►
From YouTube: Gitlab Velocity Board Chrome Extension
Description
Overview and explanation of the GitLab Velocity Board Chrome Extension at https://gitlab.com/cwoolley-gitlab/gl-velocity-board-extension
This is in support of the Create Stage OKR https://gitlab.com/gitlab-com/gitlab-OKRs/-/work_items/2085
A
Hello,
this
is
Chad
Wooley
with
the
IDE
group
in
the
create
stage
and
today
I'm
going
to
talk
about
a
gitlab
velocity
board,
Chrome
extension
that
I
created.
This
is
working
towards
this
okr
for
the
create
engineering
efficiency
and
to
not
vary
the
lead,
I'll
give
a
quick
demo
and
then
a
long
explanation
of
what
we're
doing
and
why
so?
If
we
look
over
here,
this
is
the
iteration
planning
board
for
the
remote
Development
Group.
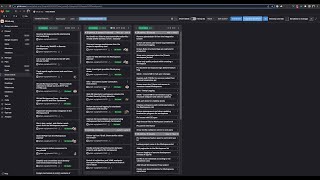
A
This
is
our
actual
board
and
you
see
I've
got
apologies
for
the
cough
I'm
a
little
bit
sick,
this
extension
installed
and
if
you
click
calculate
iterations
and
will
automatically
calculate
the
the
past
iterations
that
you've
done
the
past
four
iterations
and
based
on
that
calculate
your
velocity
and
based
on
your
velocity.
It
will
flow
the
current
and
future
iterations
and
tell
you
when
you
can
predict,
based
on
your
current
velocity,
the
stories
to
be
completed
in
what
iteration
so
backing
up.
A
And
this
is
just
a
quick
Ruby
script
that
I
threw
together,
but
it
was
able
to
tell
us,
okay
based
on
that
that
point
in
time,
which
was
April
24th,
that
no,
we
indeed
based
on
the
current
prioritize
stories
and
estimates
and
some
that
weren't
estimated
that
we
were
not
going
to
make
the
16.0
release.
So
this
was
instrumental
in
helping
us
realize.
A
Okay,
what
what
scope
did
we
have
to
cut
to
have
a
realistic
reality-based
chance
of
delivering
remote
development
in
the
16.0
release
and
the
happy
ending
that
that
story
is
we
did
by
cutting
a
lot
of
the
scope
and
which
was
mostly
around
process
overhead
and
how
we
we
got
the
integration
Branch
merged,
so
backing
up
even
further.
What
what
is
that
based
on
so
it's
it's
a
very
different
than
the
the
standard
gitlab
product
flow,
it's
primarily
based
on
pivotal
tracker,
so
which
is
based
on
velocity
so
backing
up
further.
A
What
is
velocity?
It's
a
standard
concept
that
agile
teams
have
used
pretty
much
since
the
dine
of
agile
before
the
last
millennia
and
it's
standard
in
XP
and
now
standard
in
most
scrum
approaches,
it's
alternative
to
kanban,
which
is
sort
of
a
work
in
process
driven
model.
But
with
velocity
you
estimate,
based
on
a
a
small
scale.
Usually
it's
a
I
prefer
Fibonacci
one,
two,
three
five
and
eight,
and
you
have
to
break
up
small
stories
and,
as
you
complete
them,
you
add
them
up.
A
You
average
how
many
you
got
completed
in
each
past
iteration
and
that
and
divide
by
the
number
of
past
iterations,
and
then
that's
your
velocity
and
that
lets
you
predict
okay,
well,
based
on
that.
This
is
how
many
stories
or
issues
that
I
can
complete
in
future
iterations
everything
else
remaining
the
same:
the
team,
the
experience
of
the
team,
the
availability
of
the
team
Etc
and
so
just
to
get
an
idea
of
how
this
works.
A
Let's
look
at
pivotal
tracker,
which
is
a
very
popular
tool
that,
with
small
teams
to
implement
this
process,
so
we
see
we've
got
the
icebox,
which
is
on
prioritize
stuff,
the
current
iteration
and
backlog
and
done
so.
