►
From YouTube: CNCF Research End User Group: HPC:HTC End User Landscape
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
C
A
A
D
A
So
yeah,
so
the
topic
today
was
this
hpc
htc
and
user
landscape
jamie.
We
put
some
questions,
it's
kind
of
more
to
trigger
discussion.
Today
we
can
go
through
the
replies
and
maybe
stop
on
every
topic
and
discuss
a
bit
and
hopefully
like
one
thing
that
would
be.
Nice
is
to
kind
of
come
up
with
some
next
steps
of
what
is
needed
in
this
area
for
the
cloud
native
tooling
and
what
would
be
really
useful
for
people.
D
A
D
F
A
A
G
A
A
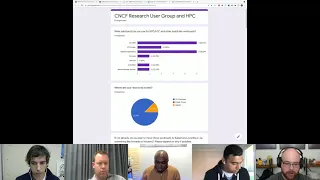
So
the
first
question
was
what
kind
of
solutions
people
are
using
for
high
performance
computing
or
high
throughput
computing
and
other
batch
like
workloads.
So
in
total
we
actually
got
eight
responses,
which
is
not
too
bad.
I
would
say
because
it
was
kind
of
a
long
question,
so
the
top
two
were
slurm
and
pure
kubernetes,
which
is
a
pretty.
A
D
H
The
kidnaps
actually
but
yeah,
so
I
was
wondering
too,
you
know,
are
we
not?
I
would
be
surprised
if
there's
really
nobody
using
volcano
and
armada
and
other
things
like
that
right
so,
like
you
know,
maybe
maybe
it's
also
kind
of
a
call
like
like.
Maybe
we
need
to
put
out
feelers
into
those
user
groups
and
try
to
get
them
more
involved
with
this
sig
right,
because
people
who
are
doing
who
are
actually
using
that
would
certainly
have
overlap
in
what
we're
doing.
H
I
think
I
wonder
if
there's
ways
we
could
reach
out
to
those
groups
or
even
coop
flow
too.
I
mean
you
know.
Those
are
I
feel
like
those
are.
I
don't
know
too
much
about
armada
and
volcano,
but
I
feel
like
those
are.
Those
are
non-zero
user
communities
right
now,
torque,
I'm
not
really
interested
in
reaching
out
to
that
community.
I'm
just
kidding,
but.
A
All
right
but
yeah,
I
think
that's
that's
a
good
point
actually
and
for
volcano.
They.
They
have
quite
a
good
structure
of
like
weekly
meetings.
I
think
they're,
mostly
targeting
or
at
least
they're
mostly
have
end
users
in
asia.
For
now
and
those
are
weekly
meetings
and
then
they
have
like
every
two
weeks.
They
have
a
meeting
that
is
kind
of
europe
and
north
america
friendly
one.
A
Okay,
that's
good!
Oh
okay!
I
see
what
yeah,
but
in
terms
of
reaching
out,
maybe
maybe
that's
a
good
point.
We
we
can
take
as
an
action
just
to
to
advertise
this
group
in
these
communities
to
see
if
they
are
interested
in
joining
it.
It's
not
like.
We
cover
every
time
this
kind
of
work
topic
either
like
there's
a
lot
of
things
that
they
will
probably
not
be
so
interested
in.
A
E
I
can
I
can
speak
for
my
old
job
yeah.
They
were
using
both
a
mix
of
slurm
and
kubernetes.
There
wasn't
any
real
transition
plan
to
go
from
one
to
the
other,
but
that's
also
was
the
university
of
michigan
and
a
good
chunk
of
their
users
were
very
familiar
with
you
know:
slurm.
They
didn't
really
want
to
like
interrupt
their
workflow.
E
H
Yeah
I
mean
or
nl.
Obviously
you
heavily
using
slurm
lsf,
I
put
them
all
kind
of
together
right
tour.
Slam
lsf.
I
guess
you
know
twerks
kind
of
on
the
outs.
I
guess
these
days,
but
you
know
pbs
all
those
right.
You
know
a
lot
of
times.
You
know,
certainly
for
us
right,
the
the
vendor
that
we
buy
the
super
computer
from
at
the
scale
that
they're
building
right.
You
know
like
they're
gonna,
it's
gonna
come
it
came
with
lsf
right.
We
bought
an
ibm
machine.
H
It
came
with
lsf,
so
you
know
those
sorts
of
things
I
don't
think
are
going
away
for
that
traditional
hpc
community
kind
of
like
what
bob's
talking
about
right
and
so
for
us,
it
was.
The
name
of
the
game
is
like
how
do
we?
How
do
we
bridge
that
gap
as
much
as
possible?
