►
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
Hi
everyone
thank
you
for
coming
to
this
month's
community
meeting
for
argo,
workflows
and
events.
My
name
is
henry
glicks,
I'm
one
of
the
product
managers
at
intuit
here
responsible
for
argo
and
before
we
get
started.
While
I
do
a
quick
minute
of
intro
here,
if
you
could,
please
add
yourself
to
the
meeting
notes
that
I
just
posted
in
the
chat
that
would
be
appreciated.
A
So
if
you
want
to
ask
any
questions
during
the
the
presentation,
I
ask
you
to
do
that
in
the
chat
and
I'll
try
and
keep
track
of
that
and
we'll
raise
those
at
appropriate
points
in
the
presentation
later
on.
When
we
do
the
discussion
around
multi-cluster,
then
they
feel
feel
free
to
to
to
unmute
and
voice
your
your
opinions
or
or
comments.
As
we
as
you
go
along,
so
this
is
also
being
recorded.
B
Awesome,
thank
you.
Okay.
You
can
see
my
screen,
I'm
hoping
here.
I
got
it
shared
okay,
we're
good
awesome!
Okay,
thanks
for
having
us
everyone,
it's
cool
to
be
here,
so
my
name
is
corey
jacobson.
I
am
also
here
with
my
colleague,
coway
I'll,
do
kind
of
the
first
half
of
this
presentation
and
he
is
going
to
jump
in
on
kind
of
the
workflow
specific
stuff.
B
B
Okay,
so
just
a
quick
kind
of
background
of
the
company
and
kind
of
where
we
came
from
from
the
github
side
of
things
and
how
we
ended
up
on
argo,
so
seven
shifts
so
we're
up
in
sunny
canada
way
up
north
here
in
the
beautiful
cold.
It's
actually
very
warm
right
now,
which
is
thankful,
but
we
mostly
do
restaurant
scheduling
so
trading
shifts.
B
So
our
infrastructure
is
run
entirely
on
the
google
platform,
primarily
on
kubernetes.
We
have
a
few
stragglers.
The
data
analytics
team
runs
their
own
vms
at
this
point,
so
we're
trying
to
move
them
into
the
clusters
as
well.
So
our
plan
is
to
have
everything
within
kubernetes
just
for
ease
of
management,
hopefully
by
the
end
of
the
year,
which
is
great.
B
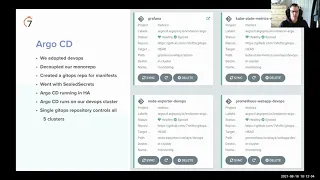
We
have
five
clusters
at
the
moment.
Two
prod
two
staging
and
our
favorite,
the
devops
cluster,
which
runs
everything
from
prometheus
grafana.
All
the
argo
apps.
Everything
like
that
and
the
craziest
part
is
our
app
is
one
giant
monolith,
so
the
actual
seven
shifts
web
app
is
written
in
php,
it's
actually
written
in
cake
php,
which
is
incredibly
old
and
we're
aggressively
trying
to
get
off
that
as
soon
as
we
can
but
yeah.
We
are
a
monolith
which
is
challenging
at
best
and
we'll
kind
of
touch
on
that
as
we
go
through
here.
B
B
B
In
the
beginning,
we
actually
continued
to
use
the
python
and
fabric
scripts
and
just
under
the
hood,
we
called
like
cube
ctl
set
image
or
rollback
or
whatever
we
had
to
do
and
that's
kind
of
how
we
were
managing
our
deploys
at
the
time
there
was
no
get
ups,
we
weren't
tracking
it
other
than
kubernetes
record
feature
on
the
set
image.
So
thankfully,
as
cali
came
on
board,
he's
like,
why
aren't
we
using
argo
cd?
And
so
that's
exactly
what
we
did?
B
We
pulled
all
of
our
kubernetes
manifests
kind
of
out
of
our
like
monolithic,
repo
that
had
everything
set
up,
and
so
we
had
a
proper
get
ops
repo
and
with
that,
that's
the
source,
the
truth
for
argo
cd,
one,
not
problem
that
we
had
is
just
managing
secrets
in
general,
so
we
did
end
up
going
with
sealed
secrets,
we're
still
not
sure
if
that's
the
right
decision
or
not
it's
tedious,
to
work
with
at
best,
especially
with
private
clusters.
It
gives
quite
a
bit
of
problems,
but
so
far
so
good.
B
I
guess
it
is
working.
The
way
it
it's
supposed
to
so
that's
good,
argo
cd
is
set
up
in
high
availability.
Our
devops
cluster
is
quite
crucial
to
running
everything.
