►
Description
Susannah Engdahl and Dr. Biswarup Mukherjee share their work using sonomyographic control of upper limb prostheses.
A detailed write-up can be found here: https://drive.google.com/open?id=1ZBzx0Y_mm700YYkTy2DZ4nHfT65yctzy
More information and discussion about EnableCon 2019 here: https://hub.e-nable.org/s/e-nablecon-2019/
More information about e-NABLE here: https://enablingthefuture.org
A
A
So
the
first
point
we
would
like
to
make
is
that
existing
my
electric
technology,
for
the
most
part,
is
controlled
using
surface
lecture
biography,
so
we're
reporting
muscle
activity
electrical
activity
from
the
muscles
through
this
in
surface,
and
this
causes
some
problems
in
terms
of
control,
which
we
can
understand
by
considering
the
sensory
motor
system
as
a
whole.
So
if
you
think
about
someone
with
an
anatomical
arm,
they
have
had
an
amputation.
A
They
have
motor
commands
that
are
sent
down
from
the
brain
through
the
spinal
cord
out
through
the
nerves
and
ultimately
arrive
the
muscles
where
they
cause
a
contraction
and
initiate
a
movement.
Now
when
those
muscles
contract
they
trigger
what
are
called
proprioceptive
receptors
that
are
within
the
structures
in
the
arm,
and
these
pro
receptor
receptors
give
us
a
sense
of
where
our
body
is
in
this
space,
and
we
do
have
obviously
other
sensory
receptors
as
well
and
following
a
mutation
many
of
those
disappear,
but
the
motor
pathways
and
the
pervious
active
pathways
are
still
intact.
A
It's
not
an
intuitive
control
strategy,
so
this
is
one
of
the
primary
areas
that
we
see
our
semi
ography
system
being
beneficial
to
reader.
At
this
point,
ultrasound
again
is
measuring
muscle
defamation.
So,
as
we
take
that
cross
sectional
view
through
the
arm,
we
can
see
how
those
muscles
size
and
shape
change
over
time
and
because
perception,
the
sense
of
perception.
The
sense
of
where
your
body
is
in
space
is
related
directly
to
muscle
deformation.
B
A
B
A
A
A
This
will
follow
this
same
training
procedure
or
more
different
grasps
it
doesn't.
It
doesn't
affect
what
grass
you're
performing
in
terms
of
the
training
but
towards
your
point,
I
will
say
that
we
are
able
to
very
accurately
discriminate
between
those
different
grasps
after
training.
So
what
we're
looking
at
here
is
a
confusion
matrix
for
anyone
who's
not
familiar
with
looking
at
these.
Essentially,
what
we're
plotting
here
is
the
percentage
of
the
time
that
someone
is
intending
to
perform
a
specific
graph
Aron
grasp,
excuse
me
and
that
we
actually
send
that
compress
command
to
the
prosthesis.
A
E
C
A
C
B
A
I'll
talk
through
this
anyway,
so
we
have
this
database
of
reference
images
every
time
that
we
record
a
new
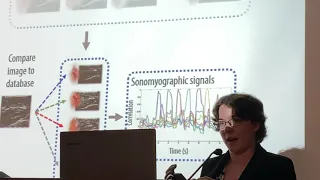
image.
That
image
is
compared
to
everything,
that's
in
the
database
and
we
calculate
correlations
between
the
incoming
image
and
everything
in
the
database.
So
what
comes
out
is
this
colorful
graph
you
seen
here?
So
these
are
the
actual
Sun
high
traffic
signals
that
we're
interested
in
I
know
it's
a
little
bit
fuzzy
to
see,
but
these
big
Peaks
that
stand
out
is
basically
the
system
identifying
that
someone
is
performing
in
grass.
A
B
C
B
B
A
A
C
A
E
B
C
B
A
A
A
So
we
can
identify
every
step
between
zero
and
a
hundred
percent
and
again
we're
just
to
drive
on
this
point
further,
because
we
are
there's
this
direct
congruence
between
the
users
intended
motion
and
we
can
map
that
all
the
way
across
the
percentage
of
completion.
