►
From YouTube: GMT 2018-09-19 Performance WG
A
B
B
D
A
B
B
A
B
A
A
This
I
think
I
bring
this
up
just
because
I
saw
a
comment
yesterday
on
one
of
the
chairs
I'm
watching,
which
was
benchmark
condition
path
on
maces
master
I
think
this
was
grouped
under
schedule.
Api,
v1,
information,
epic
and
Greg
was
asking,
isn't
the
issue?
Do
we
need
to
do
any
more
benchmarks
as
a
point?
A
A
B
Yeah
we
can
talk
about
that.
There
hasn't
been
any
work
to
my
know
that
I
guess,
that's
not
true.
There's
been
some
work
just
from
the
fact
that
we
did
some
moves
did
some
copy
elimination
that
would
improve
the
p1
path,
as
well
as
the
original
paths,
but
I
don't
think,
there's
been
any
focus
yet
on
the
scheduler
v1
call
in
Jedi
all.
A
B
A
A
A
A
B
B
Let's
just
walk
through
these
in
each
one
right
now,
mang
has
some
patches
that
are
out
that
are
almost
landed
for
making
the
resources
or
a
perk
do
copy.
Alright,
that's
helpful,
because
a
lot
of
the
functionality
of
the
resources
wrapper,
especially
in
the
allocator,
is
doing
filtering
so
say
like
getting
just
the
unreserved
resources
out
from
a
resources
object
before
the
patches.
B
We
have
to
copy
them
all
out
which
is
rather
expensive
to
do,
and
you
know,
and
often
we
don't
modify
the
output,
and
so
the
approach
in
this
patch
is
to
make
the
resources
wrapper
copy-on-write
so
that
when
you
do
filtering,
it's
less
expensive,
I
think
when
mang.
Maybe
you
can
correct
me
but
I
think
when
we
ran
benchmarks.
B
C
C
Yeah
yeah,
we
probably
should
show
the
graph
I.
Think
you.
When
we
talk
about
the
blog,
we
were
sure
it
anyway.
So
do
what
that?
Oh
yeah,
so
I
guess
you're
already
phonic
yeah.
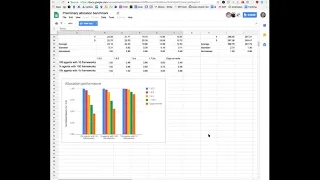
So
this
is
a
graph.
So
comparing
the
allocator
performance
across
different
versions
and
the
last
one
on
the
bottom
is
copy-on-write.
So.
C
Yeah,
so
so
it's
the
optimization
is
more.
It
is
more
significant
when
there
is
less
frameworks
and
when
there
are
large
number
of
frameworks,
for
example,
the
last
column
when
it
reaches
1k,
the
sorting
overhead
becomes
dominant,
it's
less
about
it,
the
filtering,
the
source,
copying
and
etc.
That's
why
we.
C
Yeah
so
Dino,
it's
still
like
the
the
code
is
there,
but
we
don't
have
a
good
abstraction
to
like
god
that
when
you
want
to
militate
the
underlying
resources,
you
have
to
like
be
focused
to
check
that
there's.
Only
the
modifier
has
exclusive
ownership.
So
right
now
it's
a
little
bit
brittle,
but
but
but
we
have
planned
to
add
a
better
abstraction
to
force
more
safe
access.
C
So
here
the
Treasury
is
the
richer
is
the
same,
so
the
agents
to
frameworks
is
tend
to
want,
but
based
on
the
perf
data,
I
got
I.
Think
it's
mostly
about
frameworks,
because
because
when
you
add
agents
I
don't
think
it
affects
the
sorting
right
got
it
then
I
think
you
have
the
perfect
race.
I
mean.
If
people
are
interested,
we
can
take
a
look.
So
basically
it's
the
cactus
sort
and
to
stop
functioning
disorder
and
to
calculate
shares
becomes
dominant.
C
Oh
yes,
asserting,
so
this
is
the
the
the
poor
profile
of
the
last
of
13
in
the
graph
you
see
in
the
in
the
rightmost
column,
when
there
is
I,
think
one
key
agents,
10
K,
10
K
agents
and
1k
framework.
So
this
is
the
poker
valve,
so
you
can
see
the
lodge
number,
so
the
the
the
the
most
time
are
spent
in
the
allocate
function
and
whizzing
that
it's
thought.
So
that's
the
place
where
I
think
the
number
of
frameworks
matters.
B
Yeah
I
think
with
the
patches
that
I
have
for
this
order,
that
we
can
talk
about
I.
Think
if
you
treat
this
actually,
if
you
treat
one
point,
seven
as
one
as
the
normalized
baseline
I
think
we
get
it.
These
patches
get
it
down
to
like
25%
of
that.
Something
like
that.
