UBS
neo
is
the
platform
that
I
work
for
there's
a
little
URL
there.
If
you
want
to
know
a
bit
more
about
it,
you
can
punch
that
in
and
have
a
look.
It's
got
a
micro
site,
but
this
platform
was
a
very
bold
initiative
nearly
five
years
ago
now
to
rebuild
a
client
facing
application
across
the
entire
investment
bank
and
it's
the
neo
platform
that
introduced.
If
you
willed
the
the
new
innovative
database
technologies
onto
the
stack.
A
So
where
did
we
begin
as
I
say?
Ubs
neo
was
a
very
large
initiative
nearly
five
years
ago,
to
consolidate
many
many
client
facing
applications
that
the
bank
already
had.
Those
applications
were
in
themselves
very
good.
They
you
know
individually,
they
could
win
awards
for
certain
functionality
in
their
in
their
particular
field.
But
what
was
clear
is
that
there
was
no
unified
identity
for
UBS.
A
You
know
we
would
bring
that
down
in
tests
simply
because
we
had
so
many
users
hitting
them
trying
to
pull
back
large
volumes
of
time-series
data.
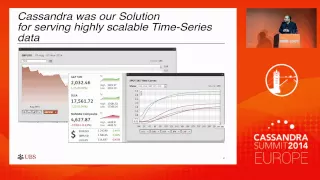
So
this
really
presented
the
problem
that
we
faced
as
I
say
nearly
five
years
ago,
when
this
initiative
was
started,
we
needed
to
find
a
way
of
serving
time
series
data
data,
very
scalable.
A
This
gives
a
pictorial
view
of
what
I've
just
said.
We
have
seven
data
centers
across
the
world,
but
a
lot
of
the
departmental
systems
that
had
time
series
data
on
them.
They
had
been
built
in
a
particular
region
for
a
particular
vertical
of
the
business
and
they
simply
weren't
up
to
the
idea
of
having
global
users
of
the
volume
that
we
were
looking
to
service
coming
in
and
hitting
those
departmental
systems
directly.
A
If
you
will,
the
time
series
data
and
providing
very
fast
reads
wherever
we
were
in
the
globe
to
the
front
end
system,
so
that
it
was
extremely
quick,
didn't
present
any
load,
it
protected
the
underlying
time
series
systems,
it
pulled
the
data
up
from
those
systems
on
a
daily
basis
to
refresh
the
Cassandra
distributed
cache
if
you
will
and-
and
that
was
why
Cassandra
was
chosen.
That
was
the
problem
five
years
ago.
This
was
that
was
the
problem
that
Cassandra
was
brought
in
to
solve.
A
A
A
A
This
was
something
that
that
we
were
picking
up
to
solve
real
problems
and
that
that's
a
good
credit
to
it.
Documentation
at
the
time
is
very
hard
and
limited
again.
Naught
point
six
version,
so
the
only
documentation
you
had
was
very
much
with
the
the
forums
and
and
that
and
a
lot
of
that
was
blocked
from
the
internal
internet
policies.
A
So
there's
a
lot
of
working
around
that
circumventing
that
and-
and
it
took
several
months
obviously
of
effort
to
put
that
together,
because
there
simply
wasn't
the
expertise
available
either
in
the
bank
or
outside,
and
there
wasn't
readily
available
documentation
and
things
were
moving
quite
fast
at
that
time
as
well.
So
it
did
present
a
number
of
challenges.
A
So
what
did
we
store
like
I
say
the
the
initial
problem
was
our
time
series
data,
but
what
became
apparent
very
very
quickly
was
once
we
had
Cassandra
in
in
our
mix
as
an
available
data
store.
There
was
a
number
of
other
use
cases
that
quickly
came
on
board
off
the
back
of
it
simply
being
available.
A
The
second
purpose
was
instrument
data
itself,
where
we
had
to
load
an
enormous
amount
of
financial
instrument,
data
into
our
2,
vo
search
engine
and
again
the
same
kind
of
problem
really,
although
not
not
to
the
degree
of
the
time
series,
but
we
had
a
lot
of
departmental
systems
that
would
would
feed
the
search
engine
always
going
back
to
those
departmental
systems,
put
an
enormous
strain
on
them.
