►
From YouTube: Delivering optimal Out-of-Box experiences
Description
Don’t miss out! Join us at our upcoming event: KubeCon + CloudNativeCon Europe in Amsterdam, The Netherlands from April 17-21, 2023. Learn more at https://kubecon.io The conference features presentations from developers and end users of Kubernetes, Prometheus, Envoy, and all of the other CNCF-hosted projects.
A
B
B
A
Attendee,
but
there
is
a
chat
box
on
the
right
hand,
side
of
your
screen.
Please
feel
free
to
drop
your
questions
there
and
we'll
get
to
as
many
as
we
can.
At
the
end.
This
is
an
official
webinar
of
the
cncf
and,
as
such
is
subject
to
the
cncf
code
of
conduct.
Please
do
not
that
or
questions
that
would
be
in
violation
of
that
code
of
conduct
and
be
respectful
of
all
of
your
fellow
participants
and
presenters.
Please
also
note
that
the
recording
and
slides
will
be
posted
later
today
to
the
cncf
online
programs
page.
A
B
Thank
you
very
much
greatly
appreciate
it
and
thanks
everybody.
For
joining
this
morning,
I'm
Bob
monkman,
open
source
strategist
for
Intel,
based
in
California
I've,
got
with
me
today:
Peter
Torre
principal
engineer
and
Daniel
Ugarte,
product
manager
and
Technical
product
manager,
and
so
we're
gonna.
We're
gonna
give
an
overview
today
of
Network
platform
reference
architectures
and
how
they
deliver
out
of
the
box
productivity
for
cloud
native
application
development.
B
B
We
go
I'm
just
familiarizing
myself
with
this
tool,
all
right,
very
good,
so
again,
OtterBox
productivity,
delivered
by
reference
system
architectures
and
we're
going
to
have
a
particular
focus
on
communication
infrastructure
systems
and
that
sector.
But
let's,
let's
just
go
through
a
little
bit
of
setup.
First
so
I
mean
some
of
the
trends
that
we're
seeing
in
network
infrastructure.
Our
course
are
the
the
cloudification
of
everything
everything's
connected
to
the
cloud.
B
You
know,
on-prem
and
Cloud
environments
and
service
agility
becomes
a
really
key
factor
in
this
in
this
new
sort
of
environment
that
that
the
need
to
or
the
requirement
from
customers
to
meet,
Market
demands
delivering
new
service
services
in
minutes,
ideally
instead
of
months
and
then,
as
I
mentioned
a
little
bit
earlier.
Now
that
we're
connected
to
everything
out
there
and
you
have
the
internet
of
things.
You
have
intelligent
systems,
millions
and
billions
of
intelligent
systems
out
there.
B
The
burden
of
orchestration
and
management
is
really
becoming
beyond
the
capabilities
of
humans
to
manage
so
you're
alone,
so
you're,
seeing
the
the
Advent
of
AI
and
machine
learning
to
help
to
orchestrate
to
schedule
to
manage
these
systems
and,
furthermore,
we're
seeing
this.
This
move
to
you
know
Cloud
native
design
and
microservices
design
and
implementation
of
those
Services,
some
of
the
market
data
that
we're
seeing
and
the
conversations
that
we'd
have
with
cloud
service
providers
and
Service
software
as
a
service
vendors
out.
B
There
is
that
over
the
next
couple,
three
years,
we're
going
to
see
80
percent
or
more
experts
predict
software
done
in
a
cloud
native
and
microservices
implementation.
So
that's
a
massive
shift,
very
rapid
shift
and
it's
really
happening
across
multiple
sectors
and
today
we're
gonna
focus
more
on.
You
know
comms
infrastructure,
because
that's
where
we
have
some
particularly
interesting
examples
today,
but
it
really
applies
broadly
across
a
broad
swath
of
sectors,
and
this
really
has
a
significant
impact
on
the
technology
building
blocks
that
are
relevant.
B
The
way
that
software
is
built,
the
way
that
software
is
assured
and
the
way
that
software
is
delivered
and,
as
I
said
earlier,
we
really
have
this.
This
massive
complexity
and
this
need
for
AI
and
ml
to
help
get
us
to
a
point
where
you
have.
They
see
the
Advent
and
the
emergence
of
Concepts
like
zero
touch,
automation,
aided
by
a
Ai
and
machine
learning.
