►
From YouTube: Automation-as-policy for Platform Teams using Kyverno
Description
Don't miss out! Join us at our upcoming event: KubeCon + CloudNativeCon Europe in Amsterdam, The Netherlands from 18 - 21 April, 2023. Learn more at https://kubecon.io The conference features presentations from developers and end users of Kubernetes, Prometheus, Envoy, and all of the other CNCF-hosted projects.
A
A
So
a
brief
agenda
here.
First
of
all,
let's
cover
an
overview
of
caverno
very
quickly,
we'll
talk
about
what
is
it
for
those
that
may
not
have
heard
of
the
project?
What
does
it
do
and
then
use
cases
for
policy
management,
of
which
caverna
has
many
and
look
at
caverno
across
the
life
cycle
and
then
we'll
actually
dive
into
some
of
these
specific
use
cases
for
platform
automation
teams
by
focusing
on
four
such
use
cases?
First,
we'll
look
at
copying
and
syncing
of
config
Maps,
we'll
look
at
refreshing
environment
variables
and
pods.
A
So,
for
a
brief
overview
of
caberno
caverna
was
an
admission
controller.
That's
purpose
built
for
kubernetes.
It
is
not
a
general
purpose,
admission
controller
as
a
result
of
it
being
purpose-built
for
kubernetes
all
of
the
policies
and
resources
are
written
as
standard
yaml,
which
means
there's
no
programming.
Language
required
either
knowledge
of
a
programming,
language
or
use
of
a
programming
language
anywhere
in
the
process
of
implementing
or
reasoning
about.
A
policy.
A
Caverno
is
also
the
most
popular
by
stars
policy
engine
for
kubernetes,
and
it
boasts
many
capabilities,
several
of
which
aren't
found
in
any
other
policy
engine,
for
example,
validation,
which
is
where
most
policy
engines
begin
and
end.
Is
your
quintessential
yes
or
no
response?
Here's
a
resource,
here's
a
policy
which
matches
it
should
it
be
allowed
into
the
cluster?
Yes
or
no.
That's
validation.
Governo.
Does
that
very
simply
and
very
easily
mutation
is
the
ability
to
change
a
resource.
A
Api
server
sends
a
resource
to
an
admission
controller,
and
the
expectation
is
that
it's
either
going
to
be
modified
and
sent
back
or
it's
going
to
be
allowed
to
persist,
as
is
Governor,
has
very
rich
and
mature
mutation
capability.
That's
been
there.
Basically
out
of
the
gate.
Generation
is
a
capability.
That's
endemic
only
to
caverno,
which
is
an
ability
for
caverto
to
create
all
new
resources
in
the
cluster
based
upon
a
policy
that
you
define.
A
Caberno
can
also
verify
images,
both
image
signatures
and
attestations
on
oci
images
in
a
registry.
This
is
great
for
things
like
software
supply
chain
security,
as
you
can
have
caverno
validate
these
things
before
they're
allowed
to
run
in
a
cluster,
and
also-
and
this
is
a
new
feature-
as
of
Cabernet
1.9,
which
was
recently
released.
Cleanup
policies.
A
So
some
use
cases
for
caverno,
which
are
many
in
stretch
from
the
command
line,
which
caberno
has
as
a
separate
CLI
utility,
which
can
be
useful
as
the
ICD
pipeline
all
the
way
through
in
the
cluster.
Several
of
these
are
in
many
different
categories,
so,
for
example,
security.
This
is
your
pod
security,
making
sure
that
pods
do
not
run
as
rude
making
sure
that
they
don't
run
privileged
things
like
pod
security
standards.
Caberno.
A
Can
it
very
well
and
very
easily
enforce
granular
rbac
being
able
to
do
things
like
making
sure
that
certain
users
cannot
delete
resources,
maybe
with
a
certain
label
being
able
to
use
labels
and
and
Define
labels
on
different
types
of
workloads
to
make
sure
that
they're
properly
identified
in
the
operations
category
which
we'll
look
at
Several
of
these
today?
This
is
where
we're
kind
of
focused
on
even
things
like
secure,
self-service
provisioning
of
clusters.
A
So
if
you
look
at
this
across
the
cloud-native
life
cycle,
there's
really
something
through
all
stages.