Basically,
so
everything
we
can
is
basically
running
in
aj
mode
and
that
single
argo
cd
instance
in
mode,
but
it
controls
all
of
our
other
clusters,
including
its
own
cluster.
So
the
devops
is
all
also
provisioned
with
argo
cd
and
then
we
have
like
marketing
clusters
and
all
of
the
actual
web
app
clusters.
B
Everything
is
controlled
with
this
single
argo
cd
entry
security
around
that
was
pretty
easy.
We
just
kind
of
we
run
everything
behind
like
vpns
and
everything,
so
the
master
authorized
list
in
kubernetes
is
what
we're
using
to
allow
argo,
basically
to
talk
to
all
the
other
clusters
within
our
projects.
B
On
top
of
argo
cd,
we
built
a
kind
of
slack
ops
style
tool
where
developers
basically
kind
of
get
in
line
to
deploy
any
code
or
to
run
deploy
trains,
and
this
is
really
cool.
We
have
argo,
set
up
as
well
to
send
notifications,
basically,
when
we're
either
progressing
or
if
something
is
degraded
state
or
successfully
synced
all
the
way
out.
We
get
these
handy
messages
throughout
on
our
slack
channel.
B
This
has
been
really
important
for
the
devs
to
see
like
when
their
change
is
fully
out,
because
during
peak
is
traffic,
I
don't
know
it
takes
20
ish,
maybe
15
minutes
to
roll
like
an
entire
release
out,
so
they
kind
of
want
to
know.
When
is
everything
out
at
the
end,
so
this
has
been
a
big
help
helper
for
us
just
to
let
the
devs
know
that
yes,
go
double
check
your
change,
because
it
is
completely
rolled
out
at
this
point
behind
the
scenes
for
deployments,
we
just
interact
with
git
itself.
B
We
just
update
our
manifests
and
commit
them
kind
of
behind
the
scenes.
The
devs
don't
really
know
that
that's
happening,
but
it
gives
us
a
really
good
view
of
who's
doing
what
what
got
deployed
when
and
it
also
really
helps
with
rollbacks,
because
again
it's
just
get
commands
to
just
undo.
The
last
commit
basically
push
it
back
out
and
we
don't
worry
about
anything.
I
think
argo's
been
a
game.
Changer
argo
cd,
there
yeah
we
have
about
50
apps.
B
I
think
we're
a
little
better
than
50
individual
apps
on
argo
cd,
but
it
manages
everything
without
a
problem,
and
I
think
I
added
this
one
in
my
personal
favorite
feature
of
argo
cd
is
where
you
can,
click
on
it
and
just
say,
restart
deployment
that
has
saved
us
so
many
times
where
you
know
a
proxy
restarts
and
all
the
connections
are
broken
and
you're
just
like
kick
the
whole
deployment
and
roll
it
over
and
yeah
it's
it's
quicker
than
actually
going
to
the
command
line
so
great
feature.
I
love
that
one.
B
B
B
B
B
So
we
basically
built
an
auto-scaling
kubernetes
cluster,
where
github
actions
would
run
on
it
and
we
would
basically
monitor
github
actions
and
spin
up
and
down,
depending
on
what
our
devs
were
doing,
what
the
pull
requests
were
doing
and
stuff
like
that,
so
it
gave
us,
you
know
a
chance
to
save
money
and
kind
of
really
understand
what
our
workflows
should
look
like.
So
from
that
aspect
it
was
really
good
because
we
really
learned
a
lot
about
our
systems
and
how
best
to
make
them
performance,
especially
in
a
test
environment,
github
actions.
B
So
this
was
last
year
or
this
spring,
even
no.
It
was
before
this
spring.
It
was
when
github
actions
was
a
bit
immature
and
they
had
a
lot
of
outages.
A
lot
of
problems
where,
like
workflows,
would
get
stuck
and
like
you
couldn't
deal
with
them
or
get
them
out
of
your
your
queue
or
anything
like
that.
So
it
was
fairly
problematic
and
we
spent
a
lot
of
time
during
the
day
kind
of
like
unclogging,
the
pipes
and
stuff
like
that.
B
B
The
monolith
man
can't
get
away
from
that
gitlab
there's
the
isolution
looked
really
good,
but
we
weren't
ready
to
commit
to
gitlab
we're
entirely
on
github
at
the
moment
and
all
of
our
dubs
like
we're
pretty
deeply
ingrained
with
github
and
all
the
features
and
different
teams
across
it
and
stuff.
So
we
felt
as
the
organization
we
weren't
ready
to
move
get
providers,
so
we
kind
of
kibosh
the
gitlab
we
did
install
jenkins.