B
Now
in
the
network,
transformation
space
in
particular,
when
we
look
at
the
applications
across
the
Continuum
of
edge
back
into
the
cloud,
there
are
some
unique
challenges
that
have
always
been
there:
realities
that
that
this
sector
in
particular,
has
to
deal
with
and
I'm,
not
going
to.
You
know,
sort
of
rattle
them
all
up,
but
you
can
sort
of
see
them
here
and
we're
working
with
all
the
leading
vendors,
the
isvs,
the
service
providers,
system,
integrators
and
and
others
to
comprehend.
B
These
challenges,
and
some
of
which
are
introduced
with
these
new
technologies
that
we're
not
necessarily
designed
with
all
of
these
challenges
in
mind.
You
know
we
work
with
these
ecosystem
players
and
leverage
our
deep
insight
into
how
software
executes
and
how
data
moves
across
the
system
to
identify
bottlenecks
and
gaps,
and
then
we
work
with
these
players
to
mitigate
these
issues
and
deliver
enhancements
to
the
open
source
communities,
our
partners
and
our
customers.
B
But
you
know
all
of
these
point
optimizations
that
we
can
achieve
and
deliver
through
these
open
source
communities
are
only
part
of
the
solution,
and
our
topic
today
is
centered
on.
How
can
we
take
this
work
one
step
further
and
deliver
highly
integrated,
well-documented
reference
system
architecture
to
the
market
that
helps
speed,
deployment
of
new
infrastructure
and
services
that
can
be
built
with
these
optimized
Solutions?
B
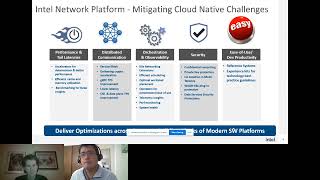
So
here
you
see
this
sort
of
introduction
to
the
Intel
Network
platform
and
the
idea
here
is
it's:
it's
really
a
an
offering
that
is
geared
towards
easing
and
accelerating
this
network
transformation.
It
addresses
these
challenges
by
delivering
software
and
Hardware
Innovation
and
adoption
tools
that
enable
the
ecosystem
of
vendors
and
service
providers
to
leverage
them
and
deliver
these
Services
much
more
rapidly.
So,
on
the
left
hand,
side,
we
see
Hardware
and
a
broad
range
of
software
optimizations
in
different
areas
that
mitigate
some
of
these
challenges
that
we
discussed
on
the
previous
slide.
B
It's
really
and
again
here.
If
you
look
at
some
of
the
details,
I
won't
go
through
all
of
them,
but
this
this
is
measured
in
terms
of
you
know:
things
like
crypto
acceleration
compression
acceleration
transactions
per
per
second
across.
You
know,
remote
procedure
calls
service.
Mesh
optimization
service
mesh
in
particularly,
is
a
really
powerful
way
to
connect
microservices,
but
it
comes
with
a
lot
of
overhead.
So
we've
we've
found
and
implemented
a
great
deal
of
optimizations
to
to
mitigate
that
overhead.
B
B
If
we
take
yet
another
deeper
look
at
this,
it's
not
just
one
sort
of
one-size-fits-all
reference
system
architecture,
because
as
you're
well
aware,
there's
at
least
three
fundamental
operating
environments
that
people
are
deploying
these
Cloud
native
applications
in.
We
have
you
know:
sort
of
native
bare
metal
on
physical
Hardware
deployments.
Typically
on-prem.
We
have
some.
You
know
virtual
machine
in
configurations
and
environments,
often
in
the
private
cloud
and
then,
of
course,
more
and
more
we're
seeing
applications.
B
Software
Services,
written
for
and
deployed
in
the
in
the
cloud
instances
from
the
major
cloud
service
providers
and
each
of
these
reference
architectures
are
designed
from
the
ground
up
to
accommodate
and
address
these
uni.
The
unique
environmental
considerations
of
these
different
environments
and.
A
B
If
we
take
a
closer
look,
what
does
that
really
mean?
If
you
look,
this
is
just
really
just
a
visual
depiction
of
you
know
what
the
bare
metal,
the
virtual
machine
reference
architecture
and
the
cloud
reference
architecture
might
look
like,
and
it
just
gives
you
a
sort
of
a
visual
sense
of
on
the
left
hand
side.
