►
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
B
Great,
my
name
is
vishal
biani,
I'm
cto
and
founder
of
inferior
technologies,
I'm
one
of
the
fission
maintainers
and
I'm
also
an
active
organizer
of
pune
kubernetes
meetup.
I
am
usually
found
on
twitter
and
linkedin.
You
know
for
connecting
cool.
So
today
we
are
going
to
talk
about
auto
scaling
event,
driven
applications
with
fission
and
cada.
Now
before
we
go
and
understand
the
actual
demo
and
the
application.
Let's
understand
what
fission
is
cool,
so
fission
is
a
serverless
framework
on
top
of
kubernetes.
B
It
allows
you
to
write,
functions
and
focus
on
code
and
not
have
to
worry
about
underlying.
You
know
details
about
infrastructure
or
kubernetes
as
much
while
it
tries
to
hide
the
details
of
your
kubernetes
and
docker
from
you.
It
doesn't
completely
limit
you,
you
can,
you
know,
get
to
as
material
as
you
want,
but
if
you
don't
want,
you
can
always
stay
up
suck
it
from
that,
and
you
know
it
does
support
a
lot
of
indications.
We'll
look
at
that
in
the
subsequent
slides.
B
B
Now,
as
a
developer,
you
might
want
to
write
functions.
You
might
want
to
write
micro
services.
Sometimes
you
might
want
to
just
give
source
code
and
let
fusion
figure
out
build,
deploy,
and
you
know
package
it
into
a
container,
but
sometimes
you
might
say
hey.
I
will
give
you
a
container
and
not
the
source
code
in
all
of
these
scenarios.
Friction
can
help
you,
you
know,
deploy
and
run
microservices
or
functions.
B
B
Now,
once
you
are
deployed
your
functions
micro
services
in
many
of
these
languages
onto
fission,
you
might
of
course
want
to
call
them
right,
so
you
can
call
them
using
http.
Obviously
you
can
also
call
them
using
cron.
There
is
a
crown
you
know,
timer
kind
of
built
into
fission
and
allows
you
to
have
functions
invoke
periodically.
B
You
know
when
you,
when
you
execute
this
functions
and
microservices
we
are
on
github.
Of
course
you
can
find
us
in
fission
fashion.
Please,
you
know,
start
us
and
follow
us,
and
if
you
have
any
issues
in
you
know
buying
out
something,
do
check
out
the
documentation,
join
us
on
slack
and
ask
questions
please.
B
Well,
if
you
look
at
a
very
simple
hello
world
version
of
you
know,
phishing,
basically
right
in
the
first
line.
What
we
are
doing
here
is
we
are
creating
environment
of
node.js
runtime
and
we
are
using
the
efficient
provided
image.
You
know
as
the
base
image
in
the
second
line.
We
are
creating
a
function
called
hello,
js
in
which
we
are
using
the
runtime
being
the
node
data
that
we
dedicated
in
the
first
line,
and
we
are
simply
pointing
to
the
code
on
a
github
repository
now.
B
This
code
line
is
doing
just
a
simple
hello
world,
and
once
we
have
done
these
two
you
know
creations,
we
can
simply
call
it
as
efficient
function
test,
and
you
know
hello
and
we
get
a
hello
world.
Now,
I'm
not
going
to
show
this
simple
example.
You
can
go
and
check
it
out
later
on
your
own,
but
just
gives
you
an
idea
that
without
having
to
understand
the
whole,
you
know
details
of
requirements
or
you
know
other
things.
You
are
able
to
run
a
simple
piece
of
code
onto
phishing
great.
B
C
B
Request
topic
is
subscribed
by
another
function.
Using
a
trigger
now
trigger
is
a
function,
fission
terminology
basically
and
we'll
explain
what
does
that
mean
in
subsequent
slides
now
this
function
will
get
directly
the
message
body
without
having
to
understand
or
talk
to
phishing
at
all.
This
function
is
going
to
process
that
message.
If
there
is
an
error,
it
is
going
to
put
that
into
an
error
topic,
and
this
is
again,
you
know,
facilitated
by
fashion.
B
The
function
doesn't
have
to
know
you
know
it
just
has
to
written
a
response
code
and
the
response
body
so
to
speak.
But
if
the
processing
is
successful,
it
will
return
a
200
response
and
the
message
body,
which
will
be
put
into
a
kafka
topic,
called
response
topic
on
the
response
topic.
There
is
another
function
which
has
subscribed
to
that
topic
using
another
trigger
and
that
trigger
you
know,
will
invoke
this
function.
