►
From YouTube: Testing the Eclipse OMR Compiler
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
All
right
so
welcome
everyone
to
this
talk,
I
prepared
on
how
to
test
Testarossa
I'm,
going
to
be
focusing
mostly
on
the
Eclipse,
so
I'm
our
compiler
part
of
it,
because
that's
what
I
work
with
and
that's
what
I'm
familiar
with
concepts
are
generally
be
applicable
to
downstream
projects.
Although
there
will
be
some
caches,
I
will
be
going
over.
So
looking
at
the
topics,
I'm
going
to
be
covering
I
will
be
going
over
quite
a
few
features
of
Google
test.
First,
because
these
will
set
us
up
for
properly
being
able
to
write
effective
tests.
A
So
some
of
learning
goals
for
this
presentation
are,
first
of
all,
being
able
to
understand
the
existing
Eclipse
omr
compiler
tests
that
have
already
been
written.
That
will
be
the
first
step
and
then
step
after
that
will
be
being
able
to
write
our
own
tests
and
add
them
to
this
suite
that
already
exists,
so
how
we
get
there
first
I'm
going
to
spend
50%
of
the
presentation,
approximately
just
talking
about
Google,
test
by
itself,
concepts
that
are
very
general
and
applicable
to
just
about
any
project
and
in
the
later
half
of
the
presentation.
A
This
is
going
to
involve
me
just
doing
a
little
bit
of
an
introduction
to
trill
for
those
that
have
not
seen
it
yet
as
well
as
just
how
to
make
trill
and
Google
test
operate
well
together.
So
at
the
end,
we
will
write
roughly
40
lines
of
code
to
generate
75
individually,
runnable
and
executable
tests,
and
my
hope
is
to
show
that
there
it
is
possible
to
get
quite
a
bit
of
coverage
with
relatively
simple
compact
code.
A
I
do
want
to
make
a
note
that
this
presentation
is
very
incremental.
Each
section
will
build
on
the
previous
ones.
So,
if
I'm
going
too
fast,
where
something
doesn't
make
sense,
please
tell
me
I,
don't
want
people
getting
too
lost
on
me,
so
jumping
right
into
the
first
big
topic,
which
is
Google
test,
so
just
a
brief
introduction
to
Google
tests.
It
is
a
xunit
style
testing
framework
for
c++.
So
if
anyone
has
ever
used
something
like
j
unit
or
s,
unit
you'll
find
most
concepts
and
google
tests
familiar
with
some
c++
twists.
A
It
supports
quite
a
few
features
right
out
of
the
box.
I'm,
not
I,
don't
have
time
to
go
over
all
the
features
present
in
Google
test,
so
I'm
only
going
to
go
over
a
subset
that
are
relevant
for
this
presentation
and
in
general
for
the
objectives
of
this
talk.
It
is
open
source.
So
anyone
is
free
to
look
at
the
code
and
contribute
to
it.
Potentially
it
is
cross-platform.
Mostly
there
are
times
when
the
requires
a
little
bit
of
convincing
to
get
working
just
right,
and
it's
also
embedded
directly
into
the
Eclipse
om
our
project.
A
So
anytime,
you
want
to
write
a
test
case.
The
framework
is
already
there
available
for
you
to
use
so
jumping
right
into
the
very
first
example.
This
is
kind
of
going
to
be
the
hello
world
of
Google
tests.
So
first
thing
we
need
to
do
is,
of
course,
include
the
framework
next
to
write
a
very
first
test,
three
lines
of
code,
we're
going
to
use
this
test
macro
that
uses
syntax
very
similar
to
what
you
would
use
for
function
definition.
The
first
argument
to
the
macro
is
the
test
case
name
now.
A
A
We're
also
going
to
define
a
second
test.
This
one
is
a
little
bit
different
here,
because
we're
actually
expecting
this
test
to
fail.
This
is
just
so
I
can
show
you
what
the
output
is
of
a
test
when
things
go
wrong,
so
in
this
case
notice
that
the
test
case
name
is
the
same
as
in
the
previous
test.
But
the
test
name
is
different.
A
So
before
running
it,
of
course,
because
this
is
C++
code,
we
have
to
compile
it,
making
sure
that
we
link
in
the
Google
test
library
and
then
once
we
run
the
tell
the
test
suite
we
get
output.
That
looks
something
like
this
so
right
now
we
only
have
two
tests,
one
test
case,
so
it's
not
a
lot
of
output,
but
I
am
going
to
go
through
with
one
tiny
bit
at
a
time.
