►
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
A
The
available
open
source
tooling,
is
not
universally
supporting
the
whole
feature
set,
which
can
be
a
limitation
for
projects
considering
these
tools.
This
talk
covers
the
chips
alliance,
efforts
to
provide
strong
support
for
system
verilog,
ranging
from
the
compiler
front
end
using
sherlogg
and
uhdm
for
tools
such
as
geosys
and
verilater
to
the
formatting
and
linting
variable
tool
variable.
A
B
B
Like
to
work
a
lot
in
an
open
source
and
advanced
technology,
and
one
thing
that
I've
noticed
for
a
while
as
a
like
hobby
electronics
person,
is
that
the
support
in
and
hardware
was
not
very
good,
the
support
for
open
source
and
so
on
student
hardware.
So
this
is
why
I
joined
the
team
around
temensa,
who
probably
everyone
knows
to
improve
that
that
whole
infrastructure
and
yeah
today
we've
been
talking
about
a
system
verilog
and
the
improvements
in
free
and
open
source
tools.
B
B
B
One
thing,
though,
is
system
verilog
the
input
of
of
many
of
these
tools
or
this.
This
tool
chain
system,
verilog
support
in
menu.
Oss
tools
is
partial.
I
mean
there
are
tools
like
braille
later
and
uses
or
icarus
that
pretty
much
support,
variable
verilog
and
some
more
than
others
also
system
verilog
features,
but
not
all
system
variable
features
are
typically
covered.
B
But
one
thing
that
we
all
work
towards
is
that
more
people
are
enabled
to
use
the
open
source.
Toolchain
form
synthesis
play
through
fpgas
all
the
way
up,
but
if
the
input,
if
they,
if
their
existing
code
base,
cannot
support
that,
then
this
would
be
a
problem.
So
an
important
factor
for
engineers
adopting
a
work.
A
new
workflow
and
engineers
are
not
only
open
source
engineers,
but
also
engineers
in
the
industry.
B
They
will
kind
of
start
seeing
this
as
a
viable
option
if
they
can
just
dump
their
existing
code
base
their
existing
system
viral
code
base
to
these
tools
and
say:
oh
okay,
that's
that's
a
good
starting
point.
It
works
and
then
I
can
go
from
there
so
system
verilog
is
important
and
relevant
for
success
of
open
source,
tooling.
B
So
now
that
we
identified
that
this
is
needed,
what
can
we
do
to
do
that?
There
are
a
bunch
of
tools
out
there.
I
mean
I
mentioned,
for
instance,
your
says
very
later.
I
guess
that
all
have
their
front
ends
for
very
lock
and,
of
course,
one
could
go
ahead
and
say:
well,
let's
improve
all
of
these.
To
accept
system
verilog
now
well.
System
variable
is
a
big
language.
B
B
So
a
nice
approach
or
a
nice
approach
would
be
to
solve
the
parsing
problem
of
system
verilog
and
one
tool
that
everyone
can
work
on
or
that
that
that
is
econo
economically
to
work
on,
I
mean
economically
in
this
case
is:
if
we
want
to
provide
an
open
source
tool,
it
should
be
an
easy
way
for
someone
who
wants
to
get
started
working
on
on
this
tool
chain.
Saying:
okay,
I
want
to
contribute
my
free
time
to
such
a
tool,
and
this
is
why
our
thought
is
okay.
B
B
B
B
They
need
netlist
stuff
like
that,
and
they
are
the
tools
that
are
also
important
for
the
whole
work
and
in
the
field
which
are
just
like
developer
tools
to
make
it
simple
to
work
with
system
very
long
like
formatters,
linters
things
that
help
you
in
your
editor.
So
that's
kind
of
now
that
we
identified
okay,
we
need,
we
need
to
start
out
with
some
kind
of
front
end.
Let's
look!
B
What
we
can
do
problem
is,
of
course,
how
to
find
that
we
can
just
we
could
just
go
ahead
and
say:
oh
okay,
let's
just
write
a
system,
verilog
browser
from
scratch.
Problem
with
that
of,
as
I
said,
is
systemverlock
is
a
huge
language.
It
is
not
something
that
you
do
in
an
afternoon
or
two
that,
for
that
matter,.
B
So
what
we
did
is
we
we
set
out
and
said:
okay,
let's
find
a
puzzle,
that's
a
good
starting
point
for
this
system,
veronica
support
and
then
go
from
there
and
for
that.