B
It
was
okay
on
the
kubernetes
cluster,
it
ran
and
everything
I
think
we
found
that
we
were
programming
more
groovy
than
we
ever
would
have
liked
to
kind
of
accomplish
what
we
wanted
to
do.
So
again
it
just
wasn't
the
greatest
the
devs
weren't,
a
fan
of
jenkins.
I
don't
know
it
just
has
a
bad
name.
I
guess
at
this
point
in
the
industry.
So
wasn't
the
best.
So
since
we
were
using
our
ocd,
we
decided
to
look
at
workflows.
B
We
had
kind
of
followed
it
when
it
was
released
and
looked
into
a
bit,
and
once
we
looked
at
how
to
configure
the
graphs
in
yaml
and
like
how
we
could
template
that
out.
I
think
that
was
the
light
bulb
moment
for
us
when
we
realized
that
we
could
really
like
utilize
templates
quite
strongly
and
huge
credit
to
cali
for
this,
it's
all
of
our
different
node
pools
and
what
everything
runs
on
like
it's
all,
really
really
well
done,
with
just
different
templates
to
the
point
where
we
have
a.
B
I
don't
even
know
what
he's
called
a
qa
engineer.
I
guess
where
he's
not
super
technical,
he
doesn't
have
kubernetes
training,
but
he's
at
the
point
where
he
can
go.
Look
at
yaml
and
just
be
like.
Oh
this.
This
graph
has
to
do
this.
This
test
has
to
go
over
here
kind
of
thing
and
it
really
kind
of
freed
our
time
up
as
well.
So
we
we
really
like
that
and
we
kind
of
didn't
look
back
after
we've
been
on
that
so
far.
B
We
do
you
utilize
argo
events
as
well
to
basically
kick
off
all
of
our
workflows,
so
we
have
several
github
hooks
that
just
send
the
different
payloads
into
argo
events
and
from
there
we
have
some
some
good
filters
and
what
we
need
to
pull
out
of
the
the
json
objects,
basically
like
the
git
sha
and
the
the
pr
number
who
the
author
is
and
that
kind
of
stuff.
So
events
have
been
really
good
for
us.
We
use
it
to
build
a
lot
of
supporting
docker
images
as
well.
B
So
we
have
a
lot
of
apps
just
within
the
cluster
that
kind
of
support
the
monolith,
different
proxies
and
cron
services
and
this
stuff.
So
basically
we
just
tag
them
in
git,
and
now
we
have
everything
automated
to
the
point
where
it
just
fires
the
event
to
argo,
and
it
knows
to
build
the
docker
image
and
it
knows
where
to
push
it
all
based
on
the
the
github
path
and
everything.
So
that's
again
huge
time
saver
for
us,
you
just
tag
it.
You
wait
a
couple
minutes
and
boom.
C
C
Each
workflow
has
31
workflows,
which
means,
basically,
we
are
using
something
similar
to
the
github
flow,
so
where
you
basically
have
the
main
branch
or
your
master
branch,
the
you
create
your
featured
rents
and
merge
it
back
into
the
master.
So
we
do
not
have
release
brands
or
brands
that
represent
environments.
C
Everything
that
we
do
and
work
known
is
based
on
prs
as
soon
as
your
dev
creates
a
pr
argo
events,
kick
it
off
and
start
creating
workflows
for
us.
If
you
push
something
new,
we
try
to
delete,
it
will
be
another
workflow
if
it
was
running
perfectly
and
we
create
a
new
one.
That's
one
way
to
save
a
little
bit
of
resources
because
we
create
like
tons
of
workflows
in
a
busy
day,
and
this
is
how
we
are
doing
so
in
a
big
day,
we
have
like
8
000
workflows.
C
C
In
the
last
july
month
we
have
70
000
workflows,
so
we
extract
those
numbers
from
the
database
that
we
have.
We
constantly
clean
up
the
objects
inside
of
the
cluster.
I'm
gonna
talk
about
a
bit
later,
but
we
delete
everything.
So
we
use
the
database
to
reduce
those
numbers
and
share
it
with
all
of
you,
so
yeah.
We
do
consider
that
we
are
running
at
a
was
it
really
scale
off
workflows
daily?
C
C
C
I
will
take
a
look
at
it,
but
this
is
how
we
are
doing
right
now
when
you
decide
to
run
the
massive
number
of
workflows,
as
we
are
doing,
there's
a
few
configurations
that
might
want
to
take
a
look
on
the
controller
config
map,
so
one
of
them
is
the
parallelist
where
you
can
configure
the
maximum
number
of
congruent
workflows
that
can
run
at
the
same
time.
So
this
is
pretty
neat.
We
did
not
freeze
problems
with
that.