These
are
all
the
the
stories
that
we've
got
done.
These
gray
things
are
the
iteration
markers
you
can
see.
They
have.
The
date
ranges,
so
the
oldest
stuff
is
here
at
the
top
right
in
the
past
and
as
we
flow
down,
we
go
into
closer
to
the
Future.
A
Here's
the
current
iteration,
which
is
right
now
and
then
flowing
into
the
future,
is
the
iterations
coming
up.
So
the
emergent
nature
of
this
means
that
okay,
currently
there's
five
points
in
the
current
iteration,
but
if
I
were
to
drag
this
big
five
point
story
up
here,
it
would
automatically
say
well.
Your
velocity
is
five
and
you've
already
got
two
points
in
this
iteration
you're
not
going
to
complete
it,
but
you'll
have
enough
left
over
here,
so
it
automatically
calculates
them
on
the
fly.
A
But
if
we
just
did
a
two
pointer-
okay,
well,
that
one
would
fit
in
the
narration
and
then
it
would
push
these
two
down
and
the
six
would
be
calculated
when
left
over.
So
you
can
get
five
done,
so
it
automatically
lets
you
re-prioritize
on
the
fly
in
the
iteration
planning
or
refinement
meeting
to
say,
okay,
what
what
do
we
need
to
do?
What
priority
decisions?
Do
we
need
to
make
to
be
able
to
meet
our
goals?
And
this
is
a
nice
feature
that
tracker
has.
A
You
can
have
these
special
types
of
stories
that
are
called
releases,
so,
for
example,
this
is
an
initial
demo,
so
it's
got
to
happen
around
here.
It
doesn't
really
matter
when
it
happens,
but
the
beta
launch-
that's
made
me
guide
a
hard
date
on
it,
22nd
of
June,
for
example.
So
all
of
these
stories
and
before
must
be
completed
before
the
beta
launch,
but
based
on
the
current
velocity,
which
is
five
that
is
going
to
happen
right
here,
22nd
of
June
in
this
iteration.
A
So
this
tells
us
well
we're,
definitely
not
going
to
get
all
of
this
stuff
done
before
the
beta
launch,
based
on
our
current
velocity.
So
we
either
have
to
push
out
the
date
or
cut
a
lot
of
scope
or
do
something
to
make
this
plan
match
the
reality,
because
just
saying
that
the
team
is
magically
going
to
do
whatever
two
to
three
times
the
amount
of
work
they
normally
do
is
not
based
in
any
form
of
reality
and
not
healthy
either.
A
So
what
I
did
to
try
to
to
get
this
working
with
gitlab
boards
was
it
took
some
things
you
can
see
here
like
by
default.
We
we
have
these
three
panes
here,
I'm
prior
tourist
I'm
prioritize
that
corresponds
to
the
done
panel
over
here
and
then
prioritize
corresponds
to
the
current
and
backlog
and
done
corresponds
to
done,
but
there's
several
limitations
with
the
current
git
lab
implementation
of
iterations
and
boards
that
make
it
not
possible
to
work
this
way
by
default
out
of
the
box
and
drove
the
this
plugin
is
the
next
iteration
of.
A
How
can
we
get
something
like
this
in
the
gitlab
product?
The
first
iteration
was
just
to
make
the
little
reports
in
Ruby,
so
iteration
cadences
don't
have
this
this
Paradigm.
They
assume
that
all
iterations
all
issues
are
manually
assigned
to
iterations.
You
know
definitely
not
like
tracker
where
you
can
drag
things
around
and
things
will
automatically
recalculate
as
you
drag
them
around.
Secondly,
iteration
cadences.
The
the
way
velocity
is
currently
implemented
is
that
they
don't
have
a
concept
of
a
running
velocity.
A
That
spans
of
velocity
is
only
calculated
for
stories
within
a
single
iteration,
which
is
not
useful
for
this
type
of
estimation
that
we're
trying
to
do
and
use
past
iteration
velocity
to
predict
when
future
issues
will
span
future
iterations
and
boardless
themselves
have
a
few
limitations.
