►
From YouTube: CNCF Live Webinar: Kubernetes 1.22 Release
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
Hello,
everyone
thank
you
for
joining
us.
We're
gonna
go
ahead
and
get
started.
Welcome
to
today's
cncf
live
webinar,
kubernetes
1.22,
release,
I'm
libby
schultz
and
I'll
be
moderating.
Today's
webinar
I'm
going
to
read
our
code
of
conduct
and
then
hand
it
over
to
savita
raganatan
james
lavarak
and
jc
butler
of
kubernetes
1.22
release
team,
a
few
housekeeping
items
before
we
get
started
during
the
webinar.
You
are
not
able
to
talk
as
an
attendee.
There's
a
q,
a
box
at
the
bottom
of
your
screen.
Please
feel
free
to
drop
your
questions
there.
A
Please
also
note
that
the
recording
and
slides
will
be
posted
later
today
to
the
cncf
online
programs
page
at
the
at
community.cncf.io
under
online
online
programs.
They
are
also
available
via
your
registration
link
and
the
recording
will
be
available
on
our
online
programs,
youtube
playlist
on
the
cncf
channel.
B
Hey,
thank
you
so
much
libby
and
thanks
for
having
us
we're
really
happy
to
be
here
to
talk
about
the
reaching
new
peaks
release.
Kubernetes
122.,
my
name
is
jesse
butler.
I
served
as
the
coms
roll
lead
for
122
and
I'm
joined
by
james,
who
is
the
enhancements,
lead
and
savita?
Who
was
our
release
team
lead?
This
was
my
first
experience
in
the
release
team.
B
B
First,
we're
going
to
start
with
sort
of
a
sneak
peek
at
what's
coming
in
123,
and
then
we're
going
to
talk
about
some
of
the
122
highlights
on
the
theme
and
some
of
the
the
bigger
feature
releases
are
blanked
on
that
word
and
then
the
bulk
of
the
presentation.
The
session
is
going
to
be
going
through
the
feature
and
enhancements
updates
for
each
of
the
sigs,
and
we
will
leave
some
time
for
q
a.
B
C
Thank
you
jesse.
So
much
like
yourself,
I'm
actually
on
the
123
release
team
as
well
enjoy
enjoy
the
process.
So
much
went
back
and
did
it
again,
so
it's
going
to
be
great
fun
going
through
this
process
again.
The
123
release
is
currently
in
progress.
We
are
about
halfway
through
at
this
point.
We
started
back
at
the
end
of
august
and
we
have
already
passed
the
first
big
big
milestone,
which
is
enhancements
freeze
where
we
confirm
which
enhancements
are
actually
going
to
make
it
into
the
subject
of
further
deadlines.
C
C
One
important
thing
to
note
with
123
andrew
122
as
well
actually
is
that
the
kubernetes
project
has
adopted
a
slightly
longer
release
cycle,
so
the
release
cadence
has
changed
from
four
releases
per
year
to
three
releases
per
year
as
such
kubernetes
123
is
scheduled
to
be
the
last
release
of
122
with
124
scheduled
to
begin
in
january
next
year,
and
with
that
I
think,
that's
all
I
had
to
say
about
the
upcoming
release.
So
of
course,
look
out
for
this.
D
Thank
you
james
and
thank
you
jesse.
So
next
slide,
please
thank
you
a
little
bit
about
the
team
and
the
logo
for
the
release.
So
the
theme
of
the
1.22
release
is
reaching
new
peaks
and
related
to
the
entire
release
team
and
the
contributors
of
the
kubernetes
community,
in
whatever
form
that
you
might
have
contributed
by
reporting
an
issue,
a
bug
fixing
something
creating
features
providing
review
marketing
anyway.
This
logo
is
dedicated
to
you
we.
So
this
is
like
a
remembrance
and
kind
of
motivation.
D
Through
the
tough
times
it
must
be
pandemic
and
the
constant
burnout
and
everyone
moving
and
taking
up
new
opportunities
their
way
and
a
lot
lots
of
struggle
over
the
past
two
years.
But
still
the
community
came
together
and
we
did
deliver
something
really
awesome.
There
was
a
lot
of
chaos,
but
this
is
like
till
date
the
biggest
release
like
we
had
56
enhancements
shipped
in
this
release
and
kudos
to
everyone
who
worked
on
it
to
talk
about
the
logo
a
little
bit.
D
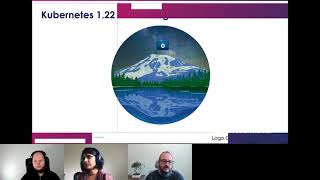
The
logo
is
designed
by
my
girlfriend,
boris
zodkin,
and
he
I
just
told
him
the
mission
about
having
a
mount
rainier
and
the
backdrop
at
the
community's
flag
in
the
milky
way
and
everything
and
it
just
brought
everything
to
life.
It
looks
really
beautiful
and
personally
for
me,
whenever
I
visit
seattle,
mount
rainier
gives
me
hope
and
motivation,
and
I
see
it
that
this
will
help
everyone
like
whenever
they
look
at
it.
