►
From YouTube: Rootless Containers in Gitpod
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
Okay,
good
morning,
good
afternoon,
good
evening,
depending
on
where
you're
joining
us
from
welcome
to
today's
cncf
webinar
rootless
containers
in
getpod,
my
name
is
christy
tan
and
I'll
be
moderating
today's
webinar.
We
would
like
to
welcome
our
presenters
today,
christian
weichel
chief
architect,
at
gitpod
and
alvin
querrey,
director
of
kinfolk
labs
at
kinvolk,
a
few
housekeeping
items
before
we
get
started
during
the
webinar.
You
are
not
able
to
talk
as
an
attendee.
There
is
a
q,
a
box
at
the
bottom
of
your
screen.
A
Please
feel
free
to
drop
in
your
questions
and
we'll
get
to
as
many
as
we
can.
At
the
end.
This
is
an
official
webinar
of
the
cncf
and,
as
such
is
subject
to
the
cncf
code
of
conduct.
Please
do
not
add
anything
to
the
chat
or
questions
that
would
be
in
violation
of
that
code
of
conduct.
Basically,
please
be
respectful
of
all
your
fellow
participants
and
presenters.
A
B
Thanks
christy
for
the
intro,
so
welcome
today
we're
going
to
talk
about
rootless
containers
in
in
gitpod
and
to
dive
right
in.
We
first
have
to
talk
about
what
is
gitpod
and
gitpod
is
an
open
source
project
that
automates
development
environments,
and
you
can
think
of
it
as
a
ci
system
that
automates
regular
builds
gitpod
automates
the
provisioning
of
development
environments
for
pretty
much
every
developer.
B
So
it
has
ready
to
code
deaf
environments,
meaning
all
your
tools
are
there
code
is
downloaded
code
is
compiled
and
you
can
ready
to
go.
You
can
start
working
with
a
click
of
a
button
and
it
does
that
behind
the
scenes
by
provisioning,
kubernetes
pods.
So
each
workspace
that
you
start
within
gitpod
is
actually
a
kubernetes
pod
and
we
want
those
pods,
those
workspaces
that
you
can
start
in
gitpod
to
feel
pretty
much
like
your
local
machine,
except
you
get
a
new
local
machine
for
every
every
task.
B
B
And
the
most
naive
way
possible
of
doing
this
is
by
simply
giving
you
all
the
privileges
within
the
workspace
container.
You
know
we
could
just
run
as
root
so
to
speak,
but
the
clear
and
obvious
downside
is
that
that
would
also
mean
that
everyone
inside
their
workspace,
would,
if
effectively
be
rude
on
the
node
they'd
effectively,
have
all
the
privileges
they'd
need
to
potentially
escape
the
container
and
to
have
really
a
lot
of
privileges
on
a
note
that
is
shared
with,
say,
25
other
users.
B
C
Thank
you.
So
there
are
different
ways
to
isolate
more
of
the
parts
from
each
other
and
from
the
host.
One
way
is
to
think
about
a
vm
like
container
on
time.
Those
are,
for
example,
black
containers,
cheap
visor
cutter
containers
like
cracker,
and
this
this
technology
to
provide
improved
isolation
compared
to
what
linux
containers
are
and
they
work
in
different
way.
For
example,
nabla
containers
use
uniqueness.
This
means
that
for
every
new
workload
there
will
be
a
different
unicorn
build
specifically
for
that
workload,
or
there
is
jvisa
what
it
does
is.
C
Re-Implement
the
linux
system
called
interface,
so
it's
really
implemented
in
code.
So
when
your
application
make
a
system
call
instead
of
talking
to
the
linux
keynote,
it
talks
to
this
interface,
this
application
can
help.
There
are
cutter
containers
that
build
a
lightweight
virtual
machines
and
it's
compatible
with
several
hypervisor,
for
example,
umu
or
firecrackers
those
different
vm
technologies.
They
provide
more
resolution,
but
they
also
give
more
limitation
compared
to
normal
linux
containers.
C
They
could
be
compatibilities
compatibility
issues
or
they
could
have
a
decreased
performance,
for
example,
with
a
network
traffic
or
io
file
system
access.
