►
From YouTube: Fluent Bit updates and Stream Processing
Description
The latest release of Fluent Bit brings some incredible performance updates, and long awaited features such as multi-workers / new crypto libraries / GeoIP and more. Additionally, we'll talk through some of Fluent Bit's SQL stream processing features that give users an easy way to route, filter, and transform data as needed.
A
We
we,
where
are
we
diving
into
the
code
behind
code
cloud
native,
I'm
paul
simoes
and
I
am
called
native
ambassador.
Every
week
we
bring
a
new
set
of
presenters
to
showcase
how
to
work
with
cloud
native
technology.
They
will
build
things
that
will
break
things.
They
will
answer
your
questions
january's
ever
wednesdays
at
3
p.m.
Et
is
a
time.
This
week
we
have
unrag
that
will
talk
about
flat,
beats,
also
join
us
and
kubecon
cloud
native
com,
con
virtual
europe
in
may
4
and
7
to
earth
the
last
from
the
cloud
native
community.
A
B
Yeah
definitely
and
I'm
happy
to
give
an
intro,
so
hey
everyone
on
iraq,
I'm
get
to
represent
the
really
awesome
fluid
bit
community.
Today,
one
of
the
main
open
source
maintainers
I've
been
primarily
focused
on
kind
of
building
out
the
features.
What
are
we
doing
next?
Getting
ready
for
kubecon
europe
and
our
fluentcon
event?
That's
co-located
with
that.
B
So
we
just
had
a
really
big
release
of
february
14
to
go
alongside
valentine's
day,
and
I
thought
I
could
talk
a
little
bit
about
for
those
who
aren't
as
aware
or
fully
enriched
in
the
fluent
community.
What
the
project
is
some
of
the
use
cases
that
we
have
some
of
the
new
features
and
then,
of
course,
a
lot
of
a
lot
of
demos.
So
we
can
walk
through
some
of
the
really
cool
stuff
that
we're
we're
trying
to
build
and,
of
course,
get
feedback
from.
You
know
this
awesome
cloud
native
community.
A
And
right,
just
before
a
little
bit,
you
start
your
presentation,
I'm
very
excited
about
this
project.
I
I
was
reading
and
study
a
little
bit
about
that
and
we
can
see
we
can.
We
can
see
that
it's
writing
in
simple
in
c.
It's
amazing
because
you
see
it's
amazing
language
and
it's
not
very
common
to
have
a
project
saying
column
native
is
community.
Writing
see,
don't
talk
to
us,
because
why
would
you
choose
c
as
the
language
for
this
project.
B
B
And
if
we
look
at
again
the
timetables,
fluid
bit
was
created
in
2015
and
the
use
case
was
not
really
for
containers
at
the
time,
but
embedded
linux,
raspberry
pi's,
whether
it's
iot
devices
and
naturally
c
is
just
so
portable.
You
know
you
have
years
and
years
of
experience
with
with
c
being
written
on
iot
devices
embedded
linux,
so
we
started
with
fluent
bit
to
say:
let's
write
it
in
c.
Let's
make
it
super
lightweight.
B
The
community
is,
is
pretty
large
for
4c,
of
course,
and
now,
when
we
look
today,
you
have
this
influx
of
go.
You
have
rust,
so
some
of
the
ways
that
we
we've
tried
to
cater
towards
that
and
make
it
easier
to
contribute
is
adding
go
plugins
with
fluidbit,
so
you
can
write
plugins
the
way
fluid
bit
works.
Is
you
have
many
sources,
many
destinations
you
can
write
those
plugins
and
go
and
and
some
exciting
stuff
that's
coming
out.
B
Is
you
have
this
large
momentum
with
webassembly
going
on
so
now
that
cloud
native
web
assembly
is
going
on
at
at
cubecon
europe
this
year?
And
you
know
we're
happy
to
be
participants
in
in
that
community
and
one
of
the
objectives
for
floatbit
is
with
c
we
can
potentially
have
web
assembly
plugins.
So.
B
Done
go
but
now
people
want
to
write
in
russ.
People
want
to
write
in
python.
They
want
to
write
in
javascript.
