►
From YouTube: Argo CD and Rollouts Community Meeting Dec 2022
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
If
you
haven't
already,
please
go
ahead
and
add
yourself
to
the
attendee
list
on
our
meeting
notes
and
just
a
reminder
that
the
Argo
project
adheres
to
the
cncf
code
of
conduct.
So
please
be
courteous
and
respectful
to
one
another,
and
this
meeting
is
being
recorded
and
will
be
uploaded
to
YouTube
later.
A
If
you
have
any
agenda
items,
issues
or
discussion
topics,
you
can
also
tack
that
on
to
the
meeting
notes-
and
we
might
be
able
to
get
to
it
at
the
end-
and
today
we
have
actually
a
number
of
topics.
Then
we
have
Captain
maintainers
about
to
talk
about
get
Ops
with
the
captain
life
cycle
controller,
some
Argo,
CD,
2.6
demos
of
new
features
and
looks
like
a
project
called
iterate
from
Allen
and
and
before
we
get
to
that.
A
Actually,
if
you
didn't
hear
the
news,
Argo
is
officially
a
graduated
cncf
project,
so
this
is
actually
a
huge
milestone
that
everyone
should
be
really
proud
of,
and
you
know
we're
up
there
with
all
these
big
names
like
Prometheus
and
kubernetes
itself
and
Envoy.
So,
first,
like
thanks
to
our
maintainers
in
their
Community
for
all
the
the
work
you
know,
documentation
fixes
and
just
even
just
using
the
product
itself.
All
that
feedback
is
what
made
get
us
got
us
where
we
are
today.
A
A
B
A
B
And
I
think
this
presentation
will
take
about
20
to
25
minutes
so
at
first,
let's
take
a
look
on
what
we
found:
what's
cool
about
GitHub,
so
at
first
we
have
a
declarative
state
in
another
version
way.
So
we
have
everything
we
want
in
a
git
repository.
We
have
a
version
that
can
apply
it
whenever
we
want
things
we
applied
are
reconciled
automatically
I.
Think
you
I,
don't
have
to
tell
this
to
you.
So
you
might
know
this
the
best.
B
B
The
second
thing
are
there
some
prerequisites
for
this
deployment
so,
for
instance,
when
it's
an
infrastructure
related
to
this
before
I
apply
the
the
configuration
then
sometimes
this
is
also
nice
and
nice
and
Argo.
You
see
graphically
many
things
very
nice,
but
often
you
really
don't
know,
what's
really
what's
happening
at
the
moment.
So
you
don't
know
how
many
deployments
are
running
on
how
many
clusters,
and
so
on
and
last
but
not
least
after
you
deploy
the
application.
B
You
only
know
that
it's
definitely
correct,
so
you
know
that
you
have
the
specified
amount
of
ports.
You
know
that
your
health
checks
are
ready
and
so
on.
But
in
fact
you
don't
know
if
your
customer
clicks
on
on
a
button
if
it
takes
him
about
one
minute
to
get
to
response,
and
these
are
the
things
we're
trying
we're
trying
to
take
a
risk
with
the
captain
life
cycle
toolkit.
B
So
the
first
thing
we
take
is,
and
what
we
are
doing
at
the
moment
is
we
are
trying
to
build
in
observability
into
the
deployment
process,
so
you
can
think
of
the
cap
life
cycle
toolkit
as
a
controller
which
is
running
in
the
community
disaster
and
which
holds
which
tracks
your
deployment
process
and
also
do
some
measures
to
add
tasks
around
evaluations
and
so
on.
During
the
deployment
process.
B
B
B
You
can
display,
as
you
want
the
second
nice
part
we
are
doing
here
is
we
are
building
traces
out
of
the
deployments
so,
for
instance,
you,
you
can
Define
some
kind
of
applications
which
can
consist
of
multiple
virtuals
and
in
the
end,
you
see
how
you
are,
how
your
application
got
deployed.