A
So
the
very
first
thing
the
frameworks
tells
us
is
how
many
tests
we're
going
to
run
and
how
many
test
cases
we
have
so
right
now,
of
course,
the
good
and
the
bad
tests
in
one
test
case.
We
then
run
the
setup
for
the
entire
testing
framework.
There
are
ways
to
customize
this,
but
right
now
we're
just
going
to
rely
on
the
default
setup.
There
are
two
tests,
of
course,
as
we
already
know
in
the
simple
test
test
case,
because
that
is
what
we
implemented.
A
The
first
test
that
we
run
is
the
good
test,
and
you
can
see
that
everything's,
okay,
it
runs
it
passes.
Then
we
run
the
bad
test
and
in
this
case,
there's
a
failure.
So
the
framework
reports
where
the
failure
occurs.
It
tells
us
the
value
that
caused
the
failure.
It
tells
us
what
the
actual
thing
we
got
was
what
we
expected
to
get
and
then
the
last
line
you
might
notice
is
actually
the
debug
message
we
specified
in
the
test
case.
A
So
I
could
go
back
a
few
slides,
but
I
won't
because
that
boots
time,
and
then
it
tells
us
that
this
is
the
end
of
execution
of
the
bad
test
once
again,
reporting
that
it
failed.
We
are
then
done
running
all
the
tests
within
the
test
case
and
since
we
are
done
running
all
test
cases
as
well,
we
are
going
to
tear
down
the
testing
framework
and,
once
again
we
get
a
summary
of
all
the
tests
that
were
executed
in
all
the
test
cases
they
were
in.
A
After
that
we
did
a
summary
of
the
results.
The
framework
tells
us
how
many
tests
passed,
how
many
tests
failed,
and
it
then
gives
us
a
list
of
what
tests
failed.
This,
you
can
imagine,
is
useful
if
you
have
a
few
thousand
tests
running
and
figuring
out,
which
one
of
those
failed
can
be
a
little
tricky
and
involves
scrolling
back
quite
a
few
pages.
A
The
summary
just
tells
you
right
off
the
bat
what
things
you
need
to
look
at
then
in
case
you
missed
it
the
first
time
the
framework
tells
you
again
how
many
tests
failed
so
jumping
into
the
very
first
slightly
more
advanced
Google
test
feature.
We
are
going
to
look
at
our
death
tests.
This
may
sound,
intimidating,
they're,
not
very
simply
put
the
answer.
The
question
did
the
test
crash
without
actually
crashing
the
test
of
course.
So
how
do
we
write
a
decimal?
A
A
So
this
can
be
a
regular
expression
or
just
a
simple
string
like
I
have
now,
and
the
expectation
is
that,
somewhere
in
the
message
that
gets
printed
when
the
process
dies,
we
expect
to
see
that
pattern
just
to
show
you
what
happens
when
the
pattern
doesn't
show
up
we're
going
to
have
a
bad
test
where
we
will
kill
the
process.
But
we
won't
find
the
pattern
that
we
were
expecting
in
the
failure
message
and
then
just
to
show
what
happens
when
we
expect
something
to
die
but
doesn't
die.
A
A
So
what's
the
output
of
this
once
again,
three
tests
or
from
one
test
case
the
very
first
test
we
tend
to
be
passed,
which
is
what
we
expected.
The
second
test
case
fails,
which
is
once
again
what
we
expected,
and
we
can
see
that
the
framework
tells
us
that
we
died,
but
not
with
the
expected
error.
So
we
were
expecting
to
find
the
pattern
fou,
but
instead
the
error
message
we
got
was
this
then
the
last
test
we
ran.
A
Okay
moving
on
so
the
next
important
feature
to
note:
there's
a
test
fixture,
so
a
test
fixture
is
a
way
for
us
to
share
the
same
setup
and
teardown
code
across
multiple
tests,
potentially
even
multiple
test
cases,
because
very
often
what
you
will
find
is
there
are
a
lot
of
tests
that
need
to
have
the
same
little
snippet
of
code
at
the
top
and
the
same
that
will
snippet
of
code
at
the
bottom.
Using
a
test
fixture
allows
you
to
encapsulate
that
code
and
have
it
be
reused
across
multiple
tests.
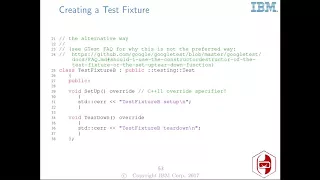
A
A
Then
we
define
the
set
of
code
in
the
constructor
and
the
teardown
code
in
the
destructor
notice
that
this
is
very
reminiscent
of
our
ai
ai,
and
this
is
not
the
only
way
we
can
define
a
test
fixture,
there's
an
alternative,
less
preferred
way,
which
is
to
still
inherit
from
the
testing
test
class,
which
is
Google
test
based
test
fixture
and
instead
we
override
the
setup
and
teardown
functions.
