►
Description
You know you need Cassandra for it's uptime and scaling, but what about that data model? Let's bridge that gap and get you building your game changing app. We'll break down topics like storing objects and indexing for fast retrieval. You will see by understanding a few things about Cassandra internals, you can put your data model in the spotlight. The goal of this talk is to get you comfortable working with data in Cassandra throughout the application lifecycle. What are you waiting for? The cameras are waiting!
A
Welcome
everybody
to
this
edition
of
cassandra
community
webinar
series.
I
am
delighted
today
to
introduce
patrick
McFadden.
He
is
the
chief
evangelist
for
the
Apache
Cassandra
community
here
at
data
stacks
and
Patrick.
This
is
the
third
in
his
data
modeling
series.
You
know
we
hear
from
so
many
people
in
the
community
that
getting
your
head
around
data
modeling
is
really
a
prerequisite
to
being
successful
with
your
application
on
Cassandra.
A
So
in
this
webinar
Patrick
will
just
recap
some
of
the
fundamentals
around
data
modeling
and
then
by
the
end
of
the
webinar,
you
will
really
be
in
good
shape
as
you
move
forward
and
as
always
with
our
community
webinars,
we
will
be
reserving
QA
until
the
end.
Please
use
the
WebEx
Q&A
panel
and
post
your
question
there.
We
will
reserve
time
I
will
read
through
them
and
we
will
get
through
just
as
many
questions
as
we
can
in
the
time
allotted
so
without
further
ado.
I
will
hand
everything
over
to
Patrick
welcome
Patrick.
B
B
B
Got
it
okay,
so
we
have
a.
This
is
the
third
part
of
the
series,
so,
let's
get
into
where
we
were
so.
The
first
part
of
the
series
was:
the
data
model
is
dead,
the
one
with
the
data
model,
and
it
was
really
about
just
bridging
that
knowledge
gap
between
relational
database,
world
and
Cassandra.
It
was
all
about
really
into
context
and
trying
to
help
you
get
through
some
of
those
concepts,
always
a
requirement
because
I
I
talk
to
people
all
the
time.
We've
learned
relational
databases
we
as
the
community.
B
We
as
a
technical
people,
have
learned
relational
databases
for
years
and
years
and
there's
just
some
ingrained
knowledge.
How
can
we
use
that
knowledge
instead
of
replacing
it
augmented
and
get
to
this
newer
type
of
technology?
That
will
give
us
things
that
we
want
that?
Maybe
a
relational
database
won't
and
then
the
second
was
the
became
a
super
model
er
next,
one
I
really
get
into
the
hard
core
part
of
data
modelling,
and
it's
all
about
cql
and
the
ticket
standard.
Query
language
I
really
wanted
to
use
that
as
a
it's.
B
Just
the
only
cql
discussion
and
give
you
some
really
good
tools,
some
of
more
advanced
features,
some
good
topics
around
that.
So
what
we're
going
to
do
this
time
is
now
that
we've
got
our
background.
Our
foundation
set
I'm
going
to
walk
you
through
some
real-world
examples.
I
work
pretty
exclusively
with
customers
and
I
get
to
see
what
people
want
to
do,
and
I've
learned
a
lot
about
some
of
the
more
common
use
cases
and
I
hey.
You
know,
I'm
an
engineer,
I
learn
from
examples
pretty
easily
I
think
that's
a
really
great
way
to.
B
B
So
the
data
modeling
Cassandra,
in
my
opinion,
is
the
path
to
a
good
time
with
Cassandra.
So
whenever
Cassandra
data
models
are
created,
they're
all
about
your
application,
I
do
not
care
as
much
about
the
data
as
I
do
about
your
application,
and
you
I
say
that
a
lot,
because
the
application
really
is
the
important
thing:
you're,
not
building
data
you're,
building,
an
application
that
will
store
data.
You
need
a
persistence
tier
that
will
work
the
way
you
want
it
to
work.
So
that's
why
I
always
take
Cassandra
data
modeling
from
the
applications
here.
B
What
are
we
doing
there?
So
it
doesn't
work
for
every
single
use
case
and
that's
okay,
because
it's
not
I,
don't
think
we're
in
the
world.
Now
that
we
should
say
there's
only
one
solution.
I've
said
this
in
my
previous
webinars
polyglot
persistence.
It
is
true.
You've
gotta
have
that.
Now
in
this
we
got
different
ways
to
store
data.
If
you're
going
to
do
search,
you're-
probably
not
going
to
use
something
like
members
or
memcache,
because
it's
a
key
value
store,
you
probably
do
something
like
solar,
which
does
search
really
well.
B
B
So
let's
talk
about
this
a
bit.
The
win
to
use
Cassandra
is
I
I
go
to
like
its
core
strength.
Is.
It
is
very
good
at
replicating
data
Cassandra
HBase
is
very
good
and
making
sure
your
data
is
available
across
inside
one
datacenter.
It's
hard
to
kill
Cassandra
where
we've
lived
in
a
world
of
single
points
of
failure,
and
everyone
preaches
a
good
word.
Don't
use
a
single
point
of
failure?
B
Well,
alright,
we
don't
want
to
use
that
use
Cassandra
and
when
you
need
to
scale
scaling
is
another
issue
that
is
difficult
in
a
single
point
like
if
one
database
or
one
database
server
usually
means
scaling
it
up
and
building
up
a
bigger
server.
One
bigger
server
I
prefer
to
work
with
things
that
are
horizontally
scalable
anymore
I
mean
it's
2013,
I'm
sure
now
that
just
data
just
talk,
but
we
shouldn't
have
to
worry
about
things
vertically
scaling
anymore.
B
So
whenever
you
use
Cassandra,
you
get
horizontal
scaling,
but
you
don't
really
know
what
the
scale
is
going
to
be
today
or
tomorrow.
The
next
day.
You
know
you
have
question
marks
about
how
far
it's
going
to
go.
It's
great
for
that
Cassandra
is
linear
scaling.
You
need
ten
percent
more
load
for
your
application.
Add
ten
percent
more
servers,
it's
just
that
easy
and
uptime
guarantees.
I've
worked
in
engineering
like
I,
said
a
long
time
and
I
always
got.
The
question
is
like
how
do
how
do
we
get
5-9
to
uptime?
B
Conscious
always
have
to
be
I.
Don't
know
anybody
that
says
hey
my
IT
budget
is
unlimited.