Well,
we
need
to
first
figure
out
okay,
what
we
need
to
do
kind
of
a
survey
what's
what
the
existing
open
source
system
buildup
front
ends,
and
so
it
first
started
out
with
writing
a
test
suite,
if
you
will,
which
you
call
as
we
test
right
now.
B
It's
it's
under
the
simple
flow
project,
which
is
the
project
started
by
by
tim
hensel
at
google,
and
it's
currently
in
the
process
of
actually
being
passed
soon,
essentially
under
the
chips
alliance
roof.
But
it's
it's!
It's
the
a
test
suite
that
we
we
built
to
figure
out
what
are
good
starting
points
for
parsers.
C
B
How
does
it
work
at
essentially
as
a
wants
to
test
against
dlm
all
kinds
of
like
little
features
from
assignments
to
what
have
you
essentially
going
through
the
sections
of
the
lm
and
seeing
okay,
making
little
test
programs
that
see
whether
a
parser
can
deal
with
it
or
not,
and
also
testing
tools
like
a
whole,
suites
or
like,
of
course,
if
you
were
like
ibex
or
gray,
that
we
run
through
the
tools
and
see
if
that
works?
So
how
does
it
look
like
that?
B
What
you
see
here
would
be
like
an
output
of
such
a
test
result.
You
see,
there's
the
tools
that
pass
system
verilog
on
the
top
and
on
the
left,
you
see
the
rows
that
represent
sections
in
the
lm
and
a
bunch
of
test
source
files
that
look
for
it.
Look
at
that
that
contain
features,
and
then
we
see
well,
does
it
compile
or
not,
and
that
helps
us
to
see.
Okay,
what
are
what
are
good
candidates
for
a
good
starting
point
that
already
do
a
lot
of
that
for
our
goals.
C
B
B
B
B
Excuse
me
talk
about
soon.
It
looks
pretty
good,
it
has
more
tests
passed
and
it's
very
fast.
The
reason
why
it's
doing
that
is,
it
has
actually
it
does
understand
less
than
sherlock.
It
is
very
good
and
fast
in
parsing
the
language
and
build
an
internal
tree,
but,
for
instance,
doesn't
provide
any
liberation
and
other
things
so
stuff
where
sherlock
would
choke,
because
it
can't
necessarily
do
the
aberration
of
a
particular
thing
would
show
up
as
a
bad
test
here,
while
variable
would
just
like
loss
overweight.
B
So
this
is
why
it
looks
like
variable,
has
a
higher
fraction
of
passing
tests,
but
that's
that's
reason
there.
So
they're
they're
two,
but
these
two
kind
of
tools
seem
to
be
a
good
starting
point
I
mean
one
part
of,
of
course,
is
like
performance
will
matter.
So
if
you
look
at
sherlock,
it's
fairly
slow,
but
it
does
a
lot
more
stuff
than
variable,
but
variable
doesn't
have
to
do
a
lot
of
things
and
therefore
could
be
used
in
different
domains.
B
We
found
that
the
test
view
is
actually
appreciated
by
by
a
lot
of
these
two
developers
or
compiler
developers,
and
people
started
to
send
their
own
tools
to
also
be
included
in
that
in
that
chart,
because
they
wanted
to
know
how
they're
doing
and
it's
it
also
supports
some
sort
of,
I
mean
essentially
a
gamification
effect
like
once.
You
have
a
table
with
like
red
and
green
areas.
B
People
try
to
make
sure
to
improve
the
green
on
on
their
tool,
so
it
actually
helped
to
just
improve
two
existing
tools,
just
by
the
fact
that
there
was
a
way
to
easily
compare
things,
and
so
that
that's
what
we
observed
so
in
itself
that
tool
that
we
set
out
as
okay
as
a
starting
point
figure
out.
What
is
a
good
way
to
find
a
good
parser.
B
B
Let's
look
at
the
linter
they're,
the
linter
of
a
variable
at
like
50
60
rules
implemented
that
check
for
various
topics
that
are
like
leaning
on
some
open
style
guide
mostly
and
can
easily
be
extended.
So
the
way
variable
structure.
It
is
this
parser
and
it
can
and
pass
that
structure
to
various
linting
classes.
