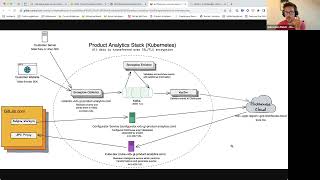
►
From YouTube: 2023-09-11 Analytics Section Meeting
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
A
A
Which
already
went
through
security
with
you,
the
problem
with
clickhouse
cloud
and
our
current
infrastructure
is
that
if
you
look
at
our
current
infrastructure,
normally
clickhouse
directly
requests
things
from
Kafka.
There's
a
Kafka
engine
table
in
clickhouse.
So
clickhouse
has
the
capability,
in
theory,
to
directly
access
a
stream
of
events
or
or
lines
block
lines
that
you,
as
you
can
see
in
Kafka
and
import
them
into
into
clickhouse.
A
In
specific
cases,
just
doesn't
support
things
that
the
click
house
open
source
solution
that
you
can
you
can
host
yourself
supports,
and
the
Kafka
table
is
one
of
those
the
Kafka
engine
table.
So
we
need
to
find
another
way
to
get
the
events
into
into
clickhouse
and
the
evade
the
way
that
actually
clickhouse
mentions
for
clickhouse
cloud
to
get
event
events
into
it
and
that
then
it
started
to
work
on
is
using
a
tool
called
Vector.
A
Vector
is
created
by
datadog
I,
think
it's
originally
for
processing
blogs
or
sending
log
somewhere,
but
I
think
it
definitely
also
works
for
our
use
case
and
it
changes
the
way
the
architecture
works
so
that,
instead
of
having
this
Direct
connection
between
Kafka
and
clickhouse,
we
suddenly
have
Vector,
which
takes
the
things
from
Kafka
and
then
puts
them
into
clickhouse.
Cloud,
there's
also
difference
that
clickhouse
is
no
longer
requesting
something
from
Kafka,
but
rather
Vector
is
putting
something
into
into
click
out.
A
And
then
this
one,
where
we
connect
from
Kafka
to
back
or
vector,
gets
the
things
from
cover
and
then
puts
them
into
clickhouse
cloud,
and
this
creates
changes
in
the
configurator,
because
the
configurator
sets
up
the
right
tables
and
so
on,
and
so
a
configurator
needs
to
know
about
whether
we
want
which
kind
of
architecture
we
want.
And
so
the
discussion
came
up,
whether
we
shouldn't
just
support
Vector
everywhere.
A
So
instead
of
having
two
different
architectures,
those
two
that
we
switched
towards
the
system
where
Vector
is
always
running
and
the
only
difference
again
is
whether
clickhouse
is
running
in
a
separate
cloud
or
within
our
own
infrastructure.
But
the
configurator
doesn't
need
to
care.
It
just
gets
a
clickhouse
API
URL.
A
And
also
the
rest
of
our
system
doesn't
really
need
to
care
that
much
about
where
clickhouse
is
actually
running.
If
we
have
Vector
running
everywhere,
the
database
set
up
the
tables
and
everything
would
be
the
same
and
in
essence
we
have
these
two
options.
We
can
either
say:
okay,
we
want
to
have
support
these
two
different
architectures,
one
with
Vector
one
without
vector,
and
then
we
have
to
deal
especially
in
the
configurator
and
maybe
also
in
other
areas
with
the
differences
or
we
say
we
don't
want
that.
A
We'd
rather
have
one
architecture,
which
is
just
this
one,
which
would
mean
we
have
Vector
running
everywhere.
So
it's
one
additional
service
that
also
needs
to
run,
for
example,
in
Docker
compose
or
in
the
in
any
other
kind
of
Stack,
but
since
Vector
would
run
everywhere
the
advantages
that
Vector
actually
has
some
inbuilt
capabilities.
You
can
do
transformations
of
of
the
the
events
that
go
through
it
and
you
can,
for
example,
try
to
send
things
directly
to
specific
databases
based
on
the
IDS
that
they
have
in
them.
