►
From YouTube: Cloud Native Live: Improve Core to Edge Mobility and Resiliency for Cloud Native Applications
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
Every
week
we
bring
a
new
set
of
presenters,
our
presenter,
to
showcase
how
to
work
with
cloud
native
technologies,
and
they
will
build
things.
They
will
break
things
and
they
will
answer
your
questions
join
us
every
wednesday
to
watch
live
so
this
week
we
have
a
great
presenter
and
amazing
content
coming
up.
We
have
ben
morrison
here,
asked
about
ebook
to
edge
mobility
and
resiliency
for
cloud
native
applications
and
as
a
housekeeping.
A
B
B
So
real
quickly,
some
statistics
here
about
the
challenges
of
kubernetes
and
users,
moving
towards
this
cloud
native
methodology
of
kubernetes
itself.
So,
on
the
left
hand
side,
we
have
some
statistics
of
a
survey
that
was
taken
actually
all
the
way
back
in
2017
and
the
reason
why
we
show
this
is
because
the
storage
component
is
what
we
really
want
to
look
at
here
when
it
comes
to
stateless
applications,
running
on
the
edge
with
kubernetes
and
state
full
applications.
B
And
so
all
the
way
back
in
2017
users
reported
a
top
challenge.
Of
course,
their
number
one
challenge
being
security
and
caution
of
those
ransomware
malware
attacks,
but
then
also
the
concern
of
storage
itself,
those
stateful
applications
running
on
the
edge
or
in
their
kubernetes
clusters,
instead
of
just
stateless.
So
already
back
in
2017
indicating
a
trend
towards
those
stateful
applications
running
on
kubernetes
and
now
we
know,
of
course,
with
any
new
adoption
of
any
new
technology,
especially
when
it
comes
to
infrastructure
and
architecture.
B
We
always
start
off
with
those
stateless
applications
but
start
to
move
towards
stateful.
We
saw
the
same
thing
here
with
kubernetes
at
first
early
adopters
were
all
running
stateless
applications
without
any
of
that
data
actually
on
their
kubernetes
cluster
or
on
their
edge
clusters,
and
now
we're
finding
that
users
are
moving
more
towards
those
stateful
applications.
Just
sort
of
setting
setting
the
theme
for
the
conversation
today
and
so
on
the
right
hand,
side.
We
have
a
cncf
survey,
which
is
from
2020.
B
B
22
percent
were
not.
They
were
only
running
stateless,
but
we
also
found
that
12
percent
were
evaluating
stateful
applications
and
11
were
playing
to
move
towards
stateful
applications
in
the
next
12
months.
So
here
just
again
setting
the
stage
for
how
to
ensure
those
stateful
applications
are
being
appropriately
migrated
from
core
to
cluster
and
making
sure
we
have
that
resiliency
across
core
to
cluster.
In
our
migration
scenarios,.
B
On
top
of
that,
it
also
requires
a
lot
of
organization
and
management
at
a
granular
level,
of
the
applications
running
in
those
clusters
and
on
the
edge
and
so
essentially
just
getting
at
the
theme
of
the
security
and
the
granularity
that
we
need
to
make
sure
we're
managing.
When
talking
about
migrating
from
core
to
edge.
B
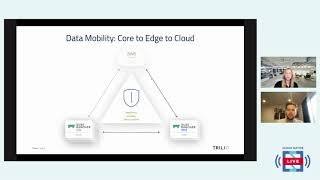
So
here,
when
we
look
at
core
to
edge
in
terms
of
how
it
comes
to
kubernetes
one
example,
we
have
here
just
there's
a
variety
of
edge
computing.
You
can
use
to
run
those
applications
at
the
edge,
but
one
example
here
would
be
a
rancher
k3s,
which
is
actually
the
edge
cluster
we're
going
to
be
using
in
a
demo.
Today,
then,
we
have
the
rancher
rke
a
core
cluster
today
for
a
demo,
we'll
actually
be
using
eks.
B
But
here
in
our
example,
we
have
rancher
and
then
the
connection
to
aws
to
the
cloud
itself,
so
just
outlining
that
architecture
of
connecting
and
migrating
that
data
from
k3s
to
core
and
connecting
it
through
the
cloud
itself
and
the
main
characteristics
again.
You
want
to
worry
about
or
be
aware
of
when
it
comes
to
this
migration
architecture
is
the
resiliency
of
those
applications,
the
mobility
of
those
applications
and
the
data
curation
at
that
granular
level.
