►
Description
We discussed the details a proposed query for store root-namespace storage statistics on database https://gitlab.com/gitlab-org/gitlab-ce/issues/62214
A
Okay,
we
are
recording,
so
thank
you.
Thank
you
for
joining
this
code.
The
thing
I
would
like
to
discuss
is
what
we
are
doing
for
this
performance
problem
in
the
aggregation
of
storage
usage
for
namespaces.
You
know
the
the
thing
is
that
we
have
this:
let's
start
with
sharing
the
screen,
maybe
so
that
we
can
do
this.
B
A
We
started
discussing
doing
this
namespace
migration
for
tagging,
the
the
road
namespace,
but
in
the
meantime
my
plan
was
started
working
on
the
next
part
of
it
and
I
and
I
said:
I
just
need
the
aggregated
data.
I
can
just
do
slow,
query
and
object
and
then,
when
we
would
be
ready,
I
will
replace
it.
So
this
was
my
my
certain
point,
but
then
because
I
was
reviewing
my
report.
I
said
this:
is
this
we
really
too
slow
for
using
fresh?
So
that's
why
I
brought
this
now.
B
A
Things
here
and
from
what
I
understand
here
is
this
know
that
okay,
so
exclusives
means
only
this
node
inclusive
means
this
node
and
everything
below
yeah,
and
this
is
just
rows.
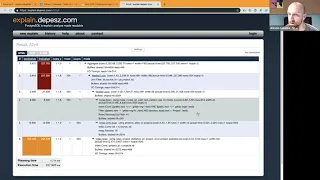
X
is
if
the
planner
underestimate,
or
overestimate
the
number
of
Drago
returned
by
it.
So
that's
the
thing
and
then
the
number
of
row
that
it
returns
and
those
okay
yeah
so
from
what
I
do
understand
here,
is
that
this
part
line
number
six
is
taking
a
lot
of
time.
A
B
Yeah,
so
the
the
thing
here
is
the
the
reason
you
see
these
loop
counts
is
because
the
second
node
is
a
nested
loop
and
that's
in
this
case
I
believe
because
we
do
with
some
with
the
the
group
by
you'll,
essentially
loop
over
every
row
and
aggregate
them.
So
the
in
this
particular
case,
most
of
the
time,
spend
just
fetching
that
data,
because
summing
the
extra
numbers
is
very
fast.
B
A
B
B
B
So
here
this
is
so
normally
for
me,
a
query
that
is
slow
is
something
that
takes,
let's
say
more
than
20
milliseconds
and
that's
that's
a
very
small
number.
But
it's
mostly
because
when
we
look
at
WebP
requests
we
typically
have
50
200
sequel
queries.
So
if
everyone
takes
more
than
it
adds
up
very
quickly
sure
and
I
think
for
a
while,
we
have
the
sort
of
goal
that
prayer
requests.
A
A
A
Suggestion
that
I
made
here
as
an
improvement
is
following
the
same
pattern
that
we
are
doing
for
the
project.
Statistics,
which
is
get
leads
on
Redis
15
minutes
leads.
We
can
change
the
number
so
update
now
and
update
at
the
end
of
the
lease
and
sir
everything
in
between.
Don't
don't
update
it
because
yeah
so
you
have,
it
can
be
current
data
or
like
15
minutes
all.
B
B
B
And
so
I
would
say,
probably
for
now.
I
think
this
is
good
enough,
because
I
don't
think
anybody
can
come
up
with
a
better
way.
Okay
and
I.
Think
the
only
better
way
is.
If
you
do
this
approach,
we
initially
thought
of
like
where
it's
incrementally
updated
for
project
and
but
it
gets
super
complicated,
yeah,
I.
A
B
B
A
B
Expect
we
might
have
to
tweak
the
intervals
a
little
bit
and
stuff
like
that.
I
I
personally,
would
be
fine
if
you
just
do
one
update
per
day,
but
I
think
some
of
there
are
people
like
sails
on
such
whatever
they.
They
might
not
be
happy
with
that,
but
I
will
probably
start
with
updating,
ideally
updating
less
often
than
more
often
simply
because
if
he
lets
say
we
deploy
this
and
we
update
the
statistics
at
most
once
every
10
minutes,
yeah.
A
B
B
B
A
B
B
B
B
B
Basically,
it's
yeah
I
think
application
aesthetics
might
be
overkill,
because
I
will
prefer
that
we
provide
a
value
that
works
for
pretty
much
everybody
and
frankly,
we're
probably
only
one
is
actually
gonna
use.
This
I
don't
think
we
have
like.
We
can
set
values
in
future
flex
and
retrieve
those
there
they're
all
boolean.
As
far
as
I
know,.
B
C
B
C
B
Let's
say
we
enable
this
trickle
up,
or
can
we
say
once
per
hour
and
we
find
out?
Oh
you
know
that
even
is
too
much.
Ideally,
we
want
to
be
able
to
very
quickly
change
that
setting
that
how
I
could
go
through
the
deploy
process,
so
I
think
if
you
in
a
llamó
file,
we
probably
have
to
start
messing
with
omnibus,
which
is
not
ideal
know
if
you
do
an
application
sense,
we
have
to
create
a
UI
field
and
stuff
for
something
that
people
probably
will
never
change.
B
A
Good,
so
let
me
check
so
I
actually
think
that
this
solves
or
the
the
question
that
we
have.
Oh,
no,
because
this
we
can
add,
maybe
Mayra
already
did
I,
don't
remember
because
we
discussed
we
have
the
updated
at
in
the
root
in
the
aggregated
statistics.
So,
from
the
UI
point
of
view
we
can
say
this
is
the
number,
but
it's
updated
to
that
hour,
because
we.
B
B
A
A
B
I
think
it's
query,
you
know,
since
it
doesn't
run
that
often
should
be
fine
and
I
think
should
we
have
cases
where
we
run
this
too
often
or
too
many
times
in
parallel.
You
can
always
increase
the
interval
or
maybe
spread
it
out
more
where
you
say,
oh
by
default,
we
enforce
the
interval
for
our
body.
If
you
have
this
many
jobs,
we
might
increase
it
for
some.
You
can
go
very
far
with
them.
Okay,.