►
Description
For more Continuous Delivery Foundation content, check out our blog: https://cd.foundation/blog/
A
Thank
you.
Let
me
know
when
the
recording
is
is
started,
so
we
can
go
ahead.
It
should
be
ongoing
now,
nice.
So
back
in
november
2019,
I
was
asked
to
create
an
overview
of
our
continuous
delivery
system,
and
this
was
in
the
autonomous
drive
department
at
volvo
cars.
So
it's
like
quite
a
complex
project.
A
Some
of
these
components
are
things
you
recognize
like
jenkins
and
garrett
and
nexus,
and
things
like
that.
Some
other
components
are
more
like
configuration
files,
but
around
25
of
these
components
were
basically
glue
code,
so
code
serving
no
other
purpose
than
just
making
things
work
together.
Making
different
systems
talk
to
each
other,
making
different
types
of
configuration,
files,
understandable
by
different
systems,
etc,
etc.
A
C
B
B
A
Yes,
and
my
name
is
eric
sanescham,
I
work
with
continuous
in
integration
and
delivery
at
do
well
and
mainly
with
high
complexity,
products
with
embedded
parts
like
autonomous
drive
and
mobile
broadband
networks
and
stuff,
like
that.
I'm
also
a
member
of
the
same
event
group
that
andrea's
co-chair
of
and
I'm
also
a
maintainer
of
the
city
events
specification.
B
A
Continuous
delivery
serves
the
purpose
of
frequently
getting
your
whole
product
ready
for
release,
so
in
its
widest
form,
it's
not
just
like
emerge,
build
deploy.
It
can
go
all
the
way
from
an
initial
idea
to
helping
you
break
down
that
idea
into
developable
parts,
helping
you
build.
Those
parts
verify
them
test
them,
deploy
them
and
get
measurements
out
of
it
and
then
feedback
to
the
initial
idea,
and
with
this
very
wide
scope,
it
becomes
too
much
for
any
single
system
to
solve.
A
So
I
mean
I
think,
instead
of
trying
to
build
a
system
that
solves
all
of
these
problems,
we
should
instead
focus
on
integrating
systems
with
each
other.
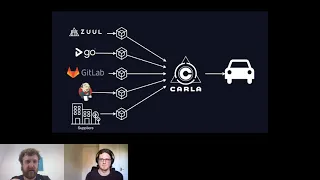
So
this
is
a
picture
that
just
shows
a
bunch
of
the
projects
that
are
in
the
open
source
in
the
continuous
delivery
area.
Some
of
these
projects
are
more
related
to
cloud.
Some
of
them
are
a
bit
more
generic,
etc,
but
in
a
typical
high
complexity
project,
a
lot
of
these
or
several
of
these
will
at
some
point
need
to
be
integrated
with
each
other
yeah.
A
So
if
we
then
say
that
we
now
have
a
shared
understanding
of
continuous
delivery,
at
least
a
quick
one,
so
again
focusing
on
getting
things
ready
to
be
released,
then
we
can
go
ahead
and
talk
about
continuous
delivery
events,
so
in
a
continuous
delivery
pipeline
or
in
all
types
of
pipeline,
typically
valuable
things
happen.
That's
the
purpose
of
having
the
pipeline.
A
You
want
to
produce
some
form
of
value
or
realize
some
form
of
value,
and
the
idea
between
or
behind
events,
then,
is
that
when
something
valuable
has
happened,
you
announce
it
so
the
system
or
script
or
tool
that
is
responsible
for
creating
this
valuable
happening
should
announce
it
and
then
typically
on,
like
a
message,
bus
or
something
similar,
but
send
an
event
that
announces
that
something
valuable
has
happened,
and
it's
not
just
like
builds
and
deployments.
It
can
be
all
kinds
of
things
that
are
valuable,
so
you
have
a
code
change.
A
You
can
have
a
test
results.
You
can
have
a
new
test
environment
coming
up
or
new
deployment
environment
coming
up.
You
can
have
a
failure
in
some
system.
