►
From YouTube: 2019-JUN-27 :: Ceph Tech Talk - Intro to Ceph
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
A
Why
it's
built
the
way
it
is
how
it
works,
but
are
the
core
concepts?
What
makes
it
different
from
other
systems,
focusing
mostly
on
raitis
the
underlying
storage
later,
but
also
talking
about
the
object,
block
and
file
components
that
are
built
on
top
of
it,
then
we'll
shift
gears
a
little
bit
and
talk
about
how
stuff
is
managed
and
some
of
the
user-facing
features
that
make
it
easy
to
consume.
A
And
finally,
we'll
talk
a
bit
about
the
open
source
community
and
for
ecosystem.
So
what
is
SEF?
It's
been
described
as
software-defined
storage.
As
a
unified
storage
system,
scalable
distributed
storage,
we've
branded
stuff
I
was
the
future
of
storage.
It's
on
a
lot
of
our
t-shirts
and
people
have
also
described
stuff
as
the
Linux
of
storage,
but
all
these
frames
braces
mean
slightly
different
things:
different
people
so
try
to
get
to
the
crux
of
it.
A
I
think
the
first
thing
to
recognize
is
that
stuff
is
open
source
software
emphasis
on
a
software
that
can
run
on
any
commodity
hardware,
so
commodity
servers
from
any
vendor
use
this
typical
standard,
IP
based
networks,
and
we
can
use
all
the
usual
standard
types
of
storage
devices,
hard
disks,
SSDs
in
muse,
Envy,
gems
and
so
on.
And
finally,
it's
it's
important
to
recognize
that
def
is
a
unified
system
in
that
you
can
serve
object,
block
and
file
workloads
from
the
same
cluster
from
the
same
hardware,
using
the
same
software
stack.
A
So
Steph
is
free
and
open
source
software.
That
means
you
have
the
freedom
to
download
and
use
f3.
In
that
sense,
you
also
have
access
to
the
source
code.
It's
open
source,
so
you
can
introspect
look
at
how
the
system
works.
You
can
modify
it.
You
can
share
changes
as
long
as
you
conform
to
the
open
source
software
license.
This
gives
you
freedom
from
vendor
lock-in.
A
You
can
choose
from
many
different
companies
and
organizations
that
are
building
products
and
services
based
on
stuff,
and,
if
you
don't
like
them,
you
can
switch
somebody
else
without
having
to
you
know.
Throughout
your
software
stack
and
by
virtue
of
the
community,
you
also
have
the
freedom
to
innovate
in
the
space
by
integrating
stuff
with
other
software
systems
and
adapting
it
to
your
particular
use
cases
and
workloads.
A
Sep
is
designed
and
built
to
be
reliable.
Our
goal
is
to
create
a
reliable
storage
service
out
of
inherently
unreliable
components,
though
the
architecture
is
designed
with
no
single
points
of
failure.
It
provides
data
durability
via
either
replication
or
erasure
coding
of
your
data,
and
it's
designed
to
be
continuously
available
so
that
you
have
no
interruption
of
service
from
rolling
upgrades
expansion
of
your
plaster
of
your
cluster
contraction
failures
and
so
on,
and
it's
also
reliable
in
the
sense
that
we
as
a
rule,
favor
consistency
of
the
system
over
correct
and
correctness
over
performance.
A
Finally,
stuff
is
scalable.
We
describe
it
as
an
elastic
storage
infrastructure.
That
means
that
your
storage
cluster
may
grow
or
shrink
over
time
as
the
size
of
your
data
sets
or
your
workloads
or
your
overall
requirements.
The
organization
change
over
time
and
you
can
add
and
remove
Hardware
from
the
system
while
it's
online
and
then
load
both
to
deal
with
failure
and
hardware
refresh
in
order
to
also
to
expand
capacity
or
deploy
a
new
different
performance
classes
or
whatever
it
is,
and
we
can
scale
a
number
of
different
ways.
A
So
you
can
scale
up
by
simply
using
faster,
bigger
servers
and
storage
devices.
You
can
scale
out
by
adding
additional
nodes
or
racks
of
nodes
and
more
storage
devices
to
get
more
capacity
and
performance
in
the
system,
and
you
can
also
federate
multiple
clusters
across
multiple
sites,
using
a
set
of
asynchronous
replication
features
for
disaster
recovery
type,
these
cases
and
to
provide
availability
in
the
event
of
a
tie,
an
entire
data
center
site
image.
A
So
our
GW,
the
rate
of
Skateway,
provides
an
s3
compatible
with
compatible
object,
storage,
API
buckets
using
a
restful,
get
input,
type
interface,
RBD.
The
rate
of
block
device
provides
a
virtual
block
device
interface.
This
is
used
very
widely
in
public
and
private
cloud
deployments
and
platforms,
so
virtual
disks
usually
backing
virtual
machines
and
stuff
if
s
is
a
distributed
network
POSIX
file
system
that
allows
lots
of
clients
to
have
a
shared
access,
shared
access
to
a
single
file
system
in
space,
with
your
usual
POSIX
like
semantics.
A
So
in
this
talk,
I'm
going
to
do
sort
of
a
deep
dive
into
how
this
architecture
is
put
together
and
how
it
works,
starting
with
raitis
this
underlying
layer
and
then
moving
on
to
Rios,
Gateway,
brightest
block
device
and
stuff
file
system.
But
let's
start
with
Freitas
raitis
stands
for
reliable
autonomic
distributed,
object
store,
and
this
is
the
common
storage
later
that
underpins
all
the
other
services
and
stuff,
and
it
provides
this
low-level
data
object,
storage
service,
that's
reliable
and
highly
available.
A
That's
scalable
both
when
you're
in
cluster
is
initially
deployed
on
day,
one
these
sort
of
arbitrarily
large,
and
also
on
one
two
three
years
down
the
line
when
you
are
refreshing
hardware
and
expanding
and
deploying
more
storage
and
so
on.
It's
also
scalable
sort
of
after
the
fact
I
mean
ray.
Does
this
job
is
to
manage
all
the
replication
and
erasure
coding
of
the
data
in
the
system
figure
out
where
that
data
should
be
stored
on
what
nodes
and
what
storage
devices
rebalancing
scrubbing
for
integrity
checks?
A
Repair
all
that
stuff
is
handled
by
this
underlying
rate
of
storage
layer.
It's
designed
to
provide
a
strong
level
of
consistency
so
for
those
familiar
with
the
cap,
theorem
Rados
is
a
CP
system.
Not
an
AP
system
and
its
purpose
within
a
larger
stuff
architecture
is
to
simplify
the
design
and
implementation
of
the
higher
layers,
so
that
the
file
block
and
object
components
can
focus
on
the
complexities
and
intricacies
around,
providing
that
particular
type
of
API
we're
all
Rados
can
handle
the
safety
and
availability
of
the
data,
so
Seth
Andrade
us
as
a
software
system.
A
So
it's
comprised
of
a
number
of
different
storage
demons.
The
first
one
is
the
monitor
step.
Monitor
these
monitors
are
a
central
authority
for
authentication
using
for
authentication
data
placement
and
policy
in
the
system,
they're
sort
of
the
central
coordination
point
that
manages
all
the
other
demons
that
participate
in
the
system.
A
They
protect
critical
cluster
state
with
an
algorithm
called
Paxos
and
they're,
typically
somewhere
between
three
and
seven
of
these
per
cluster,
usually
spread
across
different
hosts
or
different
racks,
so
that
you
have
reliability
and
availability,
there's
also
a
set
manager
demon
that
has
two
roles.
The
first
is
to
aggregate
real-time
metrics
about
all
the
demons
that
are
participating
the
system,
things
like
what's
the
current
level
of
throughput.
A
What's
the
current
disk
utilization,
what
are
the
various
internal
metrics
that
all
these
other
suffer
components
are
reporting
aggregate
all
that
so
yup
a
real-time
view
of
what's
happening
and
stuff,
and
the
second
job
is
to
provide
a
host
for
pluggable
management
functions.
Things
like
the
the
dashboard
for
user
management
or
automated
background
tasks
that
are
doing
optimization
and
other
automated
functions.
These
can
all
be
implemented
as
Python
modules
and
are
hosted
inside
the
set
manager.
A
Daemon,
there's
typically
only
one
or
always
actually
only
one
active
manager,
demon
or
cluster,
but
you
usually
will
have
a
number
of
standby
so
that
if
the
first
one
fails
or
the
host
that
it's
running
on
fails,
another
one
can
take
over.
And
finally,
we
have
the
stuff
OSD,
the
object,
storage,
demons.
These
are
the
workhorses
of
a
SEF
cluster
and
their
job
is
to
store
data
on
a
directly
attached,
hard
disk
or
SSD,
and
a
service
IO
requests
to
that
data.
But
these
OS.
A
A
But
all
of
these
design
methods
are
limiting
and
overall
sort
of
limit
the
design
of
the
system
and
limit
the
overall
performance
and
consistency
and
behavior.
So
instead,
I'm
step
is
designed
around
what
we
call
a
client
cluster
architecture,
which
basically
means
that
there
is
an
intelligent,
client
library,
that's
sitting
at
the
application
side.
That
understands
that.
It's
not
talking
to
a
single
server,
but
is
in
fact
talking
to
a
cluster
of
cooperating
servers
and
could
do
intelligent
things
like
smart
requests
for
adding
making
sure
that
IO
requests
are
routed
to
the
correct
node.
A
You
know
manage
the
fact
that
data
might
be
moving
around
in
the
background
and
provide
sort
of
a
seamless
experiment,
experience
for
the
application
and,
at
the
end
of
the
day,
we're
providing
the
same
application
API
as
far
as
the
application
is
concerned.
It's
writing
a
data
object
into
some
logical
construct
and
it's
this
library,
that's
handling
sort
of
the
internal
details
of
where
exactly
that
request
should
be
routed.
A
So
one
of
the
first
questions
when
building
a
system
like
this
is
where,
should
you
store
your
data?
And
how
do
you
know
where
you
put
it?
So
if
you
imagine
an
application
that
wants
to
read
or
write
a
data
object,
it
needs
to
know
where.
To
put
it,
though,
that's
sort
of
a
naive
approach
would
be
to
have
a
metadata
server
that
has
a
big
table
of
all
the
data
objects
and
what
servers?
What
notes
are
stored
on
em?
A
The
problem
with
this
is
that
it
involves
a
separate
lookup
step
if
you're
trying
to
read
an
object,
you
have
to
find
out
where
the
object
is
first
and
then
go
and
contact
that
particular
node.
