►
From YouTube: Supply Chain Maturity Model WG meeting - Nov 1, 2022
Description
01:27 Intros
06:11 Intro and demo of GUAC by Parth Patel, Kusari
24:59 Q&A
See meeting notes at: https://hackmd.io/xq6lH4F7RUWmqZhluMcgLw?both#November-1-2022
For more Continuous Delivery Foundation content, check out our blog: https://cd.foundation/blog/
A
B
B
D
E
Can
go
first,
yeah
hi.
Everyone
hope
you
will
hear
a
bit
of
background
noise
I'm
at
home
today.
It's
a
holiday
here
kind
of
my
name
is
Omar
Guillo
I
work
at
cyber
security,
I'm
winning
the
security
research
team
and
we've
been
focusing
in
the
last
two
years
on
researching
media
videos
of
cacd
security
supply
chain
security.
So
really
I'm
really
happy
to
to
see
this
initiative
and
enjoy
you
guys.
F
G
B
D
B
I
Yeah
sure
so
I'm
Isaac
Hepworth
I
work
at
Google
I.
This
is
my
first
time
in
a
CDF
meeting.
I
spend
a
lot
of
time
in
openssf
and
working
with
Sig
store
and
salsa
and
guac
and
others
and
chatting
with
David
yesterday,
and
he
suggested
I
drop
in
and
hang
out
and
meet
you
all
so
so
here
I
am
and
thanks
for
having
me
I'm,
also
struggling
to
get
my
video
working
and
so
hopefully
in
the
next
30
seconds.
I'll
fix
that.
B
A
A
C
Okay,
can
anybody
see
this?
Is
that
too
small
too
big
looks
good,
okay,
so
real
quick
introduction
for
myself
on
parth,
one
of
the
co-founders
that
kusari
supply
chain
security,
startup
and
some
of
the
projects
I've
been
we've
been
working
on
is
Fresca,
which
is
the
which
is
the
secure
Builder
piece
that
builds
off
of
tecton
pipeline
chains.
You
know
combining
a
lot
of
Open
Source
tools
and
you
know
having
a
secure
product
at
the
end
and
the
other
one
is
guac.
C
What
the
problem
is
right,
so
we
have
a
bunch
of
data
stored
in
multiple
different
locations
right
the
attestations,
yes,
bombs,
Vex,
all
those
kind
of
things
are
all
over
the
place,
so
the
problems,
what
we're
trying
to
do
with
guac
is
consolidate
all
this
information
and
use
this
so
that
we
can
make
you
know,
correlate
all
the
data
together
and
make
this
make
policy
decisions.
Make
you
know
more,
you
know
proactive
decisions
instead
of
more
being
reactive
right,
you
kind
of
heard
about
the
openssl
right.
C
It's
it's
not
so,
based
on
the
the
the
news
that
came
out
this
morning,
it's
not
as
bad
as
Heartbleed
right,
but
it's
still
something
that
needs
to
be
fixed.
You
know,
but,
but
in
order
to
do
that,
you
need
to
know
where
exactly
you
know
your
where
your
dependencies
are
installed.
Where
is
openssl
installed,
where
in
your
ecosystem,
it's
there
and
then
how
do
you?
You
know
quick,
find
it
quickly,
so
they
can
remediate
it
right.
C
So
that's
what
guac
is
trying
to
do
is
help
answer
those
kind
of
questions
you
know
figure
out
what
the
downstreet
dependencies
are
figure
out.
What
the
transitive
dependencies
are,
so
you
can
answer
those
questions
Downstream,
so
it
fits
in
right.
So
we
can
see
there's
a
different
levels,
but
it
fits
into
the
aggregation
and
synthesis
right.
So
it's
a
based
off
of
that
right.
You
can
have
the
trust,
Foundation
software
adaptations
are
being
generated
by
the
s-bombs,
all
satisation
effects,
osv
everything
is
kind
of
the
ecosystem
is
kind
of
coming
together.
C
C
C
So
how
does
it
work
right
so
at
the
high
level
view?