Here
we
have
a
bare
metal
cluster
deployment
here
on
individual
servers
down
in
the
sort
of
bottom
of
these.
B
Each
of
these
boxes
is
a
node,
a
physical
server
right
control,
nodes
worker
nodes
that
make
up
the
kubernetes
cluster
in
the
middle.
You
have
virtual
clusters.
This
is
just
showing
a
single
node,
but
it
should
be
noted
that
you
know
this
in
this
environment.
This
configuration
certainly
does
support
multi,
multi-nose
virtual
machine
deployments
across
multiple
nodes
and
then,
of
course,
on
the
on
the
right
hand,
side
you
have
this
particular
example.
B
Here
is
an
AWS
eks
instance
environment
and
all
the
necessary
considerations
and
support
for
that
kind
of
environment
are
built
into
this
particular
reference
architecture.
So
the
reference
architecture,
concept
and
deliverables
are
very
really
flexible.
Providing
you
know
options
for
these
multiple
modern.
You
know
Network
deployment
types.
B
And
then,
within
those
different
environments,
we
actually
have
created
a
lot
of
very
specific.
What
we
call
configuration
profiles
and
what
that
entails
is
a
very
specific
hardware
and
software
bill
of
materials,
a
manifest
if
you
will
specifically
for
certain
workloads
or
application
requirements,
the
application
requirements,
the
stack
is
going
to
be
different
for
ran
elements
versus
you
know
versus
transport
elements
versus
The
Core
of
a
5G
network.
If
you
will
so.
B
B
And
earlier
I
mentioned
that
it's
not
just
the
software
integrated
reference
platform,
that's
delivered
here.
We
have
this
notion
of
experience
kits
as
well,
and
so
the
experience
kit
again
is:
is
it's
really
a
a
a
library
of
documentation?
How-To
guides
training
that
provide
best
practices,
step-by-step
instructions
and
development
guidelines
for
each
of
the?
B
So
when
you
view
the
recording
later
you'll
be
able
to
go
to
these
links
and
actually
examine
these
experience
kits
and
see
what's
in
them,
but
this
is
a
big
part
of
the
puzzle.
It's
not
just
throwing
software
optimizations
after
you,
it's
giving
you
these
integrated
packages
with
the
guidelines
with
the
training,
with
the
step-by-step
instructions
on
how
to
use
all
of
the
various
elements
within
the
reference
architecture.
B
C
Hey
thanks
Bob,
so
so
next,
three
slides
in
about
eight
to
minutes
I
will
explain.
How
did
you
look
at
compute
intensive
workload
in
multi
and
hybrid
Cloud
environment
and
their
repaid
special
attention
to
satisfying
the
key
principles
where
we
would
like
to
do
it
multi-cloud,
meaning
across
multiple
different
environments?
C
Obvious
consequence
of
that
is,
as
we
are
trying
to
do
it.
We
should
not
be
using
single
environment
tooling.
That
will
not
work
on
the
next
environment,
and
this
is
where
previously
mentioned.
Reference
architectures
are
really
helping
and
as
we
wanted
to
have
an
outcome
that
in
real
world
would
also
have
easy
life
cycle
and
easy
onboarding.
We
need
to
be
careful,
as
we
are
layering
the
stack
in
the
sense
that
we
don't
unconsciously,
create
undesired
linkages
and
dependencies
and
actually
bring
this
thing
into
combination.
That
is
very
hard
to
decouple.
C
Now
this
example.
Here
we
have,
let's
start,
for
example,
from
the
bottom.
We
have
consistent
Hardware
platform
in
AWS
region
and
on
premises
in
form
of
inclusion,
CPUs
with
particular
CPU
instructions
that
will
help
us
and
then
next
level
of
consistency
is
to
have
a
kubernetes
environment
with
particular
features.
C
And
here
we
will
look
at
note,
feature
discovery
that
is
giving
us
details
of
underlying
software
and
Hardware
platform
and
where
supported,
we
can
also
enable
next
level
of
features
that
are
useful
for
compute
intensive
workload
that
is
coming
here,
which
is
CPU
pinning
with
static
policy
for
cubelet
for
CPU
manager.
And
while
we
do
know
how
to
do
that
in
case
of
eks,
this
is
still
to
be
all
documented
and
supported.