C
So
far,
only
when
we
had
github
outages
and
they
decided
to
send
all
the
events
again,
but
this
is
we
can
circumvent
that
in
another
way,
but
this
attribute
is
pretty
cool.
Another
good
way
to
keep
your
cluster
running
smoothly
is
of
loading
everything
that
you
can
so
we
set
it
up
a
database
to
archive
for
workflows.
When
we
create
a
workflow,
we
already
use
a
label
to
send
the
workflows
to
the
database.
C
This
is
how
we
know
we
have
a
job
to
run
hourly
and
delete
everything,
so
we
do
not
keep
with
old
stuff
starting
the
cluster,
because
we
are
creating
a
lot
of
workflows
every
time,
so
we
try
to
keep
it
clean
as
possible.
So
we
use
the
garbage
collector
from
paws
to
delete
everything
that
we
can
and
also
delete,
workflows
every
hour.
D
C
So
when
we
start
working
with
artworkflows,
as
you
can
see
sorry
about
the
quality
of
the
picture,
but
I
we
think
this
represents
like
quite
well
what
we
try
to
do.
We
had
like
a
giant
ci
ammo
file
where
we
tried
to
create
the
whole
ci
inside
of
one
single
email
file.
We
still
were
using
the
templates,
but
there
are
so
many
steps
that
we
have
to
handle
inside
of
it.
That
was
super
hard
to
manage
and
keep
track
of
the
chains.
C
C
Yes,
the
monolith
causes
a
lot
of
frustration.
Yes,
so
we
also
have
small
webs
running,
which
is
like
super
pretty
straightforward,
or
you
can
just
film
the
ripple
dude.
Everything
that
we
need
tests
is
a
small
runs
nice,
but
then
on
the
left,
we
have
to
decouple
and
create
like
a
lot
of
side
cars
every
single
time
that
we
need
to
run
the
test,
for
example,
so
this
becomes
like
super
complex
to
manage
all
the
components
and
all
the
tests
every
single
time.
C
C
C
C
Okay,
so
one
of
the
features
that
we
use
it
to
make
it
easier
and
more
manageable
was
using
the
workflow
of
workflows
pattern,
which
basically
means
you
have
a
parent
workflow
which
will
create
child
workflows
and
we'll
manage
them
for
you,
capturing
output,
results
and
make
it
easy
to
visualize
it.
So
when
we
create
a
workflow,
this
is
when
you
create
a
pr
here
at
some
issues.
This
is
what
you
can
expect
to
see
in
the
ui,
so
we
try
to
delete
the
workflows
and
then
we
start
running
the
tests,
everything
in
parallel.
C
If
we
compare
with
the
other
tools,
especially
jenkins,
so
when
we
try
to
do
like
the
same
thing
with
jks,
I
have
like
different
problems
with
connections
with
java
or
something
like
this,
sometimes
because
we
are
creating
like
tons
of
spots
every
single
time,
and
this
was
something
that
I
really
liked
about
our
workflows
itself.
It's
super.
It's
not
super.
I
think
we
don't
have
any
problems
like
trying
to
create
objects
inside
of
the
cluster
just
work,
which
is
great.
C
We
also
try
to
make
it
easier
for
someone
who
does
not
have
the
expertise
and
kubernetes,
because
all
the
templates
are
truly
concentrated
on
focus
on
the
kubernetes
perspective,
even
the
names
which
is
great,
but
sometimes
it's
harder
for
someone
who
does
not
understand-
and
we
try
to
create
this
logic
of
template,
trying
to
move
everything
that
we
use
inside
of
the
template
to
parameters.
So
you
can
basically
define
every
single
attribute
inside
of
the
base.
Template
just
inform
the
items
on
the
parameters
or
inside
of
the
if
with
items.
C
C
C
Just
using
the
items
you
don't
need
to
go
into
the
base
template
whatsoever,
which
was
super
cool
like
story,
yes,
sidecars,
as
we
explained
before
every
single
time
that
we
need
to
speed
up
the
monolith,
we
need
at
least
like
redis
nginx
mysql,
like
any
other
different
tools,
running
at
the
same
time
for
each
workflow,
which
makes
which
is
super
complicated.
Sometimes
so
we
are
using
wide
side
cars
from
the
workflows
in
a
way
that
we
found
to
speed
up.
C
Everything
for
us
was
using
the
in-memory
attribute,
so
you
can
see
that
we
are
mounting
a
volume
empty
gear,
medium
memory,
so
this
is
super
cool
if
you
never
use
it
yeah.
I
strongly
encourage
you
to
try
that.
Yes,
you
need
more
memory
in
your
machines
to
do
it,
but
it's
quite
faster.
