►
From YouTube: Integrating Backup Into Your GitOps CI/CD Pipeline
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
A
Thanks
everyone
for
joining
us
welcome
to
today's
cncf
live
webinar,
integrating
backup
into
your
ci
cd
pipeline,
I'm
libby,
schultz
and
I'll
be
moderating.
Today's
webinar
I'm
going
to
read
our
code
of
conduct
and
then
I'll
hand
over
to
michael
cade,
senior,
technologist
and
member
of
technical
staff
at
castin
by
veeam
a
few
housekeeping
items
before
we
get
started
during
the
webinar
you're,
not
able
to
speak
as
an
attendee.
But
there
is
this
lovely
chat
that
everyone
is
commenting
in.
A
A
Please
also
note
that
the
recording
and
slides
will
be
posted
later
today
to
the
cncf
online
programs
page
at
community.cncf.io
under
online
programs.
They
will
also
be
available
via
the
registration
link
you
used
to
get
into
this
webinar
today,
and
it
will
also
be
on
our
online
programs,
youtube
playlist,
which
is
linked
in
the
chat
with
that,
I
will
hand
it
over
to
michael
to
kick
off
today's
presentation.
B
Thank
you,
libby
yeah,
hey
everyone
and
everyone
on
the
recording,
as
well,
but
yeah
in
terms
of
questions.
I'd
just
like
to
say
that
yeah
I'll
get
to
I'll
get
to
as
many
as
possible.
It's
super
important
to
get
that
feedback
and
answer
those
questions,
because
I
appreciate
that
a
lot
of
us
are
in
different
different
times
of
their
journey,
whether
it
comes
to
complete
rookies
or
pros
when
it
comes
to
the
cloud
native
landscape.
B
B
I've
just
put
some
of
the
links
in
and
I'm
gonna
touch
on
some
of
those
areas,
as
well
as
part
of
the
session,
but
really
the
the
premise
of
the
the
session
is
really
about
integrating
backup
into
your
get
ups
and
I've
put
ci
cd
pipeline.
It's
more
so
your
cd
pipeline
I'm
going
to
get
into
why?
Why
that?
Because
really
the
ci
and
cd,
you
always
see
it
put
together,
but
actually
the
ci
ci
is
one
thing.
Cd
is
another.
They
are
closely
linked,
but
it's
about
deployment.
B
It's
about
delivery
of
your
your
applications
just
before
we
move
on
to
the
next
slide
and
start
walking
through
some
of
this.
A
bit
of
the
theory
before
we
get
into
a
bit
of
live
demo,
is
that
I'm
michael
cade,
I'm
a
senior
global
technologist.
I
live
within
the
office
of
the
cto
at
veeam,
but
really
concentrating
on
our
cloud
and
a
cloud
native
ecosystem,
both
open
source
and
commercial
products.
B
So
I
mentioned
around
continuous
integration
and
continuous
deployment
and
generally
being
two
separate
methods
or
ideologies
that
we
have
when
we're
creating
applications
or
deploying
or
delivering
our
applications.
So
continuous
integration
is
we're
going
to
create
something
we're
going
to
create
our
applications.
We're
then
going
to
put
it
into
some
sort
of
version
control
they're
going
to
build
it.
Maybe
we're
going
to
put
it
into
docker
hub
and
we're
going
to
test
it,
make
sure
that
everything's
good
and
then
the
software
is
available
on
docker
hub
for
us
to
take
now.
B
Underneath
that
the
release
is
has
always
been
there.
We've
always
constantly.
We've
built
our
virtual
machines,
our
physical
machines
we've
installed
software
on
top
and
then
the
release
cadence
has
always
been
whatever
that's
been
from
the
software
vendor
and
we've
deployed
that
out
into
our
into
our
ecosystem
or
into
our
environment
now
or
you're,
coming
from
a
developer
point
of
view,
where
you're
the
you're,
the
people
that
are
actually
writing
the
code
version
controlling
that.
B
Releasing
that
building
that
testing,
that
and
you're
looking
after
that
or
you're
in
the
devops,
where
you
kind
of
linger
in
between
and
you've
got
a
bit
of
everything
that
you're
that
you're
concentrating
on.
