►
From YouTube: Day zero service mesh
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
Welcome
to
this
cnc
webinar,
my
name
is
victor
gamov
and
today
we're
going
to
spend
some
time
to
learning
about
technology.
That's
super
exciting
for
me,
and
hopefully,
you're
also
a
little
bit
excited
about
this
technology
technology
called
service
mesh.
Today's
presentation
is
about
a
zero
day
service
mesh.
What
does
it
mean?
What
you
need
to
know?
What
the
first
day
when
you're
starting
on
boarding
with
service
mesh,
I'm
gonna,
be
talking
about
the
origins
of
the
service
mesh.
A
I'm
gonna
be
talking
about
what
kind
of
problems
we're
solving
there
and
you
will
see
the
demo
and
I
will
be
talking
about
some
of
the
things
that
is
applicable
for
specific
technology.
It
used
to
be
so
simple
people
say,
oh
those
days
when
everything
was
super
simple
and
we
didn't
have
all
this
distributed
technologies.
We
didn't
have
all
these
kubernetes
schmuber
natives
and
all
these
kind
of
things.
Everything
was
much
easier.
We
have
a
one
servlet
container,
or
maybe
it
was
application
server.
A
We
pack
everything
in
one
war
file
or,
if
you
not
super
lucky,
it
was
er
file
that
will
include
all
the
components
of
this
application.
And
after
that
you
know,
you
need
to
connect
to
some
databases,
and
just
you
know,
run
with
it.
But
if
you
think
about
this,
let's
take
a
look
on
this
architecture
for
a
second
and
think
about
this,
that
this
actually
already
was
multiple
components
and
multiple
things
that
might
go
wrong
things
around
connecting
this
application
server
to
database.
A
If
many
of
you
remember
the
times
where
application
server
will
provide
you
with
some
sort
of
like
a
service
discovery
known
as
gndi
java
naming
and
directory
interface,
that
allows
you
to
calling
api
of
application
server
to
get
allocation
of
your
database
like
a
rudimentary
discovery
service.
You
can
say,
oh
give
me
my
production
database
and
after
that,
this
service
will
return.
A
New
times
have
come,
so
we
can
change
everything
and
refactor
our
systems
to
microservices,
and
this
is
the
time
where
we
need
to
reinvent
some
of
the
patterns
or
maybe
re-implement
some
of
the
code,
and
today
we're
going
to
talking
about
how
can
we
can
do
this
like
less
less
painful
and
hopefully
will
be
more
efficient?
My
name
is
victor
gamov.
Once
again,
I
am
a
developer
of
the
kid
at
kong
and
kong.
I
am
talking
to
developers
talking
about
the
things
that
we
develop
at
clonk
dealing
with
some
of
the
problems.
A
Some
of
our
users
in
the
community
have,
and
also
I
do
all
sorts
of
things
around
kind
of
educating
people
about
the
technologies
and
cloud
connectivity
and
all
things
around
apis.
I
also
do
some
of
the
live
streams
on
the
konk
youtube
channel.
If
you're
interested
in
this
type
of
jazz,
don't
hesitate
subscribe
to
that
channel
and
I
will
be
sharing
some
of
the
content
there.
A
So
when
we're
talking
about
the
microservices
revolution
or
revolution,
we
usually
like
to
remember
where
the
famous
email
from
jeff
bezos
when
he
was
talking
about
all
the
systems,
need
to
start
talking
to
each
other
through
apis.
There
is
no
should
we
know
other
integrations
points
and
which
is
was
a
good
thing.
A
But
people
still
were
doing
the
things
even
before
the
containers
right.
The
things
that
I
mentioned
at
the
very
beginning,
like
a
war
files
and
yar
files.
You
also
kind
of
sort
of
package
this
in
some
of
the
standard,
the
format.
But
it's
only
was
standard
for
certain
platforms
with
docker
docker
from
operational
complexity
or
containers
from
operational
complexity
have
solved
us.
This
idea
of
transition
to
us
from
build
ones
run
the
world
where
to
the
packaged
ones
run
over
where
and
around
2016
2017.