Okay,
so
there's
so,
there's
gonna
be
an
additional
big
drop
here.
If
we
land
those
notches
and
that's
DRF
as
well,
that's
only
done
with
DRF
yeah.
We
didn't
look
at
the
random
sorter
for
this,
but
I.
B
Well,
we
can
talk
about
what
I
did
to
this
order,
but
it
I
wouldn't
be
I
would
expect
that
it,
the
DRF
store,
is
actually
probably
more
efficient
now
than
the
Oh
random
sorter,
yes,
mainly
because
it
doesn't
have
to
like
it.
It
stays
sorted
most
the
time,
whereas
the
random
one
has
to
reshuffle
whenever
asked
call.
So
it's
like
a.
B
C
B
I
guess
one
and
a
half
seconds
versus
five
and
a
half
seconds
is
I,
don't
know
25
percent
of
a
little
bit
less.
Maybe
it's
around
forty
percent
of
the
original
time
from
when
I
started
working
on
this
and
then
I
assume,
if
you
add
Meg's
changes
in
it's
probably
gonna,
be
a
little
bit
lower
as
well.
I
didn't
include
his
here.
B
Way
you
tell
the
DRF
sorter
that
there's
been
an
allocation
here.
It
goes
and
it
updates
that
node,
so
it
finds
the
node
in
the
tree,
it
updates
it
and
then
it
walks
up
to
the
parent
to
the
root
of
the
tree,
updating
all
the
parents,
and
then
we
say:
okay,
the
tree
is
dirty,
it's
not
sorted
anymore,
which
means
we're
going
to
restart
it
next
time.
Someone
asks
for
a
sorting
order.
B
What
I
did
was
each
so
I
basically
took
out
the
this
dirty
flag
setting
here
and
in
order
to
do
that,
as
we
walk
up
the
tree,
we
shift
the
nodes,
you
know
left
or
right
until
they're
in
their
right
place,
if
it's
not
dirty
to
begin
with.
So
if
the
tree
is
already
sorted
and
we
modify
an
allocation
of
a
node
here,
we
then
shifted
in
its
parents,
children
into
its
right
position
and
we
walk
up
the
tree
and
continue
to
do
that
until
we've
hit
the
root.
B
A
B
B
Not
always
beneficial
and
it
wasn't
beneficial
in
the
benchmark.
That
I
ran
this
on
originally
and
that's
because
for
the
framework
sorting
remix
orders,
we
currently
update
their
pool
of
resources
every
time
the
role
gets
allocated,
resources,
so
I
had
to
change
that
as
well,
and
once
you
change
that,
what
is
what
an
allocation
cycle
looks
like
it's
sort,
something
get
allocated,
sort
something
got
allocated
and
so
on
a
and
so
each
time
you
call
sort
that's
what
is
expensive
in
this
code.
Here
is
you
have
to
you?
B
We
just
we'd
have
to
change
the
way
that
we
do
DRF
of
the
frameworks
in
a
role
we
have
to
make
the
resource
pool
for
that
the
whole
cluster,
which
is
consistent
for
what
we're
doing
with
the
hierarchy
in
the
DRF
sorter.
So
we
might
as
well
make
it
consistent,
but
that
may
change
behavior
slightly
if
the
dimension
of
role
allocation
is
different
than
the
whole
cluster
size
like
if
the
resource
ratios
aren't
the
same,
then
this
already
might
be
a
little
bit
different.
B
D
D
D
C
C
C
D
B
So
those
are
the
some
other
patches
as
well
I,
don't
know
if
they're
gonna
be
interesting
to
talk
about
right
now,
but
they're,
just
some
more
minor
things,
just
avoiding
some
vector
resizing
and
avoiding
some
national
map
lookups
when
you're
calculating
weights
and
things
like
that
and
we
need.
We
need
different
benchmarks
if
we
want
to
show
the
weight,
lookup
improvement
right
now,.
B
A
B
C
C
Benchmark
caspase
and
what
it
does
is
what
take
a
bunch
of
parameters
that
you
set
and
initialize
a
cluster
for
you.
So
what
are
the
parameters?
So
one
is
framework
profile
you
can
specify.
The
name
goes,
number
of
instances,
resources,
etc
and
agent
profile,
so
name
again,
instances,
resources
and
used
resources,
so
so
the
base
class
worth
taking
all
these
parameters
and
set
up
to
the
classroom
for
you,
it
will
initialize
their
allocated
based
on
the
parameters.
C
You
can
specify
difference,
orders
things
like
that
and
it
will
stop
to
watch
at
the
agents
so
basically
abstract
all
the
common
things
that
previously
existed
in
the
individual
Aikido
benchmarks
at
the
frameworks
on
the
Asaro
and
then
from
that
that
point
you
can
focus
on
what
what's
happening
when
all
the
clusters
are
set
up.
