►
From YouTube: CNCF Research End User Group: Cilium and eBPF, Raphaël Pinson, Isovalent (September 21, 2022)
Description
Don’t miss out! Join us at our upcoming event: KubeCon + CloudNativeCon Europe in Amsterdam, The Netherlands from April 17-21, 2023. Learn more at https://kubecon.io The conference features presentations from developers and end users of Kubernetes, Prometheus, Envoy, and all of the other CNCF-hosted projects.
A
All
right
so
welcome
everyone.
We
are
finally
restarting
the
usual
the
regular
sessions
for
the
research
user
group,
and
this
was
a
topic
that
we
had
already
for
a
while
on
psyllium
and
evpf
that
had
been
suggested
before
and
we
got
Raphael
from
Isle
Island.
That
was
nice
enough
to
to
to
join
us
today.
So
we'll
have
a
presentation.
B
All
right
is
that
fine,
yep,
okay,
so
yeah.
Let's
talk
about
psyllium
I'll,
put
sodium
in
France
film
in
general,
sodium
evpf
and
the
tools
around
cellular.
So
my
name
is
Rafael,
so
I'm
a
Solutions
architect
at
isovan,
based
in
Switzerland
and
so
as
part
of
my
job
at
Solutions
Architects
that
you
customer
support
on
psyllium,
Hubble,
tetragon
and
I've
been
involved
with
with
chromatous
in
the
cncf,
where
several
years,
I
actually
co-organized,
as
cncf
Meetup
in
in
the
whole
monthly
part
of
Switzerland.
B
So
what
is
Cillian
these
days
with
Cecilia
means,
first
and
foremost
the
cni,
though
it
actually
started
before
kubernetes
was
widespread
or
even
announced,
I
think
so.
It
provides
the
the
Pod
to
pod
pod
to
service,
to
part
communication
even
node,
to
node
communication,
but
it
can
also
Implement
kubernetes
services
or
replacement
for
Q
proxy,
as
well
as
extra
features
such
as
multi-cluster
or
VM
Gateway,
which
is
an
extension
of
the
multi-cluster
feature.
B
On
top
of
this,
it
implements
Network
policies
using
either
the
standard,
kubernetes,
Network
policies,
resource
type
or
specific
Network
policies.
Crd
is
provided
by
psyllium
for
advanced
features.
It
is
identity
based,
and
this
is
something
very
important.
There
is
a
duplication
of
identities
that
happen
in
psyllium
both
for
performance
and
improves
the
visibility,
the
observability
layer
it
supports
encryption,
but
about
encryption
using
ipsec
or
Warrior
guide
and
there's
also
observability,
mainly
linked
to
the
Hubble
components,
providing
metrics,
providing
flow
visibility
and
service
dependency
in
the
form
of
a
service
map.
All.
C
B
B
Currently,
in
our
case,
the
Linux
kernel
in
the
future,
in
my
extent,
to
other
os's,
and
so
the
idea
is
that
you
can
have
many
programs
that
are
typically
injected
into
the
kernel
as
byte
code,
so
BPF
bytecode
are
usually
written
in
some
form,
some
subset
of
C
like
the
example
here
that
is
compiled
into
bad
code
and
then
inject
into
a
kernel,
and
then
the
kernel
will
verify
that
this
program
is
acceptable.
So
there
is
a
strict
verifier
that
verifies
for
both
security
and
stability
of
that
program.
B
And
then,
once
the
program
is
accepted
into
the
kernel,
it
will
be
compiled
into
a
machine
code.
So
so
it's
as
performant
as
the
kernel
itself
and
you
can
attach
it
to
different
events
in
the
kernel,
which
is
it
makes
a
lot
of
sense.
Given
that
the
kernel
itself
is
essentially
an
even
driven
program.
So,
for
example,
with
rdbpf
a
process
would
call
an
execd
Cisco
to
start
a
new
process
and
that
Cisco
would
be
scheduled
with
the
BP
apps.
B
B
There's
several
filter
applications
that
are
quite
natural
for
ebpf
observability
is
obviously
one
of
them,
because
you
get
to
observe
anything
that
happens
in
the
chronologic
forms
of
ciscals
or
k
probes,
your
probes,
lots
of
different
things
or
Network
events.