How
long
your
pre-deployment
tasks
took
along
your
post
deployment
tasks
took
how
long
the
deployment
itself
took,
and
you
can
start
to
troubleshoot
there
if,
on
the
on
the
performance,
and
as
you
see
here,
you
can
also
see
some
some.
B
You
can
also
see
where,
in
your
deployment,
the
problems
came
up
and
all
of
the
things
we
are
doing
here
are
working
out
of
the
box.
So
you
don't
have
to
specify
an
special
custom
resources
to
get
your
deployments
in
there,
so
we
are
using
deployment
status
and
so
on
using
the
kubernetes
recommended
labors
for
some
things,
such
as
applications
in
our
case,
which
is
a
bundle
of
market
products.
You
need
the
custom
resource
because
there
is
nothing
in
communities
at
the
moment
and
also
for
evaluations
and
tasks
here
also
in
the
customers.
B
The
second
thing
we
have
are
pre
and
post
deployment
tasks
as
well
as
evaluations,
and
therefore
you
can,
as
I
said
before,
you
can
for
us,
it's
not
really
relevant,
which
tooling
you
are
using
using
because
we
are
working
on
the
community
discussed
itself.
So
for
us,
it's
okay
to
use
cargo,
you
can
use
flux.
You
can
use
Champions
whatever
you
like.
As
long
as
it
deploys
the
community
doesn't
end
when
it
comes
to
kubernetes.
We
can't
do
some
pre-deployment
tasks
based
on
the
application
Level.
B
Okay
and
after
some
time,
all
of
the
tasks
are
already
kubernetes.
Did
this
work
till
it's
work
and
schedule
the
ports?
And
after
after
after
each
workout,
you
can
run
some
kind
of
post
deployment
past,
as
well
as
evaluations,
and
after
all,
of
the
workouts
of
one
application
have
finished,
you
can
also
post
some
tasks
and
evaluations
based
on
the
application.
B
What
you
see
on
the
right
lower
side
is
such
a
typical
evaluation
definition.
In
our
case,
we
use
Prometheus
with
specified
one
objective
and
we
did
a
problem
and
in
the
future,
will
be
possible
to
do
this
with
what
I
have
absolutely
the
provider
you,
like
whomever,
created
a
provider
for
you,
okay,
so
I
think
I
talked
very
much
now
and
I
think
you
might
want
to
know
how
this
works.
B
In
this
demonstration
I
will
this
will
change
a
bit.
I
will
use
Argo
for
deployed
for
deploying
we
will
do
some
pre-deployment
evaluation
and
check
if
enough
CPU
is
available
to
run
this.
So
for
this
we
will
utilize
Prometheus
after
we
found
out
that
this
is
that
there
is
enough,
then
we
will
run
some
pre-deployment
tasks
and
check
if
the
entry
service
is
available
and
in
the
end
we
would
send
out
this
like
a
notification.
This
is
the
single
drop
today.
B
Okay,
so
then,
let's
get
directly
in
the
demo,
so
I
have
a
sample
application
here,
and
if
we
take
a
simple
look
on
the
Manifest
here,
we
see
that
this
is
a
typical
manifest
as
when
you
know
it
from
kubernetes.
So
we
have
a
namespace.
The
only
thing
we
had
to
do
to
enable
the
lifecycle
toolkit
is
we
had
to
annotate
the
namespace.
B
Then
we
have
some
kind
of
deployment
and
in
some
deployments
we
might
also
see
a
part
of
Labor,
which
is
in
our
case
specifying
to
which
application
this
this
virtual
belongs.
We
have
a
name
labor.
This
tells
us
that
the
workload
is
named
this
way
and
we
added
some
cat
annotations
where
we
can
say.
Yes,
we
want
to
run
a
pre-deployment
task
and
the
same
would
be
for
post
deployment
tasks
and
for
post
deployment
evaluations.
B
If
we
take.
If
we
want
to
see
how
such
a
pre-deployment
task
looks
like,
then
we
will
have
such
thing.