If
we
had
to
ever
rebuild
the
search
index
so
very,
very
quickly,
Cassandra
was
used
almost
like
a
document
store.
A
If
you
will
to
again
to
bring
data
from
departmental
systems,
make
it
readily
available,
keep
it
keep
it
refreshed
and
allow
the
other
parts
of
our
platform
to
access
that
very,
very
quickly
and
refresh
very,
very
quickly
from
it
and
then
the
sort
of
human
side
of
you
know:
we've
no
longer
just
got
this
relational
database.
This
managed
service.
We
now
have
this
Cassandra
store.
A
There
was
a
whole
bunch
of
different
use
cases
where
people
started
to
put
data
into
Cassandra
I
mean
you
know,
developers
that
tend
to
get
a
little
trigger-happy
when
they
get
a
new
technology,
so
in
in
a
few
edge
cases
they
didn't
necessarily
pick
the
right
store,
but
generally
there
was
different.
If
there
was
a
need
to
store
some
data
down,
then
people
were
looking
to
Cassandra,
because
it
was
very
quick
and
very
straightforward
to
get
data
in
and
get
data
out.
A
We
made
a
few
choices
around
how
to
store
this
data.
First
one
is
natural
keys,
so
in
Cassandra
you
have
rows
or
petitions
I
think
they're
called
now
and
columns.
In
our
case
where,
if
you
look
at
our
use
case,
it
was
really
as
a
distributed
cash.
So
natural
Keys
made
sense
because
we're
not
mastering
data
into
Cassandra.
A
The
only
consideration
we
had
to
have
was
is
this
data
atomic.
It
doesn't
involve
lots
of
relationships
and
joins,
and
things
and-
and
so
data
is
stored
again
in
in
rows
that
naturally
collect
related
data
together,
but
in
columns
that
keep
them
separate
so
that
you
have
the
the
the
atomic
nature
of
pieces
of
data
that
go
to
make
up
the
collection.
A
There
was
a
lot
of
use
cases
here,
very
skinny,
very
skinny
tables
of
key
values,
binary
blobs
for
images.
Cassandra
really
just
didn't-
have
a
problem
that
the
the
key
was.
Do
you
have
relationships,
or
do
you
need
to
just
store
chunks
of
data
that
you
want
to
be
able
to
query
efficiently
and
get
out
quickly.
A
This
diagram
just
kind
of
illustrates
that
natural
fits
of
time
series
data
going
into
Cassandra.
We
have
the
feeds
from
our
departmental
systems,
coming
up
loading,
the
data
into
Cassandra,
using
natural
keys
for
the
rows,
and
then
obviously
the
variable
width
per
instrument,
depending
on
how
much
time
series
data
we
have,
it
may
be
going
all
the
way
back
to
1900
or
or
it
may
only
be
going
back
a
few
years
or
a
few
months,
depending
on
the
age
of
that
particular
instrument,
but
using
the
time
in
the
column
to
be
automatically
sorted.
A
A
Upgrades
is
not
always
something
that
when
you
start
to
introduce
something
new,
you
really
stop
to
think
about.
Certainly,
I've
worked
in
several
places
where
yeah
there's
been
a
push
for
a
new
technology,
and
people
are
very
enthusiastic
because
it
solves
a
problem,
but
they
haven't
really
thought
through
the
whole
lifecycle.
The
total
cost
of
that
of
introducing
that
technology.
So
to
touch
on
the
upgrades
we've
been
through
as
I
say,
we
went,
live
with
version,
naught
point
7
only
a
couple
of
data
centers
five
nodes
each.
A
We
then
had
to
upgrade
that
to
the
1.0
release.
That
was
a
little
bit
more
work
for
us,
because
at
the
time
the
tooling
wasn't
around
to
to
sort
of
reconcile
that
data.
