►
From YouTube: CNCF Live Webinar: Kubernetes 1.23 Release
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
A
Today's
webinar
I'm
going
to
read
our
code
of
conduct
and
then
hand
over
to
karen
chu,
ray
lahanno
and
xander
gravinsky
with
0.23
release
team
a
few
housekeeping
items
before
we
get
started
during
the
webinar
you're
not
able
to
speak,
but
there
is
a
q,
a
box
on
the
right
hand,
side
of
your
screen.
Please
feel
free
to
drop
your
questions
there
and
we'll
get
to
as
many
as
we
can.
At
the
end.
A
A
Please
also
note
that
this
recording
and
slides
will
be
posted
later
today
to
the
cncf
online
page
unity.cncf.io
under
online
programs
they're
also
available
via
your
registry
and
the
recording
will
also
be
available
on
our
cncf
youtube
channel.
Under
online
programs
playlist
with
that,
I
will
hand
it
over
to
the
team.
B
D
We've
got
just
a
brief
overview
here
of
the
projected
timeline
for
the
1.24
release,
so
we'll
be
kicking
the
release
off
on
monday
january
10th
next
monday
here
and
then
all
of
the
following
dates
after
that
are
are
subject
to
change,
particularly
the
enhancements
freeze
date.
But
this
is
kind
of
what
we
have
laid
out
so
far.
Looking
at
an
initial
enhancements
freeze
of
thursday
january
27th,
followed
by
code
freeze
on
march
29th
and
then
targeting
final
release
for
1.24
on
tuesday
april
19th.
C
C
D
A
little
overview
of
the
enhancements
that
we
had
attract
for
1.23,
we
ended
up
with
a
total
of
47
tracked
11
of
those
being
stable,
16
beta
and
then
19
new
alpha
features
and
one
deprecation-
and
you
know,
since
1.17,
there's
consistently
been
north
of
of
10
stable
features
which
is
pretty
fun,
and
then
I
guess
for
those
unfamiliar
with
the
terminology.
Here,
the
the
alpha
features.
C
C
C
Secondly,
the
pod
security
admission
is
now
beta,
so
for
those
who
are
familiar
with
the
pod
security
policies,
which
were
dedicated
in
1.21
and
pod
security
policies,
also
known
as
psps,
is
targeted
to
be
removed
in
1.25.
So
pod
security
mission
is
the
replacement
for
cop
for
pod
security
policy.
What
it
is
it's
a
mission
controller
that
evaluates
pods
against
a
predefined
set
of
pod
security
standards
to
either
admit
or
deny
the
pod
from
running,
so
we'll
go
into
a
little
more
detail
when
we
go
through
the
stick
updates.
C
C
Also,
the
cubelet
container
runtime
interface
is
now
beta,
so
the
cri
v1
apis
is
also
the
default,
since
it
is
beta.
Go
into
that
a
little
more
detail
with
the
sega
updates
as
well.
Some
more
major
themes
here.
The
ttl
controller
is
now
stable,
which
cleans
up
it's
a
little
like
a
garbage
collector
for
cleans
up,
drops
and
pods
after
they
finish,
you
do
have
to
set
a
specific
field
in
the
jobs
the
ttl
seconds
after
finish,
to
be
set.
C
Then
then,
a
kubernetes
well,
there's
a
controller
that
will
watch
all
the
jobs
and
I'll
compare
that
field
against
the
current
time
to
see
if
the
pods
are
done
or
the
job
is
done
and
they
will
delete
those
corresponding
pods
another
one,
simplified
multi-point
plug-in
configuration
for
scheduler,
so
this
is
for
the
new,
for
this
is
for
the
cube
scheduler.
It's
adding
a
new,
simplified
config
field
for
plug-ins
to
allow
for
multiple
extension
points
to
be
enabled
one
place.
Another
one
is
the
generic
inline
volumes.
C
2
is
now
ga,
so
this
allows
any
existing
storage
driver
that
supports
dynamic,
provisioning
to
be
used
and
as
an
ephemeral
volume,
that's
bound
to
the
pod
so
come
again
to
gear
another
one.
Is
software
supply
chain,
salsa
level,
one
compliance
so
kubernetes
now
releases
and
generates
pro
provenance
and
station
files
describing
the
the
staging
and
release
phases
said
the
release
process,
so
the
artifacts
are
now
verified,
as
they're
handed
over
from
one
phase
to
the
next
more
major
themes,
the
skip
volume
ownership
change.
