►
From YouTube: Managing Data Governance via Protobuf + DataHub
Description
Graham Stirling, Head of Data Platforms at Saxo Bank, shares how he and team are managing Data Governance via Protobuf during Metadata Day 2022.
Learn more about DataHub: https://datahubproject.io
Join us on Slack: http://slack.datahubproject.io
Follow us on Twitter: https://twitter.com/datahubproject
A
A
We
knew
at
the
time
that
our
target
architecture
had
to
be
federated
but
governed,
and
I
guess
governed
with
the
small
g
and
we
wanted
to
break
down
silos
and
power
domain
teams
to
be
masters
of
their
own
destiny
whilst
at
the
same
time
uplifting
our
technical
capability
and
central
to
this
idea,
of
course,
is
thinking
about
data
as
a
product
designed
for
usage.
You
know
within
a
domain
beyond
the
domain.
A
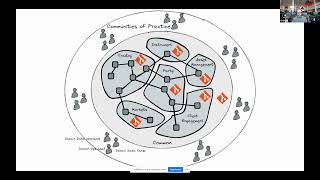
So
domains
host
and
serve
the
data
to
the
organization
using
self-service
data
infrastructure
that
my
team
is
ultimately
responsible
for
now
beyond
enabling
teams
to
get
on
with
their
use
of
kafka.
The
goal
of
the
platform
is
to
reduce
the
cognitive
load
on
our
development
community,
whilst
also
raising
the
data
management
bar.
A
It's
a
difficult
balance
to
strike
and
we
certainly
haven't
got
it
right
all
the
time,
but
in
doing
so
we
place
a
lot
of
emphasis
on
on
shifting
left
on
data
governance,
treating
governance
as
a
platform
requirements,
a
non-functional
set
of
requirements,
rather
than
an
afterthought.
I
did
notice.
There
was
a
great
paper
on
the
linkedin
engineering
blog
the
the
other
day
on
this
on
this
very
same
subject,
but
shifting
left
means
for
us
certainly
think
about
data
governances
as
code.
A
You
know,
for
example,
by
annotating
schemas,
with
their
information
classification
at
source,
rather
than
as
an
afterthought,
and,
of
course,
for
this
data
mesh
idea
to
be
worth
it.
We
need
to
see
the
utility
of
the
data
amplified
at
the
end
of
the
day,
we
need
more
consumers
and
producers.
Otherwise,
what's
the
point
quite
frankly
and
key
to
this
is
of
course
metadata.
A
We
see
metadata
as
being
the
glue
that
ties
these
different
data
domains
together.
That
ensures
that
the
sum
of
the
parts
is
is
greater
than
than
the
home
and
schemas
are
a
key
part,
of
course,
of
our
metadata
story.
So,
for
example,
through
the
use
of
strong
typing,
we
believe
that
it'll
be
easier
for
engineers
to
find
the
data
they
need
to
use
and
to
use
it
safely
without
introducing
tight
coupling
between
services
or
teams.
A
A
So
within
the
trading
domain
we
have
a
topic,
a
log
of
positions
essentially
which
is
represented
by
this
open
position,
schema
here
and
then
within
the
instrument
domain.
Obviously,
financial
instruments.
We
have
a
compact
topic,
which
represents
a
bunch
of
commonly
used
instrument,
attributes
as
represented
by
the
instrument-based
schema.
Now.
Both
of
these
schemas
then
make
reference
to
this
identifier.
This
instrument,
identifier
and
we
think
very
much
about
these
identifiers
as
being
the
join
keys
of
our
data
mesh.
A
It
makes
it
very
clear
to
potential
consumers
how
they
might
go
about
joining
the
the
two
data
sets
together
to
create
their
own
data
products.
That's
certainly
the
idea
and
that's
all
great,
but
you
know
navigating
what's
turning
in
to
be.
You
know,
thousands
of
schema,
fragments
and
git
repositories
isn't
particularly
accessible,
and
this
is
where
the
fantastic
data
hub
project
comes
into
play
from,
from
our
perspective,
so
a
discovery
platform
that
can
surface
this
rich
metadata
and
make
it
accessible
to
a
much
wider
audience.
A
A
This
open
position
is
then
mapped
in
data
hub
terminology
to
a
data
set
and
these
these
fragments
these
schema
fragments.
These
reference
types
are
then
mapped
to
glossary
terms,
so
we
have
a
glossary
term
in
this
particular
case
here
for
instrument
identifier
and
similarly,
we
also
create
one
for
open
position
with
the
basis
on
the
on
the
assumption,
of
course,
that
that
same
schema
could
be
used
by
multiple
topics.
So
again,
nothing
particularly
error
shattering.
A
So
putting
this
all
into
context,
we
have
schemas
authored
by
some
lucky
individual
in
the
role
of
a
domain
data
modeler,
and
you
know
for
our
complex
domains
or
trading.
For
example,
that
might
be
someone
who
spends
you
know
a
lot
of
the
time
in
that
particular
space,
and
sometimes
in
our
you
know,
analytical
consumer-aligned
domains.
A
A
A
We
can
see
which
data
sets
are
using,
what
terms
without
losing
the
fidelity
of
the
underlying
data
contracts.
As
I
say
it's
all
about
trying
to
it's
all
about
trying
to
bring
the
power
of
proto
to
the
people,
okay,
so
that
foundation
in
place.
