►
From YouTube: DataHub at DefinedCrowd: Apr 23 2021 Community TownHall
Description
Pedro Silva shares the journey of adopting DataHub at DefinedCrowd and their plans.
A
C
C
So,
first
of
all,
let
me
just
very
briefly
explain
to
you
what
a
company
is.
Essentially,
we
are
a
marketplace
for
ai
data
and
our
objective
is
to
make
your
ai
use
cases
smarter
and
the
way
that
we
do,
that
is
by
crowdsourcing
data
assets
specific
to
your
use
case
into
your
industry
as
a
service
with
certain
quality
guarantees.
C
These
can
be
things
like
speech
to
text,
translations,
audio
or
even
image
recognition
type
data
assets
regarding
the
company
we
were
founded
in
2015,
we
have
over
300
employees
and,
through
our
series,
a
and
series
b
funding
we
have
over
63
million
dollars
already
raised
important.
To
mention
in
this
talk
is
that
one
of
the
ways
or
the
way
in
which
we
crowdsource
datasets
is
through
our
nevo
platform.
C
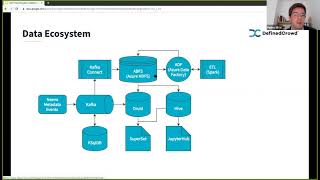
Regarding
the
architecture
itself,
what
we
have
is
nivo
generates
certain
metadata
events,
so,
let's
suppose
that
a
certain
unit
of
work
has
been
assigned
to
a
user,
he
has
been
working
on
it.
So
you
have
progress
over
time.
It
can
be
cancelled,
it
can
be
completed
these
sort
of
things,
so
a
sort
of
state
machine
of
events
and
based
on
multiple
aspects
of
the
platform
is
the
input
or
the
source
of
data
for
our
platform.
C
This
is
then
retrieved
from
a
kafka
log
storage,
where
we
can
perform
a
number
of
things,
one
of
which
is
through
k-sequel,
perform
streaming
joins
and
the
reason
that
we
want
this
is
to
have
a
real-time
computed
view
over
certain
data
views.
If
you
will
on
our
data
and
that
is
stored
back
into
kafka,
which,
through
kafka,
connects,
we
store
in
htfs
and
internally
at
the
fine
crowd
we
use
or
our
cloud
is
azure
and
we
do
use
certain
managed
services,
including,
for
instance,
azure
data
factory,
which
is
azure's
managed
offering
of
something
like.
A
C
It's
their
own
interpretation
of
that
and
we
also
have
the
typical
etl
batch-like
processing,
in
this
case,
through
spark
where
we
take
raw
data
and
process
process.
Our
kafka
topics
into
usually
views
that
are
more
a
consumable
for
our
stakeholders
and
and
these
views
can
either
be
consumed
via
druid
or
via
hive.
C
The
use
case
here
is
in
druid:
we
want
to
work
with
more
real-time
queries
than
an
sql-like
approach,
but
in
hive
through
jupiter
hub
for
those
cases,
for
example,
data
scientists
where
they
want
to
perform
actual
manipulations
on
the
data,
and
they
want
to
perhaps
do
some
daily
cleaning
and
feature
engineering
for
our
internal
machine
learning
models
so
in
a
very
high
level
overview.
This
is
what
we
have
for
a
day-to-day
ecosystem.
This.
A
C
Everything,
but
it's
what
I
feel
is
relevant
to
this
conversation
right
now
and,
as
you
can
tell,
this
is
a
very
centralized
like
approach
and
the
whole
architecture
itself
is
owned
and
managed
by
the
data
engineering
team.
Our
vision
is
to
move
towards
a
more
data
mesh
like
approach,
which
certainly
has
some
benefits
for
us.
Concretely.
What
we
want
is
to
achieve
three
things:
data
democratization
so
allowing
data-driven
decision-making
without
bottlenecks
or
external
dependencies
by
our
stakeholders.
C
A
C
Make
those
decisions
based
on
data
but
not
being
dependent
on
the
team
and
the
reason
being,
is
that
the
scale
of
the
team
and
the
people
who
manage
this
infrastructure?
We
are
around
six
people.
This
changes
over
time
because
we
have
people
being
allocated
into
different
projects,
but
our
fan
out
ratio,
if
you
will,
is
six
to
eighty.
So
if
you
want
to
reduce
this,
I
think
it's
something
like
one
to
twelve
and
that's
sort
of
how
it
works,
and
given
this
scale
we
naturally
want
our
users
to
be
more
self-serviceable.
C
Speaking
of
intuitive
tooling,
that's
where
data
hub
itself
comes
in
right.
Self-Service
ability
is
something
that's
not
really
possible
without
having
data
discovery
and
data
data
lineage
over
the
assets
that
we
have,
and
even
for
the
data
team.
For
us,
we
do
increasingly
have
a
harder
time
keeping
up
with
the
growth
of
data
assets
given,
given
that
the
company
itself
is
a
data
provider,
our
asset
catalog
is
continuously
growing
and
for
six
people
it's
a
lot
of
information
for
us
to
handle.
C
So
we
needed
a
data
catalog
from
an
exploration
of
the
current
ecosystem
perspective.
We
explored
options
like
weworks,
marquez,
apache,
atlas,
lifts
and
mutant,
and
mainly
because
they're
open
source
solutions,
and
we
wanted
to
understand
and
wanted
to
be
able
to
contribute
back
in
case.