A
Those
ideas
that
was
promoted
by
big
tech
in
in
the
in
the
cloud
industry
or
like
web
scale
start
start
kind
of
like
a
migrate
into
the
world
of
the
normal
people,
normal
enterprises
traditionally
monolithical
systems,
because
the
companies
decide
to
go
faster
with
their
digital
approach
to
the
business
and
the
solving
the
problems
much
faster.
So
let's
get
back
to
our
my
application.
So
let
me
talk
a
little
bit
about
how
I
can
how
we
can.
A
How
can
we
talk
about
this
in
the
sense
of
the
of
the
modern
component,
so
think
about
this?
The
communication
between
databases?
You
never
deploy
database
on
the
same
server
as
your
application.
You
always
have
it
on
a
separate
thing,
and
maybe
even
separate
teams
manages
this
for
you.
It
provides
different
restrictions,
passwords
access,
control
to
those
databases,
all
these
things
not
not
running
together,
so
they
always
communicating
through
the
network.
A
So,
even
though
we're
talking
about
monolithic
application,
so
with
this
example
of
this
monolithic
application
of
this
java
ee
application
server,
the
communication
is
happening
through
ctcp
channel.
You
know
the
the
bi-directional
streaming
and
communication
is
possible
between
systems,
but
still
still
at
the
network
network
communication
can
be
unreliable,
can
be
unsecured.
A
Once
we
start
this
decoupling
of
this
monolithical
application
into
the
smaller
pieces,
those
missiles
still
needs
to
communicate
to
each
other
somehow
through
apis.
Like
give
me,
let
me
give
you
example
of
how
the
things
are
changed
from
perspective
of
how
it
was
before
when
we
have
everything
in
one
place
like,
for
example,
here
I'm
looking
into
the
interface
of
this
system,
where
one
component
talk
to
another
component
through
calling
and
do
something
method
of
this.
We
we're
replacing
replacing
communication
between
those
two
services
by
wrapping.
A
If
we
move
computation
to
the
network
now
our
network
is
our
computer,
like
one
service
will
call
another
service
through
api
through
certain
protocols,
and
it
would
also
very
similar
to
the
things
what
you've
done
in
the
past
with
you
know,
calling
interface
of
the
object
with
this
network
problem
with
the
introduct
introduction
of
the
network
communication.
We
also
start
seeing
not
the
problems,
but
the
challenges
that
you
need
to
solve.
You
need
to
solve
many
things
that
were
given
for
you
for
free,
for
example,
process.
A
Isolation
was
given
since
you're
writing
this
as
a
one
in
the
one
sandbox
and
all
the
components
needs
to
run
within
security
manager
or
whatnot,
and
if
you
want
to
do
login,
you
do
login
in
the
console
and
after
that
you
can
scrap
this
using
tools
like
grep
awk
and
some
some
other
things
or
you
can
use
like
motor
stack
and
consume
those
files
using
file,
beats
and
like
ship
it
to
elastic.
But
there
was
no
centralized
place
where
you
can
do
all
this
logging.
A
All
this
tracing
and
all
these
things
around
the
things
that
you
need
to
do
what
you
start
doing.
You
maybe
start
introducing
introducing
some
of
those
components
as
application
based
libraries.
If
you
need
to
implement
observability,
you
drop
some
of
the
library
like
java
agent
or
some
any
other
agent
that
will
listening
what
happens
in
your
system
and
ship.
This
observability
data
to
some
apm
application,
performance
monitoring
tool
and
after
that,
you
kind
of
analyze
it.
So
you
introduce
this
as
a
part
infrastructure
as
a
part
of
your
application
code.
A
So
you
start
linking
some
of
the
infrastructure
code
inside
your
application.
Sometimes
it's
good.
Sometimes
it's
bad,
but
things
getting
much
more
complex
if
you
trying
to
introduce
more
languages,
so
you
trying
to
be
more
diverse
and
hire
more
talent
regardless
of
the
platform,
and
you
want
to
build
the
services
in
the
different
languages
and
which
is
totally
fine
because
you're
now
talking
through
the
apis,
it
really
doesn't
matter
what
kind
of
implementation
language
you
use.
A
So,
with
this
mat
with
this
approach
with
this
particular
approach
now
you
need
to
make
sure
that
the
framework
that
you
use
in
one
language
gives
additional
or
like
a
similar
level
of
functionality
in
a
framework
that
you
use
in
another
language.