So
the
real
focus
for
me
today
is
around
this
bottom
part
of
the
of
the
diagram,
and
hopefully
you
could.
You
can
still
all
see
my
slides
building
out
here,
but
it's
really
from
that
release.
B
Now,
in
this
example,
I'm
using
docker
hub
as
my
source,
but
really
that
could
be
any
container
registry
any
binary
or
anything
that
your
you're,
deploying
in
your
in
your
environment.
So
again
we're
gonna
we're
gonna.
Have
that
update
we're
gonna
have
version
one
version:
one
gets
controlled
through
our
potentially
our
own
version
control
system
and
then
we're
gonna,
deploy
that
most
likely
you're
going
to
deploy
that
into
a
staged
environment
and
then
you're
going
to
validate
that
version.
1
is
good
version.
B
B
One
comes
out
version
two
comes
out
and
that
for
the
most
part
a
sync
can
be
great
and
it's
gonna
keep
keep
updating
for
you
and
that's
why?
One
of
the
big
reasons
get
ups
over
the
last
12
to
18
months
has
been
a
really
big
focus
area
for
a
lot
of
businesses,
because
we're
get
now
getting
to
the
stage
of
well.
How
do
we
automate
that
deployment?
Better
and
in
a
much
more
efficient
manner,
but
then,
when
we
think
about
okay,
I
just
mentioned
persistent
volumes
there
as
part
of
that.
B
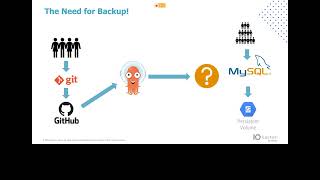
So
let's
say
that
we've
got
some
sort
of
database,
a
mysql
database
and
now
we've
got
potentially
customers
writing
data
in
a
way
to
that
database
could
be
customers,
but
it
also
equally
could
be
people
internally
and
we're
right
into
that
persistent
volume
and
my
sequel
is
the
application.
The
back
end
database
that
I'm
going
to
use,
because
I'm
going
to
use
that
in
my
in
my
example
as
well.
So
what
happens
there
like?
B
We've
got
the
application
in
version
control,
so
I
can
roll
back
and
I
can
roll
forward
from
a
version
one
to
two
to
three
and
I
can
even
roll
back
to
version
two.
If
things
go
wrong
and
they
don't
look
right,
but
version
control
is
not
going
to
be
looking
after
your
mysql
database,
which
has
an
external
user
input,
whether
that
be
a
user
input
from
internal
users
or
customers
outbound,
but
ultimately
that
data
doesn't
get
doesn't
get
stored
in
version
control.
B
B
However,
if
something
has
manipulated
that
data,
then
we're
not
going
to
have
a
copy
of
that
data,
and
what
why
this
is
really
interesting
is
if
we
like,
we
have
the
we
have
a
concept
of
config
maps
within
kubernetes
which
allows
us
to
interact
with
external
services,
but
also
external
data
sets,
and
it's
quite
common
that
those
config
maps
get
used
to
manipulate
data.
It
might
be
that
we
want
to
remove
something
or
we
want
to
change
the
way
we
see
that
data,
or
maybe
we're
shipping
that
data
between
one
database
to
another.
B
Well,
those
config
maps-
if
maybe
you've,
made
a
mistake
through
that
code,
control
and
you've
decided
to
delete
all
of
the
data,
obviously
not
through
choice,
then
that
data
is
not
captured
at
that
point.
So
one
of
the
key
areas
that
we've
been
talking
about
or
thinking
about
from
a
canister
open
source
project
point
of
view
is
well.
How
do
we
make
that
simpler
for
the
people
that
are
deploying
the
application
within
our
environment,
whether
that
is
the
developer,
the
devops
or
the
platform
engineer
and
everything
in
between?
B
So
I
keep
saying
about
data
data's
been
highlighted
and
bolded
and
capitalized
all
the
way
through
this,
but
and
I'll
keep
on
saying
as
well
about
any
persistent
data
or
volumes
used
by
applications
or
they're
not
captured
generally
through
version
control.
