►
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
Hello,
everyone
welcome
to
cloud
native
live
where
we
dive
into
the
code
behind
cloud
native.
I
am
annie
talvasta
and
I'm
a
cncf
ambassador
as
well
as
a
senior
product
marketing
manager
at
camunda,
and
I
will
be
your
host
tonight.
So
every
week
we
bring
a
new
set
of
centers
to
showcase
how
to
work
with
cloud
native
technologies.
A
So
this
week
we
have
stevie
and
andy
here
with
us
to
talk
about
implementing
kubernetes,
cartilage
and
determination
with
polaris
and
as
always,
this
is
an
official
live
stream
of
the
cnc
app
and
as
such,
it
is
subject
to
the
cncf
code
of
conduct.
Please
do
not
add
anything
to
the
chat
or
questions
that
will
be
in
violation
of
that
code
of
conduct.
So
basically,
please
be
respectful
of
all
of
your
fellow
participants
as
well
as
presenters
so
I'll
hand
it
over
to
stevie
and
andy
to
kick
off
today's
presentation.
B
Cool,
thank
you.
Manny,
hello,
everyone.
Let's
start
off
by
doing
a
quick
intro
of
who
we
are
and
then
I'll
talk
about
what
exactly
we're
gonna
cover
today
yeah.
So
my
name
is
stevie.
I
am
an
sre
tech
lead
at
fairwinds.
I've
been
working
with
kubernetes
for
a
few
years
and
then
before
that
doing
all
things
you
know,
cis
admin
and
network
engineering
and
stuff,
like
that.
So
I've
been.
A
C
Hi
everybody,
I'm
andy,
I'm
I'd
like
to
say
sometimes
I'm
a
reformed
sysadmin,
I'm
author
and
maintainer
of
a
bunch
of
our
open
source
projects
here
at
fairwinds,
I'm
also
our
cto.
I've
been
doing
doing
kubernetes
for
gosh
seven
and
a
half
eight
years
now
and
I've
been
with
fairwinds
for
four
and
a
half.
So
just
a
huge
fan
of
all
things:
open,
source,
cool.
B
B
C
B
C
Let's
just
dive
straight
into
the
demo,
because
I
think
we
have
a
lot
to
cover
today.
So
the
first
thing
I'm
going
to
do
is
I'm
going
to
get
a
kubernetes
cluster
going,
I'm
using
kind,
that's
kubernetes
and
docker,
and
we
already
have
a
problem
all
right.
I
thought
I
killed
this
test
cluster
earlier,
but
we
can.
C
Copy
pasting
commands
that
was
my
problem.
I
should
have
just
typed
the
whole
shot
out
right
all
right,
so
we're
gonna
we're
gonna
install
a
couple
of
things.
First
thing
I'm
going
to
install
is
cert
manager
as
soon
as
this
control
plane
comes
up.
So
I'm
just
going
to
install
that
straight
out
of
the
jet
stack
repo
using
home,
I'm
going
to
tell
it
to
install
the
cert
manager
crds.
C
Great
question,
so
we
are
going
to
use
polaris
as
both
a
mutating
and
a
validating
admission
web
hook,
and
so
we
need
certificates
to
put
in
the
objects
that
configure
those
web
hooks
and
so
we're
going
to
let
cert
manager
manage
those
for
us.
It's
a
very
convenient
way
to
do
it
rather
than
you
know,
generating
self-signed
certs
on
the
fly
or
anything
like
that.
We're
gonna,
let
cert
manager
just
manage
those
for
us
and
it'll
actually
go
update.
The
the
web
hook
configurations
with
those
certs.
A
Ready
sorry
for
this
question
already,
I
think
it's
been
more
for
general.
One
though,
and
you're
probably
gonna
give
some
resources
towards
the
end
as
well,
but
there
was
a
question
about
what
are
the
best
resources
to
learn
about
the
cloud,
but
another
listener
already
just
gave
the
suggestion
for
communities
that
I
o
was
a
great
starting
point
as
well.
