►
From YouTube: Cloud Native Chaos Engineering Preview With LitmusChaos
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
A
Here
is
a
agenda
we'll
first
look
at
why
and
what
are
chaos,
engineering
and
its
relevance
to
cloud
native
and
I'll
also
talk
about
how
chaos
generally
matures
in
an
organization
that
practices
around
devops,
then
I'll
delve
a
little
bit
into
the
introduction
of
nitmus?
It's
features
use
cases
there
have
been
a
lot
of
learnings
about
how
litmus
is
used
by
community
and
enterprises.
A
A
A
There
is
a
subsection
of
devops
that
we
are
calling
as
cloud
native
devops,
which
is
a
little
different
than
the
traditional
devops,
in
that
it's
faster.
The
deliveries
happen
in
a
more
automated
way,
the
new
set
of
tools
that
are
happening,
the
automation
of
applying
the
configuration
upgrades
overall
delivery.
A
A
A
Micro
services
are
generally
built
with
redundancy
as
a
goal
right
and
even
with
that,
we
are
seeing
outages
happening
right,
and
this
is
because
how
much
ever
you
build
carefully?
There
is
always
new
thing
that
fails
and
you
have
not
taken
care
of
that
corner
case.
So
outages
will
still
happen
and
that's
why
it's
it's
a
matter
of
how
many
nines
in
the
reliability
do
you
have
99.999
or
one
more
nine
to
this
percentage
of
reliability
right
so
there
are.
A
There
are
general
metrics
that
have
evolved
over
a
period
of
time
when
you
talk
about
reliability,
mean
time
to
fail.
How
often
you
fail,
so
the
distance
has
to
be
bigger
and
bigger
between
the
values
and
even
when
they
fail
how
fast
you
recover
right,
so
the
service
downtime
can
be
reduced
when
there
is
a
service
outage
right.
So
this
is
the
context
of
reliability
with
respect
to
the
the
business
you
know
and
its
reputation.
A
So
there
is
a
need
to
increase
the
reliability
or
reduce
the
downtime.
And
how
do
you
do
that
right
and
we
have
seen
devops
continuously
focusing
on
you
know
various
degrees
of
testing
various
types
of
testing,
including
functional
system,
load,
value,
testing,
right,
a
well
architected
system
with
a
good
qa,
provides
a
good
reliability
or
less
outages,
but
there
is
a
limit
to
which
all
these
types
of
testing
can
guarantee
the
quality
or
reliability
of
a
product
or
service
right.
A
So
the
next
option
or
innovation
in
increasing
the
reliability
or
resilience
of
a
service,
is
to
introduce
chaos,
testing
or
to
practice
chaos,
engineering.
And
what
is
chaos?
Engineering
right?
It's
in
simple
terms.
It
is
introducing
false
on
purpose
and
observing
the
system.
You
know,
if
a
fault
can
happen,
it
will
happen.
So
why
not
do
it
right
away
right?
So
you
want
to
be
able
to
increase
your
responsiveness
to
down
times.
A
So,
let's
actually
introduce
this
false
to
see
if
there
are
some
weakness,
weaknesses
and
then
reduce
the
recovery
times
right,
outfits
issues,
so
in
general,
it's
an
iterative
process.
So
in
chaos,
engineering,
you
pick
some
systems
or
applications,
and
then
you
pick
a
certain
chaos,
experiments
or
scenarios,
and
you
run
them
in
in
a
focused
manner,
with
the
low
blast
radius
and
then
see
if
it
is
matching
your
expected
results,
or
it
is
matching
your
expected,
steady
state
hypothesis.
A
If
not,
you
have
a
learning
and
you
go
and
fix
that
issue,
and
then
you
keep
doing
it.
So
this
is
an
iterative
process.
What
it
means
is
that
you
start
small
and
then
you
start
covering
various
services,
various
components
within
services
and
the
degree
of
randomness
of
falls
increases,
and
you
start
covering
more
complex
faults
that
could
happen.
You
know
with
chaos
engineering
right,
so
that
is
what
chaos
engineering
is
and
it
its
relevance
is
becoming
more
and
more
in
cloud
native
ecosystems.
A
So
in
effect,
you
have
multiple
micro
services
to
deal
with
and
you
are
receiving
the
updates
to
this
micro
services
at
a
phenomenal
rate
right
so,
together
you
are
seeing
more
dynamism,
and
how
can
you
make
sure
that
the
service
reliability
is
intact
if
there
are
any
failures
either?