They
get
a
little
motivation
and
hope
and
joy
and
little
adventures
and
also
the
achievements.
I
hope
at
all.
D
Everyone
can
remember
those
tiny
little
things
and
keep
moving
on.
That's
all
about
the
logo
on
the
team.
Can
we
move
that
more
on
to
the
next
one?
Please
all
right.
Like
I
mentioned
this,
release
is
like
by
far
the
biggest
one.
We
had
51
enhancements
a
ship
in
1.21,
and
that
was
the
biggest
then,
and
now
we
have
like
56,
including
three
replications.
D
We
have
like
13
stable
enhancements
up
and
24
of
the
enhancements
got
graduated
to
beta,
and
we
also
have
like
a
lot
of
new
features
that
got
introduced
in
the
1.21
22
release.
I'm
sorry
about
that
and
we
also
have
three
applications.
The
alpha
features
are
super
new
and
in
order
to
use
them,
you
need
to
enable
the
feature
gate
and
there
is
a
request
for
the
community
that
I
wanna
put
forth.
D
D
Thank
you.
So
we
do
have
a
lot
of
features
and
we
have
bubbled
up
a
few
of
them
and
they
are
grouped
together
as
the
major
themes
it's
just
not
limited
to
these.
We
do
have
a
whole
lot,
which
we
will
talk
in
the
later
slides,
but
to
just
give
a
sneak
peek
of
what
we
will
be
talking
about.
The
first
one
is
server
side
apply.
D
D
With
this
feature,
it's
all
server
side
and
it
also
uses
a
new
object,
merge
algorithm
and
then
it
keeps
a
track
of
the
field
ownership
and
it
runs
on
the
communities
api
server.
This
is
like
the
most
declarative
way
to
use
the
apply,
and
it
also
helps
the
non-client
girl
versions
and
also
languages,
and
also
like
non-cube
color
plugins,
to
use
apply.
So
that
feels
like
a
huge
feature
boost
to
me
and
moving
on
to
the
next
one
everyone.
D
This
is
a
little
bit
about
the
quality
of
service,
especially
for
the
memory
resources.
Whoever
has
been
an
administrator
or
whoever
has
worked
on
coding
applications
would
know
the
pain
of
benchmarking,
the
apps
and
trying
to
put
them
on
kubernetes
and
all
of
a
sudden
like
it
gets
killed
by
oom
right.
That
is
like
the
infamous
infamous
bug
or
like
it.
It's
always
one
one
way
or
the
other.
That's
that's
my
experience
and
I
have
been.
I
worked
as
a
platform
administered
for
like
four
five
years.
D
It
comes
down
to
om,
so
with
kubernetes,
initially
used
c
groups.
We
won
implementation
and
that
didn't
give
enough
that
didn't
provide
enough
ways
to
measure
the
memory
resources
properly
and
it
used
memory
limit
invites,
and
then
it
used
the
om
scores
to
kill
the
parts
whenever
an
oh,
it's
nothing,
but
out
of
memory.
D
D
There
is
guaranteed
memory
resources
whenever
it's
reserved,
which
was
an
issue
before
and
then
get
a
way
to
provision
the
bustable
memory
allocation
and
so
many
other
new
features
with
that
that
went
into
the
1.22
release
and
moving
on
to
the
next
one.
It's
about
security.
This
has
been
a
long
requested
feature.
One
might
say
this
is
about
running
the
cube,
adm
control
plane
in
and
on
user
non-root
users.
D
It
includes
the
overall
security,
and
this
feature
is
off
right
now
and
if
you
want
to
use
it,
you
have
to
remember
to
turn
the
kubernetes
cube.
Idiom
specific
rootless
control
plane
feature
gate
on
and
if
you
have
any
feedback
do
reach
out
to
the.
I
think
it's
from
singapore
we
will
get
to
that
later.
Do
reach
out
to
the
cap
owners
or
just
shoot
a
mail
in
the
kubernetes
slack,
and
people
will
be
able
to
read
it
in
the
right
direction.
D
Next
slide.
Please
thank
you.
Continuing
with
a
couple
more
actually
three
more
of
the
major
themes.
The
first
one
is
like
the
note
swap
support.
This
was
also
a
problem
that
I
have
often
seen
whenever
there
is
this
java
application
that
got
containerized
and
then
they
want
to
run
on
the
kubernetes.
It
takes
a
lot
of
startup
time
and
not
start
off.
D
So
that
is
that
is
this
is
in
alpha
2.
That
is
it's
a
new
feature.
So
if
you
want
to
turn
it
on,
you
have
to
remember
to
enable
the
feature
grade.
Moving
on
to
the
next
one,
I
want
to
give
a
special
shout
out
to
the
sig
windows
folks.
They
have
worked
really
really
really
hard
to
make
sure
that
all
the
good
features
of
kubernetes
is
also
available
in
windows,
and
they
also
have
released
a
tool
called
sig
window
dev
tools
and
that
repo
is
in
kubernetes
6..