That
is
also
at
least
valuable
to
know
about.
Maybe
it
doesn't
have
a
value
on
its
own,
but
yeah
and
remediation
kicking
in
and
things
like
that,
so
yeah,
a
lot
of
things
are
valuable.
A
So
this
would
be
one
side.
The
other
side
would
be
that
a
system
that
sees
something
interesting
happening
like
something
valuable
has
happened.
We
get
an
event
now
we
can
react
to
it
and
again
there
are
many
different
things.
We
could
yeah
different
reactions.
We
could
choose
so
it
could
be,
for
instance,
yeah
running
some
remediation
action.
A
B
A
A
B
So
in
early
2021
we
transformed
the
work
stream
into
a
special
interest
group
of
its
own
and
then
later
towards
the
end
of
the
year.
The
cd
event
project
was
created
to
hold
the
specification
work
done
by
the
sig
itself,
so
the
project
was
then
proposed
as
a
cdf
incubating
project
and
accepted
in
december
2021.
B
Yeah,
so
most
cd
platforms
define
their
abstraction
or
data
model
with
their
own
nomenclature,
as
eric
mentioned
they're,
not
always
the
same,
so
the
interoperability
sig
has
already
been
collecting
these
from
various
platforms.
Many
names
are
shared
across
platforms,
sometimes
name
the
same
name,
various
different
meaning
in
different
projects.
B
So
to
achieve
interoperability
for
events,
we
need
to
define
a
nomenclature.
We
share
semantics
across
the
platforms
to
achieve
that,
we
created
first
four
buckets
to
group
the
different
events.
The
list
that
we
have
today
is
not
meant
to
be
exhaustive,
as
we'd
like,
eventually
to
cover
more
aspects
of
software
life
cycle
like,
for
instance,.
B
B
So
now,
with
the
vocabulary
defined,
the
next
step
has
been
to
define
which
events
are
available,
for
which,
for
each
abstraction,
for
instance,
a
pipeline
run
can
be
queued,
started
and
finished.
An
artifact
will
be
either
packaged
or
published.
So
each
event
as
mandatory
and
optionally
filled
as
well.
We
are
also
evaluating
different
extension
mechanisms
to
allow
two
kind
of
extensions
documented
third-party
fields,
as
well
as
freestyle
content
that
might
be
added
by
a
specific
platform.
B
Now,
since
there
are
plenty
of
established
messaging
protocols
already
available,
we
didn't
want
to
reinvent
the
wheel.
Instead,
we
had
been
working
at
identifying
which
fields
are
required
for
the
continuous
delivery
use
cases,
and
then
we
defined
protocol
bindings,
which
map
cd
events
onto
a
specific
transport
protocol
cloud
events,
which
is
a
cncf
project,
is
an
established
format
in
the
cloud
native
space
and
that's
the
first
binding
we
defined.
B
So
to
sum
it
up,
we
have
cd
events,
fields,
mandatory
fields,
optional
fills
and
those
are
bound
onto
cloud
events,
transport.
So,
finally,
as
part
of
the
specification,
we
started
working
on
a
cd
events,
primary
document
which
documents
the
protocol
architecture,
design
decisions,
as
well
as
reference
use
cases.
B
And
use
cases
are
key
to
the
development
of
the
spec
of
cd
events,
so
when
we
define
events
and
their
fields,
we
ask
the
question:
what
is
a
minimal
set
of
information?
What
is
the
minimal
set
of
information
that
we
need
to
satisfy
these
use
cases,
and
there
are
two
use
cases
which
we
identified
until
now.
A
A
So
if
I
can
bring
you
into
my
world
for
a
minute,
one
of
my
main
goals
in
my
day-to-day
job
is
to
make
sure
that
we
can
build
a
car,
and
a
car
today
has
hundreds
of
or
at
least
over
a
hundred
embedded
systems
in
it
and
on
embedded
systems.