It
just
doesn't
happen,
you're
going
to
have
boundaries
on
how
much
you
can
spend
on
things
and
I've
been
involved
in
this
too
many
times
where
we
to
make
really
bad
decisions
because
of
money
like
yeah
we'd
really
like
to
have
closed
100%
uptime,
but
we
can't
afford
to
put
it
into
two
data
centers
or
something
like
that.
So
it
just
it's
bad.
B
Whenever
you
have
to
make
that
decision,
so
it
gives
you
more
abilities
and
then
doesn't
cost
as
much
so
you
know
I,
think
I'd
say
a
lot.
Is
the
Oracle
scales
right
up
until
you
run
out
of
money
and
that's
pretty
bad
when
that
happens,
so
these
I,
like
I,
put
a
little
app
to
come
there
there's
a
lot
of
Oregon
hands
on
this
there's
a
these
are
all
ores
of
not
hands,
so
it
doesn't
have
to
be.
B
All
of
these
have
to
be
true
and
there's
caveats
on
everything,
but
this
is
a
pretty
good
list,
so
you
have
to
get
the
datum
so
right.
That's
why
you're
here
data
models,
everything,
because
it's
going
to
express
the
way
you
want
to
use
Cassandra
directly
with
the
data
model.
That's
how
we're
expressing
mine
using
commander
this
way,
here's
how
I'm
going
to
use
it.
B
So
here's
my
my
core
examples
that
I'm
going
to
present
today
are
their
real
world
and
they
are
I
should
say
expressions
of
the
real
world
and
I
put
an
area.
You
think,
in
my
view,
if
I
gave
this
talk
and
I
actually
called
out
somebody
that
it
was
them
but
I'm,
neither
generalized
cases,
I
hear
these
all
the
time
and
they're.
That's
probably
why
I
use
them,
but
I
want
to
make
sure
you
have
something
that's
generally
useful,
but
also
very
specific
as
well.
B
What
I'm
going
to
present
is
it's
really
just
the
use
case
like
is
what
they're
trying
to
accomplish
and
here's
how
we
did
it.
Here's
the
model
and
everything
that
I'm
going
to
show
you
is
in
cql,
3,
c
ql.
3
is
really
the
path
forward
for
Cassandra
and
if
you
look
at
our
drivers
and
I
really
encourage
you
to
go
out
and
check
out
the
data
stacks
drivers,
we
have
C
sharp
Java
Python
more
coming
and
all
of
these
drivers
use
the
same
methodologies
and
cql
is
a
core
for
all
of
them.
B
Go
out
and
download
them.
They'll
make
your
life
a
lot
easier,
and
it's
just
a
joy
to
work
with
these
I
think.
If
you
come
from
of
maybe
two
years
back
say
or
year,
back
using
Cassandra
was
a
lot
more
difficult.
Whenever
you
did
programming,
it
makes
it
a
lot
easier
and
I
really
like
working
with
them.
B
So
let's
go
through
some
comments
here
about
CQL
and
I.
You
know:
I
got
this.
Gql
doesn't
do
dynamic
growth
hit
it
all
the
time
and
yeah
they
do
so
I'm
just
I'm.
Just
just
my
Mythbusters
slide,
just
make
sure
to
keep
reiterating
this
point,
but
cql
does
do
a
wide
row,
meaning
what
we've
always
talked
about
in
Cassandra,
where
you
have
a
row
with
a
lot
of
columns
and
that's
a
really
good
data
model.
You
don't
want
to
make
things
too
tight.
It
makes
it
real
makes
it
look
like
that.
B
You
don't
get
a
really
wide
row
anymore.
It
looks
like
it's
turning
it
more
into
like
a
relational
database.
That's
not
really
the
case.
It's
it's
really
an
abstraction
on.
What's
really
we're
doing
best
practices
under
the
hood
and
it's
an
abstraction
layer,
I
encourage
you
to
go
check
out
the
blog
post
on
here.
My
slides
are
up
online
on
SlideShare.
You
can
go
check
these
out,
so
you
have
an
actual
clickable
link
here.
A
B
More
to
it
so
read:
Jonathan's
blog,
post
and
then
read
my
I,
don't
know
what
you
would
call
it
an
addendum
in
the
comment
that
I
put
in
there
is
actually
an
answering
a
question
that
somebody
had
but
I.
This
is
a
big
deal
for
me,
because
I
really
want
people
to
understand
it.
I'm
not
just
telling
you
to
hit
the
ibelieve
button.
I
want
you
to
go.
Do
it
and
look
at
it
and
understand
it.
B
B
A
B
There's
a
good
example
of
hey
I
need
as
close
to
100%
uptime
as
possible
because
think
about
that,
that's
people
giving
you
money
and
you
do
not
want
to
lose
that
and
you
wanted
to
be
online
all
the
time
because
giving
people
giving
you
money
is
a
reason,
probably
why
you're
in
business.
So
what's
the
what's
the
use
case,
the
reliability
of
that
shopping,
cart,
critical!
You
have
to
know
that
that
data
is
getting
stored,
that
if
people
put
I
mean
I'm
I've
seen
this
happen,
you
put
something
in
a
shopping
cart.
B
Something
happened
to
redirect
you
to
the
homepage
and
then
everything
in
that
shopping
cart
is
gone.
It
never
happened,
never
happens
as
much
anymore,
but
it
when
it
does
happen.
You
don't
want
to
go
back
and
relook
for
stuff
and
have
to
redo
your
shopping
ideas.
How
many
times
are
you
just
going
to
walk
away
from
it?
You
do
not
want
to
present
your
customers
with
that
choice
of
just
walk
away
when
they
had
money
sitting
in
the
in
the
another,
shopping,
cart,
downtime
and
minimizing.
That
downtime
means
multiple
data
centers.
B
You
cannot
be
serious
about
your
uptime
until
you
start
talking
about
multiple
data
centers
and
it's
just
a
fact
of
life,
because
data
centers
go
down,
they
will
go
down,
may
not
today,
maybe
not
next
year,
but
they
will
eventually
and
if
they
don't,
your
other
data
center
will
probably
go
down.
So
just
doing
multi
data
center
is
how
you
can
get
the
most
the
most
and
the
best
high
availability.
B
So
cyber
monday
is
now
in
our
vernacular
and
that's
it
used
to
be
the
Black
Friday.
You
know
when
people
would
kill
each
other
to
go
into
a
store
after
Thanksgiving
us
Thanksgiving
is
a
November,
so
it's
always
Christmas
shopping
things.
Just
it's
really
kind
of
a
problem
that
has
more
of
a
generalized
case
now.
