►
From YouTube: Kanister Overview - An extensible open-source framework for app-lvl data management on Kubernetes
Description
A short overview to show you how simple it is to create an application-level backup to AWS S3, in this video we will show you how simple it is to deploy Kanister as an open-source way to protect your application data and also restore the data if there was a failure scenario.
You can find the readme I followed along with here - https://github.com/MichaelCade/demos/blob/main/kanister/readme.md
more information can be found at https://kanister.io/
docs - https://docs.kanister.io/overview.html
GitHub - https://github.com/kanisterio/kanister
Extending Kasten K10 with Kanister - https://docs.kasten.io/latest/kanister/kanister.html
A
Hey
everyone,
so,
in
this
demo
we're
going
to
be
focusing
on
canister,
which
is
an
open
source
framework
or
project
that
is
focused
on
application
level.
Data
management
for
your
kubernetes
applications.
So
here's
some
information
canister.io
is
where
you're
going
to
find
all
of
the
information
it
runs
within
your
kubernetes
cluster
protects
your
application
data,
basically
with
with
what
we
also
with
so
it
has.
The
case
of
blueprints
blueprints
gives
us
the
the
ability
to
dive
into
your
application.
A
If
we
take
a
look
at
what
one
of
those
blueprints
looked
like
quickly,
so
it
has
leverages
the
kubernetes
api,
then
it
has.
Its
action
sets
to
be
able
to
use
cube
task,
and
then
here
you
can
see
that
we're.
What
we're
doing
is
going
inside
of
the
the
data
service,
triggering
application,
consistency
using
native
tools,
mysql
dump
in
this
example,
and
then
we're
offloading
that
using
can
do,
which
is
another
tool
set
that
comes
through
with
with
the
canister
operator
and
pushes
that
out
into
an
s3
target
object.
A
A
So
I've
also
written
something
similar
to
that
and
it
walks
through
actually
adding
the
the
canister
helm
repository
the
net,
creating
the
namespace
deploying
that
as
well
and
and
all
of
that
good
stuff,
and
that's
really
what
we
want
to
focus
on
in
this
in
this
session.
So
I've
cleared
everything
down.
A
So
next
up
we
want
to
create
that
that
canister
namespace
so
create
namespace
canister,
and
then
we
want
to
deploy
that
using
helm.
So
I
want
to
take
the
latest
version,
which
I
think
is
67,
maybe
68
now,
but
let's
go
with
67
and
with
that
you
can
see
how
quick
that
went
and
if
we
go
and
take
a
look,
get
pods
name
space.
A
Canister
remember
what
I'm
actually
doing,
okay,
so
we
can
see
that
that's
now
deployed
and
if
we
head
on
over
here
so
once
we've
once
we
have
canister
deployed,
we
should
now
show
the
custom
resource
definitions,
and
this
is
basically
enabling
us
to
leverage
the
kubernetes
api,
and
this
is
going
to
show
action
sets
blueprints
and
profiles.
So
we
can
do
that
by
running
this
command
here.
A
And
if
we
hit
that
you
can
see
that
we're
going
to
create
or
we've
got,
the
ability
now
to
create
three
custom
resource
definitions,
one
is
our
action
sets.
Action
sets
provide
us
the
ability
to
actually
run
the
tasks
so,
whether
that
be
a
restore
or
a
backup
or
it
could
be
anything
outside
of
the
box.
But
really
what
we're
focusing
on
is
the
data
management
tasks.
A
Okay,
so
that's
canister
deployed,
but
now
we
want
to
actually
let's
go
and
deploy
my
sequel
environment
as
well.
Now,
I'm
pretty
sure
I
also
had
the
bitnami
yet
so,
let's
create
a
another
namespace
called
mysql
test
and
let's
go
ahead
and
I'm
going
to
use
the
default
or
very
simply
and
unsecure,
because
I'm
showing
you
what
that
looks
like
and
what
this
is
going
to
do
is
go
and
deploy
that
mysql
test
with
or
my
sql
from
the
helm
chart
within
our
mysql
test
namespace.
A
While
that's
running
and
deploying
I've
also
set
these
environment
variables,
so
I'm
going
to
go
and
use
can
ctl,
which
is
a
cli
tool
that
also
comes
with
canister
and
can
be
separately
downloaded
for
your,
like
a
binary
for
your
machine
and
you'll
find
that
also
at
the
github
location
and
basically,
what
we're
going
to
do
is
we're
going
to
create
a
profile,
an
s3
compliant
profile.
But
let's
clear
this
and
I'll
I'll
show
you
what
else
is
available
within
there.
So
this
gives
us
the
ability
to
create
our
profiles.
A
It
obviously
gives
you
the
ability
to
validate
some
of
those
things,
but
let's
do
a
can
ctl
create
and
then
we'll
get
to
see
what
we've
actually
so
we
can
create.
Our
action.
Sets
and
our
profiles
and
again,
if
I
just
drill
into
the
profile,
because
that's
what
we're
going
to
do
now
is
we
have
the
ability
to
create
an
azure
profile,
a
gcp
profile
or
s3
compliant
s3
compliant
gives
us
the
ability
to
use
aws
or
s3
compliant
or
s3
capable
compatible
storage.
A
So
for
the
purpose
of
the
demo,
I'm
actually
going
to
create
a
profile
of
s3
compliant.
I'm
going
to
use
those
environment
variables
that
I've
already
got
added
in
the
us
east
2
region,
which
is
actually
going
to
be
using
aws
s3,
and
I
want
to
create
it
for
my
mysql
test.