You
typically
run
software,
so
there's
probably
at
least
a
thousand
different
software
modules
running
in
an
autonomous
drive
vehicle,
so
making
like
getting
from
an
individual
software
module
through
all
the
integrations
and
combinations
and
variants
to
a
working
car
is
not
trivial.
A
So
there
are
many
systems
that
can
help
us
orchestrate
builds
and
different
teams
may
want
to
use
different
systems
or
solutions
because
it
fits
their
needs
best
and
they
have
the
right
experience
or
the
right
setup.
So
some
teams
may
want
to
use
zuul
because
it
has
really
nice
dependency
handling
and
it
scales
really
well.
A
A
Some
teams
want
to
use
jenkins
because
it's
easy
to
use
and
it
has
loads
and
loads
of
plugins,
which
makes
it
powerful
and
of
course,
a
modern
car
is
not
only
built
by
in-house
software
development
teams.
You
also
have
suppliers,
but
what
is
common
for
all
these
is
that
they
produce
built
software
modules.
A
A
So
now
it
sort
of
looks
like
we
already
have
what
we
need
to
to
get
things
to
work
together,
but
unfortunately
that's
not
the
case,
because
if
you
look
into
it,
then
zul
has
its
own
definition
of
an
artifact
go
cd.
While
it
also
calls
it
an
artifact
has
its
own
definition,
its
own
set
of
metadata,
its
own
own,
like
life
cycle
and
properties,
and
so
on
and
so
forth,
and
the
same
is
true
for
the
others
as
well.
A
Based
on
on
experience,
I
can
say
that
many
companies
and
organizations
are
spending
a
lot
of
effort,
just
writing
new
code
making
things
work
together,
because
there
is
no
standardized
way
or
commonly
accepted
way
of
announcing
when
valuable
things
happen
and
reacting
to
valuable
things.
Having
happened.
A
A
We
would
like
all
these
different
systems
to
produce
cd
event,
style,
artifacts
or
at
least
have
that
as
an
option
and
as
a
like
a
parallel
track,
so
that
even
if
soon
wants
to
keep
using
their
own
artifact
definition.
If
they
can
also
send
cd
event
style
artifacts,
then
we
can
try
to
or
we
can
start
to
get
things
working
together.
B
So,
let's
consider
the
following
cd
setup:
where
code
is
written
and
maintained
in
gita,
for
instance,
and
when
changes
are
made,
they
go
through
different
tests
maintained
by
different
teams
which
use
different
technologies.
Some
tests
are
running
in
github
directly
as
github
actions.
For
instance,
some
other
are
executed
in
jenkins
and
other
again
are
techn
pipelines
and
releases
in
our
setup
are
managed
to
protect
them
as
well,
while
deployments
are
managed
with
argo
and
finally,
captain
is
used
to
manage
remediation
strategies
on
production
clusters.
B
B
And
if
all
platforms
supported
the
same
format
of
events
like
cloud
events,
our
event
collector
could
become
just
a
single
one.
One
existing
broker,
like,
for
instance,
native
eventing,
could
be
used
there
so
going
back
to
the
end-to-end
workflow,
though,
if
we
wanted
to
visualize
the
flow
of
a
change
from
when
it's
written
for
test
release,
deploy
and
possibly
roll
back,
we
need
to
have
enough
information
in
the
events
to
be
able
to
correlate
them
with
each
other,
and
this
is
one
of
the
issues
that
we
want
to
address
with
cd
events.
B
Another
question
that
we
may
want
to
be
able
to
answer
is
how
effective
is
the
devops
setup
in
my
organization
and
to
answer
that
you
would
need
to
define
metrics,
collect
the
relevant
data
and
visualize
it.
So
cd
events
may
help
collecting
the
data
from
ethereum
sources,
store
it
and
process
it
in
a
consistent
way.
B
B
B
B
B
So
today
we
are
working
on
golang,
java
and
python
and
we
plan
to
work
as
well
on
one
or
more
pse
to
validate
our
solution
and
finally,
which
is
critical
to
the
success
of
cd
events.