So
in
the
commit
process
you
can
use
the
caperno
CLI
to
validate
that
the
changes
in
your
manifest
that
you're
checking
in
which
may
ultimately
be
be
deployed
in
a
git
Ops
tool
are
valid
and
correct
long
before
they
ever
hit
a
cluster.
You
can
sign
your
images
in
those
workflows
and
then
have
caverno
validate
them
again
before
they
ever
hit
a
cluster
and
then
in
the
deployment
and
running
phase.
A
But
this
really
is
prevalent
across
all
of
those
phases.
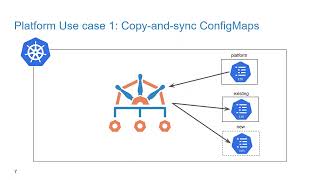
So
the
first
one,
let's
look
at
here
is
copying
and
syncing
of
config
Maps.
So
here's
the
problem,
config
Maps,
like
pods,
are
namespace
resources
for
a
pod
to
use
a
config
map.
It
must
be
co-located
in
the
same
namespace.
The
challenge,
typically,
is
you
have
a
lot
of
namespaces
and
you
may
need
to
use
one
config
map
across
a
bunch
of
different
namespaces.
A
Now
you
could
Define
that
config
map
either
multiple
times
in
your
git
Ops
tool
of
choice
or
you
could
use
other
forms
of
automation
or
imperative
declaration
to
ensure
that
you
remember
all
of
your
namespaces
and
lay
that
down.
But
what
caverno
can
do
for
us
here
with
its
generation
capability
is
allow
you
to
define
a
config
map
in
a
central
namespace.
A
Perhaps
it's
called
platform
as
we'll
show
in
this
demo
and
be
able
to
drive
that
config
map
to
both
existing
and
new
namespaces,
but
in
addition
to
that,
making
sure
that
those
config
Maps
can
all
be
kept
in
sync.
This
is
great
for
platform
teams,
because
now
it
allows
you
to
manage
resources
in
just
a
central,
namespace
and
Define
the
behavior
that
you
want
from
an
automation
perspective
as
policy
as
code
that
could
be
stored
and
deployed
alongside
all
of
your
other
resources.
A
So,
let's
flip
over
and
see
this
in
action,
so
I've
got
a
standard
config
map
here
and
it's
called
org
CA,
and
this
config
map,
as
the
key
denotes,
is
a
CA
certificate.
Now
this
is
a
certificate.
That's
from
my
lab
environment,
where
I
have
an
Enterprise
root
certificate,
Authority
and
you
may
be
doing
something
very
similar
where
you
might
have
a
certificate
that
represents
trust
across
your
Enterprise
environment
and
you
need
that
certificate
to
be
consumed
by
a
bunch
of
different
pods
and
a
bunch
of
different
locations,
maybe
even
across
clusters.
A
Although
sure
you
could
Define
that-
and
perhaps
you
are
doing
that
to
Sir
up
to
a
certain
extent
by
building
it
into
your
container
images,
maybe
you
need
to
decouple
that
for
one
reason
or
another,
in
config
maps
are
commonly
used
for
storing
certificates.
So
that's
what
we'll
do
here
and
we're
going
to
put
this
certificate
in
a
namespace
called
platform,
and
now
what
we
want
is
to
just
be
able
to
manage
this
CA.
This
config
map
in
our
Central
namespace
and
have
everything
else
be
deferred
to
coverno
as
a
policy.
A
So
in
our
policy-
and
this
is
a
standard,
coverno
policy
and
we'll
just
walk
through
it
very
quickly
converter-
has
the
ability
to
write
a
policy
that
applies
across
the
entire
cluster.
Very
simply-
and
in
this
case
this
is
a
caverno
cluster
policy,
which
means
it's
doing
just
that
it's
applying
across
the
entire
cluster
and
we
are
going
to
ask
caverno
to
generate
a
resource
for
us,
and
this
is
the
generate
type
of
rule
and
we're
going
to
generate
for
existing
namespaces
and
we're
mapping
we're
matching
on
namespaces.
A
Now,
once
we
match
on
any
namespace,
we
want
caberno
to
generate
this
resource.
For
us,
it's
going
to
be
a
config
map
also
named
org
CA,
and
the
namespace
is
going
to
be
whatever
namespace
it
matches
on,
and
it's
going
to
clone
from
an
existing
resource.