So
we
decided
to
have
like
bigger
machines
with
more
memory
and
run
everything
in
memory.
C
We
saved
a
lot
of
time
with
our
new
pipelines,
everything
we
are
trying
to
mount
everything
that
we
can
in
memory,
even
the
most
sequel
data
to
run
migrations.
Everything
it
makes
super
fast
mirror
volume
is
another
super
cool
attribute.
Where
argo
will
mirror
for
you,
the
volumes
inside
of
the
main
container,
so
the
main
container
will
ship
will
see
the
same
paths
that
you
mount
from
the
side
cars.
So
if
you
have
like
an
engine
x
or
a
redis
or
a
messico,
you
will
be
able
to
see
instead
of
your
main
container.
C
Another
thing
that
we
learned
key
os
guarantee
so
kubernetes
has
different
quality
of
services
classes
and
we
decided
to
go
everything
with
guaranteed.
So
if,
for
some
reason
the
scheduler
put
too
much
spots
into
one
single
node
more
than
it
should
it
will
not
have
resources
to
handle
with
it
later.
When
it's
in
the
end
of
the
build,
your
workflow
will
retry
again,
it
will
fail
because
of
out
of
memory
of
the
node
or
something
like
this.
C
So
we
try
to
use
the
same
values
for
memory
and
cpu
and
they
are
fully
isolated,
so
they
usually
are
not
usually,
but
almost
always
are
not
concealed
by
resources.
So
we
can
have
an
ensure
that
the
execution
will
be
fulfilled
in
the
same
node
when
it
started
and
will
not
be
deleted
because
we
don't
have
like
enough
memory.
This
was
a
nice
way
to
overcome
that
and
we
also
run
everything
on
printable
nodes,
so
the
burstable
nodes
doesn't
exist
at
all.
C
So
if
no
one
is
building
anything,
they
just
will
be
escalated
to
zero,
and
if
we
need
we
can
scale
back
again,
but
it
doesn't
exist.
We
basically
warm
up
the
nose
in
the
morning
and
we
down
scale
the
end
date
of
the
day
and
yeah.
This
was
a
nice
way
to
save
like
a
lot
of
money,
so
we
basically
keep
with
the
cluster
scale
like
for
eight
or
nine
hours,
usually
the
time
that
the
devs
needs,
because
here
in
canada,
where
we
live,
the
time
zone
is
quite
a
little
bit
different.
C
But
this
is
give
them
time
enough
to
build
and
do
everything
that
they
need
and
if
they
need
to
run
something
out
of
sight
of
the
time
they
will
still
be
able
to
do.
It
just
have
to
wait
a
little
bit
more
into
the
google
skill
machines
for
them
next
story
cost
savings.
Yes,
I
told
you
we
are
running
everything
that
is
on
large
and
only
small
pool
is
running
on
printable
mobiles.
C
The
only
thing
that
is
a
static
post
is
the
main
opto.
So
our
goal
workflows
controller,
our
ocd
notifications,
any
other
apps
that
we
have.
They
run
on
the
stack
notebook.
So
we
try
to
not
be
restarting
them.
We
want
to
make
sure
that
we
keep
running
24
hours
per
seven
and
we
are
not
restarting
it,
but
all
the
others
will
be
on
the
principles
which
is
much
cheaper
than
the
static
pools.
C
What
you
see
strategy.
So,
yes,
we
try
to
delete
everything
and
not
keep
with
the
objects
ringing
around
inside
of
the
nodes.
So
this
was
super
cool.
The
logs.
We
just
have
a
bucket
where
we
set
it
up
for
the
controller
config
map
and
the
logs
are
written
into
a
file
inside
of
the
button.
So
every
time
that
we
finish
a
build
process,
we
reading
a
file
and
then
redirect
the
devs
to
the
proper
link
into
the
bucket.
C
C
Inside
of
the
cluster,
we
have
chrome
jobs.
So
argo
has
the
chrome,
workflow
jobs
for
you,
where
you
can
easily
set
up
a
chrome
workflow
to
do
something
for
you
and
we
use
these
those
froms
to
scale
up
and
down
the
clusters
doing
their
warm
up
for
us
to
forge
the
workflows
and
anything
related
to
some
recurrence.
We
use
the
chrome,
workflows.
C
Feedbacks
for
the
devs.
I
think
this
is
one
of
the
most
important
things
and
cool
that
we
did
so
we
I
think
we
tried
we
have
to
try
and
take
advantage
of
these
handlers
and
workflow
templates
where
you
can
use
the
notifications,
so
we
are
using
commit
status
from
github
for
everything,
so
each
single
view
the
step
that
we
do
test
everything
we
create
a
commit
status
related,
so
the
dev
doesn't
need
to
go
inside
of
the
artwork
flow,
ui
and
search
for
anything.