How
can
we
make
the
developer
community
as
broad
as
possible,
but
keep
that
lightweight
efficiency
that
is
so
useful
in
container
environments
so
useful
in
embedded,
linux
environments
and
cloud-native
environments.
A
A
B
Fluentd,
which
is
the
larger
project,
is
written
in
in
ruby,
but
you're,
absolutely
right,
there's
parts
that
are
written
in
c,
so
anything
that's
going
on
with
transformation.
We
use
c
ruby
and
that's
a
little
different
than
some
of
the
other
log
shipping
that
was
out
at
the
time
which
was
written
in
you,
know,
j,
ruby
and
java,
and
you
have
to
have
whole
jvm,
and
when
we
looked
at
that
package,
which
was
still
around
you
know
a
couple
hundred
megs
of
memory.
B
How
do
we
make
it
lightweight
for
some
of
these
embedded
environments,
where
every
mag
of
memory
counts
and
the
same
thing
might
be
true
of
containers
is
c
was
allowed
us
to
get
into
less
than
a
meg
of
memory
being
used,
residually
micro
cpus
being
used?
Is
it
was
this
so
such
a
lightweight
profile
that
it
just
made
sense
to
to
leverage
that
we
don't
have
any
environmental
piece
that
needs
to
to
come
out?
B
We
can
just
deploy
it's
a
binary,
it's
compiled,
it
goes
and
runs,
and
over
time,
of
course,
you
know
more
folks
are
adding
on
to
this
we're
seeing
more
users
that
want
to
deploy
this
and
and
essentially
replace
some
of
the
the
applications
with
this
new
lightweight
seat
project.
So
yeah
it
is,
it
is
getting
a
little
larger,
but
the
core
tradition
of
lightweightness
and
performance
is
both.
There.
A
Yeah
and
where
he
said,
the
idea
principle
idea
was
to
indebted
flint
beat
inside
the
equipments
very
any
in
in
equipment.
So
we
can.
We
can
think
that
we
can
in
the
near
future,
we
can
meet
flint
with
in
many
gadgets
that
we
works
today
in
our
house,
automation
or
enterprise
automation,
industry,
automation,
makes
sense.
This
imaginary
flint
beta
greater
project,
so
cloud
native,
open
source,
great
products
spread
in
the
world
of
automation.
It
makes
sense
this.
B
Yeah
and
some
sample
use
cases
that
we've
seen,
which
is
so
so
awesome
to
be
part
of
the
communities
to
watch.
This
is
robotics.
Folks
are
embedding
fluid
in
robotics
iot
devices,
just
like
you
mentioned
home
automation,
lights,
any
of
those
switches.
We
have
folks
that
are
doing
this
in
wind
turbines,
so
environmental
effects
and
and
power
generation
and
and
a
lot
of
the
core
competencies
that
fluentd
had
at
a
pro
as
a
project
we
brought
to
fluent
bit
around.
How
do
you
handle
network
connectivity
not
always
being
available?
B
How
do
we
buffer
data?
How
do
we
retry?
How
do
we
error,
handle
and-
and
so
the
project
itself
has
evolved,
to
make
sure
that
if
you
do
want
to
deploy
it
in
some
of
those
smaller
embedded,
linux
environments
or
containerized
environments,
we
we
have
the
packaging
and-
and
it's
able
to
do
that,
yeah.
A
B
Sure
sure,
and
of
course
I
love
to
have
the
discussion
so
and
anytime
folks
have
questions
I'll,
throw
it
in
the
chat
and
I'm
I'm
happy
to
answer
them
and
we'll
go
through
fast.
I
think
the
the
more
exciting
stuff
is
the
demos,
so
I
will
keep
the
slides
to
a
minimum.
So
for
folks
who
are
joining
and
potentially
don't
have
it
ideas
about
what
fluent
d
influent
bit
are.
Let's
talk
a
little
bit
about
it
right.
So
when
we
look
at
data.
A
B
It's
definitely
different
than
it
was
a
few
years
ago.
You
have
so
many
different
sources.
You
have
formats,
you
have
outputs,
you
have
these
challenges
with.