That's
slow
and
it's
also
hard
to
scale
that
metadata
service
to
trillions
of
objects
when
you're,
storing
many
many
petabytes
of
data,
so
at
many
other
distributed
systems
and
stuff
as
well
to
do
is
something
called
calculated
placement.
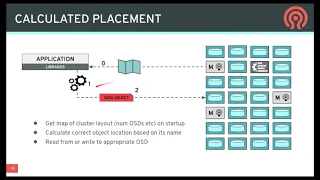
A
So
the
idea
here
is
that
when
the
library
starts
up,
you
get
this
initial
map
I'm
a
concise
description
of
the
structure
of
the
cluster.
What
servers
exist
and
how
data
is
supposed
to
be
laid
out
across
them
and
then,
whenever
you
want
to
read
or
write
a
particular
data
object,
you
do
some
calculation,
that's
a
function
of
the
state
of
the
cluster
and
the
name
of
the
object
and
that
spits
out
the
location
in
the
system
where
that
data
should
be
stored.
A
And
then
you
can
contact
the
appropriate
node
or
demon
in
the
system
and
then,
if
some
time
goes
by,
you
know,
maybe
the
cluster
gets
expanded
and
it
fails
and
data
gets
moved
around.
The
application
can
get
an
updated
version
of
the
topology
of
the
cluster
and
so
later
on,
when
it
needs
to
go,
read
back
that
data
that
a
previously
wrote
it
can
repeat
that
calculation,
it
might
get
a
different
answer,
this
time
and
it'll
go
and
contact
the
appropriate
node
where
that
data
should
be
stored.
A
This
avoids
the
complexity
of
having
that
overall
lookup
table
and
tends
to
scale
very
well
when
your
clusters
are
very
very
large.
But
this
brings
up
the
question
of
what
these
data
objects
actually
are.
So
this
is
the
fundamental
underlying
unit
of
storage
in
Rados
is
an
object,
so
each
object
has
a
name:
/
unique
set
of
characters,
usually
tense
characters
as
some
semantic
meaning.
Presumably
each
object
can
have
some
attributes
associated
with
them.
These
are
sort
of
analogous
to
extended
attributes
in
a
file
system.
A
I
mean
a
or
may
not
need
to
use
them,
but
you
can
have
some
sort
of
lightweight
metadata
associated
with
that
object,
but
the
bulk
of
the
data
that
the
object
is
really
in
the
byte
data
or
key
value
data.
So
the
first
type
of
object
looks
kind
of
like
a
file.
You
can
store
a
bunch
of
bytes
in
it.
Typically,
objects
can
be.
A
All
these
objects
exist
within
sort
of
a
logical
grouping
called
a
pool
so
pools
usually
map
to
some
sort
of
use
case
or
deployment.
So
you
might
have
a
pool
that
contains
all
the
virtual
machine
images
for
your
cloud
hosting
of
the
structure.
You
might
have
another
pool
that
contains
all
the
data
for
a
file
system
that
sort
of
thing,
so
it's
sort
of
a
high
level
large
grouping
of
objects
in
the
system.
A
So
the
question
is:
how
do
we
map?
How
do
we
decide
where
these
objects
should
be
stored
across
the
you
know,
hundreds
thousands
or
tens
of
thousands
of
OSDs
in
the
cluster?
So
if
you
imagine
you're,
storing
all
kinds
of
different
data
and
stuff
right,
it
might
be
disk
images
files,
video
files,
pictures,
let's
assume
for
for
as
an
example
that
we're
storing
a
big
impact
video.
So
the
first
thing
we
would
do
is
break
that
large
video.
A
Maybe
it's
several
terabytes
into
lots
and
lots
of
greatest
objects,
so
a
long
sequence
for
mega
objects
say
and
they're
all
going
to
add
names
that
are,
you
know,
probably
end
with
a
number
or
something
sort
of
this
sequence
of
objects.
And
then,
of
course,
all
of
these
objects
exist
within
a
pool,
so
we're
dumping
all
this
video
data
into
a
single
rate
of
spool,
and
so
when
you
do
this
with
lots
and
lots
of
videos,
you
end
up
with
a
pool
that
has
bazillions
of
objects,
millions,
billions
trillions.
A
A
4096
in
this
particular
example,
different
placement
groups
that
are
comprising
this
pool
so
that
each
placement
group
has
you
know
some
fraction
of
the
total
objects
of
the
pool
and
and
those
objects
map
into
placing
groups
in
a
deterministic
way
and
finally,
for
each
of
those
placement
groups
used
to
these
sort
of
fragments
of
your
overall
data
set.
We
have
to
store
it
on
multiple
devices
for
redundancy.
So
in
a
3,
X
replication
type
scenario,
then
each
of
these
plates
and
groups
would
be
but
a
Steudle
randomly
assigned
to
three
different
toasties
in
the
system.
A
But
these
are
small.
We
have
a
lot
more
placement
groups
than
we
have
OSD.
So
if
you
sort
of
look
at
this
from
the
other
perspective,
if
you
consider
one
single
storage
device,
it's
actually
going
to
store,
you
know
tens
or
maybe
around
a
hundred
different
place
in
groups
that
might
be
all
from
the
same
pool
or
might
be
different
pools
or
whatever.
So
each
OS
D
growing
lots
of
different
chucks
chunks
of
the
overall
data
set
over
all
pools,
placing
groups
that
are
stored
within
the
sub
cluster.
A
So
you
might
be
asking
why
do
we
have
this
sort
of
intermediate
stage?
Why
don't
we
just
sort
of
assign
objects
to
storage
devices
and
there
a
couple
of
reasons
for
this,
but
it's
helpful
to
look
at
what
the
alternative
design
options
might
be
in
this
case,
so
in
sort
of
the
simplest
approach
you
could
simply
choose
to
replicate
disks
in
your
system
right.
A
You
could
take
all
of
your
disks
there
doing
three
rare
replications,
so
you
have
a
bunch
of
sets
of
three
disks
and
these
disks
are
simply
all
replicating
the
same:
identical
identical
content,
so
sort
of
raid
zero
or
raid
one
type
configuration
the
first
limitation.
You
notice
is
that,
in
order
to
do
this,
all
these
disks
have
to
be
exactly
the
same
size,
or
at
least
you
can
only
use
sort
of
the
smallest
size
of
three
disks.
A
That's
a
bit
of
a
limitation,
but
maybe
you
can
get
past
that
if
you
instead
replicate
placing
groups,
for
example,
though,
things
are
a
bit
better
because
you
have
each
individual
placement
group,
you
can
sort
of
randomly
choose
which
devices
it's
assigned
to
and
they're
sort
of
spread
around.
You
can
have
different
size
devices,
because
the
smaller
devices
might
just
have
fewer
placement
groups
and
the
larger
devices,
but
it's
a
bit
more
flexible
in
that
sense.
A
And
finally,
you
can
imagine
taking
this
to
an
extreme
where
you
take
every
single
object
in
the
system
and
you
sort
of
randomly
map
that
to
different
devices,
and
you
end
up
with
a
situation
where
sort
of
every
set
of
posties
or
disks
in
the
system
is
sort
of
sharing
replicas
data
with
every
other
disk.
So
you
have
a
sort
of
a
tightly
fully
connected
mesh
of
storage
devices.
A
So
let's
look
at
what
happens
when
a
disk
fails.
So
in
the
disk
replication
scenario,
if
the
disk
fails.
The
first
thing
you
notice
is
that
you
have
to
have
a
spare
device,
that's
empty
and
totally
unused
in
order
to
do
a
repair
and
then
also
that
spare
has
to
be
sort
of
the
appropriate
size
so
that
you
can
make
a
new
copy
of
the
failed
data
onto
new
disks
to
compensate
for
the
fact
that
you
lost
one.
So
this
is
a
couple
of
problems.
First,
you
have
to
have
these
spares
around.
A
They
have
to
give
you
the
right
sizes
and
before
the
failure,
the
other
idle
disk-
that's
not
being
used,
you're
essentially
wasting
that
resource,
and
the
second
thing
is
that
the
recovery
process
is
bottlenecked
by
the
throughput
of
a
single
disk.
So
you
can
only
recover
as
quickly
as
this
thing
as
this
replacement
disk
can
write.
A
Its
data
or
the
source
can
read
its
data
and,
as
we
know,
hard
disks
are
getting
bigger
faster
than
they're
getting
faster,
which
means
that
the
recovery
time
for
a
single
disk
is
getting
longer
and
longer,
which
means
that
you
have
a
wider
Wender
window
of
vulnerability
during
which
sort
of
the
durability
and
replication
count.
That
data
is
somewhat
compromised.
So
that
can
be
problematic
in
the
case
of
placement
groups.
A
It's
a
little
bit
better
because
you
notice
that
when
we
lose
a
disk,
we
have
copies
of
the
loss,
placement
groups
on
lots
of
different
devices,
and
we
can
choose
new
location
for
those
placement
groups
that
are
independent
and
also
pseudo-random,
so
that
the
you
know
this
cream-colored
one
can
replicate
to
one
node
and
the
blue.
One
can
replicate
your
different
node,
and
so
you
suddenly
have
a
parallel
recovery
process,
so
both
of
these
pieces
are
recovering
in
parallel.
It
will
happen
twice
as
fast
in
the
extreme
you
can
imagine.
A
If
there
were
a
hundred
placement
groups
on
that
failed
disks,
they
could
go
a
hundred
different
disks
recovering
in
parallel,
going
taking
one
one-hundredth
at
the
time
and
also
you'll
notice
that
we
didn't
need
a
spare,
as
we
can
simply
move
these
placement
groups
to
do
the
remaining
sort
of
empty
space
on
the
surviving
nodes
in
the
cluster.
So
that
means
that
all
of
our
hardware
is
being
utilized
at
all
times.
A
It
should
work
the
larger
problem
with
that
scenario
or
what
that
strategy
comes
when
you
think
about
what
happens
when
you
have
a
concurrent
failure.
So
if
you
imagine
that
you're
very
unlucky
and
not
just
one
device
filled
the
three
device
devices
failed
at
the
same
time,
what
happens
so
in
the
original
scenario?
A
Where
you
have
these
sort
of
replica
sets
of
three
it's
most
likely
that
if
three
devices
failed
they're,
not
all
gonna,
be
from
the
same
replica
set,
they're
gonna
be
spread
across
different
replica
sets,
and
so
you're
never
gonna
lose
or
very
rarely
are
you
going
to
lose
all
three
replicas
of
the
same
data
and
actually
I'm
data
loss?