In
this
case,
I
am
using
C++
11
override
specifier.
A
A
We
specify
the
test
fixture,
we
want
to
use
and
then,
as
always,
we
specify
the
test
name
here,
I'm
just
going
to
print
out
a
debug
message
so
that
we
can
see
the
execution
of
the
various
steps
in
the
output
and
just
to
show
that
we
can
actually
share
the
setup
and
teardown
across
multiple
tests.
We're
going
to
we're
going
to
define
a
second
test:
that's
going
to
reuse
the
same
test
fixture
now.
What
happens
if
we
watch
another
test
case
to
use
the
same
test
fixture?
A
Well,
very
simply,
we
can
just
use
a
type
test,
so
we
use
a
type
that
for
the
test
fixture
and
then,
when
we
define
the
test,
we
simply
use
the
name
of
the
type
that
we
define
and,
of
course,
test
fixture
B,
since
we
implemented
I'm
going
to
also
create
a
test
for
it.
So
this
is
what
the
output
looks
like
if
you
were
to
run
the
code.
A
First,
we
run
the
first
test
case,
which
has
inherits
the
name
test
fixture
a
only
two
tests,
because
that's
how
we
implemented
the
very
first
test,
run
and
notice
that
we
indeed
do
the
setup
from
test
fixture
a
we
run
the
test,
and
then
we
do
the
teardown
for
test
fixture
a
looking
at
the
next
test
case.
This
is
notice
that
it
has
a
different
name.
This
is
the
other
fixture
test
case,
but
we
still
execute
the
setup
and
teardown
from
test
fixture
a
and
then
for
test
fixture
B.
A
We
execute
the
setup
and
teardown
for
test
fixture,
B
so
again,
fairly
straightforward.
Any
questions
so
far
am
I
going
too
fast.
Great
next
important
features
are
parameterised
tests.
These
become
a
little
bit
more
complex.
So
sometimes,
when
we're
writing
a
test,
we
have
the
system
we're
testing
and
we
want
to
be
able
to
test
it
with
different
input
values.
This
is,
of
course,
so
that
we
have
better
coverage
and
the
naive
way
of
copying
tasting
the
test
case
over
and
over
again
and
changing
the
input
values.
A
A
A
So
how
do
we
create
a
parameterised
test?
First,
we
need
to
create
a
custom
test
fixture.
It
has
to
inherit,
of
course,
from
the
base
test,
fixture
or
potentially
a
custom
one
as
well.
In
this
case,
we
don't
have,
we
don't
need
any
special
setup
or
teardown,
so
we're
just
going
to
inherit
from
the
base
fixture,
and
we
also
need
to
inherit
from
the
width.
/
am
interface.
This
allows
us
to
specify
what
the
type
of
the
test
parameter
we
expect
is
going
to
be.
A
In
this
case,
I
am
saying
that
our
tests
that
use
this
parameterize
test
fixture
expect
an
integer
as
parameter
to
actually
make
use
of
the
parameterize
test
fixture.
We
use
the
test.
P
macro
specify
the
name
of
the
test
fixture
and,
as
always,
the
test
name
using
the
parameterised
test.
Fixture
gives
us
access
to
the
get
per
am
function
which
is
going
to
return.
The
current
value
of
the
test
parameter
notice.
A
A
We
then
specify
the
name
of
the
test
case.
We
are
instantiating
in
this
case
doubling
test
and
notice
that
that
is
the
name
I
used
for
the
tests,
and
we
then
specify
the
input
values
to
the
tests.
The
Google
test
values
function
is
very
attic
and
allows
us
to
specify
a
list
of
possible
inputs,
so
this
is
our
first
instantiation
and
I'm
going
to
create
a
second
one,
to
prove
my
point
that
we
can
indeed
instantiate
a
test
case
multiple
times
this
time.
A
However,
I
will
use
the
values
in
function
that
takes
as
argument
a
standard
container
and
it
will
extract
the
input
values
from
this
standard
container.
In
this
case,
I
am
defining
one
on
the
fly,
but
you
could
imagine
that
the
standard
container
is
actually
returned
by
some
function
defined
elsewhere.
That
does
more
complicated
things
than
only
specifying
three
input
values.
So
what
does
the
output
of
this
look
like?
A
A
The
first
three
are
the
good
tests
and,
of
course,
they
all
pass
as
we
expected
and
notice
that
at
the
end
of
the
name,
the
framework
adds
in
for
us
a
number
to
tell
us,
which
instance
of
the
test
it
is
running.
