►
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
We've
got
a
community
talk
that
I'm
sharing
on
the
screen
now,
so
I'm
just
it
would
be
fantastic
if
we
could
have
anybody
who's
here,
add
yourself
as
an
attendee
today,
so
we
just
know
who's
coming
to
the
meeting
I'll
just
start
a
section
there
for
people
to
add
themselves
and
for
those
of
you
who
are
new
to
argo,
workflows
and
events.
Just
a
little
bit
of
background.
A
Argo
workflows
is
a
cloud
native
system
for
executing
workflows,
it's
very
popular
for
machine
learning
and
also
kind
of
popular
within
some
of
the
ci
community.
As
well
and
argo
events
is
it's
just
a
triggering
events
in
your
clouds
using
the
cloud
event
specifications
so
things,
for
example,
triggering
a
workflow.
If
it's,
if
a
file
has
appeared
in
s3,
my
name's
alex
I'm
the
principal
engineer,
working
on
argo
workflows
and
from
our
core
team
today,
we've
also
got
derrick.
A
Now,
if
you
want
to
ask
any
questions
during
today,
you
can
ask
those
questions
in
the
zoom
chat
or
you
can
come
and
ask
us
in
the
slack
channel
afterwards
or
you.
There
will
be
opportunities
during
the
course
of
today
to
just
ask
questions
as
we
go
along
and
you
can
just
ask
those
questions
out
out
aloud.
If
the
answer
is
going
to
be
quite
long
or
it's
going
to
require
a
follow-up.
Well,
you
know
we'll
potentially
discuss
that
with
you
in
slack.
A
So
the
first
thing
for
today
this
this
agenda's,
not
in
the
correct
order,
but
that's
fine
derek-
has
been
working
on
some
kind
of
important
changes
to
argo
events
around
things,
such
as
the
gateways
sensors
in
a
goal
to
kind
of
simplify
and
make
it
easier
for
to
use,
as
well
as
a
couple
of
security
aspects
and
he's
going
to
talk
a
bit
about
those
today.
So
derek.
Can
I
hand
over
to
you.
B
B
Let's
say
you
don't
need
to
give
a
lot
of
details
on
the
gateway,
spec
and
sensor
spec,
and
this
kind
of
things
all
these
things
just
make.
I
want
to
make
it
easy
to
use
today.
I
want
to
give
a
heads
up
about
what
kind
of
chance
we're
going
to
do
in
future.
All
this
change.
The
purpose
is
just
want
to
make
arguments
easy
to
use
reliable
and
production
level
product.
B
B
B
Let
me
go
to
the
proposal.
So
first
thing
we're
gonna,
do
is
we're
gonna
merge
the
gateway
object
to
given
source.
So
right
now
we
have
three
crds
in
arguments,
gateway,
sensor
and
even
source
and
after
the
simplification
gateway,
and
they
you
you'll,
see
that
there's
almost
nothing
left
in
gateway
objects.
So
that's
the
reason
you
want
to
merge
a
gateway
to
event
store
and
then
later
you
only
need
to
give
all
your
events
related
definitions
in
event,
source,
spec
and
then
there's
no
getting
at
all.
B
So
that's
the
first
thing
we
want
to
do
next.
Next,
one
is,
if
you
look
at
the
current
architecture,
there
are
some
some
things,
not
in
good
design.
Let's
say
the
so
right
now.
If
you
run
your
getaway
or
sensor,
you
need
to
have
a
service
account
with
some
rbac
settings
to
make
it
work.
Even
your
your
email
source
is
the
webhook
type
event
source
which
doesn't
need
to
access
kubernetes
cluster.
You
also
need
the
server
scanner.
For
that
a
sensor
is
the
same
thing.
B
If
you
only
want
to
trigger
a
http
endpoint,
you
also
need
a
service
account
to
do
that,
and
that
service
can
need
to
have
some
permissions
to
listen
to
event,
source
gateway
and
sensor.
That's
not,
you
know,
that's
inconvenient
for
the
user
and
this
it's
not
secure.
So
the
second
and
third
thing
we're
going
to
do
is
to
rewriting
the
the
controller
for
new
merged
demon
source
and
then
in
the
sensor,
so
that
you
don't
need
to
have
a
subscribe
like
that.
