►
From YouTube: CDS Pacific: RADOS
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
So
we
have
a
few
items
in
the
ether
pad
which
is
already
in
the
chart,
but
for
most
things
we
have
Trello
boards
that
have
been
marked
with
Pacific
some
that
can
be
marked
as
we
go
along
and
I
like
to
keep
this
very
open
and
very
interactive.
If
there
are
items
that
people
want
to
add
or
talk
about,
let's
just
use
this
time
to
do
that.
A
B
C
D
D
Two
years
ago,
I
start
design
and
development
in
duplication
on
SAP,
I
would
say,
I'll
say
to
give
me
the
basic
idea
for
replication
instead,
so
based
on
that
I
have
implemented
been
festering
on
sale.
So
I'm
going
to
share
the
past
and
present
of
replication
on
SAP
and
then
are
you
I
will
tell
you
the
major
remaining
issues
and
desktop
regarding
the
next
steps.
Sam,
you
talked
about
the
plan
after
my
presentation.
D
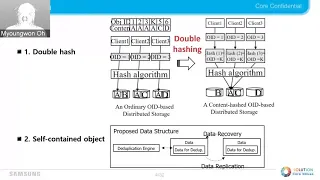
Let
me
start
with
the
background
of
conventional
tillage
system.
The
figure
described
the
TTP
patient
procedure
in
typical
system,
typically
on
object
is
divided
into
separate
rounds
by
chunking
algorithm,
and
then
the
loop
system
generate
all
think
event
values
or
each
competitor
to
check
whether
the
concrete
unique
in
the
service
system.
We
need
a
fingerprint
index
which,
which
store
or
burping
information
between
the
fingerprint
and
rotational
touching.
D
D
Fingerprint
index
is
ackee
metadata,
indeed
of
system,
so
it
could
be
according
on
the
key
value,
TB
or
vice
time,
but
let's
think
of
the
situation
where
the
number
of
chunky
storage,
so
that
fingerprint
in
this
canopy
store
in
a
single
method,
is
above
all,
whatever
morover
fingerprinting.
That
should
not
be
a
limiting
factor
or
scaling
the
story
system.
Therefore,
therefore,
the
fingerprinting
that
should
be
it
is
bit
evenly
and
efficiently
across
tiles
cluster.
D
This
is
the
problem
also
TDF
system
is
facing.
In
summary,
the
first
problem
is
scalability
of
in
opened
index.
Our
problem
was
that
adding
new
metadata
for
fingerprint
index
shear
occurs
to
change
these
old
system.
For
example,
dilib
engine
requires
all
new
metadata,
such
as
fingerprint
index
and
recipe
store
for
did
you,
but
how
can
we
add
new
metadata
into
AC
system?
D
So
our
key
idea
is
to
sort
of
first
blow
in
stop
rehearsing
assume,
as
you
know,
that
fresh
non-elect
ID
to
decide
where
to
locate
given
data.
The
problem
is
how
to
deal
ok.
This
data,
based
on
the
contents
of
the
data,
while
maintaining
the
weapon
information
to
our
approach,
is
to
use
another
hash
function
whose
input
is
the
fingerprint
and
our
Buddhists
audio
object,
ID.
So
please
loop,
yet
alright
figure
plant
one
has
already
won
by
using
crush.
We
can
get
the
location
of
white
one
after
that.
D
If
we
to
generate
ash
failure
once
again
based
on
the
place
and
object
contents,
we
can
get
the
location
about
data
a
in
the
right
ear,
so
first
fresh
through
the
stones,
the
data
in
the
same
way
except
us.
Why
why?
Second,
second
king
of
winter
hash,
decide
to
ensure
occasion?
It
means
that
we
used
the
hash
that
fingerprint
value
as
object
ID
at
the
second
hash
brown.
D
D
D
Let's
move
on
next
time,
based
on
our
based
on
the
key
ideas.
Ira
explain
the
design
of
hit
applications
on
SAP.
First
thing,
I
want
to
explain
is
object.
We
had
the
type
field
in
object
input
he
to
this
ish
between
our
manifest
objects
and
chunk
object.
Manifesto
project
has
our
object.
Id
y
chunk
object
has
the
hash
object
and
manifest
oblique
has
tunk
tunk
map
which,
in
the
include
absurdly
ng,
shankar
ID
cache
bit
and
dirty
bit.
On
the
other
hand,
chunk
object
has
diplomatic
own,
then.
D
Lastly,
tables
have
take
8
appear,
but
these
two
objects
are
just
object,
like
other
object
in
on
sap.