Basically,
what
it's
doing
is
collecting
from
a
lot
of
public
sources,
so
writes
so
recore
we
can
we're
collecting
from
Google
buckets,
we're
gonna,
add
other
collectors
in
the
future,
but
basically
for
now
we
have
I,
think
recore
collection,
Google,
Google,
bucket
collection
and
finally,
just
like
local
local
files
that
you
have
and
take
all
that
information
and
then
eventually
right
you
can
have
it
public
records
and
private
records.
C
So
it's
surprising
because,
as
we
work
through
some
of
this
stuff,
like
you
know,
if
you
have
some
missing
data,
you
know
from
one
s-bomb
another
another
s
bomb
might
come
in
and
kind
of
fill
in
the
gaps
right.
So
you
can
get
more.
As
you
add,
more
and
more
data
in
you
can
get
a
much
more
clearer
picture
on
exactly
like
what
all
your
trans
dependencies
are
and
as
and
you
can
go
further
down
and
down
the
line.
Basically,
so
you
know,
as
as
more
attestations
are
added
as
more
response
are
added.
C
You
know
the
picture
becomes
more
and
more
clear
and
then
finally
right
at
the
end,
you
can
do
some
queries
at
this
point.
We
are
using.
You
know
the
cipher
queries
that
are
native
to
neo4j,
but
we
want
to
move
on
to
like
graphql
and
make
it
a
lot
easier,
we're
gonna
just
just
for
people
to
start
querying
and
asking
questions
in
general
yeah.
C
So
what
does
this
look
like
today?
So
we
have,
you
know,
a
bunch
of
information,
a
bunch
of
nodes
that
get
generated
automatically,
so
we.
What
we
do
is
that,
as
we
are
ingesting
as
we
ingest
documents,
we
parse
out
all
the
different
informations
based
off
of
them,
so
we
create
artifact
notes.
We
create
attestation
nodes,
we
create
like
package
nodes
and
then
we
create
edges
between
them.
C
You
know
based
off
the
relationship
if
they
depend
on
this,
if
they
contain
a
specific,
artifact
and
so
forth,
and
then
we
haven't
Incorporated
this
yet,
but
we
do
want
to
start
having
identities
associated
with
each
of
these
artifacts.
So
then
you
can
be
okay,
I
trust.
You
know,
for
example,
these
are
signed,
for
example,
I,
say:
Google
is
producing
some
of
these
documents.
I
trust,
Google,
right,
I,
trust,
Google.
C
I'm
going
to
use
that
in
my
graph
to
make
valid
decisions
we
do
also
want
to
add
temporal
data,
so,
for
example,
right
if
an
artifact
was
vulnerable
one
day,
but
the
next
day
it's
not
right.
We
want
to
have
that
data
incorporated
into
the
graph,
so
we
can
ask
again
like
hey.
Yes,
this
version
was
vulnerable
during
this
time
period
and
then
now
it's
not
it's
no
longer
vulnerable
to
that
specific
CPE
or
something.
C
So
let
me
kick
it
off.
So
what
I
did
before
the
before
the
start
of
the
meeting
is
I
just
I,
just
spun
up
a
local
neo4j,
so
I'm
just
running
this
locally
on
my
computer
and
I
I
just
ingested
a
bunch
of
slides
and
if
you
guys
wanted
to
run
through
this
there's
a
setup.md
also
on
the
guac
clock
repo.
So
you
can,
you
can
do
the
same
exact
demo,
I'm
kind
of
showing
here
kind
of
show
off.
C
You
know,
ingest
the
same
information
and
kind
of
run,
your
own
queries
and
see
what
you
get,
but
so
what
I'm
going
to
show
off
here
is
this
like
quick
introduction,
exactly
like
hey
what
it
is
and
what
does
it
look
like
so
down
here?
What
I
did
is
I
just
copied
and
pasted
one
of
the
queries
that
we
have
in
there.