B
Whenever
there
is
a
message
in
the
response
topic,
this
function,
I
guess,
is
going
to
do
some
more
reprocessing
on
top
of
that
message
and
it
has
the
code
to
actually
write
the
message
to
a
rabbitmq
queue
as
soon
as
you
write
into
the
rabbitmq
called
publisher.
There's
another
function
which
has
subscribed
to
this
message
queue
and
when
there
is
a
message,
this
trigger
will
ensure
that
the
message
is
read
from
the
queue
and
actually
function
is
invoked
with
the
body
of
the
message
as
the
payload
and
then
the
function
is
gonna.
B
You
know
this
last
function
is
to
do
something
more
on
top
of
that
right.
So
the
first
one
we
are
calling
it
kafka
producer,
the
second
one
you
are
calling
it
kafka
consumer,
the
third
one.
We
are
calling
rabbit
producer,
rabbit,
mq
producer
and
then
the
last
one
is,
you
know
just
a
consumer
or
rabbitmq
consumer.
Basically,
now
two
of
them
are
written
in
golang.
Two
of
them
are
written
in
node.js,
and
you
know
we'll
look
at
the
code
of
course
shortly.
B
B
You
know
I'll
talk
about
keratin
in
subsequent
slides
and
this
data
connector
will
now
go
and
read
the
message
from
the
queue
and
call
the
the
next
function
over
http
right
and
the
best
part
is
cada
not
only
spins
up
a
part
only
when
there
is
a
message.
It
also
scales
out
the
parts
when
there
are
more
messages
and
the
scaling
is
different
from
message:
q
to
message
view,
for
example,
in
case
of
kafka,
the
scaling
is
based
on
the
number
of
partitions.
B
In
case
of
rabbitmv,
I'm
not
sure,
but
that
is
based
on
some
other
parameter.
Basically
right,
so
you
know
kind
of
double
clicking
into
the
connected
part
of
it.
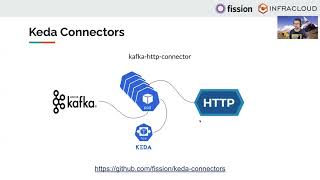
So
a
character
is
nothing
but
a
component
which
reads
from
one
source,
and
you
know,
drops
it
into
another
extension.
So
when
we
say
kafka,
http
connector,
it
is
reading
from
kafka
and
dropping
the
message
as
a
http
payload
and
the
good
part
is.
These
connectors
are
not
specific
to
fission.
B
They
can
be
used
in
any
context
any
environment
as
long
as
you
create
a
power
and
you
set
all
the
right
parameters
in
terms
of
the
you
know:
destination
or
the
source
of
the
queue
the
destination
to
call
and
stuff
like
that,
and
you
can
always
deploy
a
part,
but
the
great
part
is
if
you
require
data
along
with
that
and
define
the
scalars.
You
know
for
that
specific
message
queue.
B
Today
we
have
you
know
about
five
six
hour:
connectors
kafka,
aws,
sqs,
rapid
mq,
aws
genesis,
nas
http,
and
there
are
much
more
coming.
You
know
they
are
being
developed
actively.
So
I
go.
You
know
I
suggest
you
to
go
and
check
out
this
repository
called
cada
connectors,
very
useful
if
you're
doing
anything
with
data
processing,
you
know
between
message,
queues
and
macro
services
and
functions,
basically,
all
right
coming
back
to
the
previous
slide
right.
B
B
The
second
part
of
the
auto
scaling
is
actual
functions.
Now
all
of
these
functions,
for
example,
two
of
them
retain
golang,
two
of
them
written
in
node.js.
They
are
not
running
always
they
only
are.
You
know,
invoked
and
scaled
out
when
there
are
more
messages
coming
in
right.
So
what
we
do
is
in
fashion.
There
is
a
concept
of
environment.
B
If
the
first
message
arrives
at
the
first
or
we
invoke
the
first
function
manually
right,
this
will
be
scaled
if
there
is
more
like
request
coming
in,
but
potentially
just
one
will
be
scaled
initially
right
now
the
message
is
going
to
kafka
topic
and
the
trigger
gets
triggered,
and
this
trigger
is
again
in
auto
scaling
the
actual
parts
which
are
like
keta
connected
parts.
It
calls
the
second
function,
which
is
kafka
consumer.
B
You
know
that
pool
with
one
part
and
then
eventually
to
more
parts
as
the
more
messages
start
coming
in
and
then
it
goes
to
underground
kafka
topic
and
from
there
on
the
trigger
and
then
again
this
function
is
only
scaled
based
on
the
flow
that
is
coming
in
from
this
you
know,
q,
so
to
speak
right
and
so
so
on
and
so
forth
till
the
end.
