►
Description
Presented by: Jeff Layton
A
All
right,
so,
thanks
for
coming
to
my
talk,
I've
been
started,
work
on
a
project,
maybe
around
a
year
ago,
thinking
and
to
do
some
basically
plumbing
at
the
script
support
which
I'll
talk
about
here
in
a
bit.
I
thought-
maybe
this
would
take
me,
like
you,
know
two
three
weeks,
maybe
a
month,
to
throw
together
a
prototype,
but
here
I
am
about
it.
You
know
a
year
later
and
I'm
about
halfway
through
so
so
any
case.
So
what
is
that
script
right?
A
Well,
it's
a
a
kernel
library
that
file
systems
can
call
into
to
support
transparent
encryption,
so
it
will
encrypt
file
names,
the
contents
for
files
and
sim
link
targets.
The
thing
operates
at
the
file
system
level.
So
you
know
we
lots
of
us
have
locks
and
stuff
on
our
laptops
and
things
like
that.
This
is
not
like
that.
You
don't
need
a
key
to
mount
or
anything
like
that.
A
You
just
can
you
need
a
key
to
access
and
work
within
a
tree
that
is
encrypted,
so
it's
not
a
layered
file
system
like
ecryptoffs
or
anything
like
that.
Either
we
tried
to
go
down
that
road
in
a
lot
of
cases
on
network
file
systems
and
it
turned
out
to
be
a
real
disaster,
layering
on
with
the
encrypted
layers
quite
difficult.
A
A
A
So
if
you
that
allows
you
to
ensures
that
you
know,
even
if
you
lose
the
keys
for
the
tree,
you're
working
in
you
can
at
least
clean
out
that
directory
and
get
your
space
back,
but
you
won't
be
able
to
do
anything.
You
know
of
value
with
that
data.
At
that
point
it
also
includes
a
user
land
utility,
it's
written
in
golang,
but
and
it
stores
a
little
bit
of
per
fs
data
in
a
dot
fs
crypt
directory
at
the
root
of
the
file
system.
A
So
this
thing
generates
master
keys
for
your.
You
know
when
you
go
to
encrypted
directory
and
then
it
uses
diode
cuddles
to
to
manage
them
to
hand
them
off
to
the
to
the
to
the
kernel
to
do
its
thing,
and
so
you
have
a
sort
of
general
workflow
with
this
tool
you
episcopa
init,
which
does
some
per
machine
metadata
setup.
A
Key
to
all
this,
we
have
to
store
a
little
bit
of
per
inode
data
for
each
free
china,
there's
about
a
40,
byte
blob
that
gets
associated
with
it,
and
it
has
a
little
bit
of
info
in
it.
Some
content-
and
you
know
the
content
file
name
encryption
modes
for
this
inode
aes-
is
usually
the
standard
one,
but
there's
some
other
alternatives.
A
They're,
a
little
more
exotic
and
there's
the
flags
field
for
future
future
use,
there's
master
key
id,
which
tells
you
which
trees,
which
master
key
to
use
that
is
used
for
this
particular
inode.
And
then
you
have
a
knots
which
is
a
blob
of
random
data
so
that
we
ensure
that
you
know.
Even
if
you
have
two
inodes,
that
are
identical,
where
the
content
is
identical.
A
A
So
I
stepped
back
and
redesigned
some
of
this
work,
and
so
now
what
we
have
is
a
new
fs,
crypt
auth
attribute
that
hangs
off
of
the
inode
in
the
mds,
and
so
this
thing
lives
under
off
caps
for
those
of
you
that
are
familiar
with
ceph.
You
know
that
it
breaks
up
under
metadata
into
you
know
being
under
certain
caps,
and
this
thing
is
just
an
opaque
blob
of
variable
length.
So
the
mds
never
really
looks
at
this.
It
just
carries
it
around
back
and
forth
to
the
client.
A
So
when
you,
when
we,
when
we
encrypt
a
file
name,
we
get
you
know
it
does
it
by
byte
exchange
for
the
for
the
you
know
of
the
data
you
know,
based
on
the
encryption
algorithm
and
those
fights
that
you
get
back
can
often
be
unprintable
or
they
may
be
illegal
too.
You
might
get
slash
in
there
or
a
null
stuff
like
that.
It's
not
they're,
not
legal
characters
and
file
names,
and
so
what
we
do
is
instead
we
to
ensure
that
that
doesn't
happen.
It's
not
a
problem
for
us.
A
A
So
what
we
do,
what
it
does
actually
or
what
fscrip
does
is
that
base64
encodes,
the
first
149
bytes
of
the
name.