So
in
this
case
right
you
can
see
there
are
7
000,
nodes
and
edges
that
are
part
of
this
sorry
7000
nodes
that
are
part
of
this
ingestion
right.
C
So
we
ingested
a
bunch
of
documents.
One
main
thing
we
ingested
was
the
kubernetes,
so
we
ingested
all
of
kubernetes
s-bomb
and
some
of
the
adaptations
that
are
associated.
So
a
lot
of
our
information
came
out
of
that,
so
we
got
7000
nodes
coming
out
of
that.
So
that's
a
combination
of
artifact
notes
right
this
is
this
is
going
to
be
your
your
images,
your
files
so
forth.
The
attestation
in
this
case
is
going
to
be
the
cell
citizations.
The
Builder
is
what
actually
did
the
building.
C
So
in
this
case,
depending
on
what
kubernetes
was
using,
that's
the
Builder
that's
being
used,
it
could
be
tecton,
it
could
be
tecton
or
you
know,
GitHub
and
so
forth,
but
I
could
have
actions
or
gitlab.
The
metadata
is
the
the
security
is
a
scorecard.
So
that's
that's
that
piece.
So
we
can
I'll
show
that
later
later
on
in
the
in
the
demo
and
then
finally
packages
is
the
actual
s-bomb.
You
know
the
packages
that
come
from
the
s-bombs
themselves.
C
So
down
here,
you
can
see
I
just
ran
a
quick
match
and
limit
my
search
25,
because
lots
of
information
comes
out
of
this.
So
we
can
see
here
is
that
we
have
two
different
images,
so
this
one
is
the
Alpine
latest
itself
and
then,
if
I
scroll
up
here,
this
one
is
Bash
latest
right,
but
they
both
depend
on
Alpine
right.
Obviously,
the
Alpine
depends
on
itself
and
then
the
dash
one
also
depends
on
the
Alpine.
C
So
you
get
you,
you
can
make
all
these
kind
of
correlations
as
you,
as
you
start
looking
at
the
actual
data,
but
looking
at
it
in
in
this
node
form
right,
it
can
be
difficult,
so
you
have
to
kind
of
query
down
into
the
specific
things
you're
kind
of
looking
for
so
what
our
goal
is
in
the
near
future
is
basically
make
this
a
lot
simpler
right,
because
we
don't
want
people
writing
their
own
queries.
It's
a
lot
difficult,
there's
a
lot
of
information
out
there,
it's
really
difficult.
C
C
Okay,
so
the
next
thing
I'm
going
to
show
is
like
I
mentioned,
we
did
ingest
a
bunch
of,
we
did
ingest
a
bunch
of
you
know
the
kubernetes
s-bomb
in
here.
So
you
can
see
this
one
is
1.24.
1.25
is
a
cube
controller
manager
right.
You
can
see
right
here.
The
versions
are
changing,
so
we
have
a
bunch
of
these
and
you
can
actually
go
in
and
look
at.
You
know,
okay,
what
what
are
the?
What
does
it
actually
depend
on?
Is
there
an
attestation
associated
with
it
and
so
forth?
C
So,
if
I
expand
this
out,
you
can
see
like
lots
and
lots
of
information
comes
out
of
this
right
because
it's
like
okay,
there
is
this
package
or
depends
on
the
specific
file.
Oh
there
we
go
well,
it
keeps
changing,
but
yes,
so
it
depends
on
the
specific
file.
So
you
get
very,
very
deep.
Granular
information
exactly
what's
happening
and
what
we
want
to
do
with
this
is,
you
know,
tie
it
in
with
osv
and
Vex
and
all
this
kind
of
information,
so
you
can
be
like
okay.
C
Yes,
this
package
is
actually
vulnerable
so
like,
if
I,
if
you
remember
the
open
SSL
example,
I
just
gave
it's
like
okay
and
now
I
know
where
openssl
version
you
know
3.3.00
the
ones
that
are
vulnerable.
Where
is
that
being
used?
I
can
quickly
query
for
that
and
find
hey.
These
are
all
the
different
things
that
openssl
all
the
packages
that
depend
on
openssl
can
be
found
using
this
quickly.