Usually
it's
going
to
be
spread
across
different
wrote,
the
cassettes
and
you'll
be
able
to
recover
so
very
few.
Triple
failures
caused
a
loss.
A
On
the
other
hand,
though,
if
you
think
about
the
scenario
where
we
were
replicating
individual
objects,
because
we
have
a
gazillion
different
objects
and
they're
all
randomly
placed
pretty
much.
Every
set
of
three
devices
within
this
cluster
has
some
data
that
is
replicated
on
those
just
on
those
three
nodes,
which
means
that
there's
pretty
much
always
going
to
be
some
data
loss.
A
It
might
not
be
very
much,
but
there
you're
always
going
to
lose
some
data
and
that
can
be
particularly
problematic
when
sort
of
the
integrity
of
an
overall
data
set
depends
on
having
all
the
data
I'm
not
sort
of
having
some
random
subset
of
it
disappearing
and
hoping
that
the
rest
of
it
will
still
hang
together.
So
that's
very
concerning
and
then,
if
you
look
at
placement
groups
and
then
it's
sort
of
somewhere
in
between
right,
so
some
triple
failures.
A
But
it
turns
out
that
the
sort
of
placement
group
strategy
is
a
balance
of
these
competing
extremes.
So
in
the
academic
literature,
this
was
described
as
D
clustered
replica
placement
and
it's
this
basic
trade-off.
So
if
you
have
more
clusters
more
placement
groups,
then
you
have
faster
recovery
and
a
more
even
data
distribution.
And
if
you
have
fewer
clusters,
if
you
have
fewer
placement
groups,
then
you
have
a
lower
risk
of
concurrent
failures,
leading
to
data
loss
event
and
having
using
the
strategy
with
placement.
A
Groups
is
a
happy
medium
because
you
can
avoid
the
spare
devices
and
you
can
adjust
by
adjusting
the
number
of
placement
groups.
You
can
sort
of
choose
what,
where
you
want
to
be
on
that
on
that
spectrum
in
either
extreme
as
a
the
perfect
world.
But
you
can
sort
of
have
this
balance
and
durability
in
the
case
of
conquering
failures
and
the
recovery
time
that
you
want
to
tolerate,
and
when
you
do
that,
then
sort
of
having
a
complete
strategy
to
keep
your
data
safe
is
really
then
around.
A
Avoiding
those
concurrent
failures
in
the
first
place
or
ensuring
that
when
concurrent
failures
do
happen,
they
don't
lead
to
data
loss
and
the
way
to
do
this
is
to
separate
your
replicas
of
your
data
across
its
failure
domains.
And
so,
for
example,
you
might
have
a
rack
cluster
that
comprised
of
hosts
organized
into
racks,
racks
and
rows
rows,
no
data,
centers
and
so
forth.
A
By
having
that
infrastructure
aligns
to
sort
of
the
physical
placement
of
those
devices
in
space,
then
you
try
to
correlate
those
failures
with
the
failure
domain
and
minimize
the
risk
that
you'll
have
just
simultaneously
failing
that
are
in
different
racks.
That
might
be
sharing
the
same
and
so
the
challenge.
Then
the
real
question
is
how
to
question
you
this.
How
do
we
have
this
like
magic
policy
that
places
all
these
bazillions
and
placed
in
groups
across
devices
that
respects
this
buyer,
to
have
replicas,
separated
across
failure,
domains
and
so
on?
A
Do
all
the
things
you'd
want
to
do
in
a
real
store
system,
and
then
the
answer
is
with
an
algorithm
that
we
call
crush
so
crush.
Is
a
pseudo-random
placement
algorithm,
it's
repeatable,
deterministic
calculation,
a
function
of
the
state
of
the
cluster
and
the
name
of
the
object
that
spits
out
where
the
data
should
be
stored.
So
the
inputs
are
the
topology
of
the
system
so
that
hierarchy,
that
I
was
talking
about
how
osts
are
organized
under
hosts
and
racks
and
rows,
and
so
on.
A
The
pool
parameters
like
the
replication
Factory
and
are
my
placement
policy
and
then
the
identifier
for
the
placement
group
that
I'm
measuring
in
a
store-
and
you
put
all
that
into
crash.
That's
some
calculation
and
it's
it's
out
a
number
as
essentially
not
a
number,
but
an
order
list
of
which
OS
DS
that
they
sent
group
should
be
stored
on
and
then
that's
where.
That's,
where
you
going
to
put
your
data,
and
so
as
part
of
this,
these
pool
parameters
crush,
allows
you
to
write,
rule-based
policies
that
describe
how
those
replicas
should
be
placed.
A
So
you
can
do
things
like
say
you
know:
I
want
three
relic
dozen
different
wrecks.
Maybe
I
only
want
to
use
SSD
devices,
that's
one
of
the
inputs
to
the
function
and
spits
out
which
devices
to
use
at
the
end.
You
can
have
something
more
complicated
like
if
you're,
using
erasure
coded
scheme,
that's
six
plus
two,
so
you
have
eight
sort
of
shards
of
your
data.
Maybe
I
want
to
have
two
of
those
shards
per
rack
spread
across
four
racks,
but
of
those
two
shards
that
are
within
a
particular
rack.
A
I
want
those
to
be
separated
across
different
hosts
and
I
only
want
to
use
hard
disks.
Something
like
that.
It's
also
possible
one
of
the
key
properties
of
crush
is
that
it
generates
what
we
call
a
stable
mapping.
So
that
means
that
if
you
have
a
particular
state
of
the
cluster
with
some
set
of
devices
and
there's
some
topology
change
like
a
node
is
added
or
a
device
fails
or
something
like
that.
A
Then
we
want
the
amount
of
data
that
has
to
move
in
order
to
rebalance
the
distribution
to
be
proportional
to
the
size
of
the
change
made.
So,
for
example,
if
I
have
a
hundred
nodes
and
one
node
fails,
then
roughly
one
percent
of
the
data
is
going
to
move.
So
when
I
repeat
my
crush
calculation
with
all
the
existing
placement
groups
and
find
out
where
they
should
be
stored.
A
Now,
given
the
new
state
of
the
system
about
1%
of
those
placement
groups
will
be
mapped
to
different
OSTs
and
will
requires
some
sort
of
data
movement,
data
movement,
and
so
that's
a
very
important
property
with
storage
in
particular,
because
moving
data
around
is
very
expensive
and
finally
crush
supports
bearing
device
sizes.
So
every
device
in
this
hierarchy
has
a
weight
and
that
weight
determines
the
sort
of
proportional
amount
of
data
that
will
be
stored
there.
A
So
that's
Crush,
that's
sort
of
the
magic
that
that
figures
out
where
all
the
data
in
systems
could
go,
and
everybody
can
repeat
this
calculation
and
figure
out
out
where
to
read
her
to
write
data.
The
challenge,
then,
is
what
should
raid
us
then
do
once
it
knows
where
it's
where
the
data
should
go,
how
does
it
actually
store
it
and
two
strategies?
So
all
the
objects
that
are
stored
in
a
pool
have
to
be
durable.
We
have
to
make
sure
they're
safe.
A
Those
pools
are
broken
up
in
the
placement
groups,
so
each
individual
placement
group-
you
know
some
subset-
that
the
overall
data
has
to
be
durable
in
some
way
and
we
have
two
strategies
for
doing
that.
I'm.
In
the
case
of
replication,
we
simply
stamp
out
copies
of
placing
group.
So
if
we
imagine
this
PG
as
two
different
objects
in
it,
we
just
have
three
different:
no
SDS.
We
store
a
copy
of
this
placing
group
on
each
of
those
those
these
and
each
OSD.
A
A
A
So
if
I
want
to
go
from
three
role
because
to
five
replicas
I
can
just
you
know,
flip
a
switch
in
the
pool
and
rate
us
will
go
off
and
start
creating
new
copies
of
these
keys
and
finding
new
places
to
store
them,
and
that's
all
fine,
it's
really
quite
straightforward.
Our
researcher
coding
is
a
different
reliability
strategy
and
it
works
very
differently
in
that,
instead
of
having
identical
copies
of
placement
groups.
Instead,
we
have
different
shards
different
slices
if
you
will
of
the
same
placement
group.
A
So
if
the
placement
group
logically
contains
a
number
of
objects
in
this
example,
which
is
a
four
plus
two
scheme,
we
would
have
four
shards
and
half
of
the
data.
That's
striped
over
those
four
shards
in
a
way,
and
then
we
would
have
two
additional
shards
that
have
some
sort
of
parity
and
redundancy
information.
So
this
is
really
what
raid
is
doing.
A
A
richer
coding
is
sort
of
a
generalization,
a
more
flexible
version
of
what
raid
does,
and
so
we
have
these
additional
I'm
components
that
provide
some
redundancy
so
that,
if
I
lose
either
one
or
two
of
these
different
shards
I
can
always
read
the
read
the
surviving
pieces.
Do
some
calculation
and
rebuild
the
data
and
you'll
notice
that
eraser
coding
is
much
more
storage
efficient.
So
these
first
four
shards
have
a
complete
copy
of
the
original
data
and
then
I
have
two
additional
shards.
A
So
I
have
sort
of
a
50
percent
storage
overhead
to
provide
a
level
of
redundancy
that
allows
me
to
lose
two
different
devices
and
still
have
a
full
copy
of
my
data
or
be
able
to
rebuild
my
data.
You'll
notice
that
in
the
3x
replication
case,
I
can
also
only
survive.
Two
node
failures,
there's
two
copies
and
still
others
arriving
a
copy,
but
the
overall
storage
overhead
is
3x.
So
this
is
one
copy
of
the
data
and
I
have
sort
of
a
200%
overhead
versus
a
50%
overhead,
so
wrist
recording
is
much
more
space
efficient.
A
Unfortunately,
it's
less
efficient
when
you're
doing
recovery,
because,
as
I
mentioned
with
replication,
you
can
just
read
any
surviving
copy
and
then
write
it
again
and
that's
pretty
straightforward
in
a
racial
coding
case,
if
I
lose
one
of
these
shards
I
have
to
read
all
of
the
surviving
shards
and
do
some
calculation
in
order
to
generate
regenerate
that
one
additional
shards.
So
it's
significantly
more
expensive
in
terms
of
that
work.
Bandwidth,
then
storage
IO,
but
it
works
well,
particularly
for
datasets,
where
you
have
large
objects
that
aren't
changing
very
often
and
then
radius.
