►
From YouTube: GMT 2018-07-18 Performance WG
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
C
B
D
B
D
B
B
D
B
B
So
he
said
it's
fixed
for
him,
but
I
just
realized
that
you
know
probably
before
each
meeting
I
need
to
just
do
a
quick
audit
of
what
tickets
have
been
filed
with
the
performance
label,
because
this
did
actually
have
the
performance
label
on
it.
So
just
I'm
thinking
about
how
to
avoid
this
happening
again.
I'm,
probably
gonna,
either
in
the
meeting
or
before
the
meeting
just
go
over
those
tickets
and
make
sure
that
we're
aware
of
them,
it
probably
would
have
showed
up
in
the
dashboard
actually
that
I
have
here
somewhere
here.
B
B
B
B
B
B
B
You
you
no
okay.
What
was
the
current
status
of
it?
The
current
status
I
mean
I,
should
probably
mention
that
her
status
was
I,
did
like
a
low
like
I
did
a
short-term
fix
which
just
moves.
The
verification
in
the
read
helper
to
be
only
after
a
read
actually
fails,
so
it
directly
goes
and
does
the
read
avoiding
the
verification,
and
if
the
read
fails
it
it
does
verification
to
provide
the
better
error
message
that
verification
was
providing,
so
it
doesn't
break
any
tests
or
anything
but
longer
term.
B
B
B
B
B
E
E
Can
you
guess
they
must
see
my
screen,
yep,
okay,
so
living
what
we've
been
looking
into
the
death
of
Jason
and
briefly,
there
are
two
problems
for
the
standard
reason.
First,
what
people
usually
think
and
when
we
say
standard
Jason,
if
they
say
this
dead,
the
reason
is
slow,
which
means
it
takes
time
to
get
response
from
standard
Jason,
which
means
the
middle
UI
is
slow
and
some
other
tools
like
gcos,
UI
and
version
11,
is
also
slow.
E
However,
there
is
another
problem
which
probably
has
a
higher
higher
priority
is
the
isolation
problem
that
said,
the
Jason
impacts
the
overall
performance
of
the
master
actor,
which
means
in
that
very
unfortunate
scenarios.
Mallos
actor
can
spend
90%
of
its
time
just
crunching
data
for
Stanford
Jason.
So
there
are
several
several
aspects
of
this
problem,
especially
if
we
talk
about
how
to
improve,
especially
if
we
look
at
the
core
of
the
problem
like
delivering
state
information
to
consumers,
the
answer
to
slow's
that
the
Jason
might
be
to
use
v1
subscribe.
Endpoint
that
will
get.
E
This
will
give
you
the
first
fix
of
the
cluster
state,
and
then
it
will
give
you
an
update.
However,
we
still
want
to
tackle
the
isolation
problem
first,
and
this
is
right
now,
our
first
goal,
so
we
did
some
tests
in
order
to
gather
some
data.
The
first
was
on.
We
did
some
tests
internally.
The
first
was
a
smaller
class
2
with
22
agents
and
around
390
frameworks
and.
E
The
reason
for
this
is
that
the
time
each
subsequent
strategies
and
requests
needs
to
be
answered
includes
the
waiting
time
of
the
queue
which
includes
the
time
that
all
the
previous
that
the
Jason
risk
requested
have
been
sitting
in
the
queue
one
request
has
arrived,
took
two
took
to
be
processed,
and
these
are
these.
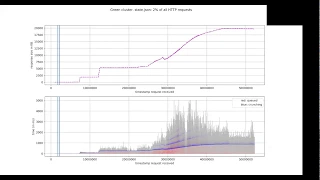
If
you
look
at
the
bottom
picture,
the
the
blue
lines,
these
echoes
this
is
exactly
the
the
amount
of
weight
of
time
that
a
specific
request
was
like.
E
So
the
gray
is
the
total
time
for
establishes
and
request
to
be
answered.
So
measured,
let's
say
from
a
client
perspective.
The
red
dot
is
the
time
that
a
specific
request
step,
the
Jason
request,
spends
in
the
master
queue
until
it
is
scheduled
for
processing
and
the
crunchin.
Here
is
the
time
that
requests.
E
That
times,
it
takes
four
requests
from
being
processed.
First
to
the
time
it
was
handed
over
to
the
process
to
be
sent
to
the
client.
The
crunching
is
a
little
bit
confusing
the
the
blue,
the
blue
points,
because
they
include
the
time
it
include
an
extra
trip
through
the
master,
Q
duty
authorization
that
we
do
an
extra
dispatch
and
it
obviously-
and
it
obviously
hands
includes
the
time
that
previous
standard
recent
requests
are
processed
and
take
to
process.