D
It
supports
like
multiple
cni's
and
can
run
on
multiple
platforms
by
platforms.
Here
they
mean
that
like
hyper-v,
virtualbox,
vsphere
or
any
vagrant
compatible
provider,
and
it
actually
provides
sandbox
for
running
the
cutting
edge
windows,
features
from
scratch,
and
you
can
do
that
by
building
the
cubelet
on
the
windows
cubelet
and
I
think
they
have
more
instructions
on
the
repo
and
I
will
post
a
link
later
in
the
chat
so
that
folks
can
take
a
look
at
it.
D
So
special
shout
out
to
the
windows,
4
sync
windows,
folks,
and
thanks
for
making
communities
available
on
the
windows
side
as
well.
Moving
on
to
the
next
one,
it's
all
it's
again
about
security.
This
is
also
an
alpha
feature,
and
this
is
a
basically
making
the
cluster
when
you
deploy
the
cluster,
make
the
cluster
secure.
D
D
I
think
it's
like
a
special
interest
group
within
the
kubernetes
ecosystem
of
projects,
and
it's
nothing,
but
there
are
like
multiple
core
components
and
they're,
like
I
think,
verticals
inside
kubernetes,
like
storage
network
node,
art
security
documentation,
so
each
of
them
are
each
of
them
are
a
unit
on
their
own
and
a
special
interest.
Group
people
come
together
and
work
on
improving
that
little
unit
and
then
make
sure
that
it
works
well
with
other
units
too,
and
there
are
like
multiple
work.
D
Other
different
groups
called
working
groups
which
can
span
across
the
sinks
when
they
want
to
interact
with
multiple
six.
It
becomes
a
working
group
and
so
on.
So
just
that's
a
little
bit
background
about
this
thing,
because
so
many
people
here
think
and
they
don't
know
what
it
is.
So
it's
like
nothing,
but
a
special
interest
group
focusing
on
one
little
core
component
of
kubernetes
might
not
be
accurate,
but
that
is
the
easiest
way
that
I
could
come
up
with,
so
that
folks
can
relate
to
it
in
a
way
james.
D
D
The
goal
was
to
provide
a
comprehensive
declarative
approach
to
use
apply,
and
this
feature
delivers
it,
and
the
highlight,
like
I
mentioned
before,
is
that
it
can
be
used
by
non-dell
languages
and
also
like
non-cucurl
clients.
You
can
use
call
you
can
use
anything
like
those
non-non-native
pupil,
clients.
D
Thank
you
and
the
next
one
is
warning
headers
when
using
duplicated
apis.
If
you
have,
if
you
ever
have
in
a
cluster
admin,
and
your
company
is
supporting
your
company
has
a
product,
but
that's
not
kubernetes
and
kubernetes.
It's
just
an
additional
thing.
That's
supporting
a
major
product.
You
wouldn't
have
that
time
to
update
kubernetes
every
release
cycle
as
much
as
you
would
have
tried.
There
are
like
other
objectives.
D
I
have
been
a
victim
of
that.
I
never
got
to
update
the
kundalini's
versions
like
on
time.
I
was
always
like
two
versions
behind
three
versions
behind
or
I
was
jumping
between
like
two
three
versions
like
I'll
be
on
1.14
and
I
jump
to
1.18,
and
there
was
no
way
to
know
like
what
are
all
the
abs
that
got
duplicated.
What
is
the
way
to
audit
what
to
do
like
how
to
communicate
it
to
the
users
or
are?
D
Is
the
platform
users
are
using
any
of
the
deplicated
api
and
that
they
are
not
catching
it?
So
this
feature
is
for
that.
This
actually
enables,
when
enable
it
lets
the
users
in
the
cluster
administrators
to
recognize
and
remedy
the
problematic
apis
or
api
duplicative
eps
that
they
are
using,
and
it
can
also
provide
auditing
information
that
can
be
later
processed
into
like
you
can
reach
out
to
the
group
and
say
hey:
these
are
all
the
rest,
duplicated
things
and
we
are
using
it.
D
The
next
one
is
enable
label
selectors
for
all
namespaces.
Basically
before
this
feature
was
available,
the
namespace
didn't
have
any
identifying
labels
per
se
and
you
need
to
have
a
right
access
to
add
a
label
and
the
names
namespace
and
bit
of
the
labeling.
It
was
very,
it
would
have
been
very
hard
to
apply
network
policies,
and
you
cannot
just
group
the
policies
together
by
telling
like
exclude
these
namespaces
or
include
these
namespaces,
because
there
was
no
identifying
flags
before.
D
This
feature,
which
is
beta
in
1.22,
actually
aims
at
providing
protection
against
the
overlord
and
also
ensuring
there
is
fairness
among
the
tenants
that
not
one
tenant
is
getting
prioritized
over
the
other
and
also
in
addition
to
that.
As
a
bonus,
it
also
works
on
optimizing
the
throughput.
So
I
think
it's
overall
a
great
feature
and
a
much
needed
one.
Moving
on
to
the
next
one
apps
james
is
gonna,
take
over
and.
