►
From YouTube: GMT20230530 170422 Recording 1652x992
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
Is
is
an
sorry
Zoom
just
and
I
threw
up
our
notification
alrighty,
so
the
the
cep
is
titled
Reading
Writing
Cassandra
data
with
spark
bulk
analytics
and
the
historical
context
here
is
that
Cassandra
as
as
a
database,
does
great
when
it
comes
to
doing
Point,
reads
or
Point
rights
type
of
queries.
But
when
it
comes
to
you
know,
scooping
data
out
of
Cassandra
into
a
system
like
spark
in
order
to
do
any
sort
of
analytical
workloads.
A
So
with
this
CP,
we
are
trying
to
address
some
of
these
issues,
which
are
generally
impact
which
generally
impact
the
database
when
we
are
doing
a
lot
of
pointers
and
point
right
queries.
So
that's
the
basic
motivation.
We
are
able
to
read
and
write
a
lot
of
data
in
Cassandra
now
when
it
comes
to
the
actual
the
cep.
There
are
two
major
contributions
here.
So
one
of
the
contributions
is
this
Cassandra
spark
analytics
Library.
A
A
For
those
who
don't
know
a
whole
lot
about
this
and
sidecar,
please
look
at
our
CP
cp1,
which
was
the
very
first
CP
that
we
proposed,
which
is
the
Cassandra
site
management
process
which
now,
in
today's
world
we
call
it
as
the
Cassandra
Sidecar.
So
with
that
historical
context,
basically
I'd
like
to
dive
deeper
into
how
this,
how
this
actual
functionality
is
implemented
for
Cassandra
users.
So
for
that,
let's
look
at
the
actual
API.
A
A
We
are
using
spark
as
an
engine
that
has,
you
know,
has
some
amount
of
data
that
you
have
loaded
in
a
in
a
data
frame,
and
you
want
to
write
that
data
frame
into
Cassandra,
so
data
frame
nicely,
you
know,
goes
and
maps
to
a
table
within
Cassandra.
It
is
a
row
oriented
structure
and
it
is.
It
has
rows
and
columns
very
much
similar
to
what
Cassandra
has
so.
In
order
to
do
that,
here's
it
has
all
the
code
that
you
need
to
write.
A
One
of
the
things
to
remember
here
is
that
when
we
do
any
sort
of
bulk
reads,
we
are
going
to
create
a
snapshot
on
Cassandra.
A
snapshot
is
a
common
operation
that
we
do
in
order
to.
You
know,
get
a
view
of
the
data
within
Cassandra,
and-
and
this
is
what
the
bug
feeder
also
does.
It
does
create
a
snapshot
on
each
of
the
nodes,
each
of
the
instances
that
Cassandra
has
and
when
we
do
that
bulk
read.
A
We
are
reading
the
data
through
the
sidecar
and
do
a
data
frame
that
that
is
made
available
in
spark
and
if
let's
say
you
wanted
to
do
some
sort
of
aggregation,
this
is
a
simple
example
where
we
are
creating
in
aggregation
and
let's
say
we
want
to
cop
count
the
you
know
the
entire
data
set
on
this
column
C.
We
can
create
an
aggregation
through
spark,
so
anything
that
you
can
do
with
spark.
A
You
can
do
it
on
this
particular
data
frame
and
you
know
you'd
basically
be
able
to
do
it
at
using
all
the
data
that
exists
within
within
Cassandra
now,
a
lot
of
You
Must
Be
Wondering.
So
this
is
functionality
that
you
know
can
can
be
implemented
using
the
Cassandra
driver.
So
what's
the
need
to
have
this
mechanism
this
this
different
mechanism
of
doing
this
pretty
much
the
same
thing
so
so
skipping
over
I
want
to
show
you
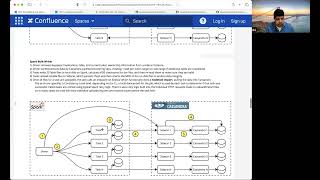
the
architecture
of
this
and
the
data
flow.
A
A
It
gets
distributed
to
all
of
these
tasks
and
the
for
the
bulk
reading
functionality.
The
the
driver
is
going
to
invoke
snapshot
functionality
within
the
sidecar,
and
each
of
these
sidecars
basically
go
in
and
create
a
snapshot
on
these
individual
nodes
that
exist
at
the
Cassandra.
Once
the
snapshot
is
created,
then
what
we
can
do
is
the
individual
tasks.
They
will
scoop
up
all
the
SS
tables
that
come
in
from
the
sidecar
into
into
spark.
A
So
that
is
like
difference,
a
big
difference
right,
where
what
we
are
doing
here
is.