It
prepends
that
actually
with
a
another
couple
of
words
that
it
uses
for
to
store
directory
index
information,
and
then
we
shot
256
hashes
the
rest.
So
you
end
up.
You
know,
after
all,
that
you
end
up
with
this
name.
A
That's
252
characters
max
and
that's
will
always
fit
in
the
name
max
field,
so
for
fs,
so
f
script
has
its
own
handling
for
this.
It
has
its
own
internal
version
of
it
and
that,
but
the
problem
is
that
that's
an
internal
implementation
and
it's
subject
to
change.
We
didn't
wanna.
I
I
wanted
to
be
able
to
store
file
names
on
the
mds
in
the
same
way
that
they
would
be
presented
when
you
didn't
have
keys
that
way.
A
A
So
it's
a
little
bit.
It
allows
for
a
little
bit
longer
base64
encoded
part,
but
it's
basically
the
same,
but
it
also
gets
us
up
to
252
characters
max,
so
the
mbs
still
needs
to
carry
the
you
know
the
catch
is
that
even
if
you
do
this,
you
can't
just
ignore
the
actual
full
length
name
of
the
file
right.
You
know
if
we
create
this
really
long
file,
name
and
hash,
the
last
parts
of
it.
A
We
can't
go
backwards
to
go
from
that
to
get
the
actual
file
name
right,
so
the
mbs
still
has
to
carry
those,
and
so
we
added
a
new
pert
entry
alternate
name
field.
So
that's
a
new
feature.
That's
been
added
to
the
mbs
and
essentially
what
mbs
again
treats
this
is
as
an
opaque
blob
and
the
client
uses
it
to
store
the
full
encrypted
name,
but
it
doesn't
bother
base64
encoding
it
because
it's
considered
to
be
a
not
it's
not
string
data,
so
we
just
store
the
full
encrypted
name
in
there.
A
We
only
do
this,
however,
for
names
that
are
very
long,
so
you
know.
If
we
can,
you
know
if
we
don't
have
to
hash
the
end
of
it,
then
we
don't
need
don't
bother
with
storing
this
alternate
name
that
cuts
down
the
storage
requirements
a
little
bit,
so
the
content
encryption
is
still
so.
Basically,
the
filename
encryption
part
is
basically
done.
A
I
have
a
little
bit
more
work
to
do.
There's
some
work
to
be
done
in
the
on
the
mds
side.
I've
got
some
bugs
I'm
chasing
down
in
the
in
the
mds
patches
for
this,
but
the
kernel
code
is
essentially
done
for
this,
but
content
encryption
is
still
very
much
a
work
in
progress,
so
content
encryption
turns
out
to
be
a
little
trickier
than
you'd.
A
Think
so
you
know
all
most
of
this
is
using
aes
encryption
right,
an
aes,
mostly
a
block
based
cipher,
and
so
we
have
to
be
able
to
deal
with.
You
know
actual.
You
know
full
blocks
of
data
whenever
we're
dealing
with
it
we're
dealing
with
the
content
so
that
you
know,
if
we
were
doing
this,
we
effectively
have
to
turn
cephaves
into
a
block
based
file
system.
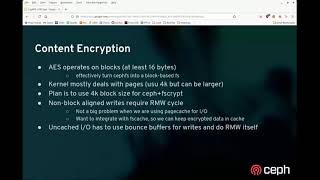
A
That
needs
at
least
a
16
bytes
blocks
to
be
able
to
encrypt
script
well,
and
the
kernel
mostly
deals
with
pages,
which
are
usually
4k,
but
they
can
be
larger,
so
our
plan,
you
know
at
least
the
initial
plan-
is
to
use
a
4k
block
size
for
7ft
script.
That'll
double
tail
with
nicely
with
the
page
cache
on
most
machines
and
most
people
are
not
gonna,
run
with
pages
that
are
smaller
than
that.
So
it
makes
it
a
little
simple,
but
you
know
the
catch
here.
A
A
A
You
still
have
this.
We
still
have
to
do
a
read,
modify,
write
cycle
on
the
block,
which
is
tricky
right,
but
it
turns
out.
We
can
do
this
with
rados,
because
rados
has
a
scheme
to
be
able
to
read
a
block
of
data
and
we
can
grab
the
version
number
for
the
osd
from
the
osd
object
and
then
you
know
modify
right.
You
know,
write
it
back,
but
gate
that
right
on
the
on
the
version
not
having
changed.