There
might
be
some
in
terms
of
lot
like
login
systems,
messaging
queues,
but
you're
not
really
going
to
want
to
store
them
in
your
lean,
efficient,
github
repository,
but
basically
any
staple
set
that
we
have
within
our
environment,
such
as
a
relational
database
such
as
nosql
or
a
nosql
database.
B
That
is
going
to
you're
not
going
to
be
storing
that
data
that
database
or
the
data
within
that
in
a
version
control
system.
So
it
requires
the
entire
application
stack,
including
the
the
data.
Now
we've
already,
we've
already
established
that
we
have
all
the
code
and
that's
great
and
in
other
words
like
we
can
always
deploy
version
one.
Two
and
three
again,
that's
always
a.
B
It
should
be
an
easy
role
now
for
anything
more
orchestrated
around
that
you
might
want
to
go
down
the
route
of
looking
at
other
products
that
allow
us
to
do
that
as
in
an
all-encompass
way.
But
the
data
is
the
most
important
part
if
you
couldn't
tell,
and
the
the
data
and
its
dependencies
of
the
stack
need
to
be
discovered
tracked
and
captured
in
a
way
similar
to
what
we
do
with
version
control.
B
But
version
control
such
as
git
will
not
capture
what
that
is
and
the
way
in
which
we're
going
to
do
that
in
part
of
our
our
demonstration.
In
a
short,
while
is
we're
going
to
use
something
from
a
canister
point
of
view,
called
an
action
set
and
an
action
set
can
be
triggered
either
via
a
cron
job
out
of
band.
B
So
we
just
make
that
happen
on
a
daily
basis,
hourly
basis
using
a
cron
job
within
kubernetes
and
we're
looking
at
how
we
can
better
orchestrate
that,
but
then
also
how
it
also
allows
us
to
use
our
cd
pipelines
to
trigger
that
action
set
which
then
off
allows
us
to
offload
that
into
a
external
data
service.
So
whether
that
be
something
like
aws,
s3
or
s3.
Min
io,
for
example,
and
canister,
is
the
the
lynch
printer
to
be
able
to
move
that
application
data
out
of
the
container
and
into
into
a
a
solid
external
source.
B
So
in
the
scenario,
what
we're
going
to
do
is
I'm
not
going
to
use
the
staging
area
because
I
could
do
and
it's
just
going
to
confuse
what
it
looks
like
on
on
on
on
a
demo.
So
I've
already
deployed
argo
cd,
and
what
I've
done
here
in
particular
is
that
this
could
be
any
kubernetes
cluster
anywhere
in
the
world.
B
B
In
fact,
if
you
want
to
think
about
this
as
a
vet
clinic
and
a
database
we're
going
to
push
some
data
into
that
database.
From
that
perspective,
then
we're
going
to
something's
going
to
modify
that
data.
Now,
I'm
not
going
to
simulate
a
config
map,
I'm
just
literally
going
to
change
that
data
or
I'm
going
to
modify
that
data
in
a
way
we'll
see
when
we
get
to
it.
But
then
let's
say
that
mistakes
were
made,
someone
dropped
the
table,
that's
exactly
what
I'm
gonna
do.
B
B
So
then,
what
we're
gonna
do
is
we're
gonna
leverage
canister
to
not
only
be
backing
up
that
data,
but
we're
also
gonna,
so
we're
gonna
back
up
everything
to
an
s3
bucket,
I'm
actually
going
to
use
minio
also
hosted
on
the
mini
cube
cluster,
not
best
practice,
because
if
you
lose
the
whole
mini
q
cluster,
then
you're
out
of
business.
You
don't
have
an
external
data
copy
of
your
of
your
application
data,
but
for
the
purpose
of
the
demo.
B
Think
of
that
as
an
external
copy
of
the
data
as
simulated
through
this
this
image
and
then
what
we're
going
to
do
is
we're
going
to
again
leverage
canister
with
another
action
set.
So
within
canister
we
have
an
action
set
that
enables
us
to
back
up,
and
then
we
also
have
an
action
set
that
allows
us
to
restore
now
they
use
the
similar
api,
it's
just
about
being
a
push
or
a
pull
into
whatever.
B
B
Now,
I'm
going
to
run
through
this,
we
might
run
through
it
again
at
the
end,
just
to
make
sure
that
we're
clear
on
the
execution
walkthrough
and
how
canister
works,
but
basically
what
we're
going
to
do,
and
I've
already
done
that.