B
Your
your
sensor
only
relies
only
relies
on
the
even
source,
there's
no
gateway,
and
we
want
to
introduce
a
new
crd,
nand
event.
Bus
and
this
even
bus
is
used
to
represent
a
pop
sub
system
in
the
back
end.
So
right
now
for
argo
events,
if
you
want
your
events
to
get
delivered
from
gateway
to
the
sensor,
there's
there
are
two
ways
to
do
it.
B
B
B
B
B
You
also
can
give
you
know
an
s,
even
bus
with
a
preferred
configuration.
Let's
say
you
already
have
enough
service
running
somewhere
and
they
want
to
use
the
existing
net
service.
So
we
also
support
that.
These
are
the
major
changes
we
want
to
want
to
do
in
the
future.
And
then
we
have
the
proposals
document
linked
in
the
community
doc
and
if
you
have
any
comments,
any
suggestions,
please
read
and
do
that
and
we
are
hearing.
A
Okay,
thank
you.
Thank
you,
derek
for
that,
so
we're
currently
still
waiting
for
viper
to
to
appear
I'm
not
exactly
sure
where
he's
got
to,
but
but
fortunately
we
also
have
summit
miguel
who's
a
performance
engineer
into
it
here
and
he
is
going
to
talk
a
bit
about
how
they
use
argo
workflows
for
site,
reliability,
engineering
and
performance
testing
so
summer.
If
you're,
if
you're
ready,
do
you
want
to
take
it
away.
E
Sure
sure,
thanks
a
lot
alex
so
before
I
jump
in
just
wanted
to
give
a
little
bit
background,
we
do
a
reliability
engineering
for
the
intuit,
which
is
providing
support
for
our
entry
kubernetes
service,
and
as
part
of
that,
we
have
built
something
which
we
thought
would
worthwhile
to
share
with
the
community,
and
this
specific
talk
briefly
talk
about
that.
This
is
just
a
brush
up,
but
we
can
go
deep
dive
if
the
community
has
the
interest.
So
what
it
is.
E
We
have
seen
that
running
the
performance
test
for
specifically
performance
scale
and
longevity
require
a
lot
of
time
and
it
cannot
be
part
of
your
pipeline.
That's
the
first
part.
We
don't
have
any
native
kubernetes
support
available
in
that
we
you
have
loadrunner,
you
have
gatling
your
frontline.
There
are
many
things,
but
there
is
nothing
is
available
on
the
kubernetes
space,
most
of
the
tooling.
What
we
have
we
have
seen.
They
are
not
supporting
the
container.
E
They
are
mainly
on
that
you
get
or
whichever
your
version
control
and
get
that
attaching
that
using
argo,
cd
and
jenkins
is
also
one
of
the
challenge
we
have
is
so
what
we
have
used
is
something
called
argo,
workflow
and
workflow
has
a
very
niche
way
how
you
can
orchestrate
a
different
kind
of
sequence,
and
we
use
that.
One
of
the
other
thing
why
we
opted
for
ergo
is
that
most
of
the
performance
tooling
or
performance
infra,
they
have
a
good
amount
of
licensing
cost.
E
Just
to
give
example,
frontline
will
cost
a
yearly
80k
for
running
the
license.
Now,
ergo
workflow
doesn't
cost
it's
open.
Sources
are
free,
so
that's
a
other
thing
and
then
it
can
buy
attach
to
the
actual
reporting
of
a
specific
technology,
and
it
is
agnostic
with
the
aws
and
it
can
support
any
of
the
technology
like
a
gatling,
geometer
and
karate,
and
the
reason
that
one
is
important
most
of
the
conventional
tool.
E
If
you
take
a
load
runner,
if
you
take
a
front
line,
they
are
attached
to
a
technology
either
someone
is
attached
to
geometer
either
someone
is
attached
to
scala
so
right
now
we
don't
have
a
mechanism,
one
cohesive
way,
that
any
any
specific
tools
support
most
of
the
technology
and
performance
testing
in
last
decade
has
changed
significantly
every
two
or
three
years
there
is
a
new
technology
come
it
was
prominently
dominated
by
geometer,
and
now
the
scala
has
bring
the
gatling.
