►
From YouTube: Mixed-deployment pipeline re-ordering
Description
Members of Delivery and Quality discuss options for improving coverage for mixed-deployment testing as part of the deployment pipeline
A
B
Thank
you
amy,
so
we
started
writing
this
kind
of
extract
of
what
can
cause
a
mixed
deployment
failure.
So
I
would
not
go
into
detail
because
I
saw
jeff
commenting
there
and
already
created
an
issue,
so
we
just
wanted
to
point
out
that
compared
to
the
use
case
that
we
identified
in
the
in
starting
this
effort,
there
are
many
other
which
may
be
harder
to
identify
in
the
beginning.
B
So
you
just
want
to
give
raise
awareness
about
what
can
go
wrong
and
other
point
of
interaction
where
a
multi
version
deployment
can
cause
a
failure.
Here
there
is
a
list.
I
would
not
go
through
it.
If
someone
has
a
question,
I
will
be
happy
to
answer
them
even
in
the
issue
that
they've
opened.
So
it's
just
that
everywhere
there
is
a
process
and
then
a
process
boundary.
There
is
an
opportunity
for
a
problem
during
mixed
deployment
testing.
So
that's
it
next
is:
let's
say
you
were
amy.
A
Yes,
so
so
we
have
a
proposal,
let
me
actually
share
the
screen.
So
we've
come
up
since
before
between
my
scheduling
of
this.
This
thing
and
I
was
actually
meeting
today-
we've
come
up
with
a
hopefully
improved
proposal,
which
I
think
works.
We
believe
from
our
modeling
covers
all
the
kind
of
use
cases
and
concerns
that
were
raised
in
the
issues.
A
This
was
started
off
as
a
personal
thing,
and
I
was
like
my
my
brain
cannot
comprehend
this
much
information,
so
he
started
modeling
it
out
so
leslie
and
I
spent
quite
a
bit
of
time
on
on
friday,
coming
up
with
sort
of
a
new
option.
For,
but
let's
hear
do
you
want
to
give
the
overview
of
this
because
I
think
you've
kind
of
internalized
this.
The
most.
B
There
is
a
key
bit
here
that
simply
this
was
important
to
say
ahead
of
time,
so
in
production
we
use
canary
as
a
way
to
diminish
the
blessing
radius
of
new
changes,
because
we
have
a
small
percentage
of
traffic
that
goes
to
canary,
and
so
this
is
help
us
identify
errors
without
affecting
too
many
users.
What
we
want
to
have
here
in
this
proposal
is
the
flip
side
of
it
so
having
a
bigger
canary
in
staging
that
amplifies
error,
so
that
we
can
spot
them
ahead
of
time
and
having
a
smaller
production.
B
Sorry,
a
staging
main
just
for
the
effort
of
making
sure
that
we
can
run
mixed
deployment
tests,
so
just
as
a
visual
consider
that
if
we
do
five
percent
of
traffic
in
production
canary,
I
will
expect
having
95
percent
of
traffic
routed
by
default
on
staging
canary
in
in
this
environment.
Okay,
so
at
the
end
of
staging
canary,
we
can
run
qa
both
mixed
and
something
that
just
targets
the
new
version.
B
B
So
when
both
staging
and
production
main
are
deployed,
we
can
hook
into
the
pos
deployment
migration
run,
which
in
our
own
schedule,
so
as
a
delivery
team,
we
are
planning
to
remove
from
the
deployment.
So
this
kind
of
help
us,
because
we
are
condensing
all
the
positive
migration
together,
because
then
we
want
to
move
them
on
a
different
schedule,
but
so
the
takeaway
here
is
that
it
solves
the
problem
because
we
have.
We
are
always
testing
multiversions
compatibility
with
the
two
versions
that
are
they
will
be
running
in
in
production.
B
B
B
B
B
We
hope
with
this
effort
to
be
able
to
add
a
third
signal,
which
is
basically
the
slo
matrix
from
the
new
staging
environment,
which
is
where
we
can
basically
compare
staging
main
with
staging
canary.
So
if
any
of
the
mixer
deployment
use
case
that
we
haven't
tested.