We
are
avoiding
through
Cassandra's
cql
protocol
and
I'll
dive
into
a
little
bit
deeper
into
why
we
want
to
avoid
the
SQL
protocol,
and
here
the
expectation
is
that
you
want
to
work
on
the
entire
data
set
that
exists
in
the
Cassandra
cluster.
So,
what's
Happening
Here
is:
let's
say
you
have
you
know
a
Cassandra
cluster
with
10
terabytes
of
data
or
100
terabytes
of
data.
A
Your
sidecars
are
able
to
stream
all
of
the
SSD
balls
at
at
a
binary
level
right
at
a
block
level,
Without
Really
interpreting
any
of
the
data
in
memory.
So
we
don't
really
serialize
or
deserialize
any
data
that
exists
in
in
Cassandra
we
just
directly
ship
the
SS
table
or
to
the
windows
of
spark
tasks,
and
this
means
that
we
are
not
going
to
create
any
sort
of
garbage.
A
We
are
not
going
to
incur
any
penalty
in
terms
of
CPU
or
memory
pressure,
because
all
we
are
doing
is
zero
copying
streaming
the
data
out
of
Cassandra
sidecar
and
into
the
tasks
that
exist
on
spark.
So
we
can
go
as
fast
as
the
network
would
allow
us
to
do
it
once
the
once.
The
data
gets
into
the
individual
tasks,
the
the
library.
This
is
the
library
that
goes
and
maintains
the
Quorum.
So
it's
everybody
should
probably
know
here
is
that
Cassandra
is
a
quorum
based
service
right.
A
It's
a
database
that
is
going
to
replicate
the
data
set
across
multiple
nodes
in
the
in
the
customer
cluster
in
order
to
maintain
availability
and
in
order
to
you
know,
maintain
durability
of
the
data.
So
in
case
one
of
the
node
dies
answer
reminiscently.
There
are
two
other
nodes
in
rf3
configuration,
and
this
is
kind
of
the
Dilemma
that
we
we
have.
Since,
let's
say
we
scoop
up
the
data
from
a
Cassandra
node.
A
Now
the
task
has
to
basically
read
the
SS
tables
from
the
other
two
replicas
in
order
to
make
sure
that
all
the
three
replicas
are
on
the
same
page.
So
we
basically
have
implemented
that
in
the
library
and
the
way
we
Implement,
that
is
again
using
Cassandra's
code
itself,
the
Cassandra
all
jar
is
packaged
as
part
of
the
library
and
all
it
does
is
it.
A
It
reads:
data
from
those
individual
access
tables
and
ensures
that
all
the
rf3
or
whatever
is
your
application
factor
is-
is
satisfied
in
in
spark
and
from
that
point
onwards,
what
we
do
is
we
actually
deserialize
individual
rows
and
columns
in
the
the
spark
task
and
provide
a
consistent
view
of
the
data
that
was
snapshotted
on
Cassandra.
This
allows
us
to
achieve
throughputs
that
are
typically
not
possible
on
Cassandra,
because
we
are
skipping
all
the
serialization
destabilization
logic
on
these
individual
Cassandra
nodes.
A
The
actual
demon
process
that
is
serving
the
read
and
write
path
of
the
database
is
not
impacted
as
a
consequence
of
this
right.
The
only
thing
is
yes,
we
are
consuming
a
lot
of
network
bandwidth,
but
network
is
typically
cheap
and
so
I
we
don't.
We
don't
see
any
sort
of
meaningful
changes
in
the
latencies
or
the
throughput
of
the
of
the
treatment,
and
this
is
what
the
bulk
reader
achieves.
A
People
do
something
very
similar,
except
that
they
they
basically
read
directly
from
Cassandra,
and
they
scan
one
token
at
a
time
and
they
dump
all
of
that
data
into
something
like
hdfs
or
Hadoop
or
S
these
days,
and
they
then
scan
that
data
or
you
know
if
they
have
converted
it
into
parquet
or
some
other
format.
They
can
run
analytical
workloads
on
that.
A
While
that
is
a
great
architecture,
it
also
incurs
the
additional
cost
of
putting
the
data
on
an
external
system
like
S3
or
hdfs,
which
itself
is
replicating
the
data
many
ways
and
that
increases
your
time
and
cost.
But
this
approach
you're
directly
reading
from
the
Cassandra
cluster,
without
impacting
the
the
cluster's
performance
and
typically
spark
and
Cassandra
have
been,
have
been
paired
together
in
the
past,
and
this.
This
continues
that
so
your
existing
code
will
pretty
much
work,
as
is
on
spark.
A
The
only
difference
is
now
you're
adopting
a
different
library
in
order
to
read
and
write
that
data.
So
that's
the
that's.
The
spark
bulk
read
functionality
similar
to
the
read
functionality,
there's
write
functionality
as
well.
