►
From YouTube: 2021 02 02 Database Team Meeting
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
A
All
right,
then,
we'll
jump
to
the
one.
This
one
was
brought
up
during
the
intradev
meeting.
It's
the
cpu
utilization
peak
times
on
the
projects
table,
and
I
was
wondering
what
the
next
steps
were.
I
thought
it
was
odd
that
was
brought
up
in
that
meeting.
Jose.
Do
you
know
why
it
was
brought
up
in
there?
Is
this
really
as
andreas
calls
out
below?
Is
this
top
five
performance
problem.
B
B
I
can
link
any
of
these
but
yeah
from
my
side.
One
thing
that
we
started
to
work
on
analysis
as
well
now
is
to
share
with
everyone.
Please
is
them
looking
for
a
request
that
are
being
executed
by
sidekiq
on
the
primary
to
analyze
the
volume
and
load
and
trying
to
think
about
it
if
we
will
manage
to
find
a
way
to
move
them
to
secondaries,
but
it's
just
the
latest
new.
A
A
D
B
D
D
We
have
the
analysis
by
jose
has
shown
that
we
have
something
between
500
and
1000
per
per
second
for
most
of
those,
so
we
know
that
those
may
be
problematic,
but
we
also
know
that
those
are
very
quick,
some
millisecond
queries
and
unfortunately
we
don't
have
a
clear
winner
after
this
analysis,
this
is
not
the
case
for
taggings,
so
for
taggings.
We
know
that
we
can
see
from
the
analysis
from
jose
that,
for
example,
that
build
queue
worker
creates
a
lot
of
queries.
D
So
my
opinion
is
that
we,
we
should
continue
checking
this,
and
maybe
we
can
find
something
there,
but
my
proposal
there.
If
everyone
agrees,
I
don't
know
jose.
What
do
you
think
about
that
is
that
for
the
projects
namespace
and
users,
maybe
we
can
wrap
those
and
revisit
them
when
we
have
more
statistics
or
if
we
continue
seeing
those
as
a
problem
like,
for
example,
what
andreas
discussed?
B
Okay,
I
understand,
you
think,
is
a
good
approach.
My
point
is
like
we
will
get
more
statistics.
I
think
in
two
three
weeks,
because
I'm
trying
to
export
more
metrics
from
what
we
did
here,
the
information
that
you
have
in
the
issues,
some
sampling
that
we
collected
me
and
nikolai
and
we
we
analyzed
it
I'm
proposing
to
collect
now
constantly
from
activity,
more
samples
and
more
comments,
and
then
we
will
have
a
huger
base
or
a
larger
base
for
analysis.
B
D
D
We
have
a
lot
of
you
know
that
that
are
equal
in
size.
So
we
have,
you
know
six,
six,
six,
five,
five,
it's
not
like
a
35
and
then
three
two
one
and
that's
why
I'm
discussing
those
three.
We
could
leave
them
open
for
three
weeks.
If
everyone
agrees
and
then
we
can
revisit
them
and
if
the
new
analysis
shows
the
same,
maybe
we
can
think
about
it
then,
and
we
can
follow
with
the
taggings.
D
B
Thank
you.
I
would
like
to
ask
one
more
thing
here
in
the
meeting
any
one
of
you
were
aware
of
the
change
on
the
weekend
on
some,
please
I'm
trying
to
really
blameless
here,
but
just
to
share
awareness
like
we
had
some
changes,
some
crown
job
and
like,
if
you
see
like
simply
the
database,
was
burning
the
whole
weekend.
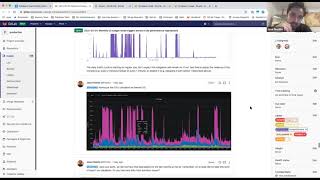
We
had
spikes
of
90
to
100
percent
of
cp
utilization
during
no.
No,
it
was
not
nice
is
that
I
can
share
the
issue
with
you
guys,
everyone,
sorry,
three,
six,
four,
six,
four
in
production,
one!
B
B
B
B
The
funniest
thing,
or
the
sad
thing
is
the
if
you're
checking
my
comment,
the
next
one
that
is
like
where
I
did
a
comment.
I
did
some
research
and
we
had
a
spike,
but
was
one
spike
at
3am
for
a
few
minutes.
Okay
and
unfortunately,
someone
tried
to
optimize
it
and
go
down.
Please
scroll,
all
down.
Please.
B
B
If
you
go
a
bit
up,
you
will
see
like
how
it
was
during
the
last
weekend
with
more
please
here
you
see,
like
was
much
more
massive,
the
spikes
constantly
they
tried
to
spread
the
the
job
during
24
hours
and
the
result
was
a
massive
impact
on
the
database
and
applications
for
the
application.
It
seems
to
be
not
so
negative
because
they
will
consider
this
a
severity
three,
but
I
raised
this
from
the
database.
Perspective
was
pretty.