No,
I
haven't.
I
haven't
done
this,
I'm
going
to
go
and
deploy
canister
using
the
helm
chart
into
our
mini
cube
environment
and
you
can
see
there
that's
known
as
the
controller
the
operator
that
we
have
within
there
and
then
we're
gonna.
B
B
I
said
about
nosql
databases,
but
you'll
see
from
that
list:
they're,
not
the
only
ones.
We've
got
things
like
elasticsearch.
I
know,
there's
a
kafka
one
being
worked
on
as
well,
there's
a
any
data
service
that
is
using
a
database
workload
or
some
sort
of
persistent
volume.
We
can
generally
use
a
blueprint
to
lift
data
from
a
to
b
and
that's
the
quite
exciting
thing
about
where
canister
is
at
the
moment.
B
B
The
controller
then
looks
for
the
blueprint
that
we're
asking
for
again
we'll
we'll,
go
and
deploy
that
as
well,
and
then
what
that
does.
Is
it
executes
a
canister
function
against
that
database
workload
and
then
allows
us
to
offload
that
into
object
storage
or
by
taking
the
ability
to
leverage
a
cloud
snapshot
from
that
point,
I
believe
this
can
also
go
to
nfs,
but
don't
quote
me
on
that.
I
need
to
need
to
check
I've
not
done
it,
but
object.
B
B
If
not,
okay
cheers
ivan
okay
cool,
so
you
should
be
able
to
see
this
inception
screen
at
the
moment,
which
is
not
pretty
for
anyone
just
a
couple
of
resources.
I
have
posted
them
in
the
chat,
but
they
might
have
been
early
on
so
kind
of
just
want
to
run
through
a
couple
of
places
where
you
can
go
and
find
more
about
canister
one
is
canister.
B
Io
super
simple:
it's
going
to
give
you
a
bit
more
information
about
what
it
is
we're
going
to
show,
but
as
a
project,
I'm
going
to
show
you
one
aspect
that
canister
can
be
used.
Candlestick
can
absolutely
be
used
as
a
standalone
tool
to
just
take
those
point-in-time
backups
of
your
application
data.
B
So
you'll
find
here,
you
can
go
and
fork
it
on
github.
Give
it
a
star
interact
with
us.
Have
a
discussion
give
us
your
ideas,
contribute
more
than
more
than
welcome
to
to
get
involved
with
with
what
we're
doing
over
here
I'll,
deploy
it
as
well.
The
instructions
are
also
there.
Another
one
is
docs.canister.io
and
again
this
is
just
going
to
go
into
a
little
bit
more
detail.
B
B
You
can
see
that
it's
very
active
so
three
days
ago
was
the
last
last
commit
you
can
see
that
the
releases
are
going
up.
It
is
a
helm,
chart
deployment
but
go
and
have
a
play.
Everything's
written
in
go
you'll
also
see
a
list
of
community
applications
as
well
as
stable
applications.
If
you
go
into
examples
and
stable,
then
you'll
see
that
long
list
that
I
had
in
the
slides
and
then
also
just
take
a
look
at
some
of
the
other
community
workings
that
we
have
at
the
moment.
B
So
being
able
to
use
canister
to
protect
aws
rds,
so
not
all
not
always.
Does
the
data
service
live
within
the
kubernetes
cluster,
so
we
want
to
be
able
to
protect
that,
but
maybe
the
application
maybe
the
front
end.
Maybe
this
stateless
part
of
the
application
does
live
within
the
kubernetes
cluster
and
the
data
lives
outside.
Well,
we
we
can
use
canister
to
be
able
to
protect
that.
From
that
point
of
view,
you
also
see
things
like
kafka
in
here,
as
well
as
a
demo
system
called
time
log.
B
B
I
don't
know
if
I
did
share
that
at
the
beginning,
but
basically,
what
we're
going
to
do
is
we're
going
to
install
canister
so
in
fact
rollback
one
we're
going
to
deploy
minicube
again.