What
we
want
in
general
is
to
have
higher
density.
That
means
to
be
able
to
put
a
lot
of
parts
on
the
same
note
without
having
to
meet
that
too
much
so
next
slide.
C
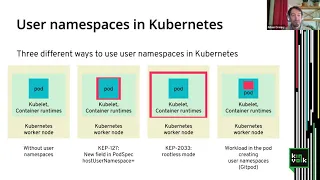
So
the
username
space
is
a
feature
from
the
linux
kernel,
among
other
namespace,
for
example,
networking
space
pin
space
and
so
on.
Currently
that's
a
feature
that
is
not
provided
by
kubernetes.
So
kubernetes
works,
like
you
see
on
the
picture
on
the
left.
It
has
worker
nodes,
kubernetes
and
so
on
that
don't
use
usernamespace.
C
C
It
adds
a
new
field
for
usernamespace,
so
I'll
present
it
in
red
in
this
picture,
where
the
user's
space
will
be
located
in
this
architecture.
So
that's
a
gap.
That
means
a
kubernetes
enhancement
proposal,
that's
not
something
which
is
merged
in
kubernetes.
Yet
that's
something
we
work
on
that
with
others
in
the
community
to
provide
that
another
way
to
use
user
namespace
is
the
next
one
cap
2033,
where
it's
so
called
the
root
test
mode,
because
it's
allows
to
run
the
different
kubernetes
component
without
being
good.
C
For
example,
it
you
can
run
couponet
without
being
wood.
You
can
run
the
container
on
time
without
being
hot.
So
in
this
way
you
have
a
username
space
that
go
around
all
the
components
of
kubernetes
on
the
last
solution
is
the
one
retained
by
git
pod,
where
we
don't
touch
kubernetes,
so
we
can
use
kubernetes
upstream
without
modification
on
inside
the
pod.
Inside
the
workload
it
make
use
of
use
on
space,
so
it
creates
the
username
space
at
this
time.
B
B
You
can
try
this
yourself
with
this
command.
This
lets
you
observe
sort
of
the
the
things
that
the
steps
that
happen
to
make
this
work.
So
unshare
minus?
U
or
in
this
uppercase?
U
creates
the
username
space
minus
r
maps,
your
current
user,
your
current
executing
user
to
uid0
inside
that
namespace
and
the
s-trace
in
front
just
traces
what's
happening.
B
So
this
is
all
fine,
except
in
a
kubernetes
pod.
We
would
need
to
give
quite
far-reaching
capabilities
to
make
this
work
so
to
write
these
two
files.
You
need
capsus
admin
in
the
outer
namespace
and
because,
at
this
point,
kubernetes
does
not
provide
username
spaces.
Yet
this
outer
name
space
would
need
to
be
the
the
node
as
a
whole,
and
we
don't
want
to
provide
capsusapmen
for
security
reasons
on
the
node
inside
the
workspace.
B
B
We
want
to
write
this
uidn
gid
mapping
for
that's
all
nice,
except
now
we
have
to
do
pid
translation
and
the
reason
for
that
is
that
containers
in
general
are
in
essence
a
collection
of
namespaces
and
other
isolation.
Isolation,
tech
and
one
of
those
name
spaces
is
a
pid
namespace.
This
is
why
any
process
that
you
start
sort
of
as
the
root
of
the
container
becomes
pid-1,
and
it's
not
the
actual
pid-1
on
the
node,
say
systemd
or
init,
or
something
like
that.
B
So
the
pid
that
we'll
receive
from
supervisor
ring
one
will
not
be
the
pid
in
the
namespace
that
workspace
demon
sees
in
the
node
namespace.
So
we
need
to
do
some
translation
here
so
outside
of
the
pid
namespace
of
the
container.
This
might
be
is
something
completely
different,
and
in
order
to
do
this
pid
translation,
there
are
a
few
ways
how
this
could
be
done.
There
is
no
syscall,
yet
that
can
just
do
this
translation
for
you.