C
C
Just
as
a
note,
that's
featured.kates.io
link
at
the
bottom
there.
If
you
follow
that
in
will
take
you
to
a
github
issue
which
has
a
lot
more
detailed
information.
So
if
anyone
following
along,
what's
going
on
at
home
or
wants
more
information,
if
you
just
talk
about
that
link
with
the
issue
number
it
can,
it
can
get
you
some
more
information,
so
the
first
one
we're
talking
about
is
cron
jobs.
Of
course,
conjobs
have
been
in
kubernetes
itself
for
quite
a
while,
so
this
isn't
adding
any
major
functionality.
C
In
fact,
this
is
just
upgrading
in
an
api,
so
we're
taking
a
v1
beta
1
to
a
v1.
We
are
us
promoting
this
to
general
availability,
so
it's
really
encouraging
to
see
features.
I've
been
around
for
a
while
entering
this.
This
period
of
stability,
it's
quite
exciting,
exciting
to
see
someone
using
kubernetes
quite
a
lot
for
pod
destruction.
Budget
eviction,
number
85
things
are
pretty
similar.
This
is
a
feature-
that's
been
around
stable
for
a
while,
and
this
is
moving
the
policy
v1.
C
So
the
pod
destruction
budget,
if
you're
you're
less
familiar,
allows
you
to
specify
a
policy
to
say
if
too
many
of
a
pod
shouldn't
be
taken
down
under
certain
circumstances
or
under
eviction,
so
you
can
evict
a
part
instead
of
deleting
it.
So
again,
it's
really
nice
to
see
this.
This
stabilize
moving
on
demon
set
max
search.
This
one's
coming
in
at
beta.
C
This
it
brings
data
sets,
are
a
policy
a
way
of
deploying
applications
that
allows
you
to
deploy
one
pod
pen
node
as
opposed
to
a
a
deployment
or
replica
set
or
stateful
set.
This
actually
brings
them
with
parity
with
features
from
those
other
deployment
mechanisms
in,
but
it
has
this
this
max
surge
feature.
The
idea
here
is
that
you
can
save
under
certain
circumstances.
C
C
Next,
we
have
a
logarithmic
scale
down
coming
in
at
beta
again.
This
one
affects
replica
sets,
which
is
what
underlies
deployments
in
most
cases,
the
idea
is
that,
when
a
replica
set
scales
down,
it
needs
to
decide
which
pods
to
remove,
and
in
doing
so
typically,
it
has
always
picked
always
picked
the
eldest.
C
So
that's
a
change
that's
coming
in
and
that
can
be
that
can
be
used
using
a
feature
flag
at
the
basic
guide.
Next,
we
have
indexed
job
semantics.
This
is
a
enhancement
to
the
jobs
api.
So
if
you
create
a
job,
it
will
create
in
the
repositories
to
fulfill
that
job.
This
allows
you
or
allows
a
user
to
specify
an
index
for
each
job
that
is
created,
and
this
is
mostly
used
to
solve
embarrassingly
parallel
problems.
C
So
if
you
have
a
problem-
and
you
have
a
thousand
things-
and
each
thing
you
need
to
process
can
be
done
completely
independently,
then
you
could
launch
100,
pods
and
process
10
things
each
or
or
whatever
you
need
to
do,
and
this
this
indexing
mechanism
allows
you,
that's
the
pod
to
know
which
number
it
is.
It
knows
it's
pod
50
and
therefore
you
must
grab
these
from
the
middle.
For
example,
another
video
beta
staying
on
the
topic
of
jobs.
We
have
the
suspend
field.
C
This
has
this
delightful
idea
that
you
can,
while
a
job
is
running,
you
can
suspend
it
using
the
api.
Any
pods
that
are
currently
running
will
be
will
be
stopped
and
then,
at
some
later
date
you
can
come
back
and
resume
it.
This
is
intended
to
give
greater
control
for
things
using
the
jobs
api
in
order
to
in
order
to
manage
how
it
is
executed
again
coming
into
beta
for
deletion
cost.
This
is
a
another
change
to
make
it
more
flexible
in
how
scale
down
for
replica
sets
works.
C
In
particular,
this
allows
a
a
annotation
to
be
used
to
specify
the
cost
in
some
generic
terms
of
deleting
a
pod
as
before,
as
I
said
before,
typically
it
would
delete
the
oldest,
but
that
might
not
be
under
some
circumstances,
the
cheapest
part
to
other
most
correct
pods
to
to
move.
So
this
allows
application
users
to
give
some
hints
to
the
kubernetes
control
plane
about
which
pods
it
would
prefer
to
keep
if
it
has
to
be
scaled
down.
C
This
again
coming
out
of
beta
joe
trucker
got
lingering
pods,
so
this
is
coming
in
alpha,
so
this
again
is
behind
it
alpha
feature
gate.
This
solves
a
limitation
with
how
again
jobs
are
run
in
the
current
versions
of
kubernetes,
where,
in
order
for
a
job
to
be
marked
as
complete,
all
of
the
containers
which
comprise
a
job
must
finish
and
must
stick
around,
and
this
is
at
worst
messy
in
not
particularly
active
clusters.