The
other
thing
you
would
call
it
as
a
thundering
heard
problem
where
all
of
a
sudden,
all
your
summers
show
up
at
the
same
time,
cyber
monday
is
in
the
u.s.
is
a
problem
with
the
Monday.
B
After
the
weekend
of
Black
Friday,
all
the
online
shoppers
show
up
at
the
same
time.
Well,
you
want
to
be
ready
for
that.
You
want
to
be
able
to
scale,
let's
say:
you're
your
load,
it's
X
and
if
you
want
to
do
X,
plus
50%
or
X,
plus
a
hundred
percent
be
ready
for
that.
So
the
last
thing
you
want
to
do
is
again
leave
all
that
money
on
the
floor.
B
So
what
you're
going
to
get
out
of
this
from
the
bad
side-
and
this
is
what
your
boss
is
going
to
tell
you-
is-
we
cannot
be
offline
for
a
minute
because
that's
money,
and
so
you
don't
you
don't
want
to
tell
your
boss
we're
offline
for
a
while.
There
goes
all
your
money
and
online
shoppers
are
all
about
speed
as
well.
If
a
site
starts
to
lag,
that's
bad,
we
do
not
want
your
site
to
lag
if
you
have
that
X
plus
100%,
so
thinking
about
scale,
and
that
way
it's
really
important.
B
So
how
do
we
do
this?
So
I
got
my
little
whiteboard
here
showing
how
we're
going
to
do
this,
so
each
customer
can
have
one
or
more
shopping
carts.
Now
let
be
or
more,
it's
kind
of
cool
I've
done
this
a
couple
websites
I
think
it's
more
common
now,
but
if
you
want
to
keep
a
couple
of
shopping
carts
going,
and
so
you
want
to
be
able
to
store
that
we're
going
to
denormalize
all
the
data,
so
it's
for
fast
active.
B
A
B
It
fast
it's
fast
access,
so
we
have
one
shopping,
cart,
one
partition
of
data,
that's
row
level,
isolation,
so
that
gives
you
the
ability
to
update
that
cart
from
multiple
sources
and
make
sure
you
never
get
a
dirty
read
out
of
it
either.
So
that's
our
row
level,
isolation,
that's
already
in
Cassandra,
so
that
that
will
save
you
from
some
embarrassing
moments
where
you
might
have
half
of
shopping
carts
show
up
in
somebody's
inbox.
B
That's
not
going
to
work
for
anybody,
and
so
now,
with
this
model,
you
can
see
that
you,
each
new
item,
will
be
a
new
column,
so
dynamic.
It
will
grow
out.
However,
many
columns
needs
to
based
on
how
many
items
that
you
have
you
want
to
put
in
there
and
that
that
makes
sense
that
fits
into
the
application
model
where
I
may
want
to
order
one
thing
or
ten
things
or
a
hundred
things.
It
shouldn't
being
limited
by
some
sort
of
hard
one.
That's
like
how
big
an
array
is
or
something
so.
B
B
So
it's
that,
if
you
recall,
is
a
collection,
that's
available
in
cql,
really
cool
method
of
gathering
random
bits
of
data
inside
your
static
model,
and
that
set
is
going
to
contain
and
I
put
this
example
over
here
on
the
right
where
I
have
this
set.
That
shows
all
the
stuff
that
I've
put
in
my
shopping,
cart
and
I
could
be
normalized
that,
if
I
wanted
to,
but
in
this
case
you
know,
I
just
put
in
a
bunch
of
information
about
my
shopping
cart.
A
B
In
there
is
another
thing
you
can
use:
if
you
want
to
do
that
now,
the
shopping
cart
itself
is
really
where
all
the
juices
so
I
have
a
list
of
all
the
shopping
carts.
Now
this
is
where
the
white
row
comes
in.
Now,
if
you
look
at
my
on
the
right
where
the
example
is
sorry
that
was
both
of
these
are
shopping
carts
in
my
bad.
If
you
look
at
the
when
you're
inserting
data
into
the
shopping
cart,
it's
really
dynamic
and
it's
showing
all
kinds
of
interesting
information
in
there.
B
B
If
you
order
a
an
e-book,
then
it's
going
to
have
so
many
cages
and
it's
going
to
be
such
so
many
kilobytes
of
size,
but
it's
not
going
to
have
any
dimensions,
but
if
you
order
something
physical
say
like
a
skateboard
going
to
be
so
long
and
it's
going
to
be
so
tall
and
going
to
weigh
so
much
to
ship.
So
these
are
all
individual
details
of
each
items
that
you
can
store
dynamically
inside
your
shopping,
cart!
B
Now
why
you
would
store
it
there,
you're
just
denormalizing
at
this
point,
and
it
just
makes
it
easier
you're
bringing
that
data
in
that's
relevant.
So
whenever
the
shopping
cart
gets
the
checkout
phase,
maybe
there's
some
information
in
there
that
helps
figure
out
like
say
shipping
costs
or
like
how
it
can
be
delivered
or
anything
like
that.
So
take
this
model,
and
you
can
see
now
you
know
how
it
can
be
done.
You
can
also
mix
and
match
on
how
you
want
to
make
yours
what's
cool
about.
B
B
A
A
B
Right,
sorry,
if
that
wasn't
very
viewable,
we
try
to
be
interactive
here
in
real
time.
Oh
yeah,
what
I
was
talking
about?
Real-Time
right,
so
use
your
activity
and
there
you
go
now:
I'm
reacting
to
user
input,
good
segue,
Thanks,
so
the
root
you
user
input
you
do
need
to
react
to
in
real
time.
You
can't
wait,
and
so
many
times
I've
heard
people
say
I'm
going
to
use
Hadoop
to
do
that.
Well,
all
right
you're
going
to
get
that
tomorrow.
B
So
that's
the
bad
right
waiting
for
batch
and
getting
input
and
then
dealing
with
it
is
really
critical
in
today's
world
support
for
multiple
application
pods
the
plot.
The
application
pod
is
more
of
a
design
architecture
concept,
but
really
it's
all
about
building
out
your
application,
so
that
everything
is
in
you
can
deploy
in
two
parts
and
I
will
show
you
my
slides
in
a
minute
here.
What
that
looks
like
and
then
speed
is
always
important
and
if
you're
acting
to
something
in
real
time,
you
need
to
be
able
to
do
it
in
milliseconds.
B
You
know
humans.
Humans
tend
to
notice
things
that
are
over
200
milliseconds
or
about
150
milliseconds.