B
So
when
it
comes
to
resiliency,
as
I
mentioned,
there
was
two
different
pieces,
the
first
one
being
security.
So
we
want
to
make
sure
we
are
aware
of
any
security
pieces,
especially
when
it
comes
to
ransomware
malware.
So
today,
we'll
be
talking
about
two
two
core
I'd
say
the
two
most
important
aspects
of
that
security
piece
when
moving
cloud
data
data
cloud
native
excuse
me
cloud
native
data
from
core
to
edge.
That
first
piece
would
be
the
immune
ability
and
the
second
very
important
piece
would
be
encryption
itself
and
then.
B
Secondly,
you
also
want
to
think
about
your
granular
application
control
when
moving
those
workloads
back
and
forth.
Of
course,
those
edge
clusters
are
usually
much
smaller
than
than
the
core
or
any
other
typical
kubernetes
cluster,
and
so
we
want
to
make
sure
that
we
have
consistent
support
from
edge
to
core.
We
also
want
to
make
sure
that
we
have
enhanced
cloud
migration
capabilities
and
then,
lastly,
have
any
granular
application
capture
to
keep
at
that
granular
level
in
mitigating
what
actually
goes
to
the
edge
and
what
does
not.
A
B
Sure
absolutely
absolutely,
and
please
feel
free
to
interrupt
me
further
any
questions
and
clarifications
like
that
as
we
go
along
as
well,
I
want
to
make
sure
everyone
is
on
the
same
page
as
we
go
through
this.
So
stateless
is
defined
as
an
application
that
does
not
store
data
on
the
kubernetes
cluster
itself.
It's
mostly
service
based.
It
does
not
store
any
cluster.
B
Any
data
in
a
persistent
volume
in
any
sort
of
way,
whereas
state
full
is
either
that
ephemeral
or
or
persistent
data
sitting
in
the
cluster
itself,
some
some
sort
of
storage
of
data
within
a
persistent
volume.
So
an
easy
way
to
think
about
this
would
be
stateful
uses
a
database.
It
uses
mysql,
mongodb
cassandra.
Any
of
the
databases
out
there.
State
lists
would
not
require
a
database
at
all.
There's
no
data
that
needs
to
be
stored
with
state
lists.
A
B
Absolutely
yep
great
question
so
moving
on
here,
the
first
piece
we're
going
to
talk
about
under
the
security
aspect
is
going
to
be
ransomware.
So,
as
many
I'm
sure
probably
know
at
this
point
as
the
conversations
of
ransomware
have
constantly
been
increasing
in
the
past
year
or
two,
especially
during
the
pandemic,
but
just
to
go
over.
The
exact
definition
of
ransomware
attacks
are
defined
as
a
cyber
security
attack,
where
a
malicious
actor
or
an
organization
gains
access
to
an
organization's
software
and
encrypts
it
and
then
holds
it
for
ransom.
B
Those
attacks
have
increased
72
percent
during
the
pandemic
itself,
and
here
especially
this
last
piece,
I
think,
is
going
to
pertain
towards
that
core
to
edge
architecture
in
terms
of
the
increased
access
to
business.
Data
over
mobile
devices
has
increased
vulnerabilities
by
50
percent,
and
that
especially,
is
relevant
for
our
core
to
edge
cases
right,
because
we
have
so
many
more
devices
out
there
on
the
edge.
B
B
Detecting
and
mitigating
would
be
detecting
any
malicious
actors,
any
malware,
any
ransomware
within
your
core
to
edge
architecture,
and
then
the
recoverability
would
be
after
an
attack
itself
has
occurred,
having
some
contingency
plan
having
some
plan
to
recover
that
data
and
not
have
to
pay
your
ransom
or
pay
the
ransom
itself
also
to
align
with
this
gardner
has
recently
come
out
with
a
report
that
you
can
look
up.
I
think
we'll
be
able
to
share
in
the
chat
or
in
the
banner
itself,
at
some
point
here
during
the
presentation.
B
You
can
also
google
it
yourself
how
to
prepare
for
ransomware
attacks,
and
here
even
gardner
you
can
see
in
the
abstract,
is
outlining
a
pre-instant
preparation
strategy.