C
Yeah
great
answer:
it's
a
very
large
topic,
the
cloud,
so
I
don't
know
if
I
can
give
specific
good
resources,
but
careers.I
o
is
a
great
resource
as
well,
as
I'm
sure
many
many
pages
from
the
cncf,
so
cool.
So
let's
see
we
already
installed
cert
manager
and
then
the
other
thing
I'm
going
to
do
is
I'm
going
to
create
a
temporary
directory
and
I'm
going
to
use
the
helm
template
command
to
grab
some
some
yellow
manifests.
C
So
if
we
look
here,
I
just
did
a
helm
template
to
pull
down
a
chart
that
we
have
for
running
a
basic
demo
in
kubernetes.
It's
got
a
deployment,
a
horizontal
pod,
auto
scaler,
a
pdb
and
a
service,
so
very
simple
setup
here
of
something
that
we
might
deploy
into
our
cluster
and
so
I'll
have
that
available
for
later
in
the
demo
to
tinker
with
that
code.
C
B
C
Yeah
definitely
so,
as
I
mentioned
before,
we're
installing
both
the
validating
emission
web
hook
and
the
mutating
admission
web
hook
for
polaris
in
order
to
show
off
some
of
the
functionality
later
on,
and
those
are
the
flags
that
will
enable
that
for
us
right.
So,
if
we
look,
we
should
have
a
validating
web
hook
configuration
and
a
mutating
webhook
configuration
for
polaris
in
this
cluster.
Now.
B
And
just
a
level
set
for
folks,
like
the
the
difference
in
terms
of
these
web
hooks,
is
that
the
validating
web
hook
simply
will
deny
or
will
deny
a
an
object
being
sent
to
the
cluster
or
at
least
print
out
like
a
warning
to
the
logs
or
something
depending
on
some
things
which
we'll
talk
about
a
little
later
and
then
the
mutating
web
hook
will
actually
change
the
aspect
of
your
resource.
That
is
opposite.
The
the
configuration
that
you
have
in
your
web
hook,
yeah.
C
Exactly
great
explanation,
so
what
we'll
do
first
is
we're
going
to
apply
those
manifests
that
I
was
talking
about
earlier,
so
we're
just
going
to
apply
those
to
the
default
namespace
and
right
off
the
bat
we're
going
to
see.
Polaris
is
already
at
work
here,
so
I'll
full
screen
this
little
section
here,
but
polaris
prevented
this
deployment
because
the
image
tag
should
be
specified.
C
So
it's
blocking
my
polaris
demo
deployment
release
blah
blah
blah
because
we
haven't
specified
an
image
tag.
So
if
we
go
take
a
look
at
that
deployment
manifest-
and
we
go
down
here
to
where
the
image
is
defined,
it
says
we're
using
the
latest
the
latest
tag,
which
is
generally
not
something
we
want
to
do,
and
so
I'm
going
to
change
that
to.
A
C
Great
question-
and
I
will
talk
about
that
a
little
bit
in
a
bit,
but
the
big
difference
is
the
the
language
that
we're
writing
the
checks
in
and
how
we're?
Oh,
just
the
language
that
we're
using
to
write
those
checks.
So
open
policy
agent
uses
rego
we're
actually
going
to
use
json
schema
here,
but
otherwise
they're
fairly
similar
in
how
they
function.
C
B
Yeah
so
as
you
like,
as
you
said,
this
immediately
flagged
some
things
in
your
cluster,
so
I'm
assuming
you
know,
polaris
comes
with
some
defaults
that
automatically
take
place.
When
you
get
started,
can
we
sort
of
investigate
a
little
bit
what
those
defaults
are
and
why
it
flat
like
where
it
got
the
information
to
flag
that
deployment
from.
C
Most
definitely
so
I'm
in
the
background,
while
you
were
asking,
I
set
up
a
port
forward
to
the
polaris
dashboard,
that's
going
to.
Let
us
show
what
checks
we're
running
and
get
a
nicer
view
of
what
we
just
saw.