A
So
in
theory,
we
could
investigate
using
the
app
ID
of
a
event
to
directly
put
it
into
a
specific
table
so
that
we
no
longer
have
to
have
one
time
table
where
everything
gets
taken
out
of
into
the
specific
tables.
All
these
things
we
could
start
to
investigate.
We
could
make
vector
and
active
component,
whereas
if
we
have
the
two
different
options,
I
think
we
would
keep
Vector
as
passive
as
possible,
just
so
that
the
the
two
different
environments
stay
stay
as
close
as
possible.
A
You
have
one
less
service
that
runs
in
those
and
so
one
less
service
that
can
potentially
break
that
can
potentially
take
performance
so
right
now,
I,
don't
think
we
really
know
how
much
Vector
is
taking
when
it
comes
to
resources
like
CPU
resources,
memory
and
so
on.
It's
supposed
to
be
lightweight
so
I
assume
that
that
much,
but
still
it's
one
more
service
that
runs
within
those
environments
and
one
more
service
is
one
more
thing
that
can
potentially
break
and
that
can
potentially
create
issues
but
yeah.
A
Necessarily
I
think
those
are
two
different.
That's
a
good
point,
but
those
are
two
different
changes.
So
when
introducing
Vector
in
here
so
within
within
this,
the
the
current
kubernetes
clusters
we
have,
we
can
then
still
have
clickhouse
run
locally
because
you
might
not
like
just
to
keep
it
simpler
from
a
setup
perspective
also
to
allow
potential
self-managed
users
who
don't
want
to
use
clickhouse
cloud
to
use
the
whole
system
to
be
able
to
host
everything
themselves.
A
So
the
question
whether
clickhouse
runs
within
the
system
like
within
the
same
cluster
or
within
the
same
Docker,
compose
setup
or
whether
it's
run
separately
on
clickhouse
cloud
I,
think
is
separate
to
whether
or
somewhat
sector
somewhat
separate
to
whether
we
introduce
vector
or
not.
When
we
introduce
vector
everywhere,
we
gain
the
ability
to
use
clickhouse
cloud
everywhere.
So
you
could
have
a
local
setup
within
Docker
compose
that
connects
to
clickhouse
Cloud,
for
example,
which
I
think
would
be
another
advantage
of
probably
having
Vector.
A
C
B
B
D
D
A
It
is
there's
I,
just
think
they
can
actually
there's.
They
have
the
concept
of
syncs,
which
is
kind
of
where
you
put
your
the
the
events,
which
is
quite
a
list
of
things,
I.
Think
it's
important
to
note
that
in
theory
also
snow
plow
I
would
support
putting
things
elsewhere.
So,
for
example,
we
could
so
I
think
in
here
you
can,
for
example,
put
the
the
events
into
an
S3
bucket
with
a
vector.
That's
something
that
also
Snow
block
would
do
directly.
A
and
Vector
is
definitely
kind
of
built
around
and
and
and
kind
of
biased
towards
observability
data,
so
also
the
whatever
you
can
see
as
soon
is
more
in
the
direction
of
observability.
So
you,
for
example,
I.
Don't
think
they
support
any
other
real
data
warehouse
there's,
but
they
support
like
something
like
snowflake
or
something
like
that,
but
they
support
I,
know
putting
things
directly
into
New
Relic
or
into
Data
dog,
or
so,
while
it
is
the
case,
I,
don't
know
how
much
of
an
advantage.
A
D
Okay,
that's
fine,
yeah
I
was
just
thinking
from
a
community
contributions
perspective.
If,
when
we
open
this,
they
stack
up-
and
you
know-
remove
certain
things
from
it
to
allow
Community
contributions,
whereas
the
areas
that
we
might
see
people
wanting
to
submit
contributions
to
add
support
for
their
own
architectural
Stacks
that
we
don't
currently
support
for
them.
So
it
sounds
like
this.
D
A
From
all
that,
we
know
right
now.