This
is
going
to
be
useful
later
on
for
debugging.
Next,
we
have
the
bad
tests
and
something
interesting
here
that
the
first
bad
test
actually
passed.
A
A
Because
so
that
yes
can
I
go
back
if
you
notice,
what
we're
testing
is
that
two
times
P
equals
P
minus
P
and
it
happened
to
work
out
because
get
forever
returns
zero,
so
that
was
just
kind
of
an
artifact
I
threw
in
there
and
so
again
here
this
is
the
second
instantiation.
Once
again,
we
have
six
tests.
A
There's
not
a
thing
much
interesting
to
see
here
so
I'm
just
going
to
move
on
to
the
next
important
feature
which
is
combined.
So
this
is
a
special
function.
Google
test
provides
for
us
that
I'm
going
to
spend
a
bit
of
time
going
over
because
it
can
actually
be
extremely
valuable
for
us
when
writing
tests.
A
What
it
will
do
is
take
two
sets
of
input,
values
and
produce
the
Cartesian
product
of
the
inputs
as
a
list
of
tuples,
so
it
does
require
c++
eleven
support,
but
if
we
do
have
it,
it
is
very
much
worthwhile
using
because
mostly
it
can
massively
increase
test
coverage
with
relatively
little
code
and,
at
the
end,
we're
going
to
use
this
too.
The
75
test
cases
I
promised
so
the
first
step
in
this
example
is
we're
going
to
use
a
type
alias
for
our
type
parameter.
A
This
is
to
avoid
errors
with
typing
in
STD,
typos
and
comma
int.
Every
time,
if
you're
not
comfortable
using
this
syntax,
you
can
also
just
use
a
type
def.
This
is
the
C++
11
way
of
doing
things.
We
then
define
our
parameterised
test
fixture
because
we
are
not
using
a
custom
based
fixture
class.
We
have
the
option
of
simply
inheriting
from
tests
per,
am
sorry
test
with
pram,
which
already
inherits
from
testing
:
:
tests
from
google.
For
us.
A
Looking
at
the
output,
this
is
exactly
what
we
get
six
tests
from
the
example.
Slash
parameterize,
test
test
case
and
notice
at
Google
is
clever
enough
to
be
able
to
format
the
values
from
our
tuples
and
also
note
that
we
do
indeed
get
every
possible
combination
from
the
inputs.
We
specified
all
right
question
so
far
great
so
now
that
we
have
all
of
these
different
ways
of
specifying
lots
and
lots
and
lots
of
tests
when
only
a
few
of
them
fail.
A
It
can
be
very
much
worthwhile
only
executing
the
test
or
investigating,
and
to
do
this.
Google
test
allows
you
to
specify
the
option
G
test
underscore
filter.
When
you
invoke
the
test
suite,
and
it
specifies
a
regular
expression
that
can,
if
own
specified
plainly
will
only
execute
tests
whose
names
match
the
regular
expression
or,
if
you
put
a
minus
sign
in
front,
it
will
execute
all
tests
except
for
the
ones
whose
names
match
the
regular
expression.
A
A
Of
course,
as
I've
already
mentioned,
there
are
many
many
features
that
I
don't
have
the
time
to
cover
in
this
presentation.
Some
that
are
worth
mentioning,
though,
are
the
ability
to
specify
output
with
color.
If
you're,
like
me,
colored
output
helps
when
you
need
to
focus
on
certain
parts
of
output,
so
that
will
just
make
it
so
that
failures
appear
in
red
and
acids
appear
in
green
there's.
A
Also,
a
wealth
of
assertions
available
that
do
several
kinds
of
comparisons,
floating
point,
comparisons,
string
comparisons
and
even
checking
if
an
exception
is
thrown
or
not
with
all
these
assert
macros
there
are
corresponding
expect
macros
that
behave
almost
exactly
the
same
way
except
for
they
will
not
abort
test
execution.
This
can
be
useful
if,
for
example,
you
are
testing
a
function
that
sets
multiple
fields
in
a
struct
using
expect,
instead
of
assert,
allows
you
to
check
all
the
fields
and
destruct
or
set
correctly,
even
if
say,
the
first
one
were
to
fail.
A
Another
set
of
interesting
features
are
typed
test
and
type
parameterised
tests
that
allow
you
to
do
effectively
the
same
thing
as
the
value
parameterised
test
we
just
looked
at,
but
with
types
these
rely
on
quite
a
bit
of
template,
metaprogramming
magic,
so
use
them
at
your
own
risk,
and
that
finishes
the
Google
test
portion
of
the
presentation.