A
Of
course,
support
allows
you
to
store
lots
of
different
pools
in
your
cluster,
and
so
you
can
have
multiple
specialized
pools
living
within
the
safe
cluster
that
have
different
storage
policy,
so
you
might
have
a
replicated
pool.
You
might
have
an
eraser
coated,
pools,
some
of
them
using
hard
disks
and
be
messy
using
SSDs
and
so
on,
based
on
those
those
quests
crushed
policies.
A
Now
by
default
and
in
most
cases
all
of
these
pools
in
the
system
X
by
will
normally
just
share
devices,
so
each
pool
is
being
broken
up
into
placement
groups
and
then
they're.
All
things
that
are
randomly
spread
across
the
u.s.
DS
in
the
system,
unless
you
are
specifically
specifying
a
policy
that
specifies
SSDs
or
her
gist's
or
something
like
that.
But
this
sort
of
mapping
between
the
logical
pools
and
the
physical
storage
devices
means
that
you
have
elastic
and
scalable
provisioning.
A
So
you
can
a
pool,
can
sort
of
contain
either
a
little
bit
of
data
or
effectively
infinite
amount
of
data.
As
long
as
you
can
provision
of
those
DS.
In
the
background
to
keep
up
with
your
storage
demand
as
you
store
data,
then
you
can
keep
expanding
the
system
and
you
won't
run
out
of
space.
You
want
to
determine
specify
what
the
size
of
a
pool
is
up
front
or
anything
like
that.
I'm,
it's
totally
virtualized
and
flexible.
A
This
approach
also
gives
you
sort
of
the
ability
to
have
uniform
management
of
devices,
though
I
just
sort
of
deal
with
the
deploying
the
Ceph
software
on
new
hardware
nodes
and
making
sure
that
they're
consuming
storage,
I,
throw
them
into
the
pool
and
then
stuff
and
crush
will
handle
remapping
data
onto
them
and
consuming
them.
So
I
have
sort
of
a
common
workflow
for
managing
the
hardware
resources.
Regardless
of
what
is
consuming
that
storage,
it
might
be
file,
storage,
the
FS
or
objects,
or
something
else.
A
Those
are
all
users
of
Rados
and
ratos
is
just
providing
that
storage
via
these,
these
logical
pools.
So
another
way
to
think
about
this
is
consider
that
Redis
is
really
virtualizing
storage
right.
We
have
these
virtualized
pool
storage,
abstractions
that
are
sort
of
variably
sized
and
have
some
have
some
of
policy
around
like
what
performance
you
want
out
of
it,
and
but
the
internal
redundancy
scheme
is
but
from
users
perspective,
they're,
just
a
bucket
full
of
objects
right
and
then
ratos.
A
Some
crush
do
some
magic
to
make
sure
that
these
things
get
replicated
in
a
richer
coated
and
distributed,
and
on
the
back
end,
you
have
all
these
different
underlying
storage
devices
and
software
demons
that
are
actually
making
this
all
work.
But
as
far
as
somebody
who's
consuming
the
storage,
they
don't
really
know
or
care,
though,
and
that
that's
an
turns
out
to
be
a
very,
very
powerful
thing,
I'm
in
a
tick
particular
because
it
means
that
radius
can
be
used
as
a
platform
or
the
higher
level
services
that
are
built
on
top
of
it.
A
So
radius
provides
this
highly
available,
highly
durable
storage
service,
and
then,
on
top
of
that
we
can
build
object,
service,
block
service
and
file
service,
so
we're
gonna,
move
on
and
talk
a
bit
about,
radius
gateway,
the
component
that
provides
object,
storage
services
in
in
the
stuff,
so
rgw
stands
for
the
rios
gateway
and,
as
you
might
imagine,
it's
a
gateway
that
provides
s3
and
Swift
api
compatible
object.
Storage,
though
this
is
an
API,
that's
based
on
rest,
it's
usually
tunneled
over
HTTP
and
provides
sort
of
a
high-level
optic
storage
service.
A
It's
the
same
type
of
thing:
that's
often
combined
with
a
load
balancer
and
actually
exposed
to
the
public
Internet.
So
much
like
Amazon
s3
service.
You
can
have
an
encrypted
connection
to
these
gateways
and
you
can
store
and
retrieve
objects
so
that
the
data
model,
our
job,
provides
a
little
bit
different
than
what
ratos
does,
though
I'm
the
s3
API
is
built
around
the
idea
of
having
users
and
buckets
collections
of
objects,
and
then
objects
are
usually
large.
A
--Is--
blobs
of
data,
so
there's
a
whole
model
around
how
that
what
the
structure
the
data
is
and
how
the
permissions
work
and
how
users
are
allowed
to
access
what
objects
and
so
on
based
around
Ackles.
All
of
that
is
implemented
and
enforced
by
raitis
gateway
and
in
fact,
what
it's
doing
on
the
backend
is
mapping
that
into
some
internal
storage.
That's
dumping
into
ratos.
So
one
important
thing
to
recognize
is
that
the
objects
that
we're
talking
about
with
our
GW
object,
storage
or
s3
objects.
That's
not
the
same
thing
as
the
radio
subjects.
A
I
was
talking
about
a
few
moments
ago
that
are
stored
in
pools
and
ratos.
Burritos
objects
are
small,
they're,
usually
you
know
less
than
10
megabytes
and
they
can
store
key
value,
data
and
byte
data,
and
so
on.
They're
sort
of
this
low-level
object,
rgw
objects,
s3
objects
can
are
usually
pretty
big,
they
can
be
gigabytes
terabytes
and
they
have
apples
associated
with
them
and
they
live
in
buckets,
which
is
a
totally
different
abstraction.
A
You
could
have
you
know
millions
of
buckets,
whereas
you
only
have
usually
a
small
number
of
pools
and
Rados
and
so
on.
So
it's
a
very
different
use
case
in
gredos
gateways,
both
component
in
the
system.
That's
sort
of
making
that
breath
remapping
and,
in
fact,
mostly
what's
happening,
is
that
rgw
is
taking
these
big
s.
Freestyle
objects
directing
them
across
a
lot
of
smaller
ratos
objects
and
then
doing
the
authentication
and
enforcement.
A
So
if
we
look
at
a
little
bit
of
detail
about
how
that
might
work,
you
can
imagine
that
we're
storing
a
large
video
file,
vn
s3
plate
or
post
operation
into
our
GW
and
that's
getting
stored
into
the
backend
stuff
clusters.
So
the
first
thing
that's
going
to
happen
is
we're
gonna
go
look
at
our
metadata.
Our
GW
can
look
at
our
metadata
about
users.
A
What
s3,
users
and
buckets
are
defined
in
in
the
system
and
make
sure
that
this
is
a
valid
request,
that
it's
authenticated
and
that's
a
bucket
we're
putting
into
actually
exists
and
what
the
policies
are
around
and
so
on.
It's
going
to
go.
Make
an
update
to
this
bucket
index
object,
so
s3
API
is
defined
around
the
idea
of
being
able
to
do
a
sorted,
lexicographic
enumeration
of
all
the
objects
in
a
bucket,
and
so
we
have
to
take
their
sort
of
s3
names
and
sort
them
and
put
them
in
an
index.
A
So
we
can
perform
perform
that
enumeration.
So
it's
going
to
make
an
update,
they're
saying
we're
in
the
process
of
updating
the
subject
and
then
it's
gonna
take
the
data
and
stripe
it
across
lots
and
lots
of
reduce
objects,
dump
them
all
in
reduce
and
then,
when
it's
done,
it'll
update
the
index
and
say
I'm
done
I'm
taking.
A
So
you
can
think
about
this
whole
picture
as
being
grouped
into
something
called
zone
right.
So
you
have
you,
have
these
radio
spools
that
have
the
actual
data
that
you're
storing
and
the
metadata
about
it,
and
then
you
have
some
number
of
ratos
gateways.
You
can
scale
these
out
horizontally.
You
know
less
than
ten
tens
of
them.
A
The
idea
here
is
that
you
can
add
multiple
zones
that
are
deployed
that
are
federated
together,
so
each
of
these
zones
might
live
in
a
completely
different
stuff
cluster,
maybe
in
different
sites
and
different
geographies
and
different
continents,
but
they're
associated
in
that
there's
a
replication
relationship
where
all
of
the
user
and
bucket
info
you
know
which,
as
freezers,
exist
in
which
s3
buckets
exist,
is
replicated
between
these
two
zones.
So
they
have
a
shared
view
of
what
buckets
they're
serving,
but
they
have
different
data.
A
So
when
you
have
a
request
to
read
a
bucket
from
one
Redis
gateway,
if
it's
stored
locally,
it
can
service
that
request
and
read
it
here.
If
you
request
a
bucket
foo,
that's
actually
stored
in
a
different
zone
bar
then
this
gateway
knows
that,
because
the
house,
with
the
metadata
about
that
bucket,
it
can
send
you
a
redirect
that
bounces
the
client
over
to
the
appropriate
gateway,
and
so
you
can
read
the
data
from
that
location
instead.
So
this
is
really
very
similar
to
what
Amazon's
globalists
service
provides
right.
A
So
you
have
a
global
namespace
of
buckets
and
users.
When
you
create
a
bucket,
you
create
that
bucket
in
a
particular
region
which
is
similar
to
a
zone,
and
you
can
request,
do
reads
and
writes
from
that
bucket
anywhere
in
the
world
and
as
soon
as
sort
of
that
access
touches
the
Amazon
Network.
It
sends
you
to
the
right
data
center,
and
so
you
can
read
and
write
that
particular
data.
A
Now,
in
addition
to
that,
Federation
capability
rate
of
Gateway
also
has
a
Geo
replication
capability,
which
is
sort
of
extending
the
zone
concept
to
take
multiple
zones
that
are
replicating
the
same
content.
So
if
you
imagine
you,
we
had
two
additional
zones
known
snow
zone,
C,
1
and
C
2.
Again,
these
are
totally
separate
zones.
A
They
might
be
in
different
clusters
and
different
continents,
even
but
we
logically
grouped
them
into
a
zone,
Group
B
and
that
essentially
tells
us
where
to
skate
wave
that
all
of
the
bucket
data,
all
the
content
that's
stored
in
these
zones
should
be
replicated,
and
this
can
be
a
unidirectional
relation
replication
relationship
where
all
the
writes
happen
in
one
zone
and
they
get
sent
off
to
the
other
one
or
it
can
be
bi-directional.
Active
active,
so
you
could
have
a
bucket
that's
stored
in
both
these
contents.