You
know
within
this
micro
services
or
the
infrastructure
that
hosts
this
micro
services,
and
the
answer
to
that
is
you
know
chaos.
Engineering
can
help
because
of
this
increased
dynamism.
A
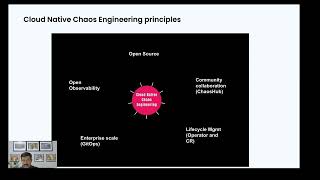
So
in
cloud
native,
if
you
are
talking
about
chaos,
engineering
practice,
we've
been
advocating
certain
principles
generally
cloud
native
rights
on
open
source
right,
so
your
chaos,
engineering,
stack
or
solution
could
be
an
open
source
based
one
and
the
chaos.
Experiments
need
to
be.
You
know,
well
tested
rugged,
flexible,
so
they're,
better
built,
you
know
through
the
community
or
put
them
in
an
open
market
place
right
and
chaos.
Experiments
are
like
any
other
software
code.
So
that
really
means
that
you
keep
changing
them.
There
are
various
version.
A
You
need
version
control
management,
around
chaos,
experiments.
So
it's
better
that
you
have
chaos,
operators
and
chaos,
experiments
as
custom
resources
on
cloud
native
and
then
obviously
the
real
problems
happen
at
scale.
So
you
need
to
ensure
reliability
at
scale
so
which
really
means
that
chaos.
Engineering
also
has
to
be
applied
on
a
scale
system,
and
you
have
to
increase
the
scale
of
chaos.
Engineering
as
well
right,
so
gitobs
is
one
possible
answer
to
you
know
chaos
engineering
happening
at
scale.
The
last
one
is
observability.
A
Observability
is
very
important
in
chaos.
Engineering
in
that
you
introduce
faults,
and,
but
you
always
observe
through
your
established
observability
practices
right,
so
the
context
of
chaos
has
to
be
placed
along
or
on
top
of
your
observability
system.
So
what
it
really
means
for
cloud
native
chaos
engineering
is
you
better
have
open,
apis
or
apis
that
are
easily
available
to
integrate
with
chaos,
engineering
or
chaos,
engineering
tools,
a
framework
should
provide
apis
to
upload,
or
you
know,
pull
the
chaos
metrics
from
the
chaos
engineering
platform.
A
So
together
these
principles,
it
covers
all
the
requirements
of
a
good
chaos
native
cloud
native
chaos,
engineering
platform,
so
one
such
platform,
of
course,
is
litmus
chaos
which
I'll
talk
in
a
bit.
So
before
I
do
that,
let's
also
see
how
chaos
engineering
happens,
how
it
starts
and
matures
within
an
organization.
A
A
You
know
with
the
simple
experiments
and
as
you
develop
and
get
experience
of
chaos,
tests,
running
kl
stress
on
cross
section
layer,
then
you
go
one
level
up
into
middle
layer,
api's
message,
queues
or
apa
servers,
and
then
you
go
into
more
stateful
services,
databases
and
data
services
and
finally,
your
own
applications.
You
can
start
introducing
simulated
faults
right
and
when
you
reach
that
level,
you
can
say
that
you
have
reached
a
maximum
level
of
chaos.
A
Engineering
in
your
organization,
right
when
you
reach
that
level,
you
can
generally
observe
if
your
language
of
chaos,
engineering,
you
know
the
maturity
is
being
dealt
in.
Terms
of
you
know,
slows
sorry
metrics.
Is
it
linked
to
chaos,
engineering
or
not,
and
developer?
Metrics
is
also
linked
to
chaos,
engineering
or
not.
So,
as
you
can
see,
chaos
engineering
plays
a
core
role
in
in
cloud
native
devops
right
and
a
good
chaos.
Engineering
solution
within
devops
or
cloud
native
devops
adopts
the
culture
of
chaos
or
chaos,
culture
across
all
functions
within
devops.
A
What
I
mean
is
in
dev,
qa
and
ops,
or
by
developers
and
srs.
You
know
both
like
practice:
chaos,
engineering,
so
developers
run
chaos
in
their
pipelines
and
you
know
sres
run
slow
validation
using
chaos
and
they
introduce
randomized
chaos
in
pre-production
or
in
production
through
game
days.
Similarly,
the
test
systems
actually
go
and
introduce
deeper
chaos,
tests
in
in
their
test
systems
and
into
their
cd
pipelines,
3cd
and
4ct.
A
So
when
you
introduce
chaos,
engineering
in
all
fields,
there
is
a
general
maturity
of
deeper
tests
that
get
developed,
and
you
are
obviously
validating
the
products
being
shipped
products
being
run
for
more
error
scenarios,
so
your
services
become
generally
more
resilient.