There's
that
correlation
with
muscular.
This
is
a
proprioception
and
the
prosthetic
hand
function
putting
this
all
together.
We
do
believe
that
it
has
enables
a
much
more
intuitive
controls.
Humans.
A
Yes,
I
goes
back
to
the
idea
that,
in
order
to
essentially
trigger
those
four
receptive
receptors
its
directly
depending
on
muscle
information,
so
as
the
muscle
contracts,
we
will
be
gain
that
sense
of
proprioception.
So
if
we're
able
to
track
that
contraction
across
the
entire
movement
cycle,
then
we
should
have
access
to
that
perceptive
cue
across
entire
movement
cycle.
B
A
Concise
way
to
put
it
yeah,
thank
you
just
to
give
a
more
visual
example
of
this
positional
control.
We
designed
an
experiment
where
people
were
asked
to
control
the
position
of
a
cursor
on
a
screen,
so
the
blue
dot
that
you
see
on
that
upper
right
graph
is
the
cursor.
They
can
move
it
up
and
down
on
the
screen
and
it
moves
in
direct
proportion
to
the
level
of
muscle
contraction.
So
if
it's
all
the
way
up
at
the
top
of
the
screen,
that
said,
you
know
maximum
contraction.
A
So
the
task
was
to
try
to
match
the
position
of
that
cursor
with
targets
which
is
represented
by
the
red
line
here.
I
own,
this
place
short
video
and
that's
a
little
bit
hard
to
see
the
trace
at
the
bottom,
but
you
can
see
that
he's
visually.
At
least
it
looks
like
he's
able
to
kind
of
match
that
target
position
pretty
well.
A
And
in
fact,
if
you
plot
this
out
over
a
lot
of
different
target
positions,
over
looking
at
here
is
the
blue
line
corresponds
to
the
position
of
the
cursor
that
the
subject
was
controlling
those
little
diamond
sheets.
If
you
can
see
them
are
the
target
positions,
and
so
you
can
see
there's
pretty
close,
that
a
lot
of
discrepancy
between
the
target
position
of
the
actual
position
is.
Somebody
was
able
to
achieve
all
right,
so
I'm
sure
these
videos
earlier,
but
again
putting
all
these
pieces
together.
A
D
D
So
most
of
the
work
that
Susannah
highlighted,
so
we
work
with
individuals
with
upper
limb
amputation
for
over
a
couple
of
years,
and
we
did
this
study
with
a
lot
of
some
systems.
The
natural
question
would
be
for
most
of
you
who
have
seen
an
alarm
sound
system.
It
looks
kinda
like
a
small
mini
fridge
right.
So
how
would
you
get
this
inside
a
space?
Maybe
this
big
or
even
smaller,
sometimes
right
so
to
understand
why
Poisson
systems
have
not
been
miniaturized
the
extent
that
we
need
it
to
be.
D
D
As
the
part
that
you
see
collision
holding
in
his
hands
and
actually
navigating
on
your
body
to
see
those
images
and
then
there's
a
back-end
which
either
looks
like
a
tablet
in
some
cases,
sometimes
like
a
mini-fridge
which
is
doing
all
the
hard
work
right,
so
it's
doing
all
the
processing.
Now,
if
you
break
open
one
of
these
transducers,
what
you're
going
to
see
is
there
are
individual
piezoelectric
elements,
so
piezo
electricity
is
essentially
the
phenomena
driving
a
material
with
voltage
and
it
generates
sound.
D
So
in
ultrasound
we
drive
each
of
these
elements
with
a
very
high
voltage
and
what
happens
is
these
small
elements
they
are?
They
are
arranged
in
an
array.
Usually
you
get
an
array
of
64
128,
sometimes
even
higher
counts
of
these
elements.
So
you
get
upwards
of
64
elements,
so
it
takes
up
a
bit
of
space
right.
So
you
have
an
array
that
has
64
elements
taking
up
space.
So
that's
one
concern
so
in
order
to
reduce
this
form,
factor
of
the
question
is:
do
we
actually
need
these
many
sensors?