From
the
from
logical
point
of
view,
a
second
a
is
poor,
which
is
recoverable
objects
that
us
there
are
two
four
two
four
four
the
cross
corresponding
object,
ID
many
pests
for
stores,
the
better.
They
looked
better
data
objects
and
chunk
for
stores
to
object.
Since
each
per
has
deepened
corpus
and
uses,
they
can
be
more
mention
of
more
efficiently.
D
D
Next
time
I'll
the
x
item
I
want
to
share
is
the
implementation
detail.
Unfortunately,
there
is
a
lot
of
practical
issues
when
implementing
his
vision
is
designed.
I
described
the
debris
so
implementation
applied
to
upstream
is
a
bit
different
from
our
suggestion.
As
you
already
know,
the
efficiency
of
opt
do
depends
on
our
code
characteristic,
so
if
there
are
only
a
few
typical
chunks,
so
using
the
precondition
using
the
dip
is
not
a
cool
idea,
so
we
think
it
should
be
applied
selectively.
D
D
D
D
Also
Terra's
of
Egypt
you
to
supplement
the
TD
provision,
implement
the
digital
has
two
doors.
First,
one
is
that
we
find
out
the
optimal
to
merchants.
The
automatron
blends
to
given
Cuban
mob
floor,
such
as
there
is
a
pool
and
if
Iran
Phillip,
to
on
the
endeavor
repeatedly
and
with
changing
Chunkin
parameters,
optimal
Chun
banks
will
be
bound
on
because
its
results
showed
how
many
chunks
are
peckin
all
is
fixing
rapidly.
D
Discussion,
as
you
can
see,
master
code
tutoring
watch
on
coexisting.
What
one
is
extinct,
your
entire
support
areas,
cache
mode
such
as
proxy
attack
and
resume
another
one-
is
latest
hearing
fortification.
There
are
two
implementing
to
the
tower
to
implement,
have
a
similar
concept
because
was
a
pure
interest
structure,
but
they
do
not
share
the
code.
I
think
this
a
bit
inefficiency,
a
big
impossibie
difference
between
existing
here
and
many
guests
here
is
a
gradual
auntie
perform
only
formal
is
for
basis,
so
that
was
ported
recovered.
Two
tractor-trailer
is
the
object
base.
D
D
Second,
this
question:
Twinkies,
just
above
my
soul,
we
merging
best
device
like
GE
SSD,
was
so
displeased
this
P
system,
tougher
on
Pokemon
segregation
to
reserve
such
a
proper
hospital
room
like
we
like
waking,
you
may
a
source
system
have
to
try
to
exploit
Pokemon
SPEA
test
here.
So
I
think
we
need
to
be
think
about
questions
arising,
as
you
know,
which
doesn't
need
from
constancy
or
poison,
see,
what's
up
sure,
I
hope
as
posturing
and
all
chakras.
It
was
a
great
in
terms
of
old
usability.
D
Not
a
big
to
be
discusses
next
step
for
the
replication
phase
function
for
SAP.
Forty
deep
has
been
kept
in
implemented
on
setlist,
wasn't
master
branch,
but
they
need
to
be
more
usual
friendly,
provides
a
high
compatibility
and
I
can
have
concrete
engineering
to
do
so.
I
have
plans
to
implement
that,
but
then
by
very
explain
other
next
step
led
to
that
tearing
video
in
DJ.
C
C
Okay,
great,
so
I
came
up
with
a
quick
summary
of
sort
of
two
broad
categories
of
what
we
want
to
do
going
forward
with
this.
So
the
first
observation
is
that
much
of
the
previous
presentation
focused
on
the
manifest
hearing
work
which,
if
you
look
at
the
code
at
the
actual
implementation,
it's
essentially
parallel
to
the
cashiering
implementation
within
the
OSD,
and
it
has
a
lot
of
duplicated
code,
but
that,
strictly
speaking,
isn't
necessary
or
even
helpful
for
implementing
t-tube
in
rgw.
C
C
In
the
OSD
directly
would
save
an
entire
layer
and
would
be
vastly
simpler
to
a
bulletin.
It's
also
more
efficient,
since
you
have
to
read
that
head
object
anyway,
so
I
think
for
d-do
purposes.
Since
our
primary
target
is
rgw,
we
should
actually
ignore
all
of
the
manifest
work
at
first
I.
Think
more
design
work
will
need
to
be
done
here
and
will
need
to
if
anyone
from
the
rgw
side
wants
to
discuss
that
a
bit.
That
would
be
good
but,
like
I,
said
a
major
advantage
here.
C
Is
that
you
don't
you
don't
have
to
rework
the
interior
of
the
OSD,
so
it's
likely
to
be
a
great
deal
easier,
semantically,
it's
pretty
straightforward.