How
do
you
handle
things
like
network
outages
if
you're
going
to
deploy
kubernetes
on
the
edge?
How
do
you
deal
with
a
low
amount
of
file
systems,
a
low
amount
of
network
connectivity?
How
do
you
deal
with
high
volumes
of
traffic
right?
You
might
be
under
a
ddos
attack.
B
A
B
And,
of
course,
these
all
have
different
formats,
so
you'd
look
at
10
years
ago.
This
today,
there's
10
more
applications
that
are
now
mainstream.
You
look
at
the
cncf
ecosystem
right.
It's
this
enormous
amount
of
plethora
of
apps
that
each
have
a
unique
way
of
distinguishing
their
logs
and
their
application
data,
and
all
of
these
things
come
together
and
what
the
folks
at
treasure,
data,
the
original
inventors
of
the
fluentd
project
saw
was.
B
There
needs
to
be
some
way
to
collect
from
many
sources
all
across
these
different
environments
and
route
it
to
multiple
destinations,
and
so
that
was
the
birth
of
fluenty.
So
here
you
can
see
we
have
things
like
applications,
container
operating
system
security
network
logs,
sending
to
a
variety
of
locations
right.
It
might
be
things
like:
elasticsearch
kafka,
splunk,
amazon,
s3
cloud
services,
open
source
tech.
You
might
even
have
tons
of
destinations
that
are
yet
to
be
invented.
B
So
more
recent
folks,
like
like
loki
grafana's
loki,
is
another
popular
destination.
That's
growing
and
being
able
to
just
add,
plug-ins
makes
it
so
that
you
can
keep
using
all
this
logging
infrastructure
without
having
to
replace
an
agent
for
every
destination
that
you
you
might
be
running,
and
so
actually
fluent
d
turns
10
this
year.
So
this
is
pre-kubernetes
era,
even
you
have
in
in
2011
the
project
was
created.
B
B
B
So
what
are
the?
What
are
the
actual
use
cases
here?
You
know
who
cares
if
I'm
just
sending
data
from
point
a
to
point
b?
Why
would
I
want
to
use
fluent
d
in
fluid
bit
now?
I
I
tried
to
separate
this
out
into
into
five
main
reasons:
one
you
might
want
to
reduce
costs.
I
think
in
today's
age,
with
the
cloud
era,
we're
seeing
a
ton
of
egress
charges,
we're
seeing
a.
A
B
B
These
are
all
things
that
fluent
bit
does
and
has
the
capabilities
for
you
might
want
to
format
that
data
in
a
different
way.
You
may
want
to
redact
anonymize.
I
think
this
this
next
few
years
we're
seeing
privacy
continue
to
be
at
the
forefront
of
folk's,
mind
with
gdpr
california's
consumer
privacy,
act
or
ccpa,
and
you
might
want
to
redact
and
anonymize
before
you
send
it
to
a
back
end
and
then,
last
but
not
least,
I
think
this
is
just
true
of
all.
B
A
Oh
sorry,
sorry
to
interrupt
you,
you
start
to
talk
about
the
release,
the
new
release.
You
said
about
gpdr
the
radication
reduction
of
sensitive
data.
This
is
very,
very
important.
Some
days
a
big
ago,
we
had
a
a
problem
with
some
many
information
from
bank
accounts
being
braving,
and
it's
it's
a
very,
very
important,
very
important
feature
how
how
easy
is
you
is
fl?
How
is
fluent
d
works
with
this
redaction
with
this
feature?
How
is
it
is
implementing
this
feature
that
very
simple?
A
B
Yeah,
it's
a
really
good
question,
so
there's
there's
a
couple
ways
that
we
we
support
these
type
of
redactions,
the
most
obvious
is
if
it
contains
x,
remove
it.
So
if
you
find
a
credit
card
number,
you
find
a
first
name.
You
find
an
address
with
something
very
simple.
Like
regex,
you
can
just
remove
that
whole.
A
B
Message
now
that's
a
very
easy
way
to
do
some
redaction,
but
it's
not
the
most
powerful
way.
There
might
be
cases
where
you
want
to
detect
that
a
credit
card
was
found
and
you
might
want
to
be
able
to
see
all
the
other
information
that
that
log
message
has
and
so
what
what
fluentd
has
had
for
a
while
is
this
concept
of
anonymization.