Another
field
of
application
is
security.
Obviously,
if
you
can
act
like
analysis
calls
even
block
them.
That
makes
a
lot
of
sense
and
the
last
one
is
networking.
I
see
the
last
one,
although
in
the
case
of
the
ceiling
project,
this
is
where
the
project
started.
B
Actually,
with
networking
it's
a
little
bit
less
obvious,
but
where's
the
bpfs.
You
can
also
bypass
some
native
Native
networking
Stacks
in
a
kernel
and
actually
re-implement
them
so
different
ways
in
which
EPF
programs
can
act
on
events
in
a
kernel.
So
you
can
typically
add
yourself
attach
yourself
to
events
such
as
a
file
being
read
or
the
I
o
reads
directly
on
the
disk
and
do
some
observability
or
some
action
on
this.
B
B
B
So,
at
the
moment,
when
we
talk
about
psyllium,
there's
essentially
three
products
that
are
part
of
the
psyllium
project
and
that
are
in
in
this
school
part
of
the
the
cncf
there's
psyllium
itself.
So
the
the
cni
and
networking
solution,
this
Hubble,
which
is
the
observability
component
and
tetragon,
which
is
the
most
recently
open
source
component
that
is
responsible
for
runtime
security
as
well
as
security
observability.
B
So
the
psyllium
networking
components,
the
cni
itself
is
responsible
for
the
networking
side
of
things,
ipv4
IPv6
integration
into
Cloud
providers
or
bgp,
if
you're
doing
on-premise,
typically
overlay,
so
there's
two
options:
either
direct
routing
using
bgp
or
overlay
using
vxlan
or
genev
srv6.
There's
special
features
such
as
egress
Gateway
and
multi-cluster,
the
possibility
of
doing
Nets,
4664
and
the
possibility
of
applying
Network
policies.
B
I
mentioned
this
a
bit
before
and
load
balancing,
which
can
be
done
actually
even
outside
of
kubernetes,
so
either
kubernetes
load,
balancing
as
a
replacement
for
Q,
proxy
or
even
outside
of
kubernetes
as
a
standalone
load
balancer
using
psyllium
as
a
container
in
Docker,
for
example,
and
on
top
of
this
because
we
see
all
the
traffic
going
through,
we
can
actually
add
a
lot
of
observability
so
observe
traffic
in
the
form
of
flows.
But
we
also
get
a
lot
of
metrics
from
all
these
components.
B
I'll
talk
a
bit
about
tetragon
here.
Tetragon
allows
to
plug
to
a
lot
of
different
kernel
events
and
actually
observe
what's
happening
there.
You
can
get
a
lot
of
observability
flows
from
there,
which
can
be
exported
to
the
same
of
your
choice
same
for
Hubble.
So
essentially
you
get
a
flow
of
Json
events
that
you
can
export
and
process.
B
That
is
still
done
on
this
layer
and
will
come
in
sodium
113n
and
following
so
next
next
release
and
following
so,
let's
dive
a
bit
into
the
networking
side
of
things.
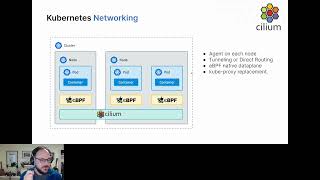
Typically
on
kubernetes,
there
is
no
default
Network
layer,
there's
only
a
standard
which
is
cni,
and
so
here
psyllium
can
replace
both
the
cni
layer
as
well
as
Q
proxy.
So
the
cni
will
be
part
to
part
intranode
enter
node
communication
and
replacing
Q
proxy
will
actually
implement
the
services
which
are
usually
implemented
using
iptables
or
ipvs
in
Q
proxy.
B
So
we
can
have
psyllium
take
care
of
all
of
this,
and
typically
instead
of
iptables
on
every
node
sodium
will
inject
evpf
programs
and
maps
to
to
implement
the
same
features
except
they
they
might
be.
It
might
be
a
little
bit
more
featureful,
because
evpf
programs
are
have
more
possibilities
than
just
iptable
rules,
so
there
is
sorry
I'll
get
back
to
this.