We
will
implement
and
promote
the
implementation
of
cd
events
in
existing
tools
and
services
so
that
you
can
natively
get
cd
events
out
of
the
tools
that
you
use
today
in
your
workflow.
A
Nice,
so
we
reached
the
end
of
this
presentation
and
we
wanted
to
summarize
a
little
bit
before
we
move
on
to
the
more
open
discussions
in
a
few
minutes
or
in
a
minute.
So
what
we
would
like
you
to
take
away
from
this
presentation,
one
cd
events,
it's
a
specification
that
aims
to
provide
or
enable
interoperability
on
observability
in
the
continuous
delivery
ecosystem.
A
But
of
course,
it
needs
to
be
integrated
into
existing
or
new
tools
to
actually
provide
any
value.
So
that
is
not
something
that
that
our
the
specification
group
is
going
to
be
able
to
do
all
on
our
own.
Even
though,
as
andrea
mentioned
before,
we
have
already
gotten
some
good
support,
and
we've
done
some
work
ourselves
to
work
on
both
sdks
and
integrations
into
existing
systems,
but
to
to
actually
provide
interoperability
and
observability.
C
A
So
with
that
andrea-
and
I
would
like
to
thank
you
so
much
for
for
listening
to
us-
and
we
really
want
cd
events
to
be
something
that
helps
you.
So
we
need
to
understand
your
use
cases.
We
need
your
support
to
integrate
the
specification
into
existing
tools
and
yeah.
We
really
want
you
to
get
in
touch,
so
we
can
can
talk
more.
A
D
D
A
A
Cars
where,
like
when
I
joined
in
like
2017
the
release
process
for
many
of
these
things,
was
put
a
file
in
sharepoint
and
send
an
email,
and
that
means
something
is
released,
and
that,
of
course,
does
not
bode
well
for
any
type
of
automation
or
any
type
of
collaboration
really
so
moving
that
over
to
okay.
But
the
our
release
statement
is
when
we
send
this
event.
A
Now
we
have
tested
it
this
far
and
now
we
have
tested
it
this
far
and
now
we
have
tested
it
this
far,
and
that
can
then
mean
that
different
teams
can
react
earlier.
Okay,
we
don't
actually
need
this
to
be
fully
validated.
We
just
need
this
part
to
be
validated.
So
when
we
get
the
event
that
that
part
has
been
validated,
then
we
take
this
delivery
and
start
working
on
it.
C
A
A
D
A
B
Just
wanted
to
add
something
on
the
first
question
before
you
went
so
and
in
in
the
context
of
tecton,
I
started
thinking
about
this
as
well,
because
there
we
have
one
component,
which
is
called
tecton
chains,
which
kind
of
works
out
of
band.
So,
while
you're
running
your
pipeline,
it
watches
your
pipelines
and
it
does
automatically
automatic
signing
of
your
container
images
that
you're
building
and
it
produces
at
the
station.
B
B
What
I
would
need
is
to
use
events
so
that
events
that
tell
me,
for
instance,
that
the
image
has
been
signed
or
at
the
station
has
been
produced.
So
if
I
had
those
event,
I
could
use
those
to
start
my
release.
Note
generation
instead,
so
that's
something
that
definitely
I
plan
to
raise
and
look
into.
A
Yeah
yeah,
yes,
so
the
second
part
of
the
question
was:
do
you
have
plans
to
look
at
other
tools
that
are
not
traditionally
considered
as
ci
cd
tools
like
artifact
repositories
and
test
frameworks?
For
me,
the
answer
would
be
absolutely
yes,
because
at
least
the
way
I
would
see
it.
I
would
like
even
like
manually,
triggered
test
activities
or
manual
test
activities,
for
instance,
should
also
cause
events
to
be
sent.
Deliveries
coming
in
from
a
supplier
to
an
artifact
repository
should
also
cause
events
to
be
sent,
so
I
don't
think
it.