That's
out
there.
Another
variant
of
this
might
be,
rather
than
defining
an
existing
an
existing
resource.
That's
out
in
your
cluster
like
we're
doing
here.
This
could
be
defined
in
line
in
the
policy
with
a
what's
called
Data
declaration,
now
I'm
not
showing
that
here.
A
So
what
we
want
to
have
happen
is
when
we
create
this
policy
existing
namespaces,
because
we're
matching
all
namespaces
get
this
config
map
instantly
and
should
any
new
namespaces
be
created
after
this
point
in
time.
Those
new
namespaces
will
also
get
that.
So,
let's
just
try
this
out.
First
thing
we
need
to
do
is
create
the
config
map.
So
that's
what
I'll
do
and
we've
created
the
config
map
in
the
platform
namespace
and
now
we
will
create
this
cluster
policy.
A
A
And
you
can
see
here,
we
did
get
a
config
map
and
if
we
were
to
inspect
it,
we
would
find
that
it's
identical
to
the
one.
That's
in
the
platform.
Namespace
now
that's
great,
but
the
last
part
that's
missing
here
is:
we
need
to
be
able
to
create
new
namespaces,
because
this
is
a
production
cluster
and
we're
going
to
continue
to
operate
this
and
have
coverino
fire
and
manage
that
certificate
that
config
mat
for
us.
A
So
let's
create
a
new
namespace
all
right,
so
we
just
created
a
namespace
called
new
and
we
will
get
config
maps
in
this
namespace
and
we
should
see
that
caberno
has
detected
that
new
namespace
and
has
responded
by
cloning.
This
new,
this
config
map
into
this
new
namespace-
and
indeed
we
see
that
here
we
see
the
org
CA-
has
been
generated
into
this
new
namespace.
A
A
So
that's
the
first
use
case
copying
and
syncing
a
config
Maps.
Let's
move
on
here.
Let's
talk
about
the
problem
of
refreshing
environment
variables
and
pods.
So
here's
the
problem
in
kubernetes,
you
have
a
pod
that
consumes
something
like
a
config
map
or
a
secret
in
an
environment.
Variable
and
later
you
need
to
update
whatever
that
source
is
could
be.
A
config
map
could
be
a
secret,
doesn't
matter
in
this
diagram,
obviously
we're
showing
a
secret
now.
Normally,
if
you
do
that
and
you're
consuming
a
secret
as
an
environment
variable
in
a
pod.
A
After
you
update
that
secret,
the
pods
have
no
knowledge
of
the
update
that
you
just
made.
There's
no
API
that
goes
and
refreshes
that,
if
you
did
this
in
a
volume
that
would
be
another
story,
but
very
commonly
these
things
need
to
be
consumed
in
an
environment
variable,
yet
changing
that
source
does
not
affect
the
downstream
pods.
They
don't
know
anything
about
it.
A
This
is
where
platform
teams
really
can
use
caverno
to
make
their
lives
Easier
by
installing
automation,
that's
defined
as
policy
without
having
to
write
any
code
and
maybe
even
eliminate
some
other
tools
in
the
processes
in
the
process,
maybe
some
of
those
being
either
bash
scripts,
or
maybe
it's
even
handwork,
that's
done
so
any
case.
What
we
want
to
see
here
is
we
have
a
secret,
that's
being
consumed
in
a
deployment
and
obviously
that
deployment
is
spawning
pods
now
I'm,
not
showing
your
replica
set
here.
A
We
understand
that
that
is
an
intermediary
controller,
but
that
the
deployment
is
responsible
for
pods
and
those
pods
are
getting
a
secret.
Now
caverno
is
going
to
watch
that
specific
secret
for
any
changes
that
may
occur.
If
there
is
a
change.
That's
detected
perhaps
by
a
user
by
process.
It
makes
no
difference.
A
A
A
That
has
the
necessary
labels,
which
aggregate
to
the
cluster
role
that's
responsible
and
can
get
picked
up
by
the
coverno
service
account.
So
in
this
case,
I'll
just
create
an
additional
cluster
role
that
will
get
aggregated
and
it
will
grant
additional
privileges
that
allows
coverno
to
update
deployments.
