►
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
A
The
first
thing
that
we're
going
to
explore
is
why
do
we
need
snapshot
to
make
a
good
backup
rather
than
file
system
copy?
Then
we'll
see
what
is
the
container
storage
interface
then
we're
going
to
use
this
part
of
the
csi
called
the
snapshot
part
to
take
a
backup
of
your
world
namespace
and,
to
finish
we'll
see
the
limitation
of
the
solution
that
we're
going
to
demonstrate
for
the
long
term
protection.
A
The
reason
is
simple:
let's
take
us,
let's
take
a
pvc
with
six
five
at
t0
f1
has
four
banana
f6
has
four
pineapple
at
t1
5
at
t2
6,
then
you
take
a
snapshot
and
the
snapshot
is
crash
consistent,
which
means
all
the
files
are
captured
exactly
in
the
same
time.
So
you
capture
the
six
banana
and
you
capture
also
the
sixth
pineapple
all
that,
in
the
same
time,
consistent
with
the
actual
file
system
state
before
the
crash.
A
If
you
do
a
file
system
copy,
you
copy
each
file
one
by
one,
while
the
system
is
still
evolving,
so
you
may
find
yourself
at
the
moment
of
the
backup
taking
the
sixth
banana.
But
when
you
finish
the
copy,
you
finish
with
f6
with
eight
pineapples
and
you
are
not
in
the
real
actual
state
of
the
file
system
before
the
crash,
so
you're
not
crush
consistent.
A
A
It's
made
of
topic
topics
are
made
of
partitions,
partitions
are
made
of
segment
and
segments
are
the
fives
in
which
you
write
the
kafka
message
to
get
very
high.
Throughput
kafka
is
not
writing
immediately
the
message
to
the
file
system.
It
actually
used
the
os
virtual
memory
to
open
the
file
and
when
you
write
when
kefka
writes
a
message,
it
actually
write
it
in
the
ram
in
the
memory
not
in
the
file
system.
It's
only
when
some
of
the
conditions
are
made
like
size
is
rich
or
the
timer
root
is
reached.
A
A
So
you
may
find
yourself
in
the
situation
where
some
of
the
partition
has
all
the
segment
and
some
other
partition
does
not
have
all
the
segments
and,
in
the
point
of
view
of
kafka,
this
is
not
consistent.
It's
why
we
say
that
snapshots
are
crash
consistent,
but
not
application
consistent
as
a
quick
takeaway.
A
A
A
Oh
the
issue
here
was
this
part:
the
driver,
the
driver,
belonged
to
the
kubernetes
code,
and
for
this
reason
it
was
a
limited
number
of
driver.
You
can
see
this
limited
number
of
drivers
here.
They
are
all
represented
here.
Actually,
that's
all
and
that's
an
issue
because
let's
say
you
are
netapp
and
you
want
to
communicate
with
kubernetes.
You
want
to
let
your
customer
be
able
to
create
netapp
volume
for
their
kubernetes
workload.
A
The
only
solution
the
netapp
team
has
at
this
moment
was
to
submit
her
code
to
the
kubernetes
team,
and
the
kubernetes
team
has
to
accept
the
code.
Then,
if
you
have
a
bug
in
your
driver,
you
need
to
wait
for
the
next
kubernetes
release,
so
your
your
release,
cycle
of
your
driver
is
tied
to
the
release
cycle
of
kubernetes
and
for
all
this
reason
that
was
an
issue.
It's
why
the
kubernetes
team
created
the
csi,
the
continuous
storage
interface
csi.
A
Let
you
introduce
your
storage
driver
without,
depending
on
the
kubernetes
code,
you
define
a
specific
set
of
interface,
that
you
must
respect
to
communicate
between
communities
and
your
driver.
First,
your
driver
register
declare
its
capabilities
and
then
you
will
be
able
to
handle
all
the
pvc
requests
now.
How
does
it
done?
A
Then
you
have
the
provisioner,
so
the
provisioner
is
the
one
who
has
to
translate
the
pvc
request
to
the
driver.
You
have
also
the
registrar.
I
should
have
spoken
about
it
in
the
first
place,
which
register
this
kind
of
storage
to
the
communities
api.
You
have
the
csi
attacher,
which
is
responsible
for
the
not
published
volume.