A
We
should
limit
ourselves
to
just
like
focusing
on
on
things
like
zul
and
jenkins,
and
things
like
that,
but
make
sure
that
we
have
messages
or
event
definitions
to
support
the
whole
the
whole
flow.
That
would
be
my
my
view,
at
least,
but
I
guess
to
start
with,
we
would
be
focusing
on
the
more
traditional
cic
tools
just
to
have
a
good
good
starting
point,
or
what
would
your
other
people.
D
Say
I
agree
and
I
think
we
yeah
we
should
focus
on
the
core
events.
First,
of
course,
the
ones
that
are
needed
to
build
up
the
pipeline
and
to
inform
what
happens
in
the
pipeline
itself
on
the
on
some
level.
But
then,
of
course,
we
could
go
arbitrarily
deep
into
test
frameworks,
and
we
could
also
look
at
the
surrounding
systems
which
deliver
things
to
the
pipeline
or
which
take
results
from
things
happening
in
the
pipeline
and
somehow
leverage
on
those
and
make
even
better
results.
D
C
Yeah,
so
basically,
I've
seen
this
happening
several
times
when
we
try
to
create
any
kind
of
like
real
integration
with
this,
and
I
think
that
it
was
something
that
we
were
discussing
with
andrea,
like
that.
Tecton
is
in
a
very
specific
place
because
it
has
tecton
triggers
it.
It
has
a
very
different
set
of
mechanisms
to
basically
accept
incoming
events
and
then
do
something
about
it
right,
like
they
have
that
wiring
mechanism
that
most
of
other
tools
out
there
they
will
not
have
so.
C
The
problem
that
I'm
having
right
now
is
that
when
we
are
integrating
multiple
tools
together,
we
see
that
in
the
vocabulary
we
have
expressed
all
the
events
that
can
be
produced
by
these
different
tools
right.
So,
if
you
are
an
environment,
you
are
going
to
be
able
to
produce
these
events
and
that's
basically
what
we
have
in
the
vocabulary.
C
If
you
are
like
a
pipeline
engine,
you
are
going
to
be
able
to
produce
all
these
events,
but
on
the
other
side
on
the
consumer
side
like
we
haven't
defined
anything-
and
I
think
this
is
kind
of
like
what
my
my
issue
is
all
about.
It's
all
about,
if
you
think
about
components,
exposing
their
internal
state,
you
know
to
other
systems,
so
they
can
integrate.
C
What's
not
defined
right
now,
or
at
least
we
don't
have
like
a
clear
semantic
way
of
saying
things
about
like
what
about
when
we
want
to
listen
for
events,
so
we
can
do
something
inside.
You
know
inside
of
our
tools,
and
I
know
that
it's
a
little
bit
convoluted
and
it's
very
difficult
to
explain
like
how
it
works,
but
we
can
go
through
concrete
examples
of
integrations
just
to
try
to
figure
out
if
this
is
something
that
we
want
to
add
in
the
vocabulary
or
not.
A
So
the
way
we
solve
this
in
volvo
cars,
for
instance,
I
think
iphone-
does
the
same
thing
is
so
they.
Basically,
there
are
two
different
strategies.
You
can
either
push
an
action
saying
that
this
should
happen.
I
don't
know
who
will
do
it,
but
this
should
happen
or
you
can
pull
to
say
this
thing
that
I'm
interested
in
has
happened
so
now.
I
should
go
ahead
and
do
my
stuff-
and
I
recall
that
we
have
had
such
discussions.
Well.
A
Records
has
definitely
gone
for
the
pull,
so
they
have
a
system
that
where
you
can
define
rules
like
when
this
type
of
value
is
produced,
kick
off
this
this
action
or
make
this
http
request
or
whatever
you
want
to
do
so
an
example
would
be
yeah
a
build
has
finished
or
some
tests
activity
has
finished
with
a
successful
result.
Then
we
want
to
kick
up
the
next
thing
but
yeah.
So
there
we
don't
have
those
push
events,
we're
not
saying
this
should
happen,
but
just
this
has
happened.