We
just
read
the
create
a
link
into
the
details.
C
If
you
did
that
raising
the
details,
you
will
be
redirected
to
the
proper
well,
which
is
cool,
sometimes
can
be
complicated
when
you
work
like
with
tons
of
workflows,
if
you
try
to
go
over
the
main
screen
and
filter
everything,
there's
a
lot
going
on
there.
So
this
was
a
nice
way
to
keep
them.
You
know
like
more
focused
and
keep
track
of
the
things
that
we
are
measuring.
C
Maybe
we
are
also
emitting
metrics
into
the
permissions,
so
our
workflows
can
create
metrics
for
you
inside
of
the
workflow,
so
you
can
easily
populate
fields
inside
of
the
prometheus
and
create
your
own
views
on
grafana.
So
this
is
exactly
what
we
are
doing.
We
know
how
many
prs
we
open
it,
who
open
and
who
a
bit
more
and
less
how
many
subs
and
failures-
and
we
are
using
those
metrics
inside
of
seven
shifts,
something
that
we
learned
have
to
be
careful
about
the
github
outages.
C
When
we
had
a
problem,
they
usually
flow
the
us
with
events
later,
as
happened
last
week,
so
try
to
filter
as
much
as
you
can
to
not
receive
events
that
you
don't
want
to
process.
This
can
be
overwhelming
and
you're
going
to
scale
up
your
cluster
like
a
lot
in
our
case,
because
we
have
like
tons
of
machines
that
can
go
out
and
we
reach
the
maximum
numbers
last
week,
and
this
is
not
great
so
try
to
create
some
filter
based
on
date
or
something
yeah.
C
C
What
do
we
do
to
test
our
workflows
when
we
are
creating
something
new?
We
have
another
automation
that
we
created.
We
created
our
google
workflow
sandbox,
which
will
spin
up
everything
using
guide,
installed
our
boo
and
pull
the
templates
inside
of
it,
and
then
you
can
test
it
and
create
everything.
This
is
how
we
are
managing
and
testing
everything
before
we
open
up
vr
and
ask
for
any
change
into
the
environment.
A
C
Question
so
this
is
home,
so
all
right,
oh
okay,
so
for
the
ci
part,
I
think
the
one
thing
is
more
about
the
you're
doing
the
darker
build
one
big
challenge
normally
is
like
you
build
darker
image.
You
always
start
from
scratch.
Like
in
your
presentation.
Do
you
see
any
performance
issue?
I
know
you
are
using
the
the
memory.
Fs
actually
will
help
speed
up
a
lot,
but
do
you
have
this
like
want
to
reuse
the
pre
cache
the
darker
image
layer
to
speed
up
things?
More
so
have
you
think
about
that?
B
C
You
are
not
caching
the
layers
from
the
docker.
You
are
caching
more
about
your
dependency
to
making
building
that
layer
to
be
very
fast.
Okay,
I
have
another
question
you
mentioned.
You
are
using
the
events
workflow
to
do
the
ci
using
roc
to
deploy
everything.
That
means,
even
for
all
the
sensor
configuration
workflow
template.
Those
things
is
also
being
checked
in
into
the
repository
basically
you're,
using
rgo
cd
to
sync
everything
single
cluster
every
time.
Yes,
okay,
impressive!
Thank
you
very
great
job.
A
C
Yes,
we
don't.
Actually
we
don't
need
these.
Those
events
for
like
anything
at
all.
I
just
need
to
know
if
they
work
for
society
or
not
succeed,
and
this
can
be
captured
from
the
workflow
itself,
which
means
if
the
workflow
flail
they
definitely
need
to
go.
Look
at
the
test
that
failed
or
something
else
and
understand
deed
is
stalker
in
docker
and
that's
it.
So
I
don't.
We
don't
feel
like
the
necessity
of
the
mini
events
for
anything
and
the
with
the
amount
of
workflows
that
we
create.
C
A
C
C
Yeah,
so
we
are
using
the
bns
executor
and
we
what
we
do
have
is
we
have
like
the
themes
in
the
docker
gmo
side
of
the
cluster,
so
this
was
the.
Can
you
go
back
to
that
image,
curry
that
we?
What
I
explained
about
the
thing
and
you
basically
will
have
like
a
one
ephemeral,
no
go
ahead.
A
little
bit.
C
A
Excellent,
thank
you.
Thank
you
so
much.
I
think
we
have
two
more
topics
on
the
agenda,
so
I
think
maybe,
if
there
are
more
questions,
maybe
we
can
do
those
on
either
on
the
chat
here
or
on
slack.