So
when
you
start
reacting
much
slower,
it
starts
to
become
a
very
apparent
to
the
end
user.
So
let's
try
to
work
that
into
the
budget
for
time
and
react
in
that
time.
So
the
too
bad
I
mentioned
the
batch,
which
is
you
know
if
you
got
to
have
now.
Hadoop
is
not
the
choice.
It's
just
not
going
to
do
what
you
need
to
do
now.
B
You
have
to
have
another
plan
and
losing
those
interactions
when
you're
on
somebody
on
your
website
say
they're
in
the
shopping,
cart
or
they're
doing
something
on
your
website.
You
want
to
react
to
that,
can
potentially
give
you
more
lists
or
give
you
more
money,
then
you
need
to
interact
with
them
now,
and
so
how
do
you
plan
that
out?
Do
it?
So
my
activity
model
data
model
is
is
somewhat
different.
This
is
them.
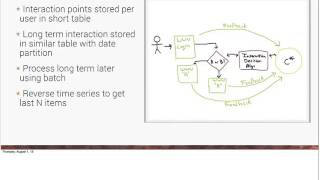
B
This
is
more
of
a
flow
diagram,
sort
of
thing
where
so
the
interactions
are
stored
per
user
in
a
very
short
table.
So
let's
say:
if
someone
logs
into
the
website,
we
have
a
decision
engine
that
can
make
things
happen,
and
so,
as
things
are
happening
we
can
do.
We
can
take
these
long-term
interactions
to
store
them
later,
but
then
we
can.
We
can
also
interact
with
them
now
and
make
decisions
so
like
when
they
log
in
and
then
we
maybe
have.
B
We
have
something
like
a
an
a/b
choice,
and
so
they
can
go
either
to
a
page
or
a
B
page.
Well,
the
feedback
is
going
to
be
whatever
you
log
in
to
the
page.
We
could
store
what
this
person
has
and
what
their
next
destination
will
be,
maybe
based
on
this
user
profile,
we
want
them
to
go
to
a
different
web
page.
Maybe
it's
something
that
they
did.
B
B
That's
the
kind
of
freaky
part
about
this,
which
a
is
cool
and
creepy
at
the
same
time,
which
is
we're
kind
of
getting
into
people's
heads
a
little
bit,
and
but
that
can
only
be
done
if
you're
doing
this
in
real
time.
I've
done
a
lot
of
data
mining
and
data
data
science
tests
on
previous
interactions,
they're
cool,
but
they
just
don't-
have
the
same
kind
of
impact
as
real
time
like
what
I'm
talking
about
here.
B
So
one
of
the
other
things
we're
going
to
do
is
store
these
in
long
term,
so
we
can
create
feedback.
There's
there's
still
cases
for
Hadoop,
there's
still
cases
for
a
long
term
batch
analysis
and
that's
that's
to
validate
our
models
and
then
things
like
that.
We'll
still
store
that
data
and
we're
going
to
use
a
reverse
time
series.
Reverse
time.
Series
is
one
of
my
favorite
little
time
series
tricks
and
we're
going
to
look
at
that.
B
So
I
have
my
user
activity
table
and
this
is
the
one
that
stores
that
interaction
as
we
go
through
getting
the
data.
Now
it's
just
as
someone's
clicking
on
webpages.
So
basically,
we
put
a
widget
or
something
like
that
in
the
web
page
whenever
they
click
in
click
to
the
next
page,
blah
blah
blah
that
we're
tracking
that
interaction
that
was
going
into
the
user
activity
table.
B
B
A
B
What
I
want
to
point
out
here
is
when
someone
logs
into
the
website,
for
instance,
we're
storing
that
dated
to
two
different
tables
and
that's
totally
cool.
You
can
do
it
in
five
different,
get
six
different
tables,
10
different
tables
and
I've
done
this
a
lot
they
where
you
just
get
so
many
good.
You
have
such
good
right
speed,
so
you
can
do
multiple,
writes
per
second
thousands
and
thousands
millions
potentially
on
Cassandra.
That
should
not
be
limiting
factor
in
your
data
model.
B
You
should,
when
I
was
an
Oracle,
DBA,
dev
I,
worried
about
how
much
I
was
inserting
into
the
database
at
one
time.
So
that
is
just
not
a
consideration
with
Cassandra
so
think
about.
What
are
you
going
to
do
to
lay
out
your
data,
so
you
can
read
it
up
more
effectively,
so
how
I'm
going
to
use
this
data
now?
Here's
an
example
of
why
that
reverse
works
so
well.
Is
that
if
you
look
at
the
select
from
user
activity
limit
5,
what
I'm
saying
is
I
only
want
the
last
5
things
that
happen.
B
I
don't
want
the
last
10
I
want
the
last
5
and
it
doesn't
have
to
go
over
this
massive
amount
of
data
to
get
that
data
out.
It's
just
going
to
go
over
the
first
5
items
in
that
row
very
efficient
and
if
you're
running
a
trace
of
some
sort,
you're
trying
to
figure
out
where
your
performance
is,
if
you
didn't
do
the
reverse,
and
you
asked
for
the
lab
size,
things
you'd
be
iterating
over
a
ton
of
data
before
you
got
to
what
you
want.
Reverse
prevents
that
so
this
is
fast.
B
This
is
an
interaction
pattern
that
makes
it
feel
really
fast.
So
what
I've
got
here
is
this
this
person
they
went
into
the
jewelry.
They
created
this
anniversary,
the
shopping
cart
and
then
they
deleted
the
gadgets
I
want.
So
in
my
my
algorithm
that
I
picked
them
like
whoo.
Maybe
we
should
put
a
sale
item
up
for
flower,
see
because
this
dude
must
be
in
trouble
and
so
then
open
up
the
gadgets
I
want
and
so
wait
a
minute
hold
on.
So
we
deleted.
We
created
this
anniversary
gift.
Now
we're
doing
jewelry
awesome.
B
How
about
some
flowers
with
that?
It's
got
my
dumb
example,
but
in
my
in
my
opinion
you
know
this
is
the
kind
of
stuff
you
could
do.
You
just
got
to
come
up
with
what
you
want
to
do,
and
that's
probably
that's
when
it
gets
fun.
Probably
a
little
more
interesting
is:
what
do
you
want
to
do
with
that
data,
simple
or
complex?
You
have
the
data.
No
that's
the
important
thing.
B
My
third
one
is
the
log
collection,
and
that's
probably
one
I,
hear
probably
the
most
easy,
because
people
want
to
store
blogs
in
an
efficient
way.
