►
From YouTube: Preventative Metadata: Building for Data Reliability with DataHub, Great Expectations, and Airflow
Description
John Joyce & Tamás Nemeth go in-depth about how you can use DataHub + Airflow + Great Expectations to scalably address data reliability.
Learn more about DataHub: https://datahubproject.io
Join us on Slack: http://slack.datahubproject.io
Follow us on Twitter: https://twitter.com/datahubproject
A
So
hopefully,
everyone
can
see
my
screen
we're
going
to
be
actually
giving
like
a
condensed
lightning
talk,
based
on
a
talk
we
gave
on
monday
at
airflow
summit.
It
was
about
building
data
pipelines
for
data
reliability
in
mind,
with
a
set
of
tools,
data
hub,
great
expectations
and
airflow
all
right,
let's
get
right
into
it.
So
the
first
thing
we're
talking
gonna
talk
about
is
what
this
concept
of
data
reliability
even
means
and
kind
of
why
you
should
care.
A
So
we
looked
to
two
definitions.
When
we
were
thinking
about
what
data
reliability
means,
the
first
is
reliable,
which
means
consistently
good
in
quality
or
performance
able
to
be
trusted
and
reliability,
which
really
means
the
overall
consistency
of
a
measure,
and
when
you
think
about
this
applied
to
data,
we
think
a
good
way
to
think
about.
It
is
really
that
data
reliability
is
the
overall
consistency
of
data
quality.
A
Well,
data
quality
can
be
thought
of
as
kind
of
a
set
of
living
dimensions,
availability,
which
just
means
that
you
know
data
is
available
for
access
timeliness
which
is
really
about
you
know
how
soon,
after
something
happens,
does
the
data
actually
reflect
that
it
happened?
So
data
is
typically
modeling.
Some
events,
how
long
after
those
events
is
that
updated
data
ready
to
use
and
then
correctness
which
is
really
about?
A
Does
the
data
accurately
represent
what
it's
supposed
to
be
representing
and
then
data
reliability,
which
can
be
thought
of
again
as
sort
of
the
consistency
of
data
quality
over
time?
So
what
we're
looking
at
here
is
something
that
would
be
maybe
less
reliable,
where
the
quality
is
sort
of
varying
dramatically
over
time,
and
this
would
be
something
more
reliable
where
the
quality
is
sort
of
stable
and
high
over
time.
A
So
two
characteristics
there,
both
the
consistency
and
the
fact
that
the
quality
is
remaining
high,
all
right
so
thinking
about
this,
how
do
we
realize
data
reliability?
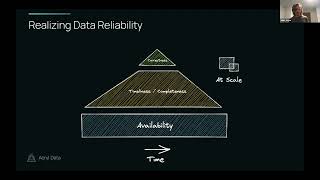
Well,
we
try
to
build
availability,
timeless
completeness
and
correctness
into
all
of
our
data,
but
we
have
to
do
this
across
time.
So
as
our
ecosystem
changes
and
as
our
data
changes
which,
as
we
all
know,
this
is
a
really
tough
challenge
by
itself
and
then
finally
at
scale.
A
A
What
we're
seeing
is
companies
sharing
data
and
actually
building
data
dependencies
across
one
another
very
similar
to
how
many
companies
have
built
online
dependencies
across
each
other's
services?
And
what
that
means
is
that
you
know
these
attributes.
Availability,
timeliness
and
correctness
are
just
going
to
continue
to
grow
in
importance
over
time
and
as
a
data
platform
team.
There's
various
challenges
we
have
to
face
in
data
reliability.
The
first
is
we've
kind
of
touched
on
its
scale.
You
know,
collecting
data
has
never
been
easier.
More
people
have
never
been
interfacing
with
digital
products
than
today.