B
C
Part
of
clouds
is
to
make
sure
that
across
different
environments,
we
have
minimum
inconsistency
and
maximum
in
common
in
Tosca
blueprints.
Of
course,
the
Pod
is
the
same,
and
the
different
ways
of
building
kubernetes
environments
are
very
consistent,
and
this
is
all
also
documented.
You
have
the
paper
here
for
the
reading
and
if
you
could
move
to
next
slide,
this
is
visualizing
how
we
built
the
stack.
So
in
this
example,
here
we
will
have
benefits
of
the.
C
C
Get
hold
of
appropriate
eks,
kubernetes,
managed
service
and
appropriate
ec2
instances,
and
here
for
purpose
of
comparison,
we
will
take
the
current
compute
instances
with
third
generation
Xeon
and
then
the
previous
Xeon
also
to
compare
it
to
and
in
those
CPUs
we
have
different
Vector
instructions
that
are
either
the
current
is
AVX
512
or
the
previous
is
avx2.
They
are
512
or
256
bits
bit
and
based
on
that,
we
will
see
different
performance.
C
So
so
all
of
that
being
automated,
it's
easy
to
create
different
instances
all
within
the
same
cluster
and
also
to
deploy
different
versions
of
this
Monte
Carlo.
Well,
actually,
the
same
pod,
which
is
different
environment
variables.
So
it
knows
how
to
run
and
what
to
do,
and
we
can
observe
that,
for
example,
we
have
so
so
lower
is
better
here.
This
is
elapsed
time
to
complete
the
simulation
of
particular
size,
and
we
can
observe
two
benefits
coming
here.
C
One
is
that
generational
improvements,
the
current
instances
so
c6i
or
equivalent
that
is
coming
with
third
generation
Xeon
ice,
like
is
the
code
name,
are
faster
than
the
previous
ones.
For
this
type
of
workloads,
boats
running
in
avx2
version
and
AVX
512
and
generally
when
we
run
just
compute
workloads
that
are
not
using
Vector
instructions,
also,
we
observe
similar
and
then
this
workload
really
correlates
with
the
size
of
those
the
width
of
those
vectors
and
because
512
is
double
the
256.
C
We
see
that
the
workload
runs
two
times
faster
when
we
enable
it
with
AVX
512
compared
to
avx2,
and
we
see
this
about
2x
consistent
on
current
Generations
or
on
previous
generations,
and
this
directly
equates
results
in
reduced
time
to
use
the
instances
or
reduce
costs
of
those
instances
of
the
compute
time,
and
this
was
our
example
and
with
that
we
will
moved
to
Daniel,
who
will
explain
a
little
not
little
but
way
more
complicated
example
than
just
compute
intensive
one.
Okay,
it's
better
thanks.
D
Yes
hi:
this
is
Daniel
liberte,
so
I'll
be
presenting
the
the
application
of
the
bmra,
the
bare
metal
reference
architecture
to
the
vran
and
our
Flex
Run
Intel's
Flex
Run
solution,
and
we
go
to
the
next
slide,
please.
So,
let's
start
by
explaining
what
is
brn
and
or
flex
run.
So
this
is
part
of
the
5G
Network
and
the
V
run.
It's
the
the
radio
access
node.
It's
been
used
as
the
base
station.
D
This
is
what
handles
the
physical
layers
for
the
wireless
for
the
wireless
media
and
all
the
way
to
the
control
layer
in
the
in
the
in
the
5G
Network.
Now
what
is
the
reference
architecture
doing
here?
So
if
you
see
on
the
left,
so
Bob
Bob
mentioned
the
the
configuration
profiles.
So
this
is
an
example
of
what
the
configuration
profile
for
the
vran
is
right.
So
basically
it's
a
it's
a
representation
of
all
software
in
ingredients
that
we
have
from
the
network
from
one
of
our
teams
from
the
network
platform
teams.
D
D
If
you
see
at
the
top,
there
are
different
buckets.
Let's
say
that
okay
kubernetes
has
many
different
features
and
we
turn
on
a
subset
of
these
features
for
kubernetes,
for
service
mesh,
for
security,
for
power
management,
and
we
go
all
the
way
down
to
the
hardware
and
techniques
operating
system
and
so
on
right.