It's
a
big
problem
and
there's
just
a
lot
of
it.
Machines
generate
a
lot
of
data.
We've
got,
man
is
weird
I
mean
there's
so
many
cool
and
scary
statistics
out
there.
Like
you
know,
humans
have
generated
more
data
in
the
past
five
years
and
they
have
an
olive
history
or
something
we
just
love
generating
data.
So.
A
B
To
store
it
logs,
if
you
write
a
few,
our
application
developer,
I'm
sure
you
put
enough
log
statements
in
your
in
your
code
to
make
it
so
that
you
need
something
like
this.
So
always
it's
always
going
to
be.
We
need
to
collect
data
at
a
high
speed,
so
it's
coming
at
a
high
speed.
If
you
have
30
application
servers
in
your
app
tier,
then
they're
generating
10
15,
20
application,
log
events
during
a
single
interaction,
you
can
be
generated,
x'
and
hundreds
of
applications.
Events,
application,
logging
events
in
a
very
short
order.
B
So
commander
will
do
this
in
near
where
the
logs
are
generated
and
I.
Think
that's!
When
you
talk
about
how
we
deploy
applications,
we're
probably
going
to
do
a
multi
data
center
hat.
If
you
are
a
multi
data
center
and
you're
collecting
your
logs
to
one
data
center
you're
sending
a
lot
of
data
over
the
wire,
but
it
may
not
be
as
relevant.
B
So
we
want
to
make
sure
that
the
application
that
generating
the
data
is
just
goes
to
a
local,
stop
and
then,
like
Cassandra,
do
the
replication
for
us,
the
the
need
for
dicing
the
data
as
well
so
classic
use
for
logs
is
something
like
a
dashboard
or
lookup.
So
we
need
to
come
up
with
it.
That's
our
use
cases.
We
need
to
be
able
to
dice
up
all
that
data
or
put
it
into
a
usable
form.
B
The
bad
side
is,
is
that
the
scale
you
know
we
don't
don't
try
to
do
this
with
your
really
expensive,
relational
database,
and
it's
just
a
lot
of
data
that
it's
going
to
have
to
collect
you're
going
to
have
to
scale
that
thing
to
the
point
where
it's
not
very
cost
effective,
and
so
it's
a
better
there's
a
better
way
to
do
this.
The
batch
analysis
of
logarithms
way
too
late
as
well
too,
and
let's
go
back
to
my
previous
use
case
where
the
data
you're
getting
now
is
relevant.
B
Now,
maybe
it's
relevant
the
next
five
minutes,
maybe
the
next
10
minutes
I
can
think
of
many
times
where
I've
actually
built
the
system
years
ago.
I
built
this
system
in
Cassandra,
and
it
was
really
so
that
we
could
get
up
to
the
millisecond
information
about,
say
how
many
five
hundred
areas
we
were
getting
on
our
website
or
how
many
404s
we
got
after
a
code
push.
These
are
relevant
information
points
that
we
needed
now.
B
Batch
picked
it
up
and
gave
us
a
report
the
next
day,
because
it's
usually
affecting
customers
right
now,
if
we're
getting
all
sudden,
we
spiked
up
and
we
get
a
delta
on
our
500s
of
you
know,
plus
100
percent.
In
the
last
five
minutes
we
better
start
looking
at
what's
going
on
and
that's
some
relevant
information
that
we're
getting
from
our
logs.
B
This
is
what
we're
going
to
do
we're
going
to
use
flume
in
this
case
those
of
you
not
familiar
with
flume,
it's
pretty
cool
tool
from
it's
another
Apache,
another
patchy
project.
It's
actually
a
sub
project
to
do,
but
it
could
stand
alone
pretty
well.
It
doesn't
really
need
to
do.
It
was
a
gent
again
as
a
way
to
get
logged
in
to
do,
but
it's
found
a
lot
of
general
purpose.
Waves
I've
worked
with
some
teams
that
use
flume
in
all
kinds
of
interesting
ways,
especially
dumping
data
directly
into
Cassandra.
B
B
Now
what
that
means
is
that
we're
going
to
have
the
table
for
I
put
some
some
on
here,
like
just
one
for
the
raw
log,
so
just
store
the
raw,
but
I
don't
really
care
what
format
dates
in
I
just
want
to
have
those
for
the
like,
if
I
ever
want
to
do
batch
analysis
on
those
and
then
I
have
my
latest
successes
and
my
latest
fail.
So
this
is
a
dicing
action,
I'm
talking
about
it.
B
When,
when
data
comes
into
flume,
you
can
look
at
the
event
pick
it
apart
and
start
setting
up
counters
or
maybe
putting
that
information
into
a
separate
table.
I
wrote
an
application
that
for
every
web
event,
we
got,
we
wrote
it
out
to
90
different
column,
families
and
those
table.
Those
90
different
tables
we're
collecting
data
for
different
reads
perfectly:
okay,
Cassandra
will
scale
to
that.
For
you
and
so
there's
different
things
we
may
want
to
do
with
it
like
a
lookup
or
a
dashboard.
B
Dashboard
applications
are
really
cool
for
that
kind
of
stuff
and
you
need
access
to
that
data
in
just
a
short
window
of
time.
Great
time
series
model,
so
here's
our
log
lookup,
so
I
want
to
look
up
the
raw
data
in
my
logs
and,
let's
say
I
just
know:
I
have
a
time
frame
or
something
like
that.
So
here's
here's
the
case,
let's
say
we're
using
an
access
control
device
and
we
want
to
look
up
based
on
the
source
and
the
date
when
we
actually,
you
know
when
we
actually
collect
that
data.
B
So
I
want
to
look
at
an
event
that
happened
at
a
certain
time.
Well,
the
data
event
or
the
tables
logger
lookup
table
I'm,
going
to
have
the
source
and
then
date
up
to
the
minute,
as
my
partition
key.
That
will
make
sure
that
I
have
a
nice
partition
of
data.
It's
not
collecting
tons
and
tons
of
data
all
in
one
row,
but
I
can
get
to
it,
because
I
have
one
of
the
keys
that
I
found
to
creating
the
queries
and
putting
data
into
the
table.
B
It's
using
data
that
you
have
you're
going
to
have
a
time
stamp
on
that
data.
Use
that
data
to
create
your
key
you've
got
data
to
create
the
actual
columns.
You
don't
have
to
derive
anything.
You
just
use
the
data
you
have
and
then
it's
natural
on
the
other
side,
if
I'm
looking
up
data,
I'm,
saying
hey
everything
from
this
one,
Access
Controller
I
want
to
know
everything
that
happened
at
this
certain
time
to
that
certain
time.