This
will
work
on
any
of
your
x86
kubernetes
clusters,
I'm
just
using
mini
cube
because
a
lot
of
us
don't
have
access
to
aks,
eks,
gke
managed,
kubernetes
services
so
being
able
to
use
mini
cube
on
literally
pretty
much
any
any
desktop
machine
laptop.
B
This
gives
us
a
huge
opportunity
to
be
able
to
leverage
that
and
actually
see
it,
because
I
think
that's
one
of
my
big
things
about
learning
and
learning
in
public
is
well.
It
needs
to
be
accessible
so
how
to
how
to
install
canister.
So
we
run
through
adding
the
the
helm
repository
creating
the
namespace
we'll
run
through
this
deploy
in
argo
cd.
I've
put
the
steps
in
I'm
not
going
to
do
that
today.
B
B
So
I
probably
don't
need
to
go
into
that
too
much,
then
we're
going
to
create
a
canister
profile
using
can
ctl
now
can
ctl
is
the
cli
for
canister
original
naming
is
that
this
gives
us
the
ability
to
create
those
three
things
that
we
first
spoke
about,
so
being
able
to
create
your
profile,
but
then
also
being
able
to
interact
with
those
blueprints
as
well
as
being
able
to
create
the
action
set
as
well.
So
we're
gonna
create
the
canister
profile
using
canned
ctl.
B
B
If
we
can
go
and
look
at
that
again
in
the
in
the
github
repository
and
then
we'll
just
confirm
that
we've
got
it
and
then
what
we're
going
to
do-
and
this
is
so
at
that
point
I
could
just
use
canister
to
go
and
protect
my
application.
That's
been
deployed
without
using
argo
cd,
but
that
probably
wouldn't
fit
the
bill
for
the
for
the
session.
B
B
B
Of
the
github,
but
then
also
being
able
to
leverage
something
like
arcade
so
arcade
from
a
alex
ellis
point
of
view,
an
open
source
application
marketplace,
kubernetes
marketplace
and
in
here
you're
gonna
find
canister
is
available
within
within
here.
So
I
think
that
was
it.
I
think
me
jumping
around,
isn't
probably
helping,
but
so
yeah
we're
gonna,
restore
our
database
and
get
get
our
data
back.
B
So
just
to
confirm
our
environment,
so
I
have
a
mini
cube.
Just
called
simple
mc
demo,
we're
using
the
docker
driver,
we're
using
container
d
as
the
runtime
blah
blah
blah
port
version
of
kubernetes
and
how
many
nodes
you
can
also
see
here
that
we
have
that
one
node
and
then
you
can
see
here
that
we
have
these
name
spaces.
So
we
have
argo
cd.
We
have
our
our
default
namespaces
and
then
we
have
minio.
B
Obviously
we
don't
have
any
canister.
So
what
we
want
to
do
first
is
we
want
to
add
canister
helm
now
I
already
have
that.
So
if
I
do
helm
repo
list
you're
going
to
see
that
I
have
canister
in
in
play
already-
and
I
have
just
done
an
update
beforehand,
so
I'm
deploying
the
I
have
the
latest
helm
charts
available.
B
Now
it
should
work
with
72
as
well,
I'm
not
as
daring
but
72.
Only
just
came
out,
as
you
saw
three
days
ago,
I
haven't
tested
it.
I
wanted
the
demo
to
to
go
as
it
should.
Okay,
so
we
can
go
and
deploy
that
this
doesn't
take
very
long
at
all
to
spin
up
before
we
do
that.
What
we're
going
to
do
is
we're
going
to
go
and
check
out
some
custom
resource
definitions
that
get
deployed
as
part
of
the
helm
deploy
of
of
canister.
B
B
So
you
can
see
that
we
create
these
custom
resources,
custom
resource
definitions,
so
that
we
can
then
leverage
that
as
part
of
the
the
kubernetes
api.
So
if
I
then
quickly
run
a
cube,
ctl
get
pods
under
canister,
okay,
good
stuff,
less
than
a
minute
and
we're
up
we've
deployed
argo
cd.
Like
I
mentioned,
we've
created
our
bucket
in.
B
B
B
You
see
that
there
isn't
a
profile
in
our
namespace,
but
we
want
to
create
that,
and
this
is
going
to
create
the
location
profile
for
us
to
store
our
backups
in
that
min
io.