You
never
know
tomorrow.
E
What
will
be
there
and
now
the
if
the
team
or
company
is
spending
that
much
it
would
be
very,
very
challenging
for
them
to
attach
to
the
same
technology
to
support
the
real
new
tech
stack.
So
what
we
have
come
up
and
this
team,
because
we
work
very
closely
with
the
jc
baba
initially,
when
we
started
that
we
did
a
small
poc
that
how
we
can
use
ergo,
workflow
for
doing
performance
testing
and
creating
an
infrastructure
which
is
scalable,
self-service
and
kubernetes
native.
E
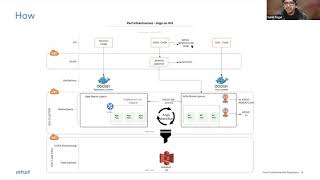
So
what
we
have
actually
done
is
that
we
have.
This
is
us
the
same
way
how
any
service
is
being
deployed.
You
have
a
git
code,
you
build
and
you
create
a
container
artifact,
which
is
a
docker
now.
What
we
have
done
is
that
we
have
started
adding
a
test
code
and
we
started
creating
a
container
out
of
the
test
code.
E
Now,
once
you
have
that
container
out
of
this
code,
we
use
argo,
workflow,
yaml
and
use
this
specific
container
and
orchestrate
through
jenkins
file
as
part
of
the
setup
we
have
created
for
all
our
cluster.
There
is
a
specific
name
space
we
calling
as
a
perfloat
infra
namespace
in
that
we
have
installed
argo
workflow
and
the
ergo
ui,
and
we
have
created
one
account,
which
is
ergo
workflow
account
which
will
go
from
this
namespace
and
trigger
the
execution
on
any
of
the
namespace
argo
cd
after
argo
cd
sync.
E
So
now,
if
you
could
see
that
the
existing
workflow,
what
we
have
is
become
so
interesting
and
it
can
go
and
do
things
what
you
actually
code
it
to
demonstrate
that
we
have.
One
scenario
like
this
is
one
of
the
sample
pipeline
and
we
will
add
this
part
as
a
one
of
the
lab
example
how
anyone
can
use
that.
E
In
that
container,
we
are
saying
that
you
wanted
to
run
that
for
ramp
up
time,
study
time
and
how
the
execution
time
and
then
we
are
passing
this
base
url,
which
is
that
ingress
endpoint,
and
then
we
run
the
load
test
once
we
run
the
load
test,
we
push
the
artifact
to
the
s3,
and
this
is
important,
because
one
of
the
biggest
challenge
is
that
in
part,
every
pod
will
generate
specific
report.
So
we
put
all
the
reports
together
and
later.
E
So
here
is
a
report,
so
you
have
running
your
performance
test
using
this
infra
and
you
can
get
the
actual
result
coming
so
to
demonstrate
this.
I
I
have
naveen
in
my
team.
He
can
just
run
one
live
execution
and
can
show
that
how
all
this
live
test
running
and
then
how
you
can
do
the
live.
Dashboarding
I
mean,
are
you
there?
E
E
E
Do
you
want
like,
if
you
want,
say,
10
000
tps
you
can
give
as
10
pods.
So
in
this
case,
like
I'm,
giving
the
default
s2
a
peak
tps
is
like
how
much
per
pod
like
what
is
the
tps
that
you
want
to.
You
know,
give
or
generate
the
load
and
ramp
up.
Time
is
like
how
much
from
like
zero
to
one
tps,
how
much
time
you
want
to
ramp
up.
So
you
can
give
like
hundred
thousand.
E
How
much
ever
like
the
pod
is
capable
of
that
load
generator
is
capable
of
steady
state
is
like
once
it
reached
that
one
or
1000
tps.
It
will
continue
at
the
same
state
and
then,
like
the
execution,
will
start
so
for
now.
For
this
demo,
I'm
just
giving
like
a
one
one
and
one.
So
it
should
be
done
sooner
and
now
that
you
have
seen
like
this
load
testing
at
pfi,
which
is
like
we
have
a
name
space
called
pfi,
that's
where
the
execution
starts.