So
from
the
range
of
dates
awesome,
you
can
do
that
now.
B
It's
interesting
is
we
have
this
blob
of
data,
this
raw
log
I
did
here's
my
ninja
trick.
Everybody
should
pay
attention
this,
because
I've
seen
this
in
great
effect,
you're,
storing
any
kind
of
raw
log
or
even
something
that
doesn't
need
to
have
you
don't
need
to
get
insight
into
you
just
need
to
store
something
in
bulk,
like
even
JSON
or
XML
gzip
it
at
your
application,
compress
it
at
your
application
before
you
send
it
over
the
wire
great
idea,
because
you're
you're
minimizing
the
amount
of
data
that
you're
putting
on
on
the
wire.
B
That's
a
good
thing,
but
it's
also
more
efficient
on
the
Cassandra
side.
You're
just
going
to
store
data,
I
mean
you're,
storing
gated
to
retrieve
later
there's
almost
no
cost
to
zip
it
I
mean
you
were
talking
microseconds
and
time
to
gzip.
You
know
a
reasonable
science
object,
so
just
use
that
so
we
on
this,
we
were
also
storing
that
exact
same
and
web
event
into
two
other
column:
families
throw
their
tables.
So
if
you
look
to
the
right,
I
have
my
login
success.
Now,
what
I'm
doing
with
that?
It's
so
like.
B
Let's
say
this,
Access
Controller
I
keep
the
the
source
which
asterisk
controller
is
you
the
date
up
to
the
minute
is
as
the
one
of
the
partition
key
but
I'm,
using
that
to
create
a
wide
row,
and
then
my
successful
logins
and
I
uses
the
counter
so
the
counter
column.
What
I'm
doing,
if
you
notice
again,
like
I,
said
it's
one
of
my
favorite
tricks
with
time
series
in
time
for
dinner
models.
It's
clustering
order
by
reversing
the
the
clustering,
so
that
you
could
that
last
objects
is
the
first
one
on
there
here
we
go.
B
B
You
know
everything
within
a
time
frame,
but
usually
it's
going
to
be
the
last
ten
things
think
about
a
dashboard
where
here's
my
here's,
my
I,
select
I'm
going
to
select
up
to
this
minute,
successful,
logins
and
I'm,
going
to
limit
20,
so
I'm
grabbing
the
lap
twenty
second
for
the
stuff,
cuz
I,
know
I'm,
sorry,
twenty
minutes
with
the
stuff
because
I'm
collecting
it
by
the
minute.
So
here's
my
counter.
B
This
is
really
fast
because
I'm
going
to
be
able
to
get
I,
have
the
exact
row
key
and
it's
a
very
small
slice
of
data.
It's
only
twenty
items,
but
it's
pre-optimized.
It's
ready
to
go
for
this
dashboard,
very
cool
way
to
do
this.
So
in
this
case
you
know
I'm,
looking
at
here's,
my
successful
logins
are
going
up.
B
Also,
they
start
going
down
in
my
log
into
my
failed
logins
are
going
up,
maybe
I
have
an
access
and
my
L
duck
and
sort
of
on
the
back
end
isn't
working
or
my
maybe
one
of
my
access
controllers
isn't
working
very
well.
This
is
relevant
information
right
now.
If
I
had
to
find
that
out
with
a
report
tomorrow,
I'd
still
have
a
whole
bunch
of
users,
not
very
happy
with
me,
so
the
the
kind
of
stuff
you
want
to
know
about
and
react
to
it
immediately.
B
This
is
real
time
the
need
for
real-time
data,
pops,
one
is
user
form
versioning,
and
that
was
one
that
I
called
out,
but
I
think
this
is
more.
This
is
a
little
different,
definitely
not
at
mainstream,
but
give
you
a
bunch
of
interesting
ways
to
model
your
data,
so
here's
the
this
is
that
this
is
a
good
actual
real
I
had
a
couple
places
do
this,
but
a
real
need
for
this
user
form
versioning
and
be
able
to
roll
back
so
I
want
to
I,
have
a
form.
B
The
user
form
on
my
website
and
I
want
to
store
every
one
of
those
versions
efficiently,
and
the
I
mentioned
this
before
I
think
it's
funny.
Is
it
I?
Do
not
expect
people
like
admins
in
the
front
office
to
learn
how
to
use
get
I
mean?
Can
you
imagine
that
it
just
wouldn't
work
I
think
that
there's
that
kind
of
functionality
that
you
may
need
to
present
to
them?
But
you
need
to
find
a
way
to
do
it
a
little
better
and
there's,
probably
that's
where
we
probably
can
get
a
little
more
creative
with.
B
Model
so,
and
the
scale
is
really
important
if
we
have
a
lot
of
users
on
our
websites-
let's
say
you're,
creating
web
forms
for
users
and
they
like
use
them
on
their
website.
It's
got
to
be
able
to
scale,
and
that's
where
things
that,
like
version
control
issues
of
locking
and
just
turning
a
real
problem
of
scale
and
the
other
really
critical
thing
is
you
need
to
be
able
to
do.
They
commit
a
change,
but
then,
more
importantly,
roll
it
back.
B
You
need
to
say,
oh,
that
was
bad
change,
I'm,
going
to
take
it
back
to
a
previous
version,
so
you
need
to
have
the
way
to
scroll
up
and
down
the
versions.
So
in
a
relational
database
it
is
a
very
complicated
relationship
model,
and
this
is
probably
one
of
those
times
where
relational
model
breaks
down.
It's
just
so
complicated
to
do
a
joint.
In
these
cases
it
becomes
prohibitive
in
a
way
it's
very
complex
and
very
slow
and
I
will
look
at
our
data
model.
B
So
what
we
can
do
is
create
that
data.
That
data
will
be
used
by
our
application
to
create
the
forms
on
the
webpage.
But
if
we
ever
need
to
change
it,
we
can
just
roll
back
to
a
certain
version
number
inside
their
form
table
and
the
other
thing
is:
we
need
to
have
this,
this
business
of
an
exclusive
lock.
So
look
well,
how
do
we
do
that?
Do
did
I
say
lock.
I
did
so.
A
working
version
is
our
table
that
we're
going
to
use
for
our
forms-
and
most
of
this
is
pretty
basic.
B
You
have
a
username
and
a
form
ID
which
creates
the
partition
key
and
then
a
version
number
version
number
we'll
make
it
so
that
every
bit
of
every
one
of
these
attributes
is
then
locked
into
a
particular
partition.