A
strategy
you
need
to
have
to
identify,
ransomware
attacks
are
happening
that
second
piece,
the
identify
piece
and
then
that
third
piece
training
for
all
staff
for
a
post-incidence
response
and
even
scheduling
drills,
is
what
gardner
recommends
here
and
so
part
of
that
post-incident
response
would
be
something
like
recovering
your
data
using
some
sort
of
backup
recovery
solution
such
as
trulia.
B
So
getting
a
little
more
depth
into
this
cloud
native
challenge
of
ransomware
and
security
when,
when
looking
at
edge
to
core
architectures,
you
have
two
different
components
here.
Two
entries
of
attack
where,
where
you
want
to
make
sure
your
security
is
handled,
first,
would
be
the
kubernetes
management
console
itself.
B
We're
going
to
talk
about
this
here
is
a
is
a
variety
of
features
that
trilio
has
instigated,
and
I
know
many
of
the
other
backup
and
recovery
solutions
out.
There
have
some
pieces
of
these
features
themselves,
but
for
trilio
we
we
took
this
security
piece
very
very
seriously,
especially.
We
see
an
increase
of
stateful
applications
in
kubernetes
and
increase
of
use
of
cluster
core
to
edge
migration
using
kubernetes.
B
So
when,
when
talking
about
a
backup
solution
for
recovering
in
the
event
of
ransomware
attacks,
you
you
want
to
make
sure
that
you
have
the
backup,
immutability
piece,
so
not
just
immutability,
of
an
entire
target
like
an
entire
s3
bucket,
but
very
granular
immutability.
So
you
can
go
in
and
make
each
individual
backup
plan
of
each
individual
workload.
You
have
moving
across
your
core
to
edge
environment,
making
sure
that
each
individual
one
is
actually
immutable.
B
So
when
you
get
to
that
granular
level,
you
can
not
only
save
costs
because
causing
a
having
a
backup,
be
immutable,
creates
more
storage
within
an
s3
target,
and
so
you
can
minimize
your
cost
by
game
or
granular,
but
you
also
have
individual
keys
to
that
immutability.
Instead
of
an
entire
s3
bucket
being
immutable,
each
individual
backup
plan
is
immutable
and
the
same
piece
goes
for
encryption
as
well
one
you
can
get
more
granular
and
be
more
cost
effective.
B
So,
instead
of
encrypting
everything
within
an
s3
storage
target,
you
can
encrypt
down
to
the
backup
level
and
select
what
you
want
to
encrypt
and
what
you
do
not
essentially
selecting
what
is
the
most
mission
critical
data
and
which
is
not
and
then.
Secondly,
having
that
backup
level.
Encryption
means
that
you
have
a
essentially
a
different
key.
You
have
a
different
encryption
key
to
every
single
backup
itself.
So
if
a
malicious
actor
were
to
try
to
attack
these
backups
and
maybe
get
into
the
s3
target
itself,
they
find
that
each
individual
backup
is
also
encrypted.
B
B
We
truly,
we
actually
have
added
extra
functionality
in
terms
of
application,
backup
itself,
and
so
we
you
can
back
up
based
on
helm,
operator
labels
and
you
can
select
which
homes
and
operators
you
want
to
backup
within
a
certain
namespace
itself,
so
again,
getting
very,
very
granular,
I'm
sure,
especially
with
the
labels
piece.
Many
of
us
are
familiar
with
labels
and
and
keeping
them
organized
with
our
workloads
themselves,
and
so
you
want
to
make
sure
you
have
a
backup
solution
that
allows
you
to
select
individual
labels
to
get
to
that
granular
level.
B
A
B
Sure
so
the
encryption
keys
themselves
I
might
have
to
follow
up
on
the
exact
framework
we
look
at
in
terms
of
the
encryption
piece,
but
essentially
through
trilio.
What
we
do
is
we
utilize
the
s3
target
encryption
capabilities
from
there
we've
been
able
to
slice
it
down.
Essentially,
so
you
can
encrypt
at
that
backup
level,
but
the
answer
that
would
be
essentially,
it
relies
heavily
on
the
s3
target
you're
using
and
how
you
choose
to
protect
those
encryption
keys
through
that
s3
target
itself.
B
A
B
Yep
absolutely
thank
you
and
then
the
last
place
when
it
comes
to
granular
workload.
Protection
would
be
that
migration
workflow
piece
as
well
with
trilio
we've
designed
a
disaster
recovery,
slash
migration
tool
to
quickly
pull
applications
from
one
cluster
into
another
cluster,
which
would
be
that
easy
way
that
you
can
actually
perform
that
migration
itself
with
a
tool
like
trilio
you're
performing
that
migration
through
your
target
through
your
s3
bucket
or
nfs
storage.