E
So
this
is
the
namespace
where
we
have
the
argo
workflow
installed
and
what
we
are
doing
is
we
are
taking
the
service
account
and
that
service
account
is
being
provided
from
the
jenkins
such
that
it
can
perform
the
argo
actions
so
in
here,
like
the
argo,
submit
command
has
started.
So
this
is
the
place
like
where
these
are
the
two
load:
generators
perfect
for
a
hyphen.
These
two,
the
run
test
run
test
and
the
execution
has
just
started.
E
E
E
So
this
is
our
like
jenkins
file
load,
which
is
actually
performing
the
jenkins
actions,
and
this
is
the
workflow
file
which
is
being
called
and
in
the
workflow
file
like
we
have
like
five
steps
but
like
I
will
talk
about
the
pdb,
create
and
delete
at
the
end.
But
these
three
are
the
main
steps.
So
run
test
is
the
one,
as
you
have
seen
like.
E
We
are
giving
like
two
parts
and
the
two
parts
will
be
generating
the
load,
so
the
two
is
a
dynamic,
so
you
can
give
two
or
ten
or
hundred
whatever
number
so
depends
on
the
load
that
you
want.
So
it
is
a
highly
scalable
a
list
test
after
the
run
test,
like
all
the
execution
and
everything
is
done
in
the
individual
parts
and
they
will
generate
the
reports
in
each
of
those
parts.
So
list
test
is
the
step
wherein,
like
once
the
results
has
been
generated
from
the
individual
parts.
E
E
So
after
this
all
three
steps
are
done.
The
next
step
would
be
since
the
results
are
in
the
s3,
so
we
are
downloading
those
assets
from
s3
here,
so
downloading
the
assets
from
s3
and
once
the
results
are
downloaded
from
s3,
so
we
are
archiving
the
registers
that
the
teams
can
access
it
from
the
same
jenkins
file
going
back
here,
and
so
we
have
added
the
pdb,
create
and
pdb
delete.
So
this
actually
enables
us
to
increase
the
efficiency
of
the
parts
that
is
in
progress.
E
So
that's
about
the
one.
Can
we
go
and
see?
That
is
the
test
done.
Let's
see
that,
I
think
it's
almost
36,
so
one
of
the
most
important
thing
which
we
have
actually
solved,
that
is,
the
cost
today
running
the
performance
test,
with
any
sophisticated
tools
required,
two
things:
licensing
cost
and
the
operating
cost.
E
Even
yesterday
we
have
done
the
10
000
tps
so
and
it
is
a
scalable.
We
are
using
all
the
goodies
of
our
go
workflow
and
we
are
using
kubernetes
to
scale
up
and
scale
down,
and
this
is
something
which
we
think
worthwhile
sharing
I
mean
if
you
can
just
see
that
I
wanted
to
show
one
or
two
more
things
on
this
yeah.
This
is
done,
so
I
think
it
will
be
done
sooner,
so
it's
merging
the
results
now
cool.
E
So
one
of
the
other
thing
which
we
are
working
and
we
are
enhancing
in
in
this
itself-
is
that:
can
we
get
the
this
performance
test
and
the
chaos
to
be
added,
and
that
would
be
probably
maybe
a
next
meetup
we
will
share.
But
what
eventually
will
happen
is
that,
as
everything
has
been
a
kubernetes
native,
we
can
run
the
performance
test
as
well
as
we
can
run
the
chaos
test
same
and
then
we
can
see
the
chaos
interruption
and
then
we
can
measure
the
performance.
E
This
is
a
good
segue,
where
you
are
doing
lot
of
testing
as
part
of
the
kubernetes
way
of
execution
right
now.
These
two
things
are
not
being
tied
together
in
the
open
era,
and
everyone
is
trying
to
doing
these
are
the
two
distinct
activities,
so
we
are
hoping
to
get
those
things
attached.
So
any
questions.
E
So
this
is
again
bringing
back
the
same
reporting
what
we
use,
and
it
is
technology
agnostic.
As
long
as
you
are
able
to
use
the
specific
execution
of
the
programming.
So
here,
if
you
see
that
in
the
container
how
we
are
executing,
we
are
making
the
container
call
with
this
option,
and
these
are
options
which
are
actually
being
parameterized
in
the
workflow.
