►
From YouTube: GitLab CI Deep Dive Presentation
Description
Cristiano Casella, Technical Account Manager in EMEA, walks us through some of the popular features and best practices of GitLab CI.
A
Hello,
everyone
and
thank
you
for
joining
us
for
another,
exciting
installment
of
the
customer
success
skills
exchange
very
very
excited
about
the
topic
today.
We're
going
to
do
a
CI,
deep
dive,
special
shout
out
to
Cristiano
for
building
the
demo
and
the
presentation.
I'm
really
excited
for
this
topic.
I
know
it's
been
a
huge
ask
from
many
of
you
so
without
further
ado
Cristiano.
The
stage
is
yours.
A
B
The
suggestion
is
to
follow
the
presentation
also
from
the
website,
because
in
the
present
in
the
related
notes,
you
can
find
a
lot
of
interesting
links
related
to
what
I
sharing
so
especially
after
this
meeting.
I
suggest
you
to
give
a
loop
to
the
links
that
you
can
find
in
the
notes.
So,
let's
start,
the
topic
of
the
presentation
is
CIN
CD,
probably
today
we
will
focus
more
on
CI
just
for
timing
trouble.
So
this
is
our
typical
image
that
we
know.
B
I
would
like
to
go
a
little
bit
deeper
about
what
we
can
really
do
inside
the
CI
pipeline
today.
So,
let's
start
with
the
pipeline
and
ask
me-
and
this
is
the
really
basic
essence
about
our
pipeline-
I-
have
just
one
stage:
I
have
three
commander
Lance
Adina
in
a
row,
and
this
is
really
the
simple
the
easy
scenario
that
you
can
find,
but
the
strength
understand
how
a
pipeline
can
scale
can
grow
and
become
a
little
bit
out
of
our
control.
B
So
the
first
point
is:
managing
the
pipeline
file
is
not
sustainable
to
have
a
pipeline
file
that
is
containing
200
or
300
line
of
code,
and
this
is
not
so
not
so
uncommon,
I
found
and
some
casts
were
really
longer
pipeline.
The
approach
is
the
same
that
you
should
use
where
you
are
coding.
If
you
have
to
long
file,
if
you're,
including
too
many
different
pieces
of
code,
that
the
suggestion
is
to
split
them,
how
we
can
split
them,
we
can
include
the
file
inside
our
pipeline
and
this
file
can
have
different
origin.
B
We
can
use
local
file
file
coming
from
the
same
project.
You
can
use
external
file
from
other
projects.
You
can
use
it.
One
of
our
templates
that
we
are
using
and
that
we
build
on
out
of
the
verbs
or
we
can
use
a
remote
file.
I
can
I
could
have,
for
instance,
a
web
server
that
is
just
disposing.
A
plain
text.
File,
hey
I
can
use
that
as
as
a
pipeline
inclusion
or,
for
instance,
using
another
instance
of
Caleb,
exposing
that
sorry
that
file.
B
So
this
is
a
great
advantage,
looking
at
the
ACI
file
to
understand
each
stage
what
is
doing
and
where
I
can
find
many
detail
about
my
codes,
but
before
we
can
also
change
the
file
name
of
the
location
of
our
CI
file.
For
instance,
the
typical
use
case
is
a
customer
that
have
a
large
organization
and
who
is
managing
the
code
is
not
is
managing
the
pipeline.
B
We
can
use
only
edit
sector
to
decide
that
a
job
have
to
be
executed
just
on
some
kind
of
branch
or
naming
convention,
but
pay
attention,
because
actually
this
feature
is
a
candidate
for
duplication.
What
we
can
use
instead
of
this
is
the
rule.
We
are
going
to
see
how
to
use
them.
Pay
attention
to
this,
because
is
a
function
that
a
lot
of
customer
are
actually
using,
and
so
it's
a
risk
for
our
future
migration
and
upgrades.
B
B
This
is
giving
you
a
lot
of
advantage,
for
instance,
the
typical
use
cases
regarding
security
check.
Some
security
check
could
take
a
lot
of
time,
and
maybe
the
developer
don't
want
to
wait
for
that
time,
because
it's
just
working
on
his
local
branch
or
a
secure
stage
or
testing
environment.
So
is
not
that
moment
where
that
I've
ever
want
to
challenge
with
security
with
this
setting,
so
you
can
just
keep
what
is
really
important
for
you.
B
Okay,
I
take
these
opportunity
to
show
you
something
more
when
you
find
a
piece
of
code
or
where
I'm
talking
about
the
special,
a
specific
feature:
I
created
a
snippet
of
code
inside
our
github
demo,
environment,
where
you
can
find
a
piece
of
code
that
is
working
and
you
can
find
also
the
link
to
our
documentation.
So
you
are
able
to
find
exactly
what
you're
looking
for
like
in
this
case.
I
want
to
know
where
has
been
introduced.
B
B
B
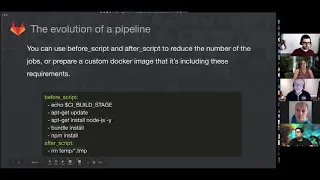
This
is
a
disadvantage
when
I
want.