B
Where
you
can
take
a
salt,
you
can
hash
the
the
entire
field
with
something
like
shot:
256,
hashing,
algorithm
and
then
all
of
a
sudden,
the
person
who
is
looking
at
that
won't
be
able
to
say.
Oh,
this
is
the
credit
card
number,
but
they'll
be
able
to
see
that
the
credit
card
existed
and
here's
the
the
additional
metadata
now.
There's
all
these
all
sorts
of
other
ways
that
you
could
do
this
type
of
redaction
and
anonymization.
B
You
could
do
things
like
take
that
data
and
say
that
okay,
the
security
team
needs
to
see
it
and
send
that
data
to
the
security
team,
while
the
remainder
of
the
fields
get
separated
out
into
another
record,
you
could
do
instead
of
doing
some
salting.
You
might
be
able
to
salt
and
hashing.
You
might
be
able
to
just
append
that
field
with
you
know
I
don't
know
warning
or
error
and
and
have
folks
be
able
to
alert
on
top
of
that.
A
B
Yeah,
thank
you
thank
you
and
so
the
newest
release
1.7.
We
released
10
days
ago.
So
it's
a
it's
a
bit
new
we've
already
had
you
know
another
upstream
version
since
then.
It's
fully
focused
on
performance,
so
what
we
saw
before
was
fluid
bit
could
handle
5,
000
6
000
events
per
second,
which
is
not
too
bad,
but
people
want
more
people,
have
tons
and
tons
of
data
and
now
we're
seeing
just
enormous
amount
of
data
being
able
to
be
processed
and
handled
with
a
single
instance
of
flipbit.
B
A
B
Be
so
we
made
changes
to
how
we
look
at
io
and
that's
for
things
like
resiliency
and
making
sure
fluid
bit
dies.
You
don't
lose
your
data
and
then,
of
course,
the
one
that
everyone
had
been
asking
for
for
so
long
is
give
us
multi
workers,
you
know,
let
us
run,
we
deploy
fluid
bit
on
a
64
core
machine.
Let
us
use
our
64
cores
and
now
we're
really
excited.
We
have
a
new
setting
within
our
output
plug-ins.
B
B
Per
second
for
a
single
process,
so
that's
really
exciting
to
us
that
we're
able
to
increase
the
performance
for
everyone
and
then
two.
If
you
have
the
scale
and
the
resources
you
can
now
use
that
worker
setting
to
maximize
that
throughput,
maximize
the
performance
and
then,
of
course,
from
a
plug-in
side.
Fluent
bit
comes
pre-packaged
with
all
its
plugins.
B
We
added
go
ip
as
well
as
http
input
and-
and
these
are
great
ways
for
folks
to
ingest
data
from
say,
server
list
functions
if
folks
want
to
enrich
their
data
with
geo
ip
data,
that's
something
that
is
now
possible,
use
a
geoip
file
alongside
and
we'll
go
ahead
and
filter
it,
and
these
join
all
the
other
plugins
we
have
as
well.
So,
if
you're
sending
data
to
say
influx
db,
you're,
sending
data
to
splunk
your
sending
data
to
datadog,
etc.
B
A
And
rug,
let's
interrupt
a
little
bit
more
yeah
one.
One
question
that
to
me,
it's
very
important
is
how
you,
how
are
you
seeing,
I
think,
about
the
stream
processing
the
future
near
future
in
the
next
five
years?
I
think
in
many
things
I
think
about
the
introduction
of
5g
networks
that
will
increase
a
lot,
the
streaming
traffic
etc.
How
can
you
see,
and-
and
how
can
flint
bit
will
help
us
in
this
subject.
B
So
a
lot
of
folks
are
looking
as
well
to
say:
can
we
enrich
these
data
streams
with
for
potentially
talking
about
how
to
solve
an
issue
that
might
arise?
Can
we
enrich
it
with
some
analysis?
Can
we
enrich
it
with
geoip
and
so
stream
processing
for
us,
as
we
think
about
the
future
of
fluent
bid,
allows
folks
to
to
do
this
in
a
way
that
they
might
be
familiar
with,
so
we
support
sql.