Basically,
the
idea
is
when
there
are
no
messages
when
there
is
no
activity.
B
Technically,
none
of
the
connectors
are
consuming
any
parts,
so
zero
between
the
golang
and
node.js
environment.
Where
you
know
consuming
about
five
or
six
parts,
you
can
again
configure
this
pool
size
to
be
just
one
or
more
than
one,
basically
right
and
and
when
there
are
messages
it
might
happen
that
each
of
the
data
connector
parts
gets.
Let's
say
from
you,
know:
zero
to
one
two
or
three
parts
and
each
of
the
function.
B
B
So
let
me
switch
the
screen
here
and
go
to
first
of
all
vs
code
and
show
you
some
code
and
then
we
can
go
to
terminal,
try
it
out
and
then
go
look
at
the
rabbitmq
console
and
actually
see
messages
coming
in
basically
right.
So
this
is
our
first
function,
doctor
producer.
It's
a
simple
golan
function.
It
uses
a
specific
contract.
You
know
for
the
defining
of
the
function,
it's
a
handler
function
which
gets
a
request
and
you
return
response.
Basically
right.
B
We
connect
to
the
kafka
queue
here
and
we
create
a
few
random
messages
with
timestamp
and
the
message
id
and
then
you
simply
write
it
back.
You
know
to
the
to
the
message:
queue
right.
Okay,
so
that's
that's!
The
producer
function
right
now
trigger.
I
don't
have
like
there
is
no
code
for
trigger,
but
there
is
like
a
spec
for
trigger,
which
I
can
show
very
quickly
so
all
of
our
functions.
We
are
defining
in
specs.
B
So
consumer
is
the
function
to
be
called
right
and
then
it
talks
about
which
kafka
server
to
talk
to
which
consumer
group
you
talk
to
which
topic
to
listen
to,
and
then
you
define
also
you
know,
polling
interval
and
also,
you
know
like
minimum
practical
around
max
replica
power,
maximum
retries
and
stuff
like
that
right,
you
can
define
all
this
on
the
cli
of
fashion
as
well,
but
you
can
also
define
them
as
a
spec.
It's
a
message
to
trigger
you
know:
custom
resources,
cool,
look
at
the
producer.
B
We
looked
at
one
of
the
triggers.
Now,
let's
go
look
at
the
consumer.
The
first
consumer
gets
directly
the
message
body.
You
know
as
part
of
the
payload
request.
Payload,
you
don't
have
to
connect
to
kafka.
You
don't
know
anything
from
where
the
message
is
coming
right.
So
the
trigger
did
the
job
of
listening
to
that
request
topic.
As
soon
as
there
is
message
read
the
message
converted
it
to
a
you,
know,
specific
format
and
post
to
this
function.
As
part
of
the
request
body,
so
all
we
do
is
get
the
body
we
add.
B
So
the
function
is
completely
abstracted
from
how
it
gets
the
message
and
where
the
message
goes
right
so
very
loosely
couple
now
when
it
goes
to
the
the
second.
You
know
topic
kafka
topic,
which
is
the
response
topic.
We
are
looking
at
the
second
trigger,
which
is
k.
Two
r.
You
know
we
are
saying,
read
it
from
kafka
right
to
a
rabbit,
mq
producer
right
here
again,
you
know
we
have
configured
which
function
to
call,
and
you
know
from
where
to
read
messages.
What
topic
and
stuff
like
that
right?
B
So
that
will
eventually
call
the
rabbit
empty
producer.
Now
again
within
drivertmq
producer,
we
simply
get
the
request
and
the
request
body
is
what
we
get
right
somewhere
down
the
request.body.
Now
the
writing
part
of
it.
Of
course
we
have
to
connect
to
you
know
rival
mpu,
you
know,
give
some
credentials
and
stuff
and-
and
that
is
again
defined
in
the
function
specification.
B
B
It
has
defined.
You
know
what
to
do
and
all
that
stuff
and
the
actual
message
doesn't
know
anything
from
where
the
message
is
coming
or
it
does.
It
gets
a
message
where
you
know
appending
one
more
string
to
the
message
and
then
writing
that
message
right,
so
that
was
overall
flow.
You
know
two
functions
in
golang,
listening
to
kafka
topics
and-
and
you
know
one
last-
one
listening
to
rabbit
mq
and
so
on
and
so
forth.
C
B
Clear
up
all
the
screens,
just
so
that
you
know
we
see
things
a
little
clearly
right.