E
A
A
Today,
if
you're
using
argo,
workflows
or
other
events
for
something
interesting
unusual,
we
do
really
enjoy
seeing
the
demos
of
that
it's
really
interesting
to
find
out
what
different
people
are
doing
with
the
with
with
the
technology
and
it's
you
know
those
that
kind
of
damage
the
most
interesting
things
we
have
in
these
meetings.
So
we'd
love
to
see
more
of
those
guys
summit.
Will
you
be
able
to
share
the
slides
with
people
afterwards.
A
So
what
I'm
going
to
do
is
we're
putting
together
a
document
to
list
some
of
these
cops,
optimization
ones
and
they're
kind
of
broadly
split
into
two
different
categories,
and
one
category
is
around
optimizing.
The
execution
of
your
workflows
and
another
category
is
about
the
operation
of
argo
workflows
itself
and
the
reason
we
split
that
into
two
categories
is
because
typically,
the
costs
for
executing
workflows
can
fall
on
a
different
team
or
business
unit
or
part
of
the
organization
to
that
of
operating
it.
A
Even
though
the
two
are
obviously
interrelated
and
the
biggest
cost
savings
can
that
can
be
had
are
around
the
the
actual
execution
of
the
workflows.
Argo
workflows
itself
unless
you
have
a
very
large
number
of
workflows
in
your
system
and
we'll
come
back
to
that
shortly
and
it
doesn't
actually
have
particularly
high
resource
requirements.
A
So
the
first
tip
is
to
limit
your
total
number
of
workflows
and
pods,
and
there
are
three
settings
you
can
use
in
this
on
each
workflow.
To
do
that,
the
first
one
is
active
deadline.
It's
actually
active
deadline
seconds.
This
is
the
maximum
amount
of
time
the
workflow
is
allowed
to
execute,
and
you
can
use
this
to
kind
of
make
sure
that
any
work
for
the
workflow
doesn't
run
away
with
a
maximum
time.
A
A
You
can
also
have
one
on
workflow
completion
and
you've
got
variations,
such
as
on
workflow
failure
on
workflow
success
on
pod
fader
and
on
pod
success,
and
the
reason
you
want
to
do
this
is
that,
even
though,
when
a
pod
is
complete,
it
uses
less
resources.
It's
not
completely
cleaned
up.
There
is
a
downside
to
each
of
these
settings.
The
downside
is
that
if
your
workflow
or
pod
has
failed,
then
deleting
them
will
obviously
potentially
remove
some
useful
information
you
might
want
to
have
around
failure.
A
If
you're
like
us,
you
actually
probably
are
kind
of
the
logs
and
all
your
artifacts
automatically
and
actually
doesn't.
You
can
actually
delete
them
on
completion,
but
what
you
would
want
to
do
with
that
can
vary
now.
This
is
a
nice
one
to
kind
of
combine
using
this
feature
called
default,
workflow
specification,
which
is
a
relatively
new
feature
and
default.
A
Workflow
specification
is
a
way
in
your
config
map
here
to
set
up
a
set
of
defaults
that
are
used
and
those
defaults
are
emerged
in,
like
a
mail
merge
into
your
workflow
before
it's
executed.
So
these
are
defaults
rather
than
overrides,
and
that
means
you
can,
in
your
workflow
specifications,
specify
different
things.
So,
for
example,
you
could
use
a
set
of
default
pod
gc
strategy,
but
you
may
have
some
workflows
where
you
don't
want
to
use
that
default.
You
might
want
to
use
a
specific
one
and
you
can
just
change
those
in
your
specifications.
A
So
that's
a
tip
for
people
executing
workflows.
Here's
here's
a
couple
of
tips
for
people
running
a
large
number
of
workflow
instances,
so
we
run
107
installations
of
argo
workflows
into
it
and
it
goes
up
and
down
it's
gone
down
because
we
did
some
clusters
recently,
but
it
was
111.
So
that's
107.,
you
can
use
resource
quotas
and
you
can
use
limit
ranges
to
set
the
default
memory
of
your
argo,
workflow
installation.