Hopefully,
let's
take
this
one.
So
this
is
yes
yet
another
part
on
plus
definition,
we've
defined
how
it's
named
here
we
defined
where,
where
it
is
deployed
to-
and
we
can
specify
where
we
can
find
this
task-
this
can
be
either
in
HTTP
server
and
so
I
will
simply
open
this
and
can
choose
to
you.
B
So
in
this
case
this
is
a
very
simple
typescript
function,
where
you
see
where
your
simplification
URL
and
if
it
is
okay,
then
we
exit
with
zero
and
otherwise
we
exit
with
one
so
women's
dependency
check,
but
this
can
also
be
more
sophisticated
things.
So
we
did
the
same
with
select
notifications,
you
can
run
promotion
tasks
and
whatever,
and
you
can
parameterize
this
and
with
this
I
only
said
yes,
I
want
to
check
for
this
URL,
and
if
this
is
there,
then
then
it
can
run.
B
B
B
B
B
B
B
Yes,
I
see
that
the
pre-deployment
evaluation
now
failed.
This
was
in
this
case
because
of
because
some
thresholds
were
were
said
really
strict.
We
can
also
take
a
closer
look,
and
this
is
this-
is
the
interesting
observability
part
in
the
we
have
grafana
dashboards?
For
that
we
would
see
that
our
application
is
running
at
the
moment.
We
see
that
five
of
our
applications
were
failed
and
the
nice
thing
is.
B
We
can
also
take
a
closer
look
into
our
into
our
deployment
and
see
that
we
had
a
deployment
for
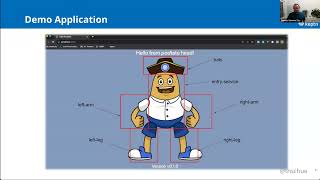
the
Potato
Head
and
the
version
zero
one
zero
one.
We
had
some
application,
pre-deployment
tasks
which
have
been
finished,
but
we
had
a
application,
pre-deployment
evaluation,
which
was
failed
and
in
the
events
here
we
see
why
it
failed.
So
we
saw
that
the
available
CPUs
were
to
view
in
this
case.
B
What
we
are
planning
to
do
for
Argo
is
that
we're
providing
Integrations,
where
you
see
the
statement
a
bit
a
bit
more
in
detail,
but
we
are
in
a
pretty
real
estate
at
the
moment,
good.
So,
let's
get
to
a
state
where
we
can
see
our
our
deployment
will
succeed.
Now,
in
this
case,
I
have
a
second
version
where,
where
I
change
this
so
I
will
simply
use
another
customization.
We'll
do
this
one
and
when
I
get
back
to
Argonaut.
B
B
B
B
That's
okay
because
they
were
prereq
and
the
interest
service
was
a
prerequisite
fall
of
the
other
ones,
and
you
can
also
find
out
where
you
lost
time
through
all
of
the
application
deployments,
and
this
is
really
nice
so
and
in
the
end,
after
everything
has
been
deployed,
you
could,
for
instance,
say
yes,
I
want
to
send
this
like
notification.
It
is
the
thing
I
do
very
often
in
my
in
my
demos.
Another
thing
where
which
you
can
think
of
is
that
you
can
do
some
changes
in
kit
afterwards.
B
B
Another
thing
we
could
think
of
is
also
that
we
could
try
to
switch
traffic
on
a
on
a
on
the
application
state
level,
but
that
this
is
a
thing
which
comes
in
the
future.
For
us.
Other
things
we
are
thinking
like
other
use.
Cases
were
thinking
of
are
some
kind
of
some
kind
of
git
promotions.
So,
for
instance,
we
could
say
this
cluster
has
been
finished.
B
B
B
B
The
integration
of
external
tools
is
very
easy,
so,
for
instance,
we
can
write
functions
at
the
moment.