C
That's
that's
why
I
collect
the
requested.
Part
of
thing
of
the
event
is
like
important,
because
we
are
just
by
sending
that
event.
Basically,
the
only
thing
that
we
are
expressing
is
that
somebody
requested
something,
but
that
nothing
nothing
needs
to
actually
happen
until
somebody
is
ready
to
process
that
event.
Do
you
see
what
I
mean?
So
this
is
more
for,
like
the
like,
a
piste
in
the
middle
who
is
doing
the
integration.
A
So
so
this
would
then
be
useful,
I
guess
primarily
in
in
some
sort
of
system
where
you
have
like
a
central
orchestrator.
Maybe
that
says:
okay,
this
has
happened
now.
I
need
to
request
this
thing
without
actually
being
able
to
know
who
will
will
run
this,
and
I
think
maybe
captain
is
something
like
that
right.
I
think
it
requests
with
a
message
and
then
it
has
services
listening
for
that
and
that
type
of
of
yeah
handling
those
incoming
requests.
So.
C
Yes,
captain
is
a
very
generic
orchestrator
of
events
that
actually
do
that.
I
think,
at
least
in
my
perspective,
that's
exactly
what's
happening
there,
but
in
this
case,
at
least
from
the
vocabulary
point
of
view
and
for
the
integration
point
of
view
it
can
be,
it
can
be
the
case
that
you
can
have
multiple
of
these.
You
know
orchestrators
that
are
listening
for
different
type
of
events,
so
it
doesn't
actually
need
to
be
something
centralized.
It
can
be.
You
know
a
number
of,
like
you,
know,
components
that
are
in
charge
of
integrating
different
systems
together.
A
B
That
needs
to
happen
so,
at
least
in
in
my
mind,
if
we
go
down
to
the
request
path,
it
means
that
it's
the
source
that
defines
what
will
happen
eventually
when
someone
is
able
to
trigger
it,
but
still
it's
a
source.
That
kind
of
controls
so
like
gary,
was
saying
it's
more
events.
That
kind
of
tell
you
what
you
want
to
happen,
rather
than
declaring
what
has
happened
if
it
makes
sense
yeah
it's
it's
a
different.
C
B
C
Let's
yeah,
so
let's
remove
tecton
from
from
the
picture
right,
because
I
think
that
tecton
again
is
like
in
a
very
specific
place.
You
have
kind
of
like
that
mechanism
before
doing
the
wiring,
which
in
other
projects
you
will
not
have
so
imagine
that
I
think
that
even
we
have
it
there,
like.
You
know,
imagine
that
you
know
we
create
a
cluster
right
like
with
crossplane,
and
then
we
are
just
emitting
those
events
right
like
a
cluster
was
created
and
the
cluster
is
ready
right.
C
D
Yeah
yeah
and
that
push
setup
or
that
that
consumer
events
then
would,
as
I
see
it,
doesn't
really
need
to
use
events.
Of
course,
it
could
use
events
to
to
propagate
the
information
towards
the
actual
deploy
it,
but
it
could
also
do
a
direct
call
because
that's
in
a
sense
what
it
would
be,
it's
like
an
rpc
called
morris
from
from
one
producer
of
the
information
to
the
consumer,
which
would.
C
C
Yes,
I
think
that
that's
that's
okay,
but
at
that
point
right,
like
you,
can
always
do
a
direct
call
to
the
deployer's
employment
right,
but
at
the
same
time
you
are
not.
You
are
going
to
be
like
in
some
way
in
some
way,
hard-coding
kind
of
like
the
one
that
is
consuming
that
event.
So
there
is
needs
to
be
a
component
that
will
listen
for
that
cluster
created
event,
and
then
it's
going
to
basically.
C
C
If
we
do
a
direct
call,
then
there
is
a
single
thing
happening
if
we
admit
an
event
with
the
intention
of
the
things
that
we
want
to
happen,
then
multiple
systems
can
pick
it
up
and
do
different
things
in
parallel,
and
I
think
that
that's
kind
of
like
where
we
were
going
where
we
were
going
with
that
right.