E
E
B
E
Queuing
this
is
correct
and
that's
why
we
see
echo
because
because
the
blue
includes
that
one
extra
dispatch
after
authorization
and
that's
where
we
see
that
the
blue
times
differ
and
their
multiple
of
of
a
specific
number,
let's
say
eighty
eight
hundred
milliseconds-
that's
because
of
this
extra
extra
trip
through
the
master
mailbox.
So
this
is
a.
E
E
The
first
is
when
the
request
is
put
for
the
first
time,
then
it's
being
processed
by
the
master
and
the
master
schedules
it
on
the
authorizer
and
once
authorizer
creates
all
the
objects
approvers
and
another
authorized
authorizing
stuff.
The
request
is
being
dispatched
for
the
second
time
and
due
to
this
fact,
due
to
these
two
two
trips
through
the
master
mailbox
in
this
process
in
time
in
which
we
include
this
second
despot
dispatch,
we
see.
E
E
B
B
So
when
I
time,
how
long
it
takes
for
my
state
to
JSON
to
get
processed,
I-I-I
have
to
do
another
trip
through
the
queue
I
already
did
a
trip
through
the
queue
to
get
on
to
start
my
timer
and
have
to
do
another
one
once
the
authorization
is
processed
in
them
in
that
second
one,
another
state
adjacent
could
be
finishing
its
continuation,
which
would
impose
like
all
that
extra
crunching
time
on
our
current
request.
Does
that
make
sense?
I
thought
I
would
do
that
more
elegant
adequately,
but
I
did
so.
C
E
Yeah,
so
it
is
unfortunate
that
we
include
waiting
time
in
the
queue
the
second
time
we
pass
through
the
master
queue
we
include
into
crunching.
So
it's
a
nice
picture
I
think
because
it
gives
a
very
good
intuition
about
what
has
happened,
that
the
processing
time
is
actually
the
multiple
of
the
it's
actually
some
time.
Four
processes
say
a
single
request,
multiplied
by
the
number
of
requests
sitting
in
the
queue.
So
we
have
a
second
test
on
a
big
cluster
with
that.
A
E
E
A
A
E
A
A
E
A
A
E
A
E
E
Okay,
shall
we
move
on
for
me,
okay,
so
this
second
test
was
a
bigger
cluster,
with
more
than
100
nodes,
12,000
tasks
and
more
than
1,000
frameworks
and
we'll
come
back
to
this
slide.
The
here
the
graph
is
slightly
different.
So
what
we
measured
here
was
the
time
that
the
request
spends
in
the
queue
including
authorizing
and
including
so
to
what
you
walks
through
the
master
queue.
Then
the
red
that
is
almost
invisible.
E
He
is
crunching
and
I'll,
explain
why
Nick
ranching
is
zero
and
the
blue
is
the
time
with
fan
to
sterilise
the
response,
and
the
blue
is
depicted
twice
on
the
lower
graph
once
on
top
of
gray
and
once
separately.
So
as
we
can
see,
the
viewer
sterilizing
time
as
well
as
sterilizing
time
put
on
top
of
the
gray
on
the
waiting
time.
So
first,
why
crunchin
is
zero,
is
because
in
v-0
v-0
stood
adjacent
response.
There
is
no
crunching
all
the
filtering.
There
are
no
intermediate
objects
anymore.
The
run
off.
There
is
no
filtering.
E
E
A
E
On
on
the
closet,
we've
been
testing
on
state
v,
zero
state
that
Jason
was
used,
so
b1
get
state
and
b1
subscribe.
Where
this
assumption
is
not
true,
where
we
actually
have
crunching,
where
we
convert
the
master
state
into
intermediate
protocol
that
we
then
serialize
no
clients,
no
tools
we're
using
these
these
endpoints.
So
there
is
no
data
here
for
this
now,
if
you
look
at
the
time
spent
per
request,
so
from
the
total
time,
thirty-nine
percent
on
average
across
all
step,
the
Jason
request
across
the
lifetime
of
the
cluster
were
spent
in
waiting.
A
E
E
Think
about
it
is
a
ratio
of
integrals
on
the
on
the
image
below
we
take
the
so
did
the
the
if
you
take
if
you
calculate
the
area
of
the
gray
and
gray
and
blues
of
that,
that
ugly
figure,
if
you
take
that
area
and
if
you,
for
example,
take
only
the
sterilizing
so
the
area
above
below
the
sterilizing
line
that
dotted
blue
line
and
they
divide
one
on
to
another.