A
So
I've
created
that
and
now
let's
take
a
look
at
our
original
secret,
so
I'm
going
to
create
a
secret
here,
and
this
is
an
API
token
you
can
think
of
it
as
and
here's
the
value
that
has
that's
in
the
clear
up
here.
So
0628
is
the
value
encoded
as
base64,
and
this
is
going
to
be
called
Blue
secret
and
it's
going
to
go
into
our
existing
namespace
now
I'm
going
to
label
this
with
coverno.io
watch
equals
true.
Now
this
could
be
any
label
that
you
want.
A
In
fact,
you
don't
necessarily
need
a
label,
but
for
this
demo
we
want
to
make
this
more
dynamic
in
nature,
rather
than
focusing
on
a
specific
Secret
by
name.
So
this
will
allow
coverno
to
be
able
to
watch
it
a
little
bit
more
easy
without
having
to
define
or
declare
a
specific
resource.
So
in
any
case
we're
going
to
create
this
Secret
as
the
first
step.
A
And
now
that
we've
created
blue
secret
we're
going
to
create
a
deployment,
and
now
this
deployment,
as
you
might
have
guessed,
is
going
to
consume
in
an
environment.
Variable
that
token,
and
so
it's
going
to
consume
it
in
an
environment
variable
name
token,
and
it's
going
to
fetch
it
from
that
blue
secret
that
we
just
created
in
the
key
called
token-
and
this
is
just
a
standard
busy
box
pod-
it's
going
to
sit
out
there
and
sleep
so
that
we
can.
A
A
So
you
can
see
here
it's
picking
up
our
token
environment
variable
and
we
see
the
value.
0628
is
what
I
just
showed
a
moment
ago
and
also
our
other
endpoint
environment
variable.
So
that's
all
well
and
good.
Now
we
want
to
get
caverno
in
the
picture,
because
this
is
where
it
can
really
help
us
in
our
jobs.
So
this
is
what
the
policy
is
going
to
look
like
again.
A
This
is
a
cluster
policy,
which
means
that
Cabernet
is
going
to
consider
this
across
the
entire
cluster
and
we're
telling
it
to
watch
on
secrets
that
have
this
coprino.io
watch
label
and
again
this
could
be
any
label
that
you
want.
If
you
didn't
want
to
have
a
label,
you
could
certainly
watch
by
name,
but
we
want
to
watch
by
a
label
to
make
this
a
little
bit
more
dynamic
in
nature,
because
we
may
have
multiple
secrets
that
are
consumed
across
multiple
deployments
in
multiple
namespaces.
A
It's
going
to
write
an
annotation
that
I've
just
called
corp.org
random,
with
an
eight
character
length,
random
string.
Caberno
has
the
ability
to
use
a
system
called
James
path
and
within
the
James
path
system
that
caverno
consumes.
There
are
many
filters
that
that
we
have
written
and
provided
specifically
for
caverno's
use
that
aren't
found
in
Upstream
James
path,
and
one
of
these
allows
you
to
very
simply
generate
a
random
string
based
upon
a
composition
of
your
design,
and
so
you
can
see
here
with
this
regex
I'm.
Just
saying
give
me
a
string.
A
A
Is
it's
going
to
cause
the
deployment
controller,
to
see
that
change
and
understand
that
the
actual
State
now
has
diverged
from
the
desired
State
and
in
response
it's
going
to
create
a
new
rollout
which
is
going
to
give
us
new
pods
and
those
new
pods
should
be
able
to
fetch
this
updated
secret.
So
let's
go
ahead
and
create
this
cluster
policy
in
our
cluster,
and
now
that
we've
done
that
now
we
want
to
change
the
secret.
So
we've
already
got
pods
that
are
out
there
running
now.
A
We
need
to
rotate
our
API
token,
and
you
can
see
above
here,
I've
already
generated
the
new
base64
for
this,
and
the
new
value
of
our
API
token
is
going
to
end
in
5
echo2.
So
what
we
expect
to
have
happen-
and
this
is
the
same
representation
as
the
original
secret.
It's
just
we're
modifying
the
value
here.
A
A
And
now
that
we've
done
that,
let's
go
back
to
our
existing
namespace
and
do
a
watch
on
pods
and
okay.