How
can
people
use
the
slurm
commands
s
batch
from
inside
of
a
container
that
sort
of
thing?
So
that's
the
direction
that
we've
gone
but
yeah?
I
don't.
I
don't
see
those
getting
supplanted.
I
mean
you
know.
H
E
I
guess
for
what
it's
worth,
I
do
see
more
people
looking
to
transition,
or
at
least
support
running
both
largely
just
because
it's
a
lot
honestly
easier,
especially
these
days
to
get
up
and
going
in
kubernetes
to
potentially
burst
out
to
some
place
and
a
lot
of
the
at
least
at
my
old
job.
A
lot
of
the
researchers
were
more
interested
in
using
things
like
keep
flow
and,
and
it
just
made
it
a
lot
easier
to
get
going.
There.
C
Yeah
and
see
what
one
sorry
go
ahead,
no
go
ahead.
Go
ahead.
I
was
going
to
say,
like
one
question
there
would
be.
Is
there
anything
that
is
prohibiting
people
from
moving
towards
using
vanilla
kubernetes
as
the
scheduler
of
choice,
or
is
it
mostly
just
familiarity
with
the
old
stuff?
So,
let's
continue
using
what
is
not
broken.
I
guess.
A
A
C
Yeah
so
then,
and
then,
therefore
a
follow-up
would
be
kubernetes
allows
for
custom
schedulers.
So
I
mean,
in
fact
I
think
volcano
is
an
example
of
that
are
people
building
their
own
custom
schedulers,
because
they're
supposedly
have
not
done
myself
but
supposedly
fairly
straightforward
to
build.
So
is
it
something
that
people
consider
and
people
say
we'll
just
build
our
own
scheduler?
Is
that
an
option.
E
A
I
think
okay
yeah,
it
might
be
just
it-
might
be
more
than
just
hooking
the
scheduler
as
well
like.
If
you
want
to
introduce
queues,
you
actually
need
to
to
handle
the
persistency
of
those
queues,
and
if
you
want
to
have
multiple
queues
and
a
priority,
there's
quite
a
bit
of
logic
there
that
all
these
systems
are
very
good
at,
because
they've
been
developed
for
ages
now,
a
lot
of
them.
So
so
it's
not
like
a
obvious
transition.
B
A
I
think
it's
good
points,
that's
a
good
point.
Actually,
like
the
experiments
we've
been
doing
with
managing
things
like
hd
condor
with
kubernetes,
even
if
we
are
still
submitting
like
under,
we
could
have
multiple
clusters
managing
the
condor
daemons
and
then
have
central
schedulers
somewhere
else.
So
you
could
kind
of
benefit
from
the
kubernetes
like
operations,
simplification,
but
then
still
use
condor.
D
D
B
C
One
last
question:
sorry,
so
do
you
guys
anticipate
that
the
existing
kubernetes
or
the
existing
kubernetes
scheduler,
the
default
category
that
comes
with
kubernetes,
will
have
options
for
a
bunch
of
these
going
forward?
Or
is
this
always
going
to
be,
like
you
know,
default
scheduler
can
only
do
this
if
you
want
something
more
specialized,
either
build
your
own
scheduler
or
like
use
this
other
open
source,
scheduler
and
whatnot.
Is
that
where
do
you
see
that
going.
A
A
F
C
A
H
We're
certainly
evaluating
and
exploring
hybrid
for
us.
The
bigger
issues
were
things
like
the
united
states
government
data
protection
stuff
around
fed
ramp
authorizations
and
things
like
that.
That
being
a
government
entity,
that's
that's
the
biggest
barrier,
but
we
are
starting
to
explore
that
that
hybrid
thing,
but
not
not
really
for
hpc,
it
would
be
more
for
for
workloads
that
could
that
I
don't
know
we
haven't,
we
don't
we
don't
certainly
don't
have
any
clear
workloads
that
are
like.
Oh,
this
would
be
perfect.
D
I
would
imagine
a
lot
of
this
group
have
got
a
relatively
established.
Infrastructure
have
already
have
on-prem,
so
it
would
start
there.
Probably
all
various
different
degrees
of
security
concerns
as
well,
and
you
sort
of
know
what
you
have
and
how
to
trust
it,
and
also
probably
just
large
data
sets
as
well,
which
is
probably
a
factor
which
might
keep
you
on
prem,
because
you
know
transferring
large
amounts
of
data
around
the
cloud
could
be
prohibitively
expensive
and
also
needing
that
the
equivalent
amount
of
compute
to
be
able
to
make
good
use
of
it.
E
One
of
the
reasons
the
university
of
michigan
was
looking
at.