On
the
other
hand,
you
will
be
able
to
run
containers
in
the
future,
and,
last
but
not
least,
the
whole
thing
is
very
easy
to
install
and
configure
at
the
moment
we
need
to
manifests.
The
one
is
third
manager
because
we're
using
a
webhook.
We
are
trying
to
get
rid
of
this.
The
second
one
is
our
lifecycle
toolkit
itself,
and
you
get.
You
need
some
some
annotations
for
the
configuration.
B
Okay,
that's
it
from
my
side.
So
if
you
are,
if,
if
you'll
find,
this
is
a
this
is
a
nice
project
and
you
want
to
try
it
out.
We
are
on
GitHub,
we
also
seeing
save
project,
so
we
will
find
us
on
the
sensitive
Slack
and
yes,
we
are
also.
We
are,
as
this
is
a
really
new
project.
We
are
very
eager
to
get
to
know
about
your
your
opinions
and
how
you
see
the
whole
thing.
B
If
you
want
you
can,
you
can
also
contribute,
raise
up
issues
and
so
on.
I
think
is
every
open
source
project
we
will
accept.
We
will
we
are
willing
to
accept
many
pull
requests
and,
yes,
as
I
said,
you'll
find
us
on
a
sincere
flick
with
this.
Thank
you
for
having
me
here
and
I'm,
not
sure
how
it's
how
it's
used
to
work
here.
A
No
thank
you
for
the
presentation,
so
we
had
some
questions
that
popped
up
in
the
chat.
The
first
one
was
actually
for
me
as
winning
asanas
the
pods
weren't
starting
is
that
is
there
anything
the
technical
reason
they
weren't
studying?
Was
it
because
of
a
injected
pod
Readiness
gate
that
Captain
and
injected
into
the
Pod
to
prevent
it.
C
B
C
B
School
schedule
running
a
schedule,
extension
I,
see
scheduler
extension
takes
care,
takes
care
of
our
custom
resources
and
tries
to
find
out
if
everything
is
ready
and
after
everything
was
ready,
then
it's
then
it
bound
the
ports
and
therefore,
then
then
the
ring
we
know
with
kubernetes
1.26.
There
is
a
feature
for
scheduling
readiness,
and
this
is
a
thing
we
we
plan
to
utilize
in
the
future.
B
B
A
B
Yes,
if
I
have
time
enough,
then
it
will
be
definitely
possible
to
run
tasks
in
patent,
because
I
like
to
run
to
to
write
a
like
pattern
called
more
than
the
typescript
code
and
for
go
it's
more
about
contributions.
So
when
some
someone
wants
to
create
the
create
a
runtime
for
this,
then
it
also
is
not
not
a
really
Pro.
A
real
problem.
I
also
think
that
it
that
it's
not
a
real
problem
to
to
implement
this
into
our
into
our
anthem.
C
A
B
B
A
B
Use
case
we
want
to
cover
which
we
did
not
cover
at
the
moment,
so
we
started
writing
the
lifecycle
toolkit
in
the
middle
of
September,
but
it
is
definitely
a
use
case
because
we
we
saw
that
this
is
that
this
is
asked
by
many
people
and
using
such
functions.
I
think
this
will
be
possible.
The
it's
only
a
matter
of
time
until
someone
writes
it
to
be
honest,.
A
Okay,
great
so
Michael
is
gonna,
propose
that
we
actually
let
Alan
from
iterate
go
next
and
then
just
in
case
we
run
out
of
time.
Then
we
can
save
our
2.6
content
for
the
next
month's
meeting
in
case
just
in
case,
we
ran
out
of
time.
Sure,
okay,
Alan,
is
that,
okay
with
you
yeah,
that's
that's.
Okay,.
D
But
I
can
I
can
I
can
still
talk
so
hello,
everyone,
my
name
is
Alan
Chao
and
joining
with
me
today
is
also
shree
and
also
Michael,
and
we
are
representing
iterate,
which
is
an
open
source,
kubernetes
release
Optimizer
for
testing
kubernetes
apps.
