►
From YouTube: Flatcar Container Linux community meeting
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
B
C
D
I'm
joseph
sandoval,
I
thought
you
all
knew
me
already,
but
I'm
I'm
with
adobe
as
well,
and
I'm
coming
in.
I
think
I'm
just.
I
did
have
a
follow-up
item
from
the
flat
car
session
that
was
given
at
rejects
in
regards
to
a
flat
car
and
the
direction
it's
going
with
community
upstream.
I
think
that
was
talked
about
so
looking
for
an
update.
A
A
E
Oh
yeah,
so
we
for
the
time
being
we
will
we
will
relax
or
release
cadence
a
little
to
give
the
maintainers
team
a
little
breath.
Currently,
our
release
are
still
still
involve
a
lot
of
manual
steps
if
you're
curious,
just
look
at
release
tracking
issues
and
or
issue
tracker
for
each
release.
We
have
such
a
tracking
issue
and
there
are,
I
think,
up
to
40
steps
that
the
team
works
through
for
each
release.
E
We
have
finished,
we
have
almost
finished
work
on
a
much
more
automated
release
pipeline
and
we're
gonna
tie
up
those
loose
ends
in
the
future
and
basically
bring
it
all
on.
Actually,
first
results,
you'll
see
in
the
the
demo
today
that
gabriel
will
do
on
garm,
because
garm
already
uses
the
the
new
pipeline
elements
from
the
new
pipeline
until
we
have
everything
automated
and
integrated,
we'll
just
give
ourselves
a
little
more
time
and
we'll
relax
from
releases
every
two
weeks
to
roughly
release
every
four
weeks.
A
B
B
B
Now,
the
first
attempt
failed
very
badly,
mostly
because
the
default
github
runners
have
only
two
cpu
cores
and
flat
card
being
a
distribution.
A
linux
distribution
has
many
packages
you
need
to
compile,
and
that
means
it
takes
a
lot
of
time
just
compiling
the
the
flat
card
packages
without
anything
else,
takes
roughly
five
hours
and
there's
a
time
limit
of
about
six
hours
for
every
job
in
github
to
run
so
it
github
just
canceled
my
job,
and
that
was
it
now
to
get
around
this.
B
There
are
two
options:
one
is
to
create
a
github
workflow
that
creates
resources
on
an
external
cloud
somewhere
so
create
a
a
vm,
a
larger
vm.
In
any
cloud
you
wish
and
use
ssh
from
that
job
to
run
the
steps
inside
that
particular
vm.
The
other
one
is
to
use
github
self
hosted
runners
now
github
gives
you
the
actual
binary,
the
actual
worker
you
used
to
run
github
jobs.
You
can
set
it
up
yourself
on
any
server.
You
wish
it
will
join
github
and
you
can
re
use
it.
B
You
can
reference
it
using
a
self-hosted
tag
or
any
other
tags
that
you've
used.
Now
this
this
runner
has
two
modes
of
operation.
One
is
the
fmerl
version
where,
after
each
job,
github
just
removes
it
from
the
list
of
runners
and
the
permanent
version
where
you
can
reuse
it
over
and
over
again
on
the
permanent
version.
You'll
need
to
clean
up
your
cells
after
each
job
to
ensure
that
you
have
a
clean
environment
in
which
you
run
the
tests.
B
Now,
managing
those
self-hosted
runners
means
that
after
each
job,
you
need
to
be
able
to
tear
them
down
automatically
and
spin
up
another
one
automatically
to
replace
it,
so
that
when
the
next
job
runs,
you
get
a
fresh,
a
fresh
worker,
that's
ready
to
run
your
tests,
so
I
started
fiddling
around
the
apis
and
came
up
with
with
gar.
Basically
gar
means
github
actions,
runners
manager,
that's
that's
all
it
is
so
I'm
going
to
show
you
how
it
works.
B
I
don't
have
slides.
I
don't
like
slides,
I'm
just
going
to
show
go
through
the
thing,
so
you
can
see
it
in
action.
It
has
native
support
for
lex
d,
which
can
run
containers
and
and
virtual
machines.
Now
I
must
mention.
Github
recommends
two
open
source
projects,
one
of
which
is
an
operator
on
kubernetes,
but
that
gives
you
a
containers
runtime
so
for
flat
car.