And
so
essentially,
you
would
do
a
capture
of
a
backup
of
an
application
running
in
the
core.
B
For
example,
then
that
backup
would
be
stored
on
your
s3
or
or
nfs,
and
then
you
could
recover
it
to
your
k3s
edge
cluster,
which
is
actually
the
demo
that
we're
going
to
be
doing
today
and
so
having
that
workflow
piece,
some
sort
of
tool
where
you're
able
to
easily
have
minimal
clicks
to
restore
a
backup
from
the
core
into
k3s
is
the
format
that
you
want
to
have
in
the
demo.
Today
we're
going
to
be
showing
how
to
do
that
migration
piece.
B
B
So,
for
example,
if
the
core
cluster
and
your
edge
clusters
are
using
two
different
storage
classes,
you
can
use
a
transform
to
go
in
and
change
the
metadata
before
you
pull
that
back
up
into
the
edge
cluster
and
change
that
storage
class
itself
before
it's
restored
into
the
edge
cluster
for
inclusions
and
hooks.
Excuse
me
for
inclusions
and
exclusions.
This
help
just
helps
you
get
very
granular.
B
So
this
means
that,
once
you
do
a
backup
of
let's
say
an
entire
namespace
on
your
core
cluster,
but
you
do
not
want
to
restore
the
entire
namespace
to
your
edge
cluster.
You
can
get
very
granular
to
include
certain
components
and
exclude
certain
components
so
that
you're
really
optimizing
your
usage
of
that
edge
cluster.
As
I
said
before,
it's
going
to
be
a
significantly
smaller
size
and
you're,
probably
not
going
to
be
able
to
run
everything.
That's
on
the
court.
You
shouldn't
be
able
to
run
everything.
That's
on
the
core,
then.
B
Secondly,
here
when
we
talk
about
these
migration
features,
we
have
hooks
as
well
at
trilio.
We,
we
use
pre
and
post
hooks
for
before
and
after
a
backup
occurs,
which
allows
you
to
essentially
execute
any
command
that
you
need
to
before
and
after
that,
backup
actually
takes
place,
and
so
this
especially
gets
into
databases
and
properly
quiescent
a
database
to
make
sure
it's
in
a
capturable
state,
but
it
can
also
be
used
to
have
any
other
sort
of
system,
integration
or
automation
within
your
system
itself.
B
So
you
can
utilize
these
hooks
and
input
commands.
However,
you
wish-
and
then
our
last
piece
here,
I
believe,
is
the
last
one:
is
that
application
consistent
support,
and
so
you
want
to
make
sure
you
have
application
consistent
backups
through
those
hooks
themselves,
as
I
was
just
mentioning
that
quieting
in
the
database
in
terms
of
trilio,
our
database
support
is
very
extensive.
It's
actually
more
than
what's
listed
here.
The
these
databases
you
see
listed
here
are
just
examples
we
have
in
our
documentation.
B
If
you
want
to
take
a
look
at
what
these
hooks
would
look
like,
we
have
cassandra,
mongodb,
mysql,
mariadb,
etc.
All
these
examples
in
our
documentation,
but
the
nice
thing
about
hooks,
is
that
it's
very
easy
to
become
compatible
with
any
of
those
databases
out
there.
So
I
personally
have
rarely
ever
seen
an
issue
where
we
didn't
have
database
support
with
trilio
and
so
make
sure
that
your
backup
solution
is
compatible
with
whatever
database.
You
are
using
okay
and
I
think
we're
gonna
switch
to
our
recorded
demo
here.
B
I
I'll
pretty
much
play
this
all
the
way
through.
I'm
gonna
talk
through
the
demo
itself,
because
it's
a
chord
hedge
migration.
You
know
we
wanted
to
capture
this
beforehand
to
make
sure
everything
was
smooth,
and
so
what
we're
doing
here
is
we
are
going
to
be
migrating,
an
application,
a
wordpress
application
from
our
primary
cluster,
which
is
an
eks
cluster.
You
can
see
in
the
url
up
at
the
top
and
migrating
that
wordpress
back
up
to
our
k3s
cluster.
The
primary
cluster
is
eks.