A
A
A
So,
for
example,
we
have
one
that
produces
a
derived
table,
we
have
another
which
maybe
produces
a
table
that
serves
as
input
to
a
to
a
looker
chart,
and
then
we
have
another
which
maybe
generates
some
emails
based
on
that
table,
and
one
key
characteristic
here
is
that
the
producer
of
the
upstream
table
is
independent
of
the
consumers.
So
there's
decoupling
between
the
two
and
really.
A
A
This
is
what
we
call
contract
on
read
and
what
I
mean
by
that
is
that
the
contract
of
the
data,
not
just
its
structure
or
like
the
columns
and
the
that
kind
of
thing,
but
the
actual
kind
of
row
profile
as
well,
so
the
whole
semantic
contract
of
the
table
is
verified
by
the
consumers
when
they
read
the
data
and
there's
some
different
downsides
to
this
approach.
That
we've
seen
one
is
that
it's
just
ad
hoc
and
inconsistent.
A
A
A
B
A
A
This
is
what
we
call
contract
on
right,
because
when
the
table
is
written,
we're
verifying
certain
attributes
of
the
table
establishing
that
it's
trusted
and
there
are
self
upsides
to
this
type
of
a
pattern.
There's
consistency,
there's
better
coverage
of
the
contract
because
the
owner
has
all
of
the
the
context
of
what
the
table
should
look
like,
theoretically
being
closer
to
the
source
and
then
finally,
it's
like
a
centralized
play.
A
We
don't
have
to
have
the
consumers
verifying
things,
but
in
this
approach
you
know
there's
a
few
patterns
you
can
use
one
is
you
could
fail
the
upstream
dag
if
the
validations
don't
pass?
Maybe
this
is
running
as
the
final
operator
in
the
dag
or
you
could
I
mean
that's,
that's
pretty
much
the
main
one,
but
there's
not
really
any
way
to
communicate
that
that
status
of
the
upstream
dag
to
the
downstream
consumers-
and
this
is
what
we
call
the
communication
problem.
A
It's
really.
How
do
the
downstream
consumers
really
know
whether
the
upstream
validations
pass
or
fail
for
a
given
day,
there's
not
really
a
clear
way
to
communicate,
and
so
what
we're
proposing
is
introducing
a
metadata
platform
in
between
these
two
decoupled
producer
and
consumers
and
what
we
call
this
is
metadata,
driven,
orchestration
and
here's
how
it
works.
Basically,
as
a
producer,
dag,
you
kind
of
add
a
final
step
after
you've
produced
a
table
and
run
validations,
which
is
called
the
reporting
step.
A
So
what
you
do
during
the
reporting
step?
Is
you
push
a
signal
to
data
hub
which
basically
says
I
have
produced
this
downstream
table
and
it
has
passed
or
failed
its
validations
and
then
what
you
can
do
on
the
other
side
is
add,
a
very
thin
preflight
check,
which
simply
checks
that
the
upstream
data
that's
serving
as
inputs,
have
indeed
passed
and
are
up
to
date
based
on
the
consumer's
expectations.
A
So,
for
example,
this
producer
may
say:
hey,
I
inserted
45
rows
into
the
table
and
the
table
passed
its
entire
validation
suite
and
then
the
preflight
check
would
ask
the
same
question.
Is
the
input
data
up
to
date,
meaning
has
it
been
updated
in
the
last
12
hours
and
is
it
passing
its
validations
or
is
it
failing
all
right
and
then
basically
there's
kind
of
two
outcomes
that
we
can
take?
If
the
checks
pass,
we
can
run
the
pipeline
if
they
fail.
A
We
can
circuit
break
just
to
make
sure
that
bad
data
is
not
propagating
downstream
and
we
don't
have
a
huge
mess
to
clean
up.
Obviously,
this
is
a
very
simple
case,
but
there
are
cases
where
there
are
many,
maybe
hundreds
of
downstream
looker
charts
or
dashboards
dependent
on
an
upstream
table,
and
you
can
imagine
the
difficulty
and
the
complexity
associated
with
kind
of
going
up
that
entire
dependency
chain
and
backfilling
stuff
when
bad
data
makes
it
all
the
way
down
all
right.