Rgw
already
sees
the
data
stream
as
it
comes
in
as
it
does
the
writes.
So
it
runs
some
kind
of
a
hashing
IAM,
sorry,
a
content,
hashing
scheme
to
find
chunk
boundaries
and
then
writes
them
out
to
the
ref
counting
pool
as
needed
and
then
simply
writes
the
head
object
with
those
references
it
up.
The
ref
counting
class
already
does
the
actual
atomic
ref
counting
component.
C
So
that's
no
big
deal,
of
course,
that
won't
work
for
our
BD
or
sefa
fests,
where
we
don't
really
want
to
store,
like
an
external
literal,
manifest
for
each
object
at
a
different
layer.
So
for
those
purposes
there
are
a
number
of
things
we
want
to
clean
up
in
the
existing
manifest
code.
I'm
not
going
to
go
over
these
in
detail,
but
those
really
four
copies
the
same
thing:
okay
anyway.
C
The
next
big
component
we
want
to
address
is
we
don't
want
tutoring
implementations
and
the
existing
cashiering
implementation
is
a
world
of
pen,
so
we
would
probably
like
to
replace
it
completely
with
this
new
manifest
concept,
in
that
it
ought
to
be
more
flexible,
with
the
slight
difference
that
there
must
be
at
least
a
manifest
object
for
each
object.
Unlike
the
existing
cast
hearing
machinery
which
allows
which
deals
to
the
whiteouts
right,
so
there
are
sort
of
three
broad
things
we
need
to
deal
with
here.
C
C
The
other
thing
that
we're
sort
of
leaving
on
the
table
is
that,
regardless
of
what
we
want
to
do
here,
it's
super
valuable,
whether
it's
an
external
tearing
agent
or
one
built
into
the
OSD
to
be
able
to
find
out
how
recently
an
audit
has
been
accessed.
Fortunately,
there
is
already
support
in
the
OSD
for
tracking
hit
sets,
and
it
actually
is
very
little
to
do
with
kashering.
It's
just
that
it's
autumn,
it's
enabled
automatically
depending
on
the
pool
type.
C
So
we
need
to
give
it
its
own
separate
set
of
config
options
and
finally,
it
needs
to
properly
support
snapshots.
The
current
code
is
mostly
wrong
in
that
regard.
I
didn't
finish
this
light
before
I'm
finished,
but
one
of
the
short
of
it
is
that,
up
until
now,
there
is
no
librettos
operation
that
directly
mutates
the
clone.
C
C
What
that
is
they
trigger
a
wrap
up
like
trim
does,
but
they
don't,
they
don't
trigger
any
of
the
snap
contact
stuff.
This
would
allow
us
to
just
allow
things
like
set
chunk
to
be
done
directly
on
a
clone
by
a
liberators
client.
That
knows
what
it's
doing.
It
would
also
allow
us
I
think
to
create
a
somewhat
less
confusing
square,
prepare
story.
So
I
think
this
is
a
positive
step.
Generally,
there
are
a
few
big.
What's.
F
C
C
G
C
Yeah
well,
we'll
have
to
think
carefully
about
what
the
semantics
will
be
for
each
of
like
each
each
one
of
the
operations
that
behaves
like
this
will
be
a
little
bit
dangerous.
So
we'll
have
to
think
carefully
what
the
semantics
are,
but
I
think
it'll
be
it'll,
be
good,
but
this
is
also
super
invasive,
so
we'll
have
to
think
carefully.
I.
C
Think
about
it
pose
an
object,
has
I,
don't
know:
20
snapchat,
20
clothes
right,
so
there
it's
already
possible
to
introspect
what
the
clones,
what
clones
there
are
and
what
their
overlaps
are.
So
a
smart
tearing
agent
might
observe
that,
let's
say
at
the
tenth
clone
sees
a
lot
of
read
traffic,
but
none
of
the
other
ones
do
so.
It
wants
to
selectively
D,
dupe
and
evict
all
of
the
extents
for
the
inactive
clones
and
only
promote
back
in
the
extents
that
are
relevant
and
that
set
might
change
over
time.
C
So
with
the
existing
capturing
code,
we
sort
of
conveniently
didn't
have
to
worry
about
this
by
creating
an
invariant.
That
said
all
clones
between
some
arbitrary
C
and
the
head
exist
and
we
get
to
move
C
depending
on
how
active
the
object
is,
but
if
just
the
very
oldest
clone
is
active
and
none
of
the
interior
ones
are
the
all
the
interior
ones
have
to
exist
and
they
have
to
exist
in
their
entirety.
C
They
can't
be
just
partially
present,
but
with
manifests
because
we
get
to
do
more
than
have
the
up
should
be
just
present
or
not
present.