So
if
I
could
share
my
screen,
I
would
show
you
our
website
right
now,
which
is.
D
C
D
B
Yeah
so
before
Captain
was
a
tour
where
we
had
well
with
very
much
use
cases
so,
and
it
was
often
not
clear
what
what
the
positioning
of
Captain
is,
and
we
also
found
out
that
it's
very
hard
to
to
integrate
in
github's,
tooling
and
so
on.
Therefore,
we
decided
to
build
something
new
for
such
use
cases,
and
this
was
the
birth
of
the
life
cycle.
It
Wicked.
B
E
D
A
D
So
again,
I'll
just
restart
hello.
My
name
is
Alan
Chao
and
joining
with
me.
Today
is
SRI
Barta,
sarathi
and
also
Michael
calendar,
and
today
we're
representing
iterate,
which
is
an
open
source,
kubernetes
release
Optimizer
for
testing
kubernetes
apps
and
we're
here
today,
because
we're
working
on
a
new
feature
that
is
built
on
top
of
Fargo
CD
and
unfortunately
it
is
still
in
the
works.
D
So
we
cannot
demo
it
today,
but
we
want
to
to
share
and
have
a
discussion
with
you
guys
and
see
what
you
guys
think
about
it.
So,
in
order
to
describe
what
we're
working
on
I
need
to
First
give
some
context
on
what
iterate
is
so
like
I
mentioned
before
it
is
a
open,
open
source,
kubernetes
release
Optimizer
for
testing
two
links,
apps
with
iterate.
You
can
perform
experiments
different
various
kinds
of
experiments
such
as
SLO
validation,
Canary
tests,
ABN
tests,
Etc
and
so
in
iterator.
D
So
our
latest
feature
is
Auto
X,
and
this
is
just
a
snippet
of
a
blogger
call.
Then
I'm.
Writing
I
would
not
recommend
reading
this
right
now,
because
you
probably
need
the
context
from
the
reset
article,
but
we
do
have
like
this
little
image
that
might
be
able
to
give
you
an
idea.
What's
going
on,
but
Auto
X
Auto
X
is
short
for
automatic
experimentation,
and
the
idea
is
that
iterate
can
detect
changes
in
the
different
kubernetes
apps
that
you're
running
and
based
on
those
changes.
D
D
You
can
set
up
Auto
X
so
that
it'll
automatically
start
a
validation
tests
for
that
new
version,
and
you
will
be
able
to
know
if
you
know
the
latest
version
of
your
application
meets
basic
functional
requirements
right
making
sure
that
it
is
performing
well.
It
is
meeting
latency
and
error
related
metrics
Etc,
and
this
this
feature
is
built
on
top
of
Argo
CD.
So
in
it
in
essence,
with
auto
wax,
there
is
a
way
to
define
what
what
the
watch
for
what.
D
What
kind
of
kubernetes
resource
should
be
used
to
trigger
a
new
experiment
and
which
experiments
should
be
run
and
Argo
Argo
CD
is
used
to
install
these
experiments,
which
are
captured
in
home,
charts
and
and
there's
a
few
reasons
why
we
chose
to
use
Argosy
to
do
this.
First,
we're
building
the
the
Auto
X
capability
for
GitHub
users
specifically
get
up
get
up,
users
that
are
already
using
Argo
CD
and,
secondly,
iterate
packages.
D
F
Well,
we
do
have
a
demo
that
we're
working
on
and
we
hope
to
release
through
the
community
just
a
little
bit
more
context
in
terms
of
you
know
who
this
is
really
intended
for,
so
we
have
been
working
with
a
few
other
communities,
especially
machine
learning.
Communities
like
case
serve
even
the
serverless
k-native
community.
So
we
have
a
few
users
who
are
starting
to
use
iterate
for
ML
deployments
and
experiments
with
you
know,
ml
models
and
also
Selden,
which
is
like,
which
is
a
startup
machine
learning
startup,
but
they
have
their
own.