C
So
this
feature
allows
you
to
to
to
choose.
If
you
want
to
change
your
ownership,
when
a
volume
is
by
not
inside
a
container,
otherwise
it
would
go
back
recursively
to
change
the
ownership
for
each
for
each
volume
I'll
go
into
this,
like
I
mentioned
more
in
the
sig
updates
as
well,
and
the
problem
is
that
it
could
kind
of
take
too
long
for
very
large
volumes.
C
So
this
allows
you
as
an
option
to
eat,
to
skip
that
also
allows
csi
drivers
to
opt
in
volume
and
permission
changes,
so
this
allows
csi
drivers
to
declare
support
for
fs
group
based
permissions.
Structured
logging
is
now
data,
so
most
log
messages
from
cubelets
and
cubescheduler
has
been
converted
and
there's
more
csi
migration
updates.
So
there's
this
is
a
continuation.
C
C
So
if
the
feature
gate
is
enabled,
a
custom
resource
can
be
valid
using
the
common
expression
language,
no
one's
opened
api
b3,
open
api
v3
is
more
transparent
than
an
open
api
v2.
It's
also
more
expressive
because
we
actually
lost
some
fields
when
we
published
with
open
api,
v2
server
side,
feed
validation.
So
the
this
is
now
alpha,
so
the
speech
gate
is
enabled
users
will
receive
warnings
from
the
server
when
they
send
a
kubernetes
objects
in
their
request
that
contain
unknown
or
duplicate
fields,
deprecation
of
flex
volume.
C
C
Now
we'll
go
into
the
sig
updates,
so
we're
going
so
we're
going
to
go
through
each
various
cigs
and
talk
about
the
enhancements
per
sig,
starting
off
with
sig
api
machinery,
which
covers
all
aspects
of
the
api
server.
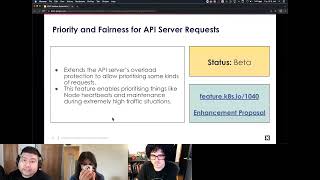
The
first
one
is
priority.
Fairness
of
api
server
request,
so
this
actually
extends
the
existing
maxim
flight
request
handler
in
the
api
server,
so
that
we
can
make
more
distinctions
among
requests
to
provide
prioritization
fairness
among
other
other
categories
of
requests.
So
this
so
we
get
priority.
C
C
C
So
this
is
the
links
here
again
to
feature
announcements
issue
2885.
So
this
allows
you
to
send
before
if
there
was
a
server-side,
a
node
field,
validation,
it
will
let
go
through,
but
now
with
the
server
side.
Validation.
If
there's
an
if
there's
a
misspelled
field
or
or
invalid
field
or
extra
field
or
any
field,
that's
duplicated,
it
will
not
allow
that
this
also
is
also
kind
of
linked
to
there's
the
client
side
validation
might
is.
C
Open
api
enum
types
is
alpha,
and
so
the
way
it
is
now
currently
or
before
123
or
currently,
since
this
is
still
at
alpha
the
api
fields
that
meepseed
are
actually
enums
but
they're
actually
represented
as
plain
string.
So
this
adds
in
in
a
marker
so
that
those
enum
types
so
that
allows
for
element
type
support
for
open
api
open
api
v3
goes
to
alpha
so
open
api
v3,
like
I
mentioned
before,
is
more
transparent
and
expressive
and
with
open
api
v2,
there
are
some
fields
that
were
dropped
when
published.
D
D
And
then
this
one
ray
touched
on
as
a
major
theme,
I
believe
the
the
ttl
after
finish
controller,
so
this
adds
a
field
to
jobs.
The
the
ttl
seconds
after
finish,
to
allow
this
new
controller
to
clean
up
old
pods
related
to
jobs.
So
this
actually
went
stable
this
time
around
and
yeah
like
ray
mentioned
in
the
the
major
themes,
it
does
require
that
that
field
set
to
to
make
use
of
that.
D
D
And
then
min
ready
seconds
on
stateful
sets
allows
end
users
to
specify
a
number
of
seconds
that
a
pod
must
exist
without
crash
looping,
for
the
stateful
set
to
be
considered
ready
and
have
that
status.
It's
an
existing
feature
with
deployments
and
daemon
sets
and
replica
sets.
So
this
adds
parity
with
stateful
sets.