B
As
I
mentioned,
the
k3s
cluster
is
a
rancher
cluster,
so
here
we're
looking
at
that
admin
view
we're
looking
at
the
multi-cluster
management
and
the
trilio
ui,
showing
both
of
those
clusters,
but
we're
going
to
move
to
just
the
k3s
cluster.
For
the
sake
of
this
demo,
pretty
much
simulating
what
would
be
like
to
be
a
user
with
only
permissions
to
that
k3s
cluster,
along
with
permissions
to
the
target
itself
to
grab
that
backup
and
what
that
what
that
piece
would
look
like
so
here
in
our
k3s
cluster.
B
You
can
see
again
that
url
at
the
top.
We
changed
windows
and
we
are
now
in
that
rancher
k3s
cluster.
We
can
see
some
application
discovery
in
the
middle.
This
is
essentially
just
showing
all
of
our
name
spaces
and
showing
what
is
protected
and
what
is
not
protected
on
this
cluster
so
right
now,
let's
just
switch
it
over
quickly.
There
then
we'll
go
back
here
there.
We
are
okay,
we're
back
here
at
the
k3s
cluster,
just
showing
our
namespaces
themselves
what's
protected,
what's
not
protected,
and
this
is
a
fresh
k3s
cluster.
B
B
B
B
So
here
what
we've
already
done
is
we've
done
that
back
up
from
the
core
to
the
s3
target
piece.
We
have
our
target
here,
demo
s3
target
where
that
backup
is
stored
of
our
wordpress
application
that
was
originally
in
the
core,
and
now
we're
going
to
launch
a
target
browser
so
from
this
window,
what
we're
doing
is
we
are
looking
into
the
target
browser
looking
at
that
backup
that
was
taken
from
the
core
cluster
and
then
we're
going
to
be
restoring
it
into
the
k3s
cluster
running
on
the
edge.
B
So
here
going
into
that
target
browser,
we
can
see
an
angel
beats
backup
plan,
which
is
where
this
backup
occurred
again
backing
up
that
wordpress
application
from
the
core.
Here.
Look
in
this
backup
we
can
see
our
wordpress
backup
sitting
here.
It
was
taken
some
time
ago
and
we
can
go
ahead
and
restore
that
backup
into
our
current
cluster.
The
k3s
right
from
this
window
here
so
gonna
simply
name
that
restore
restore
one
two
three
four
and
then
find
that
restore
namespace.
B
B
A
variety
of
flags
that
we
offer
just
to
get
again
very
granular
with
the
skip
already
exists,
as
you
can
imagine.
If
an
object
already
exists
on
that
k3s
cluster,
that
trilio
is
trying
to
restore
trulia,
will
know,
then
to
just
skip
that
object
entirely
to
not
have
duplicates
of
that
object
as
again
making
sure
you're
optimizing
and
being
very
conservative
with
the
space
in
the
in
the
workloads
that
you
have
running
on
your
k3s
cluster.
B
B
So
in
our
original
application,
our
wordpress
application
on
the
core
eks
cluster,
we're
using
a
storage
class
of
ebs,
sc
and
we'll
show
that,
at
the
end
of
this
video
here
as
well,
but
in
our
k3s
cluster,
we're
using
a
different
storage
class.
So
what
we
need
to
do
in
our
k3s
cluster
before
we
restore
it,
is
go
in
and
select
the
objects
we
want
to
alter
we'll.
Do
a
replace
operation
and
selecting
the
path
of
spec
storage
class
name
to
change
the
actual
name
of
the
storage
class.
B
This
application
is
going
to
use
and
then
change
that
application.
Excuse
me
change
that
name
of
the
storage
class
to
csi
host
path
sc.
So
now,
when
that
backup
is
restored,
our
wordpress
application
is
migrated
to
k3s
automatically
right
from
the
get
go.
It's
going
to
know
to
to
use
the
csi
hostpath
sc
storage
class
instead
of
the
eds
storage
class.
B
Here
we're
just
making
sure
it
was
properly
saved
and
once
that
transform
is
saved,
it
can
of
course
be
reused
over
and
over
again.
So
you
don't
have
to
worry
about
recreating
and
figuring
out
the
paths
to
change
those
storage
class
once
it's
saved
you'll,
have
it
forever
on
your
instance
of
tvk,
and
now
here
we're
just
going
to
go
back
and
monitor
that
this
restore
process
itself.
So
at
this
point,
it'll
take
about
four
minutes
for
this
restore
to
occur.