B
C
D
D
B
B
C
C
B
B
B
C
E
E
This
is
this
is
something
that
we
can
help
and
that
that
would
be
a
good,
a
good
thing,
but
yeah,
because
I
don't
think
it's
I
think,
from
a
sort
of
from
a
scalability
perspective
like
I
think
the
database
label
is
used
as
a
if
it
has
it
right.
It
will
be,
will
be
triaged
by
this
group
eventually,
but
if
people
just
make
changes,
especially
on
the
application
layer,
it's
probably
impossible
to
catch
all
of
those
things.
So
it's
like,
how
will
you
know.
B
Yeah,
because
what
understood
there,
I
don't
know
in
detail
that
change,
but
it
seems
that
was
a
massive
update
there
that,
like
we
got
some
problems
with
the
statistics
and
we
needed
to
run
some
vacuums
there
out
of
vacuums
vacuums
manually
to
fix
the
situation
and
just
sharing
with
you
with
everyone.
Thank
you.
A
D
D
C
D
D
B
Solution
search
interruption,
but
the
vacuum
was
managing
to
collect
better
the
statistics
and
cleaning
up
the
table.
But
my
point
here
is
you
I'm
asking
you
because
you,
the
team
here,
has
more
experience
than
I.
If
you
would
have
executed
this
in
a
database
labs,
perhaps
we
would
see
some
strange
behavior
or
do
you
think
it
wouldn't
happen.
B
D
B
What
happened
the
last
month
is
like.
We
had
an
alert
on
that
turpos.
Then
you
run
out
of
action.
We
are
happy,
but
we
had
just
one
spike
in
2
3
a.m.
In
the
weekend
that
was
yeah
thankful
in
the
first
of
the
month,
because
my
my
main
concern
here
is
like,
thankfully,
this
run
on
the
on
the
on
the
off
peak
time
or
weekend,
because
if
we
execute
this
during
a
tuesday,
I
think
the
impact
would
be
higher.
C
C
B
A
C
E
B
E
E
A
D
D
F
Yeah,
the
tagging's
one,
I
think
I
do
agree.
We
should
prioritize
it.
I
think
there's
maybe
it
might
even
be
a
bigger
issue
than
we
know,
because
when
I
was
looking
at
the
one
that
went
into
triage
recently
when
we
had
the
migration
that
failed
on
the
name
space
table,
because
we
weren't
able
to
get
the
lock
due
to
like
a
long-running
transaction,
we
found
that
statements
were
timing
out
or
though
the
requests
were
timing
out.
F
Was
discussed
in
one
of
the
issues,
so
it's
very
inefficient
the
way
it
does
it.
If
you
add,
like
10
taggings,
to
say
to
like
a
runner,
it
runs
10,
individual
queries,
it
runs
10,
individual
inserts
and
I
think
in
that
case,
particularly
it's
hitting
some
like
pathological
case
or
something
where
it's
basically
stuck
in
a
loop.
And
it's
trying
to
do
like
that.
Like
tens
of
thousands
of
queries
and
then
this
the
request
is
timing
out,
so
I
think
the
yeah,
the
tanks,
one
that's
worth
looking
into.
F
A
D
That's
my
question:
how
I
see
things
so
the
statistics
on
how
often
queries
run?
What's
the
cpu
cost,
what
was
the
load
on
the
database?
Those
are
there
to
explain
why
we
need
to
investigate
and
justify
that.
This
is
a
problem
so
and
then
what
jose
was
adding
afterwards.
The
analysis
with
the
sampling
analysis
or
whatever
other
analysis
we
do
is
the
to
debug
and
to
figure
out
the
root
cause.
So
I
think
that
we
need
both.
I
don't
know
if-
and
everyone
agrees.
C
A
Is
there
anything
else
we
should
add
to
this
template
now,
so
we
can
start
using
it
going
forward
and,
as
andrea
said,
if
there's
anything
missing,
we
can
iterate
on
it.
But
I
want
to
get
a
starting
point.
We
can
close
this
out
and
say
we're
all
in
an
agreement
and
then,
like
I
said,
iterate,
I
don't
think
this
needs
to
stay
open
or
we
need
to
spend
a
ton
of
time
on.
I
think
we
have
a
pretty
good
understanding
of
what
we
want
now
and
how
we
want
to
proceed
going
forward.
A
A
C
B
D
B
C
A
C
A
C
E
D
D
E
C
C
F
Yeah,
the
the
first
one
really,
I
think,
can
be
closed.
Now
it's
been
more
than
24
hours.
I
just
wanted
to
make
sure
everything
was
breaking,
but
I
haven't
heard
any
or
seen
any
reports
of
anything
the
second
one,
the
the
first,
mr
that's
using
it
that
this
was
blocking
is
going
to
go
be
merged
very
soon.
So
I
think
I'll
just
make
sure
that
that
mr
or
that
the
new
migration
helper
works
properly
and
that
should
be.
A
C
F
It
so
we
sort
of
had
a
discussion
about
this
a
little
last
week,
giannis
and
andreas,
and
I-
and
so
I
think
we
need
to
maybe
have
a
follow-up
from
that
conversation.
Basically
we're
talking
about.