You
will
get
you'll
get
what
I'm
talking
about.
E
A
E
E
The
second
would
be
to
pool
state
requests
together
and
process
them
in
parallel,
and
the
idea
above
the
idea
behind
is
behind
this
approach.
Is
that
if
we
observe
at
a
certain
point
of
time
we
observe,
let's
say
six
state
requests
in
the
master
queue,
we
will
dispatch
an
internal
response.
Let's
say
respond.
All
state
requests
call
on
to
the
master
queue
at
the
at
the
moment
when
we,
when
we
observe
the
first
request,
then
until
we
reach
that
dispatch
in
the
master
mailbox,
we
accumulate
all
six
requests
and
then
we
blog
the
master
actor.
E
E
E
The
drawback
here
might
be
that
if
master
Q
is
long
and
we
have
a
lot
of
state
requests
sitting
in
there
when
we
gather
them
and
we
are
about
to
process
them-
let's
say
we
have
three
30
or
40
requests
to
answer.
Then
spinning
up
40
worker
worker
threads
and
blocking
the
master
actor
until
all
the
old
lives
on
the
old
it
finish
might
not
give
us
a
44
2x
speed-up,
so
it
might
take
still
more
time
than
we
spend
processing
one
single
request.
E
So
this
is
why
we
would
like
to
estimate
the
cost
of
creating
a
deep
copy
of
a
master
state,
because
an
additional
approach,
additional
or
alternative,
but
probably
additional
approach
would
be
instead
of
trying
to
respond.
These
pooled
state
requests.
In
parallel,
we
can
create
a
deep
copy
of
the
master
State.
Let
the
master
continue
doing
its
job
and
answer
all
the
pooled
requests,
either
together
or
one
by
one.
It
doesn't
matter
in
a
separate
actor
or
on
a
separate
thread.
E
However,
it
makes
sense
only
if
creating
a
deep
copy
is
way
cheaper
than
answering
one
single
request.
So
we
would
like
to
get
a
better
idea.
How
expensive
will
it
be,
then,
obviously
to
get
some
numbers
how
we
improve?
We
would
like
to
add
a
benchmark
to
somehow
measure
the
master
actor
load
so
that
we
can.
So
we
thought
that
we
can
see
that.
E
Okay
with
this
approach,
we
would
use
the
master
actor
load
by
let's
say
30
or
40
percent,
and
an
extra
sounds
like
a
very
easy
improvement
would
be
to
avoid
the
extra
the
first
trip
through
the
master
key.
While
we
need
to
get
authorization
and
did
not
wait,
do
not
send
the
authorization
through
the
master
queue,
but
on
two
separate
actor
that
has
a
shorter
queue.
There
is
one
another
suggestion
came
recently
from
Ben
Maller,
but
I
think
Bell
and
Ben
will
talk
about
it
separately.
D
Was
just
wondering
if
you
guys
had
to
consider
so
along
the
lines
of
making
it
fun
a
good,
deep
copy
of
the
master
state.
I
I
was
wondering
if
you
guys
can
consider
the
possibility
of
incrementally
pushing
updates
to
do
a
copy
of
the
master
state
in
batches
or
something
to
avoid
like
a
big
one-time
cost
of
the
copy.
E
E
However,
it
sounds
like
a
non-trivial
and
definitely
not
a
very
easy
task
to
incorporate
those
updates.
So
pretty
much
so
pretty
much.
Let's
say
we
need
some.
We
need
specific
structures
in
order
to
answer
each
state
adjacent
requests.
They
are
actually
frameworks
and
enslaves
and
these
structures
inside
they
contain
all
kind
of
a
lot
of
different
collections.
Now,
each
time
when
the
master
updates
anything
in
those
collections,
we
should
issue
an
update
to
the
separate
actor
and
I
think
just
finding
all
those
places
and
make
sure
that
we
modify
the
next
time.
E
Anyone
modifies
the
internal
state
of
the
master
that
we
need
for
the
Teresa
Teresa
to
respond
to
state
requests
that
next
time
the
person
modifies
that
state.
They
remember
that
they
need
to
send
an
update
or
it
should
happen
automatically.
It's
definitely
not
the
previous
three
trivial
tasks,
so
I
would
say
the
global
idea
that
we
probably
at
this
time
agree
upon
is
that
we
should
move
off,
move
off
from
v-0
step
adjacent
to
v1,
get
state
and
subscribe.