So
we
were
kind
of
nervous
about
going
from
a
point:
seven
release
to
a
1.0
release
in
case
that
any
of
the
data
was
lost.
So
we
spent
a
little
bit
of
extra
effort
there
to
make
sure
that
that
was
all
sound,
that
we
had
the
the
the
checks
in
place
to
be
able
to
check
some
of
the
data
before
and
afterwards.
A
But
that
went
through
very
very
smoothly.
Just
you
know
there
was.
There
was
no
surprises
out
of
that
and
then
more
recently
this
year,
we've
upgraded
to
Cassandra
2.0
through
the
data
stacks
product,
and
that
was
incredibly
smooth
as
well
and
and
those
kinds
of
lessons
on
a
journey
like
this
is
quite
important
because
you
know
as
a
big
organization.
We
don't
like
to
go
through
these
upgrades.
Very
often
it's
actually
quite
hard
to
to
get
the
time
to
tell
the
business.
A
You
know
we're
gonna
have
to
sort
of
divert
some
of
your
precious
resources
onto
upgrading
a
database
technology.
What
am
I
going
to
get
for
its
there
performance,
maybe
something
else.
It
doesn't
go
down
very
well,
so
you
want
it
to
be
painless.
You
want
it
to
be
reasonably
efficient
and
in
our
cases
we've
we've
not
had
any
difficulties
there.
A
We
are
using
the
thrift
driver,
which
is
why
the
last
points
there,
because
it
was
five
years
ago.
Obviously,
cql
is
very
new.
We're
currently
in
the
process
of
looking
migrating.
Everything
over
to
cql
and
I
can
only
say
that's
another
step
in
in
a
positive
direction.
It
looks
very,
very
promising
indeed,.
A
Ok,
so
what
we
learnt
through
this
process,
we
did
go
through
several
pain
points.
You
know
around
the
testing
and
and
I'll
share
those
with
you
really
really
wide
columns.
So
we
built
our
own
indexes,
because
the
local
index
is
that
Cassandra
supports
were
not
suitable
for
kind
of
lookups
that
we
wanted
to
do,
but
in
our
in
our
urgency
we
kind
of
put
too
much
into
one
row
to
its
credit.
A
Cassandra
is
simply
complained
and
said:
really
quite
badly
hurt
my
memories
not
doing
so
good,
and
it
was
very,
very
easy
to
see
how
we
should
have
chunked
that
down
and
broken
it
out
into
into
different
partitions
in
order
to
spread
that
load
across
across
the
different
Cassandra
nodes.
That
was,
that
was
a
quite
a
big
one
for
us,
but
it,
but
again
it
was
nice
to
see
that
Cassandra
sort
of
dealt
with
it.
Yes,
it
complained
as
it
as
it
should,
but
it
didn't
fall
on
its
knees
and
give
up
it.
A
A
And
if
you
use
the
default
compaction
strategy,
then
you
have
a
lot
of
these
tombstones
building
up.
Then
you
will
get
timeouts
because
cassandra
is
effectively
having
to
seek
its
way
past
lots
of
tombstones
in
order
to
get
to
the
real
data,
but
again
changing
to
leveled
compaction
has
has
leveled
that
out
and
removed
that
problem
performance
tuning.
This
is
something
that
you
can.
You
know
when
a
product
works.
A
You
tend
not
to
spend
a
lot
of
time
on
the
tuning
that
we've
got
a
lot
of
value
from
actually
looking
at
the
settings
that
we
had
in
Cassandra
the
memory
in
particular
and
making
sure
that
that
things
were
set
up
correctly
and
using
the
natural
keys
for
the
actual
data
itself,
which
is
the
primary
use
case,
work
very
well.
But
if
you,
if
you
iterate
through
partition
keys,
then
it's
quite
a
slow
process.
So
looking
at
creating
your
own
indexes
so
that
you
can
do
fast,
query
lookups!
A
A
So
natural
Keys
made
sense,
but
if
I'm
mastering
data,
then
I
probably
would
want
to
go
with
a
key
and
thinking
about
your
queries
and
understanding
how
how
the
the
table
model
of
rows
and
ordered
column
names
works
to
your
advantage
for
the
different
use
cases
that
you
have
and
your
time
to
live
so
how
quickly
something
is
going
to
stick
around
off
and
have
deleted.