You
know
it's
very
hard
to
manage
this
migration
because
we
don't
know
production
timings.
Really.
We
were
talking
about
doing
initially
doing
like
a
sampling
approach
so
that
we
would
change
the
schema.
F
F
So
I
think
we
want
to
have
a
conversation
around
that
a
little
bit
more
instead
of
putting
together
some
ideas,
but
also,
obviously,
we
have
a
sort
of
a
timeline
that
we
need
to
get
these
migrations
out.
So
I
think
we
need
to
figure
out
if
there's
something
that
we
can
work
on.
It's
not
going
to
be.
C
C
A
C
D
C
E
D
D
D
E
But
I
do.
I
do
think
and
correct
me
if
I'm
wrong
here,
that
there
is
a
hard
failure
date
on
those
things,
but
at
some
point
things
are
going
to
just
crash
and
burn
right.
So
in
my
mind
we
should
you
know
this
is
the
thing
that
we
really
need
to
get
a
good
handle
on,
and
I
think,
as
andrea
said,
this
is
likely
going
to
happen
in
other
areas
as
well.
E
So
you
know
if
we
can't,
then
we
still
need
to
do
it
manual
because
it's
it's,
but
it's
going
to
be
very
painful
and
error-prone
and
all
of
those
things.
So
if
we
can
find
a
pragmatic
solution
to
make
this
easier,
I
think
that's
good,
but
I
like
my
worry,
is
obviously
right.
If
you,
if
we
spend
some
some
months
finding
that
nice
solution
and
then
it
doesn't
quite
materialize,
you're
going
to
do
it
manually,
anyways
and
then
it's
going
to
be
really
rushed
right.
D
C
And
we
talked
about
this
today
and
we
shouldn't
bet
on
on
the
refactorings
that
we
are
discussing
right,
so
we
we
might
have
a
big
refactoring
coming
up
for
the
eyeballs.
That
also
incorporates
that.
So
we
don't
have
to
do
it
in,
in
that
case
we're
fortunate.
But
we
shouldn't
bet
on
that
and
we
need.
We
need
a
good
solution
anyways,
because
we
have
these
problems
in
other
places
as
well.
C
E
Is
this,
maybe
I
don't
know
if,
if
you
do
do
this,
but
is
this
maybe
a
large
enough
sort
of
project
to
take
an
afternoon
as
a
group
with
some
coffee
and
map
out
those
plans
and
talk
about
it,
sort
of
synchronously
and
just
say
like
okay?
This
is
how
how
it
looks
right
and
have
that
discussion
so
so
that
we
we
we
do
this
proactively
rather
than
when
things
are
starting
to
get
a
little
bit
out
of
out
of
the
hand,
maybe
as.
A
B
D
E
C
F
C
C
Otherwise
I
would
be
working
on
the
instrumentation.
This
is
the
next
on
the
next
tab,
which
enables
us
to
to
actually
use
this
testing
pipeline,
which
also
helps
the
other,
mrs,
because
this
is
just
migrations
that
we
want
to
run
on
the
database,
and
I
would
like
to
see
those
mrs
run
on
the
testing
pipeline.
C
A
C
D
C
A
F
There's
the
second
part
or
the
the
related
one
to
that,
which
is
the
third
one,
which
is
adding
the
migration
helpers,
that's
something
that
we
can
potentially
start
working
on
once
we
figure
out
what
we're
doing,
but
the
converting
the
events
id
we
haven't
even
done
the
first
part.
Yet
so
I'd
say
we're
not
going
to
tackle
that
for
some
months
or
weeks.
A
D
F
Yeah,
it's
really
I
just
the
actual
dropping
the
table
and
stuff
should
be
fast.
It's
really
just
the
post
analysis
hasn't
really
been
done
yet,
which
I
would
like
to
do
so
we
can
clean
all
that
up
and
be
done
with
it.
Finally,
I
just
haven't
really
got
around
to
it,
so
I
guess
if,
if
you
feel
that
you
have
any
time
for
that,
you
probably
don't
you
want
to
look
at
it
or
anyone
wants
to
contribute.
F
D
E
E
That's
always
the
question
I'm
sort
of
asking
like
at
the
end
is
like:
if,
if
these
are
not
just-
and
I
I
kind
of
know
that
they
are
but
I'm
that's
always
what
I'm
interested
in
and
given
how
much
work
is
in
depth
and
how
many
items
are
in
here.
I
think
there's
nothing.
We
need
to
schedule
for
the
next
week.
E
I
think
and
again
I
think
what
I'm
most
interested
in
personally
is
sort
of
the
cycle,
time
right
so
having
issues
that
are
small
enough
and
really
find
enough,
so
that
they
can
go
from
ready
for
development
into
you
know
being
closed
in
a
relatively
short
amount
of
time,
and
I
think
that
is
actually
quite
nice.
So
maybe
that's
something
we
can
also
look
at
at
some
point.
It's
like
if
some
of
these
issues
are
large
right
and
if
we
can
make
them
smaller,
but
that's
for
the
future.