As
we
see
here,
we've
got
a
new
pod
that
has
a
four
seconds
ago
is
being
spawned
and
this
one
is
going
into
a
terminating
state.
So
this
is
the
new
rollout,
that's
taken
place
and
it's
going
to
tear
down
the
old
one.
So
we
should
be
able
to
get
the
environment
variables
in
this
pod
and
hopefully,
with
luck.
A
And,
as
you
can
see
here
in
fact
that
has
occurred,
the
new
value
of
the
token
environment
variable
is
zero.
Five
Echo,
two
zero
five
Echo,
two
that
corresponds
to
our
new
value.
So
you
can
see
in
this
case
there's
some
really
Nifty
capabilities
that
you
can
use
as
a
clustered
operator
or,
if
you're,
in
a
platform
team
already.
A
This
can
really
save
you
time
and
help
alleviate
some
of
the
challenges
that
you
might
be
faced
with
today,
or,
if
that's
not
a
challenge,
this
can
give
you
some
new
ability
that
you
didn't
have
today.
In
any
case,
this
is
an
illustration
of
caberno's
mutation
capability,
but
its
ability
to
mutate
existing
resources,
not
just
it
resources
that
come
in
on
the
admission
chain.
A
A
The
next
one
here
cleaning
up
bear
pods.
This
is
a
new
capability
that
we
released
in
covering
a
1.9
which
gives
caverno
the
ability
to
delete
resources
clean
them
up
based
upon
another
governo
policy
that
you
install,
so
caverna
has
long
had
the
ability
to
validate
butate
and
even
generate,
as
we
saw
in
the
first
use
case,
but
what
we
heard
was
there's
still
gaps
that
need
to
be
addressed
when
it
comes
to
a
lot
of
these
especially
platform
and
automation.
Use
cases
that
something
like
being
able
to
move
remove
resources
would
nicely
complement.
A
So
we
came
up
with
this
ability
for
it
to
remove
resources
based
upon
a
new
cluster
cleanup
policy
or
a
cleanup
policy.
So
here's
a
challenge,
then
this
use
case
that
this
solves
very
often
when
you're
operating
a
cluster.
We
all
run
into
problems
during
the
course
of
operation,
no
matter
how
much
you
automate,
no
matter
what
you're
doing
in
git
Ops,
there
are
always
cases
where
a
human
needs
to
get
involved
and
jump
into
a
cluster
and
do
some
troubleshooting.
A
Now
this
could
be
doing
things
like
Ping
check,
name
resolution
curling
to
another
pod,
just
to
make
sure
that
either
the
network
is
good
or
you
have
services
that
are
up
and
running.
But,
as
commonly
happens,
we
tend
to
forget
about
some
of
these
things.
Once
the
job
is
done,
we
put
down
our
tool
tools
and
we
go
home
so
bear
pods
are
oftentimes
used
for
this
type
of
break
glass
or
troubleshooting
scenario,
and
the
word
bear
pod
refers
to
a
pod:
that's
not
owned
by
a
high
level,
a
higher
level
controller
like
a
deployment.
A
A
bear
pod
is
oftentimes,
created
imperatively,
using
something
like
a
cube:
control,
create
or
cube
control,
run
command,
and
once
those
pods
have
done
their
job
and
users
and
operators
have
execed
into
them
or
done
whatever
they
need
to
do.
They
might
still
be
running
out
there
and
in
cases
where
you
might
be
running
kubernetes
in
a
public
Cloud
environment,
this
can
incur
additional
costs
because
you
multiply
this
by
multiple
teams
in
multiple
namespaces.
It's
not
uncommon
to
see.
A
Maybe
many
of
these
pods
that
are
running
out
there
and
that
could
become
fairly
cumbersome
and
introduce
a
lot
of
clutter.
So
what
we
could
do
is
use
caverno
to
help
us
solve
this
by
scouring
the
cluster
and
finding
these
bare
pods
and
if
they
exist,
deleting
them,
and
it
can
do
this
on
a
scheduled
basis
rather
than
just
running
an
imperative
command
one
time.
A
So
that's
what
we'll
show
here:
we've
got
a
bunch
of
different
name
spaces
with
these
bear
pods
and
we're
going
to
create
a
new
cluster
cleanup
policy
which
will
look
across
the
cluster
and
find
all
of
these
bear
pods
across
these
namespaces,
and
it
will
remove
these
for
us.