Their
approach
was
not
perfectly
fixed
to
the
finance
crowd
use
case,
though,
we
did
also
look
to
inspiration
at
companies
like
netflix
and
intuit
that
had
other
approaches.
In
the
end,
though,
we
did
decide
to
go
to
data
hub
the
reason
being,
it's
extremely
active
community.
C
C
They
are
directly
interacting
with
data
that's
available
in
variable
in
druid
and
hive,
and
this
was
a
work
that
involved
three
people
and
overall,
it
was
an
extremely
positive
experience
and
our
initial
rollout
had
over
20
plus
data
users
and
their
feedback
has
been
quite
good,
though
at
this
time
because
of
the
lack
of
metrics.
I
can't
really
tell
you
if
this
number
has
changed
over
time,
but
it
is
the
information
that
we
have
right
now
and
but
finally,
data
how
about
as
a
system.
It
is
relatively
complex
right.
C
C
This
we
did
contribute
with
some
things,
particularly
monitoring
metrics
cron
crawling
support
for
metadata
all
of
this
done
in
kubernetes,
because
that
is
our
default
deployment
mode
and
finally,
support
for
jude,
though
it
is
not
the
end
of
contributions,
I
hope,
but
we
will
see
as
time
moves
on
so
just
to
give
you
a
sense.
This
is
the
ecosystem
that
we
had
before,
and
this
is
what
we
have
additionally
with
the
with
data
right
and
you
have
your
they
have
you
high
your
installation?
C
This
is
all
done
in
kubernetes,
then,
through
the
data
hub,
metadata,
crawlers
and
the
cron
jobs
we
very
high
and
and
finally
with
regards
to
opportunities,
and
we
feel
naturally,
there
are
things
to
improve.
There
always
are
in
good
projects,
and
in
our
case,
for
our
use
case,
it's
dynamic
metadata
models.
C
It
is
true
that
these
models
are
flexible
and
that
you
can
change.
However,
they
are
hard-coded
into
the
database
in
the
sense
that
if
we
wanted
to
change,
we
needed
to
maintain
a
fork
of
the
project
continuously
and
from
time
to
time,
merge
things
from
the
original
repository
to
game
all
the
niceties
and
all
the
features
that
have
been
released
and
the
reason
we
want
to
do.
This
is
not
all
our
data.
Stakeholders
are
tech,
savvy
right.
Some
of
them
come
from
linguistics
backgrounds,
with
little
to
no
cs
training
and
for
them
semantics
matters.
B
C
Other
things
include
role-based
active
access
control
so
having
granular
entity
level.
Access
definitions
is
something
that
I
feel
is
quite
important
so
being
able
to
say
that
a
given
data
user
has
access
to
data
sets
a
b
and
c,
but
not
d,
e
and
f,
and
this
is
something
that
is
very
relevant
to
us
and
finally,
field
level,
lineage
based
on
jobs
and
pipelines.
So
because
we
have
certain
data
sets
or
in
a
certain
views
where
a
subset
of
those
columns
are
generated
by
job
a
and
the
others
are
right
on
job
b.
C
This
is
the
sort
of
information
that
we
want
to
make
sure
we
surface
correctly,
though
I
do
have
to
mention
that
all
of
this
is
already
in
data
hub's
backlog.
So
I
don't
think
that
I'm
saying
anything
new
here
sure
shankar,
but
it's
just
what
we
had
to
find
crowd
and
would
like
to
see
in
the
future
and
yeah.
I
guess
that's
it.
I
don't
know.
If
anyone
has
any
questions,
I
do
apologize.
If
I
sped
through
this
presentation,
but
give
me
your
feedback,
if
you
have
any
thank
you
so
much.
A
Cool
thanks
a
lot
pedro,
definitely
plus
one
on
all
the
pain
you
felt
with
some
of
those
things,
especially
the
metadata
models.
We
feel
it
every
time
we
add
one
small
thing
to
it,
so
no
code,
metadata
models
are
absolutely
top
of
mind
for
us
and
our
back
also
on
the
roadmap
field
level.
Lineage
also
we've
got
the
rfc
in
and
so
we'll
figure
out
the
implementation
pretty
soon.
A
Question
for
you
pedro,
and
then
we
can
do
some
quick
questions
from
the
community.
You
know
you
currently
have
it
have
data
hub
kind
of
crawling,
your
druid
and
hive
clusters.
You
also
have
some
kafka
connect
in
your
ecosystem.
Yes,
do
you
anticipate
kind
of
pushing
metadata
from
that
streaming
ecosystem
into
data
hub
in
the
future.
C
Ideally,
yes,
I
do
feel
that
kafka
connects
integration
is
more
on
the
level
of
lineage
than
generating
metadata
assets
themselves.
So,
right
now,
as
I
understand
it,
the
ingestion
framework
will
generate
data,
sets
snapshots
and
possibly
even
user
information
for
ldap
systems,
and
I
feel
that
it
needs
to
be
adapted
to
be
able
to
provide
these
sort
of
connections
or
updates
to
aspects
of
metadata
right.
Kafka
connect
feels
very
much
like
a
source
of
that
type
of
metadata
and
at
the
ingestion
framework
level.
We
don't
yet
have
that.
A
We
can
probably
use
the
same
strategy
for
kafka
connect
where
there's
like
framework
level
integration
with
kafka
connect
and
when
those
pipelines
start
up,
they
emit
metadata
events
that
then
connect
the
edges
together,
so
that
I
think,
would
be
great
for
the
community
as
well.
Are
there
any
other
questions?
We
have
a
minute.