F
You
know
open
source,
kubernetes
resource
types
they
use
for
machine
learning
deployments.
So
we
have.
You
know
when
we
talk
about
experiments,
we're
talking
about
performance,
experiments
like
load,
testing
and
performance
testing,
basic
experiments,
but
also
a
b
testing,
which
is
more
like.
How
do
you
collect
business
metrics?
Make
sure
you
promote
the
version
that
is
maximizing
business
metrics.
So
all
those
experiments
are
what
we
want
to
automate.
F
We
envision
here.
The
scenarios
appear
envisioning.
Is
that
your
app
goes
through
your
new
versions
of
the
app
or
going
through
git,
so
argosity
is
reconciling
and
deploying
those
applications
and
get
from
get,
but
just
looking
at
the
labels
that
are
supplied
with
those
applications,
that's
what
we
are
actually
watching
for
you
know
specific
labels
on
the
application
resource
objects.
We
can
trigger
these
experiments
a
b
testing
and
performance
experiments
automatically
for
those
application
resources.
F
The
experiments
themselves
do
not
go
through
git.
The
experiments
are
just
you
know
in
the
cluster
and
they're
kind
of
transient
resources
right.
So
when
a
new
version
comes
up,
they
experiment
automatically
pops
up.
You
can
you
know
you
can
use
the
iterate
tooling
to
query
results
of
the
experiment
and
when
the
new
version
is
taken
away,
the
experiment
is
cleaned
up
transparently
and
it's
happening
in
the
cluster.
That's
the
idea.
F
A
F
So
it
is
a
yeah,
it
is
a
kubernetes
job,
but
there
can
be
experiments
where
it's
it's
their
sort
of
repeated
Loops
of
the
experiments
or
a
period
of
time,
you're
collecting
metrics
for
your
different
application
versions
and
over
a
period
you're
checking
whether
the
metrics
are
you
know
satisfying,
but
you
have
a
new
version.
Is
that
new
version,
maximizing
profits
or
maximizing
user
engagement?
New
version
of
a
machine
learning
model,
for
example,
is
that
you
know
leading
to
more
clicks
compared
to
an
older
version.
So
that's
an
example
of
a
b
testing
experiment.
F
A
I
see
the
in
the
diagram
a
user
can
get.
You
know,
reports
on
the
experiment,
so
this
when
an
experiment
succeeds
or
fails
or
or
just
provides
information,
whether
it's
the
user.
How
does
the
user
get
these
reports
and
then
like
does
it
affect?
Is
there
any
automation
that
happens
like
after,
like
if
it's
or
is
it
just
more
for
reporting.
F
So
let
me
take
a
look
at
right,
so
this
is
a
simple
load,
testing
experiment,
so
you're
viewing
a
report
using
the
CLI
and
you're
in
a
certain
conditions
using
a
CLI
but
in
terms
of
further
automation
after
the
experiment
finishes.
One
example
is
notifications,
of
course,
so
the
experiment
as
part
of
an
experiment
task,
one
of
the
tasks
could
be
just
notified
and
you
could
say
you
know,
notify
slack
notify
some.
You
know
GitHub
actions,
receiver.
There
are
different.
Of
course
you
can
build
other
notifiers
also.
F
F
F
Yeah
one
thing
we
were
hoping
one
thing
we
were
hoping
to
achieve
through
this
conversation
was
first
of
all,
we
wanted
to
get
illicit
your
feedback
and
you
know,
thoughts,
comments
and
second,
we
do
want
to
come
back
to
you
with
a
working
demo
of
this
capability
so
that
we
can,
you
know,
get
a
a,
perhaps
even
more
relevant
comments.
And,
finally,
you
know
any
ideas
we
might
have
on
how
you
know
we
can
benefit
the
Oregon
City
Community.
With
these
capabilities.
A
F
So
this
is
this
is
that
this
does
not
use
a
crd.