Yet,
if
we
are
running
qa
on
it,
they
will
just
generate
errors,
and
so
having
a
spike
in
errors
could
be
something
that
we
say.
Maybe
something
is
wrong
here.
Let's
stop
this
build
for
a
moment
and
try
to
figure
out.
What's
going
on,
okay,.
C
C
You
only
need
a
minimum
amount
of
traffic
being
on
the
other
version,
so
the
the
current
sorry
yeah,
there's
no
m
in
gstg,
so
I
having
some
some
nomenclature
that
helps
so
the
old
version,
the
previous
version,
minimum
traffic
on
stage
main
staging
and
then
the
bulk
of
the
hardship
that
we
want
to
test
on
canary
station.
That
makes
a
lot
of
sense.
C
A
A
But
the
only
thing
that
we
really
need
to
control
is
the
package
that
we
have
on
g-staging.
So
g-staging
is
our
sort
of
control
environment
that
we
will
test
against,
which
is
acting
as
production
ends
up
acting
against
g
g
prod
canary.
So
all
of
the
same
testing
that
we
do
at
the
moment
with
the
addition
of
the
new
mixed
deployment
tests
would
still
happen
on
the
three
environments
we
just
control,
at
which
point
we
actually
do
the
deployment
to
g-staging.
B
A
We
perhaps
feel
like,
maybe
for
like
marketing
and
kind
of,
like
external
views,
we'd
probably
need
to
try
and
show
this
as
a
there's,
probably
a
separate
view
of
maybe
a
like
a
like
a
testing
flow,
or
something
like
that,
because
we
still
would
do
exactly
the
same
as
what
we're
doing
right
now.
We
do.
D
A
A
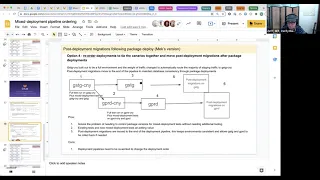
Of
I
think
slide,
19
kind
of
shows
this
the
best.
So
what
we
need
to
be
able
to
control
is
around
steps.
Two
is
kind
of
the
one
that
the
key
step
where
what
we
want
to
end
up
with
is
this
the
canaries
and
the
main
stages,
plus
the
database
being
remaining
consistent,
whereas
if
we
continue
with
the
pipeline
as
we
currently
have
it,
where
we
do
a
staging
canary,
plus
staging
and
then
gpod
canary,
we
kind
of
step
through
it
and
that's
where
we
start
to
get
particularly
the
database.
C
Okay,
can
you
please
go
back
to
17?
Yes,
I
I
think
this
sounds
good.
We.
I
would
like
to
see
more
visibility
on
what
actually
happens
between
two
and
these
two
three
boxes
can.
Can
you
go
to
18,
so
I
just
created
this
on
the
fly.
Is
it
more
like
this,
where
it's
actually
a
dual
dual
track
of
the
staging
and
fraud,
and
then
we
are?
This
is
probably
like
closer
here
right.
C
You
want
to
shorten
the
time
and
having
an
actual
visual
on
what
the
time
frame
is,
is
helpful
for
me,
and
maybe
it's.
This
is
what
you're
we
are
doing,
but
it
shows
the
clarity
in
the
environment
tracks
and
how
it
lands
in
production
and
if
something
happens
before
production
by
maybe
five
minutes
or
ten
minutes.
C
That
helps
us
understand
if
we
have
enough
window
to
revert
things
or
stop
things
going
wrong
into
production
from
a
from
an
electrical
perspective.
The
key
is
we're
preventing
issues
going
into
production
and
it
should
be
done
in
the
name
space
of
staging
and
b,
if
it's,
if
we're
catching
most
of
it
in
staging
canary,
that's
great
and
then
minimum
time
in
in
g-staging
main.
A
So
staging
and
production
would
be
in
parallel,
and
that
would
be
important
because
we
we
wouldn't
want
to
upgrade
our
staging
environment
like
our
control
environment.
Until
the
point
where
we
also
know
we
want
to
upgrade
our
production
environment.
So
that
would
that's
at
the
point
where
we
sort
of
conclude
the
testing
round
and
we
upgrade
everything
and
move
on
to
the
next
version.