So
what
we
just
saw
obviously
was
the
admission
controller,
but
at
the
same
time
the
dashboard
is
running
these
checks
and
giving
you
the
ability
to
see
you
know
existing
issues
or
non-blocking
issues.
C
C
B
C
C
C
B
C
C
By
default,
polaris
will
check
any
pod
controller
because
it
looks
up
the
pod
and
then
walks
up
the
owner
references
in
order
to
find
the
top
level
controller.
The
admission
controller
by
default
is
set
up
to
watch
specific
resources.
So
if
we
go
to
the
values
file
for
polaris,
when
we
go
down
to
the
web
hook
section
and
we
see
the
default
rules,
these
are
the
default
rules
for
the
both
admission
controllers
for
both
the
mutating
and
the
validating
admission
web
configurations.
C
So
we're
looking
for
daemon
sets
deployments
and
stateful
sets
any
creator
update,
operation
and
then
also
actually
jobs
and
cron
jobs
and
pods
and
replication
controllers.
So
if
you
want,
you
know
to
watch
for
just
pod
creation
and
block
that
which
actually,
I
think,
is
what's
happening
in
our
cluster
right
now
so
yeah
and
you
can
add
any
you
want
to
this
configuration
here.
B
C
C
Yes,
there's
a
lot
of
config,
I
dug
through
a
lot
of
config
while
building
this
demo,
because
there's
a
lot
of
options
there.
So
the
other
thing
to
note
is
if
you're
curious
about
default
checks
and
what's
built
in
you,
can
also
go
to
the
checks
folder
in
the
polaris
repo
and
see
all
the
different
files
that
define
the
checks.
C
So
if
we
want
to
take
a
look
at
that
tag,
not
specified
that
we
just
got
blocked
on
here,
you're
going
to
see
a
yaml
version
of
json
schema,
which
I
realize
is
a
little
bit
weird-
you
can
also
specify
it
in
inline
json
strings.
If
you
want
so
you
can
replace
this
schema,
I
think
schema
with
schema
string.
This
is
in
the
documentation,
but
basically
we're
saying:
okay,
we're
looking
at
the
container
spec,
so
polaris
will
automatically
pull
just
the
containers
spec
out
of
your
entire
spec.
C
So
if
you're,
creating
a
deployment,
it'll
just
grab
the
different
containers
and
run
the
schema
against
that.
So
you
don't
have
to
write
your
whole
nested
json
schema
in
order
to
get
down
to
a
field
in
the
container,
and
so
we're
going
to
say
that
the
image
the
the
image
field
inside
the
container
spec
has
to
match
this
pattern,
which
is
just
any
string
colon
any
other
string,
and
then
it
cannot
match
the
pattern,
any
string,
colon
latest,
and
so
obviously
you
could
expand
on
this
and
say
you
know
it
has
to
match.
C
C
B
C
C
So
what
I'm
going
to
do
is
first
in
order
to
ease
our
lives
a
little
bit
here,
I'm
going
to
change
the
failure
policy
of
both
web
hooks
to
be
ignore
that
way,
while
pods
are
restarting
and
the
things
are
failing,
we're
not
going
to
accidentally
block
our
polaris
deployment
and
then
I'm
going
to
start
filling
out.
This
config
block.
B
And
I'm
just
going
to
say:
that's
a
good.
That's
a
good
basic
pattern
to
follow
whenever
you're
working
with
web
hooks
and
the
mission
controller
in
general
is
to
start
off
not
actively
not
in
an
active
mode,
not
like
blocking
things
you
want
to.
You
want
to
run
it
sort
of
in
a
test
mode
by
having
it
do
ignore.
C
A
C
Is
that
we've
specified
in
our
configuration
to
say
block
this,
it
will
still
go
ahead
and
block
it,
and
so
what
we'll
actually
do
here
is
go
if
we're
testing,
we
can
put
all
of
these
different
checks
into
warning
mode
and
that
will
prevent
actual
blocking
by
the
by
the
the
web
hook
itself,
and
so
we
can
go
ahead
and
do
that.
If
we
want
to
do
this
in
test
mode
and
then
you
know,
we
can
also
just
turn
these
ignore.