So
now
we
can
move
on
to
trill.
A
So
for
those
that
haven't
heard
yet
trill
is
a
language
with
a
one-to-one
mapping
to
Testarossa
il
it
uses
s,
expressions
to
represent
IL,
so
it's
both
fairly
human,
readable
and
machine
readable.
This
gives
us
the
advantage
of
having
very
tight
control
over
IL
that
gets
generated,
which
is
very
useful
when
writing
test
cases,
of
course,
so
very
simple
example
of
what
a
method
that
returns
three
looks
like
you
specify
comments
with
a
semicolon,
because
I
think
I
was
thinking
in
assembly.
A
When
I
wrote
this,
you
specify
the
method
you
can
give
an
optional
method,
name
specify
the
return
type.
Of
course
il
has
to
go
in
a
block,
so
you
also
specify
a
that.
You
want
a
block
and
then
the
two
nodes
that
we
want
for
returning
three
slightly
more
complicated
example.
That
does
also
return
three,
but
with
a
conversion
operator
thrown
in.
A
A
A
A
We
can
also
represent
commoning,
which
I
happen
to
think
is
a
cool
feature
of
trill,
and
so
in
this
example,
we're
going
to
return
the
square
of
an
input
parameter
by
multiplying
it
with
itself
and
the
way
you
would
define
a
comment.
Note
is
first
specifying
the
node,
giving
it
some
ID,
which
can
be
any
string.
A
Then,
when
we
want
to
comment
the
node,
we
specify
it
with
the
add
common
command
and
then
the
IDS
of
the
node.
We
are
going
to
comment.
You
can
imagine
that
if
you
were
to
look
at
a
trace
log
for
this
output,
you
would
get
I'm.
Always
it's
two
children
being
the
same
node
slightly
more
complex
example.
That
I
should
probably
spend
a
bit
of
time
on,
but
I
won't,
because
it's
not
really
all
that
interesting
for
control
flow.
A
A
Now
we
can
actually
start
talking
about
the
implementation
of
the
tools
built
around
trill,
so
these
are
located
in
the
OM
r
FB
test
or
trill
directory
of
the
eclipse
om
our
project.
If
you're
interested
in
looking
at
the
source
code,
the
lexer
and
parser
are
implemented
using
flex
and
bison.
If
you're
curious
about
how
that
works,
it
currently
supports
most
op
codes
implemented
in
the
eclipse,
OMR
compiler.
However,
only
a
very
small
number
of
them
have
actually
been
tested,
so
you
can
put
that
on
your
to
do
list.
A
It
uses
Jude
filter
as
the
compiler
back-end
and
I
want
to
emphasize
here.
That
Jude
builder
is
really
only
used
for
optimizing
the
code
and
for
generating
machine
code.
It
is
not
used
for
generating
il.
This
is
so
that
we
can
avoid
running
into
problems
with
too
much
IL
being
generated
unnecessarily,
and
it's
built
using
cement
for
those
who
are
interested
in
that
as
well.
So
the
API
for
these
trill
tools
is
quite
extensive.
If
you're
curious
about
them,
I
will
just
point
you
to
the
source
code.
A
A
A
A
A
The
last
interesting
function
we
have
is
get
entry
point,
as
the
name
suggests
it's
going
to
return
the
entry
point
to
the
compiled
body
once
it's
been
compiled.
An
interesting
feature
is
that
you
can
specify
the
function
pointer
type
of
the
entry
point
you
want
to
use
and
if
it
is
not
a
function,
pointer
type,
it
will
fail
to
compile.
A
Next,
we
need
a
concrete
instance
of
this
interface,
which
is
going
to
use,
as
I've
mentioned
already
JIT
builder,
as
the
backend
and
for
the
purposes
of
these
tests.
All
we
need
to
film.
A
header
we
need
to
include
is
the
JIT
builder
underscore
compiler
HPP
header,
which
is
going
to
include
everything
else.
We
need
from
trill
with
these
testing
utilities
for
controlling
trill.
We
can
now
start
talking
about
the
compiler
tests
that
use
trill
so
currently
I've
already
mentioned.
There
are
a
few
of
these
as
already
that
are
implemented.
A
These
are
in
the
OM
r
FB
test,
compiler
trill
test
directory.
The
name
is
not
great,
but
that's
what
we
have
right
now,
if
you
were
to
add
in
your
own
tests,
which
I
really
hope
you
will
at
some
point.
This
is
where
the
test
would
go.
All
the
tests
in
here
have
the
general
pattern
of
parsing
the
trill
method,
compiling
the
method,
and
if
compilation
succeeds,
we
call
the
compiled
body
and,
if
not
well,
we
continue.