C
But
if
you
had
a
particularly
long
running
job
that
required
lots
of
executions,
of
containers
and
or
pods,
I
should
say-
and
you
had
a
very
busy
cluster,
which
had
a
large
amount
of
churn
in
pods.
You
might
hit
the
circumstance
where
a
the
earliest
pods
in
the
job
are
removed
and
cleaned
up
from
the
cluster
before
the
last
ones
execute,
in
which
case
the
the
job
will
not
be
able
to
mark
itself
as
completed.
C
C
C
D
D
So
all
the
certificate
rotation
needed
a
client
restart
and
there
were
no
support
for
the
standard
key
management
solutions,
but
but
this
one
with
this
feature
in
it,
in
addition
to
supporting
the
key,
manage
status,
key
management
solution,
it
also
supports
like
token-based
protocols,
and
more
than
that
it
has
made
kubernetes
vendor
neutral.
Recently,
the
azure
and
the
gcp
plugin
has
been
removed.
D
It
also
provides
a
template
or
like
an
interface
for
external
providers
where
they
can
external
art
providers,
authentication
providers,
they
can
just
create
their
own
package
separately
and
that
can
be
easily
integrated
with
kubernetes.
So
this
feature
is
decoupled,
a
lot
of
things
and
it's
a
it's
a
it's.
It's
a
win
for
making
kubernetes
interface
when
neutral.
Moving
on
to
the
next
one.
D
We
have
a
bound
service
account
of
token
values,
so
commands
provisions,
json
web
tokens
for
workloads,
and
this
functionality
is
on
by
default
and
widely
used,
and
the
current
the
previous.
The
system
had
a
lot
of
securities
issues
and
also
scalability
issues
that
it
required
a
kubernetes
secret
per
service
account,
and
that
was
not
a
scalable
option.
Security
issues
like
someone
gets
all
of
the
jwts.
D
So
basically,
this
this
feature
helps
in
providing
a
new
optional
field,
where
you
can
specify
the
number
of
specified
duration
time
to
for
the
certificate
to
be
active
before
that,
I
think
it
was
like
an
ear
and
you
have
to
rotate
it
out
every
year
or
something
like
that.
But
now,
with
this
featuring
beta,
it
actually
provides
a
time-bound
certificate
certificates.
D
C
Here
so
sig
cli,
as
the
name
implies
cli
stands
for
command
line.
Interface
deals
with
all
of
the
command
line,
tools
which
power
kubernetes,
which
help
you
use.
Cube
definitions,
principally
cube
ctl,
but
also
other
tools
as
well.
So
the
one
we
want
to
talk
about
here
is
qcdl
commands
in
headers.
So
this
is
a
enhancement
to
cube
ctl.
C
This
is
designed
to
help
cluster
administrators
understand
how
vectors
are
being
used,
because
this
information
is
collateable
and
exposable
from
from
the
kubernetes
metrics
and
logs
and
other
things
like
this,
so
they
can
start
to
help
with
debugging
and
they
can
help
with
understanding
usage
patterns.
That's
a
really
interesting
one.
Does
he
come
in
and
again
that's
that's.
Coming
in
in
beta
handing
back
over
to
savita
for
provider.
D
So
the
sig
cloud
provider
next
slide,
please
so
this
sick
cloud
provider
plugin,
has
always
been
an
entry
and
we
are
actively
working
on
moving
it
out
of
the
tree.
The
entry
means
that
it's
part
of
the
core
community's
code
base,
which
is
in
kk
and
when
it
moves
out
of
free,
it
can
live
in
the
kubernetes
ecosystem
or
it
can
actually
live
as
an
external
package
and
see
cloud
power
has
been
working
on
it
and
this
feature
actually
helps
in
migrating.
D
The
workloads
from
the
older
feature
to
the
new
external
out
of
three
equivalents
without
having
a
downtime.
If
your
system
needs
to
be
head
shave,
your
system
needs
like
if
your
cluster
cannot
afford
any
downtime
at
all.
So
this
feature
can
be
used,
but
they
do
recommend
that
if
okay,
they
do
say
that
you
kind
of
like
they
recommend
that
the
entry
cloud
providers
be
disabled
and
then
deploy
their
respective
or
a
free
cloud
controller
manager.
When
you
bring
this
on.
D
C
Thank
you
so
sid
close
the
lifecycle,
as
the
name
implies
again
things
about
clusters
and
how
to
manage
them
and
how
to
administrate
them
going
forward
across
the
entire
life
cycle
of
a
single
coaster,
as
their
name
implies.
Their
big
change.
This
time
is
the
one
we
spoke
about
during
the
major
themes
is
ability
to
run
the
control
plane
as
a
non-root
user
to
increase
security.
C
D
So
the
next
one
up
is
api
server
tracing
and
before
in
order
to
support
the
large
communities
cluster
without
having
to
create
a
lot
of
ncd
and
crips
for
because
to
keep
server.