So
that's
another
problem
where
you
start
introducing
infrastructure
into
your
application
code.
A
So
all
these
things
becoming
the
part
of
your
application,
which
is
good
thing
you're,
trying
to
make
connection
to
application,
to
like
say,
external
data
source
resilient.
You
know
the
introduction
of
the
connections
pools
that
will
handle
retries
that
will
handle
connection,
pooling
and
reuse
of
the
connection,
maybe
logging,
all
these
other
things.
A
Those
pieces
are
part
of
your
architecture
now,
but
many
applications
might,
you
know,
fail
on
this
recovery
or
not
providing
meaningful
logs
just
simply
because
the
library
in
one
language
or
library
that
use
one
application
will
not
have
the
same
functionality.
That
has
another
one
so
we
need
to,
but
we
need
to
have
the
consistent
ways
to
look
into
our
application
performance
and
those
applications.
There
will
be
tons
of
different
applications
and
the
communication
and
the
different
functionalities
that
we
will
put
in
there
also
will
have
different
and
distinct
things.
A
I
didn't
even
started
talking
about
fragmentations
from
perspective
of
how
we
secure
those
connections.
Security
is
also
when
we
start
moving
into
the
cloud-based
environments.
The
connection
connectivity
security
is
important
dating
motion.
Security
is
important
because
you're
not
running,
not
you're,
not
running
on
your
infrastructure,
where
you
can
be
make
sure
that
everything
that
you
have
is
kind
of
like
a
super
secure
so
and
with
security
and
reliability
in
mind.
A
More
like
a
gorilla
or
like
a
hacking
approach
would
be
kind
of
introduction
of
this
like
shadow
it
element,
so
some
of
the
team
members
would
decide
to
or
some
of
the
team,
some
of
the
groups
and
applications
they
implement
the
stuff
for
themselves.
So
they
would
make
sure
that
their
system
was
not
is
not
compromised.
A
However,
they
might
need
not
for
100,
following
whatever,
whatever
like
requirements
available
in
organization,
because
those
requirements
simply
cannot
allow
them
to
move
faster,
and
this
is
going
to
be
more
human
problem
rather
than
technology
problem,
where
the
different
teams
in
different
goals
and
different
the
targets
are
competing
instead
of
building
one
thing
that
will
be
solving
one
greater
good
and
those
duplication.
Fragmentation
brings
us
to
the
point
where
what
we
will
like
to
do
with
this
due
duplication
and
fragmentation.
We
would
like
to
start
decoupling
this
thing.
So
what
about?
A
So,
let's,
let's
see
how
it
can
be
done
so
with
the
idea
of
outsourcing
or
moving
some
of
the
logic
around
error,
error,
handling,
retry
security,
login
tracing
all
these
kind
of
things
into
separate
process
and
talk
to
this
process
through
sets
of
api.
So
your
application
will
always
be
talking
to
outside
world,
not
through
the
direct
communication
to
the
service,
but
through
the
proxy.
That
will
be
also
providing
the
ways
how
you
can
do
service
discovery,
how
you
will
figure
out
where
this
data
is
and
so
far
and
so
on.
A
So,
let's
talk
a
little
bit
closely
about
this
proxy.
How
this
will
work,
so
each
service
now
will
have
its
own
small
proxy
that
the
footprint
would
be
negligible
for
comparing
two
benefits
that
this
this
proxy
provides.
So
in
this
case,
this
proxy
will
will
will
be
handling
all
communication
between
between
the
services
in
you
know
in
just
you
know,
running
a
little
bit
in
front
of
the
gun.
A
So
that's
why
we
we
have
this
name
of
the
mesh,
so
communication
not
happening
directly
between
the
services,
but
rather
the
proxy,
so
essentially
proxies
are
establish
our
communication
and
establish
our
mesh
so
and
this
this
pattern
also
works
in
in
in
your
past,
like
it
also
works
with
the
legacy
or
monolithical
application,
where
you
have
one
component
that
will
be
the
just
just
service
mesh
or
this,
the
proxy
will
be
handling
all
this
communication
between
different
components
of
the
system.
Now
so
now
we
need
to
figure
out.