B
B
And
the
possibility
to
replace
QT
proxy,
typically
on
kubernetes,
when
you
have
a
service,
you
have
a
virtual
IP
that
works
as
an
lcl4
load
balancer
to
pause
in
the
back
end
points,
and
this
is
typically
implemented
using
iptibles
in
Q,
proxy
or
ipvs
and
with
IP
tables.
What
you
get
is
essentially
a
system
of
sieve
where
you
will
go
through
all
the
rules
before
you
find
the
role
that
is
proper
for
you.
That
applies
in
your
case.
B
The
whole
list
of
iptables
need
to
be
Rewritten,
whereas
with
an
evpf
based
approach,
we
can
have
hash
tables
that
will
link
directly
the
identity
instead
of
the
IP
address
the
identity
of
a
pod,
based
on
a
set
of
labels
that
are
known
from
kubernetes
by
the
edpf
program
and
based
on
this
identity,
you
can
link
directly
to
the
way
it
should
be
routed
to
another
Identity
or
if
this,
this
traffic
should
be
allowed
or
not.
So
typically,
both
routing
and
network
policies
can
be
implemented
in
a
much
more
performant
and
scalable
way.
B
One
of
the
examples
of
features
that
that
are
provided
in
psyllium,
that
is
interesting,
is
the
possibility
of
having
an
egress
gateway
to
access
a
workload
typically
a
database,
for
example
outside
of
the
kubernetes
cluster,
and
so
we
have
a
crd.
That's
called
egress
Network
policy,
psyllium,
not
policy.
Actually,
that
allows
you
to
Target
some
pods
in
the
comment
this
cluster
and
say
when
coming
from
the
spot
and
accessing
this
cider
outside
of
the
kubernetes
cluster.
B
I
want
to
go
through
this
specific
IP
or
this
specific
node
of
the
cluster,
and
this
allows
the
the
application
outside
of
the
cluster
to
know
to
to
recognize
the
IP
that
it's
coming
from.
So
typically,
if
you
have
a
firewall
in
front
of
this
application,
you
can
filter
on
this
IP.
Otherwise,
you
don't
know
exactly
which
IP
would
be
coming
out
right.
B
It
could
be
from
the
node
itself
or
it
could
be
directly
from
the
Pod,
if
you're
using
direct
routing,
but
it
would
be
really
hard
to
identify
which
application
is
reaching
out
to
this
external
application
outside
the
cluster
there's,
actually
a
mode
that
is
provided
in
the
isoville
NCM
Enterprise
distribution,
which
allows
for
high
availability,
egress
Gateway.
So,
instead
of
having
one
IP
to
exit
the
cluster,
we
have
several
and
sodium
can
load
balance
between
them
and
failover
as
well.
In
case
one
of
the
nodes
actually
is
not
available.
B
This
operator
also
has
a
role
to
do
some
garbage
quality
in
the
cluster.
In
the
case,
for
example,
one
node
is
removed.
Obviously
the
agent
on
this
node
is
not
there
anymore
to
remove
stuff
from
the
from
the
API
server,
so
the
operator
can
do
this,
there's
a
possibility
to
do
cni,
chaining,
so
using
one
cni
as
the
base
layer
and
then
deploying
psyllium
on
top.
Some
people
want
to
do
this.
B
It's
more
and
more
rare
I
would
say
the
typical
cases
because
they
don't
want
to
lose
possible
support
from
the
cloud
provider
by
using
something
else.
Fortunately,
psyllium
is
getting
more
and
more
common
and
supported
by
Cloud
providers,
so
it's
not
necessary
to
use
cni
chaining
anymore
in
a
lot
of
cases.
B
You
can
also
share
Network
policies,
so
typically,
you
can
have
Network
policies
with
labels
that
labels
that
typically
Target
one
or
the
other
clusters.
So
you
can
say
this
backend
from
this
cluster
is
allowed
to
talk
to
this
front-end
or
the
other
way.
Actually,
this
runtime
from
this
cluster
is
allowed
to
talk
to
this
backend
on
the
other
cluster,
and
this
allows
for
cross-cluster
Network
policies.