We
want
to
be
able
to
simply
mutate
that
that
manifest
it
shouldn't
change.
The
actual
contents
of
the
object,
like
one
of
the
rules
here,
should
be
that
it
isn't
possible
to
make
any
of
the
non
special
librettos
objects
return.
C
A
different
answer
by
running
one
of
these
commands,
accepting,
of
course,
the
scrubber
pair
ones
or
things
of
that
nature,
but
we
do
want
to
be
able
to
selectively,
say
no
I'm
actually
doing
a
mutation
on
this
object.
It's
just
not
one
that
changes
normal
liberators
level
results.
Does
that
make
sense.
Yeah.
C
Okay,
so
I'd
wanted
to
back
up
to
the
cache
concept,
generally
speaking,
weak
consistency,
it
doesn't
describe
very
much
on
its
own.
That
pair
of
words
isn't
super
descriptive.
If
what
you're
asking
for
is
a
client
level
down,
persistent
cache
I
think
their
implementations
of
that
like
floating
around
already
right,
/
BD
at
least,
and
that's
where
you'd
want
to
do
it.
You
wouldn't
want
to
go
over
the
network
for
in
infer
for
an
ephemeral
right
right.
I
C
D
C
Bang
for
our
buck
in
terms
of
implementing
of
in
terms
of
workloads
that
would
benefit
well
from
dee.
Doop
are
probably
in
rgw,
and
that
doesn't
require
any
of
this
manifest
support
at
all.
All
it
requires
is
the
atomic
rough
cutting
stuff
that
already
exists,
then,
as
we
can
write
a
fire
gw2
just
explicitly
write
down
which
nuclear
project
it
it's
pointing
out,
there's
already
a
metadata
layer
in.
I
C
D
C
C
Guess
that's
a
good
point.
Even
for
ole
object,
D
tip!
You
would
still
need
to
store
a
pointer
to
each
Rados
object
because
it
won't
do
an
interaction
to
another
rgw
object
anyway.
It's
something
we
can
look
at
in
more
detail.
It's
a
smaller
problem.
I
think
the
generalizing
liber8
owes
to
support,
manifests.
C
I'm,
a
little
ambivalent
on
that
score.
Actually,
so,
for
one
thing,
there's
no
reason
you
couldn't
reach
in
and
change
the
rgw
headers
the
same
way
so
that
design
choice
is
orthogonal,
I
feel.
But
given
that
rgw
sees
the
whole
logic
stream
seems
like
you
may
as
well.
Do
a
raven
hashing
again
right
perhaps
stop,
but
I
think
we
can
do.
I
think
that
decision
is
orthogonal.
C
A
J
C
E
A
C
Would
like
to
see
the
cleanups
I
I've
outlined
in
the
existing
manifest
code
in
and
we'll
have
to
discuss
whether
we'd
rather
go
for
the
rgw
thing,
which
I
think
is
the
simpler
option
or
make
progress
towards
better
snapshot.
Support,
but
I
think
it
depends
on
who's,
gonna
sort
of
how
much
bad
what
there
is
to
work
on.
A
A
A
A
A
F
A
user
who's
asking
for
this,
but
we've
never
really
prioritized
it.
The
idea
would
be
that
if
their
failure
domain
is
rack
or
host,
let's
say
its
host
you'd
want
to
issue
a
warning
if
the
failure
of
any
single
host
would
make
cluster
so
up,
yeah
seems
like
something
that
we
should
do
at
some
point,
but.
I
A
All
right,
so,
okay,
next
there
is
simple
adaptive
recovery
settings.
This
was
there
earlier
solely
amok
for
octopus.
We
decided
not
to
do
it
to
this.
We
had
other
recovery
stuff
going
and
we
had
partial
recovery
and
get
some
easy
recovery
bloom
in
size.
Things
go
ahead,
but
I
think
this
is
still
relevant
and
hence
marked
it
for
Pacific
again,
because
there
are
people
still
coming
and
asking
for
it.
F
A
All
right,
then,
the
next
one
on
the
list
is
yeah
again
it's
something
that
could
be
useful,
so
its
distinguished
unfound
versus
impossible
to
find
this
is
again
mostly
when
there
is
some
disaster
recovery
or
like
something
goes
wrong
in
the
cluster
people.
Come
asking
for
this
feature
again
and
again
so
I
guess
it's
a
matter
of
improving
our
listing.
Unfound
objects
that
really
are
useful
to
recover
or
not
is
they
are
secure?
A
A
B
E
B
A
Ever
what's
what
we
already
have
a
PR
which
is
under
work,
as
Josh
mentioned,
we
just
trying
to
sort
out
the
dependencies
and
try
to
make
it
build
a
dependent
source
I.