A
A
quick,
takeaway
csi,
let
any
storage
vendor
register
to
kubernetes,
csi,
decouple
storage,
vendor
code
to
kubernetes
code
and
most
of
the
sidecars
for
communicating
with
kubernetes
can
be
reused
with
little
configuration
change.
Only
the
csi
endpoint,
which
is
the
driver,
is
the
storage
vendor
responsibility
to
create
a
snap
of
your
volume.
A
You
create
a
volume
snapshot
object.
The
volume
snapshot
object
is
a
namespace
here
object
and
is
made
of
two
things:
first,
the
source
which
is
the
pvc
that
you
want
to
snap
and
the
snapshot
class
name,
because
you
may
have
more
than
one
csi
driver
in
your
cluster
and
you
want
to
address
the
snapshot
request
to
the
proper
driver.
A
Now,
if
you
want
to
restore
from
a
snap,
you
create
a
regular
persistent
volume
claim,
but
this
time
you
specify
the
data
source
as
the
snapshot
that
you
just
created
and
once
again
you
specify
the
proper
storage
class
name
in
order
to
use
the
proper
driver
for
the
restoration
and
that
will
create
a
clone
of
the
snap,
a
clone
of
the
pvc.
When
the
snap
was
created.
A
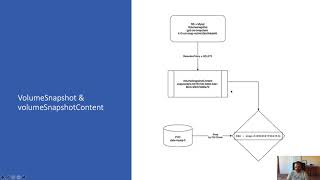
Here
is
the
volume
snapshot,
which
is
a
namespace
head
object,
and
when
you
create
it,
it
triggered
the
creation
of
the
volume
snapshot
content
and
it's
the
volume
snapshot,
content
that
will
be
responsible
for
the
creation
of
the
snap
or
the
driver
is
going
to
take
the
actual
volume
and
do
the
snap
to
the
storage
layer.
Here,
it's
ebs.
A
A
I
create
another
volume,
snapshot,
content
pointing
to
the
same
volume
snapshot
under,
and
I
create
a
volume
snapshot
in
my
namespace,
the
mysql
story,
and
from
this
snapshot
I
create
a
clone,
and
here
I
am-
I
have
my
new
pvc
with
exactly
the
same
data
than
the
pvc
that
I
had
originally
on
my
sql
interesting
to
note
here
that
I
put
retention
policy
delete
and
here
retention
policy
written.
Why
that
it's
because
my
initial
action
was
to
create
a
snap
here,
and
I
want
to
keep
the
control
of
the
deletion
of
that.
A
A
It's
interesting
to
note
here
that
I
don't
use
any
kind
of
secret
to
speak
to
the
storage
layer.
I
don't
have
to
provide
my
as
your
secret
or
my
aws
access
key
with
the
proper
right
to
create
or
delete
volumes.
All
that
is
not
my
preoccupation.
Now
I
just
have
to
work
with
api
as
a
quick,
takeaway
csi
lets
you
create
snapshot
with
kubernetes
api
and
any
applications
that
want
to
manage
backup,
don't
need
anymore,
to
have
all
the
secret
of
your
storage
layer.
A
There
is
limitation
to
the
solution.
I
propose
some
obvious
limitation.
The
first
one
that
I
already
discussed
is
the
fact
that
snap
is
not
application
consistent,
as
I
show
it
in
the
kafka
example.
The
second
thing
is
snap
are
not
durable.
Backup
chance
is
that
if
you
have
a
disaster,
your
snap
will
be
included
in
the
disaster,
and
you
need
a
way
to
extract
your
snap
to
make
them
durable
backup.
A
A
Next
things
is
the
backup
policies.
You
don't
want
to
just
punctually
backup
your
project.
You
want
to
do
regular,
backup
to
have
a
rto
rto
is
the
recover
time
objective,
which
means
the
time
where
you
lose
the
data,
and
you
want
to
reduce
that.
So
you
need
to
take
regular
backup
and,
of
course,
if
you
take
regular
backup,
it
means
that
you
have
to
clean
the
backup.
A
A
A
All
these
questions
are,
of
course,
in
the
limitation
of
the
solution
I
show,
but
the
tools
that
that
will
give
you
some
professional
support
for
your
backup
will
address
that.
Okay,
thanks
a
lot,
and
I
hope
this
presentation
was
helpful
and
I
just
have
to
say
see
you
soon
in
the
next
kubecon
thanks
a
lot
bye.