So,
let's
flip
over
and
show
this.
A
So
similar
to
what
I
talked
about
in
the
second
demo,
we
need
to
Grant
coverno
a
little
bit
more
privileges.
Here,
specifically,
we
need
the
ability
for
it
to
remove
pods
and
it's
necessary
for
us
to
list
and
delete
these
and
you'll
notice
again
here
we're
not
having
to
modify
one
of
the
main
or
the
main
cholesterol.
We
have
role
aggregation.
That's
enabled
you
can
create
a
simple
cluster
role
like
this
and
as
long
as
the
labels
are
installed,
it
will
get
aggregated
to
the
base.
A
A
We've
done
that
and
now,
let's
create
some
bear
pods.
So
you've
noticed
here,
I
like
to
use
BusyBox
as
a
very
simple
container,
to
illustrate
a
number
of
things,
and
we've
got
a
number
of
busy
box
pod
that
are
just
going
to
go
into
another
sleep
State
across
a
bunch
of
different
namespaces,
so
our
ing
namespace,
our
platform
namespace
and
our
existing
namespace
we're
just
going
to
simulate
some
bear
pods
now,
you've
noticed
here.
These
are
just
your
standard.
Bear
pods
they're
not
owned
by
a
deployment,
and
so
let's
go
ahead
and
create
these.
A
And
we
have
some
bear
pods
that
are
now
out
there
running
now.
Let's
take
a
look
at
the
new
cluster
cleanup
policy
that
comes
with
caverno
1.9,
so
in
this
cluster
cleanup
policy,
this
is
a
new
custom
resource.
You
notice
the
previous
ones
were
cluster
policies.
Well,
we've
introduced
a
cluster
cleanup
policy
which
is
similar
to
other
caverno
policies.
A
You
can
do
with
simple
paradigms
like
this,
so
we
want
to
be
able
to
use
those
same
constructs
and
policy,
and
so
we're
just
matching
on
pods
and
also
we're
going
to
look
into
those
pods
and
now.
What
we're
doing
here
is
we're
looking
at
the
owner,
references
key
and
the
owner
references
object.
That's
in
a
pod
is
where
a
pod
would
declare
another
ownership.
A
So,
for
example,
if
you
had
a
deployment
that
was
spawning
pods,
those
pods
would
have
an
owner
reference
back
to
a
replica
set,
for
example,
and
these
could
be
owned
by
something
else
or
even
multiple,
potentially,
but
we're
we're
specifically
looking
for
pods
and
Target
refers
to
all
of
the
existing
pods
that
are
found
out
there,
not
new
pods
that
are
coming
in.
It's
only
looking
at
the
existing
ones.
A
It's
returning
all
the
ones
that
have
empty
owner
references,
because
those
are
the
only
ones
that
we're
interested
in
and
then
our
schedule
here,
which
is
a
common
cron
format.
We're
going
to
run
this
every
minute.
Now,
I'm
only
doing
this
for
the
purposes
of
this
demo.
This
is
probably
not
something
that
you
want
to
do
in
a
live
environment,
but
in
the
interest
of
time,
I
will
go
ahead
and
create
this,
and
what
we
expect
to
have
happen
is
from
the
moment
that
I
create
this
it'll
start
its
countdown.
A
So
let's
create
this
and
see
if
it
actually
does
that
so
I
have
created
our
clean,
naked,
pods
cluster,
cleanup
policy,
and
so
let's
go
and
look
at
these
bear
pods
and
I've
assigned
a
label
to
them
for
easier
tracking.
So
let's
get
pods
across
all
the
namespaces
that
have
run
busy
box
associated
with
them
and
we
will
watch
them
and
since
these
are
all
in
a
running
State,
these
have
done
their
job
admirably.
They're
no
longer
needed
yet
they're
still
sitting
out
there
and
running
so
once
the
schedule
has
elapsed.
A
Proveno
should
be
able
to
find
just
these
pods,
but
not
any
other
pods,
because
these
are
the
only
ones
that
are
bare
and
it
should
call
out
to
the
cleanup
controller
and
have
it
remove
them.
So
what
we
expect
to
see
is,
which
is
what
we're
just
now
seeing.