C
C
C
There
is
a
feature
blog
on
this
on
the
kubernetes.io
website
and
with
some
tutorials
as
well.
Support
security
mission
controller
enforces
the
pod
security
standards
on
pods
within
the
namespace
there's
three
pod
security
stand
three
levels
of
pod
security
standards,
privileged
baseline
and
restricted,
and
you
can
set
the
policy
enforcement
in
three
ways
as
well:
enforcing
audit
or
warning,
and
you
use
this.
You
use
policy
enforcements
through
label
through
namespaces
and
through
labels
on
the
namespace.
D
D
C
Next
is
six
cli,
which
covers
keep
control
and
related
tools,
there's
a
new
command
which
is
in
alpha
as
cube
control
events,
it's
different
from
control
get
event,
so
it
this
does
add
a
new
command
and
adds
more
features.
Then
keep
control
get
events.
So
there's
like
default
sorting
of
the
events.
You
can
manipulate
events
more,
so
you
could
sort
events
with
other
criteria.
You
could
also
list
events
in
the
timeline
for
last
and
minutes.
C
D
We've
got
cluster
life
cycle,
and
so
this
sig
deals
with
everything,
cluster
life
cycle
deployment
and
and
upgrades
of
kubernetes
clusters
and
the
the
one
enhancement
that
we
have
here
is
for
keep
adm.
So
when
q,
a
q
adm
does
its
initial
init,
it
creates
a
config
map
in
the
cluster,
and
this
is
just
a
kept
that
changes.
The
naming
of
of
that
config
map
to
a
more
simplified
form.
C
Next
is
sig
instrumentation,
which
covers
best
practice
for
observability
through
metrics
logging
and
events
across
all
the
components,
so
structured
logging
went
to
beta
so
structured,
so
structure
logging
defines
a
standard
structure
for
log
messages
before
structure
log.
Before
this
next
month
there
was
no
structure
for
log
messages
and
add
some
methods
to
k.
Log
k
log
is
a
fork
of
g
log
to
enforce
this
structure,
and
so,
with
this
most
log
in
123,
most
log
messages
from
cubelet
and
cubescheduler
has
been
converted
related
to
to
k.
Log.
C
Like
I
mentioned
before,
how
k
log
is
a
fork
of
g-log
123,
whether
it
was
alpha.
There's
deprecation
of
k-log,
specific
flags
and
kubernetes
components
is
to
make
logging
more
simplified,
but
there
are
some,
the
the
ones
that
are
being
the
flags
are
being
deprecated
now
they're
now
they're
leaving
them
with
defaults,
so
so
for
the
k,
log
flags
they're,
all
the
they're,
the
plans
to
remove
all
the
flags
besides
dash
v,
and
that
should
be
module.
D
D
So
first
up
was
one
of
the
major
themes
that
that
ray
touched
on,
which
was
ipv4
and
v6.
Dual
stack
support
and
we're
going
stable
this
release,
so
it
adds
adds
dual
stack:
support
for
pods
nodes
and
services
and
yeah.
It's
it's
a
super,
exciting
feature.
I
know
that
this
one,
a
lot
of
folks
worked
really
hard
to
deliver
this
and
it's
it's
really
great
to
see
it
go
to
stable.
D
And
next
up
we
have
namespace
scoped
ingress
class
parameters,
so
it
adds
a
new
scope
and
namespace
fields
to
the
ingress
class
parameter
ref
field
to
allow
referencing
name,
space
scope,
parameters,
resources.
So
this
is
one
I'm
actually
not
super
familiar
with
this
one,
but
you've
got
a
description
there.
I
encourage
folks
to
go.
Take
a
look
at
the
cap
on
the
features
website.
D
I'm
actually
really
excited
about
ephemeral
containers
along
with
the
cube
cuddle
debug
feature,
so
it
adds
a
mechanism
to
run
a
short-lived
container
that
executes
within
the
namespace
of
an
existing
pod
and
allows
debugging
capabilities
against
running
pods
without
having
to
do
the
whole.
Like
cube,
cuddle,
exec,
workflow,
yeah,
this
one's
super
cool
and
then
we've
got
a
container
runtime
interface
support
going
to
beta
yeah.
D
D
And
then
extending
pod
resources
api
to
report,
allocatable
resources,
so
it
ends
up
enhancing
the
metrics
information
adds
to
the
the
cubelet
pod
resources
endpoint,
which
will
allow
third-party
consumers
to
get
more
information
about
compute
allocation.