A
We
we
figure
out
the
the
mechanics
between
the
traffic
management,
but
the
next
thing
that
we
need
to
figure
out
is
how
to
provide
those
configurations.
So
definitely
those
configurations
can
be.
You
need
to
deploy
this
in
a
different
environments
like
in
this
particular
case.
We
can
deploy
this
in
a
different
environment
where
we
have
only
virtual
machines
or
we
have
a
kubernetes
cluster,
or
we
have
like
bare
metal
machines,
but
definitely
some
of
the
things
around
how
these
things
will
be
handled
for
perspective
of
communicating
or
from
perspective
of
configuring.
A
The
services
needs
to
be
solved
as
well,
since
we
starting
putting
all
these
proxies
in
one
place
next
to
our
applications
and
the
number
of
applications
will
grow.
We
might
have
a
situation
where
we
cannot
go
and
configure
door
service
like
manually
or
like
having
static
configuration.
So
that's
why
we
need
to
come
up
with
some
other
approach,
and
this
is
where
another
element
of
service
mesh
comes
into
play.
Now
we
can
propagate
this.
This
communication,
those
configurations
to
each
service,
but
it's
all
about
automation.
A
We
need
to
have
a
suitable
automation
in
order
to
propagate
those
configurations.
So,
with
the
with
the
concept
of
this
of
the
service
mesh,
each
individual
component
or
each
individual
application
that
will
be
part
of
this
mesh
will
have
its
own.
We
call
it
data
plane,
so
those
proxy
also
name
as
a
data
plane,
and
there
will
be
some
config
server
that
will
be
also
connected
to
those
data
planes,
and
this
is
the
benefit
between
this,
because
we
already
established
in
a
few
slides
before
that
communication
between
the
systems
only
happens
through
this
proxy.
A
So
there
will
be
no
third
party
and
this
communication
service
will
use
some
sort
of
back
channel
to
or
configuration
service
to
we'll
be
using
some
back
channel
to
send
this
data
into
into
this
data
plane.
So
this
configuration
service,
we
will
be
calling
a
control
plane
and
our
proxy
servers
that
would
be
running
based
on
this
control.
A
Plane
will
be
called
data
planes,
so
the
control
plane
will
have
up-to-date
information
and
it
will
replicate
this
configuration
to
all
data
planes
so,
but
those
data
planes
will
continue
to
operate
in
even
in
situation
when
they
lose
control
to
control
plane
when
they
lose
the
connection
to
control
plane
and
when
the
connection
will
be
re-established,
control
plane
will
ship
a
latest
and
greatest
configuration
back
to
data
planes
and
that's
pretty
much
it
about
the
service
mesh.
This
is
how
this
pattern
works.
A
Your
application,
your
service,
your
piece
of
functionality
that
will
be
you
know,
exposing
either
to
end
user
or
to
another
service
to
consume,
will
communicate
through
network
through
data
plane.
That
will
be.
That
would
be
like
a
proxy
server
that
will
handling
traffic
and
there
will
be
somewhere
deployed
a
another
component
that
called
control
plane
that
will
be
responsible
for
shipping
the
configuration
to
all
data
planes.
A
This
is
exactly
how
it
look
like
from
perspective
of
you
know.
This
is
the
bigger
picture.
Each
service
will
have
its
own
data
plane
and
the
control
plane
will
be
running
this
configuration,
and
this.
This
configuration
also
works
at
scale
where
we
need
to
have
communication
between
different
components
that
runs
not
only
inside
one
cluster
or
like
one
data
center.
They
may
be
running
across
some
white
area
network
and
with
same
pattern,
but
like
put
this
into
like,
is
a
different
gears.
A
You
can
establish
connectivity
and
provide
transparent
and
seamless
integration
between
components
and
runs
at
one
data,
centers
or
one
region,
or
one
in
in
one
availability
zone
to
another
that
would
be
running
in
different
region
or
given
continent
or
even
different
cluster.
We
can
have
one
applications
runs
inside
the
kubernetes,
another
one
runs
on
the
bare
metal
and
the
service
mesh,
and
those
like
data
planes
will
allow
to
connect
this
and
unify
those
networks
and
unify
the
communication
between
the
systems.
A
So,
let's,
let's
start
putting
things
into
perspective,
so
we've
with
invention
of
this
very
lightweight
and
super
performant
and,
most
importantly,
api
reach.