Api
contains
a
cache
in
memory
cache
basically,
and
that's
a
wash
watch
catchy
that
has
all
the
requests,
and
if
some,
if
there
is
an
inability
to
re-establish
the
watch,
what
happens
the
cube
api
server
restarts
and
that
causes
like
a
couple
of
issues?
I
there
would
not
be
no.
D
There
will
be
like
empty
change
history
and
there
were.
The
resource
version
would
be
like
out
of
the
history
window
in
order
to
avoid
all
those
things.
This
new
feature,
which
is
an
alpha
feature
that
aims
at
avoiding
these
major
two
pitfalls
and
make
sure
that
there
is
a
api
tracing
available
even
with
the
keyway
based
on
restarting
moving
on
to
the
next
one
network,
with
james.
C
Sure
so
sig
network
deals
with
everything
from
a
service
implementation
to
dns,
to
cni,
plugins
and
and
really
covers
a
wide
gamut
of
what
kubernetes
is
feature
set
does
so
one
of
the
big
ones
we've
seen
is
endpoint
slices.
This,
I
believe,
entered
either
stapler
beta,
but
last
time
in
121,
so
seeing
this
come
and
increase
approach.
Stability
is
really
interesting
and
and
really
cool.
So
this
is
order.
C
C
And
of
information,
but
this
allows
you
to
talk
a
little
bit
more
about
the
pro
that
is,
that
is
used
on
a
more
granular
level
again
seeing
this
go
stable
is
really
interesting:
service,
disabling
web,
balancing,
no
ports.
This
allows
you
to.
If
you
create
a
normally,
if
you
create
a
cumulative
service,
it
can
be
cluster
ip
or
it
can
be
node
port
or
it
can
be
a
load
balancer,
and
if
you
create
a
load
balancer,
you
still
get
a
node
port
assigned.
C
C
At
beta
next
is
the
load
balancer
class,
so
this
is
a
lighter
weight
approach
of
dealing
with
load
balancers
in
kubernetes.
So
I
believe
this
yeah,
so
this
this.
This
is
very
similar
to
an
api
elsewhere
that
has
like
a
a
gateway
class
resource,
and
things
like
this
so
again
seeing
this
coming
up
beta
in
part
of
sig
network's
ongoing,
ongoing
work
in
this
area.
C
So
this
again
addresses
certain
topologies
that
you
might
see
in
in
networking
and
allows
to
do
things
like
a
node,
local
and
other
topology
aware
things.
So
this
is
again
to
make
traffic
policy
more
powerful
as
a
feature
set
in
in
kubernetes
and
to
address
a
few
more
use
cases,
namescaped
scoped,
ingress
class
parameters.
C
C
This
again
is
just
a
very
simple
improvement.
It's
only
at
alpha.
So
again,
you
will
need
a
feature
gate
in
order
to
properly
understand
in
order
to
properly
activate
this
feature.
But
this
is
again
a
big
big
thing
that
cig
network
is
working
on
and
it's
really
exciting
to
see
them
bring
so
much
change
to
the
table.
In
this
case
and
then
finally,
from
sig
network,
we
have
extended
dns
configuration,
so
this
allows
just
more
fine-grained
dns
control,
so
this
allows
configuring
resolvers
with
more
detail.
D
So
this
is
like
this
feature
is
about
configuring.
Fully
qualified
domain
name
has
hostname
for
parts,
so
people
have
used
servers
before
communities
like
red
hat
or
sentence.
I
predominantly
used
centos
and
rail
for
a
while
when
I
was
doing
a
platform
administrator
and
then
it
actually
takes
the
host
name
as
fqn,
and
this
feature
actually
enables
portability
between
the
older
application
legacy.
D
Sorry
fqdn,
I'm
like
what
am
I
saying
I
was
like
just
interchanging
things
in
my
mind,
so
it's
fully
qualified
of
my
name
to
try
to
stick
to
that.
So
the
part
supports
it
now
and
it's
a
stable.
It's
a
stable
feature
right
now.
Moving
on
to
the
next
one
is
about
sizeable
memory.
Bagged
volumes
so
kubernetes
supports
empty
their
volumes,
whose
backup
storage
is
basically
memory,
and
that
is
like
50
of
the
memory
on
the
linux
host.
D
Moving
on
to
the
next
one
is
ephemeral
container,
so
everyone
who
has
been
working
on
with
applications
using
communities
would
have
come
across
a
point
where
you
wanted
to
debug
and
the
one
way
to
do
is
like
keep
curl
as
exit,
and
then
you
get
in
the
pod
and
you
run
as
a
process
within
the
part.
But
this
feature
is
in
beta
and
it
lets
you
create
an
ephemeral
container
that
attaches
to
depart,
and
you
can
do
all
the
troubleshooting
and
debugging
within
the
container.
D
Moving
on
to
the
next
one
liveliness
pro
grace
seconds
so
before
this
feature
existed,
the
liveliest
props
used
a
termination
grace
period
chickens
for
the
normal
shutdown
and
whenever
the
prop
failed
failed.