E
However,
because
there
are
a
lot
of
people
use
instead
to
JSON
and
v1
get
stayed
and
subscribe.
Calls
are
not
very
well
tested,
yet
with
decided
to
go
for
smaller
improvements
first
and
then
think
about
sending
updates
later
and
probably
move
into
these
two
v1
API
later.
Does
it
does
it
answer
the
question?
Greg
yeah.
B
B
B
B
What
it
does
is
it
spins
up
a
bunch
of
synthetic
agents
with
tasks
and
have
has
them
registered
with
the
master,
and
then
it
issues
a
state
query:
it
does
a
V,
0
state,
query,
a
V,
1
state,
protobuf,
query
and
I
think
some
other
variants
of
that
with,
like
maybe
converting
to
JSON
and
so
on.
But
the
baseline
here
is
v-0
state,
and
this
is
like
a
boxplot
where
the
lower
end,
here's
the
minimum.
B
B
I
also
tried
turning
on
the
single
instruction,
multiple
data
options,
but
it
looks
like
that
actually
is
a
little
more
inconsistent
and
maybe
a
little
slower
there's
actually
not
a
ton
of
those
instructions
that
are
used
in
the
writer
path.
There's
just
one
spot
that
there
used
those
those
are
probably
more
useful
in
the
parsing
path,
and
this
is
the
serializing
path.
So
it
didn't
make
much
of
an
impact
here.
It
kind
of
looks
like
it
might
actually
slow
it
down
a
little
bit,
but
it
looks
like
this
does
provide
a
quick.
F
F
F
F
F
B
B
B
Utf-8
I
think
the
only
impact
this
has
on
us
is
the
files
end
point
where
we
will
sometimes
spit
out
binary
data.
If
people
are
trying
to
look
at
log
files
in
the
past
there's
there
were
some
issues
around
like
actual
Unicode
characters,
because
we
don't
do
it
properly,
but
this
this
would
fix
that
part
of
it.
I
think.
B
If
it's
not
you
tiffy
it'll
it'll
do
something
which
puts
you
know,
I,
don't
know
if
it's
doing
them
the
right
thing,
but
it's
doing
something.
We're
also
doing
the
wrong
thing.
So
it's
kind
of
hard
to
compare
the
approaches,
but
that's
where
I
think
I'm
not
sure,
yet
to
what
degree
I'll
have
to
change
things
or
just
adjust
tests
and
so
on,
but
other
than
that
I
pretty
much.
The
integrations
done.
B
E
B
Yeah
I
think
with
this
with
this,
along
with
this
single
dispatch
change,
we
should
have
a
pretty
substantial
improvement
for
users
like
if
we
compared
those
graphs
that
you
had
to
what
it
would
look
like
with.
You
know
things
taking
half
the
time
in
the
queue
as
well
as
half
the
time
serializing
it
should.
It
should
help
us
get
a
little
bit
more
Headroom,
so.
B
B
B
B
F
E
B
B
E
B
Okay,
we
have
only
12
minutes
left,
so
I
don't
know
if
we're
gonna
get
through
all
this,
but
maybe
I'll
just
call
this
live
front.
Actually,
how
do
I
do
this?
So
I'll
just
mention
a
few
brief
through
things
that
we
don't
have
any
slides
or
anything
interesting
to
show
for
the
first
was
our
JSON
parsing.
B
We
don't
so.
First
of
all,
we
don't
really
use
this
in
a
lot
of
performance-critical
places.
The
master
does
use
it
in
some
end
points
like
if
an
operator
posts,
JSON
or
a
scheduler
post
JSON,
then
we
do
JSON
parsing,
not
a
lot
of
users.
It's
not
a
high
load
generally
from
what
users
are
doing
today,
but
I
did
notice
when
I
was
writing
a
test
that
the
conversion
cost
is
essentially
doubling
the
the
time
it
takes
to
parse.
B
I'll
mention
this
other
one,
which
is
Greg
and
I,
have
been
making
some
improvements
to
metric,
scalability
and
Lib
process.
This
is
mainly
in
support
of
per
framework
metrics,
so
there
were
some
pathological
performance
issues
where,
like
we
were
doing
an
STD
list,
size
which
was
still
N
squared,
which
was
still
order
n
on
in
some
standard
libraries.
So
we
fixed
all
that
and
if
we
have
time
but
I,
don't
think
we'll
have
time
so
I'll
just
punt
on
showing
anything
for
that
right
now.