A
system
called
own
boy-
many
it
actually
also
gives
a
huge
boost
to
development
of
many
like
service
meshes.
That
kuma,
for
example,
is
a
control
plane
that
uses
envoy
that
uses
envoy
data
planes
in
order
to
configure
and
implement
this,
the
service
mesh,
so
kuma
available
in
akuma
dot
io
you
can
find
the
documentation
there.
A
We're
going
to
talk
about
this
in
in
a
second
and
envoy
is
also
cncf
project
that
is
actively
developed,
and
it
has
a
like
very
small
footprint
that
very
negligible
comparing
to
the
benefits
that
it
provides
from
perspective
of
a
service
to
service
communication
and
from
perspective
of
things
that
available,
including
reliability
component,
including
security
component
and
including
observability
component,
all
right.
So
it's
time
to
jump
into
some
demo
and
the
demo.
Today
we
will
have
a
distributed
distributed
system,
microservices
system
and
the
e-commerce
system
as
well.
A
This
is
what
you
see
here.
It's
called
online
boutique
and
the
system
that
you
can
go
and
buy
some
stuff.
For
example,
if
I'm
interested
in
buying
salt
and
pepper
shakers,
I
can
put
multiple
items
and
add
this
to
card.
After
that,
I
can
do
either
continue
shopping
or
I
can
do
checkout
with
the
checkout.
This
is
my
address.
This
is
my
credit
card
that
I'm
using
and
after
that,
when
I
can
place
the
order,
my
order
will
be
sent
to
warehouse
for
fulfillment
and
I'll
continue
to
work.
A
So,
if
you
think
about
this,
it
can
be
one
monolithic
application,
but
actually
this
is
system
where
the
multiple
components
are
playing
nicely
together.
So,
first
of
all,
if
you
see
here,
there's
a
currency
like
I
can
switch
different
currency
and
my
system
will
immediately
immediately
will
display
all
things
in
the
current
currency,
for
example.
Here
I
want
to
use
a
japan
yen.
A
It
will
show
me
immediately
in
japan,
yen
and
it
can
show
me
in
usd
and
so
far
and
so
on.
So
this
particular
thing
is
actually
calling
external
service
that
provides
information
about
exchange
rate.
Now,
when
I
want
to
go
here
and
say,
add
to
cart,
it
will
be
handled
by
another
service
that
will
be
handling
the
persistence
of
the
card
address
lookup
and
all
these
things
also
handled
by
another
service
and
when
I
click
place
order,
it
will
send
simply
send
this
to
to
this
and
the
way
how
it
works.
A
This
application
is
deployed
using
service
mesh
and
exposed
to
outside
world
using
clone
gateway.
So
let's
take
a
look.
What
we
can
have
here
in
this
application?
So
personally
I
didn't
write
this
application
and
I
thought
it
would
be
good
example
of
what
is
possible
to
do
with
the
with
the
system
where
you
don't
have
access
to
the
code.
A
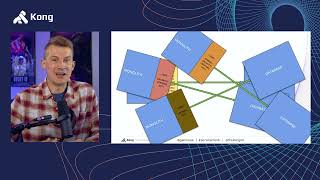
So
in
this
case
this
is
the
google
cloud
platform
microservices
boutique
system,
that
all
the
components
of
the
system
is
actually
multiple,
microservices
they're
communicating
to
each
other
through
grpc
and
all
these
things
there's
a
front-end
there's
a
mail
service,
there's
currency
service,
checkout
service,
advertisement,
service
and
so
far,
and
so
on.
So
I
decided
to
take
this
and
implement
this
with
service
mesh,
so
the
way
how
it
works.
A
Let's
start
with
the
very
beginning,
my
service
mesh
control
plane
already
deployed
inside
my
my
cluster,
I'm
using
kong
mesh,
which
is
which
is
distribution
of
kuma
mesh,
just
simply
because
it
was
handy
for
me
to
use
what
I
can
see
here
from
the
day.
One
there's
a
default
mesh
is
created
for
me.
So
all
the
things
that
I
can
see
here,
it
already
have
a
12
data
plane
proxies.
Let's
take
a
look.
What
do
we
have
here?