B
So
if
there
are
any
other
questions,
I
encourage
everyone
to
drop
those
in
the
chat
now,
and
we
can
have
some
open
discussion
about
some
of
what
we've
seen
so
far.
If
there
are
no
questions,
I
can
of
course
skip
ahead
since
this
is
recorded,
but
would
like
to
take
some
time
for
questions
if
need
be
so
I'll
go
ahead
and
keep
an
eye
on
a
chat.
If
anyone
wants
to
asking
those
questions.
B
B
So
that's
really
what
you
know.
Solutions
like
trilio
are
offering
here
in
terms
of
a
backup
and
migration
solution,
all
in
one
so
as
you're
backing
up
those
applications
in
the
core.
From
that
backup.
In
your
s3
or
nfs
target
storage,
you
can
restore
those
backups
into
multiple
edge
clusters
and
you
can
get
very
granular
in
how
you
restore
them
as
well.
B
B
Any
other
questions
we
have
here.
We
have
a
few
more
times
we
can
see.
We
can
see
the
target
validation
has
occurred,
we've
had
validation
of
the
backup
itself,
just
ensuring
that
is
a
healthy
backup.
It
looks
like
now
that
data
restore
process
is
occurring.
So
currently
it's
restoring
that
wordpress
application
into
our
k3s
edge
cluster.
B
A
B
B
B
B
Thank
you.
Thank
you.
So
here
we
can
see
just
fast
forward
in
a
little
bit
that
our
restore
process
is
complete,
took
about,
looks
like
six
seven
minutes
to
complete
here,
going
through
that
data,
restore
process
and
the
metadata
restore
as
well.
That's
part
of
trulia's
functionality
is
we
capture
both
the
metadata
and
the
data
itself,
because,
of
course
you
would
need
both
in
order
to
migrate
and
run
those
workloads
across
different
clusters.
B
Here
we
can
see
a
resource
summary
and
a
metadata
summary.
We
can
look
at
the
exact
metadata
and
here
we're
looking
at
our
persistent
volume
claim,
and
we
can
see
that
in
this
restore
process
we
successfully
restored
the
wordpress
application
using
csi
host
path
sc,
as
the
storage
class,
now
just
to
confirm
that
part
of
this.
B
My
excuse
me,
I
have
lost
my
speaking
there
part
of
this
restore
process,
changing
that
storage
class
itself,
we're
going
to
go
back
into
the
original
backup
plan
here,
we're
back
at
angel,
beat
plan
working.
Looking
again,
the
original
word
press
backup
that
we
pulled
this
from,
and
we
can
see
here
that
the
storage
class
is
that
ebs
sc,
so
just
showing
again
that
as
you
back
up
your
core
applications,
you
can
migrate
them
across
those
different
edge
clusters
and
still
alter
the
data
itself.
A
B
Gotcha,
okay,
that
that
definitely
clarifies
it.
Thank
you
for
that
clarification.
So,
first
off
the
in
terms
of
the
system
running
while
that
migration
and
backup
is
being
done.
What
trilio
does
is
when
it
captures
that
application
to
do
the
migration.
It
uses
csi,
snapshotting
capabilities,
to
take
a
quick
snapshot
of
that
application
itself
and
capture
the
data,
as
it
sits
at
that
nanosecond
of
the
snapshot
itself.
It
captures
the
data
as
it
sits
and
backs
that
up
to
then
be
migrated.
B
If
you
use
hooks
in
your
backup
process,
then
you
can
make
sure.
However,
you
customize
those
hooks
that
those
that
database
and
that
data
you're
capturing
is
in
an
application,
consistent
format
that
you
are
not
backing
up
data.
That's
partly
complete!
That's
partial
data
that
you're
backing
up
all
complete
data.
However,
you
need
to
have
it
quiesce
for
your
system
itself
and
then
the
later
part
of
that
question
in
terms
of
how
to
ensure
that
inflight
data
that
hasn't
been
persisted
to
destinations
makes
it
to
the
destination
source.
B
B
So
I
that
concludes
my
demo
itself
that
I
want
to
show
today.
I
think
hopefully
we
also
got
those
two
links
dropped
in
the
chat.
At
some
point,
we
had
one
link
about
a
trilio
blog
that
we
came
out
with
talking
about
edge.
Decor
excuse
me
quarter
edge
or
vice
versa,
migrations
using
trilio,
and
then
there
was
another
post
in
there,
which
was
the
gardner
report.