Litmus
chaos
is
a
cncf
incubating
project
that
has
got
high
adoption
levels
by
this
popular
companies
and
also
it's
got
a
large
community
around
2000
users.
A
Let's
talk
about
the
litmus
use
cases
that
are
generally
practiced
from
vertical
standpoint:
they
are
more
used
in
banking,
retail
and
e-commerce
services,
which
is
directly
related
to
the
digital
traffic.
We
have
seen
litmus
being
used
in
edge
computing.
You
know
scenarios
as
well
in
general.
The
litmus
usage
is
more
and
more
happening
around
wherever
cloud
native,
devops
or
or
commonplace,
and
they
can.
A
A
And
if
you
have
a
good,
you
know
scale
and
performance
testing
chaos.
Engineering
can
help
or
litmus
can
help
validating
the
current
strategy
of
your
scale
and
performance
testing.
And
similarly,
if
you
have
invested
in
good
observability
systems
around
cloud
native
litmus
or
chaos,
engineering,
that's
based
on
litmus
can
help
validating
whether
your
observability
systems
will
really
help
when,
when
there
are
outages
that
may
happen
right,
so
how
litmus
chaos
in
general
works
litmus.
A
You
can
start
very
small
and
grow.
You
know
in
a
distributed
fashion
as
it's
a
kubernetes
application
you,
you
start
with
a
simple
helm,
shot
when
you
install
litmus.
You
have
chaos
center,
where
users
can
go
and
orchestrate
create,
orchestrate
and
manage
chaos.
Scenarios
right
and
when
you
install
the
platform
comes
with
a
bunch
of
experiments.
A
These
are
chaos,
experiments
for
kubernetes
resources
and
you
have
some
cloud.
Chaos
experiments
as
well,
and
it
also
comes
with
a
good
sdk
way
to
introduce
your
own
chaos
logic
into
the
platform.
We
call
it
as
bring
your
own
chaos
right,
so
you
use
all
these
chaos
experiments
and
then
you
put
them
into
a
chaos
scenarios
or
chaos,
workloads
and
you
stitch
them.
A
A
So
this
is
how
litmus
landscape
looks
when
it
comes
to
ci,
cd
and
observability
in
ci.
What
is
possible
is
in
in
pipelines.
You
can
log
into
chaos
center,
create
a
workflow
that
creates
a
manifest
and
include
that
manifest
into
a
stage
of
a
pipeline
all
right
and
we
have
tested
this
integration
of
ci.
There
are
tested
examples
available
for
jenkins,
get
lab
data
actions
and
a
harness
drone.
A
Similarly,
in
cd,
you
can
trigger
it
pre-cd,
post,
cd
or
based
on
an
event
happening
at
the
time
of
deployment
example,
a
pod
version
changes,
so
you
can
run
some
chaos
test,
so
it's
well
tested
with
our
gopluck
spinnaker
and
harness
continuous
delivery
module
and
similarly,
on
the
observability
side,
it's
got
integrations
with
well-known
observability
platforms
in
general.
How
you
can
do
observability
integration
with
these
platforms
is
by
using
litmus
http
pro.
A
Politics
and
primarily
it's
around
kubernetes,
becoming
a
configuration
control
plane
like
google
and
those
or
azure
or
cross
plane,
or
even
kubernetes,
to
manage
openstack,
so
the
usage
of
kubernetes
is
increasing,
and
that
really
means
that
kubernetes
becomes
really
really
critical.
The
reliability
of
kubernetes
becomes
critical,
but
there
are
many
users
who
are
using
litmus
to
validate
such
a
platform
implementation
by
introducing
kubernetes
faults
and
the
other
one
is.
A
You
know
you
will
always
have
hybrid
infrastructures,
even
though
you
start
litmus
with
the
kubernetes
experiments,
you
will
see
the
need
for
an
integrated
chaos
around
bare
metal
or
other
switches,
rack
servers,
load,
balancer,
etc,
etc,
and
also,
nowadays
you
have
multi-cloud.
You
know,
scenarios
or
deployments
where
you're
using
various
cloud
services,
either
database
services
or
app
services
or
serverless
systems,
where
you
will
start
using
different
other
tools
in
conjunction
with
chaos,
for
example,
load
testers
right,
a
chaos
tool
plus
load
tester
together
can
simulate
a
chaos
scenario
for
you.
A
So
these
are
some
of
the
newly
foreign
use
cases
of
repress.