C
But
it's
nice
to
see
it
all
in
the
dashboard
and
the
other
thing
we're
going
to
do
here
that
I
haven't
talked
about
yet
is
mutations.
So
we
do
have
the
ability
to
to
mutate
objects.
If
you
want
to
automatically
enforce
a
policy
in
a
specific
way,
we
can
just
go
ahead
and
do
that
at
admission
time,
rather
than
blocking
the
deployment
we
have.
One
of
these
turned
on
by
default
in
the
default
configuration
and
it's
the
pull
policy,
not
always
mutation.
C
If
we
go
back
to
our
our
policies,
our
checks
in
polaris-
and
we
take
a
look
at
the
poll
policy
policy.
Not
always
we
have
a
new
section
in
the
the
check
configuration
here
called
mutations,
so
we're
gonna.
Do
the
operation
to
add
the
path,
image,
pull
policy
and
we're
gonna
set
it
to
always
and
that's
again
on
the
container
target.
We
have
other
targets
available,
and
so
this
will
say,
like
you
know,
okay,
this
is
our
normal
policy.
We
say
that
we
should
always
use
the
always
pull
policy.
C
That
was
a
confusing
sentence,
but
in
the
case
that
we're
using
the
emission
controller,
the
mutating
and
mission
controller
we'll
just
go
ahead
and
do
that,
because
this
should
be
safe
to
do
in
most
cases
in
most
of
your
average
clusters
right.
So
we're
just
going
to
go
ahead
and
do
that
and
you
could
do
this
for
all
sorts
of
things.
B
C
This
particular
check
does.
I
believe
it
is
the
only
check
currently
that
we
felt
was
okay
to
go
ahead
and
add
that
to
the
defaults,
all
right,
so
most
checks
will
not
have
a
mutations
section
by
default.
We
are
definitely
open
to
ideas
on
mutations
that
are
valid
all
of
the
time,
but
it's
a
very
risky
thing
to
enable
by
default.
So
we're
trying
to
be
cognizant
of
that
all
right.
B
C
Let's
talk
about
custom
checks
because
I
think
that's
honestly
where
things
get
super
interesting.
So
in
our
documentation
we
have
lots
of
examples
and
documentation
of
how
you
write,
custom
checks
and
how
they
get
added
into
your
configuration,
because
this
can
be
a
little
bit
tricky.
You
have
to
both
specify
the
custom
check
and
then
in
the
check
section
you
have
to
define
how
to
handle
that
check.
You
have
to
say
you
know,
warning
or
danger
level
like
we
saw
earlier.
C
C
So
in
my
config
I'm
going
to
add
a
section
called
custom
checks
and
I'm
going
to
put
that
in
here
and
I'm
going
to
invent
it
correctly,
and
so
we
have
an
image
registry
check.
That
says
that
images
should
be
from
allowed
registries
and
I've
written
json
schema
to
say
it
has
to
be
any
of
these,
and
so
we
have
a
series
of
regex
patterns.
So
I'm
saying
usdocker.package.dev
docker
dot,
io,
slash
kindest,
because
we
have
some
control
plane
stuff
coming
from
the
kind
docker
registry.
C
Obviously
we
need
case.gcr.io,
because
all
the
stuff
for
kubernetes
is
going
to
come
from
there
and
then
we
have
our
quay
repo
and
then
the
jet
stack
one
for
cert
manager
as
well.
So
all
of
our
images
in
this
cluster
should
be
coming
from
this
particular
list
of
repo
of
registries
and
again
we're
checking
that
container
target.
C
And
so
then
I
have
to
go.
Add
the
image
registry
to
my
list
of
checks
and
what
I
like
to
do
is
add
a
section
here
called
custom
and
then
image
registry
and
I'm
going
to
say
danger
here,
because
I
wanted
to
get
blocked
by
the
admission
controller
and
I've
written
this
in
such
a
way
that
that
should
be
safe.