It
was
because
a
lot
of
the
grants
were
coming
with
like
cloud
credits,
so
it'd
be
a
lot
easier
to
give
people
one
interface
that
they're
familiar
with
and
just
sort
of
abstract
it
all
away.
So
the
cloud
credits
could
go
to
you
know
it
could
be
gcp,
it
could
be
amazon,
it
could
be
wherever
but
they're
still
getting
an
interface
they're
familiar
with
and
know
how
to
work
with.
D
B
I
suppose
the
counter
argument
jamie
to
like
that
the
big
data
sets
we
have
on
prem
is
that
companies
that
use
cloud
data
sets
like
data
providers
who
are
cloud-based
initially,
then,
if
you're
in
the
cloud,
you
don't
have
to
move
them
as
far
to
your
on-prem
location.
So
you
know
we
might
even
be
in
that
state
for
some.
A
All
right,
I
can,
I
cannot
hear
we
I
think
the
answer
for
hybrid
is
is
ours,
so
we
are
already
deploying
some
workloads
in
this
hybrid
mode
and
the
ones
we
do
are
the
ones
that
are
from
this
embarrassing
parallel
type
of
workload.
But
we
also
have
a
couple
where
we
actually
established
links
network
links
between
our
on-premises
data
center
and
some
regions
in
different
clouds.
A
It's
much
easier
to
do
what
was
describing,
which
is
you
will
you
depend
on
the
kubernetes
api
and
you
you,
you
just
use
it
for
workloads
that
can
be
loosely
coupled
and
don't
have
like
interdependencies
that
would
require
a
low
latency
or
some
sort
of
special
network
connectivity
and
the
motivation
is
really
bursting
and
especially
for
accelerators,
which
we
don't
have
many
on
premises.
Right
now,.
C
A
Well,
it
depends
like
which
unit
for
for
for
the
batch
systems,
we
can
really
tune
the
amount
of
resources
that
are
there
for
for
things
like
the
ml
workloads
using
things
like
kubeflow,
for
example,
we
actually
auto
scale
the
clusters,
so
they
will.
They
will
only
scale
up
when
workloads
go
there
and
we
try
to
define
policies
on
what
can
go
there.
A
C
A
A
Okay,
so
then
we
move
to
a
question
which
was,
if
not
already,
do
you
plan
to
move
these
workloads
to
kubernetes,
please
expand
and
yeah.
The
couple
of
questions
we
had
was
no,
but
the
ones
with
more
details.
It
said
we
have
workloads
in
kubernetes.
That's
for
hpc
some
use
governance
to
launch
jobs
on
supercomputers.
I
guess
that
kind
of
makes
sense.
A
Then,
for
some
workloads,
I
guess
it's
the
answer,
portability
being
the
reason
and
trying
to
burst
this
is
in
line
with
what
was
describing
earlier.
I
guess
mostly
already
on
kubernetes
planning
interested
or
another.
So
I
guess
the
the
next
question
is:
what's
stopping
us,
we
already
covered
up
it.
I
don't
know
if
anyone
wants
to
add
something.
E
A
D
D
Presumably,
I
suppose
really
is
probably
what
I
expected
to
see
in
a
way
we
can't
really
tell
within
the
both
how
much
is
one
or
the
other
and
we've
got
different.
I
mean
in
our
case
anyway.
We've
got
different
groups
of
users
where
some
people
are
a
bit
more
sort
of
power
users
and
do
access
kubernetes,
directly
and
obviously
the
administrators
thereof,
but
most
of
the
our
researchers
anyway
go
through
tools
which
we
build
for
them
to
help
them
do
what
they
need
to
do
rather
than
using
kubernetes
directly.
C
C
D
C
I'm
also
learning
a
little
bit
about
some
of
these
modern,
newer
projects,
or
at
least
modern
and
newer.
For
me,
which
is
ray,
be
a
v-a-e-x
anything
one
more.
I
think.
That's,
no,
not
that
stacks
is
different,
dusk,
yeah
and
and
some
of
those
things
I
believe,
the
way
they
expect
you
to
run
with
kubernetes.
C
Is
you
have
your
local
cube
config,
so
they,
the
the
das
scheduler,
will
run
pods
inside
kubernetes,
so
the
user
who's
using
it
doesn't
know
that
you
know
I
mean
they
know
that
there
is
kubernetes.
They
have
to
set
up
some
things,
but
they
are
not.
The
user
is
not
the
one
who
runs
the
cube,
ctl
created
or
whatnot.
So
it
is
again.
I
don't
know
how
many
people
are
using
these
modern
services.
Yet
again
I
don't
know
about
modern
sorry.