We
wanted
to
make
sure
we
shared
with
the
audience
as
well.
A
Yes,
and
if
not,
we
are
gonna
post
him
around
now,
so
everyone
can
get
to
the
links
and
get
started
on
learning
more
and
then
diving
deeply
into
these
really
important
topics.
Yeah,
that's
great
yeah
and
thank
you.
That
was
a
thank
you
for
the
clarification
very
wordy,
but
I
think
we're
already
is
good.
As
far
as.
A
Questions
yeah
for
sure,
and
now
thank
you
so
much
for
the
presentation
and
the
demo.
So
now
we
have
a
bit
of
time
for
the
q
a
portion
as
well,
not
that
we
haven't
gone
through
q
a
during
this
session
already,
but
now
that
we're
kicking
that
off
everyone.
Obviously
just
you
know,
keep
questions
coming
comments
and
anything
we're
super
happy
to
hear
from
you.
That's
why
we
are
here.
A
B
B
If
you
don't
get
those
workloads
on
the
edge
itself,
then
there's
not
much
to
operate
when
it
comes
to
it
operations.
So
that's
really
at
the
core
of
what
we've
been
striving
for
here
at
truly.
I
was
having
that
backup
and
then
also
the
migration
piece
as
being
as
automated
and
as
minimal
headaches
as
possible.
B
You
know
I
mean
kubernetes
has
obviously
really
grown
in
the
past
couple
years,
as
we've
seen
as
cncf
has
seen,
and
everyone
here
has
seen,
and
so
the
part
of
that
is
constantly
constantly
developing
those
new
tools
to
be
able
to
make
all
of
these
processes
such
as
migration
as
smooth
as
possible.
So
this
is
our
approach
and
I'd
be
curious
to
see
any
other
approaches
out
there
as
well.
B
You
can
not
only
you
can
not
only
backup
those
applications
using
the
same
tool,
but
you
can
migrate
those
applications
using
the
same
tool
so
there's
a
variety
of
other
backup
solutions
out
there.
This
is
the
trilio
approach
of
how
we
go
about
that
piece,
but
essentially
now
you
can
know
that
you
can
have
one
tool
to
do
both
the
migrations
and
the
backups
themselves.
A
Perfect,
that's
always
nice!
So
now
that
we
have
seen
kind
of
what's
the
current
best
practices
in
state
of
of
core
to
edge
mobility
and
resiliency,
how
do
you
see
this
space
going
growing
in
the
future?
What's
kind
of
in
the?
What
does
the
road
map
hold
for
trillio
or
what
will
the
kind
of
space
have
coming
up
in
the
future
as
well.
B
Yep,
absolutely
that's
a
great
question.
I
love
that
question
so,
as
we
saw
a
little
bit
in
the
beginning
of
our
talk
here
today,
those
industry
trends
increasing
when
it
comes
to
workloads
being
put
on
kubernetes
clusters
themselves.
As
we
all
know
you
know,
kubernetes
is
quickly
being
adopted,
a
very
rapid
and
steady
state,
and
so
I'm
sure
that
that
cord
edge
and
edge
computing
and
edge
clusters
are
going
to
be
a
huge
part
of
that.
A
B
Sure
great
question,
so
both
of
these
two
links
would
be
a
great
place
to
start.
The
first
one
is
that
gardner
report
that
I
mentioned
briefly
talking
about,
essentially
how
you
should
go
about
protecting
your
environments
in
your
especially
quarter
edge
architectures
against
any
ransomware
attacks.
So
that
would
be
a
great
place
to
start
just
to
know
it
might
not
be
the
direction.
B
You
think
that
that
needs
to
be
addressed,
but
it's
definitely
you
know
security
is
day
one,
and
so
that's
something
that
needs
to
be
addressed
immediately
when
thinking
about
your
core
to
edge
architectures
and
then.
Secondly,
you
can
start
off
with
that
blog.
That
trilio
has
posted
talking
about
using
a
tool
like
like
truly
vote
for
kubernetes
to
to
go
about
those
core
to
edge
migration,
so
that
would
be
an
excellent
place
to
start
as
well
beyond
that.
B
A
B
I
have,
I
have
nothing
else
on
my
end,
thank
you.
Everyone
for
coming
and
attending
today
talking
about
core
to
edge
mobility
and
everything
that
goes
around
core
to
edge.