A
So
the
bucket
either
exists
on
these
zones
and
zone
Group
C
or
the
buckets
enzyme,
Group
B
or
those
bucket
lives
in
zone
Group,
A
and
regardless
of
which
gateway
you
touch.
You
get
sort
of
sent
to
the
red
zone
and
then
the
rate
of
State
ways
for
each
of
these
zones.
They
sort
of
scale
out
horizontally
and
there
they
are
literally
the
Gateway.
So
all
of
this
replication
between
between
zones
is
actually
tunneled
via
the
gateways
over.
You
know:
TLS,
secure
channels
between
them
and
a
scale
well
fashion.
A
A
So
that's
Federation
rgw
is
a
sort
of
a
robust
product
with
lots
of
other
lots
of
other
features
as
well,
though,
first
and
foremost,
we
emphasize
very
strong
s3
api
compatibility.
This
is
a
huge
investment
for
the
project,
unity.
We
have
a
test
suite.
We
built
called
s3
tests.
That's
a
functional
test,
suite
that
evaluates
whether
we've
sort
of
correctly
implemented
the
s3
API.
A
That's
this
test
suite
is
in
fact
used
by
lots
of
other
projects
and
products
better
s3
API
compatible
and
we
implement
lots
of
other
API
is
mostly
focusing
on
things
that
are
in
s3,
so
there's
sts,
which
is
a
security
token
service
which
allows
you
to
sort
of.
Instead
of
using
the
native
s3
authentication
model,
you
can
integrate
with
external
dedication
frameworks,
things
like
Kerberos
and
so
on.
We
support
encryption,
there's
a
whole
set
of
API
s
and
s3
around
this.
A
In
a
few
different
ways,
you
can
manage
keys
and
so
forth
that
we
implement
several
different
flavors
of
that
API,
there's
inline
compression.
So
if
you
put
an
object,
they
look
and
compress
before
it
gets
written
back
after
a
dose.
We
support
COEs
cores
and
Static
website
hosting
features
which
are
I'm
used
by
many
many
people.
A
There's
a
metadata
search
capability
that
integrates
with
elastic
search,
though
you
can
do
queries
over
metadata
about
objects
that
are
stored
in
a
bucket
and
we've
recently
added
a
pub/sub
event
stream
capability,
which
is
useful,
in
particular,
with
your
integrating
with
the
serverless
framework
like
a
native,
so
you
can
imagine
putting
an
object
into
a
bucket
in
our
GW
and
that
triggering
an
event
that
then
induces
a
serverless
function
or
lambda
to
be
called
somewhere.
That
does
some
processing
on
that
data.
A
So
you
can
imagine
that
you
might
have
some
Rado
schools
that
are,
you
know,
erasure
coded
on
hard
disks
and
other
ones
that
are
replicated
on
nvme
and
devices
for
very
high
performance,
and
when
you
put
a
object,
you
can
specify
which
storage
class
that
object
might
get
stored
in
or
you
can
set
policies
and
buckets
so
that
all
the
objects
in
a
bucket
are
either
very
fast
or
very
slow.
Something
like
that.
A
There's
also
support
for
a
lifecycle
management
feature
which
allows
you
to
have
cheering
Andry
tearing
between
those
storage
classes
happen
automatically
on
a
time
basis,
so
that
maybe
when
an
object
is
two
weeks
old
again,
this
gets
moved
to
the
slower
storage.
Maybe
when
it's
six
months
olds,
it
gets
deleted
automatically.
That
sort
of
thing
there's
also
the
ability
to
create
an
archive
zone.
A
I'm
sort
of
within
that
federated
view,
where
that
particular
zone
stores
a
full
copy
historical
copy
of
all
the
data
that
has
ever
been
written
so
even
after
an
object
has
been
overwritten
or
deleted.
It
preserves
all
copies
of
that
object
for
compliance
and
other
backup
type
use
cases,
and
that's
that's
raitis
gateway
and
sort
of
a
complete,
robust,
s3,
API
implementation.
That's
used
in
many
different
private
cloud
and
private
infrastructure
environments,
on-premises.
A
That
is
also
used
by
several
public
cloud
companies
offering
public
object,
storage
services
on
the
open,
Internet
next
up
is
RBD
their
rate
of
suck
device,
which
is
the
component
that
provides
block
storage
process.
So
our
buddy
stands
for
rate
of
block
device
and
its
purpose
is
to
provide
a
virtual
block
device
that
allows
you
to
store
Disqus
images
in
Assefa
and
Assefa
frado's
cluster
and
at
a
high
level
really.
A
What
we're
doing
is
basically
taking
a
big
virtual
disk
and
we're
striping
and
across
a
bunch
of
smaller
radius
objects
and
dumping
them
dumping
on
the
Doritos,
and
the
purpose
of
this
is
usually
because
you
can
take
the
storage
and
decouple
it
from
the
hosts
from
the
sort
of
the
compute
side.
That's
actually
going
to
consuming
that
storage.
So
if
you
imagine
that
it's
a
virtual
machine,
for
example,
if
the
storage
is
stored
in
a
rails
cluster
attached
to
the
network,
you
can
just
aggregate
your
compute
resources
from
your
storage
resources
and
scale
them
independently.
A
You
can
take
virtual
machines
and
live
migrate,
then
between
compute
hosts
and
fail
them
and
move
them
around
or
whatever.
With
that,
I
mean
to
touch
the
storage
sort,
just
sort
of
always
available
over
the
network
really
and
sort
of
all
the
use
cases,
and
they
can
imagine
a
August
to
the
EWS
is
the
eds
service
in
Amazon
and
our
beauty
is
accessible
via
both
virtualization
technologies,
like
KVM
and
also
from
a
raw
linux
device
from
a
Linux
host.
A
Some
implementations
of
the
errbody
client
link
directly
into
KD
into
key
mu
if
they've
been
sort
of
very
tightly
integrated
there
for
many
years,
so
that
that
virtual
machine
process
is
talking
directly
to
the
storage
cluster
on
the
back
end
or,
conversely,
if
you
have
sort
of
a
regular
bare
metal
Linux
host,
you
can
also
map
a
virtual
RBD
disk
device
I'm
using
the
RB
driver
to
a
dev
RBD
raw
block
device
in
Linux,
and
then
you
can
put
whatever
you
want
on
top.
You
know
usually
a
filesystem
thanks,
so
you
could
skim
that
storage.
A
A
So
the
RBD
supports
snapshots
and
clones
sort
of
table
stakes
these
days
for
any
sort
of
virtual
just
device.
So
a
snapshot
is
a
read-only
point
in
time
copy
of
the
state
of
the
disk
image
and
so
for
any
RVD
image
and
stuff
cluster.
You
can
create
multiple
snapshots
on
that
at
any
point
in
time
and
there's
essentially
a
snapshot
view
of
state
of
that
image.
At
that
point
time,
all
the
snapshots
are
sort
of
logically
linked
to
the
original
image.
A
So
if
you
have
an
image
called
foo,
you
can
so
you
go
enumerate
the
snapshots
for
foo
and
you
can
delete
them
and
make
copies
with
them
and
so
forth.
A
clone
is
a
little
bit
different,
in
contrast
to
being
a
read-only,
it's
actually
a
writable
overlay.
That's
created
a
sort
of
logically
layered
on
top
of
an
existing
snapshot.
A
So
a
typical
way
that
these
are
used
is
that
you
might
have
an
RBD
image.
That's
a
base
operating
system
image.
You
know
like
a
blank
empty
install
of
a
particular
Linux
distribution,
for
example,
create
a
snapshot
at
that
and
then
every
time
you
create
a
new
virtual
machine
in
your
environment.
You
simply
in
order
one
time,
create
a
writable
overlay
of
that
operating
system,
snapshot
and
then
start
making
changes
on
top
of
it
and
then
all
the
kicks
in
all
the
sort
of
copy
and
write
behavior
did
that.
A
So
you
can
sort
of
instantly
start
booting
up
new
virtual
machines
with
a
full-blown
existing
OS
install
image,
and
because
these
clones
are
first-class
images,
they
can
themselves
be
snapshotted.
They
can
be
resized
renamed.
All
the
stuff,
you'd
usually
do
with
arguments
you
can
do
to
the
clones,
unlike
the
snapshots,
which
are
sort
of
read-only
immutable
copies,
but
in
both
cases
for
both
snapshots
and
clones,
all
this
is
efficient,
so
creating
snapshots
and
clones
is
an
order.
A
One
near-instantaneous
process
doesn't
involve
copy
any
data
just
dealing
with
some
metadata
and
in
both
cases
we
leverage
copy-on-write
support
in
Ratos,
though,
that
space
is
only
consumed,
as
data
has
changed.
If
you
create
lots
of
snapshots
but
don't
modify
anything,
the
snapshots
no
consume
any
space
same
thing
with
the
clones
you
don't,
a
clone
doesn't
occupy
any
space
until
you
start
modifying
the
data
that
was
in
the
original
snapshot,
and
only
then
does
it
consume
storage
resources.
A
A
These
objects
are
four
megabytes,
but
you
can
configure
that
to
have
any
sort
of
straightening
scheme
that
you
want,
and
notably
the
important
thing
to
remember
is
that
this
is
a
it's
a
sparse,
sparsely
allocated.
So
when
you
create
a
new
our
beauty
image,
it
creates
the
header
image,
but
no
data
objects
are
created,
so
the
it
might
be
a
four
terabyte
image,
but
it
consumes
almost
no
space,
except
for
this
header.
A
It's
not
until
you
actually
start
writing
to
a
location
in
this
block
device
that
instantiates
this
object
and
write
some
data
into
it
and
in
fact
these
objects
themselves
are
also
stored
in
a
sparse
fashion.
So
if
you
write
a
4k
in
the
middle
of
a
four
mega
object,
it's
still
only
consumed
as
4k
of
storage,
and
these
others
can
get
dumped
in
any
radio
school.
So
it
can
be
a
replicated
pool
or
a
richer
coded
pool.
Depending
on
here.
What
your
dura,
bility
and
performance
requirements
are.
A
So
our
BT
also
has
an
alternative
mode
of
writing
data,
so
a
write
instead
of
just
going
to
the
particular
location
of
the
block
device
and
mapping
to
the
image
and
writing
there.
We
can
instead
enable
a
journaling
mode
and
the
idea
there
is
that
all
the
rights
are
1st
appended
to
this
sort
of
sequence
of
journal
objects.
A
That's
you
know
growing
here
to
eventually
get
ain't.
Remember
there.
After
a
write
is
persistent
to
the
journal
and
stable,
then
we
can
go
write
it
also
over
into
its
normal
location,
and
then
we
can
trim
the
journal.