A
D
D
C
A
D
A
A
So
the
replies
are
pretty
much
integrating
them,
although
only
one
in
one
case
or
no
like
yeah,
still
quite
relevant
with
a
thousand
or
more,
we
still
have
quite
a
bit
there.
So
one
one
question
I
had.
I
don't
know
if
people
want
to
say
other
things
about
this,
but
one
question
that
I
had
was
what
types
of
gpus
are
this:
is
it
all,
nvidia
or,
and
also
is
there
any
sort
of
virtualization
or
is
it
all
like
pci
password
like
and
dedicated
cards
for,
the
jobs.
H
We
we
added
some
gpus
it
that
the
hardware
took
like
three
months
to
come
in
and
we
using
the
gpu
operator
got
the
nodes
up
and
running
allocatable
in
the
cluster.
In
like
two
days
you
know
the
gpu
operator
was
awesome,
and
I
really
can't
say
enough
about
that.
I
think
it's
really
cool.
How
that's
how
nvidia
is
able
to
kind
of
do
that
and
just
kind
of
throw
that
over
the
fence,
and
I
don't
even
know
how
much
they
support
it.
H
So
actually
we
just
here
gpus
in
to
start
doing
some
of
that
stuff
with,
but
we
haven't
haven't
played
with
those.
Yet
those
are
sitting
on
the
floor
getting
getting
installed,
hopefully
in
the
next
week,
so
but
yeah
I
know
we
haven't
it
was
they
were
voltas,
I
believe,
was
the
ones
we
have
today
so
but
yeah
so
so
then
you
know
we
get
like
a
jupiter
notebook
that
allocates
a
full
volta
and
they
use
it,
like
maybe
less
than
10
of
the
time.
H
A
Yeah
we
we
offer
also
the
possibility
to
do
this
virtual
gpu,
that
nvidia
already
supported
with
t4s
and
v100s,
but
it
was
kind
of
time
sharing.
Oh
okay,
we
realized
that,
in
addition
to
being
very
unstable
in
terms
of
performance,
there
were
limitations
in
doing
things
like
that
there
were.
There
were
some
bits
of
functionality
that
that
were
not
available
for
for
for
this
sort
of
driver.
It
also
needs
an
additional
license,
but
that
we
we
managed.
A
B
A
It's
easier
for
now,
but
yeah.
We
would
like
to
get
something.
In
addition,
there
are.
There
are
sites
because
we
collaborate
with
a
bunch
of
sites
around
the
world
and
there
are
sites
that
have
amd
cards
as
well,
so
we
started
looking
at
integrating
them,
but
they
run
properly
code
but
yeah
for
now
it's
it's
all
anything
yeah.
I
think
they've
got
pretty
mad
markets
there
or
we
get,
but
we
also
have
issues
with
the
delivery
times.
A
C
D
B
B
You
know
we're
looking
at
all
the
graph
cores
and
sub
novas
and
what
are
some
of
the
other
ones
takians
or
what
are
those
other
ones
ascension,
or
something
like
that?
There's
a
there's,
a
bunch
of
those
things
that
are
being
tested
and
played
around
with,
but
nothing
that's
gone
near
to
production
or
kubernetes
status.
So.
E
A
E
A
I
think
I
don't
know
if
anyone
wants
to
add
anything
to
what
is
already
here.
I
think
we
see
yeah
x
509
in
kerberos
so
off
and
the
main
thing
would
be:
how
are
these
credentials
being
maintained
and
like
refreshed
for
long-lived
jobs
and
things
like
this?
I
guess
everyone
has
this
sorted
out
or
any
problems
there.
D
D
Yeah
sure
so
yeah
question
around
how
we
handle
data
in
our
clusters,
what
kind
of
file
systems
people
use
or
other
quite
split
lots
of
ceph
cfs,
that
is,
people
choosing
multiple
as
well,
but
yeah
lustre,
gps
hdfs
as
well.
Quite
I
mean
there's
yeah
lots
of
different
various
responses.
I
don't
know
is
anyone
interested
to
know
if
the
hdfs
people
are
on
the
call?
Actually,
I
haven't
talked
much
about
that
previously
in
our
group.
B
A
H
Sort
of
I
don't
know
I
mean
so,
did
you
see
that
apptaner
is
the
new
singularity
they
just?
They
just
announced
that
the
other
day
the
I
feel
like
I
feel,
like
you,
know,
hpc
containers
people
want
more
than
than
what
they
think
they
want
kind
of
thing
right.
I
feel
like
the
name
of
the
game.
You
know
we
were
working
for
a
while
on
trying
to
replicate
singularity,
contain
or
hpc
containers
with
podman
and
really
the
amount
of
holes
that
you
kind
of
poke
in
the
container.