Okay,
someone
is
telling
me
that
they
have
a
question
Matthew.
Oh.
A
A
A
So
it's
a
little
bit
more
flexible
than
G
test
implementation
and,
of
course,
we
also
have
a
filter
function
that
allows
us
to
take
a
standard
container
and
remove
elements
from
it
that
match
a
specific
Coretta
Kate.
Anyone
who
has
used
STD
remove
if
this
function
works
almost
the
same
way,
with
the
exception
that
it
will
actually
erase
the
elements
from
the
container
instead
of
just
moving
them
somewhere
else
next
slide.
If
I
can
alright
so
now
we're
going
to
look
at
our
first
example
test
that
is
going
to
use
trill
first
things.
A
A
So
first,
we
define
in
just
a
plain
C
string,
the
trail
code
we
are
going
to
compile.
This
is,
if
you
look
carefully,
it's
really
the
same
code.
I
showed
in
the
previous
slide,
just
all
on
one
line.
Instead
of
being
nicely
formatted,
we
parse
the
string
and
we
get
back
the
ast
root
for
the
method
we
just
defined.
Of
course,
we
are
going
to
assert
that
we
actually
successfully
parsed
the
method
and
next
we're
going
to
create
our
compiler
object
and
compile
the
ast
method
we
defined
asserting
that
compilation
actually
succeed.
A
Lastly,
we
grab
the
entry
point
and
those
take
note
of
how
I
specify
the
function
pointer
type
in
this
case.
I
am
saying
that
I
want
the
entry
point
to
be
a
pointer
to
a
function
that
takes
no
arguments
and
returns
a
32-bit,
integer
and
again
assert
that
the
entry
point
is
indeed
not
channel
so
that
we
don't
end
up
calling
nothing
and,
of
course,
at
the
very
end,
we
are
going
to
call
the
compiled
code
and
assert
that
we
get
three
just
to
show
you
that
this
is
still
very
little
code.
A
Here's
the
entire
thing
on
one
slide:
I
won't
go
through
it
again
to
save
time
for
building
these
tests.
The
first
thing
we
have
to
do
is
actually
build
JIT
builder
itself
for
technical
reasons,
but
once
you
have
that
done,
you
can
go
into
the
tests
directory
and
build
the
tests
using
C
mate.
This
will
produce
a
binary
file
called
comp
test.
A
A
What
will
go
into
the
test?
Parameter
our
test
input
values
to
the
compiled
body
right,
because
up
codes
can
have
more
than
one
child
and
therefore
more
than
one
input,
the
name
of
the
opcode
we
are
going
to
test
and
the
Oracle
function
that
we
expect
to
return
the
same
value
that
we
get
when
we
call
the
compiled
body
with
the
opcode
we
specified
in
the
test
parameter.
Does
that
make
sense?
A
Yes,
okay,
good!
Then
there
is
the
binary
off
test
specialization
of
this
class
that
it
mostly
just
is
there
to
make
it
convenient
to
deal
with
up
codes
that
take
two
children,
so
binary
optos,
so
jumping
right
into
an
example.
I
will
make
a
note
right
here
that
this
is
an
actual
test
that
is
currently
running
as
part
of
the
OMR
continuous
integration
builds,
and
so
this
is
an
actual
test.
A
A
Next,
we
define
the
first
part
of
our
test
case
or
sorry,
the
first
part
of
our
test.
We
call
get
program
to
grab
the
parameter
from
the
test
framework
and
we
use
to
struct
to
unwrap
the
test
parameter
in
a
struct
that
is
going
to
make
it
more
convenient
to
access
the
different
fields
of
the
tupple
we
get.
This
is
so
that
we
don't
have
to
use
STD
get
over
and
over
again.
A
A
A
Next,
we
are
going
to
parse
the
code
which
is
generated.
This
of
course
means
the
code
that
has
a
specified
opcode
name
and
we
are
going
to
assert
that
parsing
succeeds
and
in
the
case
that
it
doesn't
we're
also
going
to
print
out
the
trill
code,
we
attempted
to
parse,
just
in
case
we
might
have
a
chance
at
figuring
out
what
went
wrong
by
eyeballing.
The
code
may
be
helpful,
maybe
not,
but
we'll
have
it
there
in
case
we
need
it.
A
Next,
we
again
compile
the
code
again
outputting
the
trail
code.
If
things
go
wrong
and
at
the
very
end
of
our
test,
we
grab
the
entry
point,
expecting
it
to
be
a
pointer
to
a
function
that
takes
two
32-bit
integer
arguments
and
returns.