So
to
summarize
benefits
of
lateness
with
litmus
or
with
chaos
engineering,
you
increase
your
capability
to
inject
false.
As
well
so
mean
time
to
inject
or
identify
a
fault
actually
decreases
your
faster
and
whenever
faults
happen
or
service
outages
happen,
you
recover
faster,
your
mttr
decreases
and
because
of
one
and
two
you
are
more
agile
and
you
are
fixing
issues
or
weaknesses,
so
the
failures
will
eventually
reduce
right.
A
So
these
are
the
general
benefits
of
chaos,
engineering
and
especially
true
with
the
litmus
together.
So
we
have
a
service
available
for
litmus
chaos,
engineering
control
plane
as
a
service
for
users.
You
can
get
your
own
control
plane
by
signing
up
at
litmus
k,
all
star
cloud
connect
your
targets
and
run
chaos.
Experiment
and
you
know,
observe
resilience
or
you
know,
find
an
opportunity
to
improve
resilience
with
that.
Let
me
turn
over
to
karthik
to
do
a
demo.
B
Hello:
everyone
in
this
demonstration,
let
us
take
a
look
at
how
you
can
install
the
litmus
chaos
platform
and
how
you
can
get
started
by
running
a
simple
chaos,
workflow
against
a
sample
application
and
observe
the
impact
of
the
chaos.
My
name
is
karthik.
I
am
one
of
the
maintainers
of
the
ritmos
project.
B
B
B
Now
that
we
have
our
chaos
center
up
and
available,
the
load
balancer
is
working.
Let
us
go
ahead
and
login
with
the
default
credentials,
that
is
admin
and
litmus,
so
each
user
in
kr
center
is
allocated
a
dedicated
chaos.
Workspace
also
called
as
the
chaos
project,
which
is
where
they
will
be
performing
the
chaos,
workflows,
management,
creation
of
workflows,
visualization
of
the
workflows,
creation
of
new
teams,
with
the
invited
members
comparison
of
workflow
runs,
etc.
B
B
The
kiosk
dashboard
is
the
first
page
that
grades
us
once
we
log
into
the
chaos
center.
We
do
not
have
any
workflows
that
are
executed.
This
was
our
first
login,
but
one
of
the
most
important
things
to
look
for
and
check
immediately
after
logging
in
into
the
chaos
center
is
whether
we
have
a
chaos
agent
connected.
B
B
B
What
this
means
is
that
the
cluster,
where
we
have
installed
the
control
plane,
microservices
automatically
qualifies
as
an
environment
in
which
you
can
do
your
chaos
in
our
demonstration.
We
would
be
connecting
an
external
cluster
which
houses
our
sample
application,
but
this
is
the
self
agent
that's
available
for
you,
so
you
could
have
micro
services
that
you
want
to
do
chaos
upon
on
the
same
cluster,
and
this
helps
you
execute
it
next
useful
thing
to
look
forward
to
in
the
chaos
center
is
the
chaos
hub.
B
The
chaos
hub
is
an
open
catalogue
of
several
faults
or
chaos.
Experiments
which
you
can
piece
together
perform
a
chaos
workflow.
There
are
different
number
of
experiments.
There
are
different
types
of
experiments,
totaling,
50
experiments
in
the
chaos
hub
and
the
chaos
hub
is
also
the
place
where
you
have
some
demo
or
illustration
workflows
that
you
can
use
to
kick
start
your
evaluation
process
of
the
kiosk
project,
fitness.
B
B
The
settings
page
in
kr
center
is
useful
to
manage
your
account
to
create
new
users
on
the
platform
as
an
admin,
you
could
create
new
users,
and
you
can
also
create
teams
in
each
project
where
you
invite
members
that
are
already
created
on
the
project.
That
is,
the
admin
can
go
ahead
and
create
different
users,
providing
them
with
username
and
password.
B
The
respective
users
can
log
in
with
their
credentials,
and
once
they
get
into
their
chaos
project,
they
can
come
to
settings,
go
to
the
teams
tab
and
invite
members
into
their
own
project
with
specific
role.
So
let
us
provides
our
back
at
the
chaos
center
level.
The
users
are
classified
as
owners,
editors
and
viewers,
each
with
desired
set
permissions.
B
There
are
a
few
other
settings
that
are
available
on
the
chaos
center
typically
used
as
part
of
the
data
operations
as
part
of
a
chaos
practice.
For
example,
you
could
influence
where
your
images
for
the
the
chaos
workflow
parts
are
coming
from.