I
know
it's
obviously
a
lot.
There
could
be
some
things
here
that
maybe
we're
not.
You
may
not
have
thought
of
as
being
a
top
priority
for
that
mobility
and
resiliency.
B
But
these
are
you
know
the
two
aspects
that
we
think
are
the
most
important
when
looking
at
that
mobility,
resiliency
security
and
granularity-
that's
what
it
really
comes
down
to,
and
so
from
that
I
would
say
thank
you
for
everyone.
I
don't
think
we
have
too
many
more
questions
here,
but
if
there
are
any
more,
we
can
wait
around
and
see
as
well.
A
Yeah
for
sure,
maybe
from
my
side
final
question:
if
there's
any
any
questions
being
written
here,
so
you
mentioned
helm
as
a
great
cncf
project
to
to
to
use
as
well
and
then
and
kind
of
went
deeper
into
there.
Is
there
any
other
cncf
projects,
either
sandbox
incubating
or
graduated
that
you
would
like
to
kind
of
recommend
in
this
space
or
see
as
a
good
complementary
to
work
with
him
as
well.
B
I
personally
use
them
all
the
time
and
I
think
it's
smoother
to
go
about
deploying
those
applications,
and
so
we
wanted
to
make
sure
that
you
could
migrate.
Your
actual
helm
chart
itself
along
with
the
application,
so
to
clarify
some
of
that,
I'm
not
sure.
Actually
I
covered
this
as
much
during
the
talk.
So
this
is
a
great
question
when
trilio
goes
about
capturing
a
helm
chart.
Not
only
do
we
capture
all
the
metadata
and
data
of
the
application
associated
with
that
home
chart
every
every
object
needed
to
run
an
application.
B
We
capture,
but
also
we
captured
the
helm,
chart
itself
in
all
revisions
of
the
helm
chart
itself.
So
when
you're
restoring
a
helm
chart
from
one
cluster
to
another
you're
getting
the
application
exactly
as
it
was
running
before
in
that
point
in
time
that
was
captured
and
you're.
Also
getting
all
revisions
of
that
helm
chart
itself.
So
our
compatibility
with
helm,
charts
vary
has
a
lot
of
depth
to
it,
and
we
did
that
for
a
reason,
because
we
see
a
lot
of
adoption
of
home
charts
in
kubernetes.
A
Franknell
helm
is
absolutely
wonderful.
I
always
recommend
people
to
use
it
as
well.
It's
a
great
great,
complementary
thing
for
sure,
but
yeah,
since
no
new
questions
has
popped
in,
we
did
handle
a
lot
of
questions
during
the
presentation
as
well,
so
we've
been
busy
with
the
q
a
during
and
after
here.
So
let's
I
will
start
wrapping
things
up
for
today.
A
A
We
I
have
to
say
that
I
really
love
the
interaction
with
the
questions
from
the
audience.
We
tackled
many
good
clarifications
as
well
and
as
always
tune
in
next
week
as
well,
because
we
bring
you
the
latest
cloud
native
code
every
wednesday
as
well.
There's
actually
a
final
question.
I
think
we
can
take
it
before
I
wrap
things
up
with
the
final
words.
So
is
there
a
simple
way
to
create
a
testbed
to
experiment
with
these
processes.
B
Absolutely
if
you
want
to
experiment
with
I
mean
I
can
always
speak
to
trilio
in
our
approach
to
migration.
If
you
want
to
experiment
with
trilio,
we
have
free
trials,
you
could
download
and
then
beyond
that
just
any
other
cluster,
any
cluster
that
you
have
available.
I
know
there's
a
lot
of
free
trials
out
there
to
spin
up
a
gke
cluster
or
anything,
and
they
also
have
mini
cube
as
well.
You
could
I've
I've
installed
a
mini
cube
cluster
on
my
personal
computer
itself
or
any
any
computer
that
you
have.
B
You
can
install
mini,
cube
onto
and
start
testing
out
those
migration
capabilities.
You
had
two,
of
course,
two
different
mini
cube
clusters,
so
that
would
be
my
recommendation
is
look
into
mini
cube.
Looking
at
some
free
trials
for
clusters
themselves
get
two
of
them
spun
up.
However,
you
can
and
then
get
a
tool
like
trilio
to
then
take
a
backup
and
restore
applications
across
those
clusters
to
to
test
that
migration
piece
great
question:
there.