A
So
a
practical
example
of
this
and
we're
going
to
actually
continue
with
what
maggie
introduced
earlier.
This
idea
of
long
tail
companions,
which
is
a
company
that
you
know
pet
adoption
company
and
we're
going
to
have
a
very
basic
pipeline
as
an
example,
we
have
a
set
of
pet
profiles
which
is
updated
from
some
online
store,
periodically
it's
etl
into
s3.
A
Well,
what
happens
is
that
the
snowflake
table
is
also
delayed,
so
it's
not
updated
for
the
day
and
our
email
sender,
job
doesn't
know
about
this,
of
course,
and
it
still
runs,
and
so
what
does
that
mean?
Well,
it
means
that
we're
pushing
bad
recommendations
to
prospective
adopters,
so
maybe
for
pets
that
have
already
been
adopted,
and
that's
that's
pretty
bad,
because
we
don't
want
to
pull
on
their
heart
strings
or
like
make
our
customer
support
team
upset
by
all
of
this.
So
we
really
want
to
prevent
this
type
of
thing.
A
So
we
start
to
think
okay.
How
can
we
prevent
a
situation
like
this
in
the
future,
and
this
is
where
the
first
abstraction
provided
by
datahub
comes
into
play,
which
is
we're
calling
datahub
operations
and
the
first
step
of
using
datahub
operations
is
to
report
when
something
happens
in
an
upstream
dag.
So,
for
example,
in
that
snowflake
loader
dag,
we
could
add
a
final
piece
of
code
that
would
push
that
they
had
inserted
a
thousand
new
rows
into
pet
profiles
at
some
point
in
time
and
then
on
the
other
side.
A
B
Yeah,
let
me
show
you
how
you
can
apply
this
technique
to
your
airflow
pipeline,
so
for
the
simplicity,
these
two
dags
will
be,
will
have
only
one
task
for
each,
so
even
the
snowflake
loader
and
the
email
center
one
and
as
well
for
the
simplicity
for
both
tasks,
will
be
a
simple
bash
operator,
some
kind
of
limit
bachelor
period
there.
So
for
this
task,
which
will
be
the
prep
profilers
load,
we
define
inlets
and
outlets,
which
is
provided
by
the
airflow
lineage
api,
and
we
define
data
sets
like
input.
B
Data
sets,
which
will
be
here
in
this
case,
an
s3
location
where
we
load
data,
which
will
be
the
outlet
into
snowflake
and
on
success.
We
want
to
send
out
operational
metadata
and
how
you
send
it
with
operation.
Metadata
is
pretty
easy.
We
have
a
we,
we
basically
working
on
these
new
api.
So
first
you
have
to
create
a
data
hub
connection,
and
then
you
keep
here
this
operational
reporter
and
basically
you
go
through
all
of
the
outlets
and
send
out
operational
metadata
to
data
hub.
B
In
this
example,
we
are
sending
out
the
operation,
the
urn
of
the
data
set,
which
we
would
like
to
send
in
operational
metadata
and
the
type
of
operation
which,
in
this
case,
is
our
insert
operation.
Of
course,
you
will
be
able
to
send
out,
like
other
informations
as
well
like
partitions
or
the
number
of
other
metadata,
or
a
number
of
rows
affected
and
various
other
key
values,
very
key
values.
What
you
can
imagine
or
what
you
want
to
send
out.
A
Awesome
so
once
we've
kind
of
posted
that
to
datahub
we
can
add
a
small
snippet
on
the
email
sender
side,
which
basically
just
verifies
that
that
information
has
been
reported,
and
you
can
do
things
like
verify.
Custom
metadata.
So,
as
tamash
was
alluding
to
you
can
verify
that
a
partition
has
landed
even
or
you
can
verify
that
the
upstream
job
was
a
scheduled
job
versus
a
backfill
job.