A
But
what
we
could
do
here,
maybe
to
make
this
clearer,
is
add
in
so
what
we've
shown
here
is
just
the
stages
through
the
environment,
but
perhaps
what
we
could
show
is
actually
the
flow
of
events
and
compare
those
so,
for
example,
right
now
we
do
deployments,
and
then
we
run
certain
test
suites
and
we
have
baking
times
and
the
only
thing
that's
changing
is
which
environments
get
hit
between
all
those
things.
All
of
the
same
control
gates
are
still
in
place
with
the
same
duration,
but
we
could
certainly
map
that
out.
A
D
A
Is
a
is
a
fuller
environment.
What
we
would
do
is
build
out,
g-stage
and
canary
to
be
a
full
environment,
so
developers
needing
to
test
things
could
could
fully
test
things
on
g-stage
and
canary
as
well
as
kind
of
running
qa,
suites
and
things.
So
what
we
would
actually
end
up
doing
is
kind
of
repurposing,
a
lightweight
staging
environment
and
make
it
a
bit
more
dedicated
to
guaranteeing,
as
we
have
the
right
package
to
be
able
to
test
against.
D
That
way,
we
always
have
this
stable
environment,
where
we
can
test
any
other
changes
that
we
would
introduce.
That
would
come
up
through
g-staging
canary
now,
instead
against
a
true
production-like
environment,
same
package
level
same
everything,
which
is
the
piece
that
we're
missing.
Whereas
if
we
would
upstate
update
g
staging
before
g
prod,
then
we
would
end
up
missing
out
on
that.
D
B
Yeah
this
is
this
could
happen
basically
every
day,
because
we
do
automated
promotion
up
until
production
canary.
So
with
the
current
workflow
we
do
staging
canary,
then
we
do
staging
staging
main,
obviously,
and
then
we
do
production
canary
so
and
then
there's
a
manual
there's
baking
time
and
manual
promotion.
So
if,
for
any
reason,
a
package
is
not
promoted,
there's
no
release
manager
around
or
there
are
other.
There
are
incidents
and
things
like
that.
B
So
even
less,
I'm
expecting
that
if,
as
staging
is,
I
would
say,
shrink
down
not
really
shrink
down,
but
you
get
the
point
that
the
bulk
of
the
traffic
goes
in
in
staging
canary,
so
staging
it.
Staging
main
has
less
load
on
it,
so
would
be
faster
to
deploy,
and
this
will
basically
give
us
an
opportunity
to
run
post
deployment.
Migration
on
staging
and
a
full
qa
run.
C
Helpful,
I
I
think,
there's
some
if
it's
60
seconds
or
five
minutes,
that's
that's
different
right.
When
you
go
to
our
customers,
we're
not
telling
them
that
hey,
we,
you
are
getting
the
same
changes
in
production.
The
same
time.
We
deployed
to
staging
that
that
that
is
a
wrong
perception
to
set
to
our
customers,
especially
when,
when
they're
asked,
I
I'm
ibm
I'm
being
asked
by
my
customers.
How
are
you
testing
it?
C
C
A
I
think
I
mean
that's
a
that
was
almost
sort
of
a
secondary
benefit.
Actually,
when
we
worked
out
the
the
the
new
order.
Actually,
the
the
challenge
that
we're
trying
to
that
we
really
need
to
manage
here
is
the
controlling
which
packages
are
on
which
environment
and
being
able
to
guarantee
those
and
and
also
be
able
to
recover.
Because
say
we
do,
but
once
we've
run
post-employment
migrations,
we
can't
roll
back.
C
A
We
can
certainly
put
some-
I
mean
there
will
be
like
a
last
case.
There
actually
will
be
some
time
on
staging
the
difference
between
staging
and
production,
but
we
can
work
that
out.
We
could
guarantee
that
there
is
a
you
know.
It
would
be
multiple
minutes,
so
we
could
guarantee.
There
is
always
like
10
minutes
or
whatever
an
exception.
We
can.