So
if
the
combination
period
that
was
said
was
long
and
then
the
liveliness
prop
failed,
the
workload
was
not
start
restarted
because
it
was
actually
waiting
on
the
full
termination
period.
D
In
some
cases,
this
to
start
the
actual
like
this
cause
like
delay
in
things-
and
this
was
not
like
there
were
like
different
use
cases
which
can
be
seen
in
the
cap-
a
link
mentioned
in
the
slide
use
stories.
So
this
feature
actually
supports
setting
an
optional,
prob
or
termination
grace
period
seconds.
D
When
said,
it
actually
ignores
the
readiness
probes
and
then
the
part
can
be
terminated
without
having
to
go
through
the
full
wait
time.
This
feature
is
in
beta
right
now
and
if
you
are
interested
in
more
details,
please
click
on
the
links
in
the
slide,
which
should
be
available
later
moving
on
to
the
rootless,
mod
containers.
D
D
This
is
a
really
important
security
feature
available
right
now
and
take
advantage
of
it.
If
you
like
to
keep
your
cluster
secure.
Moving
on
to
the
next
one,
so
c
groups,
v2
kubernetes,
initially
was
implemented
with
the
c
groups,
v1
version,
and
recently
the
c
group's
v2
in
the
corner
went
stable
a
couple
years
ago.
D
I
think,
and
since
then
most
of
the
distros
have
started
supporting
secrets
v2
as
default,
thus
providing
kubernetes,
which
is
using
secrets
v1
working
in
the
intended
way.
So
this
basically
adding
the
support
to
supporting
the
kubernetes
platform
to
support
c
groups
v2,
which
is
already
supported
in
the
kernel
it's
in
alpha
state,
and
if
you
want
to
use
it,
please
take
advantage
of
enabling
the
feature
gate
and
the
next
one
is
the
memory
qos
with
the
cgroup
32.
D
We
discussed
a
little
bit
about
it
in
the
major
themes,
so
this
is
nothing
but
it
adds
additional
support.
Memory
qs,
with
taking
advantage
of
the
c
groups
v2
moving
on
to
the
next
one
node
system
swap
support.
We
talked
a
bit
about
it
already,
it's
mainly
for
a
certain
type
of
applications,
and
it
also
can
take
advantage
of
the
linux
system
swap
which,
when
this,
this
feature
is
now
for,
when
enabled
and
at
the
containers,
the
parts
can
take
advantage
of
this
too.
D
C
Oh
yeah,
so
with
sig
scheduling,
we
have
a
confusion
to
talk
about.
The
first
enhancement
is
schedule,
a
component
config
api.
This
allows
cluster
administrators
to
more
fluently,
express
the
configuration
for
various
scheduler
components,
so
this
is
a
beta
iteration
and
some
plug-in
additional
plug-in
additional
plug-in
functional
functionality.
C
So
again,
it's
gonna
be
interesting
to
see
if
it's
in
beta
and
it's
gonna
be
interesting
to
see
where
we
go
with
this
this
feature.
Next,
we
have
prefer
nominated
node.
This
can
speed
up
scheduling
an
eviction
if
you're
sketching
a
lot
of
pods
at
the
same
time,
principally
by
allowing
pods
to
nominate
a
node
that
they
particularly
prefer,
and
then
the
scheduler
will
try
its
its
best
to
get
you
there,
but
no
guarantees.
Of
course.
C
Next
we
have
namespace
selector
for
pod
affinity,
so
this
allows
for
anti-affinity
to
work
without
knowing
the
namespace's
name
ahead
of
time.
So
this
allows
you
to
use
labels
or
point
specific
levels
on
namespaces
in
order
to
select
them
for
infinity
and
anti-infinity
and
then,
finally,
from
the
sig,
we
have
the
single
scoring
plugin
for
node
resources.
C
D
So,
first
up
with
six
storage
is
the
csi
service
account
token.
So
this
features
table
right
now
and
it
provides
a
service
token
for
the
parts
that
the
csi
drivers
are
mounting.
The
volumes
for
and
the
tokens
are
actually
valid
only
for
like
a
limited
period
of
time,
and
this
feature
also
enables
the
csi
drivers.
This
feature
actually
provides
an
option
to
the
csa
drivers
to
re-execute
the
no
publish
volume
to
mount
the
volumes
back
again.
D
D
Moving
on
to
the
next
one
is
delegating
fs
group
to
csi
driver
instead
of
cubelet,
so
currently
for
most
of
the
volume
plugins
cuboid
applies
in
a
first
group
of
ownership
and
which
means
that
permission
based
changes
that
it's
gonna
recursively
change,
ownership
and
change
the
mode
of
the
files
and
directory
inside
the
volume-
and
this
is
not
applicable
for
all
the
csi
drivers.
For
example.
D
Moving
on
to
rbo
pod
access
mode
read
only
rewrite
only
part
access
mode,
so
this
is
a
new
mode.