Guess
we
hopefully
get
that
in
the
next.
One
here
is
map
device
carers,
OST,
Trash,
Pack,
two
devices
I
think
this
thought
something
that
your
it
may
be
interested
hearing.
If
you
looked
at
this
card,
this
kind
of
fits
in
with
the
telemetry.
A
E
B
Idea
here
is
that
we
have
our
areas
from
the
device
you
just
repair
them
immediately
now
and
instead
of
tracking,
where
they
came
from,
like
which
disk.
If
it's
worm
like
the
DB
or
the
main
device,
for
example,
and
we
don't
even
having
any
kind
of
play
performance
counters,
which
would
be
the
minimum
for
telling.
What?
What.
J
E
J
A
F
B
F
Wonder
if
just
the
the
class
has
part
of
the
dee
doop
work,
though,
which
reserves
a
card,
this
would
just
be
the
object
class
that
manages
the
reference
counts
on
objects
that
are
being
consumed
by
either
the
manifest
hearing
stuff
or
by
urge
you
to
be
directly
but
I.
Think
just
having
that
class
like
well
documented
with
a
set
of
tests
that
exercise
it
and
validate
that
you
know,
references
aren't
leaked
or
whatever.
It
is
definitely
would
be
useful.
F
It's
a
little
bit
different
as
a
ref
count
class.
Doesn't
it
assumes
that
the
number
of
references
are
well?
It
has
back.
It
sounds
like
a
tag
or
a
reference
like
a
back
corner,
descriptor
string
or
whatever
for
every
reference,
and
so
the
Cavs
will
and
the
intention
original
design
originally
was
that
it
would
start
out
with
the
full-back
pointer
to
like
the
object
or
whatever
it
was
that
reference
it.
But
as
you
added
more
references
back,
pointers
would
decrease
in
resolution,
so
you
could
bound
the
total
amount
of
on
your
space.
F
F
B
I
said
a
little
conscious
effect,
trying
to
influence
like
that
before
we
understood
fully
they
users
of
it.
It
was
like
we've
done
a
few
of
these
in
the
past
and
we
have
to
be
more
helpful
if
we
knew
that
it
was
doing
the
right
thing
like
that
API
we
were
providing
was
like
when
we
were
going
to
friendly
to.
J
F
F
A
F
Right
so
so,
there's
a
set
of
patches
been
there
this
that
try
to
automatically
detect
what
Numa
node
your
network
card
and
your
engineer
on
and
if
they're
on
the
same
new
a
note,
then
it
pins
your
the
process,
abuse
on
that
new
node,
but
there
I
was
remember
while
I
was
working
on
looking
at
this,
but
there's
a
parallel.
That
of
there's
another
thing
you
can
do
about
memory
where
you
basically
also
confine
the
process
to
memory.
F
That's
attached
for
that
new,
a
node
and
it's
the
same
policy
thing,
and
there
was
some
reason
why
I
couldn't
automatically
figure
out
I
think
it
was
that
you
have
to
set
it
before
the
process
starts.
I
think
that
was
what
it
was,
whereas
the
painting
the
process,
the
other
CPU
stuff,
can
happen
after
you
started
up
and
those
these
initialized
and
start
up
blue
store,
and
so
it
knows
what
energy
needs.
F
A
A
Not
it
on
there
then
yeah.
The
second
card
is
about
controlled
OSD
map
trimming
and
there's
been
a
PR
that
has
been
lying
around
for
a
while
and
I,
really
think
we
should
get
it
to
a
state
orchard.
It's
been
causing
you
seen
our
issues
in
the
field
because
of
this
it'd
be
really
nice
to
have
this.
Oh
that's.
Why
I
added
it
I
believe
Joe
has
been
updating
this
PR
recently
and
testing
it
as
well.
A
F
H
A
The
next
one
is
again
about
severity
of
a
trade
earnest
and
SEF
health,
and
it's
also
something
that
came
from
the
field
ad
said.
But
the
idea
is
that
when
there
are
events
that
are
happening
in
the
cluster
like
migration
and
things
like
that,
chef
health
could
give
us
more
hints
as
to
how
much
more
tea
trade
the
cluster
would
become,
or
if
we
perform
certain
actions
this
in
general,
on
the
in
the
USD
lakhs.
We
do
have
information
about
it.
F
A
A
F
F
A
A
B
A
A
Also
think
we
didn't
end
up
doing
it,
but
we
decided
that
at
least
wherever
we
are
adding
that
information
about
waiting
on
variety
locks
in
that
particular
function
or
in
that
particular
place
in
the
code.