So
super
useful
for
getting
a
clear
understanding
of
the
state
of
resources
within
a
cluster
and
utilization.
D
And
then
got
a
priority
pod
priority
based
graceful
note,
shut
down
going
to
alpha
so
graceful
node
shutdown
itself
was
a
a
feature
that
moved
up
in
one
of
the
more
recent
releases,
and
this
ties
pod
priority
into
that
feature.
So
it
should
take
pod
priority
values
into
account
to
determine
what
order
the
pods
are
stopped
when
going
through
a
graceful
note,
shutdown
and
then
also
add
some
flags
to
specify
the
total
time
for
shutdown
and
time
to
reserve
for
shutting
down
critical
pods.
D
D
C
C
C
C
So
the
motivation
of
this
announcement
came
from
the
2019
external
security
audit,
where
the
exposure
or
we
we,
what
was
discovered
was
that
secrets
were
were
exposed
to
logs
or
execution
environments.
In
three
ways
the
bare
tokens
are
revealed
in
logs
environment
variables
exposed
since
the
data,
iscsi
volume,
storage,
sort
of
clear
text
secrets
and
logs.
C
So
with
this
enhancement,
there's
a
type
analysis
called
taint
propagation
analysis
which
provides
inside
how
on
how
the
data
is
spread
from
within
the
program.
So,
with
this
feature
with
their
state,
there's
a
taint
propagation
analysis
tool
called
go
flow
levy,
so
it
runs
as
a
blocking
presement
test
and
which,
which
will
detect
if
the
secret
is,
is
being
exposed
anywhere
with
that
pull
request.
So
during
the
testing
of
that
and
it
will
block
any
pull
requests
that
log
any
secrets.
C
First,
one
is
skip
volume,
ownership
change,
so
this
feature
went
too
stable.
So
this
is
one
of
the
one
of
the
major
themes.
So
the
problem
before
was
that
when
a
volume
is
by
mount
inside
a
container,
the
permissions
on
that
volume
are
changed.
Recursively
to
to
that
fs
group
value
that
is
provided.
C
This
change
in
ownership
can
take
a
very
long
time
if
the
volume
is
very
large.
So
any
issues
this
we
saw
a
lot
of
issues
with
databases
with
very
large
volumes,
so
with
this
feature,
allows
the
user
to
specify
how
they
want
the
permission,
ownership
change
for
volumes-
you
can
set
it
to
always
so
always
change
your
their
permissions
and
ownership
to
match
this
group
or
on
route
mismatch
so
only
perform
the
permission.
Ownership
change.
C
If
the
permissions
does
not
match
the
expectations
compared
to
the
top
level
directory,
so
there's
like
I
mentioned
one
of
the
major
themes
that
there's
a
continued
effort
to
move
entry.
Csi
plugin
entry,
two
csi
plugins-
so
this
is
one
of
the
enhancements
that
went
to
is
aws
ebs
entry
to
csi
driver
migration.
So
this
is
the
part
of
that
continued
effort
to
migrate
entry
storage
plugins
to
your
csi,
so
this
migrates
internal
73,
aws
eds
plugin,
to
call
out
to
the
ebs
csi
plugin.
C
This
is
another
one
for
gcepd.
Another
continued
effort
to
move
the
migrate
entry
storage
plugins
to
csi,
so
migrated
internals,
avenchy,
gsgcpd
plugin
to
call
out
the
pd
csi
driver.
So
this
went
to
beta
azure
desk
entry
to
csi
driver
migration
went
to
beta.
This
is
another
one
of
the
continued
entry
storage
plugins,
two
csi
next
config
fs
group
policy
and
csi
drive.
C
Generic
inline
thermal
volumes
went
too
stable.
So
this
is
one
of
the
major
themes
as
well,
so
this
allows
you
similar
to
empty
deer,
but
with
with
csi
plug-ins
that
allows
you
to
use
any
existing
storage
driver
that
sports
dynamic
provisioning
to
be
used
as
an
environmental
volume
recovering
from
resize
failures
went
to
alpha.
So
the
issue
before
is
that
when
a
pvc
is
expanded,
let's
say
if
you
let's
say:
if
you
expand
a
pvc
to
that,
was
10
gigs
and
you
expanded
to
500
gigs,
but
it
underlying
storage
provider
doesn't
support
it.