So
we
do
have
advertisement
service.
A
A
So,
if
I
will
tell
you
show
you
definition
for
this,
there
would
be
very
interesting
connotation
called
kuma
io
sidecar
injection
enabled.
So
what
does
it
mean
if
I
go
to
any
service,
for
example
this
ad
service,
and
I
will
see
that
this
application
will
include
two
components.
This
is
actually
my
application
code.
A
This
is
stuff
that
I
will
be
running
and
there's
two
things:
there's
a
side
card
in
init
container,
so
sidecar
container
will
be
handling
all
the
communication
for
the
service
and,
as
you
can
see
here,
it's
one
of
the
data
proxies
that
the
plane
proxies
here.
So
every
service
will
have
its
own
data
plane,
and
this
is
how
this
is
what
we
see
here
when
we
open
mesh
list
here.
A
I
do
have
a
graffana
here,
so
not
only
my
application
will
be
part
of
this
mesh,
but
also
I
can
see
how
communication
between
external
services
also
handled.
I
can
show
you
this
in
a
few
seconds.
The
kuma
is
designed
to
be
developer
friendly
and
provide
some
of
the
developer
oriented
insights
for
the
system.
So
when
the
first
time
you
run
this
default
service
without
doing
anything,
you
will
see
this
very
nice
tip
that
allows
you
to
see
how
we
can
improve
your
service.
A
So
before
we
jump
in
here,
I
can
show
you
one
quick
thing
before
before
we
enable
all
these
kind
of
things.
I
do
have
a
grafana
and
prometheus
deployed
in
my
brains,
cluster,
so
I
can
start
seeing
some
of
the
dashboards
kuma
provides
the
dashboards
that
allow
you
to
observe
things.
So,
let's
take
a
look
on
the
control
plane
and
the
control
plane.
This
is
our
process
that
will
be
responsible
for
propagating
this
configuration.
We
can
see
this
control
plane
is
up
and
running,
so
it's
alive
and
traffic
is
steady.
A
So
now
we
will
be
able
to
see
some
some
other
things
around
mesh.
So
if
I
want
to
see,
for
example,
service
to
service
communication,
I
don't
want
to
save
any
changes
from
the
previous
dashboard.
I
see
no
data
because
by
default
we're
not
capturing
any
data
between
the
systems.
Communication
between
the
components
are,
you
know
continue
to
be,
but
those
things
are
not
not
up
in
running
yet.
A
So
what
I
need
to
do
here
is
to
enable
those
communication
bits
so,
and
it
shows
what
kind
of
components
you
need
to
enable
link
to
documentation.
We
interested
in
couple
things
we're
interested
to
enable
observability,
so
we
can
see
a
communication
between
those
sources.
Let's
take
a
look
how
we
can
enable
this,
and
I
already
have
my
mesh
configuration
and
specifically
we're
going
to
be
looking
at
a
what
we
call
it
if
we
go
in
here
we're
going
into
traffic
traces.
A
So
in
this
case,
that's
the
policy
that
we
can
create
and
these
traffic
traces
will
will
be
able
to
capture
communication
between
the
services.
So,
let's
enable
this,
I
have
a
traffic
trace
and
when
the
when
you
install
kuber
in
your
kubernetes
cluster,
it
also
installs
a
bunch
of
different
custom
resource
definitions,
one
of
the
things
here
that
you
can
see
it
has
this
definition
called
mesh
and
all
the
components
that
we
will
be
configuring
today,
traffic
trays,
traffic
log.
A
All
these
things
have
a
custom
resource
definition
that
allow
you
to
focus
on
specific
area
rather
than
having
dealing
with
some
sort
of
like
a
config
maps
that
would
be
more
or
less
generic.
Now
we
can
say
the
traffic
traces
all
coming
all
communication
between
all
the
services.
Each
service
will
be
annotated
with
kuma
service.
A
Let
me
show
you
so
this
microservice
demo
and
I
have
a
kubernetes
manifest,
so
it
has
annotations
what
kind
of
protocol
it
source
and
this
service
will
be
served
by
kuma
mesh
there's
only
one
annotation
that
will
tell
kuma
what
ports
to
listen.