Encryption
can
also
be
extended
between
the
two
clusters,
as
well
as
obviously
routing,
otherwise
it
wouldn't
work.
B
Another
option
is
to
have
several
clusters
with
shared
services,
so
here
I
have
a
service
that
is
global
between
the
three
clusters,
but
I
don't
actually
have
pods
on
cluster
one
and
cluster
2
to
implement
it.
The
pods
are
only
on
the
shared
services,
cluster
and
typically
one
use
of
this
is
using
a
stateful
cluster,
where
I
have
like
a
database
running
an
icon,
easily
scale
this
cluster,
so
I'm
keeping
it.
B
It's
also
possible
to
integrate
with
service
mesh
so
typically
having
an
Ingress
in
front
of
each
cluster
and
then
making
sure
that
the
backend
service
is
always
accessible
using
either
the
local
pods
or
the
remote
pods,
and
in
the
latest
version
of
selenium
you
can
actually
specify
if
you
want
a
local
or
remote
Affinity.
So
if
you
have
a
local
Affinity,
you
will
say
preferably
one
access.
The
service
I
want
to
access
the
local
pods
on
my
cluster.
If
there's
no
such
bus
then
go
to
the
other
cluster
to
fulfill
the
service
access.
B
So
that's
the
case
for
remote.
It
looks
like
this:
it's
actually
a
normal
Service
definition,
except
it
has
annotations
for
Global
Service
and
for
service
Stephanie.
There's
actually
other
options
available
for
this.
Just
to
give
an
example,
let's
dive
into
security
like
I
said
security
is
very
important
in
psyllium
and
it's
clearly
based
on
identity
and
I've
shown
you
how
you
know.
Psyllium
can
use
a
concept
of
identities
that
is
native
to
it
and
that
Associates
labels
in
kubernetes
workloads
directly
to
their
identity.
B
This
identity
in
the
case
of
vxlan
can
actually
be
transmitted
encapsulated
into
the
the
network.
Packets
are
going
from
one
node
to
the
other,
so
that
the
identity
is
propagated
between
nodes,
typically
for
observability
and
network
policy
applications.
In
the
case
of
direct
routing,
it
works
a
little
bit
differently,
but
the
idea
is
that
every
time
something
a
network
flow
arrives
on
a
node,
there
is
a
knowledge
of
this
identity
which
allows
for
Advanced
observability
and
network
policy
enforcement
based
on
this
identity.
B
Based
on
this,
we
can
have
three
layers:
three
levels
of
Network
policy
application,
either
l3s
or
just
connection
between
two
pods
L4
connection,
plus
the
port
or
protocol
TCP,
UDP
and
L7,
which
allows
to
actually
parse
the
the
application
networking
layer
and
extract
the
the
protocol.
The
application
protocol
and
filter
on
this,
so
typically
you
can
allow
HTTP
get
on
slash
public.
That's
an
example,
and
in
this
case
it
will
actually
go
through
an
Envoy
proxy
provided
with
cilia
money
on
every
agent.
C
B
The
standard
things
like
pod
labels,
namespace
Services,
account
service
names,
cluster
names
as
well
when
using
a
cluster
mesh,
DNS
names
I
just
talked
about
this
ciders
either
external
Outsiders.
In
this
case,
Cloud
providers-
and
this
is
one
role
of
the
psyllium
operator-
is
to
actually
resolve
instance,
labels
or
subnets
or
security
group
names
into
ciders
and
and
logical
entities.
Logical
entities
can
be
the
host
on
which
the
Pod
is
running.
The
container
is
running.
Typically,
it
can
be
another
host
in
the
Clusters.
That
would
be
the
remote
node
entity.
B
B
So
this
is
an
example
of
the
Hubble
CLI.
So
here
we
have
some
Buzz
running
and
with
the
Hubble
CLI,
you
can
see
traffic
going
through
your
cluster.
So
here
we
see
the
DNS
lookup
that
a
pod
is
doing
to
core
DNS.
We
see
the
reply
in
UDP
and
you
see
the
IDS
that
are
associated
the
https
requests,
and
here
we
see
we
have
DNS
visibility.