Again,
all
of
this
functionality
has
been
implemented
in
terms
of
like
no-toll
import
that
that
pretty
much
exists
in
Cassandra
and
what
the
writer
does
is
basically
the
the
exact
inverse
of
what
the
reader
does
this
case.
A
You
could
do
one
record
at
a
time,
but
again
you
end
up
with
the
same
exact
scenario
where,
for
the
batch
load
of
that
data,
you
are
going
to
dominate
the
the
night
path
of
Cassandra
and
while
Cassandra's
right
skills.
Well,
you,
we
will
see
an
added
pressure
on
all
of
these
individual
instances,
so
instead
of
you
know
generating
the
SS
tables
in
the
individual
customer
nodes.
What
the
bulk
writer
does
is.
It
goes
and
uses
the
the
same
library
that
we
have.
A
It
uses
that
to
take
the
data
set
and
sort
them
into
rows
that
go
into
the
individual
Cassandra
nodes
based
on
their
tokens,
and
it
will
then
create
the
SS
tables
on
the
spark
worker
nodes
itself.
Once
the
the
SS
tables
are
created,
then
it
uses
the
sidecar
apis
to
push
the
data
into
individual
Cassandra
nodes
on
the
disk
and
then
once
all
of
the
data
is
in.
A
All
we
do
is
import
the
data
into
Cassandra,
so
the
lsm3
architecture
of
Cassandra
makes
it
possible
for
us
to
just
create
new
access
tables,
put
them
inside
Cassandra,
and
then
you
know,
call
node
to
import
and
Cassandra
basically
makes
them
available
as
part
of
the
as
part
of
the
view
live
serving
view
of
the
data.
So
it
makes
it
very
easy
for
us
to
work
with
with
new
access
tables
and
that's
the
that's
the
capability
that
we
are
using
in
this
model
as
well.
A
So
with
the
bulk
writer
and
bulk
reader,
there
have
been
some
benchmarks
that
we've
done
and
essentially
what
what
it
reveals
is
that
you
know,
since
we
are
generating
the
access
tables
on
spark
or
we
are,
we
are
interpreting
in
such
a
business
part.
We
are
not
impacting
any
any
of
the
nodes
in
the
Cassandra
cluster
itself,
so
you
don't
need
to
like
create
a
separate
Cassandra
cluster.
The
historically
people
have
created
two
Cassandra
clusters.
Each
one
is
for
Reading
Writing
data
and
the
other
is
for
purely
running
analytics.
A
Now
you
can,
with
this
model,
get
away
from
creating
that
extra
cluster.
Just
you
know,
run
your
analytical
workloads
on
the
same
same
class,
same
set
of
nodes
that
you're
doing
reads
and
writes,
and
there
is
enough
redundancy
that
is
built
into
the
bulk,
read
and
bulk
right
capabilities
that
we
can
ensure
that
you
know
we
don't
overwhelm
any
of
the
nodes.
So,
for
example,
we
have
throttling.
A
So
if,
if
you
are
not
sure
whether
you
you
would
want
to
saturate
the
network
bandwidth,
so
what
you
can
do
is
you
can
certainly
set
some
throttling
on
the
side.
Car
sidecar
has
those
throttling
capabilities
and
you
can
limit
the
throughput
if
that
is
a
area
of
concern,
but
overall
that
is
sufficient,
return
logic
and
sufficient
guards
in
place
that
we
would
not
like
overwhelm
the
consignment
cluster.
A
One
of
the
things
that
the
bulk
writer
does
is
is
that
once
it's
done
with
the
import
or
if
the
import
Fields
part
way,
there
is
data
that
that
might
be
lying
around
in
these
in
this
disks
that
hasn't
been
imported
or
has
been
partly
imported,
and
basically
there
is
logic
that
would
clean
up
the
data
that
exists,
but
has
not
been
imported.
So
all
of
these
capabilities
already
exist.
A
Let's
see
yeah,
so
all
of
these
site
current
points
are
basically
their
services
which
give
us
some
metadata
that
is
required
for
the
bulk,
read
or
bulk
right
functionality
to
work,
but
all
of
these
are
composable
and
rest
endpoints.
So
if
somebody
would
like
to
use
these
endpoints
in
order
to
replicate
some
of
this
functionality
in
other
systems,
or
you
want
to
write
a
like
a
standalone,
Tool
Cassandra
has
this
SSD
poll
loader
tool
that
that
exists
inside
the
Cassandra
repository
this.
A
These
apis
can
can
augment
or
even
replace,
that
function
D,
and
with
this
these
apis,
you
could
reuse
them
in
in
your
in
your
Tooling
in
any
of
your
scripts
there.