So
since
this
particular
service
exposes
port
955,
we
will
be
listing
this
and
report
this
to
tokuma
as
well.
So
when
I
go
here,
I
can
say
that
every
service
to
communicate
into
every
service,
all
the
data
will
go
to
jager
collection.
I
already
have
a
jager
deployed.
A
If
I
go
here
and
show
you
data
sources,
I
do
have
a
jager
deployed
for
capturing
traces.
I
have
a
loki
deployed
for
capturing
logs
from
those
systems
and
the
prometheus
also
deployed
kuma
itself.
Data
plane,
xposed
api.
That
allows
you
to
plug
it
directly
to
your
grafana.
So
information
about
service
to
service
communication
and
data
plane
can
be
retrieved
from
here
from
using
the
kuma
as
a
data
sources.
Api
data
source
now
another
thing
that
we
also
enable
is
logging.
A
So
we
need
to
know
in
order
to
kind
of
make
sense
of
the
traces
we
need
to
also
capture
logs
from
the
system.
So
we
need
to
say,
like
a
communication
from
one
source
to
another,
also
will
be
captured
through
this.
All
the
traffic
will
be
captured
by
this
policy
for
tracing.
We
do
have
a
collector
configured
and
for
metrics
we're
going
to
be
using
prometheus
collector
and
for
logging.
We
also
will
be
using
lucky
collector.
A
There's
also
ability
to
expose
this
to
there's
some
other
collector
that
allows
you
connect
this
to,
for
example,
elasticsearch.
Another
thing
that
we
will
be
enabling
is
immediate
communication
between
the
systems,
those
what
we
called
a
mtls
between
between
components,
one
of
the
things
that
you
can
see
here
in
puma
ui.
When
you're
going
into
our
view,
you
will
get
a
yeah
so
enabling
mtls.
A
So
I
want
to
go
in
here.
Just
click
kubernetes
apply
so
and
now
my
mesh
was
updated.
We
enabled
traffic
permissions
for
everything
to
everything
and
we
enabled
encryption
between
the
system.
So
when
I
go
ahead
here
and
refresh
screen,
we'll
see
that's
all
these
things
now
enabled
we
have
a
observability
is
enabled
logging
tracing.
A
Everything
is
enabled,
so
we
will
be
able
to
go
into
my
grafana,
for
example,
and
let's
see
what
do
we
have
here
from
perspective
of
observability
we're
going
here,
I'm
going
home
and
we're
going
to
service
the
service
communication,
and
now
what
we
can
do
here
we
can
say
we
have
a
end
and
goes
into
say
payment
service.
And
now,
when
I
go
here-
and
I
will
start
doing
this,
my
thing:
oh,
that's
what
happened.
So
we
what
what
just
happened!
A
I
enabled
a
mtls
between
my
elements
of
the
of
this
mesh,
but
my
gateway
that
serves
the
proxy
the
outside
world.
This
stuff
was
not
configured,
so
I
don't
have
like
the
pod
that
will
be
around
the
traffic.
The
ingress
pod
now
has
a
problems
right
so
because
it
cannot
communicate
this
and
specifically,
if
I
will
go
in
logs
and
say,
let's
go
to
corn
and
go
into
my
proxy,
so
it
will
set
like
I
will
not
be
able
to
to
go
there.
A
We're
getting
the
error
because
we
cannot
reach
upstream
servers
so
upstream
prematurely
closed
connection.
So
what
does
it
mean
so
how
we
can
fix
that
in
this
case
our
gateway
doesn't
have
access
to
our
mesh,
because
our
gateway
is
not
the
part
of
the
mesh.
How
I
can
know
that
in
the
ui
I
can
go
and
see
here.
There's
a
few
types
of
data
plane:
proxy
standard
data
plane
proxy
that
allows
communication
between
particular
service
and
there's
gateway
that
the
plane
proxy.
A
So
what
I
need
to
do
is
I
need
to
also
enable
this
and
make
my
gateway
make
my
proxy
server.
Also
part
of
this
data
plan
and
the
the
the
the
kuma
ui
provides
the
ways.
How
I
can
do
this
and
gives
me
so
we're
gonna.
Do
this
namespace
we
have
a
namespace
called
quang
and
we're
gonna
do
next,
so
it
will
generate
us
command
that
I
need
to
modify.