B
B
So
this
is
the
the
CLI.
This
is
the
UI
for
Hubble.
This
is
the
open
source
version
of
the
UI.
The
isoville
slim
Enterprise
has
a
slightly
different
version
of
it
with
a
few
more
features,
and
essentially
this
uses
the
same
source
of
information
as
the
CLI
except
it
actually
builds
a
graph
of
dependencies
between
the
Bots
between
the
pods,
the
services
that
shows
how
they
actually
communicate.
So
here
you
only
see
gray
lines,
they
could
be
red
lines
as
well.
B
I'll
finish
the
psyllium
side
with
service
mesh.
This
is
the
extension.
This
is
where
we're
going
at
the
moment,
because
we
know
that
people
are
interested
in
this
part
and
psyllium
is
quite
low
level,
but
a
lot
of
people
are
interested
in
features
that
are
a
bit
higher
level
and
the
idea
is
that
synonym
already
has
a
lot
of
the
features
that
people
expect
from
service
mesh.
B
So
one
thing
we've
added
in
stone:
112
is
the
possibility
of
programming
the
envoy
proxy
that
is
already
provided
with
the
psyllium
agent,
using
a
crd,
so
cm112
provides
a
psyllium,
Envoy
config
crd
that
allows
to
program
your
the
envoy
proxy
on
every
node
using
logical
identity.
So
you
can
see
from
the
spots
to
this
Parts
I
want
to
apply
this
as
Envoy
configuration
and
one
layer
of
control
plane
that
we've
added
in
cm112
is
an
Ingress
controller
that
bases
itself
on
it.
B
So,
essentially
now
you
can
use
the
psyllium
Ingress
glass
if
you've
activated
Ingress
control.
Obviously-
and
this
will
human
Breath
class,
we
will
essentially
implement
the
Ingress
by
creating
an
envoid
configuration
dynamically
for
the
Ingress
for
a
specific
pod
in
the
future.
What
we're
adding
what
we're
currently
working
on
is
support
for
the
Gateway
API
and
support
for
species
for
a
form
of
mutual
authentication
directly
implemented
in
psyllium.
This
is
planned
for
113
for
the
next
major
release
of
psyllium.
B
You
can
already
use
these
two
with
psyllium
as
a
yeah,
sorry
as
a
novelty
on
top
of
psyllium,
but
we're
also
planning
in
the
future
to
integrate.
Istio
Society
uses
the
envoys
crd
natively,
as
a
as
as
the
implementation
for
for
the
Easter
abstraction,
instead
of
injecting
an
Envoy
proxy
into
every
pod
like
it
does.
Currently.
B
B
B
We
think
that
a
lot
of
the
features
and
service
meshes
today
that
started
at
as
libraries
that
you
had
to
use
in
your
application
for
instrumentation
are
now
at
the
external
implementation
in
the
form
of
sidecar's
step,
and
we
think
it
could
go
even
lower
into
the
kernel,
obviously
not
patching
the
kernel.
The
way
it
was
done
for
TCP
back
in
the
day
by
using
ebpf
to
inject
this
feature,
so
it
becomes
totally
transparent
for
the
users
and
it's
just
there,
observability
encryption,
Mutual,
authentication
and
so
on.
B
We
also
gain
a
lot,
obviously
in
performance,
because
instead
of
having
one
one
proxy
one
avoid
proxy
per
pod,
which
means
a
lot
of
Android
proxies
running
on
your
nodes.
If
you
only
have
one
per
node,
you
gain
a
lot
in
CPUs
and
CPU
and
RAM.
Typically
so
the
The
View
that
the
idea
is
whatever
we
can
do,
natively
any
BPF
would
try
to
do.
Native
Laney.
C
B
Including
observability
security
traffic
management,
because
we
gain
a
lot
in
performance
and
whatever
we
can't
do
natively
in
BPF,
we
can
still
use
an
external
proxy
for
it,
and
evpf
can
still
allow
to
directly
route
into
this
Android
proxy
provided
per
node.
So
are
we
still
getting
performance
compared
to
a
sidecar,
the
performances?