That's
pretty
difficult
to
use.
B
Considering
that
you
guys,
your
sdk
is
runs
on
docker
and
the
other
one
is
a
cdk
for
aws,
essentially
so
you're
stuck
with
aws
garm
was
written
in
a
very
modular
fashion.
It
has
native
support
for
lex
d,
which
allows
you
to
run
on
any
bare
metal
machine,
a
vm
with
linux,
and
it
has
also
an
external
provider
which
allows
you
to
write
your
own
binary
that
interfaces
with
whatever
cloud
you
want,
but
we
wrote
a
couple
of
them.
One
is
for,
let
me
make
this
bigger.
B
One
is
for
openstack
and
one
is
for
azure
and
they're,
essentially
just
bash
scripts.
That
garm
calls
into
just
to
create
the
necessary
resources
inside
a
particular
cloud.
So
let
me
get
to
it
to
use
garden
with
your
repository
or
organization.
You
just
have
to
create
a
personal
access
tokens
with
access
to
your
repo
or
organization.
I
already
created
one
and
configured
it
inside
the
garm
config
file.
It's
a
it's
a
static
config.
The
plan
was
to
use
something
like
vault
the
store
secrets.
B
B
B
And,
of
course,
the
webhook
secures
so
the
webhook
secret
is
used
to
validate
the
webhooks
that
coming
from
github.
So
whenever
a
runner
is
added
or
deleted,
or
something
happens
in
the
workflow
that
we
need,
we
care
about.
A
web
hook
call
is
sent
from
github
to
garm,
telling
it
that
a
new
job
is
skewed
and
we
need
a
new
runner
or
a
job
is
done
and
we
can
remove
the
old
runner.
B
So
now
we
added
a
repo.
We
need
to
create
a
pool
for
the
repo,
so
we
have
essentially
a
few
layers
of
on
in
garm,
so
we
have
the
repository
or
organization,
we
have
the
pool
and
we
have
the
runners.
You
can
have
multiple
pools
per
repo
or
organization,
and
each
pool
has
multiple
runners
of
the
same
type,
so
you
can
mix
and
match
whichever
way
you
want.
In
this
case
we
have
this
particular
repo
added.
B
B
The
profile
allows
you
to
specify
how
many
disks
this
particular
instance
will
have
how
many
nics
ram
cpus
and
so
on.
I
only
have
one
flavor
one
profile,
which
is
the
default
one
we'll
use
that
for
now
the
image
is
the
usual
lxd
image
that
one
would
use
so
ubuntu,
for
example,
2004
max
runners
and
min
idle
runners.
B
So
this
is
the
maximum
amount
of
runners
that
the
pool
will
handle,
after
which
it
won't
create
any
more
runners
and
and
the
min
idle
runners
is
essentially
a
set
of
warm
booted
runners
that
linger
and
wait
for
jobs
to
happen.
So
if
you
have,
for
example,
an
operating
system
that
boots
slowly
or
something
that
boots
slowly,
you
might
want
to
increase
this
option
and
have
a
bunch
of
them
ready
to
to
run
jobs.
B
B
os
type
will
be
linux
provider
name.
This
will
be
local
lxd,
the
one
that
we
showed
here,
it's
lxd
local,
actually,
okay
and
tags.
This
is
important.
This
you'll
use
to
target
runners
that
get
spun
up
by
this
particular
pool.
So
let's
go
with
ubuntu
local
lxd,
for
example,
and
whatever
else
with
my
runner,
these
are
arbitrary,
so
you
can
add
whatever
tags
you
want,
you
can
use
these
tags
in
your
workflow
to
target
these
particular
this,
this
particular
pool
of
of
runners.
B
B
This
particular
pool
enabled
true.
Now
it's
enabled
and
we
could
do
a
garmin
cli
runner
list.
We
should
still
see
it
here.
We
go.
Let
me
just
full
screen.
This
spending
create
now
it's
creating,
and
if
we
look
at
let's
see
list,
we
see
that
it's
already
being
spun
up
like
c
console.
We
can
see
this
booting.
B
B
B
So
if
we
switch
to
our
repo,
let's
try
settings
actions
runners,
we
see
it
here,
so
it
installed
it
spun
up.