C
So
I'm
going
to
so
what
I'll
do
is
I'll
narrow
down,
specifically
so
I'm
going
to
be
looking
at
version
1.2
1
1.24.6.
So
what
that
does
is
gives
us
a
lot
more.
You
know
much
more
readable
information,
so
let
me
zoom
in
here.
So
as
you
were,
if
you
recall
I
mentioned
there
was
a
security
scorecard
right.
So
scorecard
information
is
stored
in
here,
so
that
this
is
the
actual
git
repo
that
kubernetes
comes
from.
So
you
can
see
here
the
name,
that's
the
actual
repository
for
kubernetes.
C
This
is
a
scorecard
scores,
a
different
scores
based
off
of
the
based
off
the
scorecard
report,
and
then
you
can
see
down
here.
This
is
the
actual.
So
this
is
one
of
the
binary,
so
I
said:
Cube
controller
manager
is
the
actual
binary,
which
is
an
artifact
there's.
Also
a
go
Runner
artifact
up
here
and
both
of
these
both
of
these
are
dependencies
of
that
package
of
the
kubernetes
1.246
package.
C
Right
both
of
these
are
contained
within
that
package,
and
then
finally,
you
see
that
there's
an
attestation
assault
status
station
associated
with
the
the
cube
controller
manager,
but
there's
not
an
attestation
associated
with
the
go
Runner
right.
So
what
Glock
also
allows
you
to
do
is
figure
out.
Okay,
what
information
am
I
missing
right,
so
it's
like
okay,
there's
no
attestation
associated
with
this.
This
specif,
this
particular
binary
or
particular
image.
C
So
maybe
I
need
to
go,
create
that
or
find
more
information
about
that,
or
you
know
or
query
Upstream,
to
find
more
information
about
that.
So
you
can
see
exactly
what
information
you're
lacking
at
the
same
time,
you
can
see.
Okay,
what
do
I
trust
do
I
have
enough
information
to
make
valid
decisions
if
I
should
be
running
this
in
a
production,
environment
and
so
forth.
C
Lastly,
I'm
just
going
to
show
a
quick
thing
for
you
know
like
Debian,
is
used
in
a
lot
of
places.
So
what
this
is
going
to
show
is
basically,
okay,
show
me
Debian
all
right
and
then,
if
I
expand
this
out
right,
lots
and
lots
of
things
are
using
Debian.
So
we
can
actually
make
much
more.
We
can
actually
find
out
okay,
what
are
the
shared
dependencies
and
what
uses
Debian
and
what
how
much,
how
much?
What
packages
do
they
share
between
each
other?
C
C
So
you
can
make
lots
of
decisions
and
see
where
you
know
what
relies
on
what
you
might
not
think
something
you
know
something
minuscule
might
you
know
you
might
think
of
package
doesn't
rely
on
something,
but
you
might,
it
might
be
the
contrary
right,
it
actually
does
depend
on
it
and-
and
it
could
be
something-
that's
vulnerable
right.
So
it
gives
you
a
lot
of
insight
and
deep
insight
into
the
things
you're
actually
looking
at
and
then
so
like
so
forth.
C
Let
me
go
back
to
the
slides
here,
so
this
is
just
a
subset
right.
We
have.
This
was
I.
Think,
probably
50
documents,
maybe
maybe
a
little
bit
more
but
I-
think
we've
ingested.
You
know
my
Mike
Michael
Lieberman
has
ingested
at
least
I
think
he
want
he
ingested
about
I
want
to
say
like
seven
thousand
or
some
some
documents,
so
he
pulled
down
a
bunch
of
a
bunch
of
images
and
use
and
use
Swift
to
create
the
s-bombs
and
ingest
all
that
information.
C
So
I
think
we
ended
up
getting
about
like
500
000
nodes
and
a
million
edges,
so
we
can
ingest
information
really
quickly
and
then
start
making
all
these
correlations
very
quickly.