You
have,
in
my
script,
part
just
what
I
made,
but
if
you're
going
to
look
at
the
the
optimization,
usually
a
custom
image
for
the
build
environment,
including
the
before
script,
can
let
you
save
a
lot
of
time.
So
my
suggestion
is
a
value
every
time
what
you're
putting
in
the
before
script
or
the
common
operation
that
you're
doing
during
your
job
put
all
of
these
things
inside
a
custom,
docker
image
that
you
can
cache
and
in
this
way
your
build
will
have
a
stronger
improvement
on
timing.
B
Let's
talk
about
the
cash
we
receive
a
lot
of
question
about.
How
can
I
use
my
care,
the
cash
to
speed
up
my
process?
It's
important
to
understand
that
we
have
a
lot
of
different
crash.
It
depends
from
my
new
platform
different
from
my
bidding
environment.
If
I'm,
making
the
build
on
Linux
virtual
machine
I
have,
for
instance,
the
local
apt
cache
if
I'm,
building
on
docker
I
have
the
docker
image
cache.
B
If
I'm
working
on
CUNY's
I
need
to
define
an
external
sts-3
storage
to
use
a
shared
cache
and
talking
about
the
artifact
I
can
expose
an
artifact
I
use
these
as
a
sort
of
cache.
So
it's
never
about
the
one
thing
of
cache.
It's
never
about
the
same
kind
of
cache
and
you
need
to
also
to
pay
attention
to
the
cache,
because
you
risk
to
expose
your
build
to
a
garbage
garbage
collection
problem,
so
it's
very
important
to
define
exactly
and
to
trace.
So
what
is
impacting
your
build
time.
B
Sometimes
the
problem
is
regarding
the
size
of
my
reef
off,
it's
usually
happening
with
a
mano,
a
mano
rifo
application
when
I
have
tons
of
different
file
and
resources
inside
the
same
repo
in
this
case
is
that
you
can
define
a
static
volume
for
your
honor.
You
can
change
the
get
strategy.
Instead,
the
fetching
the
wool
repo
you
can
just
ask
it
to
the
build
environment,
to
pool
the
new
update
from
your
git
repository.
Obviously,
you
need
to
have
a
permanent
storage
behind.
B
We
can
also
use
a
pipeline
to
trigger
another
pipeline
in
a
different
project.
Sometimes
the
timing
is
not
just
it's
not
just
about
the
the
is
not
just
about
my
process.
I
can
see
a
long
pipeline
running,
but
maybe
half
of
this
is
out
of
my
department.
So
it's
not
important.
For
me.
It's
not
interesting
or
maybe
I
have
a
lot
of
different
pipeline
that
are
using
the
same
piece
of
code
for
the
deployment
part
or
for
another
piece
with
the
triggering.
B
You
can
reuse
the
same
pipeline
from
many
project
passing
intermediate
job
between
them,
so
you
can
figure
an
external
pipeline
outs.
In
this
case
you
can
find
some
snippets
down
and
you
can
also
have
the
child
pipeline
if
you
have
a
long-running
job
and
the
the
result
of
that
job
is
not
blocking
your
work.
For
instance,
I
have
a
long
security
scanning
again,
but
I'm
in
the
staging
environment.
I
don't
want
that.
B
My
build
is
stop
it
from
the
tester,
because
I
am
still
working
on
the
code,
but
I
would
like
to
have
the
restaurant
anyway,
without
waiting
for
the
next
step.
What
I
can
do
is
using
a
child
pipeline
I
can
detach
the
security
scanning,
for
instance,
just
in
the
staging
environment,
so
I'm
able
to
complete
my
pipeline
I
can
test
in
my
review,
harp
my
application
and
see
of
my
change
but
IDM
before
to
decide
to
promote
my
application
to
the
next
stage.
B
I'm
able
to
give
a
look
to
the
reporter
for
security
scanning
or
whatever
same,
if
I
have
to
upload
a
large
artifact
in
my
artifact
store.
I
can
complete
the
build
and
when
all
my
tests
are
confirming
that
my
builder
admits
a
safley
I
can
just
trigger
charge
or,
but
you
make
the
upload
on
the
artifice.
B
You
cannot
so
call
a
pipeline
that
doesn't
exist.
You
can
create
a
script
that
is
dynamically,
creating
the
last
piece
of
your
pipeline,
and
you
can
then
trigger
that
in
this
case,
your
your
your
pipeline,
your
child
pipeline,
will
be
totally
dynamic,
so
you
don't
need
to
define
a
right.
Every
single
use
case
is
every
single
parameter
that
can
be
changed,
but
you
can
just
use
a
script
to
generate
that.
B
Sometimes
another
problem
is
releasing
to
the
dependencies.
You
know
that
when
we
have
a
stage
every
job
we
start
at
the
same
moment
and
before
the
next
stage
is
starting.
We
need
to
wait
for
the
completion
of
each
job
in
the
previous
stage.
In
especially
where
you
have
a
lot
of
services
or
a
complex
environment,
you
could
have
a
dependencies
tree.