It
has
our
tags,
it
also
has
a
bunch
of
default
tags
like
x.
X64
is
added
automatically
self-hosted
and
linux
is
also
added
automatically,
and
these
are
some
tags.
We
add
to
keep
track
of
of
runners
created
by
a
particular
guard
installation.
B
B
B
B
B
B
B
B
B
B
B
B
B
B
There
we
go
and
that's
about
it
so
essentially,
garm
is
a
simple
tool.
It's
single
purpose!
You
don't
need
anything
complex
to
learn.
Everything
you
just
saw
is
everything
that
it
does
there's
nothing
more
complicated
than
that.
All
you
have
to
do
is
define
your
repositories.
Your
organizations
perhaps
create
a
pool
with
the
definitions
you
you
would
like
to
have
that
pool
having
inside
that
wall,
the
operating
system,
the
size
of
the
machine
that
you
would
like
to
to
use
and
you're
done.
B
Garm
takes
care
of
everything
automatically,
so
you
don't
have
to
once
you've
set
up
your
pools.
You
can
target
them.
You
can
create
a
pool
in
azure.
You
can
create
a
pool
in
aws.
You
can
create
a
pool
in
openstack
lxd
on
bare
metal
or
any
other
cloud
provider.
You
can
write
a
a
bash
script
or
a
python
script
or
any
any
any
kind
of
executable
you
would
like.
B
F
B
F
That
looks
all
very
good
thanks
a
lot
for
that,
just
a
yeah
like
a
side
quest.
So
what
do
you
think?
Because
it
kind
of
takes
longer
to
put
up
a
bare
metal
instance
for
workflow
and
yeah?
The
compilation
of
flat
card
takes
a
lot
of
resources,
but
it
still
looks
like
it
could
be
done
at
least
two
to
a
certain
amount
in
parallel
on
a
on
a
server.
That's
strong
enough!
So
do
you
think
it
makes
sense
to
use
lxc.
F
B
B
It's
using
the
same
stuff
I
found
in
the
groovy
files
attached
to
the
github
pr
that
I
was
involved
in
it
builds
the
images
sorry
about
that,
builds
the
images
and
builds
the
vm
images.
So
this
all
happens
in
within
one
hour
and
20
minutes.
Essentially
using
16
cores
didn't
add
much.
I
didn't
add
anything
at
all.
Actually,
so
you
can
essentially
have
a
bunch
of
bare
metal,
equinix
machines,
so
this
was
run
on
an
equinix
machine
on
a
vm
on
an
equinix
machine.
B
B
So,
for
example,
in
this
case,
it's
in
snap
lex
d,
common
config,
not
this
one,
actually
so
snap
like
sd
print-
maybe
oh
not
here
my
apologies
next
snap
xd
common
config,
so
you
have
the
client
key
client.
Crt
gordon,
can
just
use
this
and
the
server
search
which
you
get
once
you
connect
using
the
cli.
B
But
if
you'd
like
you
can
use
any
cloud,
so
lxd
is
just
one
cloud
like
system
that
you
can
use
bare
metal
directly.
I'm
not
sure
it's
worth
it
unless
you
want
to
use
some
specialized
hardware,
that's
available
only
on
the
actual
hardware
and
which
you
can't
just
pci
pass
through
to
the
vm.
But
in
most
cases
you
can
just
pass
it
to
the
vm.
B
So
garden,
just
spins
up
virtual
machines
for
various
reasons.
One
is
that
you
might
want
to
use
an
sdk
like
a
flat
car
has
that
needs
docker
to
run
the
other.
One
is
security,
so
allowing
github
workflows
to
run
means
that
you
may
potentially
be
running
untrusted
code
and
a
container
is
sometimes
not
that
hard
to
break
out
of
while
a
vm
adds
an
extra
layer
while
not
bulletproof
adds
an
extra
layer
of
security.
B
So
you
limit
any
malicious
codes
ability
to
run
on
the
host
itself,
but
you
still
need
to
take
great
care
not
to
trigger
the
workflow
unless
the
code
that
you're
trying
to
test
is
trusted.