B
We
allow
for
predictions
and
functions.
One
of
the
not
well
known
filters
that
fluidbit
supports
is
tensorflow
right,
so
tensorflow,
great
project,
that's
being
driven
by
a
huge
community
in
itself
and
tensorflow
light
can
actually
be
used
as
a
filter.
So
we
can
have
the
model
that's
trained,
and
then
you
just
do
the
inferences
as
the
data
comes
through.
Is
this
an
error,
or
is
this
not
near
and
stream
processing
lets
us
take
those
type
of
filters.
B
It
lets
us
take
some
of
the
very
basic
math
capabilities
like
max
min
and
even
time,
series
linear
predictions
and
give
it
to
everyone
so
fluent
bit
by
the
way,
gets
gets
deployed
about
a
million
times
a
day
and
that's
been
growing
rapidly.
So
this
is,
and
actually
that's
just
from
our
docker
container
side.
We
don't
even
we're
not
even
measuring
the
full
extent,
including
the
amazon
packages,
the
ubuntu,
the
debian
red
hat,
so
that
that
scale-
and
we
think
about
how
prevalent
folks
have
this
around
their
environments.
B
We
can
just
add
sql
stream
processing
on
top,
and
it
doesn't
need
to
be
a
replacement
of
some
of
the
big
technologies
that
are
out
there
that
are
doing
stream
processing,
but
it
can
be
something
in
addition
to
that.
It
can
be
something
that
you
use
to
do
some
really
quick
checks.
Hey,
let
me
do
some
summary.
Let
me
do
some
max.
Let
me
do
some
minimum.
B
Requires
the
same
lightweight
profile
that
you
already
have
and
it's
schema-less.
So
it's
not
something
where
you
need
to
define
all
the
data
ahead
of
time.
You
take
a
file
and
you
can
run
some
stream
processing.
You
can
run
some
sql
on
top
of
that,
you
can
connect
to
some
kubernetes
logs.
Do
some
stream
processing?
B
A
B
A
B
Oh,
maybe
too,
large,
okay,
so
this
terminal,
I
I
have
flip
it
already
deployed
or
installed.
I
should
say,
and
what
we're
going
to
do
is
walk
through
a
few
examples,
so
the
first
example
is
going
to
be.
How
do
I
do
some
quick
selections
of
of
data?
How
can
I
take
say
apache?
I
have
apache
http
access
logs
and
I
want
to
select
all
of
the
http
codes
that
have
200
it's
a
very
basic,
a
simple
example,
but
to
showcase
this
let
me
first
go
ahead
and
show
the
configuration.
B
So
the
stream
files
is
what
dictates
the
actual
query
or
stream
processing
that's
going
to
occur
from
an
input
side,
I'm
going
to
be
reading
a
file,
var
log,
apache
and
anything
that
has
a
dot
log
in
that
that
path,
I'm
going
to
use
the
apache
parser.
So,
with
fluid
bit,
we
ship
a
bunch
of
parsers
out
of
the
box,
apache
nginx
syslog,
both
rfcs,
we
ship
cri,
logs
docker
logs.
So
all
those
formats
come
out
of
the
box,
a
tag
so
the
way
that
fluid
bit
routes.
Events
is
is
generally
through
its
tagging
system.
B
B
So
here
we're
going
to
redefine
a
stream
task,
rename
it
called
http
200
code,
we're
going
to
create
a
stream
we're
going
to
use
this
this
tagging
system,
so
we're
going
to
create
a
new
tag
called
http
200
and
here
you're,
going
to
see
sql
we're
going
to
do
select
star
the
entire
record
from
the
tag
apache,
where
the
code
is
equal
to
200..
So
only
events
with
the
code
200
are
going
to
show
through
when
we
run
the
stream
processing
junk.
B
B
Because
we
have
a
thousand
records
in
that
file,
but
let's
just
highlight
a
few
of
these.
So
let's
look
at
this
last
message.
So
here
we
had
a
get
method
and
we
have.
The
code
is
equal
to
200
same
thing
over
here
code
is
equal
to
200
and
so
on
and
so
forth.