So
I
want
to
make
sure
we
have
time
for
obama
and
alex
here
as
well.
So
thank
you
so
much
excellent
presentation.
A
D
A
D
So
I'm
going
to
talk
about
what
are
the
new
features
going
to
come
in
the
upcoming
release?
3.2
since
three
dot
argo
3.
3.1?
We
are
mainly
focusing
on
the
optimizing,
the
resource,
optimization,
the
cost
and
all
the
things.
If
we
know
that
in
the
3.1
we
introduced
container
set
and
data
template
to
avoid
creating
a
more
power
for
the
simple
steps,
the
same
same
agenda
was
following
to
the
3.2
here.
Also,
we
are
optimizing
optimizing
for
http
task,
as
well
as
like
reducing
the
the
workflow
resource
size.
D
So
there's
a
two
features
coming
into
the
3.2,
mainly
like
a
http
template
with
the
agent
architecture.
The
second
one
is
inline
template.
Let
me
explain
that
http
template
http
template
is
mainly
for
forming
that
http
request.
The
http
request
is
like
a
lightweight
request,
but
in
the
previous
version
we
nee.
We
need
to
create
a
pod
to
execute
the
http
request,
but
in
the
3.2
it
will
create
a
single
part,
and
it
will
execute
that
all
the
http
steps
in
that
workflow.
D
D
D
D
D
A
E
So
our
top
rated
issue
in
github
for
argo
workflows
is
multi-cluster.
I
think
it
has
around
I'd
have
to
check
70
thumbs
up
making
it.
You
know
you
know
two
or
three
times
more
popular
than
any
other
issue
in
github.
We
do
tend
to
use
the
number
of
thumbs
up
the
issues
and
bugs
get
as
as
probably
the
main
way.
One
of
the
main
ways,
certainly
that
we
prioritize
work,
if
not
the
main
way,
that
we
prioritize
work
and
kind
of
drive
our
road
map.
E
With
multi-cluster,
I
think
we're
hearing
a
lot
more
about
that
from
people
in
the
community
and
also
I
see
a
lot
of
talks
at
kucon
related
to
multi-cluster
management,
but
we
haven't
really
been
able
to
satisfactorily
make
sure
that
we
understand
what
multi-cluster
means
to
people.
So
I
really
wanted
to
open
up
the
floor
for
people
to
talk
about
the
the
kind
of
situations
where
they
might
want
to.
E
You
know
really
for
people
who
are
running
in
multi-cluster
environments,
the
kind
of
problems
that
they
find
when
running
in
multi-cluster
that
they
want
to
solve,
and
just
I
wanted
to
open
up
that
in
the
room.
I
know
we've
got
people
from
pipekit
here
who
I've
spoken
to
briefly
about
this
before
so
I
hope
we
can
just
have
an
open
discussion.
Anybody
can
just
chime
in
and
add
anything
they
want
to
say
about
this.
A
Do
you
want
to
do
a
quick,
just
a
high
high
level
description,
maybe
alex
of
what
we,
what
we
mean
with
multi-cluster,
just
to
have
the
same,
the
same
framework
and
reference,
because
there
are
a
lot.
I
know
there
are
a
lot
of
different
views
on
what
it
is
and
what
it
means.
Maybe
just
want
to
give
a
you
know
some
a
little
context
on
that
sure.
E
What
I'll
do
is?
I
have
a
document
here
where
I
record
the
three
three
visions
of
multi-cluster
and
they're
kind
of
broadly,
in
summary,
a
workflow
where
the
pods
of
the
workflow
run
in
different
clusters
or
different
and
also
different
name
spaces.
Typically,
because,
as
soon
as
you
go
multi-cluster
you
have
to
deal
with
multi-tenancy
and
often
you
might
not
have
the
name.
Space
have
the
same
name
in
two
clusters,
so
a
multicast
workflow
is
it's
by
implication.
E
E
The
second
vision
is
a
multi-cluster
user
interface
or
control,
plane
or
multi-cluster
api
I.e.
The
idea
I
can
go
to
a
single,
an
end
point,
api,
endpoint,
single
user
interface
and
all
my
workflows
in
multiple
clusters
are
displayed
in
there
and
they
are
multiplexed
into
the
same
view
for
me
to
look
at
it
and
then
the
third
one
is
really
an
operationals
one,
a
multi-cluster
controller.
E
So
rather
than
deploying
one
workflow
controller
per
namespace
or
one
workflow
controller
per
per
cluster,
you
can
deploy
a
single
workflow
controller
that
actually
runs
all
the
workflows
in
multiple
clusters.