C
It'll
show
up
on
the
dashboard
now,
so
we
can
rush
our
dashboard
and
go
see
if
any
of
these
things
are
failing,
that
image
checks,
that
image
checks
that
sorry
image
registries
check,
I
got
stuck
in
a
loop
there
and
I
realized
I
forgot
to
talk
about
one
interesting
thing.
So
we
have
this
category
here
called
security.
We
have
our
built-in
category
security,
efficiency
and
reliability.
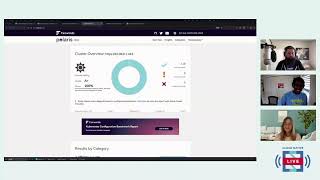
C
What
I'm
actually
going
to
do
is
change
that
category
to
fairwinds
custom,
and
what
that
will
do
is
it
will
put
that
in
this
results
by
category
here
as
its
own
new
category
in
the
dashboard.
So
now
I
can
see
how
many
of
my
custom
checks
are
failing.
This
will
allow
me
to
see
okay.
This
cluster
is
currently
passing
all
of
these
custom
checks.
B
C
All
right,
let's
go,
take
a
look
at
our
dashboard
again
and
now
we'll
see
this
fairwinds
custom
policy
and
this
fairways
custom
category
and
we'll
see
everything's
passing.
We
have
no
failing
checks
in
this
category.
So
now
I
feel
comfortable
going
in
and
saying:
okay,
let's
just
let's
just
turn
on
the
admission
controller.
For
that
and
now
we
won't
ever
be
failing
that,
because
all
requests
will
get
blocked.
C
My
config
here
and
I
change
the
level
of
that
check
to
danger
and
I
rerun
my
home
command
and
I
look
at
my
deployment
here
and
I
go
to
where
it
says
quay
I'm
going
to
change,
crayon,
io
fairwinds
to
create.o,
fargo
barbel,
and
obviously
that
was
not
in
our
list
of
allowed
registries.
It
also
doesn't
exist,
but
that's
not
important
right
now.
C
B
Cool,
so
that's
prob,
so
that's
that's,
probably
a
more
reliable
sort
of
process
for
setting
up
your
your
checks,
like
you,
create
your
checks,
set
it
in
warning.
Wait.
You
know
work
on
it
work
on
the
reported
items
until
it
turns
green
and
then
set
it
to
danger
so
that
it
will
actually
block
things
and
keep
your
cluster
clean
right
got
it
cool.
C
At
the
same
time,
I
kind
of
doubled
down
on
this
little
piece
of
the
demo.
Here
we
can
see
our
our
mutating
web
hook
it
at
in
play
here.
So
I
have
the
image
pull
policy
set,
if
not
present.
Here
I'm
going
to
get
the
deployment
and
look
for
image
poll
here
and
we'll
see
that
the
image
pull
policy
that's
actually
in
the
cluster
is
always
that's,
because
our
mutating
admission
web
hook
picked
that
up
and
automatically
just
kicked
that
over.
C
To
always,
it
also
won't
show
up
in
the
dashboard
anymore,
but
also
you
can
see
that,
if
you're
using
infrastructure
as
code
methods
now
we're
out
of
sync
with
our
infrastructure
as
code,
and
so
that's
the
type
of
thing
that
where
we
have
to
be
really
careful
with
mutating
admission
web
hooks
and
why
we
want
to
be.
You
know
relatively
conservative,
about
where
we
use
those
and
careful
about
how
we
use
those
so.
C
B
C
It
should
allow
me
to
apply
this
yaml.
That
says,
if
not
present,
because
it
mutates
it
and
then
it
hits
it
got
it
all
right.
So,
let's
talk
about
other
policies
that
so
we've
talked
about.
You
know
controlling
your
image
registries.
We've
talked
about
kind
of
a
strategy
for
rolling
those
policies
out
in
your
cluster.
C
B
So
I
mean,
I
feel
like
a
thing
that
we
hear
about.
A
lot
is
resource
limits?
Well,
so
not
allowing
a
workload
to
sort
of
consume
all
the
resources
on
on
a
node
so
like
setting
limits,
like
maybe
namespace
limits
at
the
res
at
the
sorry,
nayspace
resource
limits
or
just
setting
the
resource
limits
on
on
individual
workloads.