So
the
Strela
contains
recent
data
rights
and
it
also
contains
any
metadata
changes.
Things
like
resizing
the
image
and
creating
captions
and
so
on
sort
of
a
full
record
of
all
the
things
that
are
happening
to
the
image
or
a
recent
recent
history
at
least
are
contained
and
within
the
write
journal,
so
in
and
of
itself.
A
The
image
is
now
it's
making
rights
depending
to
the
journal
and
then
flushing
them
all
to
the
data
pool
like
we
just
described,
but
then
you
also
have
an
orbiting
daemon,
which
is
essentially
just
watching
all
the
rights
that
are
happening
to
this
image
in
the
journal
and
reading
them,
and
then
it's
applying
them
to
a
copy
of
the
image
that's
stored
in
a
separate
cluster,
probably
in
a
separate
data
center.
So
this
gives
you
an
asynchronous
copy
of
the
image
in
a
different
cluster.
A
So
notably,
this
is
a
point
in
time
and
crash
consistent
copy.
So
if
this
first
cluster
blows
up,
even
if
all
the
latest
haven't
been
modified,
what
we
have
in
cluster
B
is
a
point
in
time
crash
consistent
view.
So
it
says
this
thing:
consuming
writing
to
the
storage
crashed
a
little
bit
sooner,
because
we
have
lost
the
last
few
rights,
but
it's
fully
consistent
in
that
it's
point
in
time,
because
if
it
nonsense,
it
also
mirrors
not
just
the
data
that's
stored
in
the
image,
but
also
all
the
snapshots.
A
I
know:
there's
sort
of
metadata
type
changes,
so
this
this
is
copy
and
the
second
cluster
is
a
sort
of
a
complete
clone
that
has
all
the
properties,
not
just
the
actual
data
and
already
Mearing
supports
sort
of
the
full
cycle
of
lifecycle
events.
That
can
happen,
so
you
might
lose
your
first
cluster
and
have
to
failover
to
cluster
B
and
start
consuming.
That
and
updating
this
image
cluster
a
comes
back
online.
A
A
What
images
are
being
written
in
read
to
you
and
how
much
bandwidth
they're
using
there's
a
quota
mechanism,
that's
enforced,
sort
of
at
the
time
that
the
devices
are
provisioned,
though
it
will
prevent
you
from
creating
images
and
then
later
filling
up
the
cluster
by
sort
of
enforcing
the
total
size
of
the
image
at
provisioning
time.
There's
the
ability
to
restrict
different
clients
via
the
authentication
keys
that
these
to
connect
to
the
cluster,
to
restrict
them
to
different
private
namespaces.
A
So
they
can
only
see
their
own
RBD
images
and
not
access
others,
even
though
they
might
be
sharing
the
same.
Underlying
ratos
pool,
there's
full
set
of
important
export
capabilities
for
backups
and
getting
communal
bits,
migrating
data
and
all
that
stuff
and
there's
a
trash
give
ability
so
that
when
you
delete
an
image,
it'll
actually
get
kept
around
for
some
period
of
time
before
it's
automatically
purged
to
help
avoid
sort
of
fat-finger
type
situations.
A
You
can
do
the
same
thing
using
the
kernel
mvd
feature
in
NBD
mode,
where
it
creates
an
NBD
style
device,
but
that
essentially
deserves
and
a
pass
through
to
a
user
space
implementation.
That's
a
live!
Rbt
client,
that's
useful
for
using
sort
of
the
latest
user
space
features
that
aren't
yet
implemented
in
the
kernel.
Client,
there's
an
iSCSI
gateway,
so
you
can
create
gateways
that
take
our
beti
images
and
expose
them
over
the
ice
cozy
protocol.
A
So
that's
that's
our
BD
so
already
is
used
extensively
in
the
OpenStack
community
and
elsewhere,
and
that
gives
you
that
virtual
block
device,
abstraction
that
is
much
more
flexible,
scalable
and
powerful
than
then
alternatives
like
ice
cozy.
And
finally,
that
brings
us
to
stuff
of
s
which
is
distributed
file
system.
So
stuff
s
is
a
distributed
network
file
system.
That
means
that
you
get
files
directories,
things
like
rename,
hard
links
and
so
on.
A
It
gives
you
a
concurrent
shared
access
to
the
same
file
system,
main
space
from
multiple
clients
that
are
mounting
the
same:
the
same
file
system.
The
fess
is
designed
to
provide
a
strong
level
of
consistency
and
caching,
which
means
that
if
you
make
changes
to
a
file
in
the
file
system
from
one
node,
if
another
client
looks
at
that
file,
it
will
immediately
they
see
those
changes.
So
it's
a
it's
a
fully
coherent
view
of
the
data
and
through
a
combination
of
locks
and
laces
and
so
forth.
A
So
it's
important
to
note
that
the
way
that
is
implemented
is
by
separating
data
and
metadata
management.
So
when
a
client
host
mounts
ffs
and
you
read
and
write
to
a
file,
the
client
is
writing
directly
to
read
us
directly
to
the
objects
that
store
that
file
data.
So
the
I/o
path
is
direct
to
the
OS
DS
and
it's
scalable
and
high
throughput
and
so
on,
because
you
have
lots
of
different
O's
to
use
and
you're
balancing
data
and
so
on.
A
Metadata
access,
on
the
other
hand,
goes
to
a
new
type
of
demon
called
a
metadata
server.
So
metadata
accesses
things
like
creating
files
opening
files
listening
directories,
all
that
sort
of
namespace
coordination
is
handled
by
communicating
with
these
metadata
services,
and
this
bi
is
something
very
important.
It
means
that
we
can
scale
metadata
and
data
independently
in
the
system.
So
if
we
need
more
storage
capacity,
if
we
need
more
I/o
throughput,
then
we
can
expand
the
size
of
the
rightest
cluster
and
just
deploy
more
and
more
OS
DS.
If
you
get
more
capacity
and
throughput.
A
On
the
other
hand,
if
I
have
more
files,
if
I
have
lots
and
lots
of
small
files,
for
example
or
I
just
have
a
workload,
that's
I'm
making
a
lots
of
metadata
changes,
then
I
can
deploy
more
metadata.
Server,
daemons
and
I
can
scale
the
metadata
capacity
of
this
file
system,
so
that
happens
by
deploying
these
stuff
metadata
services
is
a
new
demon
type.
That's
sort
of
complements
the
sort
of
the
core
Rado
Stevens.
So
the
set
metadata
service,
the
metadata
server
daemons
job-
is
to
manage
the
file
system
namespace.
A
Its
primary
purpose
is
to
store
all
that
file
metadata
in
Rado
subjects.
So
these
demons
are
stateless.
You
don't
have
any
direct
storage
attached
on
the
notes
that,
where
these
demons
are
running
they're
actually
des
storing
all
their
data
back
into
Rados,
though
you
can
employ
these
demons
pretty
much
anywhere.
You
just
want
lots
of.
You
know
a
few
resources
in
memory.
A
Their
main
job,
then,
is
to
coordinate
file
access
to
join
clients,
though
they
need
to
make
sure
that
if
multiple
clients
are
accessing
the
same
directory
or
accessing
this
file,
they
have
a
coherent
view,
and
so
they
have
to
manage
the
consistency
of
those
client
caches
and
make
sure
that
they're,
cooperating
and
so
on.
So
it's
managing
that
cache
consistency,
LOX
leases
and
so
on.
There
again
they're,
not
part
of
the
data
path.
A
A
So,
as
I
mentioned,
the
metadata
from
Seth,
FS
or
stuff,
s
is
stored
back
into
raised
pools,
and
so
the
client
is
directing
its
metadata
operations
towards
the
metadata
server.
All
of
those
modifications,
the
namespace,
are
getting
drilled
into
a
set
of
objects
in
a
metadata
journal
and
then
once
it's
stable
there,
they
get
written
out
to
all
these
objects
on
a
per
directory
basis.
So
each
directory
in
the
namespace
has
a
radius
object
in
the
made
of
metadata
pool.
A
That's
essentially
a
map
of
file
names,
I,
know
in
metadata
and
then,
when
you
actually
want
to
read,
write
data
or
you
go
directly
to
the
variable.
So,
unlike
RVD
you'll
notice
that
for
each
file
system
and
stuff
s,
there
are
at
least
two
different
pools,
one
for
data
and
one
for
metadata,
I'm
stored
in
the
rio
sequester
and
you
can
do
tricks
like
put
the
metadata
pool
in
SSDs.
So
you
can
use
the
performance
here
and
so
on.
A
One
of
the
key
challenges
in
making
such
a
fast
scale
is
making
this
metadata
scale,
and
the
problem
is:
how
do
you
take
this
sort
of
complicated
hierarchical
file,
structure
and
distributed
across
sort
of
a
linear
set
of
store
servers
and
the
way
that
stuff
does?
This
is
using
a
technique
that
it
pioneered
called
dynamic,
sub
tree
partitioning,
and
the
idea,
basically,
is
that
we
take
the
overall
file
hierarchy
and
we
partition
that
hierarchy
and
it's
on
a
sub
tree
basis
and
we
map
sub
trees
to
different
metadata
servers.
A
But
we
do
that
dynamically
based
on
what
the
current
workload
is.
So
if
you
have
a
billion
files
in
this
file
tree
and
you're,
not
actually
looking
at
them,
you
might
not
even
load
them
in
a
memory
and
they
might
all
sort
of
the
Technic
bicycle
metadata
server.
It's
not
until
you
actually
start
accessing
data
and
loading
that
metadata
into
the
metadata
servers
memory
that
it
starts
consuming
resources,
and
at
that
point,
then
the
metadata
cluster
might
dynamically.
A
Take
a
subtree
of
it
and
pass
responsibility
for
that
subtree
off
to
a
different
metadata
server
ship
that
metadata
to
another
meditative
service
cache
in
a
coordinated
way,
so
that
somebody
else
is
responsible
for
managing
all
the
updates
there.
So
the
clients,
then,
as
they're
traversing
the
file
system,
they
sort
of
dynamically,
explore
the
file
space
they'll,
learn
that
this
particular
part
of
the
namespace
is
mattre
different
metadata
server.
A
That's
can
even
fragment
that
directory
into
lots
of
little
pieces
and
then
take
those
fragments
and
map
them
to
different
metadata
servers
and
so
that
you
get
that
that's
scalability
in
the
system,
so
overall,
a
very
flexible
approach
to
managing
managing
your
metadata.