A
cql
partition.
So
it'll
look
like
a
roll
of
data
when
you
look
at
it
and
see
ql,
but
the
created
the
locked
by
is
how
we're
going
to
make
sure
that
we
only
have
one
user
during
this
at
a
time
and
then
the
form
attributes
map
is
where
all
the
real
business
is.
B
That's
a
very
cool
use
of
the
map.
So
you
have
a
key
value
pair
inside
of
your
working
working
version,
that's
locked
by
a
version
number.
So
if
you
look
at
my
inserting
of
my
first
version,
so
the
working
version
that
I'm
creating
is
this
version.
1
of
the
application
and
you'll
see
that
it's
my
my
username
and
my
my
form
ID
and
then
I.
Have
it
just
a
map
of
all
the
different
things.
B
B
A
B
I
made
a
manager,
so
it
will
do
natural
ordering
if
I,
don't
reverse
it.
If
I
reverse
it
then
it'll
be
the
highest
number
will
be
the
first
thing
on
the
row,
which
is
kind
of
what
we
want.
We
want
the
older
versions
to
start
trailing
off
and
then
have
the
current
latest
version
right
there.
So
how
do
I
do
this
so
when
I
insert
my
first
version
and
I'm
so
that
that's
in
the
system
now,
whatever
I
start
editing
it.
B
So
this
is
an
application
concept,
and
so
what
happens
whenever
someone
logs
into
my
site-
or
they
log
in
they,
say
ok
I'm,
going
to
work
on
that
form
when
they
click
on
that
we
just
do
a
single
write.
We
say
locked
by
this
person
and
I'm
going
to
do
an
update
where
username
equals
people
add
the
form
ID
equals
1138
and
I
have
a
particular
version
that
I'm
walking
that's
cool
most
that's
what
I
would
call
an
optimistic
lock.
B
It
doesn't
have
to
be
deterministic
but
from
a
website
that
works
pretty
well,
because
you're
only
going
to
have
two
or
three
people,
probably
working
on
the
form.
If
ever
and
you
just
need
to
know,
if
someone's
doing
it
so
whenever
you
go
to
edit
a
form
you
can
see,
if
there
is
anybody
that
they've
got
locked
by
is
even
filled
now,
so
what
happens
whenever
you
insert
a
new
version,
so
you
want
to
put
in
version
two
well
now
what
we
can
do
to
quote-unquote
release.
B
The
lock
is
just
nullify
that
number
so
or
that
that
name
that
lock
by
so
whenever
you
in
one
pass
you're
pretty
much
releasing
a
lock.
You
insert
your
new
data
and
take
up
a
lock
it
just
doesn't
just
anymore
and
so
that,
yes,
this
is
kind
of
a
poor
man's
lock,
but
it's
really
a
cop
accomplishing.
What
we're
hoping
is
that
we
just
want
one
person
working
on
this
form
at
once.
This
isn't
like
a
transactional
lock
in
a
database.
B
This
is
more
of
just
a
user
lock
like
keeping
one
person
out
from
getting
another
later
a
later
webinar.
When
we
start
talking
about
2.0
features,
I
will
further
enhance
this
using
our
Cavs
functionality
and
compare
and
set-
and
that
is
probably
a
good
use
for
this
whenever
you
want
to
get
better
transaction
quality,
if
you're
really
being
paranoid
about
it
like
having
multiple,
multiple,
multiple
users
going
against
at
the
same
time
that
functionality
was
designed
around
this
problem,
so
stay
tuned
for
that,
so
there
you
go.
B
We
saw
our
four
data
models
and
there's
Master
Yoda
he's
the
data
model
of
people.
Don't
know
that
he's
not
only
pretty
good
with
the
lightsaber
and
dudes
running
through
a
swamp,
but
he's
also
really
container
modeling,
and
so
this
is
important
stuff
to
think
about
whenever
you're
creating
your
data
models
like
okay,
these
are
all
good
use
cases.
This
is
how
I
walk
through
the
process.
This
is
not
meant
to
turn
you
into
an
absolute
ninja
but
you're
on
your
way.
B
I
hope
and
I
know
that
people
have
watched
some
of
mine,
my
what
I've
seen
people
now.
You
know,
especially
with
groups
that
I
work
with
when
they
watch
data
modeling,
stuff
they're,
starting
to
really
get
some
great
use.
Cases
out
there
so
I
hope,
someday
I'll
do
do
more
of
these
and
they'll,
be
your
use.
Cases
and
I.
Think
yes,
that's
about
it.
So
you
can
always
you
know,
get
with
me.
I
have
a
lot
of
people
that
get
with
me
on
Twitter
about
various
things.
B
B
If
you
have
questions,
ask
me
there
might
have
to
get
any
email
get
in
to
IRC
you
user
group
I
mean
they
there's
a
very
strong
community
out
there
willing
ready
to
help
you
so
please,
let's
do
that
and
I
would
hope
that
everybody
you
know
takes
this
and
does
what
they
can
to
make
their
own
data
model
really
cool,
so
I
think
that's
it
Christian.
We
need
to
do
some
questions
a
we.
A
Sure
do
we
have
11
minutes,
let's
see
how
many
we
can
get
through
pretty
quickly,
here's
one
from
Tom
or
Paige
Lewis.
She
took
it
away
from
me.
I
was
on
the
cusp:
Tom
can
order
by
be
used
for
any
column
in
the
primary
key?
For
example,
primary
key
columns
ABC
can
I
set
the
order
by
on
just
column,
C.
B
A
Okay,
great
I
can
I
love
questions.
I
can
answer.
Here
is
one
for
me,
so
many
people
asking
about
getting
access
to
the
slides
and
the
recording
we
always
send
out
to
everyone
who
is
registered
for
the
webinar,
the
slides
and
the
recording
in
about
24
hours
so
stand
by
for
that
also
people
asking
where
they
can
view
Patrick's.
A
B
B
Whoever
asked
that
I
swear
I
did
not
make
them
do
that.
Yes,
we
have
an
awesome
driver.
The
data
stacks
Java
driver,
it
is
in
GA,
it's
I'm,
you
know,
I
I
know
it's
new
and
not
a
lot
of
people
know
about
it.
You
use
that
driver
and
our
driver
has
a
lot
of
things
in
it.
That
you
will
need
I
saw
questions.
They
said
no
to
wear.
Of
course
it's
no
to
wear
it.