So
saying
that
you
can't
go
above
a
certain
amount,
because
you
know
what
kind
of
nodes
you're
running
in
your
cluster.
C
C
C
We're
excluding
init
containers
from
this,
so
we
also
have
an
extension
that
allows
you
to
say
only
check
the
the
main
containers,
not
the
innate
containers,
very
common
to
have
an
init
container
that
just
you
know
you
don't
worry
too
much
about
its
resource
requests
and
limits.
We're
gonna
set
our
maximum.
C
C
Amount
of
resources
in
this
cluster
here
all
right,
so
we're
gonna,
and
then
we
have
to
go.
Add
this
to
our
list
of
custom
checks
and
resource
limits.
I'm
just
gonna
go
ahead
and
set
that
straight
to
danger,
and
then
I'm
gonna
go
ahead
and
change
that
category
again
to
fairwinds
custom
and
we're
going
to
rerun
our
helm,
install.
C
C
All
right.
So
now
we'll
see.
Yep
we've
got
a
couple
of
fairwin's
custom
ones
that
are
failing.
We
can
filter
down
to
our
default
namespace
again
and
see
that
our
fw
custom
deployment
here
resource
limits
should
be
within
the
required
range.
So
that
is
failing
there
and
if
we
apply
our
deployment
again,
we
should
get
rejected
resource
limits
should
be
within
the
required
range.
I
was
thinking
about
this
yesterday.
While
I
was
building
this
and
I
think
another
possibility,
because
json
schema
is
fairly
flexible,
would
be
to
right.
C
B
C
C
So
the
target
has
been
container,
but
the
volumes
the
volume
mounts
in
a
container
are
not
in
our
volume.
Mounts
in
a
pod
are
not
in
the
containers
back
they're
in
the
pod
spec,
and
so
I
want
to
show
how
we
can
add
those.
So
I
have
this
check
here
that
I've
written
for
checking
for
host
path,
mounts
and
again
it's
in
that
category
of
frameworks,
custom,
but
now
we're
going
to
target
the
pod
spec
and
so
inside
the
pod
spec.
C
C
C
Actually,
you
know
implement
rego
in
our
alongside
polaris
inside
of
our
commercial
offering
and
right
like,
I
think
they
both
have
their
place.
I
think,
if
you
need
to
write
just
like
a
really
quick
like
I
want
to
check,
if
there's
a
label
on
this
workload,
json
scheme
is
so
much
quicker
and
easier.
If
you
want
to
do
something
really
complex,
json
schema
gets
ugly
in
a
heartbeat.
C
C
C
C
C
C
B
B
B
We
all
have
tons
of
time
to
address
things,
but
you
do
all
that
stuff
and
then
there's
also
the
the
the
ci
component
to
this,
where
you
can
use
it
and
like
your
ci
setup
to
then
even
before
you
send
anything
to
the
cluster,
it
can
fail
like
a
ci
check
and
you
have
to
make
that
change
in
your
in
your
deployment
before
you
even
get
to
the
cluster
part.
So
you
have
like
a
nice,
you
keep
your
cluster
green
by.
C
So
if
we
do
a
polaris
audit-
and
we
take
a
look
at
the
help
for
that-
and
we
do
a
polaris
audit
audit
path
and
I'm
going
to
point
it
at
the
yaml
that
I
have
in
my
repository
here-
we
see-
let's
do
a
different
format
here,
because
nobody
wants
to
read
json
on
the
fly.
We
can
see
all
of
these
checks
available
here
visible
to
us,
and
then
we
can
also
control
the
exit
code.
C
You
can
also
run
the
cli
against
your
cluster.
By
the
way
you
can
just
do
a
polaris
audit
and
that'll
hit
your
whatever
cluster.
You
have
in
your
cube,
config
and
give
you
the
quick
results.