So,
as
we
ingest
more
and
more
data
we
can
make,
you
know,
have
a
much
clearer
picture
and
exactly
what
we
are
ingesting
so
future
work
for
this
right.
We
start
one
ingesting
what
I
didn't
show
in
the
demo
is
like
I
want
to
say,
like
it's
the
whole
vulnerability
piece
right
in
the.
C
If
you
look
at
the
cube
kubecon
demo,
some
of
the
some
of
the
docs
I
didn't
have
locally,
so
I
couldn't
spin.
That
up,
but
basically
we
do
want
to
be
able
to
like
hey
here,
is
log4j
here's
a
version
of
block
4J
that
was
vulnerable.
He
and
then
in
the
next
updated
version
of
that
image.
Log
for
J
is
no
longer
vulnerable
same
for
I.
Think
it
was
text
for
Shell
was
another
vulnerability
that
got
resolved.
C
You
could
see
it
being
honorable
in
one
of
the
versions
and
not
the
other
right,
so
you
can
make
decision
space
off
of
that,
so
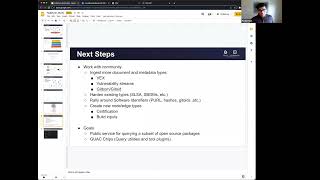
ingest,
more
vulnerabilities
teams
get
bomb
and
then
it's
hardened
some
of
the
existing
types
right.
So
we
have
some
issues
in
terms
of
like
Swift
and
some
of
the
other
tools
are
not
generating
s-bombs
per
spec.
So
we
want
to
make
some
or
we're
working
Upstream
to
start
making
those
changes
so
as
we're
ingesting.
C
You
want
to
make
sure
that
it's
collecting
the
right
information
and
you're
outputting
the
right
information
that
makes
tools
like
this,
where
that
gener,
that
makes
generating
X
problems
valuable
in
the
future
and
then
yeah
so
and
then
the
other
thing
basically
is
make
this
a
public
service.
I
think
that's
further
down
the
line!
Probably
next
year.
We
want
to
have
some
kind
of
an
open,
open
public
service
that
people
can
use
to
go
query
for
a
lot
of
the
open
source
projects
and
then
have
chips.
C
So
guac
chips
is
basically
plug-ins
right.
So
it's
like
I
said
like
we
don't
want
people
going
in
and
querying
neo4j
directly.
We
want
to
make
this,
you
know
have
have
utilities
that
go
to
guac.
Do
some
do
some
searching
around
and
do
some
queries
automatically
for
you
and
give
you
the
output.
So
one
of
the
things
that
we've
actually
been
working
on
is
vs
code
extension.
Basically,
so
what
this
does-
and
if
this
is
too
small
I
can
zoom
in
that's
okay.
C
This
is
not
working,
oh
anyways,
okay,
but
what
this
does
is
basically
for
now
what
this
does
is
like
hey.
If
you
have
an
s-bomb,
it
automatically
recognizes
that
you
have
an
s-bomb
in
your
vs
code,
that's
open
and
then
it
can
go
and
go
into
guac
query
for
that
specific
s-bomb
and
give
you
a
lot
more
information
back.
So
you
can
see
down
here,
guac
spam
information,
so
you
can
actually
for
each
of
the
different.
You
know,
packages
that
are
associated
with
that
root
level
package
right.
C
You
can
get
more
information,
more
granule
information
and
I.
Think
eventually
we
want
to
make
it
so
like
okay.
Yes,
it
gives
you
more
information
back
saying
like
oh,
this
package
is
actually
vulnerable.
You
probably
want
to
change
this
and
so
forth.
Like
gives
you
a
lot
of
recommendations
back
so
as
you're
working
right,
it
gives
you
integration
back
to
exactly
what
what
needs
to
be
changed
and
why
but
and
that's
everything
I
had
any
questions.
C
So
not
yet
so
we've
we
actually
started
speaking
with
Jim
mcguardia
from
kuberno
and
Estrella.