B
So
this
is
my
qa
sp
qa
suit
is
the
only
thing
that
I
know
that
I
can
test
and
I'm
just
telling
you
to
run
only
on
the
machine
that
are
upgraded
and
because
this
new
environment
will
be
a
full
environment,
so
he
will
have
a
prefect
we'll
have
connect
we'll
have
easily
all
the
components
in
there.
This
will
cover
the
package.
C
C
A
That's
right
like
we.
What
we'll
do
is
we'll
do
this
reordering
from
within
delivery,
so
that
we
have
it'll
be
most
likely
graham
actually
to
work
out
projects.
So
we'll
have
someone
who
understands
kind
of
the
intricacies
of
deployments,
we'll
do
the
ordering,
and
then
we
can
work
really
closely
with
with,
therefore,
or
whoever
else.
We
need
to
to
actually
check
that.
We
have
all
the
testing
that
we
want
to
have
in
place
and
monitor
deploys.
But
absolutely
if
we
need
to
change
stuff,
we
can
absolutely
change
that.
C
C
So
is
it
something
that
we
could
say
that
when
things
flow
into
box
one
and
box
two,
we
are
like
80
percent
confidence
that
if
nothing
happens
in
box
one
and
box,
two
80
percent,
confident
that
production
is
going
to
be
okay
and
then,
when
the
box
three
lands
in
that
fills
another
the
reverse
of
the
2080.
It's
like,
okay,
those
are
the
edge
cases
we
tried
our
best
and
then,
when
this
is
done,
we
are
100,
confident
that
four
is
going
to
be
the
green
field.
B
To
you
that
doesn't
make
sense,
there's
also
another
box
that
you
can
draw,
which
is
around.
I
mean
five
is
kind
of
a
safety
belt
around
six,
because
we
cons
right
now.
This
is
our
alignment
that
we
have
in
delivery
is
that
we
are
considering
positive
development
migration
as
a
separate
type
of
deployment,
because
the.
D
B
B
But
the
point
is
that
this
reordering
will
give
us
the
confidence
that,
if
something
goes
wrong
in
five,
it
will
not
affect
production,
and
we
will
still
be
able
to
ship
a
package
that
fix
the
fi,
the
failure
on
five
and
make
sure
that
we
don't
obtain
the
production
database
with
our
failed
possible
migration
until
we
are
sure
that
post
deployment
migration
are
fine
on
staging
as
well.
Okay,
it's
cool.
A
One
one
little
caveat:
I
would
like
to
add
those
I,
the
number
is
certainly
very
high,
but
I
don't
think
it's
100
to.
We
still
have
the
problem
of
the
limitations
of
the
staging
environments.
We
still
have
the
data
problems,
so
I
think
that
this
changing
this
order
and
adding
these
tests
certainly
removes
like
a
fairly
big
risk
area
that
we
know
of,
but
I
don't
think
it
eliminates
all
risk
areas
yeah.
There.
A
Yeah
exactly
yeah,
okay,
that's
right,
and
I
think
some
of
the
I
mean.
I
think
it
will
be
a
case
of
us
trying
to
categorize
incidents
into
things
like
mixed
deployment
and
work
out
like
where,
where
was
the
gap
like?
What's
the
thing
that
we
need
to
like,
modify
or
improve
to
change,
to,
try
and
eliminate
them?
Yep.
C
Okay,
cool
yeah:
if
we
can
align
on
this
and
outline
this
as
the
confidence
boundaries
say,
maybe
99.5
or
90
confidence
that
the
four
is
going
to
be
okay
and
then
the
five
and
six
is
its
own,
separate
one.
If
we
do
that
and
that
ensures
that
six
can
run
fine
in
production,
if,
if
we
need
it
so
yeah,
I
think
it
makes
sense
we
should
we
should.
C
A
Okay,
excellent.
What
I
do,
then,
is,
I
think,
you're
right
like
18,
is
a
more
accurate
representation.
So
we'll
we'll
rework
the
the
diagram
to
show
the
kind
of
the
ordering,
and
we
can
add
the
timings
and
try
and
make
it
a
little
clearer
as
well
about
the
the
activities
that
are
taking
place
as
well
in
amongst
these
boxes,
yep.