In
addition
to
the
existing
read
write
once
more,
which
actually
says
the
single
node
can
mount
the
volume,
but
any
like
the
volume
is
just
attached
to
the
single
one
particular
node,
but
all
the
parts
in
the
node
have
access
to
that.
C
Hi,
so
with
sig
windows.
First
of
all,
we
have
csi
plugins
for
windows,
so
csi
is
container
storage
interface.
These
plugins
are
going
stable
in
122..
So
again,
this
is
part
of
the
thing
we
were
talking
about
about
windows,
support,
gaining
a
lot
of
parity
with
linux,
supporting
kubernetes
so
really
exciting.
To
see
this
stabilize
next,
we
in
alpha
we
and
our
final
enhancement
that
we're
talking
about
today
is
windows.
C
Privilege
containers,
so
this
has
is
the
idea
that
you
can
launch
a
privileged
container
on
on
windows,
which
previously
you
were
unable
to
do
typically
for
configuring,
networking
or
storage
or
some
other
thing
that
requires
privileged
access,
and
this
is
coming
in
alpha
and
with
that.
I
think
we
are
done
talking
about
every
just
about
every
enhancement
in
incoming
122..
I'd
like
to
pass
back
over
to
savita
to
talk
about
the
release
team
shadow
program.
D
D
Moving
on
to
the
release
team
shut
up
program,
we
wanted
to
talk
about
like
what
is
to
be
a
part
of
the
release,
team
and
they're
like
oh,
what
is
the
release
team
and
what
do
we
do
there
and
how
to
apply
or
how
to
be
a
part
of
it?
Basically,
the
release
team
is
there
to
facilitate
all
the
enhancements.
The
feature,
duplication
that
goes
in
the
release.
D
D
They
keep
a
track
on
the
critical
box
that
got
open
again
to
release
and
help
coordinating
with
coordinating
with
the
contributors
and
the
seeks
so
that
they
can
be
closed
and
making
the
release
more
stable
and
reliable
documentation
team
helps
with
coordinating
between
the
enhancement
owners
and
if
their
future
needs
new
locks
or
like
updating
the
existing
dogs.
They
help
with
the
coordination
then
comes
the
release,
notes
team.
D
They
help
in
automated
generation
of
the
release,
notes
the
features
what's
going
on
in
the
release,
just
another
feature,
bug
fixes
or
anything,
and
everything
that
goes
in
the
release.
Basically,
that
means
release
notes.
They
keep
track
of
it
and
help
coordinate.
It
then
comes
the
communications
communications
responsible
for
a
lot
of
things,
starting
with
coordinating
the
release
within
the
communist
community,
with
cncf
setting
up
the
sub
this
webinar
and
making
keeping
a
track
of
all
the
feature
blog.
D
D
You
are
a
beginner
or
you
already
participate
in
a
thing,
but
you
want
to
expand
your
knowledge,
it's
again
a
great
opportunity
and
if
you
are
like
a
really
advanced
contributor-
and
you
want
to
act
as
a
liaison
between
the
sig,
your
sig
and
the
release
team,
there
are
opportunities
for
that
as
well.
So
you
can
ensure
that
whatever
the
feature
your
sig
is
working
on
gets
like
you
can
you
can
be
the
person
who
can
help
the
release
team
understand
what's
going
on
and
also
like
who
can
help?
D
The
sikh
understand
like?
Oh,
these
are
the
red
lines
and
we
need
to
get
things
done
by
this
time,
so
it
could
be
that
so
the
shadow
program
is
for
everyone
who
wants
to
learn
and
develop
their
knowledge
around
the
ecosystem
or
get
started
or
even
to
try
something
out.
New
one
thing
to
keep
in
mind
is
that
it
has
gotten
very
competitive
over
the
years.
So
don't
be
disheartened.
C
D
So
it's
getting
very
competitive,
but
that
is
not
the
only
way
to
help
out.
So,
if
you
are
interested
in
helping
out,
there
are
like
a
lot
of
ways
come,
say:
hi
and
reach
out
to
folks
start
contributing
the
new
year
like
good.
First
issues
and
work
on
area
improve
your
skills
reapply
and
you
can
learn
more
about
the
release
team.
The
links
are
mentioned
in
the
slide.
There
are
like
various
the
roles
we
talked
about.
D
We
there
is
an
old
handbook,
so
you
can
go
and
take
a
look
at
it
and
let
us
know
if
you
have
any
questions
about
that
and
we
are
super
sorry
that
we
are
way
over
time
and
apologies
for
the
inconvenience
and
thank
you
for
staying
with
us.
Thank
you
james.
You
see
libby
and
all
the
audience
who
are
here
with
us.
Listening
to
our
session,
please
please
feel
free
to
ping
us
in
the
slack.
A
You
so
much
what
a
great
presentation
and
thank
you
for
your
time
and
everyone
else
as
well,
and
here
is
the
slack
channel
once
again
all
right.
Well
with
that,
we
will
let
everyone
go
and
follow
up
on
the
slack
channel,
and
all
of
this
will
be
online
in
just
about
an
hour
or
so
so
you
can
re-watch
and
get
all
your
questions
answered.