D
D
D
So
you
measure
how
long
it
took
for
sound
to
come
back
in
order
to
figure
out
how
far
the
object
is
so
measurement
of
time
when
it's
in
the
body,
it's
in
the
order
of
centimeters
and
the
speed
that
sound
travels
in,
but
around
1540
with
m/s.
These
time
periods
are
in
the
order
of
microseconds,
so
you're
measuring
very
precise
amounts
of
time.
It's
very
difficult.
D
D
Is
there
an
optimal
number
of
transducers
that
we
can
use
and
get
away
by
if
you're
doing
a
five
motion,
classification
right,
you
know,
all
we
want
to
do
is
a
gesture
recognition
task
or
a
proportional
control
task.
Do
we
really
need
64
sensors?
So
that's
one
critical
question,
second:
is:
can
we
even
with
lower
voltage,
can
we
send
out
low
voltage
pulses
as
a
result?
D
Merely
you
get
a
weaker
signal,
but
is
that
degradation
in
signal
quality
acceptable
if
the
task
is
just
to
classify
images,
if
you
are
not
bothered
about
a
nice
interpretive
image,
can
you
get
away
with
these
constraints?
And
finally,
can
we
measure
depth
without
measuring
time?
So
if
you
don't
have
to
measure
time,
then
you
don't
need
to
make
very
precision
measurements
with
using
digitizer.
So
these
are
the
challenges
that
we
are
trying
to
solve.
D
So
in
order
to
understand
the
first
problem,
can
we
pan
this
down
to
maybe
a
few
sensors
instead
of
64
sensors
right?
So
let's
look
at
what
a
typical
order.
Sound
image
looks
like
so.
You
have
depth
on
the
y-axis,
so
you're,
looking
down
through
the
layers
of
tissue
down
into
your
body
and
on
the
y-axis.
D
What
you
have
is
the
individual
scan
lines
or
the
individual
elements
that
have
basically
passed
on
for
some
signals
into
the
body,
and
you
stack
them
together
and
you
get
this
nice
beautiful
image
now
as
you're
scanning
through
the
body
in
time.
You
get
these
stacks
of
images
and
we
call
these
stacks
of
cinema
as
you
go
as
he
stacked
most
of
these
images
together,
as
you
start
mourning
these
images
together,
you
get
a
nice
cinnamon
loop.
That
shows
you
know
your
muscles
moving
now.
D
A
D
On
the
right,
which
are
which
are
called
EV
mode
images
motion
mode.
So
what
are
we
seeing
here
right?
So,
if
I
select,
let's
say
the
blue
slice
right,
so
it's
a
slice
that
corresponds
to
one
line
or
not
being
on
image,
and
it
goes
across
fine,
so
you're
tracking
one
transducers
image
the
image
that's
coming
out
of
one
transducer
over
time,
so
along
that
line,
whatever
movement
you've
seen
over
time,
you're
going
to
be
able
to
plot
that.
So
now
this
axis
is
time.
A
D
Up
and
down,
you
can
nicely
track
it.
So
now
we
select,
so
we
have
a
blue
scan
line.
We
have
a
red
scan
line
and
we
have
a
green
scan
line,
so
this
can
correspond
to
three
different
sensors
placed
equidistant
from
each
other,
and
so
we
get
three
different
images:
three
different
M
mode
images.
Now,
if
you
move
our
might,
if
I
move
my
index
finger
and
my
god,
what
did
we
get
right?
So
if
he
superimpose
this
images-
and
we
see
what
sort
of
patterns
emerge
out
of
it
right.
D
Most
of
the
movement
is
actually
mostly
restricted
to
M
mantras,
2
&,
3,
so
sensors,
2,
&
3
pick
up
that
most
of
that
motion
and
even
and
are
they're
actually
distinct
right.
So
if
you,
if
you're
just
looking
at
n
1
2
&
3,
you
can
see
that
the
amount
as
distinct
patterns.
Whereas
if
you
look
at
the
ring
finger
movement,
you
see
that
it's
located
in
all
three
sensors.
So
you
can
find
information
about
this
movement
in
all
three
senses.