That
sort
of
thing,
and
now
we'll
just
look
at
how
you
can
do
that
verification.
B
Yeah,
so
to
protect
us
from
a
premature
pipeline
start
we
create
for
the
email
center
set
up
a
data
hub
operations
circuit
breaker
sensor,
it
is,
will
be
a
sensor
which
will
be
in
the
beginning
of
your
pipeline.
It
will
be
going
to
check
the
if
operation
and
metadata
exist
and
if
and
it
and
the
pipeline
continues,
if
there
is
so
to
create.
It
is
very
easy.
You
just
create
a
data
hub,
operational
circuit,
breaker
sensor.
You
basically
pass
in
a
data
connection
and
as
well
a
list
of
earns
which
data
set.
B
You
want
to
check
operational
metadata
and
also
you
can
set
a
time
data,
which
is
the
time
frame
where
you
accept
operation
metadata.
In
this
case,
it's
like
a
12
hour,
because
you
can
imagine
you
don't
want
to
start
your
pipeline.
If
you
only
have
a
data
which
was
created
like
two
days
ago.
This
makes
sure
that
your
pipeline
won't
start
in
this
case.
B
Yeah
and,
of
course
yeah.
So
this
is
now
a
sensor,
but
we
are
going
to
provide
other
airflow
primitives
like
operator
and
also
we
under
the
hood,
the
operator
and
the
sensor
as
well,
using
a
python
api,
and
you
will
be
able
to
use
that
as
well.
So
in
this
way
you
can
basically
integrate
not
just
for
airflow,
but
any
other
systems
as
well.
A
Okay,
so
we've
solved
the
time
problem
with
the
operations.
But
in
this
case
it's
really
a
correctness
problem.
It's
something
about
the
data
itself,
and
this
is
where
our
second
abstraction
comes
in,
which
is
called
data
hub
assertions.
Some
of
you
may
already
be
familiar
or
even
using
assertions
with
great
expectations
already
but
great
expert.
The
assertions
integration
basically
allows
you
to
run
some
validation
at
the
end
of
the
producer.
A
Job
push
those
validations
into
data
hub,
so
examples
are,
you
know
things
about
the
columns
and
then
again
verify
that
before
the
email
sender
runs
and
then
we
can
just
zoom
through
this
piece.
This
is
the
first
step
is
defining
assertions
in
something
like
great
expectations
in
the
future
will
probably
support
other
things
like
eq
or
dmt
tests.
A
Once
once
those
assertions
are
run.
We
push
those
into
data
hub
and
of
course,
some
of
you
may
be
familiar
with
this
screen
already
on
the
right
side,
where
we
surface
the
results
and
then
the
final
step
here
is
again
asking
datahub:
hey
are
my
upstream
assertions
passing
and
are
there
results
that
are
recent
that
I
should
be
able
to
trust
tamash?
You
want
to
talk
about
this
part
again.
B
Yeah
so
here
in
this
example
for
the
email
standard,
we
will
introduce
a
data
accession
circuit,
breaker
operator.
So,
as
you
can
see,
we
provide
operators
as
well,
then,
basically
setting
up
quite
similar
like
how
it
was
like
the
operator
operational
circuit
breaker.
Basically,
you
just
create
a
database,
a
session
circuit
breaker
operator.
A
B
A
Have
data
hub
operations
which
maybe
helps
towards
the
availability
and
timeliness
side,
and
then
we
have
data
hub
assertions
which
will
help
more
on
the
correctness
aspect
of
things.
I
think
we're
doing
an
okay
job
on
the
through
time
aspect
of
reliability.
But
one
thing
we
haven't
really
touched
on
is
how
to
actually
do
this
at
scale.
So
we've
instrumented,
you
know
one
dag,
but
how
do
you
handle
hundreds
or
thousands
of
dags
in
your
ecosystem?
A
A
Is
basically
two
steps?