A
So
that's
probably
what
we'll
end
up
having
to
do
in
the
uncached
case.
The
cash
case
is
already
sort
of
designed.
This
way,
because
the
current
deals
and
pages
in
a
very
similar
fashion,
so
for
I'm
cached,
I
we'll
have
to
use
bounce
buffers
for
rights
and
and
we'll
have
to
do
all
the
read,
modify
right
work
ourselves.
A
It's
a
fair
bit
of
work
but
there's
another
problem,
and
that
is
that
truncation
on
the
in
cfs
is
handled
by
the
mds.
You
know
when
you
go
to
truncate
a
file,
we
you
know
the
mds
just
goes
and
finds
the
objects
and
it
deletes
whatever
objects.
You
fall
off
the
end
of
the
file
and
we'll
just
you
know,
truncate
the
object
at
the
end
of
the
file
or
you
know
whatever
it
needs
to
do
for
that.
A
But
that's
a
problem
for
you
know,
that's
the
problem
with
the
with
f
script.
Right
I
mean
we
do
not
want
the
nds
to
truncate
off
half
of
a
block,
because
at
that
point
the
end
of
the
you
know.
That
block
would
not
be
scriptable
anymore,
so
we
really
have
to
think
about,
but
now
other
things
that
we
don't
want
to
enshrine.
A
So
in
any
case,
we
have
two
size
values
we
have
to
deal
with.
We
have
the
actual
length
of
the
file
right.
You
know,
you
know
the
inode
eye
size
value,
the
value
you
get
back
when
you
stack
the
thing,
but
then
we
also
have
the
amount
of
data
that's
on
the
osdds,
which
basically
that
same,
I
know
size
value
rounded
up
to
the
end
of
the
crypto
block,
and
the
mds
really
only
cares
about
the
last,
the
latter
one
right,
you
know
it.
A
You
know
as
far
as
it's
concerned,
all
this
is
opaque
data.
It
doesn't
care
that
the
the
the
eye
size
is
a
little
smaller
inside
that
block
because
it
can't
see
in
there
anyway.
So
the
solution
we've
got.
Is
we
added
yet
another
new
opaque
field
that
can
hold
the
real
size
so
that
this
is
what
we
will
get
our
eye
size
from
and
then
the
any
place
that
we
would
send
the
size
to
the
mds?
A
We
will
just
send
up
the
round
rounded
up
value.
So
in
case
we
add
this
thing
to
the
nfs
script
file
field,
which
is
under
fsx
caps
file.
Caps
mds
treats
this
value
as
opaque,
so
you
know,
and
basically
the
plan
is
just
to
stuff
the
size
in
there
and
whenever
we
get
a
new
size
from
the
mds,
we
should
get
one
of
these
two
and
then
the
client
can
just
you
know
substitute
that
in
as
it
needs
it,
we
may
even
be
able
to
take
this
size
field
and
encrypt
it
as
well.
A
A
A
A
What
it
cares
about
is
being
fed
the
appropriate
keys,
so
you
could
foresee
something
like
you
know:
kubernetes,
using
a
different
scheme
for
encrypting
these
directories
and
feeding
keys
into
the
kernel,
but
any
case
now,
let's
make
a
new
directory
grouped
okay,
so
that's
done
and
now
we
can
fscript
encrypt
that
directory,
so
we're
gonna,
and
so
you
can
have
some
there's
different
schemes.
You
can
use
right,
you
can
hand
it
a
you
know:
login.
A
A
A
So
we
have
all
this
in
there,
and
so,
if
you
go
and
look
on
another
client,
we
would
see
scrambled
file
names
here
so
I'll.
I
could
just
pull
up
another
client,
but
I
can
also
do
this.
I
can
just
fs
critical
lock,
so
I
can
just
now
lock
the
directory
and
if
we
go
into
crypt
now-
and
we
see
gibberish
names
right
got
this-
you
know,
but
you
know
the
interesting
bit
right
is
that
if
we
stack
these
things
right,
you
know
whatever
this
guy
is.
This
is
the
directory.
A
A
Sizes
are
also
the
same,
though
that
may
be
a
little
different
once
we
implement
content
encryption,
but
but
the
file
names
themselves
are
scrambled
and-
and
basically
this
will
happen
for
you
know
for
anything
that
is
created
below
this
point
in
the
tree,
so
they
will
all
share
this
sort
of
stuff
in
any
case,
and
then
you
could
also
come
back
on.
Fpscript
mock
script.
A
A
I
can't
actually
do
anything
right
now
with
blocked,
but
in
any
case
so
yeah
I
mean
this
is
basically
where
we
are
with
it.