A
So
the
best
way
to
reduce
the
memory
requirements
of
the
workflow
controller
is
actually
to
reduce
the
total
number
of
complete
and
incomplete
workflows
that
you
have
and
that'll
obviously
address
your
cost
beforehand
and
then,
once
you've
got
that
down
to
a
nice
level.
You
can
put
in
place
limits
to
control
that
there's
any
questions
about
these
two
strategies.
Before
I
move
on
to
some
of
the
the
more
kind
of
niche
strategies.
E
A
F
F
A
So
I'll
just
address
pod
gc.
First,
that's
easy
that
that
that
works
as
as
usual,
that
doesn't
that's
not
impacted
at
all
by
by
your
persistent
setup
for
people
not
using
persistence.
There
are
two:
there
are
two
things
you
can
do
with
persistence
and
one
is
to
archive
workflows
and
one
is
to
offload
large
workflows
I'll.
A
Just
talk
briefly
about
the
offloading
feature,
because
I
think
it's
important
to
go
into
some
of
the
details
there,
the
the
offloading
actually
only
occurs
under
specific
circumstances,
so
argo
workflows
prefers
to
store
your
workflow
specification
in
the
xfd
database.
However,
the
xd
database
has
a
one
megabyte,
a
limit
to
the
size
of
the
data
you
can
store
in
there.
So
what
happens
is
if
it
becomes
large?
What
it
attempts
to
do
is
compress
a
specific
part
of
the
specification.
A
part
called
the
node
status,
which
is
under
the
status
field.
A
Slash
nodes,
and
the
first
thing
they'll
do-
is
attempt
to
compress
that
and
keep
that
data
on
that
set
d,
because
we
know
that's
faster
and
more
reliable
than
using
a
database
for
these
things.
It
removes
kind
of
edge
cases
where
you
know
you
lose
your
database
connection,
so
your
workflow
fails.
It's
only
only
when
it
can't
compre
when
it's
too
large
and
it
can't
compress
it.
Then
it
offloads
it
into
the
database,
so
I'll
save
it
in
the
database.
Now,
that's
actually
quite
a
non-trivial
piece
of
code
to
do
there.
A
A
Only
the
most
recent
version
is
kept
plus
anything
that's
happened
in
the
last
five
minutes,
because
we
need
to
be
able
to
support
a
watch
on
each
workflow
and
that
and
a
watch
xfd
actually
stores
multiple
versions
of
your
specification
in
it.
So
we
actually
also,
therefore
need
to
store
multiple
versions
as
well,
and
that
ttl
still
applies
to
it,
but
there
are
two
ttls
there.
A
One
one
is
to
delete
the
older
data
five
minutes
and
the
other
one
is
to
ttl
those
workflows,
so
so
in
a
short
answer
that
that
still
happens.
However,
if
you're
using
persistence
to
save
your
workflows
into
the
workflow
archive-
and
that
has
a
completely
different
set
of
garbage
collection
settings
and
specifically,
you
can
set
a
ttl
for
the
archive,
so
your
data
is
deleted,
but
that
wouldn't
be
a
short
ttl.
A
F
No
so
I
actually
work.
We
have
a
home
brew
system
that
does
pretty
much
this
and
I
have
40
000
artifacts
right
now
in
ncd.
So
I'm
dealing
with
this
right
now
as
fcd
has
completely
slowed
down
and
everything
about
on
this
homebrew
system.
So
I'm
just
trying
to
make
the
parallel
between
this
and
argo
and
just
ensure
that
the
argo
artifacts
get
pushed
into
postgres
as
soon
as
possible.
As
my
dags
are
over
two
to
three
thousand
nodes
wide.
A
Yeah
that
that
would
be,
that
would
be
a
good
that
would
be
a
good
thing
to
do
is
have
have
the
persistence
enabled
have
that
ttl
set
jobs
are
on
completion
and
save
them
into
workflow
archive
so
that
the
workflow
control
doesn't
have
to
manage
that
large
amount
of
data.
Certainly
for
for
the
use
case
of
you
know
a
thousand
ten
thousand
plus
workflows
that
that's
the
right
solution.
A
Awesome.
Well,
thank
you
for
the
answer.
So
there's
a
question
from
michael
crenshaw.