So
I
need
to
copy
this
command,
go
to
my
kubernetes
cluster
and
run
this
command.
So
what
we'll
do
for
nem
space
quank?
A
This
is
where
I
am
running
my
gateway.
I
also
need
to
do
sidecar
injection
and
also
I
need
to
mention
that
this
guy
needs
to
join
this
mesh.
So
what
we'll
do
we
will
bounce
the
chronic
pods?
We
also
will,
let's
take
a
look,
what's
going
to
happen
here.
So
this
is
the
init
container.
Now
my
quant
port
will
get
also
side
cars
here.
So
those
side
cars
will
be
injected
as
we
speak
right
now.
So
we
see
the
old
port
is
germinating.
New
one
is
starting
up
now,
let's
create
it.
A
We're
going
in
through
this
crash
loop
back
off
a
few
more
seconds
and
we
will
get
back
to
ready
state,
so
we
deployed
the
sidecar,
meaning
that
all
the
policy
around
mtls
also
will
be
applied
to
this
component
to
this
system
and
now
looks
like
it's
up
and
running.
So,
let's
see
if
I
will
go
into
mesh
and
there
you
see
this
gateway,
and
now
I
see
there
is
a
gateway
proxies
here,
so
gateway
data
plane.
A
A
A
It
goes
into
front-end
service,
so
front-end
service
service
that
actually
serves
all
these
things,
all
the
requests
and
makes
it
you
know
routable,
let's
generate
a
little
bit
more
traffic
to
this
system,
so
we
will
make
sure
that
this
communications
actually
works.
Just
quick
refresh
last
five
minutes.
No,
no
doesn't
doesn't
doesn't
want
me
to
show.
A
Maybe
I
require
some
some
more
data
to
collect,
but
essentially
from
this
front-end
boutique
service,
we
will
be
able
to
see
how
we
can
go
and
check
out
how
we
can
go
into
card
service,
how
we
can
go
to
advertisement
service.
So
once
again,
let
me
let
me
quickly
summarize
what
you
just
saw
here,
so
I
took
the
I
took
the
existing
application,
that's
already
available
as
containers
inside
this.
You
know
google
micro
services
demo.
I
installed
them
into
my
mesh
in
micro
brands
cluster.
Now
those
applications
are
running
inside
a
mesh.
A
I
enable
mtls
communication
between
all
the
components.
Now,
each
and
every
application
will
have
its
own
mtls
certificate
that
was
released
and
that
was
generated
by
built-in
certificate
authority.
That
is
a
part
of
control
plane.
My
gateway
also
now
is
part
of
this
of
this
overall
architecture.
So
you
can
you
can
mix
and
match
different.
You
can
bring
different
components
into
this
mesh,
not
only
your
application.
A
Whatever
you
can
put
in
the
container,
you
will
be
able
to
join
the
mesh,
and
now
my
quality
gateway
communicate
to
the
system
to
these
black
applications
through
mtls.
I
also
enabled,
by
default
like
some
of
the
traffic
traffic
permit
routes,
so
every
service
can
talk
to
each
service,
but
I
can
be
more
explicit.
A
Let
us
know
in
the
comments
or
let
us
know
in
the
q
a
section
if
you're
interested
to
learn
more
about
those
policies
in
the
future
and
we'll
definitely
get
back
to
talk
about
those
and
yeah.
That's
the
nice
nicey.
With
this
nice
ui,
we
can
like
immediately
understand
what
we're
running
here.
What
kind
of
how
we're
collecting?
Let
me
show
you
quickly
how
we
can
see
logs
here
that
allows
you
to
speed
up
your
root
cause
analysis.
A
Just
do
search
from
the
service
front
end
to
check
out,
and
I
we
can
do
all
the
things
so
one
of
the
traces
that
come
from
front-end
service
to
out
service
we'll
have
this
kind
of
like
I'm
calling
from
frontend
to
chicago,
and
I
will
be
able
to
to
retrieve
the
service
from
the
system
that
I
will
be
able
to
retrieve
logs
and
see
what
is
going
on
there.
We
see
there
was
a
call
over
http
2,
which
is
like
jrpc
and
all
these
logs
from
the
from
checkout
service
based
on
this
particular
trace.