The
content.
Encryption
is
still
a.
You
know,
work
in
progress,
I'm
looking
to
hoping
to
get
this
all
finished
up
for
quincy
and
I
think
that's
probably
possible,
and
I
think
this
is
actually
a
pretty
compelling
feature.
You
know
one
of
the
problems
you
know
there's
a
lot
of
hosting
providers.
A
People
like
that
that
would
like
to
be
able
to
you
know,
create
a
self-effects
volume
or
a
chunk
of
a
tree
and
hand
it
to
a
customer,
but
you
know
customer
might
be
understandably
wary
about
putting
sensitive
data
on
on
that
share,
given
that
it
would
not
be
hideable
from
you
know
like
the
admins
at
that
of
that
hosting
provider.
But
with
this
you
know
you
don't
even
need
root
to
be
able
to
encrypt
directories
and
stuff.
A
You
just
need
to
have
access
to
a
file
system
that
supports
it,
and
you
know,
even
as
an
unprivileged
user,
you
can
create
a
directory
tree
and
as
long
as
you
have
control
over
the
client
yourself,
you
know
you
reasonably
sure
that
that
no
one's
gonna
be
able
to
get
into
that
data.
You
know
released
against
most
threat
models
so
anyway,
that's
about
all
I've
got.
Anybody
have
questions,
looks
like.
A
A
Oh
someone
says
maybe
interesting
to
create
this
smv
module
that
offers
this
functionality
for
smb
shares.
Yeah,
I
mean
this
is
a
generic
kernel
feature.
You
know
I'm
kind
of
implementing
it
in
seth
right
now,
but
eventually
I
can
see
other
other
file
systems.
Picking
this
up.
I
know
david
howells
is
looking
at
some
more
are
looking
at,
maybe
adding
this
to
to
afs.
We
may
also
see
if
we
can
do
this
for
nfs
so
yeah.
A
This
is
something
that
could
be
done
on
other
types
of
file
systems
as
well,
but
you
know
the
catch
is
that
there
are
some
there's
some
trickiness
involved
with
you.
You
know
like
extra
long
file
names
and
such
you
need
to
be
able
to
support
that
somehow.
So
you
know
there
are
some:
it's
not
trivial
to
go
and
do
this
for
another
file
system,
and
it's
not
even
it's
not
trivial.
To
do
this
for
sephie,
there's
taking
me
quite
some
time
to
get
it
done.
A
So
I
have
a
pat
a
bunch
of
patches,
maybe
30
or
so
patches,
and
they
there's
a
little
bit
of
dfs
functionality
that
needs
to
be
exposed
for
modules.
A
little
bit
of
the
fs
crypt
infrastructure
that
needs
tweaking
for
this,
not
not
heavy
and
most
of
it,
it
seems
to
be.
I
don't
think
that
part
will
be
very
controversial,
but
the
seth
patches
are
quite
invasive,
so
they
really
rip
apart
a
lot
of
the
of
the
path,
walking
code
paths
and
things
like
that
place.
A
A
Very
very
early,
I
did
some
work.
I
have
a
at
least
a
few
patches
kind
of
going
down
this
route,
and
but
you
know
I
kind
of
got
started
working
on
it
and
then
I
figured
out.
Oh
no,
we
have
this
problem
with
truncation,
and
so
I
haven't
done
any
of
the
work
to
plumb
in
support
for
that.
I'm
really
still
working
on
the
best
patches
for
all
this,
so
it'll
be
a
while
before
that's
done.
A
A
A
All
right,
no,
if
not,
then
thanks
for
your
time,
everybody
all
right.
Thank
you,
jeff.
Thank
you
for
providing
a
demo
as
well
yeah.
Well,
it's
it's
interesting
to
see
it
working
I
want
to
you
know.
I
think
this
is
actually
quite
you
know.
There
are
a
lot
of
real
use
cases
for
this
and
feel
a
really
killer
feature
for
stuff,
and
you
know
other
file
systems
if
they
get
it.
You
know.
A
We
don't
want
them
sniffing
and
sleeping
through
the
cache
to
be
able
to
figure
out
what
it
is.
So
that's
a
big
part
of
this
is
there's
a
lot
of
re-engineering
going
on
in
general
in
the
data
path,
and
that's
one
of
the
reasons
I
haven't
tackled
it
yet,
but
that's
coming
next.
You
know
once
I've
finished
up
the
last
bits
of
the
of
the
file
name
portion
anyway,
yeah
thanks
everybody
for
coming.