Actually,
the
everything
is
kubernetes
native,
that's
jobs,
current
jobs,
they
experiment
under
the
covers
that
the
configuration
of
the
experiment,
job
is
through
secrets
and
the
whole
thing
is
packaged
as
Helm
charts.
So
when
you
deploy
the
helm,
chart
you're
really
deploying
jobs
whose
configuration
is
in
Secrets
or
crown
jobs
whose
configuration
is
in
secrets.
That's
how
it.
A
Works
in
nice
hours,
yeah
Okay.
The
reason
I
was
asking
because
I
thought
if
there
was
a
custom
resource
that
represented
an
experiment,
just
an
idea
that
occurred
to
me
while
you're
showing
me
this
report
was
actually
the
we
have
capabilities
in
Argo,
CD
itself
to
visualize
CRS
in
any
way
that
a
user
can
code
it
in
JavaScript,
and
this
I
was
thinking
a
nice
Improvement.
If
you
were
to
go,
this
route
is
to
actually
embed
the
the
reports
in
the
Argo
City
UI
using
our
UI
extension
mechanism.
A
A
Like
iterate
job
that
would
have
this,
and
the
benefits
of
using
a
CR
is
that
you
can
customize
the
data
that
appears
in
the
status
and
tailor
it
for
the
like
Dennis.
At
that
point,
it's
really
easy
to
just
get
information
out
of
it.
I,
don't
you
wouldn't
have
to
like
run
logs
or
other
commands
to
get
it,
but
is
why
I
asked
if
it
was
implemented
as
a
crd,
because
if
it
was,
it
would
be
a
lot
easier
to
surface.
F
Yes,
we
I
can
see
how
it
is.
It
makes
it
easy
from
the
rocd
visualization
perspective,
but
you
know,
part
of
the
thinking
here
was
that
we
we
have
a
CLI
driven
experimentation
capability,
also,
which
is
more
imperative.
So
really
anybody
with
namespace
scoped
in
a
privileges
can
launch
experiments
without
having
to
install
clusters,
crd
definition,
so
that
was
part
of
the
thinking
that
went
behind
this
design.
F
F
A
F
So,
depending
upon
some
labels
that
you
mark
up
on
the
resources,
the
experiments
are
automatically
instantiated
or
removed
for
that
matter
or
updated.
So
that's
that's!
A
more
declarative!
Flavor
of
running
these
experiments
right,
of
course,
consume
results
from
the
experiments.
You
still
need
a
CLI,
and
you
know,
or
some
tooling
and
that's
the
CLI
will
continue
to
provide
the
tooling,
but
the
launch
has
now
it's
become
more
than
just
you
know
imperative
you
can
do
it
in
a
more
declarative
manner.
A
Okay,
yeah,
because
I
was
leading
to
a
question
of
how
a
user
might
integrate
like
experiment.
Iterates
in
experimentation
is
part
of
their
their
process,
so
I
guess,
if
they're,
using,
for
example,
just
CI
to
kind
of
orchestrate
their
deployments,
they
could
invoke
the
iterate
CLI
to
to
say,
okay
after
I
deployed,
then
kick
off
an
experiment.
The
other
thought
I
had
was
Argo.
A
Cd
itself
can
launch
a
job
which
could
that
as
opposed
sync
hook,
and
that
job
could
be
nothing
but
an
iterate
CLI
invocation
to
to
launch
an
experiment
as
part
of
the
deployment
process.
So
just
going
throwing
out
ideas
that
how
people
might
get
started
or
how
you
might
suggest
people
that
integrate
with
Fargo
CD
even.
F
Yeah,
that's
a
very
interesting
thought:
the
the
post
deployment
hook
using
the
iterate
CLI.
We
we
never
thought
of
it
that
way,
but
it's
certainly
that
opens
up
it's.
It's
really
the
same
functionality
but
depending
upon
you,
know
their
cicd
process,
and
you
know
the
familiarity
with
stooling,
and
you
know
the
process
they
want
to
adopt.