B
The
next
thing
to
mention
is:
there's
been
some
various
allocator
performance
work,
I
think
the
short
of
it
and
please
correct
me
if
I'm,
wrong,
Ming
but
I
think
the
short
of
it
is
that
in
our
in
our
scale
test
that
we
were
doing,
we
saw
the
allocation
around
time,
go
from
I,
think
15
seconds
to
3
seconds,
something
like
that
five
seconds:
okay,
so
something
like
15
seconds
to
five
seconds
and
after
gathering
more
perforated,
there's
still
some
really
obvious
improvements
to
make
so
we're
thinking.
We
can
get
that
much
lower.
B
B
F
B
The
last
thing
over
the
last
few
things
so
Dario
is
on
the
call
I
don't
know
if
Dario
you
want
to
chat
about
this
briefly
or
if
you
have
any
interesting
numbers
to
share,
but
there
was
a
additional
queue
added
recently
specialized
to
be
multi
producer
single
consumer,
which
is
our
use
case
for
I,
think
event,
consumption
right.
Yes,.
C
So
the
reason
this
has
been
headed
is
I.
Mina
has
been
some
work
on
going
with
getting
not
free
cues
into
the
process
and
the
the
original
queue
that
was
used
there
has
I
mean
it
is
really
fast.
The
problem
with
it
is
that
it
does
not
guarantee
the
order
of
the
elements
to
be
the
same
wendy
cueing
that
it
was
when
nquing
so
enjoy.
I
mean
it
guarantees
that
for
per
thread.
C
The
messages
could
be
out
of
order
from
within
the
actor
context,
which
is
a
huge
problem
to
fix
that
there
was
a
sequence,
number
added
and
so
reordering
had
to
be
done,
undo,
cueing
the
messages
which
obviously
created
some
of
the
performance
of
the
cue.
So
I
came
up
with
this
MP
fcq
it's.
It
is
heavily
inspired
by
implementations
in
JC
foods,
and
this
is
not
post
on
10:24
course
about
a
queue
like
that.
C
It's
an
EQ
structure
and
guarantees
the
ordering
it
it's
I
think
it
yeah
it's
linearizable.
It
is
mostly
weight.
Free
and
I
can
share
some
numbers.
So
on
my
machine,
I'm
working
on
a
Macbook
four
cores,
eight
threads
I
think
2.5
gigahertz
I
am
getting
on
a
contended
with
soca
music
using
seven
threats
introduced,
one
to
consume
of
e-zpass
single
consumer
I,
get
a
total
throughput
of
around
54
million
messages,
a
second
or
operations,
a
second
that
is
around
38
million
inserts
and
15
million
views.
C
Anything
interesting
here,
I
have
some
slight
optimizations
in
flight
that
especially
improve
non
contended
DQ's
and
also
teach
you
on
an
empty
queue
which
I
mean.
Is
it's
not
a
very
interesting
case?
It's
just
just
a
side
effect,
but
it
would
improve
DQ
on
an
empty
queue
by
an
order
of
magnitude,
but
also
be
queuing.
Undone
contended
queue
so
that,
if
there
are
no
producers
running
at
the
moment,
would
also
improve
throughput
slightly,
not
not
quite
as
much
but.
C
C
It's
the
current
non-blocking
or
lock-free
queue
implementation,
but
I
can
run
some
benchmarks
and
see
how
much
better
would
be,
but
the
the
queue
itself.
As
I
said,
it
is
hard
to
test
that
because,
because
of
the
reordering
that
is
stunningly
accurate
implemented
or
in
the
previous
implementation,
that
is
not
done
anymore
in
this
implementation.
So.
C
B
B
B
F
C
It's
just
just
the
current
design,
there's
nothing
that
would
prevent
us
from
doing
it
at
run.
I'm
I
mean
obviously,
if,
if
you
use
a
fixed
implementation,
there's
potential
for
better
compiler
optimizations
but
I
think
that's
the
only
thing
like
no
no
virtual
calls
or
anything
like
that.
Right,
yeah.
B
That
was
the
only
concern
at
the
time
if
it
turns
out
that
we
want
to
actually
have
multiple
queues
and
you
can
select
from
them
depending
on
like,
if
I'm,
a
low
overhead
situation
or
if
I'm
like
a
high
throughput
situation
or
whatever.
Then
probably,
we
have
to
have
the
run
time
option,
but
I
think
the
original
thinking
was
that
we
would
would
eventually
get
towards
having
this
queue
but
be
the
default
and
not
necessarily
having
the
other
options.
But
but
maybe
that's
not
how
we
should
do
it.
I'm,
not
sure
that.