If
you
don't
want
to
run
the
dashboard
and
just
kind
of
see
what's
going
on
so
then
you
talked
about
like
okay,
you
know
get
it
running,
get
it
installed
and
then
clean
up
your
cluster.
But
if
we
think,
if
we
look
at
this
like
that
host
path,
now
that's
great.
C
I
don't
want
developers
deploying
into
the
cluster
with
a
host
path.
Mount
right,
there's,
no
real
reason
that
an
application
should
need
that,
but
that
kind
control
plane
needs
it
right.
My
data
dog
installation
is
going
to
need
it
to
be
able
to
pick
up
container
logs.
My
you
know
whatever
is
going
to
need
some
of
that
stuff,
so
we
have
to
be
able
to
create
exemptions
from
these
rules
and
there's
a
few
different
ways.
We
can
do
that
in
polaris.
C
One
of
them
is
just
with
with
annotations.
So
actually,
if
we
go
look
at
the
docs
again,
I
really
love
our
docs.
I
think
it's
it's
pretty
pretty
good.
We
can
annotate
with
this
polaris
fairwinds.com
exempt
equals
true
or
we
can
exempt
specific
checks
on
a
workload.
So
if
we
want
to
go
that
route,
we
can
just
annotate
things
and
then
someone's
going
to
ask
me.
Well,
if
you
let
people
just
you
know,
exempt
their
workloads.
How
is
this
a
security
thing
right?
How
is
admission
controller
working?
Well,
you
can
disable
that.
C
C
Yeah
config.yml,
we'll
scroll
down
you'll,
actually
see
a
bunch
of
built-in
exemptions
into
the
default
configuration.
You
can
tinker
with
these
and
modify
these
as
much
as
you
want,
and
so
you
can
specify
specific
controllers.
You
can
specify
specific
controllers
in
specific
name
spaces
and
then
what
rules
they're
exempt
to
and
then
you
can
so
then
you
can
also
go
and
exempt
them
from
your
custom
checks
in
this
exemption
file.
C
C
C
Maybe
do
I
not
have
the
right
file
here?
Oh,
I
don't
sorry
there
we
go
polaris
values.
If
we
go
to
exemptions,
we
now
have
all
the
exemptions
necessary
for
this
kind
cluster.
So
I
have
the
kind
control
plan.
I
have
the
metric
server,
which
is
also
running
in
this
cluster.
I've
got
the
kindnet,
which
is
the
cni
for
the
kind
cluster
and
then
some
exemptions
for
cert
manager.
Now
these
are
some
of
these
are
trade-offs
right.
I
may
want
to
actually
go
configure
cpu
limits
in
memory
for
for
cert
manager.
C
For
the
purposes
of
this
demo,
I
just
went
ahead
and
ignored
those
instead
of
writing
up
a
whole
values,
file
for
cert
manager
and
then
some
the
kind
now
rules
as
well,
but
you
can
see
we
have
our
custom
checks
in
here
for
host
path,
mount
and
then
a
couple
other
exemptions
as
well.
So
basically,
I
went
through
this
process
of
looking
at
my
cluster
and
saying:
does
it
need
to
pass
that
check
or
not
adding
an
exemption?
C
Does
it
need
to
pass
that
check
or
not
adding
an
exemption
and
then
going
through
and
fixing
the
other
things
that
may
need
to
be
fixed?
And
then
we
also
have
a
couple
other
custom
checks
in
here
like
I
want
all
of
my
deployments
to
have
a
specific
label
called
team,
because
I
use
that
for
cost
allocation.
C
C
C
C
C
The
other
thing
that's
cool
about
exemptions
is
with
the
dashboard.
If
you're
curious,
you
know
what
what's
going
on
without
the
exemptions,
you
can
actually
click
here
at
the
top
to
view
the
report.
Without
the
exemptions,
it
just
adds
a
url
parameter
called
disallow
exemptions
and
so
now
we'll
see
like
the
full
view,
without
the
exemption.
So
if
you're
curious,
you
know
what
that
looks
like
so
here
we
see
now
we're
down
to
113
passing
checks.
Three
warnings
in
two
dangerous,
it
looks
like
dangerous
is
in
our
fair
ones:
custom!