So
this
implements
a
number
but
they're
sort
of
unique
user,
visible
features.
The
first
of
those
is
the
way
the
snapshots
sowhat's
of
file
systems
can
do
snapshots
in
such
a
fast.
A
You
can
snapshot
not
just
any
file
system
but
any
directory
within
the
file
system
and
when
you
snapshot
a
particular
directory,
it
applies
not
just
to
that
directory,
but
all
sub
directories
nested
beneath
that
point
in
the
file
tree.
This
is
in
contrast
to
most
file
systems
where
you
have
two
snapshot:
sort
of
a
volume
or
sub
volume
and
that's
sort
of
a
predetermined
unit
of
storage
or
boundary,
though
snapshots
are
point-in-time
consistent
and
its
emphasis
from
the
perspective
of
a
POSIX
API
from
the
actual
assist
calls
at
the
client
side.
A
Unlike
some
manifests
based
file
servers
which
happens,
sort
about
the
client-server
boundary
when
things
are
written
back,
so
the
consistency,
an
ACEF,
a
snapshot
a
little
bit
stronger,
that
it
is
in
many
other
systems
but,
most
importantly,
these
snapshots
are
very
easily
I'm
using
assumed
the
other
file
system.
So
you
can
imagine
moving
into
any
directory
in
the
file
system,
and
you
see
some
files.
There's
no
snapshots
listed
there
vo,
that's,
not
hidden
dot
snap
directory
if
I
want
to
create
a
snapshot.
A
I
simply
do
a
make
dur
in
this
hidden
magic
directory
to
create
the
snapshot
and
voila
there.
It
is.
This
is
a
fast
metadata
operation
and
we
have
said
the
usual
behavior.
So
if
we
delete
a
file,
it's
gone,
you
know
we
don't
see
it
here,
but
if
I
look
on
the
snapshot,
it's
still
part
of
the
snapshot
and
I
can
still
read
these
files
from
the
snapshot
I'm
using
normal
POSIX
operations
and
when
I'm
done
later,
if
I
want
to
delete
the
snapshot,
I
can
just
do
an
armed
or
operation
and
proof
the
snapshot.
A
Death
of
that
snapshots
are
efficient
you,
so
the
creation
deletion
is
sort
of
a
fixed,
immediate
operation
and
snapshots
only
consume
space
in
the
system
when
you
actually
overwrite
or
modify
data
again,
bypassing
coordinating
with
some
features
in
the
greatest
layer
to
make
sure
that
sort
of
copying
right
and
all
the
way
up
and
down
the
stack,
the
other.
The
other
unique
feature
in
stuff
FS
is
its
support
for
recursive
accounting
and
the
underlying
capability
here
is
that
the
metadata
servers
are
maintaining
recursive
statistics
across
the
entire
file
hierarchy.
A
A
new
stats
cover
file
and
directory
counts,
the
sizes
of
files
and
summations
with
file
sizes
and
the
most
recent
modification
in
C
time
on
I/o
notes,
and
these
statistics
statistics
are
visible
via
virtual
Exeter's.
So
if
you
mount
the
filesystem
and
you
go
into
some
arbitrary
directory
and
you
dump
the
extended
attributes
on
a
directory,
for
example,
you'll
see
some
information
about
that
particular
directory.
How
many
files
and
subdirectories
are
contained
within
it,
and
then
you
also
have
all
these
statistics
at
our
recursive
stats.
A
So
this
is
the
summation
of
all
bytes
stored
within
this
directory
recursively,
not
just
this
directory,
but
I'll
subdirectories
nested.
They
means
that-
and
this
is
the
most
recent
modification
time
of
any
file
nested
beneath
this
point
within
the
hierarchy
and
in
fact,
if
you
mount
the
filesystem
with
this,
are
by
HTML
option
when
you
do
the
Mount
and
then,
if
you
do
an
LS,
this
recursive
bytes
value
is
the
value
that's
reported
as
the
size
of
a
directory
which
can
be
very
convenient
right.
A
You
just
do
an
LS
AO,
and
you
can
immediately
see
that
this
directory
contains
four
point:
five
Meg's
of
data,
most
of
it's
in
this
directory.
You
can
see
not
nested
and,
as
I
can
see
that
my
parent
directory
is
12
gigs
all
this
stuff.
It's
actually
the
same
information
that
you
would
get
out
of.
Addi
you,
but
it's
sort
of
immediate
and
free,
sadly,
and
having
these
sizes
reported
here,
confuses
our
sink,
because
sometimes
they
update
a
little
bit
asynchronously
and
our
sink
gets
confused
when
the
directory
size
has
changed.
A
It
thinks
that
there's
some
larger
change
in
it.
That's
not
a
warning
message.
So,
unfortunately,
by
default,
this
option
is
turned
off
I'm,
hopefully
in
the
future
sometime
we
can
fix
our
sink
so
that
it
doesn't
get
confused
and
we
can
leave
them
on
and
stuff
s
contains
a
number
of
other
features,
so
you
can
create
multiple
file
systems
within
the
same
stuff
cluster
and
each
of
those
file
systems
have
sort
of
its
own
independent,
separate
set
of
metadata
servers.
So
you
can
have
no
tenon
or
use
case
isolation.
A
You
can
do
subdirectory
nested
mounts,
so
you
can,
for
example,
have
a
client
that
has
an
access
key.
That's
only
allowed
to
mount
its
particular
subdirectory,
like
its
home
directory,
for
instance,
and
it's
I'm
sort
of
locked
out
securely
from
accessing
any
other
files
in
the
system.
You
can
create
multiple
storage,
tiers
and
I
mentioned
that
every
file
system
has
at
least
one
data
pool,
but
you
can
actually
have
multiple
data
pools
and
you
can
set
policies
on
directories
so
that
files
created
in
different
sub
directories
get
mapped
to
different
radio
spools.
A
So
you
might
have
you
know.
Everything
in
/home
is
mapped,
she's,
sort
of
a
generic
lower
performance
to
your
storage,
that's
backed
by
hard
drives,
and
you
might
have
other
directories
that
have
a
policy
set
on
them
so
that
they
get
the
files
are
created,
backed
by
a
faster
rate,
Oh
school
within
DME
and
replication,
for
example,
and
they're.
A
Also,
some
other
features
there's
this
lazy
IO
capability,
for
example,
that
allows
applications
to
selectively
relax
some
of
the
strict
consistency
behaviors
instead
of
s
and
if
they
sort
of
know
what
they're
doing
that
can
be
very
helpful
and
having
some
high
performance
computing
applications
improve
their
iOS
foot
and
as
with
RBD,
there
are
lots
of
different
ways.
You
can
access
that
if
s
so,
of
course,
there's
a
Linux
kernel,
client,
that's
where
we
focus
most
of
our
efforts.
Any
recent
Linux
kernel
you
can
just
do
mount,
do
stuff
and
access
us.
A
That's
the
best
file
system,
there's
also
a
fuse
implementation
that
you
can
use.
Instead,
for
example,
if
you
have
an
older
kernel
or
if
you
want
to
take
advantage
of
some
new
or
different
feature,
for
example,
and
in
certain
cases,
you
can
also
build
stuff
used
on
all
Linux
hosts
to
mount
SMS
from
there.
You
can
export
stuff
if
SP,
NFS
and
sifts
via
either
the
Ganesha
or
Samba
products
projects.
These
essentially
act
as
gateways.
A
So
you
have
NFS
to
a
gateway
that
then
talks
to
stuff,
that's
the
meditative
service
and
their
rate
of
lowest
ease
and
so
on
on
the
backend
and
those
actually
work
by
linking
with
flips
ifs,
the
user
space
client
implementation
dynamically.
Anything
that
and
if
you
want
to
you,
can
directly
link
flips
FS
into
your
own
application.
If,
if
you
have
some
seven
reasons
to
do
so
as
well,.
A
So
that's
and
that
sort
of
completes
our
overall
picture
right.
We
have
Rattus,
which
provides
this
highly
reliable,
highly
available
storage
service.
We
have
object,
a3,
API
service
provided
by
rios
gateway.
We
have
virtual
disks
provided
by
the
rate
of
block
device
and
we
have
POSIX
distributed
file
access
provided
by
SEF
of
s
all
of
that
within
a
single
cluster
running
on
the
same
storage
hardware.
A
So,
let's
ship
here's
a
little
bit
and
talk
a
bit
about
how
is
the
user?
You
would
actually
consume
SEF
how
you
would
manage
this
type
of
system,
so
CF
has
an
integrated
dashboard.
This
is
built
into
the
set
manager
daemon,
so
it
comes
with
every
cluster.
You
just
set
this
or
turn
it
on
and
set
your
initial
user
password
decide
what
ports
run
it
on
and
it'll
come
up
and
the
dashboard
has
sort
of
three
basic
rules
all
right,
so
you
can
do
monitoring.
A
So
if
you
go
into
the
dashboard
and
you
go
into
the
pools
and
the
Oh
Steve's
and
you
click
on
the
specific
ghostie,
you
can
go.
Look
at
some
low
level,
metrics
about
the
I/o
latency
on
the
particular
device
in
this
large
cluster
and
pull
all
that
information.
A
lot
of
Prometheus
and
have
these
nice
pretty
great
photographs
too.
So
it's
a
very
deep
level
of
monitoring
and
metrics
that
it's
provided
by
the
dashboard.
And
finally,
the
dashboard
provides
a
lot
of
sort
of
typical
storage
admin
type
day,
2
tasks.
A
So
things
like
modifying
the
staff,
configuration
all
the
documentation
and
all
that
stuff
to
sort
of
manage
the
dashboard
and
you
can
do
provisioning,
creating
new
pools,
creating
our
buddy
block
devices
managing
your
NFS
kate
ways
all
that
stuff.
A
lot
of
these
day.
2
operations,
provisioning
tasks
and
I'll
be
done
done
to
the
dashboard
set
pass.
Some
other
nice
management
features.
So,
as
sort
of
noticed
mentioned
earlier,
stuff
monitors
the
internal
status
of
the
cluster
and
reports
sort
of
an
overall
health
status.
It
has
error
in
running
states.
A
Every
specific
alert
has
sort
of
a
unique
ID
type
associated
with
it
with
an
Associated
documentation.
So
you
can
tell
what
that
particular
warning
means
and
what
steps
you
might
want
to
take
or
it
could
take
to
mitigate
it
and
so
on.
All
the
configuration
management
for
the
cluster
is
integrated
into
the
system.
So
all
the
configuration
options
are
self
documenting.