So
I've
already
set
these
environment
variables
with
the
commands
up
above
so
in
theory.
Unless
I've
cleared
out
my
cache,
which
is
absolutely
possible,
I
should
be
able
to
run
all
of
this
and
it
goes
and
creates
a
secret
as
part
of
that
using
the
access
key
in
the
secret
key
and
it
creates
our
profile.
Now.
B
If
I
go
back
and
run
get
those
profiles
in
theory,
there
should
be
one
now
called
s3
profile:
6v,
nv9,
okay,
so
we've
confirmed
that
we
have
that
profile.
I've
jumped
ahead
notice
as
well.
If,
if
I
was
to
use
so
here
in
the
instructions-
and
I
need
to
change
that,
and
maybe
anyone
on
the
call
that
wants
to
dive
in
and
just
contribute
that
to
my
repo,
if
I
do
a
cube,
ctl.
B
B
I
should
say
okay,
so
we
can
check
that
in
our
environment,
make
sure
that
has
created
like
no
spoilers
here.
It's
definitely
going
to
be
there
because
it
just
said
created:
okay,
now
we're
going
to
flip
to
argo
cd
to
deploy
our
app
and
we're
going
to
create
a
namespace
called
mysql.
I'm
actually
not
going
to
do
that
because
we
can
do
it
as
part
of
the
the
app
deployment.
B
B
I
need
to
take
that
and
I
need
to
jump
into
here
and
we'll
go
new
app,
so
we're
going
to
call
this.
What
does
it
say?
My
sequel?
I've
probably
kept
it
quite
simple
project,
name,
my
sequel,
namespace,
my
sequel,
super
simple
right.
My
sequel
project
is
going
to
be
default.
We're
going
to
use
a
sync
policy
of
manual
now
you
might
in
your
own
testing,
want
to
make
this
automatic.
So
any
new
changes
happen.
They
can
automatically
be
rolled
out
within
your
environment.
B
B
So
sometimes,
if
you've
ever
seen
me
do
this
demo
before
we
could
use
base-
or
we
could
just
say
right-
everything
everything
available
in
our
whole
github
repository,
we
could
just
say
dot
and
that
goes
recursive
through
through
everything-
might
save
someone
a
couple
of
seconds
going
through
going
through
the
documentation
cluster
url.
So
the
default
cluster
url
and
our
mysql
namespace,
we
could
say
directory
recurs
as
well
here
to
go
through
everything,
but
I
think
before
we
do
that.
Let
me
go
back
down
here.
B
Let's
do
a
get
pods,
my
sequel
that
might
fail,
because
there
isn't
one
nope
we're
good
at
the
moment.
So
if
I
go
create
okay,
I
now
need
to
go
into
this,
but
it's
saying
it's
out
of
sync,
but
you
can
see
here
that
it's
going
to
go
and
deploy
the
my
seat
is
going
to
deploy
the
my
sequel
namespace
with
a
secret
called
my
sequel,
a
service
called
my
sequel
and
a
a
staple
set
called
my
sequel.
B
I
haven't
done
anything
wrong,
well
good
stuff,
but
what
you'll
see
here
is
that
we've
actually
already
kicked
off
a
canister
precinct,
I'm
going
to
show
you
what
that
looks
like
as
well.
So
if
we
have
a
look
at
our
where's
argo
now
you
you
suddenly
now
see
a
load
more
things
that
have
appeared.
So
we
have
our
canister
precinct,
which
is
actually
a
a
user
account.
We
have
a
job,
we
have
a
role-based
access,
admin
role
and
an
operator,
okay,
good.
B
So
what
else
does
it
do?
It
then
throws
that
data.
So
everything
looks
good.
That
pod
is
just
coming
up.
If
I
go
into
here
again,
we're
gonna
see
that
my
sequel
is
one
of
one:
let's
go
back
into
our
that
should
refresh
any
second,
and
if
we
go
into
our
min,
I
o
browser.
Although
there's
nothing
there,
we
should
see.
B
And
this
might
kick
me
out
because
there
was
nothing
to
back
up,
because
there
wasn't
actually
a
my
sequel
database,
two
back
up,
so
our
action
set
would
have
gone
in
there
and
gone
there's.