Is
these
pods
go
into
terminating
State,
because
Governor
has
ordered
their
deletion
and
once
this
termination
State
finishes,
these
pods
will
be
removed
from
the
cluster
and,
if
we
check
again,
then
they're
still
in
terminating
state,
but
in
just
a
moment
here
once
those
processes
exit.
A
A
So
hopefully
this
was
a
a
an
enlightening
use
case
on
how
you
can
maybe
operationalize
these
types
of
cleanup
policies.
So,
let's
look
at
the
last
use
case
here
last
platform.
Use
case
here
is
scale
deployments
to
zero.
Now
this
isn't
really
about
things
like
event:
Driven
Auto
scaling.
This
is
more
about
from
an
operator's
perspective.
You
getting
automated
help
that
you
need
to
be
able
to
know
what
to
do
next
or
just
to
assist
in
some
of
your
day-to-day
jobs.
So
here's
a
common
problem.
A
You
have
a
deployment,
that's
managing
pods
and
something
happens
in
those
pods
continually
restart.
They
go
into
crash
loop
back
off
and,
as
you
probably
know,
caverna
is
going
to
continue
to
try
and
restart
those
on
a
periodic
basis.
Very
often,
though,
depending
on
the
problem
that
happens,
no
amount
of
restart
could
be
potentially
useful.
A
What
we
can
do
is
help
use
caverno
to
help
us
identify
those,
and
if
that
situation
is
happening
on
a
threshold
which
may
be
too
much,
we
can
have
coverto
scale
that
deployment
down
to
zero
and
also
tell
us
about
it
in
some
way,
marking
that
we
need
to
do
some
additional
troubleshooting.
But
the
reason
why
this
is
especially
helpful
is
that
it
doesn't
create
that
additional
pod
churn
and
if
this
is
happening
across
multiple
deployments
in
a
cluster,
that
pod
churn
could
be
fairly
significant.
A
So
if
this
is
happening,
if
this
restart
process
is
happening
too
much
caverno
can
observe
that
and
that's
exactly
what
we're
going
to
show
here.
So
we've
got
a
deployment
that
is
spawning
one
or
multiple
pods,
and
something
happens
in
that
pod.
There's
a
problem-
and
it's
restarting
and
in
this
case
I'm
just
going
to
set
the
threshold,
the
three
you
can
imagine
this
could
be
anything
but
the
Pod
if
it
restarts
any
more
than
three
times.
We
know
that
something's
gone
wrong
with
it.
Further
restarts
aren't
going
to
help
it.
A
We
need
coverno
to
help
us
out
here
so
that
we
can
take
action
on
a
later
date,
so
caverno
is
going
to
be
deployed
and
it's
going
to
observe
that
event
happening
and
when
that
happens,
it
is
going
to
scale
that
deployment
down
to
zero
and
also
annotate
it
so
that
we
know
from
a
platform
perspective,
and
we
might
pick
this
up
in
our
monitoring
tools-
hey.
This
is
now
with
zero
replicas,
it's
because
Something's
Happened,
let's
take
a
look
at
it.
So,
let's
flip
over
and
do
that.
A
Let's
take
a
look
at
this
now
again,
we
need
to
Grant
Governor
some
of
those
additional
privilege
that
I
mentioned,
because
just
like
in
the
Second
Use
case,
we
need
to
update
deployments
so
since
I've
removed
those
previous
resources,
I
need
to
put
that
cluster
role
back
in
place
and
again
same
thing
with
role
aggregation.
That's
what
we're
doing
here
so
we've,
given
it
those
permissions
and
now
I'm,
going
to
create
a
deployment
and
back
to
our
Ye
Old
busy
box.
This
time
it's
going
to
sleep
for
10
seconds.
A
So
it's
just
going
to
sit
out
there
and
run
and
we're
calling
it
distressed
busy
box,
it's
going
to
sleep
and
then,
after
10
seconds,
it's
going
to
restart,
and
so
here's
our
governor
policy.
Now
this
is
a
little
bit
more
involved.
So
I
won't
walk
through
all
of
this,
but
this
is
just
an
illustration
of
some
of
the
power
that's
capable
of
in
caberno
and,
as
you
can
see,
there's
no
programming
language.
That's
involved
here.