You
are
opening
up.
There
are
lots
of
different
ways
in
which
the
experiments
can.
A
A
E
A
C
E
E
All
right
so
23
new
features
in
2.6,
which
will
be
released
in
12
days,
the
at
least
the
release
candidate.
First,
one
I
want
to
talk
about
Leo
and
Blake
worked
on.
So
if
you
use
create
namespace
sync
option,
there's
now
the
ability
to
add
metadata
to
the
namespaces
that
are
automatically
created,
both
labels
and
annotations.
So
it
ends
up.
Looking
like
this.
This
is
the
test.
I
just
ran.
E
This
namespace
was
automatically
created
by
Argo
CD
and
got
these
labels
added
that
one
was
pretty
fast,
but
a
lot
of
work
went
into
getting
it
done.
The
next
one
is
the
most
requested
feature
for
Argo
CD,
which
is
the
ability
to
use
an
external
values
file
with
an
open
source
Helm
chart,
and
because
that
creates
two
sources
of
Truth.
Now
we
need
to
manage
a
cache
for
two
sources
of
Truth,
so
we
went
ahead
and
expanded
the
feature
to
allow
basically
just
a
list
of
sources
for
an
application.
E
So
let
me
look
at
the
demo
app
app
details
manifest
instead
of
a
source
field,
we
now
have
sources,
which
is
a
list.
I've
got
two.
The
first
one
is
this
example:
app
it
just
can
has
a
deployment
and
a
service.
The
second
is
where
I'm
keeping
my
values
file.
So
right
now,
I've
not
connected
these
two.
So
we
have
deployment
with
one
replica.
One
pod
came
up
for
it
now
I'm
going
to
connect
these
two
using
a
special,
newly
invented
syntax.
E
And
it
looks
like
this
I'm
going
to
reference
that
other
source
and
add
values
rod.yaml,
which
just
happens
to
be
where
I'm
holding
the
values
file
and
that
values
file
is
just
this.
It
bumps
the
replica
count
up
to
do
so.
You're
going
to
see
me
doing
a
bunch
of
hard
refreshes
because
we're
still
working
on
the
caching
logic.
But
ideally
this
would
just
happen
automatically
for
you.
So
now
you
can
see
that
replicas
went
to
two.
So
it's
using
that
other
values.
File
I
can
sync
that
up.
C
E
Second
thing
that
this
buys
us
is,
we
can
just
add
arbitrary,
additional
sources
to
this
list
and
they'll
be
added
to
the
application,
so
I'm
going
to
have
to
use
a
release
name
so
the
so
that
the
names
don't
conflict
but
but
save
this,
and
let's
do
a
hard
refresh.
I
should
see
two
additional
services
and
deployments
added
and
they
are
not
only
can
I
add
additional
resources.
I
can
override
resources.
So
if
the
name
in
this
second
source
of
truth
of
a
resource,
the
name
kind
group,
everything
was
all
the
same.
E
But
I
changed
one
thing
about
it:
the
resource
from
the
Second
Source
would
take
preference
and
override
the
first.
So
if
there's
a
Helm
chart
that
you
just
want
to
change
one
thing
about
now,
you
can
do
that
with
arbitrary
resource
overrides.
So
this
was
I.
Didn't
write
this
code,
Ishita
from
Red
Hat,
wrote
this
so
huge
shout
out
to
her
and
that's
the
demo.
A
A
Okay,
so
it
looks
like
we're
out
of
time
and
I,
don't
think
there
was
any
other
agenda
items
so
we'll
call
it
a
wrap
thanks.
Everyone
for
attending
the
December,
Argo,
City
and
rollouts
community
meeting
and
I
will
see
you
actually
in
two
weeks,
probably
for
the
workflows
meeting
and
then
next
month
for
the
monthly
CD
rollouts
January
meeting
thanks.
Everyone
thanks.