B
Does
things
like
cql,
it's
actually
built
around
the
idea
of
using
cql,
but
our
drivers-
and
this
is
not
just
the
Java
drivers.
It's
a
c-sharp
driver
and
the
Python
driver
as
well.
They
also
embody
the
methodology,
will
failover
and
clustering
and
doing
things
like
setting
up
chorim's.
All
these
things
are
built
into
it
and
they're
very
you
know,
they're
very.
B
A
B
No
compassion
doesn't
scan
all
the
SS
tables
it.
Compaction
takes
the
S
of
tables
that
need
to
be
compacted
and
then
freed
them
mergesort
some
and
then
writes
them
out
to
a
new
SS
table.
It
is
the
only
thing
that
ever
if
the
only
way
you
would
ever
do
all
those
tables
or
the
compaction
is,
if
you
did
a
major
compaction,
meaning
that
you
it
was
a
user-initiated
compaction.
I
do
not
recommend
doing
that.
That
is
not
a
good
thing
to
do.
The
other
there's
two
other
things
that
will
touch.
B
No,
no,
it
the
TTL,
the
TTL
s
will
expire
from
the
application
level.
You
won't
see
that
data
whenever
you
ask
for
it
and
they
will
naturally
expire
over
time
whenever
the
compaction
is
run,
but
not
deterministic.
Now
with
1.2,
there
are
settings
there
that
will
know
that
that
will
trigger
what's
called
the
TTL
compaction,
but
only
in
those
specific
use
cases,
it's
not
something
that
whenever
we
run
compaction,
it
just
looks
at
every
single
access
table
that
that
is
not
what's
going
on.
A
B
All
right
so
there's
a
couple
of
things
actually
that
the
calves
functionality
would
be
where,
if
you
were
worried
about
simultaneous
access,
the
new
version
2.0
feature
will
prevent
that.
That's
using
more
of
it,
it's
a
deterministic
type
lock.
What
I
presented
was
more
than
optimistic.
Lock
there.
There
are
probably
some
methods
you
can
do
to
detect
that,
and
this
is
meant
to
be
more
of
a
simplistic
data
model
not
into
more
complicated.
We
can
go
into
your
specific
use
case
if
you're
worried
about
that.
B
A
A
B
Clustering
order
by
again
is
how
you
specify
the
sort
order
of
the
data
as
it's
being
created,
so
an
SF
table
sort
of
string
table
it
stores
data
on
the
disk
in
a
sorted
fashion
when
you
use
clustering
order
by
you're
specifying
that
order.
So
in
this
case,
what
I'm
doing
is
I
have
the
date
to
the
minute,
the
varchar'.
So
it's
a
date
when
I
say
clustering
order
by
him
using
that
date,
two
minute
and
using
the
you
know,
basically
reversing
that
so,
instead
of
instead
of
ascending
order,
a
SCA
use
descending
order.
A
B
That
happened
would
be
the
first
thing
on
that
row
so
that
it's
just
some
complicated,
it's
more
complicated
syntax
to
mean
I
want
to
reverse
the
order
of
data,
that's
being
stored
on
the
disk,
much
more
efficient,
but
the
key
is
that
it
allows
for
things
because
select
queries
just
like
that,
where
you
say
select
date
to
a
minute
limit.
20
I
want
the
last
20
things
that
happened.
A
Thank
you
so
little
clarification
here
on
replication
Maury
is
asking
in
any
data
center
containing
three
nodes,
but
with
replication
factor
to
does
the
replication
happen.
Clockwise
if
the
topology
is
in
a
ring
say
datacenter
one
is
two
and
datacenter
two
is
two,
but
each
data
center
itself
has
three
nodes,
so
I
think
a
little
clarification
on
how
actually
replication
works
would
be
good,
Patrick.
A
B
Inside
the
data
center,
yes,
it's
the
adjacent
nodes,
like
you
said
it's
clockwise,
but
across
the
data
center
the
coordinator
will
communicate
with
the
node
in
that
just
one
node
in
that
data
center.
It
does
not
replicate
data
to
each
individual
node.
So
when
that,
when
that
coordinator
then
sends
data
to
the
other
data
center,
it
talks
to
a
coordinator
on
the
other
side
and
then
that
coordinators
job
is
to
replicate
it
in,
but
it
replicates
in
parallel.
It's
not
one
at
a
time.
It's
not
a
serial
serial
replication.
It
does
everything.
B
In
parallel,
it's
determining
the
replicas
pairs
is
in
a
clockwise
fashion.
Maybe
that's
the
kind
of
that's
a
combo
you're
trying
to
mix
together
here
when
data
is
actually
replicated
when
you
create
it.
It's
done
in
parallel,
but
when
you,
when
you
specify
the
replication
pairs
or
the
replication
server,
they're
done
in
a
clockwise
fashion,.
A
B
There
they
are
completely
separate
they're
their
cousins
who
talk
to
each
other
at
the
family
reunion
every
once
in
a
while,
but
they
don't
they
don't
need
either
of
each.
They
exist
so
independently
that
there's
not
even
any
crossover.
For
instance,
Hadoop
is
pretty
complicated
from
an
ecosystem.
It
requires
nindo
job
trackers
zookeeper,
you
know,
there's
a
lot
going
on
there.
Cassandra
is
completely
self-contained,
there's
nothing.
It
needs
to
run
by
itself
and
you
startup
Cassandra.
That's
all
you
need
to
start
so.
B
There's
some
integration
patterns
with
data
sex
Enterprise
that
we've
created
to
make
the
to
work
well
together,
and
it's
just
really
more
blue
than
anything
and
our
our
big
native
sex
Enterprise
version
of
Hadoop.
Well,
then
Hadoop
will
then
use
Cassandra
as
the
data
store
instead
of
HDFS,
which
that
yes,
then
at
that
point
they
are
pretty
inextricably
locked,
but
it's
just
because
we're
layering.
Can
you
tell
topic
to
sander.
A
B
B
Ingestion
boy
you're
asking
the
wrong
guy
because
I
like
to
write
my
own
code
for
ingestion,
but
if
you
have
to,
if
you
want
to
use
something
off,
the
shelf,
I
mean
if
you're
gathering
log
data
flume
is
awesome
for
that.
There's
plenty
of
code
out
there
example
code.
If
you
want
to
use
something
like
a
ETL
tool
to
Tahoe
Talon,
they
all
they
all
will
take
data.
What
data
sex
Enterprise!
We
also
use
scoop
grabbing
data
out
again,
you
can
use
something
like
Talon.
You
can
write
your
own
code.