D
So
this
is
the
bomb
the
bill
of
materials
that
was
presented
previously.
Now
they
line
the
the
green
line
that
you
see.
There
implies
that
that
those
are
our
choices
right
for
the
needed
for
the
appearance.
If
you
move
to
the
right,
what
we
have
here
is
how
does
the
flex
run?
So
how
does
the
reference
architecture
deploys
this
configuration
profile
right?
D
We
use
a
set
of
ansible
scripts
and
civil
playbooks
that
deploys
a
capabilities
or
these
ingredients
on
a
cluster-wide
based
or
or
for
this
software,
the
software
that
it
is
required
for
the
work
worker
nodes
or
control
nodes,
some
of
these
capabilities-
yes,
they
they
are
shared
across
all
all
nodes.
Some
of
them
are
only
in
the
in
the
in
the
work
or
not
with
the
flex
run
application.
D
If
we,
this
is,
if
you
see
a
this,
is
an
optimized
and
validated
easy
and
fast
way
to
deploy
the
vrm
reference
system
right.
If
you
go
to
the
next
slide,
please
thank
you.
So
how?
Let's
see
how
how
this
is
consumed
right
so
at
the
bottom,
you
will
see
all
our
Hardware
selections
for
vran
or
Flex
Run.
D
D
So
if
there
are
tests
that
are
Standalone,
they
could
deploy
these
test
modes
right
to
see
in
this
case
is
The.
Bu
is
part
of
the
Vari
run
to
see
that
the
room
they
their
sorry,
the
the
DU
and
flex
run
in
action.
They
would
see
how
that
how
does
the
layer
one
performs
right
and
how
does
the
layer
one
layer
one
performs
with
their
Nicks
if
they
are
connected
to
a
to
a
radial
simulator
right,
so
we
have
created
a
couple
of
profiles,
one
on
the
left
side.
D
D
In
the
case
of
Intel,
we
can
reach
the
customers
with
a
an
early
version
of
our
of
ours,
silicon
right,
and
so,
when
customers
receive
these
early
versions
of
Hardware,
they
could
see
the
flex
money
in
action
and
and
see
how
what
performance
improvements
they
have
right.
So
it's
a
way
to
engage
the
the
customers
earlier
on
another
way
to
to
use
the
reference
architecture
is
so
if
Partners
would
like
to
start
testing
right
and
they
have
a
more
complicated
tests
to
perform.
D
The
reference
architecture
is
the
first
step
where
they
receive
a
pre-verify.
Already
verified
software
platform
and
a
software
and
Hardware
platforms,
and
and
they
can
check
that
everything
is
in
place,
that
they
have
the
right
versions,
the
right
configurations
all
over
the
system
and
then
start
their
testing,
and
this
will
reduce
a
lot
of
the
overhead
produced
when
the
customers
or
Partners
have
to
verify
every
single
little
thing
in
the
recipe
that
they
are
using.
D
If
we
go
to
the
next
slide,
please,
so
how
does
the
reference
architecture
evolve
over
time
right?
So
this
is
an
example
of
what
we
call
a
capability.
A
capability
is,
basically
they
the
bundle
of
different
software
ingredients
that
provide
one
system,
property
or
system
behavior.
Let's
say
you
have
you
can
have
a
capabilities
or
one
capability
could
be
a
security.
Another
capability
could
be
power.
Management
in
the
case
of
a
flex
run
application.
D
We
have
the
power
management
capability
and
these
are
a
series
of
optimizations
in
different
pieces
of
software
and
different
across
different
layers
of
the
stack
now
so
many
much
of
this
capability
or
already
exists,
and
it's
been
moving
from
one
generation
to
the
next
right,
but
in
this
case
our
new
suffer
Rapids.
They
have
optimizations
or
how
to
send
our
course
to
sleep
for
to
reduce
the
power
consumption.
D
So
there
are
different
instructions
provided
to
different
layers,
all
the
way
to
the
application
layer.
So
the
application
is
in
control
of
of
how
to
send
this
this
this
Force
to
sleep.
So
in
the
case
of
suffer
Rapids.
Yes,
there
are
new
states
that
are
being
used
at
the
dpdk
and
with
different
boot
settings
and
that's
provided
to
the
flex
run
application
right
and
yes,
so
so
you
will
see
improvements
when
moving
from
one
generation
to
the
next.