First
step
is
defining
a
data
hub
test
and
here's
what
the
definition
of
language
will
initially
look
like
it's
going
to
be
a
yaml
file
and
there's
two
key
blocks.
I
want
you
to
look
at
the
first
is
the
on
block
and
that
basically
filters
down
the
different
entities
in
your
metadata
graph.
A
So
that's
kind
of
the
first
step
is
the
test
definition.
Second
step
is
data
hub
runs
these
tests
continuously
over
time
on
your
graph
as
the
metadata
changes
and
we
surface
the
results
of
these
tests
in
real
time
on
the
entity
pages
to
which
they've
been
applied.
So
here's
what
that
would
look
like
on
the
right
side,
all
right,
that's
great!
But
again,
how
do
you
integrate
this
seamlessly
into
your
airflow
environment
tamash
one
more
time.
Can
you
walk
us
through
this
one.
B
Yeah
yeah
so,
as
joe
mentioned
metadata
test
validation,
you
don't
want
to
let
your
dag
owners
to
basically
control
if
they
want
to
enable
or
disable
it,
but
you
want
to
make
sure
that
it
will
run
for
all
the
tasks
in
all
your
devs,
and
actually
there
is
one
way
to
do
that
in
airflow,
which
called
like
cluster
policies.
If
you
are
not
familiar
with
what
cluster
police
is
basically
when
create
policies
which
which
will
do
that.
B
What
I
mentioned
so
basically
get
will
be
applied
to
all
of
the
tasks
in
oil
with
that
and
we
are
going
to
create
here
a
test
policy
which
basically
will
get
all
the
tasks
and
basically
you
can
mutate
or
all
of
your
tasks
with
this
policy.
In
this
case
we
are
going
to
add
a
pre-execution
method
to
all
of
your
tasks
which,
where
basically,
we
are
going
to
run
a
metadata
test
circuit,
breaker
setting
it
up.
It's
pretty
easy
here
you
will
see
we
are
going
to
use
the
python
api.
B
You
just
set
up
a
github
connection
and
then
create
a
metadata
test
circuit
breaker,
and
then
we
are
getting
all
the
inlets.
So
the
inputs
input
data
sets
for
your
task
and
basically
we
just
run
the
circuit
breaker
for
all
of
the
data
sets
and
if
any,
if
any
data
set
has
a
failing
test.
Basically,
we
fail
your
task,
and
the
cool
thing
is
that
in
in
this,
is
that
that
you
don't
have
to
change
any
of
your
text
or
any
of
your
tasks?
It
will
be
get
applied
automatically.
A
Awesome
all
right,
one
more
demo,
we're
gonna
escape
at
this
point,
you're,
realizing
that
I
am
not
good
at
the
lightning
portion
of
the
talks,
mostly
just
talking
so
as
we're
as
we're
moving
up
this
this
pyramid.
What
we're
kind
of
trying
to
see
here
or
tell
a
story
about
is
really
preventative
metadata,
so
it's.
A
I
think
that's
the
next
one,
which
is
this
friday,
the
circuit
breaker
apis,
will
come
in
the
next
release,
which
is
june
10th.
I
believe
that's
going
to
include
the
operation
circuit
breaker.
You
saw
the
assertion
circuit,
breaker,
the
test
circuit,
breaker
and
then
deep
integration
with
airflow,
so
supporting
pushing
this
metadata
from
sensors
and
or
from
your
operators,
and
then
the
test
apis
will
be
coming
a
little
bit
later
as
well
in
v0837
june.
A
10Th,
all
right
we're
going
to
go
through
these
one
more
time,
all
right
and
a
summary
of
what
we
talked
about
in
the
talk
data
quality
can
be
thought
of
as
availability,
timeliness
and
correctness.
Data
reliability
can
be
thought
of
as
data
quality
over
time,
and
we
presented
a
new
approach
to
build
data
pipelines
for
data
reliability
or
with
data
reliability
in
mind
using
metadata-driven
orchestration.