The
main
benefit
that
is
really
not
necessarily
about
cost
reduction,
which
you
might
think
it
might
be
one
of
the
main
benefits,
but
actually
about
simplifying
operations.
C
C
G
E
E
E
They
have
different
understandings
interpretations
of
it
different
use
cases
they
want
to
solve.
So
it's
quite
kind
of
it's
quite
a
varied
area.
There's
just
a
lot
going
on.
In
my,
I
think
when
people
talk
multi-cluster,
it's
just
a
really
huge
topic
and
you
end
up
going
into
lots
of
things
like
multi-tenancy
and
so
forth.
E
F
Which
is
why
I
think
the
working
group
would
be
important
for
at
least
establishing
that
shared
understanding
of
what
multi-cluster
will
mean
for
workflows,
and
it's
hard
to
proceed
with
this
until
we
have
that
shared
understanding,
yeah
hoping
that
we'd
get
more
folks
that
want
this
feature
in
this
meeting
to
kind
of.
But
it
looks
like
maybe
this
time
didn't
work.
Yes
sure
sure,
okay,.
A
Thanks
alex,
I
think
we
have
a
couple
of
minutes
left,
but
I
want
to
thank
everyone
for
for
joining
joining
this
month.
We'll
have
our
next
one
in
early
october
and
if
we're
always
looking
for
presenters.
So
if
anyone
has
an
interesting
use
case
or
if
you
want
to
share
something
similar
to
what
we
heard
earlier
today
about
how
you're
using
argo
workflows
at
your
company
or
if
you
want
to
show
up
something
else,
cool
you
did
with
argo
workflow,
then
please
reach
out
on
slack.
A
I
think
I'll
just
need
30
more
seconds
and
I'll
open
up
for
more
questions.
Yes,
we've
also
had
some.
Some
of
our
users
do
blog
posts
in
the
past.
If
I
don't
want
to
do
a
blog
post
and
you
want
to
do
that
instead
of
presenting,
you
can
also
reach
out
to
us
and
we'll
we'll
help,
you
help
you
review,
maybe
even
co-author,
if
you
feel
more
interested
in
that,
so
please
reach
out.
A
If
you
have
anything
to
share
and
and
we'll
do
what
we
can
to
to
accommodate
you
in
whatever
medium
you
feel
the
more
comfortable
in.
So
I
think
we
have
with
that.
I
think
we
have
a
couple
of
minutes
left.
So
all
it
sounds
like
there.
What
might
be
some
more
more
questions
for
seven
shifts,
so
I'll
open,
open
up
the
floor
again
here
for
any
any
additional
questions.
C
Great
great
question,
I
would
say
firmly
curry
can
correct
if
I'm
wrong,
but
the
ui
itself.
We
tried
to
do
like
a
lot
of
stuff
to
overcome
a
few
white
challenges
that
we
have,
and
this
is
the
you
know
like
the
most
complaints
about
that
we
have
instead
of
the
company.
What
do
you
think
about
the
argo
cd
micro
workflow
itself
is
sustaining
you,
so
they
mostly
complain
about
the
white
it's
hard
to
search
it's
hard
to
find
what
they
need
that.
C
I
honestly,
I
don't
know
if
I
totally
agree
with
it,
but
I
do
understand
you
know
like.
Sometimes
they
just
won't,
they
just
want
to
see
the
log.
They
just
want
to
know
what
is
wrong,
but
yeah.
I
will
start
with
the
ui
itself
and
later
on.
I
would
like
to
have
more
beauty
mechanisms,
so,
for
example,
if
you
could
create
like
plugins
or
something
and
tie
these
plugins
into
their
overflows,
to
simplify
the
animals
and
do
not
have
to
be
create
these
animals
every
single
time.
F
A
Okay,
thanks
jesse
yeah,
thanks
for
the
reminder
alex.
I
also
wanted
to
highlight
that
we
have
our
very
first
inaugural
argo
con
coming
up
here
in
december,
and
the
cfp
is
open,
I'll
post
the
link
here
in
the
chat,
but
there
should
be
a
link
from
from
the
website
as
well.
So
if
you,
if
you
have
a
presentation
that
you
want
to
present
at
argo
con,
it
will
be
a
one-day
event.
A
We're
hoping
we'll
be
able
to
do
a
hybrid
in
person
in
virtual,
but
if
you're
remote
and
not
able
to
travel
to
the
bay
area,
then
we
will
definitely
have
virtual
options
both
to
present
and
attend.
So
please
go
register.
Please
submit
your
cfps
and
we'll
get
back
and
publish
some
some
speakers
and
some
agenda
here
here
shortly.