We
could
made
it
more
of
this
at
least
debug
messages
of
other
things
like
that.
That
could
give
us
a
chain
of.
C
C
A
C
A
A
Okay,
so
I
think
we
can
move
on
to
manager,
should
I
manager.
We
have
a
white
scale
down
yeah
this.
This
is
the
last
piece
of
improvement.
We
wanted
to
do
for
eg
autoscaler,
oh
I'd
scale,
down
until
there's,
basically
a
back
pressure
mechanism
to
reduce
the
number
of
peaches.
We
eat
it,
a
couple
of
things
already
in
Pacific,
but
the
default
number
of
peaches
of
pool
starts
out
with
and
also
the
auto
tuning
of
the
PG
log
lanes.
B
J
A
A
F
I
think
the
idea
here
is
just
to
include
as
much
interesting
information
as
we
can
about
how
the
multi-site,
rgw
stuff
is
being
used.
I
think
there's
some
really
really
basic
information
being
included
right
now,
but
I
forget
exactly
what
it
was.
Oh,
this
actually
would
probably
be
something
for
somebody
like
you
who
to
early
to
look
at
and
just
see
what
is
easily
included
that
isn't.
F
A
A
This
is
also
something
we've
seen:
customers
and
our
user
environments,
so
you've
been
adding
a
lot
of
manager
modules
and
a
lot
of
them
are
now
on
by
default,
because
of
which
we
have
a
lot
of
CPU
extra
CPU
cycles
in
processing
redundant
information
like
one
example,
would
be
what
we
recently
observed
in
the
network.
Paying
time
features
that
we
had,
because
of
which
we
were.
A
We
actually
didn't
realize
that
we
were
sending
a
lot
of
extra
information
that
we
didn't
need
in
the
manager
modules,
and
you
could
easily
get
rid
of
that,
and
this
scar
actually
popped
up
from
there.
Then
we
should
probably
go
and
investigate.
Where
are
the
other
pieces
in
the
manager
or
in
management
modules
that
we
are
doing
that?
A
The
other
item
I,
think,
is
the
balancer
and
I
know
there
are
a
few
patches
that
are
already
trying
to
optimize
this
by
producing
or
like
only
trying
to
get
the
required
information
and
not
and
try
to
save
it
for
future
purposes
and
not
try
to
fetch
it.
Every
I
guess
that's
the
idea
and
of
the
Scots
we'd
have
to
probably
go
and
look
where
other
opportunities
or
improvement
are
there
Josh
did
you
have
anything
else
to
add
yeah.
B
E
H
A
Us
that
I'm
going
a
little
off
topic,
but
we
did
decide
that
every
time
now
we
are
going
to
be
doing
releases.
We
want
to
install
it
in
our
lab
cluster.
Let
it
run
for
like
few
days
and
then
do
a
release,
but
if
we
could
also
add
some
sort
of
monitoring
system
which
would
look
out
for
these
kind
of
things,
manager
like.
J
A
F
Well,
now
that
it's
upgraded
to
octopus,
the
dashboard
and
stuff
is
all
there,
although
actually
that
something
needs
to
get
cleaned
up,
because
a
lot
of
the
stuff
is
deployed
manually,
though
the
automatic
set
stuff
didn't
actually
work,
because
it
was
conflicting
with
the
stuff
that
was
already
there.
So
probably
should
try
straighten
it
out,
but
in
theory
probably
what
we
want
to
do
is
make
sure
that
they're,
like
automatic
stuff,
EDM
monitoring,
stuff,
actually
works
and
actually
use
it,
because
I
think
all
the
pieces
are
there,
but
they
should
be
there.
H
F
F
H
F
F
A
A
Cr,
the
next,
this
balancer
consider
number
of
primaries
for
real
performance,
so
yeah
so
I.
Think.
Currently,
the
problem
is
that
the
system
balancing
the
up
map
mode
just
looks
at
the
number
of
PGS
per
OST,
and
this
pad
is
coming
from
the
idea
that
if
we
could
also
consider
the
number
of
primaries
that
are
present
on
a
particular
versity
and
try
to
spread
the
load,
then
we
could
probably
get
better
performance
and
not
rate
hotspots.
E
B
Since
these
are
kind
of
all
different
dimensions
that
may
be
in
conflict,
they
might
have
some
kind
of
Eurasian
thank
right
now.
The
only
configuration
for
the
competitor
patents-
oh,
it
is
in
order
list,
but
just
filled
wheat
I'm,
not
sure
you
might
not
think
about
how
to
make
that
more
easily
configurable,
so
you
can
choose
which
characteristics
you
are
balancing
by
ear.