So
even
with
just
three
sensors
we
can
see.
D
D
So
these
patterns
will
emerge
out
of
these
senses
and
we
have
done
some
formal,
formal
work
where
we
have
systematically
shown
that
if
you
reduce
it
down
to
as
low
as
four
sensors,
you
can
still
retain
classification
accuracies
higher
than
90%,
and
that's
really
was
the
key
finding
that
led
us
to
believe
that.
Yes,
we
can
pare
it
down
to
just
four
senses
to
get
it
to
work
so
from
there
on
what
we
did
was
we
developed
wearable
art,
asan's,
transducer
patches,
so,
on
the
left
hand
corner.
D
What
you
see
is
if
I
take
one
or
two
sound
transducer,
so
not
personal
transducer
will
be
that
white
dot
in
between.
So
each
of
these
elements
can
be
excited
electrically
and
they
will
emit
sound
into
the
body.
So
we
have
four
such
elements.
I
have
only
shown
three
here,
but
there
are
four
elements
over
there
and
this
is
placed
on
a
flexible
silicon
based
patch
and
the
electrical
signals,
and
the
back
end
show
you
later,
and
this
can
be
placed
directly
on
the
skin.
D
D
B
D
F
D
The
cost
was
less
than
4%,
for
so
it's
the
reason
is
the
beta
is
so
rich
and
and
there's
a
lot
of
redundancy
in
the
muscle
Wow.
It
would
be
probably
so.
The
largest
muscle
group
in
the
forearm
is
probably
around
one
square,
centimeter
plus
cross-section
right,
so
you
don't
really
need
that
much
information.
Sure.
F
D
By
sparse
sampling,
if
you
can
still
get
away
by
doing
this
so
yep,
so
now
we
have
attached
these
some
transducers.
What
remains
to
be
seen
is
you
know
the
other
part
of
this
system
where
the
back
end,
but
in
order
to
reduce
the
bulk
of
the
back
end,
we
really
need
to
move
traditional
ways
of
processing
the
signal.
We
cannot
be
exciting.
These
transducers,
with
high
voltage
pulses
high
voltage
pulse
generation
requires
large
circuits.
We
cannot
do
that
so
we
actually
adopted
a
new
technology
called
time.
Delay
spectrometry
this.
D
D
Over
room
stevie
time,
delay,
spectrometry
was
used
extensively
for
this
application
and
we
adopted
those
applications
adopted
this
technology
into
our
facade
imaging
and
we
developed
our
own
system,
which
uses
a
low
voltage
pulse
and
solves
many
of
the
problems
with
the
back
end,
electronics,
and
so
this
is
one
of
the
ports
that
basically
excites
and
receives
signals
from
one
sensor
or
one
channel.
This
is
still
not
the
form-factor
ideal
form
factor
that
we
would
like.
So
this
form
factor
is
about
five
centimeters
by
3.5.
C
D
C
A
D
It's
going
to
be
the
size
of
an
EMG
electrode,
essentially,
so
each
of
these
units
basically
sends
our
signal
receives
it
processes
it,
and
you
have
a
stack
of
four
such
sensors
and
you
can
come.
You
can
basically
control
and
receive
signals
from
that
awesome
band
direction,
so
it's
receiving
from
this
and
the
ultimate
image
that
you
get
from
it
would
be
these
end.
More
images.
F
B
C
D
A
traditional
office
on
system:
what
are
you
doing?
It's
almost
like
hitting
the
transducer
with
a
hammer
right,
so
it's
a
high
voltage
short
trying
pulse.
What
we
are
doing
is
we're
spreading
the
energy
out
over
time,
so
the
total
energy
is
the
same,
but
it's
it's
routable
time.
So
the
small
voltage
that
we
use
our
about
2.5
volts
peak
to
be
compared
to
at
least
forty
two
hundred
volts
peak-to-peak.
So
those
are
much
easier
to
generate.
Yes,.
B
D
Those
sensors
VRS
on
sensors,
but
they
are
operating
at
a
much
lower
frequency,
so
typically
aeroacoustics.