That
can
be
that
can
look
at
particular.
B
It
is
actually
I
mean
people
are
using
it
for
whatever
is
lending
things.
One
important
thing
for
us
was
one
of
the
first
steps
to
actually
put
it
into
the
open,
titan
continuous
integration.
You
can.
You
can
see
a
dashboard
here
on
the
right
which
highlights
one
of
one
of
the
important
aspects
of
having
available
a
linter
that
is
open
source.
I
mean
there
are
closed
source
lenders
out
there
and
they
often
have
one
problem.
C
B
B
B
B
It
is
all
currently
also
used
in
the
open,
titan
project.
Not
all
of
these
files
are
yet
formatted
with
with
variable
there,
because
in
some
cases,
variable
produces
an
output
that
the
developers
don't
like
as
much
so
we've
excluded
them
from
formatting,
but
other
than
that.
The
files
that
do
generate
if
proper
formatting
are
actually
also
tested
in
dci.
So
if
someone
checks
in
or
update
the
file
that
is
like
would
would
result
in
a
difference
in
the
the
formatting,
it
would
flag
that
can
be
easily
fixed.
B
B
A
B
B
Their
virus,
which
is
a
particular
name,
a
way
to
essentially
cross
or
enough
information
to
cross,
navigate
the
code
base,
be
it
in
a
web
front
end
or
by
like
editors
that
need
a
context
of
completion
stuff
like
that
it
can
output,
kai's
indexing
facts.
Kaiser
is
an
open
source
language,
agnostic
code.
B
B
C
B
That
nx
extraction
and
it's
it's
making
progress,
there's
a
tools
and
variable
that
are
based
essentially
in
the
same
parser
and
and
provide
other
features
for
users.
One
interesting
one
is,
for
instance,
the
variable
very
low
project
tool
that
can
extract
dependencies.
You
can
give
it
a
bunch
of
files
and
it
can
see
okay
well.
This
file
uses
a
module
that
is
defined
there,
so
it
can
provide
a
whole
dependency
tree
essentially
so
that
you
could
order
files
in
a
way
to
create
a
file
list.
B
It
does
understand
semantics,
it
can
understands
the
generate
statements
and
can
expand
them
does
elevation
and
it's
mostly
a
complete
front
end
also
was
high
scoring
on
the
sv
test.
I've
seen
if
we've
seen
before
it's
it's
just
a
parser,
it
doesn't
actually
provide
any
synthesis
or
simulation
back
end,
which
is
fine
for
us,
because
that's
what
we're
looking
for
it
was.
It
is
written
by
alan
douglas,
who
is
also.
C
B
B
Tools,
but
I
mean
that
was
not
its
original
goal.
Its
original
goal
would
be
to
was
to
be
a
complete,
parser
and
and
liberation
tool,
and
now
we
just
need
to
add
some
intermediate
format
so
that
we
can
use
it
in
our
original
goal
being
a
front
and
fourth
all
kinds
of
back-ends,
and
that
in
the
media,
format
is
uhdm.
B
B
B
B
The
api
is
modeled
after
the
vpi
interface,
which
is
a
standard
programmatic
interface
in
the
system
verilog
standard.
We
chose
that
because
it's
it's
easy
to
say:
oh,
let's
invent
get
another
new
format,
but
that
might
be
harder
for
for
people
to
adopt.
But
if
it's
something
that
is
at
least
rooted
based
in
some
standard
api,
that
is,
that
is
or
already
part
of
the
standard,
it
might
need,
maybe
extension
for
some
some
features.
We
need
it's
much
easier
for
for
people
to
work
with.
B
How's,
the
actual
transmission
done
between
front
and
back
end,
so
uhdm
is
serializable,
so
it
actually
can
be
written
to
a
file.
So
if
we
do
some
passing
and
convert
it
to
whatever
this
uhdm
intermediate
like
free
structure
thing-
and
that
is
serializable,
so
it
can
be
written
to
disk
and
then
be
read
by
other
tools,
which
is
also
a
good
thing
for
caching.
Think
of
make
files
and
and
general
build
tools
where
you
can
parallelize
things.
B
You
can
have
one
thing
that
pauses
a
file,
outputs,
uhdm
and
then
have
a
separate
to
read
that
file
and
process
and
all
these
tools
that
that
work
with,
like
caching
and
figuring
out,
okay
files,
didn't
change
stuff
like
that,
can
be
used
as
such.