You
can
do
this
in
github
by
limiting
the
the
automatic
running
of
of
workflows
to
contributors,
past
contributors
or
current
members
of
the
repository,
and
just
do
it
manually
or
based
on
a
tag
or
some
something
of
the
sort.
B
But
you
have
to
take
great
care
when
running
untrusted
code
inside
your
ci
always
either,
even
if
it's
github,
workflows
or
jenkins
or
whatever,
because
you
want
to
limit
the
amount
of
malicious
code
that
may
run
so.
Security
is
important.
Containers
are
nice,
but
you
need
to
trust
the
code
that
you're
running
inside
them.
E
I
really
love
this,
and
only
just
by
listening
to
your
presentation
thanks
a
lot
by
the
way.
This
is.
This
is
amazing
only
just
by
following
your
presentation.
I
realized
that
in
the
new
ci
automation
pipeline,
there's
like
a
small
gap
that
we
didn't
consider
which
your
your
tool
exactly
fills,
and
that
is
how
to
connect
individual
workers
or
runners
to
github
actions
or
tags,
or
whatever
views
to
to
build
and
to
test
prs.
That
is
that
is
awesome.
Thank
you
for
the
presentation.
B
This
works
in
organizations
or,
if
you,
if
you
have,
for
example,
two
repos
of
under
the
same
user
and
you
have
access
rights
to
both,
so
you
can
potentially
build
the
packages.
Upload
artifacts
use
those
artifacts
in
a
different
job
running
in
a
different
repository.
So
this
is
also
possible
from
what
I
understand.
B
What
what
github
doesn't
have,
unfortunately-
and
this
is
something
that
most
projects
usually
build
on
their
own
or
use-
something
that's
already
built-
is
unit
test
aggregation.
So
once
the
tests
are
done,
you
need
something
to
to
aggregate
those
results
and
present
them
in
a
fashion
that
are
easily
digestible
by
everyone
and
that
allow
you
to
do
flaky,
test
detection.
So
a
history
of
test
runs
and
their
status
if
they
succeeded,
if
they
failed,
for
example,
the
kubernetes
folks
have
test
grid.
B
They
have
this.
Let
me
just
for
example,
and
you
see,
for
example,
here
we
have
a
test-
that's
flaking
a
lot,
but
this
is
something
that
the
kubernetes
folks
set
up
themselves.
I'm
not
sure
if
this
is
open
source
or
not.
The
idea
is
that
you
need
something
like
this
to
aggregate
the
results
over
a
period
of
times
of
time
and
do
flaky
test
detection
and
stuff
like
this.
E
We
have
the
lower
level
part
covered
where
we
can
run
like
any
number
of
tests
on
automatedly
on
on
any
number
of
of
vendor
backends,
and
we
re-run
tests
on
our
flaky
and
we
also
collect
the
test
results
and
we
sum
it
up
to
a
single
like
yes
or
no
depending
on.
If
any
of
the
tests
failed,
we
don't
have
visualization
yet,
but
the
tests
and
the
test
reports
that
we
deliver
are
in
tab
format.
So
there
should
be
tooling
that
that
can
can
visualize
those
results,
but
it's
yeah.
It's
it's!
B
Yeah
I
mean
this
is
a
minus.
I
mean
this
is
something
that's
missing
by
default
in
github,
and
it's
mostly
due
to
the
fact
that
each
project
wants
different
something
different
from
from
visualizing
their
test
results
and
keeping
track
of
like
flaky
tests
and
some
such
so.
I'm
not
sure
if
this
is
something
that's
missing
in
github
or
if
something
that
is
expected
for
projects
to
implement.
If
they
want,
you
may
not
even
need
it
so.
E
B
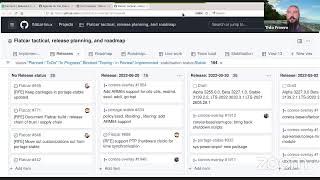
G
Yeah,
this
is
our
flat
car
release,
board
release
planning
board
and
the
last
release
was
at
the
may
end
of
the
may
actually
beginning
of
the
june,
actually
yeah,
that
was
alpha,
20,
32,
55
and
so
on,
and
that
was
about
two
weeks
and
the
next
release
will
take
place
one
week
after
that,
three
weeks
after
that,
one
day
after
this
time.