One
32-bit
integer,
and
the
very
last
thing
we
do
is
assert
that
when
we
call
the
entry
point
with
the
values
we
get
from
our
test
parameters,
we
get
the
same
value
we
get
from
calling
the
Oracle
function
with
the
same
input
arguments.
A
Hopefully
this
gives
you
a
hint
as
to
what
needs
to
be
done
to
implement
these
Oracle
function,
but
without
leaving
too
many
things
to
the
imagination.
This
is
how
we
have
to
implement
it
or
instantiate
the
test,
we're
going
to
use
Google's,
combined
function,
and
the
first
thing
we
are
going
to
give
the
combined
function
is
a
list
of
input
values
generated
from
my
implementation
of
combine,
which
is
simply
going
to
generate
sets
of
pairs
for
us
from
to
input
lists.
A
Constant
values
is
a
convenience
function,
I
recreated
that
will
simply
return
some
list
of
inputs
of
the
specified
type,
and
this
way
you
don't
really
have
to
worry
about
what
the
test
inputs
are.
You
just
have
to
worry
that
they're
going
to
be
good
enough
and
of
the
correct
type
or
the
test,
so
notice
that
we
are
doing
two
Cartesian
products
here.
A
The
second
value
we're
going
to
provide
to
Google
tests
combined
function,
call
is
a
list
of
tuples,
with
the
first
element
being
the
name
of
the
opcode,
we're
testing
and
the
second
element
being
a
Oracle
function
which,
in
this
particular
case,
I,
am
defining
using
C++
11
lambda
syntax
for
those
that
are
not
familiar
with
the
syntax.
The
example
I
am
showing
right
now
simply
defines
a
function
on
the
fly
that
takes
two
32-bit
integer
arguments
and
returns
their
son.
A
A
That
is
very
similar
to
what
I
just
wrote,
modulo
indentation,
so
that
I
could
make
it
fit
on
one
slide,
but
it's
still
very
fairly
straightforward
code,
and
if
any
one
of
these
were
to
fail,
you
would
be
able
to
debug
it
by
only
running
the
one
test
that
failed
and
the
framework
would
also
tell
you
what
the
input
values
were
that
caused
the
test
to
fail.
So
this
is
a
fairly
powerful
technique.
A
You
can
imagine
also
that
this
was
only
one
test
and
one
instantiation.
You
could,
of
course,
define
a
second
test
and
a
second
instantiation
to
potentially
double
or
quadruple
this
number
of
tests
fairly
easily
and
with
that.
That
concludes
what
I
have
right
now
for
how
to
test
Testarossa
with
the
current
tools
we
have.
This
leaves
us
with,
of
course,
a
follow-up
question,
which
is
what
can
we
do
in
the
future
to
make
things
easier
for
ourselves
and
I've
come
up
with
the
decent
list
of
things.
A
A
This,
of
course,
are
saying
that
our
for
future
work
and
so
could
not
may
not
be
completed
in
any
reasonable
amount
of
future
time,
but
hopefully
we'll
get
there
at
some
point
soon
and,
of
course,
writing
more
tests.
We
can
never
have
enough
tests.
Well,
maybe
we
can
but
I
like
to
pretend.
No
so
with
that.
Here
are
some
resources
in
case
this
presentation
was
not
enough,
which
I
can
tell
you
right
now
that
it
was
not
because
it
was
only
the
introduction.
A
Despite
being
this
long,
there's
still
lots
of
documentation,
you
can
go
through
for
Google
tests.
I
have
found
it
to
be
fairly
well
documented,
so
you
could
get
quite
a
bit
from
just
even
skimming
some
of
the
available
documentation
and
also
the
documentation
for
trill
is
available
both
in
the
trail
source
code,
ending
the
source
code
for
the
tests.
So
if
you
want
to
know
what
exactly
it
is
that
you
can
do
with
trill,
the
documentation
should
tell
you
again
have
spent
a
lot
of
time
working
on
that.
A
So
I
hope
that
it
will
be
useful
and
with
that
and
brings
me
to
the
conclusion
of
this
presentation,
which
has
already
been
long
enough,
I
think
so
just
a
few
closing
remarks.
First
of
all,
thank
you
for
bearing
with
me
I
know.
It
was
a
lot
of
information
to
go
through
now.
Go
write.
Some
tests
go
make
Testarossa
easier
to
test,
and
please
do
ask
questions
if
you
have
any
that's
my
contact
information.
If
you
want
to
reach
me,
thank
you.
A
A
Yes,
so
the
question
was
with
the
complexity
of
isolating
the
different
components
of
the
compiler.