A
A
F
F
The
problem
is
that
that's
ATM
only
supports
blue
store
and
doesn't
support,
file,
store
and
burn
are
currently
planning
on
implementing
files
for
support,
unless
somebody
shows
up
and
like
wants
to
do
work,
but
I'm
really
high
on
the
priority
list
there,
and
so
without
that
I'm
not
sure
how
useful
this
is.
There
are
other
cases
where
you
might
want
to
repay
those
teas
because
of
different.
B
That
we
are
hiding
already
that,
like
things
like
regarding
for
blue
store
or
upgrading
the
format
for
your
octopus,
for
example,
we
probably
want
to
make
eat
more
easily.
Automated,
so
I
think
that
this
kind
of
framework
for
doing
those
kinds
of
prosky
they
take
it
offline
and
do
something
to
it
started
back
up
again,
it's
be
useful,
yeah.
F
B
F
F
B
F
Think
the
only
other
thing
that
stands
out
to
me
and
this
manager
list
is
the
capture,
exceptions
and
crashes
Arden.
When
a
demon
crashes,
we
we
have
a
crash
report
and
it
gets
Pontormo
telemetry,
but
if
there's
an
exception
and
a
manager
module,
we
don't
it.
If
there's
no
log-
and
these
are
positives-
even
see
it.
H
A
H
F
F
Somebody
brought
up
this
compression
and
the
wire
thing
the
other
day
and
age
is
having
compression
on
the
wire,
and
that
also
be
having
some
like
cleverness
to
only
compress
sessions
that
are
like
crossing.
This
is
for
deploying
stuff
inside
and
was
done
only
compressing
the
links
across
availability
zones
to
reduce
your
bandwidth
bill
or.
F
G
F
F
G
F
But
I
think
I
I
think
that,
like
most
of
the
hard
work
is
done
and
there's
separate
options
for
binding
to
be
for
and
v6,
so
you
can
tell
a
demon
to
bind
to
both
and
it
will
show
up
in
your
enter
Specter
I.
Think
what's
missing.
Is
them
like
client-side
smarts
that
say
prefer
the
v6
to
the
v4
address
or
like
even
understanding
that
you
might
have
connectivity
with
one
or
the
other,
which
ones
are
edible
or
not?
I'm
not
I
think
that's,
probably
all
that's
really
needed,
but.
F
F
That
there
will
be
cases
where
the
the
client
node
has
v6
and
that
v6
address
or
thinks
it
does
and
the
server
does.
But
there
the
networks
aren't
like
credible
or
there's
like
some
other
stupid
ipv6
thing,
and
then
they
just
can't
talk,
even
though
they
could
talk
over
before
and
I.
Don't
think
we
can
mix
the
two
where
like
they
could
choose
one
or
the
other,
because
it
screws
up
fix
everything
else
confusing
so
that
we
could
probably
just
blame
general
sad
state
of
ipv6
deployments
in
the
world
and.
F
Yeah
right
now,
I
can't
remember
what
the
logic
is.
I
think.
Basically
they
just
it
looks
at
the
address
back
and
it
just
chooses
the
first
one
in
the
list
that
it
supports,
though-
and
it
did
that's
I-
think
it
literally
I
should
just
choose
the
first
one
because
I'm
the
v2
is
always
listed
before
we
won
and
if
you
can't
parse
the
address
back,
then
you
support
the
b2
protocol
and
so
you'll
always
just
use
the
v2.
F
So
it
needs
to
basically
look
at
the
whole
address
back
and
say:
well
there
CA
v4,
address
entity
six
address,
though
ipv4
ipv6
and
choose
which
one
you
want
to
do,
I
think
that's
mostly
it
I.
Some
can
take
option
two
like
to
prefer
one
of
the
other
and
or
something
that
figures
out
whether
the
current
host
has
a
rattle
these
legs
of
address
that
it
should
use.
F
F
I
I
I
A
A
F
I
think
the
missing
piece
is
that
you
have
to
update
the
key
on
the
Mon
database
and
you
have
to
update
the
key
for
the
demon
and,
if
there's
a
ill-timed
failure,
then
you'll
update
one
and
not
the
other,
vice
versa.
So
I
think
we
need
to
do
something
where
that
monitor
has
like
two
keys
that
work
for
the
same
off
user.
Oh
it's
switching
it
out,
and
then
it
removes
the
old
one
or
on
the
other
side,
the
demon
has
two
keys
that
it
tries
to
connect
it'll
try
both
of
them
it
to
implement.
F
A
A
K
One
would
be
running
the
you
know,
one
one
would
work
and
one
wouldn't
effectively,
though
adding
sub
interpreters
gives
us
some
isolation
between
each
of
the
manager
modules
and
there's
probably
still
problems
with
the
libraries
with
global
state.