Now
we
could
have
different
profiles
for
different
workloads,
but
for
this,
let's,
let's
create,
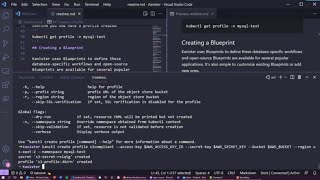
can
ctl
create
profile,
profile,
s3
compliant,
and
let's
see,
if
that
fixes
it.
A
So
you
can
see
that
we're
creating
the
secret
and
the
profile,
and
if
I
now
like,
you
saw
that
it's
created,
but
if
I
do
a
cube,
ctl
get
profile:
minus
n,
my
sql
test.
So
let's
see
what
profiles
we
have
available
to
us
within
our
mysql
test
namespace,
and
you
can
see
that
I
have
an
s3
profile.
D4Z
rn
and
then
the
next
stage
is
okay,
so
we've
got
my
sql
deployed,
let's
just
check
whether
that
what
that
looks
like
now,
so,
okay
get
namespace,
so
we
should
have
a
mysql
test.
A
Okay,
all
good,
but
now
we
need
to
have
that
hook
that
data
service
hook
into
our
application,
so
canister
uses
blueprints
to
define
these
database
specific
workloads
and
open
source
blueprints
are
available
for
several
popular
applications.
You
saw
them
in
the
github,
it's
also
simple
to
customize
existing
blueprints
or
add
new
ones.
Basically,
what
we're
doing
is
we're
providing
a
way
of
being
able
to
automate
that
hook
into
your
data
service
to
hook
into
whatever?
A
That
may
be
now
we're
using
my
sql
dump
but
think
about
other
tasks
that
you
could
potentially
perform
here
as
well.
So
what
we're
going
to
do
is
we're
going
to
pull
down
the
the
blueprint
from
that
github
location
and
it's
going
to
be
my
sequel
blueprint.
In
fact,
what
I'm
going
to
do
is
I'm
going
to
cube
ctl,
create
minus
f,
create
minus
f.
You
can
see
there
that
I'm
already
pulling
that
down
and
I'm
putting
it
into
our
canister
namespace.
And
if
we
were
to
then.
A
A
A
A
A
So
let's
update
my
readme
and
then
let's
insert
this
line
of
text
this
command
and
if
we
then
go
and
select
that
we
should
see
our
data
okay,
so
quick
demo,
without
it
being
in
my
sequel
demo,
is
we've
added
some
data
to
our
database.
You
can
see
it
here
that
we
have
a
pet
named
puffball,
an
owner
of
diane,
it's
a
hamster,
etcetera
right.
Then
we
want
to
be
able
to
create
a
action
set.
That
gives
us
the
ability
to
offload
that
into
our
object,
storage.
A
A
A
You
can
see
here
11
seconds
ago,
and
then
we
want
to
see
actually
did
it
work
so
by
being
able
to
go
into
using
a
cube,
ctl
describe
that
action
set.
In
fact,
what
we
need
to
do
is
we
need
to
change
that
action
set
to
jt
lr7,
and
you
can
see
here
that
the
executed
action,
backup
executing
phase
updated
action
set
now
what
we
can
do
is
we
can
jump
over
to
our
aws
s3
management.
So
this
is
what
the
profile
looks
like.
A
You
can
see
that
we've
already
created
a
folder
called
mysql
backups,
and
there
should
be
my
sql
test
that
some
of
these
are
previously
created
snapshots,
but
you
can
see
here
that
we
have
a
28
for
the
9th
2021
which
is
today.
You
can
see
here
that
we
have
that
native
suit,
my
sequel
dump
of
all
of
our
data.
A
A
A
See
how
this
goes
as
just
one
block
of
text,
but
what
it
should
so
you
can
see
there
in
here.
We've
dropped
that
test
database.
Okay.
So
let's
exit
that
and
now
in
order
for
us
to
restore
the
data
from
our
aws
s3
profile,
we
need
to
create
another
action
set.
But
this
time
it's
a
restore
action
set
and
note
again
that
your
action
check
will
be
named
different
to
what
I
have
below.
A
A
And
now
we've
created
that
we
could
go
and
let's
see
what
that
action
set
actually
looks
like
again
make
sure
it's
there.
You
can
see
that
our
backup
is
there
and
our
restore
backup
is
also
now
in
play.
We
can
also
go
and
describe
that.
So,
let's
do
a
let's
grab
this
bit
and
let's
add
in
this
bit
and
by
the
time
we've
done
this.
Actually
the
data
will
be
back
and
restored
because
it
was
only
a
a
table
so
again
for
the
third
time.
Let's
now
go
and
jump
into
our
my
sequel
instance.
A
And
let's,
in
fact
this
will
let
us
see
everything
that
we
need
to
see.
Okay,
so
we
can
see
that
the
test
database
is
now
back.
We
can
see
that
the
pets
table
is
there
and
we
can
see
that
our
information
in
that
table
is
also
there
and
that's
a
very
quick
way
of
looking
into
what
canister
is
capable
of
from
a
my
sequel
point
of
view.
A
But
ultimately
this
is
going
to
give
you
that
operator
function
of
being
able
to
capture
the
data
in
a
consistent
manner,
so
that
you
can
then
use
that
as
a
as
a
restore
point,
either
back
into
itself
like
we
just
did
there,
but
also
take
that
dump
and
put
it
into
a
maybe
a
test
and
dev
environment
as
well.
Hopefully
that
was
useful.
Any
questions.
Let
us
know
yeah
be
happy
to
do
so
and
any
more
information
that
you
want
on
canister
check
out,
canister.io
and
yeah.