B
There
are
some
tricks
using
unix
pipes,
but
also
it's
in
the
in
the
proc
file
system.
So
if
we
look
at
the
status
file
of
a
process,
we
see
that
there
is
an
nspid
entry
which
lists
all
pids
in
the
children
namespaces
from
the
perspective
from
the
process.
That's
looking
at
this
file
because
we
know
that
the
pid
that
we're
looking
for
must
be
a
child
process
of
the
container
of
the
workspace
container.
We
can
look
at
the
children
of
that
workspace
container,
look
at
their
status
files
and
this
way
identify
the
correct
pid.
B
Now
we're
left
with
a
problem,
because
this
is
working
really
well.
If
we
look
at
the
file
system,
we
see
that
the
uids
now
all
of
a
sudden,
don't
make
sense
anymore,
at
least
at
first
glance,
but
thinking
about
it.
This
is
exactly
expected
behavior,
because
on
the
file
system,
we
have
some
files
that
belong
to
actual
proper
uid0,
and
we
have
some
files
that
belong
to
a
user
that
has
a
mapping
within
this
username
space
and
the
ones
that
actually
belong
to
proper
uid
0.
B
They
are
shown
as
65
534
in
here,
because
we
don't
have
a
mapping
that
maps
the
user
inside
the
namespace
to
uid
0
outside
to
illustrate
that
what
we
would
like
to
have
is
a
file
system
that,
from
within
the
username
space,
looks
like
this.
You
have
a
whole
bunch
of
files
and
folders
that
belong
to
uid0,
and
you
have
some
that
belong
to
say
some
other
user.
B
So
in
order
to
get
this
view
on
the
left
from
within
the
username
space,
we
would
need
to
have
a
file
system
on
the
node
that
actually
looks
like
this
right.
That
actually
has
this
uid
shift
implemented,
but
in
reality
the
file
system
that
we
need
to
do.
The
shift
for
is
the
root
file
system
of
our
container,
and
this
root
file
system
was
put
there
by
the
snapshotter
of
the
container
runtime,
and
it
doesn't
know
about
this
uid
shift
and
it
also
doesn't
care
so
in
reality,
the
file
system
looks
exactly
like.
B
We
would
want
it
to
look
like
from
within
the
username
space.
So
we
need
some
process
that
dynamically.
Does
this
ui
or
does
this
uid
shift
for
us
and
there
are
a
few
technologies
that
can
do
that?
For
example,
there
is
fuse
overlayfest,
which
has
the
benefit
that
it
can
be
used
without
any
privileges
outside
of
the
username
space.
So
you
can
use
that
completely
from
within
the
username
space,
because
fuse
can
be
mounted
within
username
spaces
and
the
rest
that's
needed
is
a
username
process.
B
B
There
is
also
overlay.
Fs
meta
copy
metacopy
is
a
mode
in
overlay
fs,
where
it
just
copies
the
metadata
to
to
the
upper
deer.
So
what
we
could
do
is
we
could
basically
mount
an
overlay
fs
on
top
of
the
file
system,
that
we
would
like
to
shift
and
then
basically
do
a
change
own
on
onto
that
file
system,
and
this
is
exactly
where
the
upfront
cost
comes
in.
This
change
zone
is
potentially
very
expensive
if
the
root
file
system
is
large,
the
runtime
cost
is
comparatively
low
in
terms
of
platform.
B
Specificity
overlay,
fs
to
my
knowledge,
can
only
be
mounted
from
within
username
spaces
on
ubuntu
because
they
have
a
non-upstream
patch
that
takes
the
right
box
so
to
speak
on
on
oval
afs
and
lastly,
speaking
of
ubuntu
ubuntu
has
support
for
a
file
system.
They
call
shiftfs,
which
can
do
this
uid
shift
at
mount
time,
so
to
speak.
B
It
doesn't
completely
work
from
within
the
username
space,
because
you
need
something
that
they
call
a
mark
mount
and
this
you
can
only
do
with
privileges
in
the
outer
name
space,
but
it
has
very
little
upfront
cost
and
all
you
need
is
amount.