So
let
me
click
on
it.
Several
pi's
were
already
merged,
including
container
g
docker.
G
G
So
this
have
a
look,
and
probably
we
need
to
discuss
today's
like
what
we
should
do
with
the
wrist
update
of
the
arm
64,
which
was
yes,
they
merged
by
yellow
this
one
is
usually
going
to
be
included
in
the
stable
version,
probably
three
months
later,
and
so
I've
heard
that
that
was
not
going
to
be
good
for
adobe
folks.
So
I
would
like
to
listen
to
what
be
the
solution
to
that
yeah
mike.
C
G
C
So
we're
you
know
we're
trying
to
figure
out
some
of
our
deadlines.
We
we
had
hoped
to
start
rolling
it
out
towards
the
more
beginning,
mid
of
august
to
our
stage
clusters
with
potentially
the
production
you
know
across.
I
don't
know
30
20
30-ish
clusters
around
that
time
frame
with
production
clusters
coming
a
month,
or
so
maybe
two
months
on
the
outside
after
that,
so
from
a
production
perspective
that
would
work
just
it's
a
few
hundred
hosts.
C
C
Well,
I
mean
quite
a
quite
a
bit
limited,
which
it
is
something
we
can
work
around:
it's
not
ideal,
but
just
yeah
yeah,
I'm
kind
of
rambling
yeah.
Just
to
throw
an
additional
point
here
with
our
particular
situation.
We
tend
to
slow
our
releases
to
our
production
environments
towards
the
end
of
the
year
being
the
holiday
season.
What
not,
I
would
imagine,
probably
other
folks,
are
in
the
same
situation
as
well,
so,
the
sooner
that
we
can
deploy
arm
into
our
staging
environments,
the
sooner
we
can
get
into
production
sooner.
F
So
maybe
to
add,
in
the
past
we
cherry
picked
stuff
like
that
to
the
better
release
and
also
to
the
stable
release.
If
we
thought
it's
worth
to
have
something
backported
and
yeah.
The
general
yeah
feeling
is
that
we
should
only
do
it
when
it's
necessary,
because
sometimes
you
think
it's
working
well
for
you
when
you
develop
it
and
test
it,
and
then
it
affects
somebody
else's
use
case
in
unexpected
ways.
C
Yeah,
I'm
definitely
not
advocating
for
cherry
picking
directly
to
stable
at
this
point
just
to
be
clear,
I
I
definitely
don't
have
a
problem
with
I.
If
we
were
to
be
cherry-picking
towards
like
a
beta
for
the
six
for
the
upcoming
june
release,
you
know
we
can
definitely
do
a
bunch
of
testing
on
it
very
soon.
You
know,
after
you
know,
within
a
couple
days
after
that
release
and
give
you
any
sort
of
feedback
at
that
point,
for
it.
C
E
So
just
raised
my
hand
to
kind
of
stand
in
for
my
pr
I
am
I
I
did
most
most
of
that
work.
The
potential
impact
is
pretty
limited
first,
because
it
only
affects
on
64
images
and
second,
because
it
merely
adds
a
number
of
tools
that
then
are
additionally
shipped
on
on
arm64.
It
doesn't
change
any
existing
tools.
It
doesn't
update
any
libraries
to
newer
versions.
E
So
my
gear
and
your
team
would
have
all
of
july
basically
end
of
june,
all
of
july
to
really
test
whether
the
feature
fulfills,
what
you
need
and
whether
there
any
any
side
effects
and
then
based
on
that
feedback
we
can.
We
could
consider
for
the
end
of
july,
release
to
then
cherry
pick
that
into
the
stable
that
we're
gonna
release
end
of
july,
or
we
could
also
promote
the
beta
we're
gonna
release
in
june
to
stable
by
the
end
of
july.
E
C
E
There's
still
a
little
bit
of
headroom
until
we
start
working
on
the
release
and
those
dates
are
basically
the
weeks
that
we
plan
to
release.
So
the
new
release
is
not
going
to
happen
at
the
20th,
but
in
the
week
of
the
20th,
so
we
have
a
few
days.
We
have
a
few
days
left
to
put
some
extra
eyeballs,
basically
on
on
the
change
and
make
sure
there
are
no
unwanted
side
effects.