So
we've
taken
all
of
the
various
codes
that
exist
within
that
http
access,
apache,
http
access
log
and
said
only
send
me,
the
ones
that
have
two
hundreds
anything
else:
400
400
500
we
don't
care
about
now-
is
that.
B
B
And
similarly,
instead
of
this
time,
sending
all
the
200s
we're
going
to
aggregate
our
404
errors.
So,
instead
of
sending
a
thousand
logs
and
selecting
from
those
thousand
logs,
we're
going
to
take
those
thousand
logs
make
some
computations
out
of
it
and
then
pump
that
out
to
our
standard
out,
and
so
this
time
I'm
using
a
different
stream
files
streams
too.
B
Okay,
so
here
we're
creating
a
new
task,
called
aggregation,
http
404,
we're
creating
a
new
stream
and
we're
going
to
select
the
count.
So
the
nice
thing
about
our
stream
processing
is,
we
include
some
functions
out
of
the
box,
so
count
max
sum
min
all
of
those
come
as
as
needed.
We're
going
to
call
it
as
total
404,
a
very
easy
to
understand,
sql
statement
where
we're
taking
this
count,
giving
it
a
name
we're
going
to
look
at
the
tag.
Apache
we're
going
to
create
a
window.
B
B
Count
now
these
are,
these
are
great
ways
to
again
do
some
computations
before
sending
to
the
back
end,
enrich
your
data
stream,
so
you
don't
even
have
to
throw
away
any
data
or
process
the
data.
You
could
enrich
every
data
stream
with
a
computation
if
you
so
choose
and
let's
go
ahead
and
look
at
another
example.
Here.
B
4.
and
what
we're
going
to
do
here
is
say
instead
of
us
telling
the
system
go
ahead
and
count
how
many
404
errors
you
have
just
give
me
a
group
by.
I
don't
know
what
codes
are
available.
I
don't
know
what's
happening,
but
just
group
everything.
So
that
way
I
can
easily
see
all
of
the
various
codes
that
I
might
have
and
the
count
of
those
codes.
B
B
B
B
So
it's
a
great
way
to
look
at
all
of
this
data.
That's
coming
in!
You
might
not
understand
how
all
of
it
is
working.
You
want
to
do
some
sort
of
computation
on
top
of
it,
you
want
to
group
it
a
little
bit
all
this
can
be
done
in
real
time
right.
So
I'm
I'm
using
a
cheat
code
of
just
taking
data
from
a
file
reading.
It
from
the
top
of
the
file
every
time,
but
absolutely
imagine
you're
tailing-
that
file
you're
tailing
kubernetes
data,
you're
tailing.
A
A
So
do
you
do
not
not
not
second
now,
but
at
the
end
of
your
presentation,
do
you
have
any
any
case
where
you
need
to
do
a
like
a
continuous
deployment
of
this
kind
of
solution
when
I
think
about
not
only
kubernetes
with
containers?
That
is
something
that
we
know,
but
something
like
distribute
this
for
many
many
dispositives
or
equipments
engages.
A
B
Yeah
really
really
good
question,
so
absolutely
folks
need
to
update
their
configuration.
We
typically
don't
see
folks
update
their
configuration.
A
lot
so
you'll
create
these
stream
processing
jobs
and
then
you'll
go
and
deploy
it
and
it
runs
the
project
runs.
It
goes
grabs
the
data
transforms
it
enriches,
etc,
and
one
of
the
one
of
the
largest
features
that
we're
working
on
this
year
is
actually
live
reload.
So
right
now
the
configuration
is
very
static,
but
fluentd,
for
example,
has
this
capability
of
saying?
Oh,
I
have
some
new
configuration.
B
Let
me
reload
without
interrupting
my
current
stream,
and
we
want
to
bring
that
to
fluid
bit
as
well.
Today.
It
is
something
where
what
folks
will
do
is
just
like
you
mentioned
continuous
deployment
and
continuous
understanding
of
how
this
is
going
to
get
rolled
into
the
new
environment
is
essential.