So
maybe
let
me
show
so.
This
is
the
first
best
markup
you'll
edit
that
utilize
the
base
cause.
C
Jenkins
spark
dispatcher
and
then
so
all
these
are
pushed
into
the
benchmark,
config
and
pasta
config
into
the
cluster,
so
so
to
configure
well
have
a
bunch
of
default
values.
Here
we
are
using
the
API
of
sodor.
It's
like
one
second
allocation
interval,
things
like
that.
Another
thing
is
why
we
initialize
classic.
We
pause
the
allocation
so
from
this
point
on
it's
two
classes
in
a
pristine
States.
So
that's
so
that's
some
improvement
over
previous
benchmark
well.
Well!
C
Well,
while
you're
adding
frameworks
and
agents
that
might
be
event-driven
allocations
which
might
pollute
the
final
result.
So
here
on,
once
you
start
allocation,
it's
our
pristine
State
and
then
it's
it's
all
about
like
traversing
the
sort
of
issue
in
each
iteration.
We
advance
the
clock
and
you
will
get
a
bunch
of
all
for
callbacks,
which
is
put
into
the
offer,
offer
queue,
and
then
you
can
decide
what
to
do
with
this
offer
here.
I
think
it's
about
so
for
its
framework,
getting
an
offer
and
then
launch
launched
a
bunch
of
tasks
given
several
constraints.
C
For
example,
its
offer
each
framework
has
some
X
tasks
per
offer,
so
you
might
try
to
launch
as
many
tasks
as
possible,
like
the
launch.
Here
is
really
do
not
decline
the
resources.
So
after
we
are
read,
we
is
also
offered.
We
declined
at
the
remaining
resources
and
then
at
the
end
we
print
out
a
bunch
of
statistics
so
yeah.
So
so
this
space
is
really
about
initialize,
a
cluster
for
you.
C
There
are
more
future
works
by,
especially
given
the
test
body
part
where
I
think
this
part
can
also
be
automated,
so
hopefully
in
the
future.
While
you
are
creating
the
framework
profile
or
allow
you
to
specify
how
the
framework
will
be
treating
those
offers,
so
all
you
need
to
do
is
think
about
okay,
I'm,
giving
an
offer
and
what
I'm
going
to
do
with
this
offer.
So
we
will
so
basically
this
this
part
of
the
test
body
will
be
an
automated
as
well
so
in
the
future.
C
Hopefully,
writing
a
benchmark
is
a
it's
just
about
populating
all
the
few
things
that
there's
more
config,
and
once
that
is
done,
you
can
just
click
start
being
the
allocation
and
then
you're
getting
to
statistics.
You
want
yeah
I,
think
that's
pretty
much
it
so
right
now
the
base
is
there
and
there's
only
one
benchmarks:
that's
currently
using
the
base
I'm
planning
to
like
maybe
slowly
migrating
other
benchmarks
that
try
to
benefit
this
from
this
space
and
also
add
some
other
benchmarks
in
particular.
C
Right
now
on,
the
task
at
the
base
doesn't
have
any
buting
status
statistics.
So
all
these
are
are
wheezing
the
casted
body,
so
each
test
individual
will
bring
out
like
plucked
and
print
out.
The
statistics
I
do
have
plant
at
matrix,
especially
the
allocation
latency
to
the
to
the
test
base,
so
that
you
don't
need
to
I
have
so
that
at
the
end
you
can
just
courage
the
metric
snapshot
and
it
will
bring
out
at
least
allocation
latency
number
of
allocations,
etc.
But,
right
now
we
can
do
that.
C
The
cheetah
due
to
the
fact
that
the
metric
right
now
depends
on
the
clock,
the
leap
process,
clock
and
we
can't
do
that
because
in
the
test
we
have
manually
controlling
the
clock
and
it
will
mess
up
with
the
metrics.
So
once
we
decouple
the
metrics
from
the
process
clock
clock
instead
use
stopwatch,
we
will
have
buting
metrics
in
the
in
the
allocator
test
base,
but
things
like
classic
capacity,
cluster
allocation
and
all
these
things
on
the
individual
has
the
still
needs
to
you
know,
collect
and
report
itself.
C
C
B
When
I
was
auditing
the
code
path
on
the
master
side,
if
you
look
at
the
benchmarks
that
mang's
been
talking
about,
none
of
them
benchmark
the
actual
master
side
of
sending
those
offers
out
to
frameworks.
We
don't
have
a
benchmark
for
that
right
now.
So
I
don't
know
how
much
these
changes
actually
improve
things.
But
I
did
an
audit
of
the
code
paths
there
and
there
were
a
lot
of
low-hanging.