We
want
to
work
with
them
to
start
integrating
this
directly
into
into
those
two
kind
of
you
know
into
two
different
products
so
that
we
can
have
so
that
you
know
kuberno
at
the
same
time.
Oppa
you
know,
can
start
making
decisions,
query
decisions
and
use
the
information
that
comes
out
of
guac
to
make
hey.
Yes,
this
can
run
in
production
or
not.
C
So
this
is
very
much
a
pre-alpha
project
right,
we're
still
working
on
a
lot
of
Integrations
so
like,
for
example,
I
think
one
of
the
things
I
want
to
work
on
this
week
is
start
ingesting,
osv
to
start
ingesting
some
of
that
information
based
on
some
of
the
packages
that
we
have
and
and
have
that
available,
so
that
we
can
see
what
the
you
know.
Different
cves
are
associated
with
the
different
packages,
so
so,
but
I
think
that's
we're.
C
Moving
in
that
direction,
like
I
said
it's
pretty
Alpha,
so
very
much
early
stage,
so
we're
looking
for
you
know
people
to
contribute
at
the
same
time
just
advice.
You
know
just
like
technical
expertise
in
terms
of
what
you
you
know
what
we
are
missing
or
if
there's
anything
that
that
we,
you
know,
we
were
overlooked.
B
C
So
we
have
it
set
up
so
the
two
Integrations
we
have
so
far
another
one
we're
working
on
so
recore.
It
will
it's
based
on
so
basically
very
any
new
artifacts
come
in
it'll
automatically
ingest
them
same
for
buckets
and
any
other
integration
that
we
do
in
the
future
right.
So
it's
going
to
continuously
watch
over
a
specific.
B
Will
say
thanks
that
is
actually
really
insightful
and
I
can
imagine
using
that
against
a
production
deployment
and
having
that
to
take
a
recent
example
being
extremely
helpful
in
identifying
where
all
the
places
that
my
my
SSL
vulnerability
lives
exactly
we
were
able
to.
We
have
other
ways
of
doing
that
that
query,
but
some
of
the
visualization
there
is
also
quite
interesting
right.
C
I
I'm
biased
but
I
I,
I,
love,
guac
and
yeah
I'm
super
excited
by
this
I
think
there's
a
huge
need
for
it
and
I
think
you
know,
particularly
with
you
know,
the
executive
order,
new
OMB
guidance
or
less
bombs,
we're
going
to
wake
up
to
a
2023
that
is
absolutely
flooded
with
metadata
for
software
supply
chain,
including
s-bombs
and
I.
Think
that
you
know
the
comprehensibility
and
converting
that
that
data
into
meaning
is
is
the
place
where
Quark
provides
so
unique
capabilities
and
then
to
David's
point.
I
You
know,
on
top
of
that,
meaning
there's
the
layer
at
the
top
of
the
the
you
know
the
stack
of
four
which
is
turning
that
meaning
into
value,
and
so
we
can
turn
into
value
for
devops.
In
terms
of
value
for
risk
management,
we
can
turn
into
value
exactly
in
terms
of
value
for
policy.
We
can
sort
of
value,
for
you
know,
developer
assistance
and
so
there's
a
number
of
different
routes
that
we
might
take
to
to
build
value
for
different
audiences
on
top
of
Quark.
But
you
know
the
core
concept
of
guac.
I
You
know
taking
this.
The
sea
of
you
know
software
supply
chain
metadata.
It
would
be
s-bombs
Vex,
osv
developer,
you
know
a
reputation
thread,
intelligence
whatever
it
may
be.
You
know
aggregating
and
synthesizing
that
and
turning
that
data
into
meaning
is
a
huge
gap
in
our
story
today
and
I'm
stoked
to
see
guac
stepping
up
to
that.
I
C
I
So
I
was
I
was
a
co-author
of
the
Google
blog
post
on
guac
and
worked
closely
with
with
with
the
engine
at
Google,
who
are
partnering
with
with
path
and
the
rest
of
kasari
and
City
on
quark.