B
Kubernetes
can
can
assist
with
that
by
allowing
you
to
do
rollouts-
and
you
know
our
helm
chart-
has
roll
out
as
the
upgrade
way,
so
it
will
slowly
take
one
container
down
and
put
the
new
container
up
and-
and
so
this
is.
This
is
a
really
yeah
key
part
of
like
right
now,
if
you're
using
it
as
a
package
you're
installing
it
straight
on
the
os
live
reload.
Isn't
there
you're
going
to
have
to
use
the
cd
deployment
methods
that
you
already
have
kubernetes?
A
B
Yeah
yeah
we've
been
thinking
about
that
a
lot,
so
I
invite
folks
in
the
community
who
are
interested
in
this
topic.
Come
join
us
we're
we're
trying
to
find
ways
to
build
the
pipeline
of
allowing
things
like
remote
configuration
and
then
especially
when
we
look
at
fluent
bids.
You
know
if
it's
deployed
in
embedded
type
functions,
that's
going
to
be
something
where
these
these
remote
type
characteristics
are
are
really
important.
B
So
one
thing
that's
not
as
well
known
is
when
we
build
fluid
bit
for
embedded
use
cases,
we
created
a
bunch
of
input
plug-ins
for
things
like
cpu
memory,
thermal
process,
information,
disk
information,
network
information,
and
these
metrics
today
are
not
necessarily
something
that's
fully
metric
based,
they're
log
based
metrics,
but
they're
out
of
the
box,
they're
included,
and
if
you're,
using
them
or
collecting
metrics
with
flipbit.
You
can
use
the
stream
processing
to
do
some
time
series
predictions.
B
B
B
Yeah
yeah,
so
our
our
configuration
is
is
not
yaml
based
it
is.
It
is
its
own
input
filters,
outputs
today
that
you
know
that
has
been
something
else
that
we've
been
looking
at.
It's
like,
how
do
we
conform
more
and
make
it
make
things
easier,
and
so
you
know
yaml
json
config.
If,
if
folks
have
preferences
there,
you
know
we're
always
open
to
hearing
that,
but
definitely
something
we've
we've
toyed
with
in
the
past.
B
B
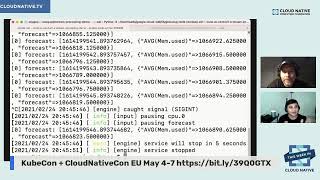
So
this
is
going
to
be
an
average
over
a
window
and
then
we're
also
using
this
other
function
called
time
series
forecast.
So
the
time
series
forecast
looks
at
the
time
that's
included
in
the
record.
It
looks
at
the
specific
field,
mem
used
memory
and
then
we're
going
to
predict
10
seconds
out
in
the
in
the
future.
It's
nothing
too
crazy.
Far
out,
but
at
least
for
the
purposes
of
this
demo,
we'll
we'll
go
for
a
10
second
forecast
and
we're
going
to
forecast
from
the
memory
stream
of
memory
records.
A
B
This
one
again,
it's
going
to
take
around
10
seconds
we're
building
up
all
these
different
memory
pieces
and
as
soon
as
that
memory
piece
is
done,
we
now
are
predicting
every
second.
What
the
next
10
seconds
look
like,
and
you
can
see
here-
it's
pretty
flat.
Nothing
too
exciting.
Here
right,
you
have
your
average
memory
used
and
you
have
your
forecasting.
B
A
B
Are
you
know
these
are
functions
that
we're
continually
building
out
the
sql
has
made
it
easier
to
pick
up
and
learn,
because
a
lot
of
folks
are
familiar
with
sql
and
it's
meant
to
complement
many
of
the
larger
stream
processing
engines
that
exist
out
there.
So
if
you
can
offload
the
the
way
I
like
to
think
about
it
is,
I
might
have
a
thousand
cores
for
doing
stream
processing,
but
if
I'm
already
deployed
across
a
thousand
distributed
nodes,
why
not
just
use
one
percent
of
cpu
on
top
of
those
thousand
distributed
cores?
B
A
A
My
experience
was
in
a
telecommunication
company
working
with
a
telco
tech,
machinist
machines,
telecommunication,
equipments
for
call
recording,
etc,
call
switching
etc.