A
If
you're
familiar
with
things
like
variables
and
as
we
showed
with
previous
policies,
some
of
the
existing
constructs
and
patterns
with
which
you're
likely
using
today,
then
you
can
probably
parse
this
so
we'll
just
a
couple
things
to
to
point
out
here:
Governor
has
the
ability
to
look
at
sub
resources.
So
we
are
looking
at
the
status
sub
resource
in
a
pod.
We
are
checking
for
updates
to
it
and
here's
where
we're
going
to
Define
our
update
count.
We
want
to
see
any
restarts
anything,
that's
greater
than
two
is
going
to
trigger
this
policy.
A
Now
a
pod
is
going
to
Define
an
owner
as
a
replica
set
in
the
case
of
a
deployment,
and
we
need
to
be
able
to
identify
the
deployment
so
we're
going
to
use
what
are
called
context
variables
in
order
to
ask
the
API
server
to
build
that
chain
back
up
to
the
parent.
So
we're
going
to
find
the
replica
set
name
and
then
we're
going
to
ask
the
API
server.
Hey,
give
me
the
deployment
that
corresponds
to
that
replica.
Set
name,
that'll,
give
us
the
deployment
and
then
from
there
and
that
started
deployment.
A
We
will
be
able
to
once
again
mutate
existing
deployments,
not
new
deployments,
because
we
already
have
a
deployment.
That's
that's
out
there
in
running.
We
will
mutate
any
existing
deployment
that
is
met
by
this,
and
we
are
going
to
put
the
replica
count
to
zero
and
we're
going
to
write
our
sre.corp.org
troubleshooting
needed
annotation
set
to
True,
which
will
allow
us
to
pick
this
up
in
a
monitoring
tool
or
some
sort
of
reporting
tool
that
we
might
be
using
to
identify
hey.
A
A
And
now
that
that's
in
place,
let's
create
the
deployment
which
is
going
to
sit
out
there
and
run
a
busy
box
container
in
a
deployment
and
it's
going
to
sleep
and
therefore
restart
every
10
minutes
every
10
seconds.
So
what
we
expect
to
have
happen
and
I'm
just
going
to
watch
the
deployment
here,
we're
going
to
watch
the
deployment
we've
currently
got
one
replica
and
now
what
we
expect
to
have
happen.
A
So,
let's
just
watch
for
a
moment
here
more
as
you
can
see
the
oscillation
between
one
of
one
and
zero
of
one
represents
those
pod
restarts
when
our
sleep
period
of
10
seconds
has
ended,
and
so
therefore
cubelet's
going
to
attempt
to
restart
that
and
give
us
another
sleep
for
10
seconds.
But
it's
just
going
to
do
this
over
and
over
again
and
on
the
next
one.
Once
this
occurs,
it's
going
to
observe
that
and,
as
you
can
see,
that's
just
happened
here.
A
It's
now
set
the
the
number
of
replicas
to
zero,
so
there
should
not
be
any
pods
that
remain
from
this
because
it
scaled
it
to
zero.
Let's
just
check
it
could
be
in
the
process
of
terminating
them
and
it's
not
it
scaled
them
to
zero.
Now,
let's
just
check
one
last
time,
let's
take
a
look
at
the
distress
busy
box
deployment
and
see
that
we
actually
got
what
we
expected.
A
And
so,
let's
scroll
up
here
and
as
we
can
see,
we
got
replica
count
of
zero
and
we
got
our
annotation
informing
us
that
somebody
needs
to
get
in
here
and
do
some
troubleshooting.
All
of
this
happened
in
an
automated
fashion
that
you
define
as
policy
without
having
any
code.
That's
defined
in
there
and
caverna
was
able
to
take
care
of
this
so
with
that.
A
That
is
the
end
of
the
demo
and
the
end
of
this
recording
I
hope
this
has
been
useful
and
how
you
can
use
caverno
to
help
you
in
your
platform,
engineering
jobs
and
save
some
trouble
and
also
maybe
make
your
lives
a
little
bit
easier.
Maybe
eliminate
some
tools
and
all
of
these
capabilities
can
be
combined
in
a
lot
of
really
interesting
ways
so
that
you
can
get
even
larger,
more
complex
use
cases
out
of
this
thanks
for
attending,
and
please
hit
me
up
if
I
can
help
you
out
thanks
very
much.