And
so
my
bias
really
is
you
know
my
my
background
at
Google
or
my
role
at
Google
is
anchored
on
software
supply,
chain
security
and
so
I.
Look
at
Google's,
first
party
software
supply
chain,
you
know
and
to
David's
point
and
trying
to
figure
out
hey.
D
A
I
But
then,
looking
at
the
open
source
supply
chain
overall
and
how
to
be
better,
secure
that
and
better
reason
about
it,
I
think
that
part
of
the
problem
that
we
have
today
is
that
open
source
brings
tremendous
value
to
consuming
organizations,
but
it
also
brings
significant
latent
security
risk
where
right,
latent
is
part
of
the
key
word
like.
We
all
know
that
we're
taking
some
Risk
by
introducing
open
source
software
into
supply
chain,
no
one
has
any
real
ability
to
quantify
or
Reason
about
that
risk
and
I.
H
Mention
that
yes,
that's
there,
the
tool
can
consume
or
or
just
public
records
private
vendors
Etc.
Is
there
any
suppressing
mechanism
in
place
so
so
that
I
can
use
that
so
I'm
not
suppressor
to
say?
Okay,
this
is
my
the
most
thrust
source
and
the
information
about
that
station,
for
example
or
dependent.
This
is
the
is
the
most
trusted
from
these
specific
Source,
something
like
like
that,
or
that's
only
like
a
database
with
all
the
information
and
then
so
yeah
yeah,
just
one
wandering
on
decision
making
chain.
So.
C
Like
I
I
mentioned,
there
are
identities
Associated
which
we
haven't
Incorporated.
Yet
so
you
can
be
okay,
these.
These
are
the
ones
that
are
these
artifacts
are
signed
by
these
identities,
and
these
are
the
ones
that
I
trust.
So
these
are
the
ones
that
I
I
want
to
use
in
my
queries
and
such
so,
you
can
make
so
we're
leaving
that
up
to
the
users
themselves
saying
like
Okay.
These
are
the
ones
I
trust,
and
these
are
the
ones
that
I'm
going
to
base
my
policies
based
on.
C
B
B
The
way
I
talked
about
this
with
Isaac
yesterday
I
pointed
out
that
what
salsa
does
for
bills
I
would
like,
and
it
provides
levels
where
you
can
measure
your
your
provenance
and
your
ability
to
reproduce
builds
and
like
I
would
like
similar
measures
and
levels
and
standards
to
apply
to
your
entire
continuous
delivery.
So
one
input
to
that
would
be
well
what
is
My
Salsa
level.
Another
input
to
that
would
be
well
am
I.
Collecting
s-bombs
for
everything
am
I
doing
vulnerability
scans
for
everything.
B
Another
possible
input
to
that
could
be
am
I
loading
everything
into
a
system
like
guac,
where
I
can
query
it,
and
these
are
all
different
measures
of
maturity
that
in
fact
go
into
security.
30
questions,
as
I
pointed
out
to
Isaac.
Yesterday
a
maturity
question
is:
can
I
do
a
push
button,
production,
rollback
or
is
in
fact
they're
a
manual
rollback
procedure
in
production?
Well,
that
actually
has
secure
that
maturity.
B
Having
hopefully
tied
everybody
sort
of
back
to
the
the
goal
of
this
working
group,
we
don't
have
any
other
topics
today.
We
do
have
25
more
minutes
scheduled
where
we
can
throw
new
topics
on
the
agenda.
If
there
are
things
people
want
to
bring
up
or
we
could,
we
could
also
End
early,
so
I'll
I'll.
Let
us
all
sit
in
an
awkward
silence
for
for
at
least
a
few
moments,
while
we
figure
that
out,
I'll
I'll.
F
Just
hop
in
and
we
don't
have
to
wait,
I've
been
thinking
about
mechanisms
to
rate
s-bombs
using
my
biases
and
the
the
general
idea
is
that
not
all
s-bombs
are
created
equal
and
some
have
tons
of
data.