If
not,
we
will
just
go
into
this
kind
of
like
messy
situation
of
kind
of
like
hard
coding.
C
What
happens
for
that,
and
also
making
sure
that
you
know
there
is
no
point
in
the
deployer
service,
for
example,
to
listen
for
cluster
created
events
right,
because
that
would
be
kind
of
like
again,
like
just
for
a
particular
use
case,
for
a
very
particular
use
case
that
you
know
the
service
is
not
even
interested
in
knowing
about
that
use
case.
The
service
know
how
to
do
a
deployment
and
will
probably
emit
events
about
deployments.
But
it's
not
interested
about
like
cluster
creations.
A
C
D
C
D
C
To
check
because
I
think
that
that's
I
think
that's
so-
but
that's
kind
of
like
a
different
interpretation
from
the
cute
events,
then,
which
is
fine
but
for
example,
yeah.
So,
for
example,
we
have
like
environment
created,
modified
and
deleted,
but
we
don't
have
like
environment
cube
for
somebody
else
to
go
and
pick
it
up
and
actually
create
an
environment.
A
Absolutely
so,
I'm
thinking
just
to
throw
something
out
there
would
this
be
a
possible
extension
to
the
cd
events
specifications.
So
we
have
like
the
core
protocol
is,
is
only
for
like
announcing
when
the
value
has
happened,
like
activity
started,
activity
finished,
build
started,
we
finished
et
cetera,
and
then
we
have
an
extension
which
provides
a
set
of
of
events
for
actually
requesting
things.
D
Yeah,
but
I
don't
know
if
we
need
that,
actually,
because
I
mean
we
have
the
queued
events,
we
have
in
the
activities
that
we
support.
We
have
build
queued
and
we
have
test
case
queued,
for
example,
and
then
we
have
of
course
build
start
and
build
finished
and
test
case
started
and
finished.
So
why
shouldn't
we
have
a
deployment
queued
as
yes
as
we
have
the
deployment
started
and
deployment
finished
in
the
core
specification.
I
think
that
fits
well
there.
A
Need
to
add,
because
that
might
be
a
misunderstanding
from
my
part,
because
I
I
I
have
sort
of
looked
like
at
queued
as
the
the
actual
thing
that
will
run
has
it
declares
that
it
has
received
the
request,
but
it's
not
able
to
start
doing
anything
yet.
A
typical
example
is
again
a
deployment
type
thing
where
you,
you
need
a
specific
type
of,
or
you
get
the
new
firmware
delivered
to
you.
So
you
pick
up
the
the
firmware
artifact
published
event
or
whatever
we
call
it,
and
then
you
say:
okay,
I
have
written
this
event.
A
I
am
now
putting
myself
in
a
queue
because
there
is
no
suitable
test
environment
for
me
to
run
this,
so
I
mean
I'm
in
queue,
I'm
not
doing
anything,
but
I'm
cute.
That
means
that
visualization
software
can
say.
Okay,
there
is
like
a
queue
icon
here.
This
pipeline
is
not
doing
anything,
but
it's
waiting
for
something
to
be
available.
A
Then,
when
I
actually
start,
I
send
the
start
event,
and
then
this
visualization
can
turn
into
a
spinning
wheel
or
whatever
it
wants
to
do,
and
then
I
fill
it
with
another
event.
But
of
course,
it
would
be
possible,
as
you
said,
email
to
use
the
same
event
to
declare
that
something
should
happen.
I'm
just
a
little
bit
worried
that
that
we
start
mixing
things
up
and
it
becomes
unclear
what
that
event
actually
means.
D
Yeah,
but
I
I
didn't
intend
to
make
it
unclear,
I
mean
if
we
would
compare
compared
to
the
jenkins
job,
an
old-fashioned
jenkins
style
job
where,
where
you
put
your
execution,
I
mean
you
to
trigger
a
job
on
something,
then
it
is
put
in
the
queue
and
then
it's
it's
executed
and
when
you
execute
executed,
you
would
then,
in
that
months
and
the
start
and
the
finished
event,
if
you
would
consider
a
jenkins
server
just
being
one
host.