Runtime
cost
is
very
low,
it
is
quite
fast
and
it
runs
entirely
in
kernel
space,
but
it
is
very
platform
specific.
It
only
works
on
ubuntu
for
gitpod.io,
which
is
the
sas
offering
the
sas
version
of
of
gitpod.
B
So
now
that
we
have
the
pid
mapping
established
we're
using
the
same
trick
that
we
used
to
write
to
the
pid
and
uid
map
to
actually
create
this
mark
mount
this
privileged
operation
that
we
need
to
do
that.
So
we
make
this
make
another
grpc
call
to
the
workspace
daemon.
Who
then
creates
that
mark
mount
for
us?
B
Once
we
have
this
mark
mount,
we
can
use
it
to
mount
the
shifted
file
system
and
then
we
do
bind
mounts
to
dev,
proc,
etc.
Other
bits
of
the
file
system
of
the
container
and
then
start
supervisor
ring
2,
which
basically
does
a
pivot
root
to
this
new
file
system,
and
this
is
how
inside
ring
2
your
a
inside
this
username
space,
but
also
you're,
looking
at
a
shifted
file
system.
So
to
you
all
file
system,
permissions
and
ownership
looks
correct.
B
So
in
the
proc
file
system
there
is
a
there
are
a
bunch
of
files,
a
bunch
of
objects
that
are
singletons
within
the
kernel
that
are
not
namespaced,
for
example,
proc,
kcor
or
scat
debug,
which
might
even
leak
information
about
other
namespaces.
Hence
other
containers
on
the
node,
and
so
what
kubernetes
and
or
more
specifically
the
runtimes
do
container
runtimes
do
is
that
they
mount
masks
on
top
of
the
files
and
folders
in
proc
in
order
to
prevent
workloads
from
accessing
those
files
and
in
the
kernel
there
is
a
check
that
checks.
B
In
order
to
work
around
that
and
to
never
sort
of
offer
an
unmasked
proc
to
to
the
workspace
container,
we
again
rely
on
workspace
daemon
to
make
that
mount
for
us
and
the
way
that
works
is
that
we
call
out
to
workspace
daemon
with
the
pid
of
the
excuse
me
passing
in
the
pid
of
the
target.
Pid
namespace.
B
B
That's
nice!
So
now
we
have
root
inside
our
workspace
and
it
feels
like
root
and
things
like
apt-get
are
working,
but
docker
isn't
working
yet
and
rootless.
Docker
has
a
has
seen
a
lot
of
work,
first
and
foremost
by
akihiro
souda,
who
has
worked
relentlessly
on
things
like
rootless
kit
and
in
general,
making
docker
work
as
in
in
a
rootless
mode,
but
also
our
friends
from
from
kinfolk
arban
and
his
colleagues
have
done
a
lot
of
work
in
this
space.
B
So
how
do
we
make
this
work?
And
the
key
issue
here
is
that
docker
needs
a
needs,
a
lot
of
capabilities
with
regards
to
networking
and
we
can
provide
those
capabilities
by
pre
by
wrapping
docker
or
the
docker
daemon,
specifically
in
a
network
namespace,
and
to
do
that
we
need
to
provide
some
networking
into
the
outside
world.
So
to
speak,
and
for
this
we
use
slurp
for
net
and
s,
which
is
a
user
land
mechanism
to
make
to
make
network
namespace.
B
For
proc
mounts
because
the
container
that
run
inside
this
or
run
in
this
docker
daemon,
they
will
also
need
specific
proc
mounts
because,
among
other
things,
they're
also
pid
name
spaces.
We
use
the
same
trick
that
we
use
to
create
the
proc
mount
for
the
workspace
container
as
a
whole
or
for
supervisor
ring
ring
one.
B
B
Orchestrator,
so
to
speak
in
this
case
docker
or
containing
id
actually
will
provide,
it
will
create
the
oci
runtimes
back
and
in
there
it
will
have
something
like
mount
proc
and
we
sit
in
between
there.
We
modify
the
the
oci
runtime
spec
and
add
ourself,
as
hook
in
the
container
lifecycle,
to
actually
do
that.