I
really
just
wanted
to
talk
about
future
directions.
You
know
some
ideas
in
terms
of
how
we'd
like
to
take
this
forward.
So
there's
absolutely
you
know
nothing
set
in
stone
here.
I
think
probably
what
we're
talking
about
here
is
much
more.
A
You
know
from
our
perspective,
q3
deliverable
so
very
much
of
the
ideation
phase,
and
you
know
super
keen
to
get
any
feedback
from
the
community,
but
certainly
as
we
get
more
eyes
on
the
metadata,
the
description
originally
provided
by
developers
you're
quite
often
under
duress.
You
know
when
they,
when
their
pipeline
fails
because
there's
no
documentation.
A
A
So
it's
not
unreasonable
that
our
data
product
owner
wants
the
ability
to
tweak
this
documentation
without
having
to
edit
the
files
himself
or
raising
a
ticket
for
the
dev
team
to
address,
and
you
can
just
imagine
what
that
workflow
might
look
like
you
know.
The
data
product
owner
raises
a
ticket.
A
developer,
picks
it
up,
creates
a
branch
makes
a
change
raises,
a
pr,
it's
a
lot
of
effort
to
fix
a
typo
and,
of
course
it's
it's
friction
in
the
process,
which
means
that
ultimately,
it
won't
get
addressed.
A
So
thankfully,
data
hub
already
has
an
edit
description
on
the
data
set.
So
you
know
in
this
particular
case
here
the
the
product
owner
might
be
thinking
about.
Well,
we
can
come
up
with
a
better
description.
You
know,
is
it
the
currency?
Is
it
the
account
currency?
Is
it
the
exchange
or
the
currency
of
the
exchange
whatever
it
might
be?
I
guess
there's
room
for
there's
room
for
improvement
and
we
have
a
long
overdue
contribution
to
the
glossary
term
to
reflect
the
same.
So
what's
the
problem,
of
course
the
problem
is
the
proto.
A
What
about
the
proto?
We
started
out
with
the
code
as
the
source
of
truth
pushed
the
data
hub
on
change
and
if
we
update
it
here
through
the
ui
well,
of
course
the
two
will
quickly
diverge
and
you
know
we
all
know
that
that's
not
going
to
end
particularly
well
so
be
to
be
consistent.
Then,
with
our
shift
left
methodology,
we
want
the
proto
to
be
the
source
of
truth,
not
just
for
the
technical
schema,
but
the
supporting
metadata
as
well.
So
how
might
we
go
about
that?
Well,
what's
the
way
forward?
A
Well,
one
approach
that
we
we
had
been
thinking
about
was
you
know,
tapping
into
the
metadata
audit
events
generated
under
the
hood
and
actually
automatically
raising
a
pr
to
update
the
proto.
Now
we've
got
that
full
audit
trail
of
ultimately
know
why
a
description
was
changed
and
ultimately,
by
whom,
but
having
said
that,
I'm
just
coming
up
to
speak
now
with
the
new
actions
framework.
So
perhaps
that's
a
better
solution.
Again.
A
I'd
love
to
get
some
feedback
from
anyone
else,
who's
tackling
a
similar
set
of
problems,
but
at
the
end
of
the
day,
the
goal
here
is
to
empower
both
those
with
a
technical,
leaning
and
those
much
more
concerned
with
curating
their
their
data
products.
Each
of
these
you
know,
personas.
These
individuals
brings
a
different
perspective
to
the
table
which
we
should
celebrate
and
embrace
rather
than
push
towards
different
tools.
Yeah,
I'm
sure
you've
been
in
situations
before,
whereby
you
know
the
business
essentially
have
one
one
data
catalog,
which
sits
in
a
conceptual.
A
A
Another
request
that
we're
starting
to
see
more
often
as
the
complexity
of
our
schemas
increases
is
the
need
to
visualize
the
relationships
between
data
sets
and
their
constituent
parts.
Again,
perhaps
thinking
about
the
community
of
data
architects,
who
are,
let's
see
more
familiar
with
visual
representations,
uml
diagrams
er
diagrams,
whatever
it
might
be,
you
know
they
still
have
a
role
to
play
in
this
new
world.
A
We
just
need
to
remove
the
friction
and
you
know
give
them
access
to
similar
sets
of
data
exploration
tools,
perhaps,
and
would
then
there
might
be
accustomed
to,
of
course,
under
the
hood,
we
have
all
this
information
in
data
hub's
graph
database.
We
just
need
to
surface
it
in
in
a
user-friendly
way.
So
certainly
that's
another
another
challenge
for
us
and
again,
you
know.
The
goal
here
is
to
power
both
those
with
a
leaning
towards
the
code
and
and
those
used
to
navigating
relationships,
perhaps
using
a
visual
modeling
tool.
A
You
know
we
certainly
don't
want
to
be
in
a
situation
where,
where
we're
modeling
schemas
in
in
uml
and
generating
code
off
off
the
back
of
that,
we
want
to
have
this
code
first
approach
and
again
I'd
love
to
hear
from
the
folks
the
community
we're
already
thinking
along
these
along
the
same
lines,
but
that's
it
for
me.
This
was,
of
course,
a
very
quick
lightning
talk
super
happy
to
take
any
questions.
I
hope
you
found
that
in
some
shape
and
form
useful.