If
you
would
like
to
as
well
so
the
sidecar
opens
up
the
ability
for
a
lot
of
innovation
on
on
this
on
the
side,
and
it
doesn't
really
impact
the
the
database
in
our
very
significant
way
if
you
are
invoking
these
apis.
A
So
apart
from
that
I
just
wanted
to
so
for
more
information,
please
read
the
cep
there
have
been.
There
have
been
a
lot
of
questions
that
were
part
of
the
discuss
thread,
so
this
discuss
thread
which
talks
about
the
cp28
was
was
started
by
Doug
and
there
have
been
some
interesting
questions
with
interesting
back
and
forth.
A
This
is
open
to
anybody
who
is
interested
in
contributing
to
the
Cassandra
sidecar
project
outside
of
the
analytics
work
that
that
has
happened
in
part
of
the
CP,
but
right
now,
I
think
the
main
main
contribution
that
we
are
looking
for
are
people
to
test
this
out,
give
us
feedback.
There
might
be
some
rough
edges
and
you
know
we
love
to
have
folks
pitch
in
and
try
it
out.
Other
example
examples
in
this
repository
as
well.
A
As
you
know,
this
page
exists
actually
readme
exists
which
will
walk
you
through
setting
it
up
and
running
your
first
analytics
job.
It
does
require
a
little
bit
of
coordination
if
you'd
like
to
deploy
this
and
try
it
out.
Currently,
the
sidecar
doesn't
have
an
authenticator,
which
is
an
area
for
contribution
as
well.
So
once
we
have
some
sort
of
authentication,
it
might
be
easier
to
deploy
this
s
cluster
and
run
it.
A
But
if
you
would
like
to
run
it
on
your
local
machine,
you
can
certainly
do
that
and
try
it
out
as
well.
So
what
I
would
highly
recommend
doing
is
just
giving
us
feedback
at
the
start,
and
if
you
find
this
useful,
do
give
us.
You
know
some
feedback
as
well.
If
you
find
some
rough
edges,
things
don't
work,
please
go
ahead
and
find
jeera's
in
the
Cassandra
project,
and
we
can.
A
A
A
So
when
you
build
your
spark
jar,
you're
just
going
to
pull
this
in
as
a
library
like
you
do
with
the
Cassandra
driver
or
any
independency
really,
and
there
isn't
anything
special
that
we
really
need
to
do
for
for
this
to
work
with
spark.
So
it's
fairly
decoupled
with
sparked
as
bits
that
make
it
easy.
Like
you
know,
Concepts,
like
data
frames,
don't
really
exist
in
other
systems,
but
they
do
exist
in
spark.
A
A
A
A
The
this
particular
functionality
has
the
potential
to
generate
garbage,
not
that
it
does,
but
it
can
in
in
some
situations
and
and
the
other.
You
know,
scenarios
that
it
can
dominate
the
network
and
so
What.
What's
best
is
if
this
is
isolated
in
a
separate
process,
you
could
use
c
groups
or
you
could
use
other
mechanisms
that
exist
in
the
industry
in
order
to
limit
the
number
of
resources
that
are
used
by
this
particular
process.
A
If
you're
running
this
in
kubernetes
kubernetes,
you
know
part,
you
can
run
this
as
a
separate
container
and
you
could
limit
the
amount
of
CPU
and
you
know,
memory
and
other
resources
that
that
particular
container
gets,
which
is
which
wouldn't
be
possible
to
do
in
in
jvm
like
you
would
have
to.
We
would
have
to
write
a
lot
of
code
to
create
that
isolation
and
it
wouldn't
be
as
strong
as
what
c
groups
allows
you
to
do.
A
C
Hopefully,
people
are
here
to
learn
and
see
what
it's
all
about
thanks,
Patrick
I
saw
your
note
yeah.
Well,
we
appreciate
you
joining.
Thank
you
Dinesh.
Hopefully
we
we
see
some
people
contributing
to
this
I
I
put
a
note
in
this
in
the
chat,
but
just
so
folks
know
this
is
great
for
first-time
contributors,
as
Dinesh
has
said,
it
doesn't
require
deep
expertise
in
Cassandra
or
spark.
C
A
C
Think
trying
it
out
and
reading
reading
the
CPS
that
indicated
by
trying
it
out
as
well
is
something
that
I
would
encourage
everybody
to
do.
Okay,
excellent!
Well,
we
appreciate
it
and
we
have
the
next
contributor
meeting
it's
the
last
Thursday
or
last
Tuesday
of
the
month.
So
the
next
one
is
June
27th.
If
folks
can
join
we'll
be
going
through
all
the
different
ceps
that
are
anticipated
features
for
5.0,
so
it's
a
great
place
to
learn
about
it,
figure
out
how
to
contribute
test.