Maybe,
but
we've
generally
done
a
good
job
of
of
having
this
all
work
more
recently,
sometime
last
year,
the
syphon
bugs
in
size
and
0.29,
they
added
a
commit
that.
K
Have
it
here
they
order
to
commit
to
siphon
that
basically
stop
sub
interpreters
from
working
for
us
and
I
hacked
around
that
by
adding
a
preprocessor
definition
to
to
turn
one
of
their
functions
into
just
a
void
or
no
up
or
something
so,
and
that
worked.
But
it
was
horrible
and,
and
so
the
concern
is
that
look.
K
The
siphon
folks
consider
sub
interpreters
to
be
a
rare
thing
that
isn't
well
tested
and
everything-
and
you
know
like
SEF
and
maybe
I'm
whiskey,
and
something
are
there's
only
three
projects
in
the
world
that
actually
use
these
things
right
and
although
I
found
something
I,
think
Eric
snow
who's
a
core
eyes
and
have
wanted
to
get
some
interpretive
things
better.
Somehow,
but
I'm
not
sure
where
that
work
is
so.
K
We
were,
it
would
probably
be
safer
for
us
to
somehow
get
rid
of
sub
interpreters.
One
horrible
way
of
doing
that
would
be
to
just
go
back
to
a
single
interpreter
and
then
make
sure
that
nobody
created
any
manager
modules
that
could
conflict'
with
each
other.
But
that
seems
silly
to
me
and
and
fraught
with
potential
problems.
F
F
F
F
K
F
K
K
F
F
B
F
Yeah
yeah
I
think
that
the
challenge
there
is
that
there
are
a
lot
of
cases
where
the
managers
are
talking
to
each
other
within
the
same
process,
and
they
do
that.
But
under
the
assumption
that
it's
efficient
and
in
fact
one
of
the
nice
things
about
the
sub
interpreters,
is
that
you
can
just
take
a
Python
object
whatever
it
is,
and
you
can
pass
it
across
some
interpreters
because
it's
the
same
interpreter,
if
it
geologists
works,
named
ruff
County
machinery
and
the
same
Gil
and
all
that
stuff.
B
E
K
Eric
snow
did
about
a
proposal
for
multiple
interpreters
in
the
Python
standard
library
and
a
whole
bunch
of
at
even
mentions
that
we're
we're
using
not
a
widely
used
feature.
The
only
documented
cases
are
mod
whiskey,
open
stacks
if
I
shouldn't
say
open
stack
there,
but
anyway
and
and
JD
please
so
ever.
K
F
Wonder
also
so
that
the
thing
that
I
remember
most
about
the
read
that
I
participated
in
this
is
like
a
year
ago,
the
Python
list
about
birds.
The
cyclone
list
was
an.
They
are
basically
saying.
Some
interpreters
are
horribly
broken,
because
some
Python
modules
will
use
C
libraries
and
C
libraries.
I'd
have
shared
global
state,
though.
Therefore,
everything
will
break
just
about
interpreters
at
all,
which
annoyed
me
because,
like
the
particular
Python
modules
that
we
care
about,
don't
do
that
but
sort
of
going
the
other
direction
back
to
a
single
interpreter
and
some
Interbike
one.
F
One
instance
is
that
it's
basically
the
same
problem
except
I'm,
poorly
written
on
modules
that
don't
let
you
instantiate
multiple
instances.
They
have
global
state
and
so
I
wonder
if
this
is
basically
pushing
people
towards
using
better
Python
libraries.
And
if
you
do
use
a
bad
one,
you
can
only
do
it
once
only
one.
F
B
F
Yeah
I
guess
nice.
It
would
be
to
wait
and
see,
hopefully
Saipan
I
found
whatever
it
does
something
nice
either
making
some
interpreters
work
better
or
multiple
interpreters,
but
in
the
worst
case
scenario,
where
they
don't
do
that,
and
we
can
do
sort
of
plan
D,
which
is,
you
know,
eliminate
multiple
users
of
poorly
written
Python
modules,
yeah.
H
G
F
K
Well,
as
a
concrete
action
item,
I'll
go
and
read
that
pept
that
I
linked
and
see
if
I
can
find
out
anything.
So
you
see
what
I
can
find
out.
Maybe
I'll
have
a
chat
with
Erics
now
and
see
if
I
can
find
out
anything
more
from
upstream
Python
folks
about
what
they
think
about
this
sort
of
thing
and
and
yeah
I
agree,
let's
just
sort
of
was
what
you
said:
Serge
about
moving
forwards
cautiously
optimistically.
Oh.