Yes,
just
one
jenkins
master,
then
it
will.
D
Of
course
the
same
process
for
us
will
will
get
will
be,
will
trigger
the
job,
put
it
in
the
queue
and
then
when
it's
ready
it
will
start
working
on
it,
but
it
could
also
be
some
other
jenkins
slave.
Taking
on
that
job,
I
mean
the
master
still
puts
it
in
the
queue,
so
one
host
should
say
puts
it
in
the
queue
and
another
host.
It
could
be
some
other
tool
actually,
but
it's
in
in
the
jenkins
case.
D
It's
still
the
jacket
slave
that
somehow
picks
up
that
job
from
the
queue
and
starts
working
on
it
actually
starts
the
actual,
build
whatever
the
job
execution
and
then
finishes
it.
So
I
think
we
could
still
see
it
as
it's
put
into
like
a
virtual
cue,
since
the
orchestrator
is
handling
it
as
an
eq.
Although
that's
somehow
using
that.
A
E
I'd
actually
would
like
to
say
that
erica.
I,
like
your
your
explanation,
better,
I'm
afraid
of
him
that
you're
you,
the
risk,
is
not
be
creating
a
draft
drift
towards
this
prescription
descriptive
things
in
another
way.
The
reason
I'm
hesitant
at
commanding
is,
if
I
read
the
cloud
event
specification,
it
says
in
my
reading
that
events
is
something
that
has
happened
and
not
something
that
should
happen
so,
but
that's.
C
But
yes,
but
I
think
that's
kind
of
like
my
intention
with
requested
it's
like
it's,
it
hasn't
happened,
I'm
requesting
it
to
happen.
So
what
has
happened
is
the
request
from
from
a
component
that
it's
basically
saying
hey,
you
know
what
somebody
should
do
something
I
don't
know
who,
but
we
need
something
to
happen
in
the
you
know,
we
are
just
creating
the
request
for
something
to
happen
and
what
just
happened
is
the
request.
E
E
C
C
If
that
event-based
approach
is
using
an
orchestrator
like
following
the
same
patterns
as
captain
is
doing,
the
question
is,
then:
can
we
include
in
the
vocabulary
the
events
from
the
orchestrator
itself
and
how
those
how
those
events
could
look
like,
even
if
it's
not
the
central
orchestrator
and
it's
a
kind
of
distributed
kind
of
thing
that
it's
you
know,
orchestrating
two
systems
and
then
another
one
that
it's
orchestrating
to
all
the
systems
and
they
will
be
exchanging
events,
how
that
would
connect?
How
do
you
imagine
like
that
integration
to
happen?
C
A
I
think
I
see
your
point.
I
would
still
be
in
favor
of
separating
it
out
as
an
extension,
because
or
mainly
to
to
be
able
to
answer
the
question
or
help
people
answer.
The
question:
am
I
compliant
with
a
cd
event,
specification
and
being
compliant
with
the
cd
event
specification
should
not,
in
my
opinion,
require
you
to
handle
requests
used
from
events.
It
should
be
mainly
about
sending
events
when
valuable
things
happen.
But
again
I
don't
have
a
super
strong
opinion
on
it,
but
I
do
see
it
like.
A
A
solution
can
either
be
compliant
with
the
the
sending
part
of
events,
and
it
can,
additionally
if
it
wants
to
be
compliant
with
the
request
part
of
the
events,
but
that
puts
quite
a
lot
of
additional
burden
on
the
system
itself
to
actually
connect
and
listen
to
this
event,
just
rather
than
just
sending
them
through
some
some
api
or
something
else.
So
that
would
be
my
motivation
for
separating
the
markets
yeah.
I
mentioned
that
we
have
reached
the
allocated
time
so
either
we
or
we
we
wrap
up
for
today.