The
configuration
is
stored
by
the
monitors
and
distributed
automatically
to
all
the
different
teams
in
the
system.
A
So
you
don't
go
I'm
poking
around
the
system,
modifying
configuration
files
or
anything
you
can
all
do
that
all
through
the
CLI.
For
it's
a
GUI
on
that
includes
things
like
history
and
the
ability
to
rollback
configuration
and
so
on.
I'm
Steph
is
a
software-defined
system
that
consumes
block
devices
for
the
OS
DS.
So
in
principle
you
can
sort
of
layer
those
of
the
season
top
of
anything
whether
it's
a
rather
vice
or
Eliam,
or
a
nice
cozy
one.
Whatever
I
mean
you
can
you
can
create
all
sorts
of
convoluted
ways.
A
So
we
can
look
at
those
metrics
and
tell
you
if
it
thinks
that
a
particular
hard
disk
is
going
to
fail
within
a
couple
of
weeks,
and
in
fact
you
know
by
default.
It'll
just
default
they'll
just
raise
a
warning,
but
if
you
choose,
you
can
also
configure
the
system
to
preemptively
evacuate
data
from
devices
that
of
thinks
they're
going
to
fail
to
improve
the
overall
reliability
of
the
system.
A
So,
instead
of
waiting
to
go
from
three
up
because
you're
up,
because
you
can
sort
of
create
a
fourth
replica
before
that
that
device
actually
fails
and
keep
your
data
that
much
safer.
And
finally,
there
is
a
telemetry
feature,
though
this
is
the
ability
for
a
stuffed
cluster
to
phone
home
anonymize
metrics
about
the
stuffed
cluster.
You
know
what
version
is
how
big
the
cluster
is,
what
api's
are
being
used?
A
What
features
are
enabled
that
sort
of
thing
can
get
phoned
home
in
sort
of
a
high-level
report
and
back
to
the
set
developers,
which
is
very
helpful
for
us
to
find
out
like
what
versions
of
the
software
are
deployed
and
what
people
are
using
and
so
on?
Recently,
we've
added
crash
reports
of
this
mix,
so
Steph
will
sort
of
automatically
generate
a
crash
report
whenever
one
of
the
daemons
crashes
either
due
to
a
software
bug
or
some
other
an
unforeseen
event
and
those
get
collected
by
the
stuff
manager
game
on
an
archive.
A
So
you
can
query
any
given
stuff
cluster
until
when
it's
crashed
and
exactly
how
it
crashed,
which
team.
At
what
time?
All
that
good
stuff
and
these
crash
reports
are
very
lightweight.
They
just
have
some
metadata
like
what
version
of
the
software
is
running
and
what
functions
were
currently
executing
when
it
crashed.
There's
no
identifying
information
in
here.
A
But
if
you
enable
the
telemetry
feature
telemetry
feature,
then
these
crash,
you
force
walls
to
get
phone
home
developers,
which
means
that
if
we
look
at
the
deployed
population
of
stuff
clusters
and
the
community,
we
can
tell
what
versions
of
the
software
people
are
running
and
what
specific
bugs
they're
hitting
and
in
which
versions
which
can
help
the
developers
immensely
in
prioritizing,
which
bugs
to
fix
and
to
tell
whether
things
that
were
happening
previously
of
stops
happening
and
when
they
started
happening.
All
that
all
that
good
stuff,
so
obviously
this
is
opt-in.
A
So
there
are
lots
of
ways
you
can
install
Seth.
Historically,
the
way
to
do
that
was
be
a
tool
called
Seth
deploy.
This
is
sort
of
a
bare-bones
CLI
tool,
written
Python,
and
that
makes
it
sort
of
pretty
easy
to
deploy
step
clusters.
It
isn't
really
maintained
anymore.
In
fact,
it's
mostly,
but
not
quite
deprecated.
Most
people
these
days
use
one
of
these
other
techniques
to
deploy
stuff.
Oh
there's
stuff
ansible,
instead
of
ansible
playbooks
that
deploy
Cephalon
bare-metal
and
enable
various
features
there's
the
GNU
project,
which
is
an
operator
for
kubernetes.
A
A
There's
also
work
in
progress
on
sort
of
integrating
the
orchestration
installation
experience
directly
more
directly
into
Seth,
and
the
idea
here
is
to
create
an
integrated
orchestration
API
that
allows
seth
to
reach
out
to
the
tool
that
was
used
to
deploy
it
in
order
to
do
things
like
restart
daemons
and
upgrade
and
provision
new
hosts
and
replace
discs,
and
so
on.
I'm
with
the
goal
of
providing
a
unified,
COI
and
GUI
experience.
A
A
So
the
stuff
cluster
will
actually
reach
back
out
to
ruck
and
telework
to
deploy
us
do
OS,
T's
and
that
sort
of
thing
and
spool
and
so
on,
and
in
fact,
there's
also
going
to
be
some
focus
on
sort
of
a
bare-bones
implementation
that
just
does
sort
of
the
bare
minimum
using
SSH.
So
you
don't
really
necessarily
need
one
of
these
more
complicated
tools
that
have
chef
sort
of
mostly
orchestrating
itself,
handling
the
installation
and
upgrade
via
containers
and
so
forth.
So
that's,
that's
very
exciting.
A
I'm
stay
tuned
for
that
more
in
the
future,
and
finally,
I
talk
just
a
little
bit
about
the
open
source,
stuff
community
and
the
larger
software
ecosystem
that
we
exist
in
so
staff
is
open
source
software.
We
have
a
open
development.
Community
seth
is
licensed
under
the
LGPL
two
point,
one
and
three.
For
the
most
part,
there
are
little
bits
of
and
pieces
of
it
that
are
have
slightly
different
licenses,
but
the
bulk
of
it
is
LGPL.
We
do
all
of
our
development
upstream
in
the
open
we
collaborate
primarily
via
github
I'm.
A
All
our
code
is
I'm
reviewed
and
merged
via
pull
requests
on
github.
We
have
a
bug
tracker
based
on
red
mine,
there's
an
email
develop
unless
for
most
of
the
discussion
takes
place,
and
we
also
have
an
IRC
channel
where
most
of
sort
of
real-time
chat
takes
places
all
as
well,
and
we
do
a
lot
of
meetings
over
video
chat.
So
we
have
beta
stand-ups
for
all
the
different
major
components:
a
lot
of
weekly
meetings,
a
lot
of
discussion,
planning,
design
meetings
and
so
on.
A
A
The
sub
community
has
also
invested
a
lot
of
effort
over
the
last
decade
to
integrate
with
adjacent
communities
and
to
make
stuff
work
very
well
as
a
source
platform
with
other
pieces
of
software.
A
lot
of
that
effort
has
gone
into
the
OpenStack
platform,
so
stuff
is
very
tightly
integrated
with
OpenStack
and
in
fact,
the
majority
more
than
half
of
all
OpenStack
installations
in
the
world
use
Seth
as
a
source
back-end,
usually
for
virtual
machines,
but
also
frequently
for
object,
storage
and
file
storage
as
well.
A
More
recently,
there's
a
lot
of
interest
in
focus
on
integrating
stuff
with
kubernetes,
as
humanities
has
become
the
container
for
patrician
platform
of
choice.
That's
scale
out,
you
need
scale
out.
Storage
to
go
with
it.
F
is
a
natural
choice.
A
lot
of
that
work
is
the
other
rook
project,
which
is
a
new
CN
CF
project.
A
That
is
an
operator
for
kubernetes
that
installs
manages
and
provision
stuff
inside
a
kubernetes
cluster
and,
of
course,
there's
a
lot
of
work
with
sort
of
the
underlying
communities
with
Linux
in
particular,
and
with
kayvyun
project
to
make
sure
that
stuff
works
well
I'm
in
those
communities
and
with
those
software
components.
There
are
a
number
of
stuff
events
that
happen
throughout
the
year.
A
The
first
is
set
days.
These
are
one-day
regional
events
that
happen.
You
know,
maybe
ten
times
a
year
spread
around
the
world.
Each
stuff
day
is
usually
between
50
and
200
people,
depending
on
the
location.
Usually
it's
a
single
track
of
technical
talks
and
is
the
mostly
user
focused,
but
these
are
very
popular,
they're,
very
cheap
and
if
they
happen
in
your
area
that
very
easy
to
attend
for
more
information
go
look
at
the
web
page.
You
can
find
out
all
about
the
upcoming
set
days
where
they're
going
to
be
at
the
CFP
is
open.
A
If
you
want
to
speak
with
them
as
well,
we
also
every
year
have
a
2-day
global
Kent
event.
We
call
cephalic
on
and
usually
it's
in
the
spring,
and
these
are
larger
events
you
know
and
if
we're
from
you
know,
350
to
a
thousand
people,
and
the
idea
here
is
to
have
multiple
tracks
and
bring
together
users,
developers
and
vendors
from
all
around
the
world
into
one
location
once
a
year
to
talk
about
the
latest
and
greatest
in
a
set
community.
A
A
Here's
a
here's,
a
quick
snapshot
of
the
current
members
that
foundation
again.
These
are
the
premier
members
that
are
part
of
the
governing
board
and
again
you
have
a
full
mix
of
cloud
companies,
hardware,
vendors,
software,
vendors
and
so
on.
We
also
have
a
number
of
general
members
that
support
the
foundation
financially
and
also
nonprofit
and
academic
institutions,
government
institutions
that
are
members
that
are
supporting
the
project
in
non-financial
ways
and
that's
and
that's
what
we
have
so
for
more
information.
A
A
There's
users
lists
with
a
lot
of
discussions,
asking
questions
about
how
to
use
SEF,
and
it's
a
very,
very
active
community
here
and
there's
also
a
developer
list
with
all
the
developers
actually
building
and
working
on
the
future
versions
of
staff
and
both
communities
also
congregate
on
IRC.
All
that's
done
through
github
I.
Also
encourage
you
to
check
out
the
that
YouTube
channel.
A
That's
where
this
talk
is
going
to
be
posted
and
past
step
talks,
as
I
mentioned
all
of
the
past
talks
at
cephalic,
ons,
we're
all
recorded
and
will
be
recorded
and
are
all
posted
on
YouTube.
We
also
have
a
lot
of
our
our
weekly
meetings,
get
recorded
and
posted
there
and
lots
and
lots
of
other
good
resources.
So
if
you're
looking
to
learn
more,
definitely
encourage
you
to
check
out
YouTube
and
that's
it.
Thank
you
very
much
for
listening
and
I
hope.
This
was
helpful
and
have
a
nice
day.