We
can
pipeline
things,
we
don't
need,
or
we
only
need
as
much
memory
as
needed.
Stuff
like
that.
So
uhdm
is,
can
be
written
to
this
and
then
read
later
by
by
tools.
B
B
B
Civilization
model,
so
captain
proto
is
a
common
simulation,
serializing
format
that
can
be
written
and
read
by
a
variety
of
languages.
So
it
is
language
agnostic.
So
we
have
to
write
it
with
a
c
plus
plus
a
front-end,
but
that
serialized
file
that
could
be
read
by
another
supersplash
file
or
by
python
or
by
java.
Or
what
have
you
so?
The
we
are
not
limiting
ourselves
to
a
particular.
B
B
B
And
so
previously,
sherlock
mostly
passed
things
and
had
its
own
form
of
representation
of
that
parse
tree.
That
was
primarily
meant
to
link
against
and
then
used
there
so
I'll
extended
that
so
that
now
sherlock
can
pass
some
system
verilog
and
do
all
the
pre-processing
can
a
liberation
if
needed
and
generate
uhdm,
which
is
then
written
to
disk.
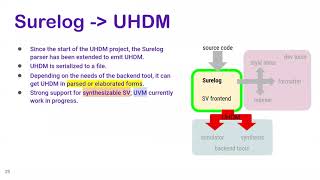
B
So
it
can
just
output
in
uhdm
that
is
more
or
less
representing
the
past
content,
but
also
can
can
whatever
do
like
deal
with
generate
statement
and
liberate
the
the
output
and
then
output
elaborate
on
that
and
output,
an
elaborated
form
which
might
be
simpler
to
process
for
some
tools
right
now.
It's
as
it's
a
strong
support
for
synthesizable
system,
verilog
and
uvm
is
currently
work
in
progress,
but
yeah.
That
is,
that
is
to
stay
there.
B
We
initially
we
just
like
built
it
in
there
and
now
we're
working
towards
essentially
a
simple
import
module
for
users,
so
uses
supports
pluggable
modules
at
runtime,
so
goal
would
be
to
have
a
have
a
plugin
for
users,
which
then
can
read
your
hdm
and
it's
simple
to
do
the
whole
workflow
I
mean
one
of
our
test.
Benches
is
start
out
with
the
ibex
core
part
of
the
open,
titan
project
and
can
be
fast
and
synthesized.
B
And
I
think
the
last
time
I
think
there
was
there
were
issues
with
the
synthesis
yeah.
It
might
not
have
been
fully
synthesized.
Last
time
I
checked,
but
I
think
right
now
it
is
so
go.
Next
was
of
course,
fully
synthesized
ibex
and
er
gray
and
upstream
integration,
which
could
be
like
bits
and
pieces
that
need
to
be
changed
in
uses.
B
This
I
mean
shows
some
well
shows
that
things
are
working,
but
it
only
gets
interesting
once
we
actually
show
that
the
uhdm,
the
immediate
format
actually
can
be
used
for
all
kinds
of
backends.
So
next
is
very
later
so
for
varia
to
be
also
working
on
essentially
a
front
end
that
reads
your
htm
and
passes
it
too,
very
late,
and
when
I
say
v
here
again,
it's
it's
micro,
doing
the
work.
B
So,
very
later,
it's
a
simulator
for
hardware
and
the
default
system.
Verilog
support
is
actually
pretty
good.
I
mean
it's
better
than
uses,
but
still
limited.
So
we,
our
goal
here,
is
to
also
you
see
if
we
can
use
our
parser
with
intermediate
to
very
later,
and
so
that
is
that's
what
the
progress
ibex
can
be
passed
and
works
underway
to
get
a
full
coverage.
C
B
System
verilog
is
an
important
language
for
the
industry
and
hence
it's
a
critical
part
for
the
adoption
of
source
tools,
also
from
the
industry
as
we
test
as
the
test
suite
have
to
identify
a
good
parses
and
the
front
and
formatible
tools
as
a
starting
point:
the
variable
family
of
developer
tools
or
increases
human
efficiency.
If
you
will,
the
developer
efficiency
and
sherlock
with
gms
back
end
enables
system
verilog
support
for
tools
that
might
not
have
that
yet
and
will
be
able
to.