So
if
I
go
and
look
at
oops
yeah,
you
can
go
and
look
at
the
deployments
in
the
default
namespace.
These
are
for
three
different
connectors
right:
the
kafka
to
kafka
kafka
to
rabbit
and
diabetic
function
right.
If
you
look
at
the
available
replicas
zero,
because
there
is
no
messages
coming
in
all
the
replicas
zero
right.
Similarly,
if
I
show
you
the
hpa's.
B
Secondly,
if
I
look
at
the
pool
the
pool
I
was
talking
about
right,
so
I'm
to
do
two
critical
parts
and
from
physician
function,
namespace.
So
these
are
the
pool
parts.
I
have
three
pool
parts
for
golang
as
the
environment
and
three
pool
parts
for
node.
You
know
jss
environment,
but
if
I
had
to
look
at
functions,
function,
specific
parts
right
so
kgpo
and.
B
C
B
So
right
now
all
the
resources
are
zero.
What
I'm
gonna
do
is
I'm
gonna
call
this
producer.
Now,
in
the
producer
code,
when
we
were
producing
the
message
to
kafka
request
topic,
we
were
producing
about
10
hour
messages,
so
I'm
going
to
call
this
function
a
couple
of
times,
so
it
produces
like
40,
50
or
messages.
You
know.
B
B
B
B
If
I
go
back
again
and
look
at
let's
look
at
r
consumer,
those
were
the
maximum
parts.
I
think
it
has
scaled
down
one
two,
three
four,
five,
six
to
still
six
still
working,
still
working
on
it
and
here
on
the
connector
parts,
the
keta
connector
part
still
one
here,
so
I
can
actually
go
look
at
it
yeah.
There
is
just
one
part
for
r12.
B
B
Okay.
Now
they
are
gone
in
terminating
state
there
you
go
so
from
running
to
terminating
because
it
has
probably
processed
all
of
them.
I
don't
know
why
this
is
still
skill
out
one.
It
should
probably
go
back
to
zero,
hopefully
in
a
minute
great,
so
consumer
parts
for
rabbit,
mq,
already
gone
back
to
kind
of
original
state.
Consumer
power
for
kafka
also
gone
back
to
more
or
less
original
state.
B
Emitting
as
well
right,
so
all
the
function
parts
are
pretty
much
in
terminating
state.
There
is
just
one
part
which
is
for
connector,
which
is
still
in
you
know,
running
state
should
go
back
to
emitting
state
in
a
way
cool,
so
that
is,
you
know,
a
brief
demo.
The
code
walkthrough
and
you
know
how
this
whole
thing
works.
How
truly
it
is
auto
scale
not
just
from
actual
workload
processing
units,
but
also
the
units
which
actually
read
a
message:
queue
and
supply.
A
A
So
what
you
can
do
is
try
this
example,
which
takes
in
six
functions
and
you
what
you
play
with
is
kafka
radish
and
a
database,
and
also
that
has
a
web
ui.
So
vishal
has
already
written
a
blog
post
about
the
same
where
he
is
describing
the
whole
functions.
And
yes,
this
is
something
that
we'll
really
like
you
to
try
and
give
us
your
feedback,
how
you
like
it
and
if
you
have
run
into
any
shoes,
we'll
be
more
than
happy
to
help
you
on
the
slack.
A
If
you
are
starting
your
journey
as
a
fresh
contributor
out
of
college
or
if
you're,
already
part
of
different
communities
and
helping
in
different
projects
we'll
be
happy
to
have,
you
contribute
to
fishing
as
well
and
yes,
definitely
you're.
Just
contributing
to
code
is
just
one
side,
contributing
documentation,
raising
issues
and
helping
with
questions.
In
fact,
asking
questions
is
just
a
marvelous
way
of
you
know
contributing.
So,
yes,
we
would
like
to
connect
with
you
on
slack
or
twitter,
wherever
you
feel
like,
and
just
help
us
out
with
contributions
to
vision.
A
In
fact,
if
you're
interested
in
contributing
to
just
fission,
you
can
also
start
contributing
to
what
cube
so
bot
cube
is
another
project
which
we
started
at
infra
cloud.
This
is
a
chat,
ops
way
of
interacting
with
your
kubernetes
cluster.
It
not
just
allows
you
to
monitor
a
cluster,
but
it
also
allows
you
to
do
some
more
fancy
stuff,
like
creating
deployments
getting
spot
and
all
so.
Yes,
this
is
also
our
open
source
project
that
you
can
start
your
journey
with.