No
there's
no,
nothing
to
back
up.
So
with
that.
What's
going
on
here,
let's
just
hit
refresh
okay
everything's
good
okay.
So
what
does
it
want
us
to
do
next?
B
So,
let's
clear
that
so
our
application
is
now
running
version.
One
has
been
deployed,
we've
got
a
safe,
canister
precinct
that
we
know
is
running,
but
we
don't
have
any
data
because
we
have
no
data
in
our
environment
right
now,
so
once
deployed
check
the
service
account.
That
was
the
essay
that
I
was
thinking
of.
Is
the
service
account
for
canasta
precinct
can
create
an
action
or
read
a
profile
set.
B
B
And
that's
good!
The
answer
should
be
yes
for
both
good
stuff.
Okay,
now
we're
going
to
actually
go
and
create
some
data,
so
think
about
this
as
being
the
external
data
set
and
someone
is
coming
through.
Maybe
a
web
portal
and
they're
submitting
some
information
that
they
want
to
be
stored
on
this
database.
B
B
B
Oh
as
if
by
magic
there's,
my
my
sequel,
backups
and
you'll,
see
that
in
here,
if
we
drill
down,
we've
got
a
date.
We've
got
a
time,
but
we've
got
that
mysql
dump.
Now
we
could
take
that
and
we
could
go
and
deploy
that
and
restore
that
into
any
other.
My
sequel
and
that's
another
another
session
for
another
time
is:
it
gives
us
the
ability
to
be
quite
fluid
in
where
we
take
that
data.
B
Obviously
I'm
using
very
unsecure
not
best
practice
because
the
sake
of
time
and
demo,
but
you
can
see
here
that
everything's
good
we've
synced
everything
is
okay,
so
back
in
here,
and
hopefully
everyone's
still
following
along
with
my
sporadic
changes
in
windows.
So
let's
imagine
you
create
a
mysql
client
app,
which
is
going
to
drop
your
database
in
your
code.
That's
a
mistake,
but
mistakes
happen
so
create
this
pod.
B
B
B
We
can
do
a
watch
on
there
because
we're
going
to
actually
remember
we're
going
to
go
and
create
we're
creating
that
client,
but
we're
also
going
to
take
a
backup
first.
So
we
are
going
to
take
it
back
up
before
we
deploy
our
new
mysql
client
covering
us
because
think
about
this
as
going
from
version
one
to
version
two,
but
some
of
our
code
is
going
to
manipulate
our
database.
Our
actual
core
data
service.
B
So
when
that's
done,
we
want
to
jump
back
in
and
remember.
I
showed
you
as
part
of
that.
My
my
sql
client
is
that
that's
going
to
drop
the
database
test
the
test
database
that
we
created.
I
should
be
more
original
with
how
I
call
these
databases,
part
of
the
demo,
so
I'm
being
impatient,
but
I
think
that's
because
there's.
B
B
B
So,
first
of
all
we
before
so
the
sink
above
represents
a
simple
change
in
code
that
could
affect
our
data.
At
this
stage,
the
bad
mysql
client
yaml
should
be
removed
or
configured
correctly
before
continuing
with
the
restore
process.
So
this
is
really
me
saying
about.
This
could
be
a
a
config
map.
This
could
be
any,
but
whatever,
whatever
you've
just
committed
to
your
database
is
or
whatever
you've
just
committed
in
terms
of
code,
has
manipulated
your
data
and
caused
some,
of
course
some
bad
stuff.
B
B
And
then
push
that
up
good
stuff
did
it
before
it
timed
out
on
the
on
the
last
bit?
Okay,
so
before
we
restore,
we
should
check
that.
We've
got
those
restore
points
we
looked
and
we
saw
them
in
inside
min.
I
o
inside
our
object
storage,
but
actually,
let's,
let's
take
a
look
at
action
set
and
it's
stored
within
the
data
center.
Sorry
within
the
canister
namespace,
okay,
so
we
have
two.
B
They
look
very
different
to
those
in
terms
of
naming,
because
we
want
to
be
able
to
name
and
differentiate
when
and
when
these
were
taken.
So
what
we're
going
to
do
is
when
we
have
the
list,
we
choose
the
correct
action
set
to
restore
from
now.