Proc
mount.
B
B
B
C
That
will
be
useful
both
for
the
rfs
of
the
container
to
be
able
to
have
this
different
ownership
of
file
that
will
improve
the
performance
both
in
the
time
on
in
disk
space
and
another
use
case
is
for
volumes.
So
we
have
when
you
have
in
kubernetes
a
host
volume,
you
do
a
buying
mod
from
the
host
to
the
container
to
be
able
to
have
this
shifted
ownership
on
this
file.
C
C
So
what
is
the
use
case
for
that
I've
seen
before
there
is
this
interface
grpc
interface
between
the
workspace
and
the
demand
outside
that?
Do
some
methods
like
prepare,
usernamespace
or
modproc
that
run
a
privilege
operation
like
mod
and
a
matter
of
this
about
second
notify,
because
that
will
be
able
to
provide
the
proper
interface
for
this
kind
of
thing.
So
what
you
will
be
able
to
do
is
to
have
the.
C
So
on
the
next
slide,
I
will
explain
a
bit
that
at
the
top
right
you
see,
I
have
a
second
policy.
That's
where
you
define
for
each
system
calls
if
you
want
to
or
deny
their
access
to
that
instant
call.
But
with
this
second
notify
feature
you
have
a
additional
action
you
can
take,
call
notify
and
what
it
does.
It
will
say
every
time.
The
process
in
the
container
use
that
system
caller.
C
It
will
work
on
exactly
a
couple
of
times
to
create
this
child
process,
and
then
it
will
execute
the
second
system
call
to
with
this
notify
feature,
and
then
you
get
a
file
descriptor
to
be
able
to
get
the
events.
In
this
example.
The
month
system
call
and
that's,
my
descriptor
will
be
passed
to
the
second
chart
that
you'll
be
able
to
run
actions
on
behalf
of
the
container.
So
when
the
container
in
there
and
marked.
C
C
C
So
first
in
kubernetes
the
support
for
username
space.
There
are
two
kubernetes
announcement
proposal
that
for
that
that
I
described
before
and
in
rootless
kit.
If
you
go
to
this
guitar
page
about
rootless
containers,
you
will
find
a
lot
of
a
lot
of
purpose.
Theory:
lots
of
projects
interesting,
like
our
wordpress
kit,
usanitis,
which
is
about
running
kubernetes
without
being
good
sleep
for
netherness,
that
creation
talk
about
on,
buy,
buy
for
lns,
which
is
the
same
thing,
but
with
more
performance
using
second
modify.
C
So
second
modifier
in
kubernetes
doesn't
exist.
Yet
that's
something
that
is
work
in
progress,
but
here
the
some
different
pillar
quest.
So
there
is
a
work
in
progress
to
make
it
available
in
rca
from
time
spec
and
in
ranci
in
sierra
non-con
man.
The
work
is
done
only
and
as
in
fact,
we
are
working
on
this
second
chance,
which
is
a
generic
second
pageant
to
make
it
easy
for
you
to
use
this
kind
of
this
second
notify
feature.
A
All
right,
thank
you
both
for
a
great
presentation
at
this
time
we're
going
to
move
into
our
q
a
segment.
So
if
you
have
a
question
for
our
presenters
feel
free
to
submit
it,
either
through
the
chat
or
through
the
q,
a
box
at
the
bottom
of
your
screen.
That
doesn't
look
like
we
have
anything
submitted
yet,
but
we'll
give
folks
just
a
few
seconds
here
to
submit
their.
A
A
Perfect
awesome,
so
you
can
see
both
of
their
twitter
handles
here
on
the
on
the
screen,
so
feel
free
to
reach
out
with
questions.
I'm
sure
they
would
love
to
chat
with
you
more
about
this
cool
thing
called
get
pod.
Well,
that'll.
Do
us
do
it
for
us
today
here
at
cncf
webinars.
Thank
you
again,
alvin
and
christian
for
this
presentation
and
thank
you
all
for
tuning
in
a
reminder
that
the
recording
and
slides
will
be
posted
later
today
to
the
cncf
webinars
page
stay
safe
out.