Is
there
a
way
to
say
active
deadline
seconds
at
the
step
level,
we
have
workflows
with
durations
that
vary
with
parallelism,
but
steps
with
reasonably
predictable
runtime.
I
don't
know
the
answer
to
that
question:
jesse
or
barlow.
Do
you
go?
Do
you
guys
know
if
we
can
do
that
on
a
step
level.
C
A
D
A
Okay,
I'm
just
going
to
move
on
talk
a
little
bit
about
execution
resource
requests,
so
we
mentioned
that
you
can
configure
then
for
the
workflow
controller
config
map,
you
can
also
set
up
the
executa
resources.
If
you
want
to
limit
the
amount
of
resources
they
can,
they
can
do
again.
This
is
this
is
one
of
those
things
that
will
scale
it.
There
is
one
downside
to
this:
if
you've
got
large
artifacts
in
your
system,
I'm
sure
many
of
you
do.
A
We
also
have
the
ability
to
set
the
pod
resource
requests
and
there's
a
new
feature
that
came
in,
I
think
2.6,
which
will
give
you
a
summary
of
how
much
your,
how
many,
how
much
resources
your
pod
uses
and
the
way
that
that's
calculated
is
determined
by
the
amount
of
cpu
and
memory
requests.
You
asked
for
multiplied
by
the
the
resource
duration
it
as
in
how
long
how
long
that
part
exists.
For
so
you
know
a
pod
that
requests
four
gigabytes
of
memory.
A
That
runs
for
one
minute,
you
know,
is
using
kind
of
much
total
memory
as
a
pod
that
requests
one
gigabyte
that
but
runs
for
four
minutes.
So
if
you
can
the
less
time
your
pods
run,
that's
another
way
to
reduce
your
your
costs
as
well,
and
you
can
see
that
in
the
user
interface
and
I
think
that's
going
to
be
turned
on
by
default
in
version
2.9,
which
will
be
at
the
end
of
june.
A
A
A
I
think
we
have
just
one
other
one.
If
you've
got
a
workflow
that
has
a
large
number
of
artifacts
and
it's
copying
it
to
and
from
storage.
You
might
want
to
consider
using
a
volume
claim
template
that'll
that
allows
you
to
basically
mount
a
volume
to
your
container
for
each
step,
and
then
you
can
read
and
write
from
that
particular
volume
between
different
steps
without
having
to
to
save
that
artifact
out
to
storage
and
then
read
it
read
it
back
in
afterwards.
That
might
be
quite
good.
A
For
example,
if
you're
running
this
comes
from
a
ci
example,
so
you
can
create
a
volume
that
acts
as
a
workspace
or
a
working
directory,
and
that's
shared
between
all
steps
in
your
workflow
and
at
the
end
of
the
workflow.
You
can
then
upload
those
you
can
zip
those
artifacts
up
and
upload
them
at
the
end.
A
A
For
the
cli,
when
it
initializes
okay,
so
those
we've
increased
the
defaults,
those
recently
to
32
the
workflow
workers,
allows
multiple
parallel
workflows
to
be
executed.
So
if
you're
running
a
lot
of
workflows,
then
you
should
increase
that
particular
setting
the
pod
workers
is
the
same,
but
for
pods
so
every
time
a
pod,
that's
part
of
your
workflow
changes,
you
know,
starts
or
stops
or
is
successful,
unsuccessful.
A
It's
it's
dealt
with
by
pod
worker.
So
if
you
have
large
workflows
with
many
many
pods
in
them,
then
you
can
increase
that
setting
to
get
more
throughput.
Both
of
those
will
require
you
to
increase
your
the
amount
of
memory
you
give
to
the
workflow
controller,
to
support
that.
Well,
that's
how
you
can
scale.
A
Okay,
great
well,
thank
you
all
for
for
coming
today.
If
you've
got
we'll
be
showing
this
video
on
youtube,
so
you
will.
I
will
drop
that
video
into
slack
for
anybody
who
wants
to
review
that
and
also
I'll
ask
summit
and
derrick
to
share
their
slides
and
I'll
add
those
to
the
meeting
documentation
if
you
want
to
have
a
look
at
those
again.