That
would
be
my
assumption,
but
it's
really
hard
to
say
because
I
mean
clickhouse
can
move
quite
quickly
in
in
certain
areas
if
they
want
to,
but
also
they
also
sometimes
don't
so,
for
example,
just
to
give
an
example,
they
I
think
added
Json
support
for
kind
of
actually
reaching
into
Jason's
a
year
ago
in
some
kind
of
beta
version,
and
nothing
happened
since
then.
A
So
it
feels
to
me
that
we,
the
best
thing
we
can
do
especially
when
it
comes
to
clickhouse,
is
just
rely
on
technology.
That's
kind
of
established
right
now
and
assume
that's
going
to
be
the
long-term
solution.
Then,
if
something
better
comes
along,
we
can
still
evaluate
it,
but
based
on
that
experience,
I'd
say
yes,
I
I
Envision
it
for
for
the
longer
term,
however
long
that
might
be
then.
C
That's
fine
I
I,
don't
ask
with
any
particular
sort
of
expectation
or
or
preference
in
mind,
because
I
mean
if
we're
going
to
trust
anyone
to
support
data
pipelines.
Then
datadog
seem
like
a
you
know:
pretty
solid
Choice,
that's
fine
yeah.
The
last
I
heard
about
this
was
the
click
pipe
seemed
interesting,
but
that
was
the
last
I
heard
before
I
went
on
PTO,
so
cool
thanks.
D
With
that
in
mind,
I'm
fully
supportive
of
us
unifying
our
stack,
the
short
to
median
term
benefits
of
our
velocity,
having
a
unified
experience
across
the
board
and
being
able
to
debug
early
while
we're
in
the
early
stages
of
this
of
analytics,
instrumentation
and
product
analytics
more
more
well
related
to
this
stack,
more
specific,
like
I'd,
be
more
than
open.
Let's
unify
it
and
make
our
lives
that
much
bit
easier
for
the
short-term
medium
term.
A
A
D
I
think
the
biggest
problems
would
be
performance,
but
we
don't
know
well.
We
have
no
idea
what
the
entire
Stack's
going
to
do
once
you
properly
gets
some
proper
amounts
of
data
being
around
for
it,
which
is
where
the
you
know.
The
gitlab.com
test
is
coming
from
to
really
put
some
genuine
data
for
it
in
any
considerable
Mass,
so
wait
and
see
if
it
becomes
a
problem
we're
early
enough
to
be
able
to
Pivot.
If
we
have
to
but
I,
don't
I
mean
it's
data
dog
I
doubt
we'll
need
to
give
it
that
much.
A
C
A
It's
very
like
one
con
I,
don't
know
one
customer
coming
in
that
creates
millions
of
events
or
that
it
is
creates.
Loads
of
events
leads
to
slow
down
for
all
other
people,
and
I
mean
we're
always
going
to
have
that
risk.
As
long
as
we
have
one
kickhouse
database
with
multiple
customers
in
there,
but
if
they
don't
use,
one
share,
DB
I
think
that's
that's
at
least
somewhat
reduced.
If
they
are
all
kind
of
spread
across
databases
and
within
the
database,
we
actually
don't
have
anything,
that's
shared
across
them.
A
D
I
assume
do
it
going
down.
That
approach
would
also
improve
our
vertical
scaling.
Our
horizontal
scaling,
sorry,
with
our
ability
to
be
able
to
just
span
out
new
Brick
House
databases,
if
someone's
being
a
particular
pain
and
causing
a
particular
influx
yeah
or
even
you
know,
get
that
dedicated
and
helping
them
get
that
set
up
and
having
their
own
dedicated
area,
although
they
may
use
similar
architecture
yeah.
A
All
right,
if
there's
no
more
feedback,
then
that's
also
from
my
side.
Thanks
a
lot
everyone
for
attending
and
for
sharing
your
thoughts.
I
think
it's
helpful
when
we
kind
of
discuss
this
in
a
bit
of
a
grander
audience
and
then
make
sure
that
everyone's
aligned
with
those
changes
before
we
make
them
more.
In
this
talented
thing,.