So
if
you're
transmitting
into
the
air,
you
need
frequencies
of
around
100
to
200
kilos,
sometimes
400
kilohertz,
because
otherwise
it
would
attenuate
a
lot.
The
higher
the
frequency
higher
that
generation
in
inside
body.
We
actually
medical
artists
on
imaging.
It
happens
above
one
one
megahertz.
B
A
D
This
image,
what
we're
basically
trying
to
show
is,
you
know,
as
you
do
different
motions.
These
patterns
emerge
out
of
these
motions
and
we
can
do
this.
Real-Time
imaging
at
about
25
words,
which
is
sufficient
for
most
applications
and
beyond.
Personally
control
actually,
and
we
get
really
nice
robust,
snr,
signal-to-noise
ratio
of
about
30,
DB
and
we're
talking
about
this.
D
So
finally,
does
this
work
so
do
we
you
get
the
same
kind
of
classification
accuracies.
The
answer
is
yes,
so
we
tried
classifying
with
these
M
mode
images,
nine
different
motions,
and
then
we
see
them,
and
this
is
with
able-bodied
individuals.
We
see
that
the
classification
accuracy
is
above
90
94%,
almost
95%
classification
accuracies.
Yes,.
D
F
D
D
D
Do
both
there
are
advantages
to
doing
both,
but
in
general
it
really
doesn't
matter.
If
you
do
see
a
degradation
in
signal
quality,
maybe
it
makes
sense
to
move
it
to
a
higher
muscle
power.
We
haven't
done
tests
with
individuals
with
limb
loss
where
positioning
might
be
critical.
So
you
know
in
order
to
get
nice
views
of
the
residual
musculature,
you
may
have
to
move
it
around
and
play
around
I.
E
D
A
D
This
video
is
not
playing
so
I'm
not
going
to
try
it.
So
the
next
step
is
our
random
research
goal
would
be
to
miniaturize
these,
to
an
extent
that
we
can
put
it
inside.
The
prosthetic
socket
socket
do
I
keep
getting
very
close
to
it,
so
the
version
2
of
our
system
isn't
works.
Hopefully
we
have
a
grant
to
get
this
done
in
the
next
year.
So,
but
we
see
applications
of
this
beyond
prosthetics
research,
where
you
want
to
see
muscle
movement,
movement
intent.
This
can
be
a
complementary
technique
to
EMG.
D
F
D
Yes,
so
we
have
done
some
studies
where
you
know
we
that's
what
we
do
is
we
present
the
user
with
a
target,
a
virtual
target
right
and
we
ask
them
to
achieve
it,
and
then
we
remove
this
visual
feedback
and
we
ask
them
to
hold
on
to
that
project
and
we
look
at
the
stability
of
that
signal.
So
how
stable
are
you?
How
stable
is
a
grip
when
you're
actually
not
looking
at
your
hand,
you're
not
looking
at
that
signal,
so
we
see
that
that
signal
is
pretty
stable.
D
You
are
very
good
at
actually
maintaining
that
level,
but
if
you,
if
I,
ask
you
to
leave
that
object
and
reacquire
that
object,
we
are
not
very
good
at
estimating
the
position
of
our
fingers
or
a
grasp
without
actually
looking
at
it.
We
needs
either
tactile
feedback,
haptic
feedback
or
we
need
visual
information,
and
we
have
shown
that
you
know
there
are
ways
to
get
around
it
with
even
very
rudimentary
tactile
feedback,
yep.
B
D
D
Yeah
I
mean
we
may
have
used
open
source
and
you
know
where
we
have
to
attribute
but
other
than
that
yeah,
it's
all
right.
Yes,
so
yeah.
We
are
interested
in
exploring
normal
haptic
technologies
to
go
with
this,
and
we
feel
there's
an
acute
need
for
intuitive
hatrocks
to
go
with
this
intuitive
way
of
controlling
devices.
So
I'm
not
I'll
skip
these
pack,
all
my
lab
members
and
collaborators,
and
we
are
looking
for
active
departments
to
help
individuals
with
limb
loss
get
to
this
technology.
Learn
about
this
technology.