It
is
something
else
you
might
want
to
think
about,
but
being
able
to
expire
data
without
having
to
write
your
own
code
is
extremely
handy.
A
A
It
usually
does
a
pretty
good
job
of
just
handling
it,
but
it
does
make
a
lot
of
doesn't
make
a
lot
of
sense
to
understand
how
your
rows
and
your
columns
are
ordered,
how
your
queries,
how
you're
going
to
pull
out
that
data
and
to
tweak
some
of
those
database
settings
just
to
make
sure
that
that
you
get
the
best
performance
possible,
because
you
can
make
quite
a
bit
of
difference.
There.
A
A
So,
just
to
round
off
overall
Cassandra
did
just
work.
I
could
say
even
five
years
ago
on
a
Northwind,
six,
nine
point,
seven
version
it
works
and
it
worked
extremely
well.
It
has
that
time
series
sweet
spot
because
of
the
column
ordering
if
you
use
that
standard
pattern,
and
it's
extremely
good
at
taking
a
lot
of
Rights
and
even
a
lot
of
reads
across
globally
distributed
cluster,
so
overall
I
think
our
production
support
department
that
obviously
have
to
maintain
and
look
after
issues
around
a
number
of
data
technologies
as
well
as
other
other
infrastructure.
A
They
really
just
don't
have
a
lot
of
problems
with
the
Cassandra
tour
I
think
it's
probably
their
favorite
out
of
all
of
them,
because
we've
not
had
production
issues
that
have
caused
them
any
pain.
So
that's
another
good
endorsement
that
pretty
much
rounds
it
up
for
for
me.
Thank
you
very
much
for
listening
happy
to
take
questions
now
or
outside
afterwards.
If
there's
anything
else,.
A
B
A
A
It
was,
it
was
different
in
instead
of
having
time
across
the
columns,
we
had
effectively
the
documents
across
the
columns
that
made
up
that
entire
instruments,
reference
data,
so
for
a
bond
you
would
have
issue
and
you'd
have
schedules
and
you'd
have
ratings,
and
so
you'd
have
all
of
these
pieces
that
made
up
that
entire
financial
instrument.
They
would
come
in
from
different
sources,
and
you,
you
know,
casandra's,
very
good
for
that
atomic
storing
of
data
and
retrieving
of
data.
You
don't
want
to
be
trying
to
merge
at
the
Cassandra
level.
A
You
want
to
keep
keep
those
blobs
if
you
will
in
separate
but
together
in
the
row
for
that
instrument.
So
so
the
same
kind
of
conceptual
model.
Is
there
that
and
instruments
data
is
in
one
row
so
that
it's
all
together
it's
on
the
same
nodes
and
when
you
want
to
grab
it
all,
you've
got
it
all
there
to
hand,
but
the
columns
are
then
used
slightly
differently
because,
instead
of
time
series
you
just
you
have
different
chunks
of
data
that
go
to
make
up
that
full
picture.
I.
A
But
the
pain
points
I
was
alluding.
To
is
more
the
the
fact
that
you
know
it
was
in
beta.
There
wasn't
a
lot
of
documentation.
Now
we
have
a
lot
of
good
material
out
there
for
the
different
versions
back.
Then
there
wasn't
a
lot,
so
you
had
to
really
just
experiment
and
that's
where
a
lot
of
the
time
was
taken.
A
But
we
have
thought
about
using
Cassandra,
for
if
you
will
the
time
series
of
reference
data
as
well-
and
there
are
actually
a
number
of
I
call
them
spin-offs,
they're,
not
really
spin-offs,
but
there's
a
number
of
departments
that
are
now
using
Cassandra
they're,
either
about
to
go
into
production
or
they
are
close
to
going
into
production
and
that's
one
of
the
use
cases,
but
they're
a
lot
bigger
than
this
one.
This
is
just
the
the
oldest.