B
B
Well,
the
patch
that
I
had
was
to
instead
have
a
specific
overloads
for
increment
of
nth.
That
knows
how
to
handle
all
of
the
old-style
messages
here,
because
previously
there
was
only
an
increment
of
nth
for
one
type
here,
which
means
you
have
to
convert
it.
Okay
into
this
type
and
it's
the
entire
type.
It
takes
the
whole
message,
not
just
the
event
type,
so
this
just
adds
overloads
to
increment
the
right
thing,
so
we
don't
have
to
copy
it
at
all.
B
We
just
pass
it
through
and
then
a
lot
of
other
stuff
was
just
like
making
sure
vectors
have
the
right
capacity,
we're
where
we
can
and
avoiding
looking
up
things
multiple
times
and
maps,
and
then
the
main
benefit
I
think
from
these
patches
is
just
eliminating
copies.
Protobufs,
the
one
just
showed
was
to
two
extra
copies
of
every
outgoing
message.
B
There
was
reducing
copying
and
there
were
evolved
helpers
by
using
moves
instead
of
copy
from,
and
there
was
yet
another
copy
of
the
offers,
because
the
way
that
the
repeated
fields
wrapper
was
implemented
for
evolve
was
it
actually
took
an
argument
by
copy
by
accident.
I
think
so.
There's
another
copy
there.
B
B
So
when
it
gets
down
to
evolving
the
actual
an
individual
offer
itself.
It
goes
through
this
path,
which
is
going
to
deserialize
the
b0
offer
and
then
serialize
it
back
as
a
v1,
offering
you'll
notice
that
some
of
the
overloads
here
actually
don't
do
that
they
have
logic
to
just
copy
it
over
and
the
claim
the
node
here
says
like
since
this
one's
common.
B
We
wanted
to
speed
up
performance
which
makes
me
think
that
maybe
they
benchmarked
this,
but
it
I
think
it
should
obviously
be
faster
to
not
deserialize
and
then
serialize
back
in
this
particular
case,
where
you're
copying
just
one
string,
there's
also
room
in
this
code
here
to
like,
take
our
value,
references
and
move
things,
but
it's
gonna
be
quite
a
bit
of
work.
So
until
we
have
a
benchmark,
I
I
probably
wouldn't
look
into
that
more.
B
So
we
still
need
a
benchmark
for
the
master
side
of
sending
offers
out
to
make
sure
we
can
do
that
as
quick
as
possible
and
there's
there's
lots
of
things
we
can
still
improve
there.
I
think
I
tried
to
write
them
down
in
the
in
this
ticket.
So
there's
the
deserializing
serializing
cost
that
I
just
talked
about
and
then
there's
also.
We
could
use
some
parallelism
to
speed
up
sending
out
the
offers.
B
B
B
A
What
really
does
just
occurred
to
me
while
we're
talking
about
possible
things
to
discuss
and
I'm,
not
fully
where,
instead
of
sentence
I
was
king
people
care,
aware
of
them,
so
I
think
in
general
I.
This
has
been
a
pain
point.
I,
don't
have
specific
numbers,
so
I
think
that's
its
overall
I
just
had
a
abstract
idea
about
what
he
I
need
to
get
us
improved,
so
not
necessarily
a
specific
things.
B
B
Where
does
it
time
it?
Okay,
so
just
times
how
long
this
and
takes
for
things
to
get
settled
yeah?
So
we
could.
We
could
use
this
to
just
take
a
quick
look
run
perf
on
it.
I,
don't
think
he
ever
back,
then
I,
don't
think
we
were
asking
folks
to
provide
perf
stack
traces,
but
it's
it's
probably
as
simple
as
just
running
this
and
getting
some
perf
data
and
sharing
it.
And
if
we
see
any
obvious
problems
there,
we
can
take
care
of
them
cool.
B
B
A
The
fact
that
you
know
one
framework
is
just
starting
out
with
nothing
and
the
other
framework.
Being
you
know,
eight
percent
of
its
way
to
fully
launch
and
doesn't
necessarily
suggest
any
kind
of
priority
to
us.
So
I
was
gonna,
see
how
how
much
ever
in
this
order
is
gonna
help.
It
seems
like
well
in
my.
B
B
B
After
these
patches,
it's
gonna
be
worse,
it's
gonna
be
slow,
the
random
store
is
gonna,
be
slower,
and
unless
we
do
the
optimization
to
be
able
to
like
iterate
without
having
to
sort
the
whole
thing
it
it's
gonna
be
hard
like
that's.
The
main
optimization
we'd
have
to
do
is
let
let
the
caller
kind
of
iterate
in
some
way,
which
basically
means
you
know
if
you
only
needed
the
first
two
results.
You
just
did
two
random
samples,
rather
than
doing
a
random
sampling
of
the
whole
data
set
and
sorting
it.