I
want
to
go
back
to
this
one
because
that
one's
the
the
latest-
and
we
know
that
that
one
was
before
the
code
change
in
terms
of
the
the
code
change
that
manipulated
our
our
data.
B
Let's
copy
that
and
drop
that
in
there,
and
so
now
what
we're
doing
with
can
ctl
so
can
ctl
is
used
to
create
your
profiles
in
terms
of
where
you're
going
to
store
your
backups,
but
it's
also
used
to
create
your
action
sets
now.
If
we
weren't
using
argo
cd
to
create
our
action
set,
we
would
be
able
to
use,
can
ctl
to
create
that
here.
But
you'll
see
here
that
action
is
a
restore,
not
a
backup
from
our
restore
set.
B
Kinda
stuff
describe
action
set
and
then
let's
delete
that
restore
action
set.
So
you
see
now
that
we
want
to
go
and
pull
this
action
set
because
we
created
a
new
one
called
called
that
I've
missed
off
the
r
need
that
right,
paste,
okay.
So
now
what
this
is
going
to
do
is
give
us
a
description
of
everything.
That's
happened
so
we
executed
the
action
restore.
We
executed
it
from
blob,
store,
meaning,
object,
storage,
we
completed
that
restore
phase,
and
then
we
updated
the
action
set,
restore
blah
blah
blah
to
status
complete
okay.
B
B
B
Use
test
select
from
pets,
good
stuff
diane
will
be
happy
that
we
now
have
our
data
back
in
our
database
and
then,
if
we
go
over
to
so
remember
we
changed.
We
took
away
this
mysql
client.
So
if
we
go
and
sync
that
now
in
theory
that
should
get
well,
it
won't
be
deployed
again,
but
a
new
backup
will
take
place.
If
we
come
back
into
our
base.
B
B
B
A
A
No
questions,
michael:
if
there's
anything
you
have
to
wrap
up
with
I'll.
Let
you
do
that
and
then
we
can
give
everybody
a
couple
minutes
back,
but
the
recording
will
be
on
youtube
at
the
link
on
the
youtube
playlist
after
the
after
this
ends,
sometime
this
afternoon
and
you'll
be
able
to
find
it
through
your
registration
link
as
well.
A
B
Some
of
these
features
are
already
in
so
I
just
want
to
highlight
these
three
big
features
file
store
destinations,
I
mentioned
nfs.
Maybe
I
just
blew
the
cover
off
that,
but
that
that's
one
of
the
destinations,
as
well
as
others,
also
being
able
to
encrypt
the
dupe
and
compress
those
as
well
using
another
binary
called,
can
do
and
then
improving
our
canister
functions
to
manage
certain
data
services
like
or
data
service
operators
such
as
kate
sanders
so
from
from
datastax
and
their
open
source
initiative
there
again,
this
is
a
big
shout
out.
B
This
is
a
community
effort.
Anyone
that
wants
to
take
a
look
ask
questions,
learn
more
contribute.
We're
all
very
welcome.
Welcome
into
that
go
and
take
a
look
see
what
you
think
ask
the
questions,
and
I
think,
on
closing,
please
take
a
look
at
the
the
project.
I
think
there's
some
really
cool
stuff
in
there.
This
is
just
a
a
little
bit
of
the
the
the
puzzle.
Like
I
said
about,
we
could
go
into
a
canister
overview
which
we've
done
in
the
in
the
past.
B
There's
some
other
areas
around
protecting
like
aws,
rds
or
data
services
outside
the
cluster.
The
way
in
which
we
make
this
better
is
feedback
from
the
community
and
contributions
spread.
The
word
and
yeah
the
concentration
here
is
it's
an
open
source
framework
for
application
level,
data
management
on
specifically
kubernetes,
so
yeah.
I
think
with
that.
That's
probably
a
good
place
to
to
finish
it
libby.
A
All
right
well,
thank
you.
So
much
michael.
Thank
you,
everyone
for
joining
us
again.
You
will
find
the
recordings
later
today,
along
with
the
slide
deck.
So
just
look
for
that
there
and,
if
you
have
any
questions,
join
us
on
slack
or
reach
out
directly
and
we'll
see
you
next
time
thanks,
everybody.