You
could
be
using
the
default
docker
dot,
io
registry
and
the
litmus
repository,
or
you
could
be
using
your
own
registries,
from
where
you
pull
in
the
experiment
and
workflow
parts.
B
The
usage
statistics
is
a
very
quick,
provides
you
with
a
very
quick
view
of
the
execution
thus
far,
and
you
could
actually
see
how
many
experiments
you've
run,
how
many
workflows
you've
run,
how
many
users
are
there
on
the
platform,
etc.
This
is
something
that
is
useful
for
the
admin
to
generate
some
helpful
reports.
B
So
with
this
introduction
to
the
various
screens
possible
on
the
chaos
center,
let
us
go
ahead
and
connect
our
target
environment.
We
spoke
about
a
gke
cluster
on
which
we
have
our
sample
app
residing.
So
let
us
connect
that
to
the
center.
Let
us
add
that
to
the
control
plane
then
begin
with
our
first
chaos.
Workflow.
B
B
B
B
So
the
first
step
here
would
be
to
create
your
account
or
to
set
the
account
on
the
on
the
working
space
that
you
have
where
you
have
installed
the
litmus
ctl
tool.
So
let
me
go
ahead
and
perform
the
ctl
set
account
step,
so
this
is
going
to
help
you
with
setting
up
the
right
keys
and
the
auth
in
order
to
access
the
the
control
plane
with
your
credentials
for
your
project,
we're
going
to
provide
the
end
point
where
litmus
is
running.
B
B
B
B
B
B
B
B
B
B
The
subscriber,
as
you
can
see,
installed
with
a
set
of
other
components,
most
of
which
are
kubernetes
controllers,
the
ks
operator.
The
event
tracker
and
workflow
controllers
are
custom
communities,
controllers
that
act
upon
different
custom
resources
and
participate
in
the
chaos
execution
process.
The
exporter
happens
to
be
a
prometheus
exporter
that
provides
chaos
metrics.
B
B
B
B
B
These
are
some
properties
that
you
could
provide,
am
providing
minimal
values
just
one
second
for
the
polling
interval,
just
one
retry.
If
the
response
code
is
not
200
and
we're
going
to
begin
this,
let's
say
a
second
after
the
experiment,
execution
begins,
so
you
have
an
option
to
abort
the
workflow
in
case
the
constraint
is
not
validated,
you
could
choose
the
stop
and
failure
to
be
true.
B
B
B
You
could
run
this
experiment
for
a
total
duration
of
30
seconds
with
a
10
second
interval.
That
means
a
pod
is
going
to
be
picked
and
killed
every
10
seconds
up
until
the
total
chaos
duration
of
30
seconds
is
the
upper
bound.
We
just
want
one
iteration
of
chaos,
so
I'll
just
probably
change
the
duration
to
a
much
smaller
value.
B
One
aspect
to
note
is
that
the
duration
here
talks
about
the
chaos
duration
alone,
not
for
the
entire
experiment.
The
experiment
in
litmus
performs
pre
chaos
and
a
post
chaos
check
to
ensure
the
system
is
left
in
the
healthy
state,
and
that
takes
a
few
seconds
up
and
over
the
chaos.
Duration
that
you
have
specified.
B
You
could
also
add
more
environment
variables
depending
upon
your
need,
let's
finish
it
and
keep
it
simple.
We
have
the
option
of
cleaning
up
the
chaos
resources
immediately
after
the
run
and
we
have
the
option
of
keeping
them
as
well.
In
our
case,
let's
keep
them,
because
that
helps
us
to
look
at
the
experiment,
pod
logs.
B
B
B
Let's
take
a
look
at
what
is
happening
as
part
of
the
workflow
run.
You
could
use
the
workflow
visualization
graph
to
track
the
progress
of
your
chaos
workflow
for
each
experiment
that
you
picked
within
a
workflow.
You
would
have
typically
two
steps
performed
so,
though,
that
is
easily
customizable.
B
B
B
B
B
B
B
We
did
have
an
aggressive
check
against
our
application
availability
and
that
failed.
What
is
the
mitigation?
You
could
be
scaling
up
your
potato
main
micro
service
to
multiple
replicas
and
repeat
the
same
fault,
in
which
case
you
will
have
the
workflow
succeed.
As
for
the
initial
hypothesis
or
the
desired
case,
where
you
would
not
see
any
downtime
on
the
probe
success
percentage
or
access
duration,
once
you
have
the
workflow
runs
executed.
Thus
you
can
go
to
the
observability
section.