That's
really
useful
and
some
have
functionally
no
data,
and
it
would
be
useful
to
be
able
to
not
necessarily
assert
correctness
but
at
least
assert
what
pieces
of
information
are
there
like?
F
We
might
have
a
dependency
on
openssl
and
the
things
that
would
be
seemingly
very
important
to
have
would
be
like
the
name
of
the
package,
a
pearl
or
similar
string,
a
version,
maybe
the
licenses
that
it
has
Etc
and
each
of
those
contributes
to
some
ranking
that
we
could
put
into
a
scorecard
of
some
sort
to
get
a
sense
of.
Is
this
s-bomb
actually
good?.
I
It's
a
really
interesting
idea:
I've
been
thinking
about
this.
This
recently
myself
and
I'm.
Looking
at
you
know,
Google's
first
party
production
of
s-bombs
to
to
comply
with
the
executive
order
and
yeah
I
mean
I,
think
you
know
there's
often
the
question
about
you
know
the
depth
of
s-bonds
like
how
deep
do
you
Traverse
these
transitive
dependencies
and
I?
I
F
I
Yeah
and
I
think
I
mean
I
think
that
this
this
speaks
to
a
real
danger
as
well,
that
we
have,
with
a
government
mandate
around
production
of
s-bombs,
that
I
think
that
there'll
be
many
organizations
that
are
prioritizing
the
checkbox
rather
than
the
actual
utility
of
the
document
and
I
think
that
that'll
be
highlighted
by
you
know.
If
you
have
a
tool
to
do
that
scoring.
I
F
A
C
Yeah
and
Justin,
we
we
also
have
like
I
mentioned
Michael
Lieberman,
actually
ingested
a
bunch.
He
generated
actually
a
bunch
of
best
pumps
from
from
GCR.
Actually,
so,
although
all
the
containers
or
the
images
that
were
in
there,
he
created
s-bombs
using
Swift,
so
we
have
a
whole
bucket
full
of
them
actually
I.
C
Think
it's
a
public
bucket
that
I
can
link
you
to
if
you
want
to
start
looking
at
it,
so
that
has
as
many
s-bombs
as
you
need,
I
think
and
what
I
Linked
In
the
the
chat
is.
Basically
you
know
the
same
thing
like
you
know
what
you're
saying
is
like
how
valid
is
some
of
the
information
or
how
complete
is
that
information?
And
you
know
you
can
see
the
issue
we
kind
of
posted
about
a
month
ago
that
Brandon
Brandon
posted
here
is
basically
like
we're
missing.
C
Like
you
know,
Swift
is
not
doing
some
of
the
things
properly
like
it's.
It's
not
creating
the
top
level
root
package
using
a
proper
Pearl,
so
that's
like
and
you
know
not
including
the
checksum
and
all
that
kind
of
stuff
right.
So
it's
like
hey.
We
need
some
of
that
information
if
we
want
to
start
making
decisions
and
making
correlations,
especially
in
guac,
and
you
know,
for
vex
and
everything
else,
osv
and
Vex
and
stuff.
So.
A
B
B
B
E
Sorry,
if
it
was
discussed
in
the
last
first
meeting,
do
we
have
a
main
objective
of
creating
of
eventually
creating
like
document
with
the
maturity
model,
as
we
believe
should
be
used.
Organizations
or
the
purpose
of
these
many
games
is
to
discuss
like
topics
like
we
discussed
today.
I
mean:
do
you
have
any
objective
of
like
a
Target
objective
or
a
big
one,
to
create
an
artifact
eventually.
B
A
It
has
has
you
know
like
someone
looked
at,
you
know
like
differences
like
I
mean
I
have
I've
like
so
I
have
seen.
You
know,
like
blog
posts,
where,
where
like
people
say
there
is,
you
know
like
differences
between
using
sift
and
using
say
KO
or
you
know
like
appco,
but
that
would
be
something
that
I'm
planning
to
do
this
week.
Maybe
next
meeting
I
can
show
if
I
see
any
you
know
like
differences.
If
people
are,
you
know
interested
to
see
that
so.