This
is
graph
that
Compass
performances
based
on
a
proxy
or
the
visibility
directly
in
a
kernel
using
an
EPF
note
that
some
of
the
the
sodium
projects
actually
use
directly
eppf
based
HTTP
visibility.
B
This
is
the
case
of
tetragon,
for
example,
and
it's
totally
possible
in
the
future.
We
might
actually
use
these
libraries
that
already
exist
to
parse
HTTP
or
other
layer,
7
protocols
directly
in
the
kernel
to
gaining
performance
again
so
last
point
on
tetragon
and
system
observability
and
enforcement.
So
tetragon
is
kind
of
a
compliment.
B
One
of
the
users
that
we
have
this
is
an
example
from
isavilion
selum
Enterprise,
where
we
have
a
process
to
review
that
has
existed
for
many
years,
where
we
have
a
correlation
between
what's
actually
running
into
inside
a
container
and
the
network
flows
that
result
from
it.
So
maybe
you
see
in
Hubble
hey.
There
was
a
connection
to
this
weird
thing
here,
something
that
not
reverse
shell.com,
which
is
definitely
not
a
reverse
shell
right
and
you
want
to
see
where
it
came
from.
B
You
know
in
Hubble
that
it
came
from
this
pod
and
so
and
this
view
here,
you
can
actually
look
into
this
box,
see
exactly
what
was
executed
in
the
spot,
that
she's
a
citric
on,
and
you
can
see
that
five
minutes
after
this,
the
the
server.js
standard
application,
the
container
started.
There
was
a
shell
that
was
started
and
an
NC
and
then
a
curl
that
connected
to
elasticsearch-
and
you
can
say:
okay,
there's
something
fishy
here,
but
at
least
you
have
a
trace
of
what
was
executed
and
what
gave
what?
B
A
D
Have
any
specific
questions
but
I've
seen
that
before
and
it's
really
really
exciting.
We
are
planning
to
I,
think
you
probably
know
already
actually
in
gr
planet
to
use
it
usually
and
we've
had
to
Implement
some
very
basic
features
ourselves
previously,
and
this
will
allow
us
to
get
rid
of
all
of
that
sort
of
accumulated
sector
I
suppose
but
yeah
it
looks
really
really
powerful.
So
it's
done.
D
Well,
there's
a
few
things
we
want
it
for
I
mean
we
haven't
implemented
this
or
something
some
got
a
solution
for
it,
but
really
basic
stuff
like
it's
not
basically
but
being
able
to
see.
You
know
real
product,
real
Source,
IPS
and
that
kind
of
stuff
for
our
traffic
I
mean
it's
got:
clusters
the
tetrachon
stuff's
really
exciting,
because
we
can
use
that
we've
got
a
lot
of
requirements
around
that.
The
things
we
have
implemented
ourselves
are
more
around
the
sort
of
service,
meshy
kind
of
stuff.
D
So
the
concept
like
egress
gateways
and
that
kind
of
thing
with
we
use
Envoy
ourselves
and
figure
it
to
do
this
kind
of
thing
and
then
I've
also
seen
them
seen
them
over
the
whole.
Almost
like
a
sort
of
Global
Network
policy
thing
working
across
clusters,
which
is
really
exciting,
but
we've
had
to
come
up
with
I
guess:
we've
pieced,
This
Together
ourselves
as
existing
kubernetes,
Primitives
and
cncs
stuff,
and
having
something
like
this,
which
wraps
it
all
up
for
us
as
a
attractive
proposition.
D
A
Yeah,
so
actually
we
we
discussed
with
Raphael
very
recently
about
this
as
well,
but
the
one
of
the
main
things
that
we've
been
looking
at
is
the
possibility
of
doing
cluster
mesh,
and
this
is
for
because
we
still
push
for
people
to
have
this
kind
of
disposable
clusters
and
to
have
applications
deployed
across
multiple
clusters
instead
of
having
clusters
that
need
to
be
upgraded
in
place,
and
things
like
this
and
for
stateful
workloads.
This
is
this
can
be
problematic.