So
was
it
you
know,
as
a
challenger
works,
with
the
current
behavior
of
all
calls
during
all
time,
24
hours
per
seven
days
was
really
really
difficult
and
this
kind
of
feature
with
time
series
with
a
capability
that
embedded
something
that
can
be
very
useful
to
get
the
the
state
the
current
state
of
this
machine
doing
their
work
around
the
the
counter
around
the
globe.
It's
amazing
congratulations.
B
B
B
A
Oh
andre,
I'm
sure
that
we'll
have
many
many
folks
are
trying
to
contribute,
try
to
participate
in
these
projects.
I
have
some
some
someone
in
my
in
my
mind,
but
can
you
show
to
us?
How
can
we,
where
is
the
your
your
community?
I
know
that
there
is
a
slack
from
flint
d
organization,
but
maybe
the
github,
and
I
will
invite
you
and
the
guys,
from
flint
b
flat
d2
to
to
return
any
other
time
to
prepare
a
hands-on,
maybe
a
hanzo,
hands-on
lab
to
contribute
for
fluently.
A
B
B
Yes,
we
have
a
couple
of
really
really
good
things
in
the
works.
The
first
is
where
we
have
a
fluidcon
event
event,
so
fluentcon
is
going
to
be
alongside
kubecon.
Europe
highly
recommend
folks
look
to
register
for
that.
We're
reviewing
sessions
right
now,
they're,
looking
pretty
excellent,
really
interesting.
A
B
The
next
bit
is
that
we're
also
looking
to
align
ourselves
with
more
of
the
ecosystem.
So
we
look
at
metrics
and
open
metrics
and
prometheus
our
standard.
Our
the
way
we
do
metrics
is
a
bit
archaic,
but
can
we
help
conform
and
and
enrich
the
the
folks
that
want
to
do
things
like
prometheus
and
open
metrics?
Open
telemetry,
of
course,
is
a
large
project.
That's
growing
a
ton
of
momentum.
B
B
So
that's
what
I
look
for
at
kubecon
europe,
and
hopefully
we'll
have
some
good
announcements
to
to
go
alongside
that
on
the
short
term,
we're
also
working
very
hard
on
multi-line,
so
the
change
from
docker
to
the
new
container
d
and
the
new
logging
formats.
We
want
to
make
sure
all
of
that
is
pleasant.
B
A
A
B
Yeah,
so
I
I
think
so
most
of
them
are
actually
public,
which
is
great,
and
some
of
the
largest
users
include
amazon,
microsoft
and
and
google.
So
if
you
look
at,
for
example,
with
google
cloud,
they
have
this
agent
called
ops
agent,
which
actually
combines
collect
d
and
fluent
bit,
and
so,
if
you're,
going
to
deploy
that
and
need
to
route
those
logs
for
windows
or
linux
that
is
used
with
flintbit
today,
you
know.
Similarly,
with
amazon
there
there's
a
lot
of
documentation
and
blogs
about
fluent
bit.
A
B
Perspective
there's
a
lot
there's
a
quite
a
few
financial
folks
that
are
routing
200k,
plus
servers
of
logs,
there's
folks
that
are
using
this
as
part
of
their
streaming
pipelines
they're
using
this
to
do
fraud,
detection
and
yeah.
There's
there's
a
lot
of
use
cases
and
I'm
hoping
if,
if
you're
watching-
and
you
have
a
good
use
case-
and
you
want
to
present
or
write
about
it-
we
you
know
we
would.
B
A
B
A
Thank
you
so
much
and
rag,
and
thanks
thanks
everyone
for
joining
us
today.
The
last
episode
of
the
week
this
week
in
cloud
native,
our
cloud
native
tv
show
it
was
a
great
to
have
you
and
rag
talk
about
flint
beats
was
amazing
project.
We
also
really
rely
really
loved
the
interaction
that
we
had
today
and
the
all
the
answers
that
we
had.
Thank
you
so
much
everyone.
We
bring
you
the
last
cloud
native
code,
every
wheelness
day
at
3pm
version
time
and
next
week,
we'll
have
other
amazing
projects
to
to
show
you
the
code.