B
Make
it
simpler
for
new
tools
to
emerge,
because
new
tools
only
might
need
to
be
able
to
deal
with
uhdm
as
a
front-end
and
then
can
do
their
own
thing,
so
it
hopefully
allows
for
for
more
projects
coming
up
that
use
that,
and
we
already
see
that
in
the
uhdm
project,
that
there
are
people
using
uhdm
for
kinds
of
things
and
research.
So
that's
interesting.
B
Also
at
the
front
end.
Sherlock
right
now
is
the
first
front
end
that
outputs
the
hdm,
but
there
the
canon
will
be
others.
So
there's
we've
seen
that
there
are
some
quality
candidates
in
the
usb
test
suite
and
we
might
see
some
of
these
people
say
well,
let's,
output
uhdm
as
a
as
a
way
to
interface
with
other
tools,
and
so
now
we
have
this.
Nice
multiplication
effect
that
people
that
are
interested
and
good
at.
A
Thanks
so
much
henner
for
an
excellent
presentation,
I
sincerely
appreciate
it.
We
have
one
raised
hand
and
one
question.
So
let
me
take
the
question
first,
since
that
came
in
back
a
bit,
it
was
from
victor
vesqueoff.
I
hope
I'm
pronouncing
that
correctly.
His
question
is
any
plan
to
make
an
extension
for
visual
studio
code.
B
B
I
think
there
are
some
people
actually
work
working
on
stuff
like
that.
Also
kaiser
is
a
universal
language,
back-end
that
is
running
as
a
server,
and
I
think
they
have
visual
studio
implementations
for
it.
That
can
talk
to
it,
but
I
don't
know
much
about
that,
but
so
to
answer
the
question:
there's
no
immediate
plans
for
us,
but
it
should
be
fairly
straightforward
for
someone
who
knows
what
a
visual
studio
and
and
how
to
how
to
add
plugins
there
to
make
that
work.
A
A
So
a
question
I
had
and
jose
appreciates
the
answer,
but
is
the
eda
industry
utilizing
uhdm
or
contributing
to
it
to
provide
a
basically
a
solid
platform
for
handling
system?
Verilog,
I
shouldn't
say
solid,
but
I
mean
in
terms
of
unifor
universal
handling
of
system
verilog,
or
is
it
pretty
much
just
an
open
source
community
effort
go
ahead.
B
B
A
B
So
the
integration
of
course
requires
sometimes
little
changes
here
and
there
in
in
uses
the
way
things
are
structured,
but
right
now
the
efforts
are
mostly,
I
mean
getting
things
right
right,
getting
okay,
making
sure
that
uhdm
contains
everything
that
the
the
original
source
code
did
and
that
we
create
the
correct
internal
data
structures
for
uses
and
yeah.
Mostly
it's
that's
independent
of
yours
or
very
late.
Or
what
have
you
mostly?
B
It
is
it's
a
bunch
of
work
and
you
need
to
get
it
done
one
by
one
correctly
and
make
sure
that
you
run
the
test
or
or
write
a
test
to
make
sure
that
you're
on
track
all
these
kind
of
things.
At
this
point
we
have,
since
it's
still
work
in
progress.
We
have
not
too
much
or
not
all
not.
All
of
these,
these
parts
needed
are
upstreamed.
B
I
mean
there's,
there's
a
lot
of
work
that
has
been
upstream
to
use
this
behind
my
crew,
also
in
in
the
context
of
working
on
on
some
system,
verilog
compatibility,
but
yeah
there
might
be
there
might
be
more
challenges
ahead.
But
at
this
point
it's
mostly
well
getting
things
done
and
getting
what
are
the
data
structures
right
and
making
sure
that
the
output
is,
in
the
end,
a
properly
synthesized
piece
of
code.
A
B
A
Very
good,
so
that
concludes
the
questions
that
we
have
so
far
and
barring
anything
else,
henry.
I
want
to
thank
you
so
much
for
taking
the
time
to
come
and
chat
with
us
today
and
share
the
excellent
work.
That's
ongoing
in
the
system,
verilog
space.
So
thank
you
very
much
right
and
for
the
audience
our
next
cafe
will
be
on
august
10th.
That
will
be
on
aib
by
dave
kellett
from
intel
and
some
of
his
colleagues
so
hope
you
are
able
to
join
us
then.