For
example,
if
you
have
an
iteration
list
in
a
board,
it
can
only
show
a
single
iteration.
So
that
means
you,
you
can't
have
it
show
multiple
iterations
like
this
in
the
current
and
backlog
or
they're
done
either.
A
Each
of
these
would
be
a
separate
list,
and
you
know
the
gitlab
current
implementations
of
iteration
based
lists
in
boards.
Secondly,
boards
can
only
show
open
issues,
so
that
means,
for
example,
in
tracker.
You
know
here.
Here's
one
issue:
that's
already
been
closed,
but
it's
in
the
current
iteration.
It
was
closed
in
the
current
iteration
just
now,
so
it
should
show
up
there,
but
in
in
gitlab
it
would
not
show
up.
A
A
So
that's
why
we're
going
to
have
to
work
with
this
pretty
strictly.
These
are
the
three
labels.
This
is
the
only
board.
We
can't
show
these
any
other
lists
to
drag
around
things
on
this
board
or
on
any
other
boards,
or
that
will
mess
up
the
prioritization
of
these
lists.
The
Ordering
of
these
issues
in
prior
to
the
prioritized
list,
which
is
the
most
important
thing
so
I,
think
we're
going
to
add.
Maybe
a
little
export
import
functionality
to
back
that
up,
just
in
case
they
they
do
get
screwed
up
somehow.
A
A
You
know
maybe
there's
some
stories
that
don't
yet
have
a
workflow
label
assigned
to
it,
but
for
generally
you
can
keep
that
off
to
keep
it
simple,
and
these
are
scope
labels,
so
they're
mutually
exclusive,
and
if
you
click
calculate
iterations,
you
can
see
it
gives
the
last
four
iterations
you
can
pick.
However,
many
iterations
it
averages
over
here
and
the
average
of
that
is
a
velocity
of
19
and
it
flows
the
issues.
So
you
can
see
here.
A
It's
also
this
this
panel,
which
was
completely
empty,
got
automatically
populated
with
these
little
fake
they're,
not
real
issues,
they're,
not
draggable,
they're,
not
editable.
You
actually
shouldn't
attempt
to
edit
this
at
all.
You
should
probably
totally
refresh
the
page,
because
I'll
bets
are
off
with
the
way,
we're
manipulating
this
Dom
and
who
knows
what
it
would
do
to
view
under
the
covers
it's
purely
for
informational
purposes,
but
we
have
these
closed
issues
and
there's
even
one
here
at
the
top.
A
So
our
velocity
is
19
and
you
can
see
in
the
19
points
fit
in
here
and
then
these
next
three
issues
which
add
up
to
nine
points,
flowed
into
next
week's
iteration
because
we're
not
going
to
get
them
done
in
this
iteration,
so
you
can
override
the
number
of
iterations
to
average,
like
that
four
weeks
ago,
was
sort
of
a
little
bit
of
an
unsustainable
Pace,
leading
up
to
that.
That's
just
look
at
the
last
two.
A
A
The
other
thing
you
can
do
is
there's
a
concept
of
a
velocity
override.
This
is
purely
for
experimentation
and
what-if
scenarios.
It's
not
changing
reality.
It's
not
changing
the
work
you
actually
did
in
the
past,
but
you
can
just
say:
okay.
What,
if
our
velocity
going
forward
changed?
You
know
it
was
instead
of
19,
it
was
10..
A
A
So
that's
the
the
demo
of
this
and
why
we're
doing
it
in
support
of
this
okr?
It's
a
work
in
progress-
and
you
know
feedback
is
welcome,
but
we're
hoping
that
this
will.
Let
us
come
up
with
some
ways
to
have
reality
based
useful
predictive
value
through
our
process
of
estimation
and
be
able
to
give
realistic
and
reasonable
estimates
that
we
have
a
high
degree
of
confidence
in
of
delivery.