H
It
turns
into
more
of
a
sieve
than
it
does
like
a
container
right,
because
you
really,
you
really
want
to
bind
mount
up
all
all
of
your,
your
your
blast,
libraries.
You
know
the
gpu
line.
You
know
you
want
to
pull
all
that
stuff
in
off
the
host
right.
You
know
it
kind
of
kind
of
necessarily
breaks
that
isolation.
H
You
know
I
mean
I
still
think,
there's
really
good
stuff
about
it
and
and
even
like,
like
nurse
nurse,
showed
that
with
what
are
they,
it's
not
singularity,
they've
got
their
they've
got
another
one
based
on
docker,
but
that
python
applications
actually
perform
faster
across
a
cluster
in
a
container
than
outside
of
a
container
right.
It
has
to
do
with
the
python
looks
up
paths
for
linking
for
dynamic,
libraries
and
stuff.
H
It
doesn't
have
as
many
paths
to
look
up
in
a
container,
because
the
way
that
the
way
that
you
link
in
a
container,
I
guess,
is
compared
to
like
a
normal
hpc
host.
So
it's
kind
of
funny,
but
but
I
don't
know
I
mean
I
don't
know
we
get.
We
get
tons
of
requests
for
people
to
to
to
support
hpc
containers,
but
and
people
do
use
them,
but
I
don't
know
I
feel
like
I
feel
like
we
always
have
to
have
this
like
hard
conversation
of
like
okay.
H
I
I
I
H
There's
a
good
good
quote
from
another
guy
in
a
different
lab
who
said
that
that
hpc
containers
is
teaching
a
whole
new
generation,
the
of
of
linking
for
errors
right
library
linking
errors
right.
You
know-
and
it's
it's
so
true,
because
you're
right,
that's
what
you're
doing
you're
mounting
it
off.
If
you
want
to
get
the
performance
so
yeah
here.
I
I
There's
a
lot
of
problems
with
that,
especially
with
the
move
to
the
the
single
floats,
the
gpus.
I
mean
you
get
the
fancier
nvidia
ones
with
the
double
floats,
it's
not
as
much
of
an
issue,
but
it
still
matters,
and
then
the
lack
of
the
ieee
float
standard
being
consistently
implemented
completely
makes
it
entertaining
yeah.
I
posted
the
link
of
a
lot
of
the
limits
that
you
know
been
around
for
a
while.
I
I
mean
right
now,
there's
a
lot
of
glue
work
that
goes
in
for
like
getting
jupiter
books
to
work
on
hbc
or
some
of
them
run
them
on
kubernetes
and
then
burst
out
to
hbc
and
stuff
like
that
really
nice
to
know
about,
you
know
what
the
sites
really
need.
What
they're
doing
I
mean
I
understand
the
use
case
of
you
know
you
want
to
use
coop
flow,
you
use
argo
or
something
like
that
or
hell
you
don't
care
how
it
runs.
You
just
wanted
to
run.
I
But
yeah
you
hit
a
lot
of
the
complications.
I
mean
in
a
lot
of
cases.
You're
gonna
have
to
recompile
absolutely
everything
to
get
it
to
the
full
performance.
You
know
when
you're
jumping
from
your
laptop,
which
may
be
like
an
armed
chromebook
to
you,
know
a
zeon
box
or
something
like
that,
or
even
a
power,
eight
or
power
power,
one
power
where
we
power
ten.
Now
we
should
probably.
D
A
A
All
right,
so
this
is
coming
a
bit
to
what
nathan
was
just
referring,
which
is
how
our
container
image
is
built.
I
think
this
is
a
one
of
the
replies
I
had
for
him,
which
is
in
most
cases
we
don't
have
people
building
locally,
they
just
push
somewhere
and
there's
some
sort
of
ci
cd
that
will
build
for
multiple
architectures,
so
those
systems
here
we
get
gitlab,
jenkins,
tecton
and
then
manually.
A
A
A
I
D
Or
any
any
hard
issue
to
raise,
we
use
artifactory
we've
run
into
some
scaling
problems
with
it,
but
we've
recently
started
looking
at
dragonfly,
it's
like
a
sort
of
caching
yeah
and
it's
very
early
days,
but
it
looks
pretty
good.
Actually,
we
started
originally
looking
at
something
called
kraken,
which
I
think
was
out
of
uber,
but
it
seems
to
have
died
in
a
ditch.
So
then
we
sort
of
moved
sideways
onto
dragonfly
and
it
looks
pretty
good
and
that's
sort
of
taking
some
of
the
pain
away
from
mars
factory.