C
C
C
B
C
Don't
think
it
would
based
on
the
way
that
particular
policy
is
written.
I
think
if
we
go
back
and
look
at
our
image
poll
policy-
oh
it
is
targeting
the
container,
so
it
might
have
yes,
it
may
have
done
that,
but
the
deployment
in
the
cluster
would
still
say
image
pull
policy,
if
not
present,
if
not
yeah,
and
so
it
would
still
show
up
in
the
dashboard.
So
we
really,
you
know,
want
to
make
it
at.
B
C
B
C
C
Yep
all
right,
I
think,
we've
so
we've
covered
validating
emission
web
hooks.
We
covered
mutating
emission
web
hooks,
we
covered
custom
policy
and
json
schema.
We
covered
customizing
your
configuration,
which
controls
how
you
block
things
with
the
admission
controller
and
the
mutating
admission
web
hook,
we've
also
covered
exemptions
and
how
you
do
that,
and
we've
talked
about
a
strategy
for
rolling
out
policy
in
your
cluster
and
then
the
three
different
points
at
which
we
can
inject
that
policy
ci
admission
or
in
the
cluster
at
runtime.
A
Did
I
miss
anything
yeah,
so
much
content
and
and
such
a
good
time?
That's
always
awesome,
and
I
guess
this
is
now
the
time
for
the
q
a
portion,
not
that
we
haven't
been
taking
questions
before
this,
but
this
is
purely
for
the
q
a
so
if
anyone
in
the
audience
you
have
questions
now
is
the
time
to
ask
so
send
those
questions
in
and
we'll
get
them
answered.
A
C
C
So
if
you
go
to
any
of
our
open
source
repos
right
at
the
top,
there
should
be
a
link
to
join
our
slack,
maybe
not
right
at
the
top.
But
it's
in
here
somewhere,
chat
with
us
on
slack
that
should
be
in
all
of
our
open
source.
Repos,
so
feel
free
to
join
that
slack,
and
we
have
channels
for
each
one
of
our
open
source
projects.
Polaris
is
just
one
of
several
that
we
we
maintain.
A
Perfect
next
steps
clear,
then,
as
far
as
contacting
that's
lovely-
and
we
also
have
a
cloud
native
live
channel
in
the
cncf
slack,
where
discussion
can
be
continued
as
well,
so
that's
always
an
opportunity
as
well,
but
going
directly
towards
if
you
want
people
to
learn
more
about
polaris.
I
think
that
sounds
like
a
great
place
to
open
to
learn
more
about
those
things,
particularly
but
yeah
still
a
few
minutes
for
time
for
questions.
A
C
C
I
don't
know
that
we
have
any
major
enhancements
planned
over
the
next,
while
the
expansion
of
policy
to
allow
targeting
different
specs
beyond
just
the
container
was
a
huge
change.
We
made
just
recently
really
so
nothing
earth-shattering
on
the
horizon,
but
yeah
always
open
to
feature
requests
in
the
github
repo
and
ideas
that
folks
have
for
players.
A
Perfect
and
still
time
for
it
for
questions,
but
this
is
most
having
a
final
call.
If
nothing
pops
up,
we
can
start
wrapping
up,
but
before
we
do
that,
if
someone's
just
now
typing
it
away
any
final
notes
from
from
you,
stevie
randy,
any
final
learn
more
resources
that
you
want
to
share
or
anything.
C
B
A
I
think
it's
good
yeah
open
source
works,
but
yeah
perfect.
So
thank
you
so
much
for
speaking.
I
can
see
that
people
are
saying
good
job.
Thank
you
and
what
not
so
awesome
demo
from
my
side
as
well.
Thank
you
so
much
for
that
really
great,
but
yeah.
Let's
start
cleaning
it
up.
So
thank
you.
Everyone
for
joining
the
latest
episode
of
cloud
native
live.
It
was
great
to
have
a
session
about
polaris
today
really
loved
the
introduction,
as
well
as
the
question
from
the
audience
really
amazing.