If
you
will.
A
A
That
that's,
where
you
get
into
the
classification
and
building
your
indexes
for
that
particular
query.
So
that's
where
we
created
various
indexes
for
different
sorts
of
lookups,
where
we
wanted
to
classify
instruments
together
and
then
be
able
to
come
in
and
and
grab
them.
So
it
just
creates
that
that
that
fast
response
to
be
able
to
say
give
me
all
the
instruments
of
this
classification
and
then
I
can
go
away
and
pull
that
data
down
that
I
need.
You
know
very
very
quickly
on
each
of
those.
A
A
Yes,
yes,
yes,
and-
and
it's
got
very
good
settings
in
terms
of
being
able
to
tune
throughput
and
things
as
well,
because
when
we
went
out
to
Sydney,
for
example,
there's
a
there's
a
lot
more
latency
there
and
we
didn't
want
to
bring
down
the
you
know.
The
pipe
there
so
being
able
to
to
set
a
throughput
on
the
replication
was
was
a
good
benefit,
because
we
we
could
tell
the
network
guys
yeah
we're
not
going
to
take
up
all
your
bandwidth.
Just
because
we're
having
to
be
bulk
loading
lots
of
data.
A
Unless
we
build
the
tools
ourselves
to
pull
out
our
data
and
to
show
it,
you
don't
really
get
a
lot
out
of
the
box
and
with
the
introduction
of
cql
you
can,
you
can
use
cql
to
query
out
thrift
tables,
but
you
get
a
lot
of
blobs,
which
isn't
very
helpful.
So
it's
it's
partly
being
able
to
to
query
that
you
know
just
be
able
to
run
some
routine
maintenance
if
there
is
an
issue
with
an
instrument,
then
not
having
to
develop
a
specific
tool
to
pull
that
data
out.
A
To
just
be
able
to
do
a
select
statement
and
have
a
look
at
the
data
is,
is
one
motivation.
The
other
motivation
is,
is
the
fact
that
you
may
have
seen
from
some
of
the
other
from
from
the
keynote
speech,
for
example,
that
you
know
cql
as
a
as
a
performance
tuned
driver
that
is
being
taken
forward
is
is
going
to
outstrip
the
thrift
driver
more
and
more
as
time
goes
on.
So
I
see
the
the
thrift
implementation
as
something
that's
going
to
go
end-of-life
at
some
point
and
that
that's
the
secondary
reasons.
A
There
is
a
there
is
a
learning
curve
in
in
that
process,
but
what
we've
been
able
to
do
so
far
is
recreate
if
you
will
the
same
sorts
of
models
that
we've
got
from
our
thrift
in
cql.
So
it's
really
more
a
case
of
choosing
the
timing.
When,
whenever
we're
going
to
go
in
and
do
a
little
bit
of
maintenance
or
enhancements
for
the
business,
then
at
that
point,
we'll
probably
flick
it
over.
A
There's
I
mean
one
one
of
the
tricks
I
blogged
about
was
to
create
your
table
in
CQL
and
then
go
into
the
Cassandra
CLI
and
have
a
look
at
exactly
how
your
data
is
being
stored.
You'll
very
quickly
be
able
to
see
how
the
cql
partition
key
and
the
column
keys
end
up
actually
in
the
storage
engine
in
some
ways
that
we
ashamed
when
they
deprecated
that,
because
it's
a
very
nice
well,
it's
very
comforting
to
be
able
to
create
that
cql
for
me
anyway,
having
having
built
it
once
into
it.
A
A
Yeah
we
I
mean
we
could
be
in
all
honesty,
and
certainly
the
cluster
runs
24/7.
We
we
haven't
had
any
outages,
we
haven't
had
any
problems,
but
in
reality
our
customers
aren't
around
at
the
weekend
and
there's
all
sorts
of
maintenance
goes
on
in
the
infrastructure
world.
So
if
we
ever
do
need
a
chunk
of
downtime,
we
do
have
that
luxury
of
being
able
to
take
a
few
hours
out
at
the
weekends.