That
is
not
so
linear,
so
you
can
define
directly
dependencies
job
by
job,
and
in
this
way
the
next
job
will
wait.
Just
for
what
you
define
it.
B
Sometimes
the
problem
is
exactly
the
opposite.
You
have
too
much
too
much
too
many
built
too
many
jobs.
You
are
going
to
hit
the
resources.
That
is
not
a
label.
You
can
define
a
research
group
or
many
of
them
to
define
a
resource
that
can
can
handle
a
job
just
one
job
in
the
same
time.
So
in
this
way,
if,
if
a
job
is
going
to
handle
with
this
resource,
the
scheduler
we
wait
and
will
we
pass
through
that
resource
just
one
job
by
time?
B
B
It's
important
also
to
manage
the
life
cycle
of
our
job.
You
can
define
job
by
job
timeout.
If
a
single
job
is
always
you
fail
or
not,
if
it's
safe
to
stop
that
job
or
the
number
of
attempts
that
I
can
retry
the
specific
job.
This
is
really
important,
because,
if
I
have
a
job
that
usually
is
taking
10,
second
I
have
no
sense
to
wait
for
two
minutes
before
to
get
the
failure.
B
This
is
just
consuming
resources
and
wasting
time
also,
having
a
longer
time
out,
can
let
you
don't
notice
a
problem
with
performance
if
my
normal
big
time
is
10.
Second,
it
could
be
good
till
20
or
30.
Second,
after
that,
I
have
a
problem
in
my
performance
and
is
important
that
I
can
notice
that
so
keep
the
time
out
near
to
double
sometimes
three
times
the
amount
of
time
that
you
usually
need
for
your
bill
that
don't
don't
put
just
their
full
timeout
for
anything
in
your
in
this.
It
is
really
important.
B
Okay,
great
so
get
some
integration.
Let's
see
how
we
are
able
to
interact
also
with
the
other
tool.
We
know
that
we
are
trying
to
cover
the
whole
lifecycle,
but
sometimes
the
customer
have
an
existing
tool
that
is
using
a
is
not
easy
to
just
remove
everything
else
and
we
get
to
our
product.
So,
let's
see
what
happen
in
Heber,
we
use
many
third-party
tool
and
we
are
able
to
deploy
them
with
our
each
lab
managed
apps
and
we
use
them
in
our
core
feature
like
for
build
or
security
scan.
B
You
know
that
a
lot
of
our
security
scan
and
giant
are
not
built
by
ourself.
We
are
managing
the
integration
saying
for
a
lot
of
lab,
managed
apps
that
we
are
deploying.
But
what
about?
If
you
have
to
integrate
with
a
tool
that
we
are
not
supporting
in
our
pipeline,
you
can
define
the
image
and
everything
you
will
find
running
your
job.
B
Basically,
if
you
are
able
to
run
a
tool
in
a
shell,
you
are
able
to
integrate
the
tool
with
github
or
if
a
tool
is
exposing
an
API,
you
are
able
to
interact
with
Caleb.
Let's
see
if
this
is
a
real
license,
I
wanted
to
use
load
tests
for
the
staging
environment
to
ensure
that
my
application
is
stronger
enough.
I
use
it
in
the
past
la
Cousteau
as
a
low
tester
for
web
application,
but
we
don't.
We
don't
have
any
integration
revealed
to
be
flawless.
B
So,
let's
try
to
understand
how
we
can
integrate
this
I
define
it
my
stage.
Obviously
I
added
this
stage
in
my
stage
least
in
the
position
just
after
the
stage
environment,
I
defined.
My
image
image
in
this
case
is
provided
by
local
law.
Host
itself
are
using
parallel
parameters
parallel,
let
you
run
the
same
job
many
times
in
the
same
moments.
So
this
is
a
load
test.
Every
single
pot
will
generate
a
specific
amount
of
load
on
my
application,
changing
the
parallel
parameter.
Let
me
this
decide
and
scale
up
my
fire
power
during
that
load.
A
B
So
you
have
a
link
to
the
real
project
that
is
working
inside
a
node.
So
if
you
want
to
give
a
look
to
that,
it's
it's
real.
This
is
the
typical
essence
about
using
a
product
that
is
not
really
out
of
the
box
with
gate
lab,
but
this
is
not
the
only
instance.
Here
we
have
an
artifice
or
J
frog.
You
know,
customer
using
j-rock
g4
is
providing
in
the
documentation.
B
Basically,
how
to
how
to
implement
the
artifact
upload
inside
our
pipelines,
so
you
can
find
the
complete
description,
and
here
you
can
find
the
the
pieces
of
the
CIA.
The
pipeline,
as
you
can
see,
is
totally
the
same
logic.
I
prepare
the
image
they
are
starting
from
my
main
image.
The
East
Al
j-rock
make
the
first
configuration
and,
after
that,
they
using
G
frog
like
in
any
kind
of
shell.
So
the
logic
is
the
same.
It's
not
important
what
you
are
implementing.
You
are
able
to
implement
everything
that
is
exposing
a
clay
or
an
API.