So
right
now
the
idea
was
isolating
the
different
tests.
Sorry
isolating
the
different
components
of
the
compiler
would
be
making
them
easier
to
unit
tests,
so
only
making
sure
that,
given
some
very
restricted
set
of
input,
each
component
of
the
compiler
behaves
as
we
would
expect
it
to.
A
Currently,
the
problem
is
with
trying
to
do
this
approach.
Is
that
there's
a
lot
of
interdependence,
and
so
anytime,
you
try
allocating
one
data
structure.
It
requires
that
you
allocate
and
other
structures
only
so
that
you
are
able
to
execute
the
one
part
of
code
you
are
interested
in.
This
complicates
the
test,
because
if
a
failure
happened,
it
could
be
that
the
failure
is
not
related
to
the
thing
or
testing
at
all,
but
a
dependent
component.
That
is
not
behaving
as
we
would
expect
it
to
be.
A
A
A
But,
generally
speaking,
you
would
not
be
using
the
approach.
I
just
went
through
to
write
tests.
I
would
take
that
into
account.
You
would
have
to
use
more
sophisticated
system
tests
which
you
could
still
use
Google
test
and
trill
for,
but
it
will
require
a
bit
more
up
set
of
infrastructure
so
that
we
can
more
finely
control
that
environment
all
right.
A
Yes,
it
is
very
deterministic,
all
the
values
are
hard-coded,
so
unless
you
have
a
funky
compiler,
which
you
might,
it
should
be
very
deterministic,
and
also
something
that
I
haven't
shown
here
is
the
filter
function.
I
used
can
be
combined
with
the
constant
value
generators
to
eliminate
potential
values
that
you
wouldn't
want
to
test,
for
example,
that
would
lead
to
division
by
zero.
A
A
Currently,
there
is
a
little
bit
of
complexity
involved
in
that
because
of
the
fact
that
we
can't
really
isolate
the
one
part
of
the
compiler
you
might
want
to
test.
So
the
current
facilities
that
are
available
for
doing
this
would
be
the
dumper
for
trill
code
that
will
take
il
and
dump
trill
out
of
it.
The
catch
with
that
is
it's
not
necessarily
obvious,
where
you
have
to
hook
that
up
where
you
would
hook
up
the
dumper
to
the
compiler,
because
of
course,
you
could
hook
it
up
between
each
optimisation
just
before
cogeneration.
A
A
Jet
filter
was
easier
to
hook
up
it's
already
compiled
as
a
library,
so
all
I
had
to
do
was
make
sure
that
I
was
including
the
right
headers
and
linking
the
library
had
I
used.
The
test,
compiler
I,
would
have
had
to
deal
with
more
setup
and
making
sure
that
I
connect
the
right
pieces
together
and
that
could
lead
to
problems
that
I
did
not
have
time
to
deal
with,
but
definitely
at
one
point.
I
am
planning
on
replacing
the
JIT
builder
back-end
with
something
that
is
more
customizable
and
provides
more
control
over
compilation.
A
Mostly
just
calling
the
compiled
method
function
so
yeah,
that's
right,
so
I
use
the
yeah
so
right
now
the
way
it
works
by
the
way.
The
question
was
about
what
I'm,
using
just
build
r4
and
basically
it's
I
use
the
JIT
builder
interface
for
compiling,
but
I.
So
I
use
the
il
injector
interface
for
those
who
have
used
it
and
I,
but
inside
that
interface,
I
use
my
own
custom,
il
generation
process,
so
I
take
advantage
of
the
node
interface
directly.
A
So
the
was
about
have
I,
looked
at
the
optimizations
to
builder,
performs
on
the
IL
that
we
provided
in
the
test
cases
and
what
effects
does
it
have
on
it?
So
it
definitely
changes
it
most
of
the
time
and
I
am
aware
that
that
is
kind
of
a
weakness
right
now
and
this
approach
to
testing,
but
most
of
the
time
I
find
that,
for
example,
the
big
thing
that
will
happen
is
and
constant
folding
seems
to
be
a
big
one
right
now.
A
That
is
simplifying
the
trees
a
little
too
much,
but
at
the
very
least
it
does
tell
us
that
we
can
handle
that
correctly.
Eventually,
as
I
said,
I
would
like
to
replace
the
JIT
builder
backend
with
something
more
customizable,
so
that
for
these
very
simple
tests
that
are
intended
just
to
make
sure
that
we
can
compile
and
evaluate
very
small
chunks
of
il
potentially
just
turn
off
the
optimizer
entirely
or
maybe
run
one
or
two
optimizations.
If
we
want
to
test
those.