A
So
we've
been
looking
at
cluster
mesh
to
kind
of
expand
the
boundaries
cross-cluster,
which
should
allow
us
to
potentially
do
to
use
this
model
even
for
things
that
have
staple
workloads,
running
like
databases
or
I.
Don't
know
we
have
some.
We
have
some,
even
even
for
like
batch
or
ml,
where
you
have
long
running
jobs.
A
C
A
A
E
B
E
Able
to
just
it's
sort
of
like
yeah,
so
admiralty
sort
of
like
the
ability
to
Federate
clusters,
so
you
know,
run
one
workload
from
one
cluster
into
another.
What
sounded
like
that?
There
was
a
lot
of
those
types
of
features
to
provide
some
sort
of
federation.
The
use
case
I'm
looking
at
is,
is
sort
of
like
on-prem,
Cloud
bursting
type
things
where
you
know
you
have
an
on-prem
cluster,
and
then
you
provide
a
cloud
versing
capability
and
sort
of
Stitch,
those
together
in
in
some
sort
of
manner.
E
D
I'm
not
going
to
answer
that
actually
I
know
I.
Think
admiralty
was
more
around
sort
of
Federated
deployment
of
applications
rather
than
accessing
them.
So
that
would
be
your
single
pane
of
glass
to
deploy
something
that
replicated
and
lost
different
clusters.
Environments,
we're
sitting
there's
more
around
but
I
suppose
the
cni
and
the
network,
access
to
Publications
decisions
get
a
post
deployment.
I,
don't
think
silion
does
any
kind
of
deployment
of
applications
for
you.
E
A
So
actually
that
was
the
other
point.
I
wanted
to
say
that
we
are
looking
at
and
I
already
mentioned
it
to
Raphael,
which
is
exactly
that.
It's
the
ability
to
do
sort
of
cluster
mesh
across
regions
or
data
centers,
which
means
that
you
won't
have
necessarily
no
do
not
connectivity,
because
you
might
not
have
a
VPN
or
something
that
will
allow
this.
The
way
admirati
I'm,
also
not
an
expert.
A
A
Yeah
but
it,
but
it's
it's
really
targeting
not
only
the
services
but
also
the
kind
of
patch
workloads
where
you
can
submit
pods
to
a
cluster
that
then
the
actual
workloads
run
in
a
remote
cluster
and
they're
kind
of
attract
through
Parts
in
local
clusters
with
with
children.
Potentially
we
could
do
this
transparently
at
the
cluster
level,
like
we
do
with
cluster
mesh,
but
we
would
need
this
kind
of
cross-boundary
communication
without
necessarily
have
a
VPN
or
something
like
that.
I
think
that's
kind
of
Timothy
to
use
k0,
so
yeah.
E
A
C
A
A
D
D
B
C
D
D
I've
seen
in
the
past
with
products
where
actually
it's
sometimes
the
most
annoying
thing
about
using
the
Enterprise
Edition,
even
though
you
beat
them
apart
from
paying,
for
it
is
oh
and
then
you
have
to
provide
license,
keys
and
set
up
some
complex
infrastructure,
especially
if
you're,
on-prem
and
don't
have
internet
access.
Then
it
all
gets
a
bit
difficult.
But
that's.
A
D
A
C
A
So
I
I
guess
I
was
just
trying
to
summarize
What
the
main
motivations
are
from
from
from
this
community
to
to
move
to
ceiling
and
I
guess
the
ones
we
we
got
here
were
the
ability
to
do
cluster
mesh,
potentially
doing
a
hybrid
bursting
things,
and
then
Jamie
you
mentioned,
because
you,
you
have
quite
a
lot
of
clusters
as
well.
Is
this
something
that
you're
also
looking
at.
D
D
D
C
A
E
A
D
B
With
the
external
beat
I
couldn't
I
couldn't
say
at
the
moment,
one
thing
I've
seen
was
keeping
the
Source
IQ,
but
that's
that's
kind
of
a
different
situation
that
what
you
have
is
the
possibility
of
actually
doing
routing
directly
or
keeping
the
IP
address
when
accessing
the
the
service
and
there's
two
ways
of
doing
this.
So
there's
either
a
DSR
or
what
was
the
other
one
I,
don't
remember.