C
C
Delegate
fs
group
csi
driver
instead
of
cubelet,
went
to
alpha
so
when
the
fs
group
is
specified,
like
we
mentioned
in
the
in
skip
volume
ownership,
the
map
volume
is
recursively,
challenged,
shown
or
ch
own
or
to
modded.
So
this
allows
it
to
you.
Don't
the
kilobit
will
do
this,
but
there
are
some
storage
drivers
csi,
since
chon
and
chmod
are
unix
primitives,
so
like
you're,
so
this
allows
it
so
that
the
cube
lights
handles
it.
C
C
C
Always
on
a
reclaimed
policy
went
to
alpha,
so
this
is
when,
if
you're
familiar,
if
you
work
with
pvs
and
pvcs,
you
know
the
issue
is
that
if
the
position
of
the
perceptive
volume
is
delayed
before
the
pvc,
then
the
reclaimed
policy
is
ignored
or
associated
so
that
this
feature
and
they.
So
there
was
a
certain
order.
You
had
to
delete
it.
C
You
have
to
delete
the
pvc
first
then
delete
the
per
system
volume,
so
this
feature
make
sure
that
the
perceptible
reclaimed
policy
is
always
honored,
even
if
you
delete
the
perceived
volume
first
before
the
pvc
another.
So
this
is
staff
rbd
entry
provisioner
to
csi
driver
migration.
So
this
went
to
alpha.
This
is
part
of
that.
Continued
effort
to
migrate
entry
storage
plugins
to
csi
next
is
sig.
Testing.
Sig
testing
is
interested
in
affecting
an
effective
testing
of
kubernetes
and
automating
away
project
oil.
C
D
We've
got
sig
windows
which
deals
with
supporting
windows,
nodes
and
scheduling,
windows
containers,
and
it's
just
the
one
enhancement
for
sig
windows,
and
that
is
allowing
windows,
privilege
containers
so
extending
that
same
capability
that
exists
for
for
linux
containers
to
run
as
a
privileged
container
and
have
more
host
level
access
getting
that
working
for
for
windows
containers,
and
that
is
moving
to
beta.
With
this
release.
C
All
right
so
next,
so
that
covers
all
the
47
enhancements
in
1.23.
What's
what's
next
is
going
to
talk
about
the
release
team
shadow
program
and
the
release
team
itself
there
with
each
kubernetes
release.
There
is
three
a
year
there
is
a
release
team
for
each
release
and
that
release
team
is
made
up
of
community
members
from
all
sorts
of
different
organizations.
C
C
So
so
there
are
a
few
roles
that
had
five
shadows
for
one
and
the
goal
for
the
release
team
is
to
train
new
leads
and
for
shadows
to
become
new
leads,
as
well,
eventually
in
the
future
and
for
and
for
role
leads
to
share
the
knowledge
that
they've
had
or
to
share
their
tasks
and
knowledge
that
they've
had
through
many
released
teams
or
release
cycles.
Like
I,
myself
have
been
on
release
teams
since
1.18.
C
It
also
is
a
good
way
to
for
new
contributors
as
well
to
be
to
be
introduced
to
the
kubernetes
project
so,
and
each
release
cycle
generally
takes
about
four
months.
A
give
or
take
of
about
15
weeks.
Every
week
depends
the
workload
for
each
release.
Team
role.
Is
it
kind
of
varies
on
the
week,
and
it
also
varies
on
the
role
itself.
Like
enhancements
is
very
early
on
the
release
heavy.
C
C
C
So
every
before
every
release
cycle,
we
released
a
an
shadow
application,
so
I
do
suggest
to
join
the
the
kubernetes
slack
and
join
the
the
sig
release
channel
or
the
sig
release
mailing
lists
or
the
or
the
kubernetes
developers
mailing
list
to
get
notifications.
When
those
shadow
applications
are
out,
so
I'm
gonna
go
to
any
questions.
D
One
question
in
the
chat
about
cni
plug-ins
that
are
compatible
with
windows
based
nodes
and
I
think
I'll
just
kind
of
add
a
a
all
up
thing.
I
don't
know
specifically
on
that,
but
I
think
four
questions
on
specific
caps
that
you
want
some
more
detail
on
a
good
place
to
go
is
gonna,
be
the
sig
channel
for
that
cap
on
the
kubernetes
slack.